目录
分析慢 SQL
SQL 优化
单表优化
多表优化
- 慢 SQL:指 MySQL 中执行比较慢的 SQL
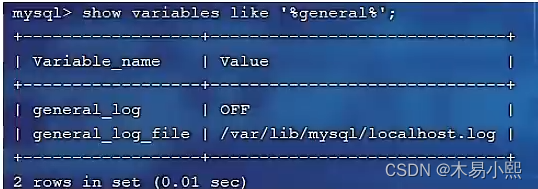
- 排查慢 SQL 最常用的方法:通过慢查询日志来查找慢 SQL
MySQL 的慢查询日志是 MySQL 提供的一种日志记录,它用来记录在 MySQL 中响应时间超过阈值的语句,具体指运行时间超过 long_query_time(慢查询阈值) 值的 SQL,就会被记录到慢查询日志中,long_query_time 的默认值为 10s,意思是运行超过 10s 以上的语句就会被当做慢 SQL 记录到日志中。
分析慢 SQL
如果一条 sql 执行很慢的话,我们通常会使用 mysql 自动的执行计划 explain 来去查看这条 sql 的执行情况

关注 type 字段:
- all — 扫描全表数据
- index — 遍历索引
- range — 索引范围查找
- index_subquery — 在子查询中使用 ref
- unique_subquery — 在子查询中使用 eq_ref
- ref_or_null — 对 null 进行索引的优化的 ref
- fulltext — 使用全文索引
- ref — 使用非唯一索引查找数据
- eq_ref — 在 join 查询中使用主键或唯一索引关联
- const — 将一个主键放置到 where 后面作为条件查询, MySQL 优化器就能把这次查询优化转化为一个常量,如何转化以及何时转化,这个取决于优化器,这个比 eq_ref 效率高一点。
如果存在全索引扫描(type = all) 则说明没有走索引,我们可以给查询的慢字段加上相应的索引就可以提交效率。
通过 key 和 key_len 检查是否命中了索引,如果本身已经添加了索引,也可以判断索引是否又失效的情况
通过 extra 建议判断是否出现回表的情况,如果出现了可以尝试添加索引或修改返回字段来修复
SQL 优化
MySQL 优化分为 单表优化 和 多表优化
单表优化
- 建立并使用索引:索引是提高查询最有效的手段
- 优化查询语句:避免使用 select * ,只查询需要的字段;使用小表驱动大表,比如当 B 表的数据小于 A 表时,先查 B 表,再查 A 表,查询语句:select * from A where id in (select id from B);如果是聚合查询,尽量使用 union all 代替 union,union 会多义词过滤,效率比较低;不使用 order by rand();
- 优化表结构和数据类型:单表不要有太多字段,建议在 20 个字段以内,使用可以存下数据最小的数据类型,尽可能使用 not null 定义字段,因为 null 占用 4 字节空间。
多表优化
- 表拆分:就是分表,让每张表的数据量变小,从而提高查询效率。表拆分又分为:垂直分隔和水平分隔。
垂直拆分:是指数据表列的拆分,把一张列比较多的表拆分为多张表,比如,用户表中一些字段经常被访问,将这些字段放在一张表中,另外一些不常用的字段放在另一张表中,插入数据时,使用事务确保两张表的数据一致性。
水平拆分:指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张的表的数据拆成多张表来存放。通常情况下,我们使用取模的方式来进行表的拆分,比如,一张有 400W 的用户表 users,为提高其查询效率我们把其分成 4 张表 users1,users2,users3,users4,然后通过用户 ID 取模的方法,同时查询、更新、删除也是通过取模的方法来操作。
- 读写分离:一般情况下对数据库而言都是“读多写少”,换言之,数据库的压力多数是因为大量的读取数据的操作造成的,我们可以采用数据库集群的方案,使用一个库作为主库,负责写入数据;其他库为从库,负责读取数据。这样可以缓解对数据库的访问压力。
优化方式有很多, 比如索引、查询优化(减少联表查询等)、减少锁竞争等因素,所以具体的慢 SQL 优化,需要根据实际的业务场景再做优化决策。