认证授权
认证 (Authentication) 和授权 (Authorization)的区别是什么?
说简单点就是:
- 认证 (Authentication): 你是谁。
- 授权 (Authorization): 你有权限干什么。
稍微正式点(啰嗦点)的说法就是:
-
Authentication(认证) 是验证您的身份的凭据(例如用户名/用户 ID 和密码),通过这个凭据,系统得以知道你就是你,也就是说系统存在你这个用户。所以,Authentication 被称为身份/用户验证。
-
Authorization(授权) 发生在 Authentication(认证) 之后。授权嘛,光看意思大家应该就明白,它主要掌管我们访问系统的权限。比如有些特定资源只能具有特定权限的人才能访问比如 admin,有些对系统资源操作比如删除、添加、更新只能特定人才具有
这两个一般在我们的系统中被结合在一起使用,目的就是为了保护我们系统的安全性。
RBAC 模型了解吗?
系统权限控制最常采用的访问控制模型就是 RBAC 模型 。
什么是 RBAC 呢?
RBAC 即基于角色的权限访问控制(Role-Based Access Control)。这是一种通过角色关联权限,角色同时又关联用户的授权的方式。
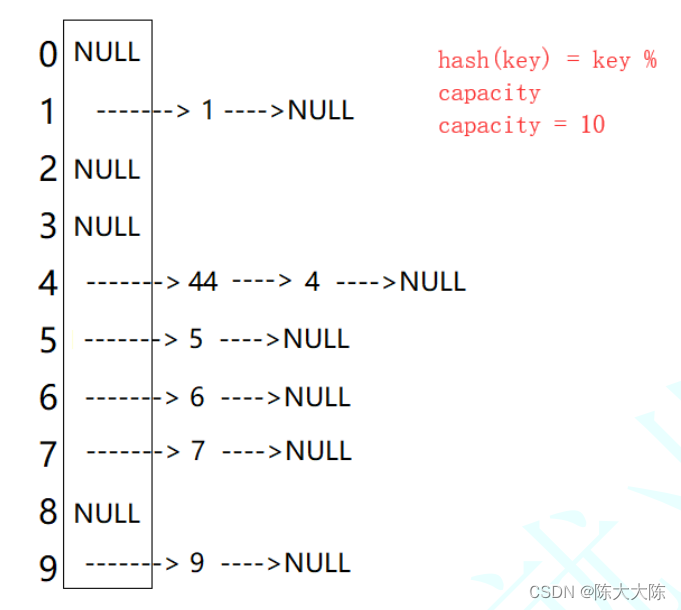
简单地说:一个用户可以拥有若干角色,每一个角色又可以被分配若干权限,这样就构造成“用户-角色-权限” 的授权模型。在这种模型中,用户与角色、角色与权限之间构成了多对多的关系,如下图

在 RBAC 中,权限与角色相关联,用户通过成为适当角色的成员而得到这些角色的权限。这就极大地简化了权限的管理。
通常来说,如果系统对于权限控制要求比较严格的话,一般都会选择使用 RBAC 模型来做权限控制。
什么是 Cookie ? Cookie 的作用是什么?
Cookie 和 Session 都是用来跟踪浏览器用户身份的会话方式,但是两者的应用场景不太一样。
维基百科是这样定义 Cookie 的:
Cookies是某些网站为了辨别用户身份而储存在用户本地终端上的数据(通常经过加密)。
简单来说:Cookie 存放在客户端,一般用来保存用户信息。
如何在项目中使用 Cookie 呢?
我这里以 Spring Boot 项目为例。
1)设置 Cookie 返回给客户端
@GetMapping("/change-username")
public String setCookie(HttpServletResponse response) {
// 创建一个 cookie
Cookie cookie = new Cookie("username", "Jovan");
//设置 cookie过期时间
cookie.setMaxAge(7 * 24 * 60 * 60); // expires in 7 days
//添加到 response 中
response.addCookie(cookie);
return "Username is changed!";
}
2) 使用 Spring 框架提供的 @CookieValue 注解获取特定的 cookie 的值
@GetMapping("/")
public String readCookie(@CookieValue(value = "username", defaultValue = "Atta") String username) {
return "Hey! My username is " + username;
}
3) 读取所有的 Cookie 值
@GetMapping("/all-cookies")
public String readAllCookies(HttpServletRequest request) {
Cookie[] cookies = request.getCookies();
if (cookies != null) {
return Arrays.stream(cookies)
.map(c -> c.getName() + "=" + c.getValue()).collect(Collectors.joining(", "));
}
return "No cookies";
}
Cookie 和 Session 有什么区别?
