HTTP(Hypertext Transfer Protocol)是一种用于传输超文本的协议。它是一种无状态的、应用层的协议,用于在计算机之间传输超文本文档,通常在 Web 浏览器和 Web 服务器之间进行数据通信。HTTP 是由互联网工程任务组(IETF)定义的,它是基于客户端-服务器模型的协议,其中客户端向服务器发送请求,服务器以相应的数据作为响应。HTTP 协议是建立在 TCP/IP 协议之上的,通常使用默认的端口号80。
以下是 HTTP 的一些关键特点:
- 文本协议: HTTP 是一种文本协议,通过纯文本的方式传输数据。这使得它易于阅读和调试,但也带来了一些安全性方面的问题,因此在需要更安全的通信时,通常会使用 HTTPS(HTTP Secure)来加密通信内容。
- 无状态协议: HTTP 是一种无状态协议,意味着每个请求和响应之间都是相互独立的,服务器不会保存关于客户端的任何状态信息。这导致了一些问题,例如在进行用户身份验证时,需要额外的机制来保持状态。
- 请求方法: HTTP 定义了一组请求方法,其中最常见的包括 GET(获取资源)、POST(提交数据)、PUT(更新资源)、DELETE(删除资源)等。这些方法指示了客户端对服务器执行的操作。
- 状态码: 服务器在响应中返回一个状态码,用于表示请求的处理结果。常见的状态码包括200(OK,请求成功)、404(Not Found,未找到请求的资源)、500(Internal Server Error,服务器内部错误)等。
- URL(Uniform Resource Locator): HTTP 使用 URL 来标识和定位网络上的资源。URL 包括协议部分(如 “http://”)、主机名(如 “www.xxx.com”)、路径部分等。
- Header(报头): HTTP 的请求和响应中都包含头部信息,用于传递关于消息的附加信息。头部可以包含各种信息,如身份验证信息、内容类型、缓存控制等。
HTTP 是万维网上数据通信的基础,它定义了客户端和服务器之间的通信规范。它支持超文本(Hypertext),使得用户能够通过点击链接访问和浏览相关的文档和资源,是构建 Web 应用程序的重要基础之一。
Web路径分割
如下提供的代码片段包含了两个用于分割URL的函数:HttpUrlSplitA和HttpUrlSplitB。这些函数的目的是从给定的URL中提取主机名和路径。下面是对两个函数的概述:
HttpUrlSplitA函数:- 使用Windows API的
InternetCrackUrl函数,该函数专门用于解析URL。 - 通过
URL_COMPONENTS结构体来传递和接收URL的不同部分,包括主机名和路径。 - 适用于对URL进行标准化处理的情境,直接调用系统提供的功能。
- 使用Windows API的
HttpUrlSplitB函数:- 手动实现对URL的解析,通过检查URL的开头,然后手动提取主机名和路径。
- 对URL进行了一些基本的检查,如是否以 “http://” 或 “https://” 开头。
- 提供了一种更灵活的方式,但需要开发者自己处理解析逻辑。
总体而言,这两个函数都属于URL处理的一部分,但选择使用哪个函数可能取决于具体的项目需求和开发者的偏好。HttpUrlSplitA直接利用Windows API提供的功能,更为直观。而HttpUrlSplitB则通过手动解析,提供了更多的控制权。在实际项目中,选择取决于开发者对项目的要求和对代码控制的需求。
InternetCrackUrl 用于解析 URL。它将 URL 拆分为各个组成部分,例如协议、主机名、端口、路径等。这个函数的目的是方便开发者处理 URL,以便更容易地获取和使用其中的信息。
以下是关于 InternetCrackUrl 函数的一些关键信息:
BOOL InternetCrackUrl(
_In_ PCTSTR lpszUrl,
_In_ DWORD dwUrlLength,
_In_ DWORD dwFlags,
_Out_ LPURL_COMPONENTS lpUrlComponents
);
lpszUrl: 指向包含 URL 字符串的空终止字符串的指针。dwUrlLength: URL 字符串的长度,如果是 NULL 终止字符串,可以设置为DWORD(-1)。dwFlags: 一组标志,用于指定解析行为。lpUrlComponents: 指向一个URL_COMPONENTS结构体的指针,该结构体用于接收 URL 的各个组成部分。
URL_COMPONENTS 结构体包括以下字段:
typedef struct _URL_COMPONENTS {
DWORD dwStructSize;
LPTSTR lpszScheme;
DWORD dwSchemeLength;
INTERNET_SCHEME nScheme;
LPTSTR lpszHostName;
