Dilated Neighborhood Attention Transformer摘要
局部注意力机制:例如滑动窗口Neighborhood Attention(NA)或Swin Transformer的Shifted Window Self Attention。
优点:尽管在降低自注意力二次复杂性方面表现出色,
缺点:但是局部注意力削弱了自注意力的两个最理想的属性:长程相互依赖建模和全局感受野。在本文中,我们引入了Dilated Neighborhood Attention(DiNA),这是对NA的一种自然、灵活且高效的扩展,可以在不增加额外成本的情况下捕获更多的全局上下文并指数级地扩展感受野。NA的局部注意力和DiNA的稀疏全局注意力相互补充,因此我们引入了Dilated Neighborhood Attention Transformer(DiNAT),这是一种结合了两者新的hierarchical vision transformer。
长程相互依赖建模:指的是模型捕捉序列或空间排列中相距较远的元素之间关系或依赖的能力。在神经网络的背景下,实现长程相互依赖建模通常涉及允许信息在远距离元素之间交换的机制,使得模型能够考虑全局上下文和依赖关系。
"全局感受野" 涉及影响神经网络层中特定单元的输入数据的空间范围。较大的全局感受野意味着层中的每个单元都会考虑来自更广泛区域的信息。这对于捕捉远距离元素之间的关系并理解输入数据的整体结构至关重要。
总的来说,长程相互依赖建模和较大的全局感受野都是神经网络中期望具备的特性。这些特性使得模型能够有效捕捉长距离的依赖关系并考虑广泛的上下文,对于涉及理解整个输入数据的关系和结构的任务尤为重要。
1. Introduction
ViT将图像视为patch的序列,并使用普通的transformer编码器对图像进行编码和分类。
卷积神经网络通常在通过模型时逐渐对输入进行降采样,并构建分层特征图。这种分层设计对于视觉任务至关重要,因为对象在尺度上有所变化,然而高分辨率的特征图对于密集任务(如分割)非常重要。为了缓解自注意力的二次成本,标准的ViT从一开始就对输入进行强烈的降采样,这种保持固定维度的大幅度的降采样反过来阻碍了将标准的ViT应用为密集视觉任务的主干。
分层的vision transformer可以与分层的视觉框架进行轻松的集成。
受现有卷积神经网络的启发,hierarchical vision transformers由多个(通常为4个)级别的变换器编码器组成(例如:swin transformer),在其间有降采样模块,且初始降采样较少侵入性(即1/4而不是1/16)。如果在hierarchical vision transformers的较早层中使用无限制(全局的)的自注意力,则与输入分辨率相关,其复杂性和内存使用也会呈二次增长,使其在处理更高分辨率图像时变得难以处理。因此,hierarchical vision transformers通常采用特定的局部注意力机制。
Swin Transformer;SWSA会进行一个特征图像素的平移,之后是一个相反的平移。这对其性能至关重要,因为它允许窗口外的交互,从而扩大了其感受野。