Session 的主要作用就是通过服务端记录用户的状态。 典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 Session 之后就可以标识这个用户并且跟踪这个用户了。
Cookie 数据保存在客户端(浏览器端),Session 数据保存在服务器端。相对来说 Session 安全性更高。如果使用 Cookie 的一些敏感信息不要写入 Cookie 中,最好能将 Cookie 信息加密然后使用到的时候再去服务器端解密。
如何使用 Session-Cookie 方案进行身份验证?
很多时候我们都是通过 SessionID 来实现特定的用户,SessionID 一般会选择存放在 Redis 中。举个例子:
- 用户成功登陆系统,然后返回给客户端具有
SessionID的Cookie。 - 当用户向后端发起请求的时候会把
SessionID带上,这样后端就知道你的身份状态了。
关于这种认证方式更详细的过程如下:

- 用户向服务器发送用户名、密码、验证码用于登陆系统。
- 服务器验证通过后,服务器为用户创建一个
Session,并将Session信息存储起来。 - 服务器向用户返回一个
SessionID,写入用户的Cookie。 - 当用户保持登录状态时,
Cookie将与每个后续请求一起被发送出去。 - 服务器可以将存储在
Cookie上的SessionID与存储在内存中或者数据库中的Session信息进行比较,以验证用户的身份,返回给用户客户端响应信息的时候会附带用户当前的状态。
使用 Session 的时候需要注意下面几个点:
- 依赖
Session的关键业务一定要确保客户端开启了Cookie。 - 注意
Session的过期时间。
多服务器节点下 Session-Cookie 方案如何做?
Session-Cookie 方案在单体环境是一个非常好的身份认证方案。但是,当服务器水平拓展成多节点时,Session-Cookie 方案就要面临挑战了。
举个例子:假如我们部署了两份相同的服务 A,B,用户第一次登陆的时候 ,Nginx 通过负载均衡机制将用户请求转发到 A 服务器,此时用户的 Session 信息保存在 A 服务器。结果,用户第二次访问的时候 Nginx 将请求路由到 B 服务器,由于 B 服务器没有保存 用户的 Session 信息,导致用户需要重新进行登陆。
我们应该如何避免上面这种情况的出现呢?
有几个方案可供大家参考:
- 某个用户的所有请求都通过特性的哈希策略分配给同一个服务器处理。这样的话,每个服务器都保存了一部分用户的 Session 信息。服务器宕机,其保存的所有 Session 信息就完全丢失了。
- 每一个服务器保存的 Session 信息都是互相同步的,也就是说每一个服务器都保存了全量的 Session 信息。每当一个服务器的 Session 信息发生变化,我们就将其同步到其他服务器。这种方案成本太大,并且,节点越多时,同步成本也越高。
- 单独使用一个所有服务器都能访问到的数据节点(比如缓存)来存放 Session 信息。为了保证高可用,数据节点尽量要避免是单点。
- Spring Session 是一个用于在多个服务器之间管理会话的项目。它可以与多种后端存储(如 Redis、MongoDB 等)集成,从而实现分布式会话管理。通过 Spring Session,可以将会话数据存储在共享的外部存储中,以实现跨服务器的会话同步和共享。
如果没有 Cookie 的话 Session 还能用吗?
一般是通过 Cookie 来保存 SessionID ,假如你使用了 Cookie 保存 SessionID 的方案的话, 如果客户端禁用了 Cookie,那么 Session 就无法正常工作。
但是,并不是没有 Cookie 之后就不能用 Session 了,比如你可以将 SessionID 放在请求的 url 里面https://javaguide.cn/?Session_id=xxx 。这种方案的话可行,但是安全性和用户体验感降低。当然,为了安全你也可以对 SessionID 进行一次加密之后再传入后端。
为什么 Cookie 无法防止 CSRF 攻击,而 Token 可以?