DWORD dwHostNameLength;
INTERNET_PORT nPort;
LPTSTR lpszUserName;
DWORD dwUserNameLength;
LPTSTR lpszPassword;
DWORD dwPasswordLength;
LPTSTR lpszUrlPath;
DWORD dwUrlPathLength;
LPTSTR lpszExtraInfo;
DWORD dwExtraInfoLength;
} URL_COMPONENTS, *LPURL_COMPONENTS;
dwStructSize: 结构体大小。lpszScheme: 指向字符串的指针,该字符串包含 URL 的方案部分(如 “http”)。nScheme: 表示 URL 方案的整数值。lpszHostName: 指向字符串的指针,包含主机名部分。nPort: 表示端口号。lpszUserName和lpszPassword: 分别是用户名和密码的部分。lpszUrlPath: URL 路径部分。lpszExtraInfo: 额外信息。
InternetCrackUrl 的返回值为 BOOL 类型,如果函数成功,返回非零值,否则返回零。函数成功后,lpUrlComponents 结构体中的字段将被填充。
这个函数通常用于在网络编程中处理 URL,例如在创建网络请求时提取主机名、端口和路径。
#define _CRT_SECURE_NO_WARNINGS
#define _WINSOCK_DEPRECATED_NO_WARNINGS
#include <WinSock2.h>
#include <Windows.h>
#include <string>
#include <WinInet.h>
#pragma comment(lib, "WinInet.lib")
#pragma comment(lib,"ws2_32")
using namespace std;
// 通过InternetCrackUrl函数实现切割
BOOL HttpUrlSplitA(const char* URL, LPSTR pszHostName, LPSTR pszUrlPath)
{
BOOL bRet = FALSE;
URL_COMPONENTS url_info = { 0 };
RtlZeroMemory(&url_info, sizeof(url_info));
url_info.dwStructSize = sizeof(url_info);
url_info.dwHostNameLength = MAX_PATH - 1;
url_info.lpszHostName = pszHostName;
url_info.dwUrlPathLength = MAX_PATH - 1;
url_info.lpszUrlPath = pszUrlPath;
bRet = InternetCrackUrl(URL, 0, 0, &url_info);
if (FALSE == bRet)
{
return FALSE;
}
return TRUE;
}
int main(int argc, char* argv[])
{
char szHostName[1024] = { 0 };
char szUrlPath[1024] = { 0 };
BOOL flag = HttpUrlSplitA("http://www.xxx.com/index.html", szHostName, szUrlPath);
if (flag == TRUE)
{
printf("输出主路径:%s \n", szHostName);
printf("输出子路径:%s \n", szUrlPath);
}
system("pause");
return 0;
}
运行后则会对http://www.xxx.com/index.html字符串进行路径切割,并输出主目录与子路径,如下图所示;

相对于使用原生API切割,自己实现也并不难,如下所示,通过_strnicmp判断字符串长度并切割特定的位置,实现对字符串的切割;
#define _CRT_SECURE_NO_WARNINGS
#define _WINSOCK_DEPRECATED_NO_WARNINGS
#include <WinSock2.h>
#include <Windows.h>
#include <string>
#include <WinInet.h>
#pragma comment(lib, "WinInet.lib")
#pragma comment(lib,"ws2_32")
using namespace std;
// 自己实现对URL路径的拆分
bool HttpUrlSplitB(const char* pszUrl)
{
char szHost[256] = { 0 };