后来引入了Neighborhood Attention Transformer (NAT) [15],采用了基于滑动窗口的简单注意力机制,即邻域注意力(NA)。与 Stand Alone Self Attention (SASA) [35] 不同,后者以卷积的方式应用注意力,NA将自注意力局限在每个token周围的最近邻域,这使得它在定义上可以接近自注意力并具有固定的注意力范围。像素级别的自注意力操作被认为效率低且难以并行化 [29, 35, 41],直到 Neighborhood Attention Extension [15] 的发布,。通过这个扩展,NA在实践中甚至可以比Swin的SWSA更快运行。
NAT相较于swin transformer 的好处。基于局部自注意的hierarchical vision transformers 进行了不断的改进和发展,但是由于局部自注意破坏了全局感受野和建模长程依赖性的能力,最理想的情况是保持线性复杂性,同时保持自注意力的全局感受野和建模长程相互依赖的能力。在本文中,我们旨在回答这个问题,并通过将一种简单的局部注意力机制Neighborhood Attention,扩展为Dilated Neighborhood Attention(DiNA)来改进hierarchical vision transformers:稀疏全局注意力,将NA中的邻域扩张为更大的稀疏区域:
- 捕捉更多的全局上下文
- 使感受野乘指数级增长
- 不带来额外的计算成本
NA的局部注意力和DiNA的稀疏全局注意力相互补充:它们可以保留局部性,建模更长程的相互依赖关系,指数级地扩展感受野,并保持线性复杂性。NA的局部注意力和DiNA的稀疏全局注意力对自注意力的限制可以潜在地避免自注意力可能的冗余交互,比如与重复、背景或分散注意力的token的交互 [26, 36],从而提高收敛性。
2.相关工作
SASA:将query-key设置为在特征图上滑动的窗口,因此将每个query(像素)的注意力局限在以其为中心的窗口中,但是由于模块的低效实现,生成的模型运行速度较慢。
SWSA:平移窗口局部自注意力,允许窗口外的交互对于不断扩大的感受野,但是swsa在非重叠的局部窗口内进行attention,类似于locality和平移不变性等归纳偏执不能被引入
Swin Transformer和DiNAT中的注意力层的示意图。Swin将输入分成非重叠的窗口,并分别对每个窗口应用自注意力,在每个其他层上进行像素移位。像素移位的层掩盖了不按顺序的区域之间的注意力权重,这将自注意力限制在移位的子窗口内。DiNAT应用Neighborhood Attention,一种滑动窗口注意力,并在每个其他层上进行扩张。
Neighborhood Attention (NA): NA [15] 被提出作为一种简单的滑动窗口注意力,将每个像素的自注意力局限在其最近的邻居,相比与swin transformer,NA在重叠的窗口进行操作,保留了locality和平移不变性。随着窗口的大小的增加,NA逐渐接近自注意力。