CSRF(Cross Site Request Forgery) 一般被翻译为 跨站请求伪造 。那么什么是 跨站请求伪造 呢?说简单用你的身份去发送一些对你不友好的请求。
举个简单的例子:
小壮登录了某网上银行,他来到了网上银行的帖子区,看到一个帖子下面有一个链接写着“科学理财,年盈利率过万”,小壮好奇的点开了这个链接,结果发现自己的账户少了 10000 元。这是这么回事呢?原来黑客在链接中藏了一个请求,这个请求直接利用小壮的身份给银行发送了一个转账请求,也就是通过你的 Cookie 向银行发出请求。
<a src=http://www.mybank.com/Transfer?bankId=11&money=10000>科学理财,年盈利率过万</>
上面也提到过,进行 Session 认证的时候,我们一般使用 Cookie 来存储 SessionId,当我们登陆后后端生成一个 SessionId 放在 Cookie 中返回给客户端,服务端通过 Redis 或者其他存储工具记录保存着这个 SessionId,客户端登录以后每次请求都会带上这个 SessionId,服务端通过这个 SessionId 来标示你这个人。如果别人通过 Cookie 拿到了 SessionId 后就可以代替你的身份访问系统了。
Session 认证中 Cookie 中的 SessionId 是由浏览器发送到服务端的,借助这个特性,攻击者就可以通过让用户误点攻击链接,达到攻击效果。
但是,我们使用 Token 的话就不会存在这个问题,在我们登录成功获得 Token 之后,一般会选择存放在 localStorage (浏览器本地存储)中。然后我们在前端通过某些方式会给每个发到后端的请求加上这个 Token,这样就不会出现 CSRF 漏洞的问题。因为,即使有个你点击了非法链接发送了请求到服务端,这个非法请求是不会携带 Token 的,所以这个请求将是非法的。
需要注意的是:不论是 Cookie 还是 Token 都无法避免 跨站脚本攻击(Cross Site Scripting)XSS 。XSS 中攻击者会用各种方式将恶意代码注入到其他用户的页面中。就可以通过脚本盗用信息比如 Cookie 。
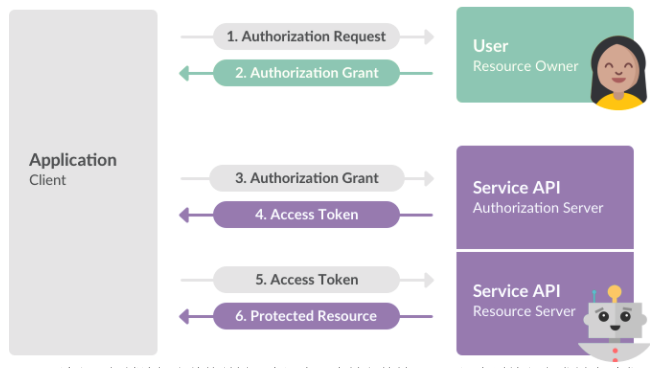
什么是 OAuth 2.0?
OAuth 是一个行业的标准授权协议,主要用来授权第三方应用获取有限的权限。而 OAuth 2.0 是对 OAuth 1.0 的完全重新设计,OAuth 2.0 更快,更容易实现,OAuth 1.0 已经被废弃。
实际上它就是一种授权机制,它的最终目的是为第三方应用颁发一个有时效性的令牌 Token,使得第三方应用能够通过该令牌获取相关的资源。
OAuth 2.0 比较常用的场景就是第三方登录,当你的网站接入了第三方登录的时候一般就是使用的 OAuth 2.0 协议。
另外,现在 OAuth 2.0 也常见于支付场景(微信支付、支付宝支付)和开发平台(微信开放平台、阿里开放平台等等)。
下图是 Slack OAuth 2.0 第三方登录open in new window的示意图:
JWT 基础概念详解
什么是 JWT?
JWT (JSON Web Token) 是目前最流行的跨域认证解决方案,是一种基于 Token 的认证授权机制。 从 JWT 的全称可以看出,JWT 本身也是 Token,一种规范化之后的 JSON 结构的 Token。
JWT 自身包含了身份验证所需要的所有信息,因此,我们的服务器不需要存储 Session 信息。这显然增加了系统的可用性和伸缩性,大大减轻了服务端的压力。
可以看出,JWT 更符合设计 RESTful API 时的「Stateless(无状态)」原则 。
并且, 使用 JWT 认证可以有效避免 CSRF 攻击,因为 JWT 一般是存在在 localStorage 中,使用 JWT 进行身份验证的过程中是不会涉及到 Cookie 的。
JWT 由哪些部分组成?