char* ptr = (char*)pszUrl;
// 判断开头是否为http:// 或者 https:// 如果不是则返回-1
if (_strnicmp(ptr, "http://", 7) == 0)
{
ptr = ptr + 7;
}
else if (_strnicmp(ptr, "https://", 8) == 0)
{
ptr = ptr + 8;
}
else
{
return false;
}
int index = 0;
while (index < 255 && *ptr && *ptr != '/')
{
szHost[index++] = *ptr++;
}
szHost[index] = '\0';
printf("主域名: %s \n 路径: %s \n", szHost, ptr);
return true;
}
int main(int argc, char* argv[])
{
BOOL flag = HttpUrlSplitB("http://www.xxx.com/index.html");
system("pause");
return 0;
}
实现HTTP访问
HTTP 通常基于TCP(Transmission Control Protocol)。HTTP的本质是建立在底层的Socket通信之上的一种应用层协议。
概述HTTP访问的过程:
- 建立TCP连接: HTTP通信首先需要建立TCP连接,通常默认使用TCP的80端口。在建立连接之前,客户端和服务器需要通过DNS解析获取对应的IP地址。
- 发送HTTP请求: 客户端通过Socket向服务器发送HTTP请求,请求包括请求方法(GET、POST等)、URL路径、HTTP协议版本等信息。同时,客户端可以附带一些请求头(Headers)和请求体(Body),具体内容根据请求的性质而定。
- 服务器处理请求: 服务器接收到客户端的HTTP请求后,根据请求的内容进行处理。处理的方式取决于请求的方法,例如GET请求用于获取资源,POST请求用于提交数据等。服务器根据请求返回相应的HTTP响应。
- 发送HTTP响应: 服务器通过Socket向客户端发送HTTP响应,响应包括响应状态码、响应头和响应体。响应状态码表示服务器对请求的处理结果,例如200表示成功,404表示未找到资源,500表示服务器内部错误等。
- 关闭TCP连接: 一旦HTTP响应发送完毕,服务器关闭与客户端的TCP连接。客户端接收完响应后也可以关闭连接,或者继续发送其他请求。
整个HTTP访问的本质就是通过TCP连接在客户端和服务器之间传递HTTP请求和响应。Socket是负责实际数据传输的底层机制,而HTTP协议则定义了在这个基础上进行通信的规范。这种分层的设计使得不同的应用能够使用同一个底层的网络传输机制,提高了网络通信的灵活性和可扩展性。
通常实现HTTP访问与主机访问相同,唯一的区别是主机应用的访问遵循的是服务端的封包规则,而对于Web来说则需要遵循HTTP特有的访问规则,在Socket正式接收数据之前需要实现一个请求规范,也就是HTTP头部。
HTTP头部(HTTP headers)是HTTP请求和响应中的重要组成部分,它们包含了与请求或响应相关的信息。HTTP头部的格式通常是一个名值对(key-value pair)的集合,每个头部字段由一个字段名和一个字段值组成,它们以冒号分隔,例如:
HeaderName: HeaderValue
HTTP头部通常以回车符(Carriage Return,\r)和换行符(Line Feed,\n)的组合(\r\n)结束,每个头部字段之间以\r\n分隔。
以下是一些常见的HTTP头部字段及其示例:
- 通用头部(General Headers):
Cache-Control: no-cacheDate: Tue, 15 Nov 2022 08:12:31 GMTConnection: keep-alive
- 请求头部(Request Headers):
Host: www.example.comUser-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
- 响应头部(Response Headers):
Content-Type: text/html; charset=utf-8Content-Length: 12345Server: Apache/2.4.41 (Unix)
- 实体头部(Entity Headers):
Content-Encoding: gzipLast-Modified: Wed, 20 Oct 2022 12:00:00 GMTEtag: "5f0a3e51-20"
HTTP头部的具体字段和含义可根据HTTP规范进行扩展,不同的应用场景和需求可能需要添加自定义的头部字段。这些头部字段在HTTP通信中起到了传递元信息、控制缓存、指定内容类型等作用。在代码中我们构建了一个如下所示的头部。