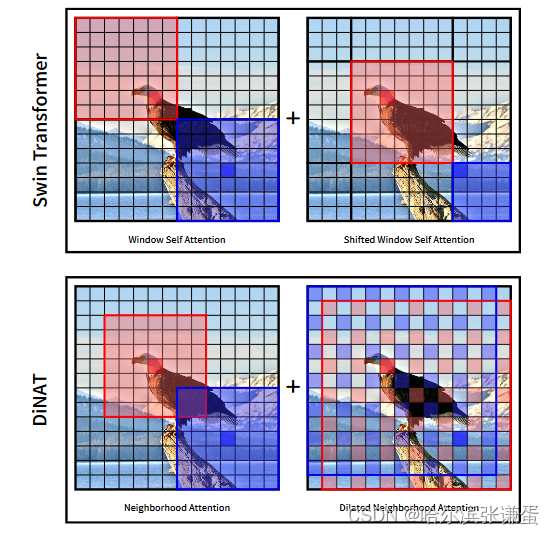
Swin Transformer和DiNAT中的注意力层的示意图。Swin将输入分成非重叠的窗口,并分别对每个窗口应用自注意力,在每个其他层上进行像素移位。像素移位的层掩盖了不按顺序的区域之间的注意力权重,这将自注意力限制在移位的子窗口内。DiNAT应用Neighborhood Attention,一种滑动窗口注意力,并在每个其他层上进行扩张。
尽管基于局部注意力的模型由于其保留局部性和高效性而能够在不同的视觉任务中表现良好,但是破坏了长程相互依赖建模和全局感受野。但它们在捕捉像自注意力这样对于视觉至关重要的全局上下文方面表现不足。此外,与自注意力中的全尺寸感受野相比,局部化注意力机制利用更小且增长较慢的感受野
非局部(全局)和稀疏自注意力的idea表现出了很大的潜力,但在hierarchical vision transformer的范围内,它们尚未得到充分研究。为了扩展局部感受野并将全局上下文重新引入hierarchical vision transformer,我们引入了Dilated Neighborhood Attention(DiNA),这是NA的扩展,通过增加步长跨越更长的范围,同时保持总体注意力跨度。DiNA可以作为一种稀疏和全局的操作,在与NA作为仅局部操作一起使用时效果最佳
将全连接层与卷积和扩张卷积进行比较,类似地将自注意力与NA和DiNA进行比较。
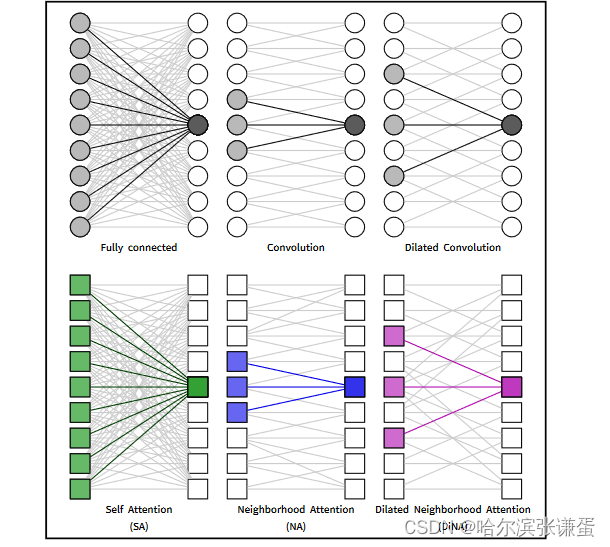
在全连接层、卷积层和不同的注意机制中,对感受野的单维度示意图。NA和DiNA通过滑动窗口限制自注意力,类似于卷积和扩张卷积如何限制全连接层。这些限制减少了计算负担,引入了有用的归纳偏差,并在某些情况下增加了对不同输入尺寸的灵活性。
3. Method
3.1. Dilated Neighborhood Attention
第i个token邻域大小k的DiNA输出定义为:
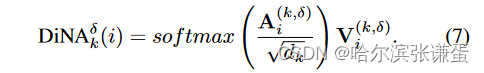
3.2. Choice of Dilation
DiNA引入了一个重要的新的架构超参数:每层扩张因子。我们定义了扩张因子的上限为n/k向下取整,其中n是token的数量,k是内核/邻域大小。这仅仅是为了确保每个token都有恰好k个扩张邻居。下限始终为1,这相当于普通的NA。因此,模型每层的扩张因子将是一个依赖于输入的超参数,可以取任何整数δ ∈ [1, n/k向下取整]。
3.3. Receptive Fields