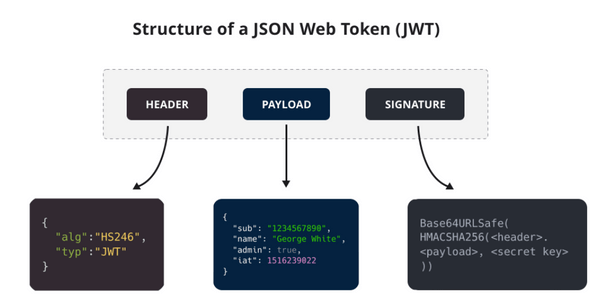
JWT 本质上就是一组字串,通过(.)切分成三个为 Base64 编码的部分:
- Header : 描述 JWT 的元数据,定义了生成签名的算法以及
Token的类型。 - Payload : 用来存放实际需要传递的数据
- Signature(签名):服务器通过 Payload、Header 和一个密钥(Secret)使用 Header 里面指定的签名算法(默认是 HMAC SHA256)生成。
Header 和 Payload 都是 JSON 格式的数据,Signature 由 Payload、Header 和 Secret(密钥)通过特定的计算公式和加密算法得到。
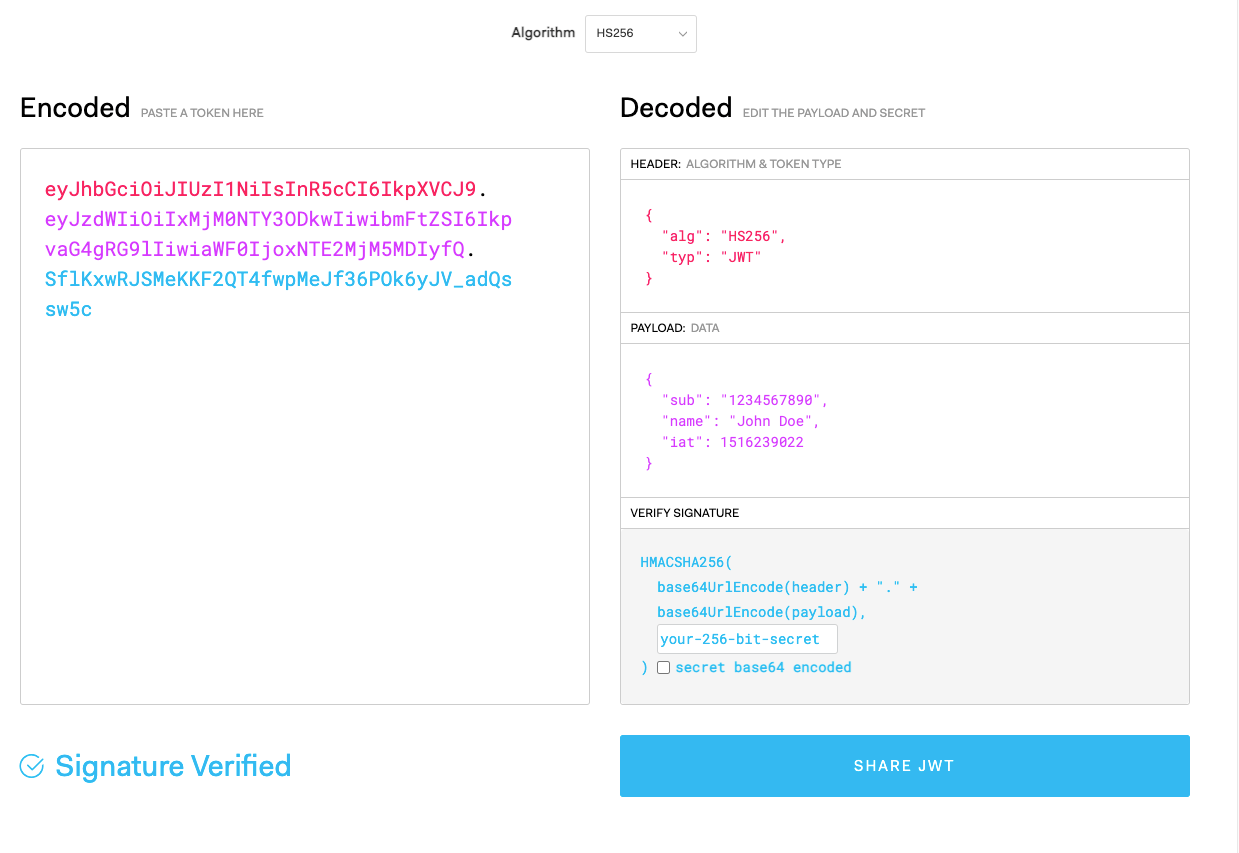
Header
Header 通常由两部分组成:
typ(Type):令牌类型,也就是 JWT。alg(Algorithm):签名算法,比如 HS256。
示例:
{
"alg": "HS256",
"typ": "JWT"
}
JSON 形式的 Header 被转换成 Base64 编码,成为 JWT 的第一部分。
Payload
Payload 也是 JSON 格式数据,其中包含了 Claims(声明,包含 JWT 的相关信息)。
Claims 分为三种类型:
- Registered Claims(注册声明):预定义的一些声明,建议使用,但不是强制性的。
- Public Claims(公有声明):JWT 签发方可以自定义的声明,但是为了避免冲突,应该在 IANA JSON Web Token Registryopen in new window 中定义它们。
- Private Claims(私有声明):JWT 签发方因为项目需要而自定义的声明,更符合实际项目场景使用。
下面是一些常见的注册声明:
iss(issuer):JWT 签发方。iat(issued at time):JWT 签发时间。sub(subject):JWT 主题。aud(audience):JWT 接收方。exp(expiration time):JWT 的过期时间。nbf(not before time):JWT 生效时间,早于该定义的时间的 JWT 不能被接受处理。jti(JWT ID):JWT 唯一标识。