int ret = sprintf(context,
"GET %s HTTP/1.1 \r\n"
"Host: %s \r\n"
"User-Agent: Mozilla/5.0 (Windows NT 10.0) LyShark HttpGet 1.0 \r\n"
"Accept-Type: */* \r\n"
"Connection: Close \r\n\r\n",
szSubPath, szURL);
在这个HTTP GET请求的基本格式,它包含了一些必要的头部信息。让我们逐行解释:
"GET %s HTTP/1.1 \r\n": 这表示使用HTTP协议的GET请求方式,%s会被替换为实际的URL路径,HTTP版本为1.1。"Host: %s \r\n": 这里设置了HTTP请求的Host头部,指定了服务器的主机名,%s会被替换为实际的主机名。"User-Agent: Mozilla/5.0 (Windows NT 10.0) LyShark HttpGet 1.0 \r\n": 这是User-Agent头部,它标识了发送请求的用户代理(即浏览器或其他客户端)。这里的字符串表示使用Mozilla浏览器5.0版本,运行在Windows NT 10.0操作系统上,LyShark HttpGet 1.0表示这个请求的自定义用户代理。"Accept-Type: */* \r\n": 这是Accept-Type头部,表示客户端可以接受任意类型的响应内容。"Connection: Close \r\n\r\n":Connection头部表示在完成请求后关闭连接,避免保持连接。\r\n\r\n表示头部结束,之后是可选的请求体。
综合起来,这个HTTP GET请求的目的是获取指定URL路径的资源,请求头部包含了一些必要的信息,例如主机名、用户代理等。这是一个基本的HTTP请求格式,可以根据具体需求添加或修改头部信息。
#define _CRT_SECURE_NO_WARNINGS
#define _WINSOCK_DEPRECATED_NO_WARNINGS
#include <WinSock2.h>
#include <Windows.h>
#include <string>
#include <WinInet.h>
#pragma comment(lib, "WinInet.lib")
#pragma comment(lib,"ws2_32")
using namespace std;
// 通过InternetCrackUrl函数实现切割
BOOL HttpUrlSplitA(const char* URL, LPSTR pszHostName, LPSTR pszUrlPath)
{
BOOL bRet = FALSE;
URL_COMPONENTS url_info = { 0 };
RtlZeroMemory(&url_info, sizeof(url_info));
url_info.dwStructSize = sizeof(url_info);
url_info.dwHostNameLength = MAX_PATH - 1;
url_info.lpszHostName = pszHostName;
url_info.dwUrlPathLength = MAX_PATH - 1;
url_info.lpszUrlPath = pszUrlPath;
bRet = InternetCrackUrl(URL, 0, 0, &url_info);
if (FALSE == bRet)
{
return FALSE;
}
return TRUE;
}
// Get方式访问页面
char* Curl(const char* szURL, const char* szSubPath, const int port)
{
WSADATA wsaData;
WSAStartup(0x0202, &wsaData);
char* context = new char[1024 * 8];
int ret = sprintf(context,
"GET %s HTTP/1.1 \r\n"
"Host: %s \r\n"
"User-Agent: Mozilla/5.0 (Windows NT 10.0) LyShark HttpGet 1.0 \r\n"
"Accept-Type: */* \r\n"
"Connection: Close \r\n\r\n",
szSubPath, szURL);
SOCKADDR_IN addr;
SOCKET sock = socket(AF_INET, SOCK_STREAM, 0);
addr.sin_addr.S_un.S_addr = 0;
addr.sin_port = htons(0);
addr.sin_family = AF_INET;