尽管Swin的感受野比NAT和ConvNeXt略大,这要归功于其特殊的偏移窗口设计,但它破坏了一个重要的属性:对称性。由于Swin的特征图被分成不重叠的窗口,同一窗口内的像素只与彼此关注,而不考虑它们的位置(无论是在中心还是在角落),导致一些像素看到它们周围的上下文不对称。与NAT、Swin和ConvNeXt中固定的感受野增长不同,DiNA的感受野是灵活的,并且随着扩张而变化。它的范围可以从NAT的原始L(k−1)+1(所有扩张因子均设置为1)到呈指数增长的kL(逐渐增加扩张),这是其强大性的主要原因之一。无论扩张如何,第一层始终产生大小为k的感受野(DiNA)。给定足够大的扩张因子,前面的DiNA层将为DiNA层中的每个k产生一个大小为k的感受野(NA),从而产生大小为k2的感受野。因此,具有最佳扩张因子的DiNA和NA组合有可能将感受野的增长呈指数级提高到kL。这并不令人惊讶,因为已知当使用指数增长的扩张因子时,扩张卷积的感受野大小也会呈指数增长[50]。图5中还展示了增加的感受野大小的示意图。
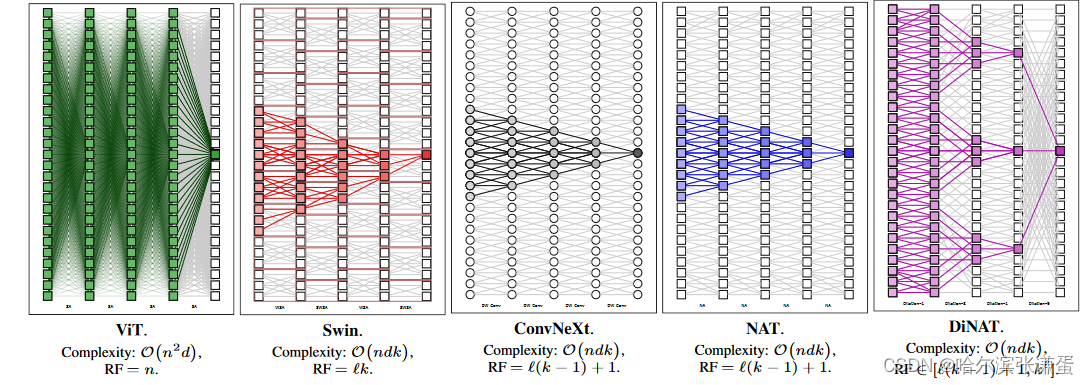
ViT、Swin、ConvNeXt、NAT和我们的DiNAT中的感受野。我们还提供了每种方法主要操作的复杂性。n表示token的数量,d表示嵌入维度,k表示内核/窗口大小。所有感受野都受到输入大小n的限制。DiNAT的感受野是灵活的,范围从线性的L(k−1)+1,到指数增长的Lk。
3.4. DiNAT

为了公平评估DiNA的性能,我们设计DiNAT的体系结构和配置与原始的NAT模型完全相同。它最初使用两个2×2步幅的3×3卷积层,导致特征图的分辨率为输入分辨率的四分之一。它还在级别之间使用一个2×2步幅的单个3×3卷积进行下采样,将空间分辨率减半并将通道加倍。详细信息见表2。DiNAT的关键区别在于每隔一个层次使用DiNA而不是NA。DiNA层的扩张因子根据任务和输入分辨率进行设置。对于2242分辨率的ImageNet-1k,我们分别将扩张因子从stage1到stage4分别设置为8、4、2和1。在下游任务中,由于它们具有更大的分辨率,我们将扩张因子增加到更大的值。所有扩张因子和其他相关的体系结构细节见表II。
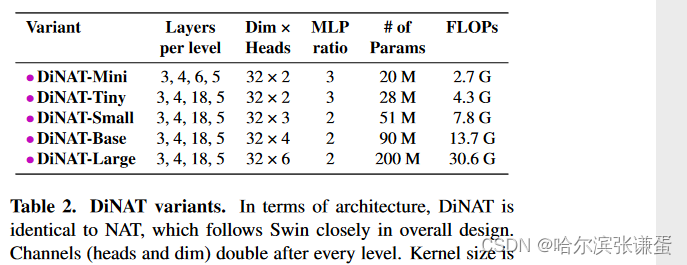
表2. DiNAT变体。在体系结构方面,DiNAT与NAT相同,其整体设计紧随Swin。通道(头部和维度)在每个级别之后加倍。在所有变体中,内核大小为7。
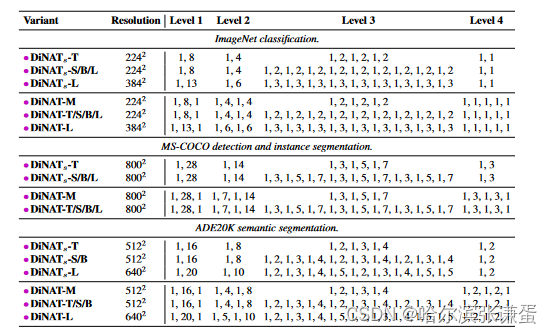
表II. 扩张因子。由于ImageNet的输入分辨率相对较小,stage 4的层不能超过扩张因子1,这相当于NA。还请注意,在224×224分辨率下,stage 4的输入将恰好为7×7,因此NA将等同于自注意力。这在分辨率明显更高的下游任务中并非如此,其中stage 2和stage 3具有逐渐增加的扩张因子,这在更深的模型中重复。这对应于表9中标有“Gradual”的突出显示行。这些配置适用于所有下游实验(不包括第4.4节中的实验)。
后边关于下游任务以及消融实验的不在阐述。








![[含泪解决]OSError: [Errno 99] Cannot assign requested address__踩坑记录——app.py绑定IP失败](https://img-blog.csdnimg.cn/direct/7b417093edc14884857c1d31b4e66d80.png)