Payload 部分默认是不加密的,一定不要将隐私信息存放在 Payload 当中!!!
JSON 形式的 Payload 被转换成 Base64 编码,成为 JWT 的第二部分。
Signature
Signature 部分是对前两部分的签名,作用是防止 JWT(主要是 payload) 被篡改。
这个签名的生成需要用到:
- Header + Payload。
- 存放在服务端的密钥(一定不要泄露出去)。
- 签名算法。
签名的计算公式如下:
HMACSHA256(
base64UrlEncode(header) + "." +
base64UrlEncode(payload),
secret)
算出签名以后,把 Header、Payload、Signature 三个部分拼成一个字符串,每个部分之间用"点"(.)分隔,这个字符串就是 JWT 。
如何基于 JWT 进行身份验证?
在基于 JWT 进行身份验证的的应用程序中,服务器通过 Payload、Header 和 Secret(密钥)创建 JWT 并将 JWT 发送给客户端。客户端接收到 JWT 之后,会将其保存在 Cookie 或者 localStorage 里面,以后客户端发出的所有请求都会携带这个令牌。
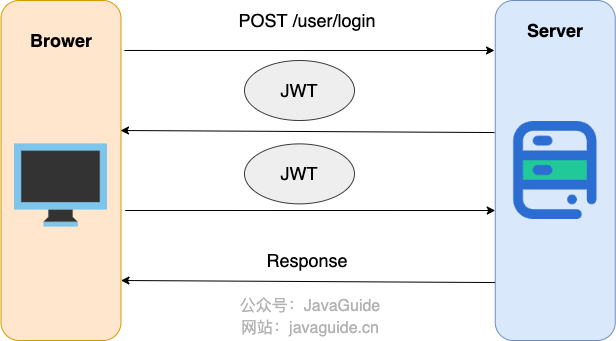
简化后的步骤如下:
- 用户向服务器发送用户名、密码以及验证码用于登陆系统。
- 如果用户用户名、密码以及验证码校验正确的话,服务端会返回已经签名的 Token,也就是 JWT。
- 用户以后每次向后端发请求都在 Header 中带上这个 JWT 。
- 服务端检查 JWT 并从中获取用户相关信息。
两点建议:
- 建议将 JWT 存放在 localStorage 中,放在 Cookie 中会有 CSRF 风险。
- 请求服务端并携带 JWT 的常见做法是将其放在 HTTP Header 的
Authorization字段中(Authorization: Bearer Token)。
如何防止 JWT 被篡改?