ret = bind(sock, (const sockaddr*)&addr, sizeof(SOCKADDR_IN));
hostent* local_addr = gethostbyname(szURL);
if (local_addr)
{
ULONG ip = *(ULONG*)local_addr->h_addr_list[0];
addr.sin_addr.S_un.S_addr = ip;
addr.sin_port = htons(port);
ret = connect(sock, (const sockaddr*)&addr, sizeof(SOCKADDR_IN));
if (ret == NOERROR)
{
ret = send(sock, (const char*)context, (int)strlen(context), 0);
do
{
ret = recv(sock, context, 8191, 0);
if (ret <= 0)
{
break;
}
context[ret] = '\0';
printf("\n%s\n\n", context);
} while (TRUE);
}
}
closesocket(sock);
WSACleanup();
return context;
}
// 访问指定页面
char* HttpGet(const char* szURL, const int port)
{
char master_url[1024] = { 0 };
char slave_url[1024] = { 0 };
char* curl_context = nullptr;
// 将完整路径切割为主路径与次路径
BOOL ref = HttpUrlSplitA(szURL, master_url, slave_url);
if (TRUE == ref)
{
// 获取所有网页内容
curl_context = Curl(master_url, slave_url, port);
return curl_context;
}
return 0;
}
int main(int argc, char* argv[])
{
char *szBuffer = HttpGet("http://www.lyshark.com/index.html", 80);
// printf("%s \n", szBuffer);
system("pause");
return 0;
}
运行上述代码则会自动请求http://www.lyshark.com/index.html路径的80端口,以获取返回参数信息,如下图所示;
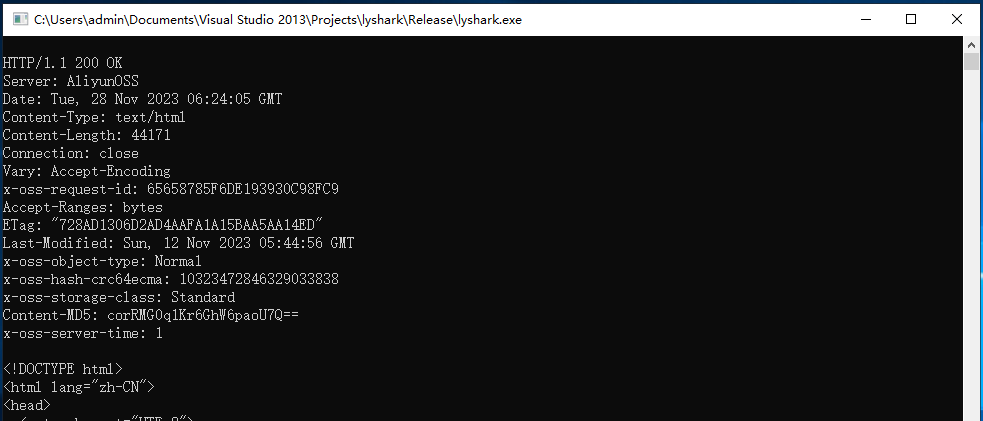
实现HTTPS访问
HTTPS的访问与HTTP基本类似,同样是通过Socket访问端口,同样是发送特定的GET请求头,唯一的不同在于当链接被建立后,对于HTTPS来说多出一个TLS协商的过程,这是为了保护传输时的安全而增加的安全特定,为了能实现访问我们需要使用OpenSSL库对完成TLS的握手才行。
OpenSSL 是一个强大的开源软件库,提供了一系列的密码学工具和库函数,广泛用于网络安全应用的开发。它支持许多密码学协议和算法,包括 SSL(Secure Sockets Layer)和 TLS(Transport Layer Security)协议,用于在计算机网络上实现安全通信。
HTTPS握手过程是建立在TLS(Transport Layer Security)协议之上的。TLS是SSL(Secure Sockets Layer)的继任者,用于在计算机网络上保障通信安全。以下是HTTPS握手的基本流程:
- 客户端Hello:
- 客户端向服务器发送
ClientHello消息,其中包含支持的TLS版本、支持的加密算法、支持的压缩算法等信息。
- 客户端向服务器发送
- 服务器Hello:
- 服务器从客户端提供的信息中选择一个合适的TLS版本和加密套件,并向客户端发送
ServerHello消息,同时发送服务器证书。
- 服务器从客户端提供的信息中选择一个合适的TLS版本和加密套件,并向客户端发送
- 认证:
- 客户端验证服务器发送的证书是否有效,通常包括证书的颁发机构(CA)的签名验证。客户端还可以验证证书中包含的域名是否匹配正在连接的域名。
- 密钥交换:
- 客户端生成一个随机值,使用服务器的公钥加密该随机值,然后将加密后的数据发送给服务器。服务器使用自己的私钥解密,得到客户端生成的随机值。这两个随机值将用于生成对话密钥。
- 对话密钥的生成:
- 客户端和服务器使用客户端生成的随机值、服务器生成的随机值以及前面协商的算法,通过一系列协商步骤生成对话密钥。
- 加密通信:
- 客户端和服务器使用生成的对话密钥对通信进行加密和解密,确保数据的隐私和完整性。
整个握手过程确保了通信双方的身份验证、密钥的安全协商以及通信内容的保密性和完整性。握手完成后,客户端和服务器使用协商得到的对话密钥进行加密通信,从而实现了安全的HTTPS连接。
如下所示代码以演示访问必应为例,需要获取必应的IP地址,以及在GET请求中更改访问域名为BING;
#define _CRT_SECURE_NO_WARNINGS
#define _WINSOCK_DEPRECATED_NO_WARNINGS
#include <iostream>
#include <WinSock2.h>
#include <openssl/ssl.h>
#pragma comment(lib,"ws2_32.lib")
#pragma comment(lib,"libssl.lib")
#pragma comment(lib,"libcrypto.lib")
using namespace std;
const wchar_t* GetWC(const char* c)
{
const size_t cSize = strlen(c) + 1;
wchar_t* wc = new wchar_t[cSize];
mbstowcs(wc, c, cSize);
return wc;
}
int main(int argc, char* argv[])
{
WSADATA WSAData;
SOCKET sock;
struct sockaddr_in ClientAddr;
if (WSAStartup(MAKEWORD(2, 0), &WSAData) != SOCKET_ERROR)
{
ClientAddr.sin_family = AF_INET;
ClientAddr.sin_port = htons(443);
ClientAddr.sin_addr.s_addr = inet_addr("202.89.233.101");
sock = socket(AF_INET, SOCK_STREAM, 0);
int Ret = connect(sock, (LPSOCKADDR)&ClientAddr, sizeof(ClientAddr));
if (Ret == 0)
{
}
}
// 初始化OpenSSL库 创建SSL会话环境等
SSL_CTX* pctxSSL = SSL_CTX_new(TLSv1_2_client_method());
if (pctxSSL == NULL)
{
return -1;
}
SSL* psslSSL = SSL_new(pctxSSL);
if (psslSSL == NULL)
{
return -1;
}
SSL_set_fd(psslSSL, sock);
INT iErrorConnect = SSL_connect(psslSSL);
if (iErrorConnect < 0)
{
return -1;
}
std::wcout << "SLL ID: " << SSL_get_cipher(psslSSL) << std::endl;
// 发包
std::string strWrite =
"GET https://cn.bing.com/ HTTP/1.1\r\n"
"Host: cn.bing.com\r\n"
"User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0 \r\n"
"Accept-Type: */* \r\n"
"Connection: close\r\n\r\n";
INT iErrorWrite = SSL_write(psslSSL, strWrite.c_str(), strWrite.length()) < 0;
if (iErrorWrite < 0)
{
return -1;
}
// 收包并输出
LPSTR lpszRead = new CHAR[8192];
INT iLength = 1;
while (iLength >= 1)
{
iLength = SSL_read(psslSSL, lpszRead, 8192 - 1);
if (iLength < 0)
{
std::wcout << "Error SSL_read" << std::endl;
delete[] lpszRead;
return -1;
}
lpszRead[iLength] = TEXT('\0');
std::wcout << GetWC(lpszRead);
}
delete[] lpszRead;
closesocket(sock);
WSACleanup();
system("pause");
return 0;
}
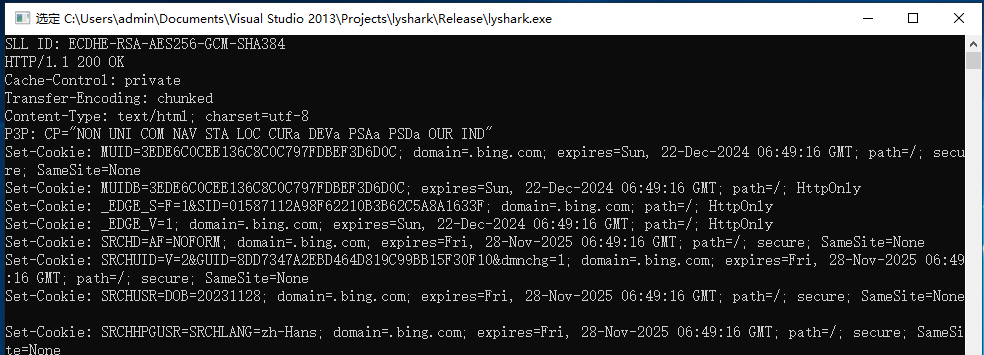
成勋运行后将会对必应发起https访问,并获取返回值信息,如下图所示;