有了签名之后,即使 JWT 被泄露或者截获,黑客也没办法同时篡改 Signature、Header、Payload。
这是为什么呢?因为服务端拿到 JWT 之后,会解析出其中包含的 Header、Payload 以及 Signature 。服务端会根据 Header、Payload、密钥再次生成一个 Signature。拿新生成的 Signature 和 JWT 中的 Signature 作对比,如果一样就说明 Header 和 Payload 没有被修改。
不过,如果服务端的秘钥也被泄露的话,黑客就可以同时篡改 Signature、Header、Payload 了。黑客直接修改了 Header 和 Payload 之后,再重新生成一个 Signature 就可以了。
密钥一定保管好,一定不要泄露出去。JWT 安全的核心在于签名,签名安全的核心在密钥。
如何加强 JWT 的安全性?
- 使用安全系数高的加密算法。
- 使用成熟的开源库,没必要造轮子。
- JWT 存放在 localStorage 中而不是 Cookie 中,避免 CSRF 风险。
- 一定不要将隐私信息存放在 Payload 当中。
- 密钥一定保管好,一定不要泄露出去。JWT 安全的核心在于签名,签名安全的核心在密钥。
- Payload 要加入
exp(JWT 的过期时间),永久有效的 JWT 不合理。并且,JWT 的过期时间不易过长。
JWT 的优势
相比于 Session 认证的方式来说,使用 JWT 进行身份认证主要有下面 4 个优势。
无状态
JWT 自身包含了身份验证所需要的所有信息,因此,我们的服务器不需要存储 Session 信息。这显然增加了系统的可用性和伸缩性,大大减轻了服务端的压力。
不过,也正是由于 JWT 的无状态,也导致了它最大的缺点:不可控!
就比如说,我们想要在 JWT 有效期内废弃一个 JWT 或者更改它的权限的话,并不会立即生效,通常需要等到有效期过后才可以。再比如说,当用户 Logout 的话,JWT 也还有效。除非,我们在后端增加额外的处理逻辑比如将失效的 JWT 存储起来,后端先验证 JWT 是否有效再进行处理。具体的解决办法,我们会在后面的内容中详细介绍到,这里只是简单提一下。
有效避免了 CSRF 攻击
CSRF(Cross Site Request Forgery) 一般被翻译为 跨站请求伪造,属于网络攻击领域范围。相比于 SQL 脚本注入、XSS 等安全攻击方式,CSRF 的知名度并没有它们高。但是,它的确是我们开发系统时必须要考虑的安全隐患。就连业内技术标杆 Google 的产品 Gmail 也曾在 2007 年的时候爆出过 CSRF 漏洞,这给 Gmail 的用户造成了很大的损失。
那么究竟什么是跨站请求伪造呢? 简单来说就是用你的身份去做一些不好的事情(发送一些对你不友好的请求比如恶意转账)。
CSRF 攻击需要依赖 Cookie ,Session 认证中 Cookie 中的 SessionID 是由浏览器发送到服务端的,只要发出请求,Cookie 就会被携带。借助这个特性,即使黑客无法获取你的 SessionID,只要让你误点攻击链接,就可以达到攻击效果。另外,并不是必须点击链接才可以达到攻击效果,很多时候,只要你打开了某个页面,CSRF 攻击就会发生。
那为什么 JWT 不会存在这种问题呢?
一般情况下我们使用 JWT 的话,在我们登录成功获得 JWT 之后,一般会选择存放在 localStorage 中。前端的每一个请求后续都会附带上这个 JWT,整个过程压根不会涉及到 Cookie。因此,即使你点击了非法链接发送了请求到服务端,这个非法请求也是不会携带 JWT 的,所以这个请求将是非法的。
总结来说就一句话:使用 JWT 进行身份验证不需要依赖 Cookie ,因此可以避免 CSRF 攻击。
不过,这样也会存在 XSS 攻击的风险。为了避免 XSS 攻击,你可以选择将 JWT 存储在标记为httpOnly 的 Cookie 中。但是,这样又导致了你必须自己提供 CSRF 保护,因此,实际项目中我们通常也不会这么做。
常见的避免 XSS 攻击的方式是过滤掉请求中存在 XSS 攻击风险的可疑字符串。
在 Spring 项目中,我们一般是通过创建 XSS 过滤器来实现的。
@Component
@Order(Ordered.HIGHEST_PRECEDENCE)
public class XSSFilter implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException, ServletException {
XSSRequestWrapper wrappedRequest =
new XSSRequestWrapper((HttpServletRequest) request);
chain.doFilter(wrappedRequest, response);
}
// other methods
}
适合移动端应用
使用 Session 进行身份认证的话,需要保存一份信息在服务器端,而且这种方式会依赖到 Cookie(需要 Cookie 保存 SessionId),所以不适合移动端。
但是,使用 JWT 进行身份认证就不会存在这种问题,因为只要 JWT 可以被客户端存储就能够使用,而且 JWT 还可以跨语言使用。
单点登录友好
使用 Session 进行身份认证的话,实现单点登录,需要我们把用户的 Session 信息保存在一台电脑上,并且还会遇到常见的 Cookie 跨域的问题。但是,使用 JWT 进行认证的话, JWT 被保存在客户端,不会存在这些问题。
JWT 身份认证常见问题及解决办法
注销登录等场景下 JWT 还有效
与之类似的具体相关场景有:
- 退出登录;
- 修改密码;
- 服务端修改了某个用户具有的权限或者角色;
- 用户的帐户被封禁/删除;
- 用户被服务端强制注销;
- 用户被踢下线;
这个问题不存在于 Session 认证方式中,因为在 Session 认证方式中,遇到这种情况的话服务端删除对应的 Session 记录即可。但是,使用 JWT 认证的方式就不好解决了。我们也说过了,JWT 一旦派发出去,如果后端不增加其他逻辑的话,它在失效之前都是有效的。
那我们如何解决这个问题呢?查阅了很多资料,我简单总结了下面 4 种方案:
1、将 JWT 存入内存数据库
将 JWT 存入 DB 中,Redis 内存数据库在这里是不错的选择。如果需要让某个 JWT 失效就直接从 Redis 中删除这个 JWT 即可。但是,这样会导致每次使用 JWT 发送请求都要先从 DB 中查询 JWT 是否存在的步骤,而且违背了 JWT 的无状态原则。
2、黑名单机制
和上面的方式类似,使用内存数据库比如 Redis 维护一个黑名单,如果想让某个 JWT 失效的话就直接将这个 JWT 加入到 黑名单 即可。然后,每次使用 JWT 进行请求的话都会先判断这个 JWT 是否存在于黑名单中。
前两种方案的核心在于将有效的 JWT 存储起来或者将指定的 JWT 拉入黑名单。
虽然这两种方案都违背了 JWT 的无状态原则,但是一般实际项目中我们通常还是会使用这两种方案。
3、修改密钥 (Secret) :
我们为每个用户都创建一个专属密钥,如果我们想让某个 JWT 失效,我们直接修改对应用户的密钥即可。但是,这样相比于前两种引入内存数据库带来了危害更大:
- 如果服务是分布式的,则每次发出新的 JWT 时都必须在多台机器同步密钥。为此,你需要将密钥存储在数据库或其他外部服务中,这样和 Session 认证就没太大区别了。
- 如果用户同时在两个浏览器打开系统,或者在手机端也打开了系统,如果它从一个地方将账号退出,那么其他地方都要重新进行登录,这是不可取的。
4、保持令牌的有效期限短并经常轮换
很简单的一种方式。但是,会导致用户登录状态不会被持久记录,而且需要用户经常登录。
另外,对于修改密码后 JWT 还有效问题的解决还是比较容易的。说一种我觉得比较好的方式:使用用户的密码的哈希值对 JWT 进行签名。因此,如果密码更改,则任何先前的令牌将自动无法验证。
JWT 的续签问题
JWT 有效期一般都建议设置的不太长,那么 JWT 过期后如何认证,如何实现动态刷新 JWT,避免用户经常需要重新登录?
我们先来看看在 Session 认证中一般的做法:假如 Session 的有效期 30 分钟,如果 30 分钟内用户有访问,就把 Session 有效期延长 30 分钟。
JWT 认证的话,我们应该如何解决续签问题呢?查阅了很多资料,我简单总结了下面 4 种方案:
1、类似于 Session 认证中的做法
这种方案满足于大部分场景。假设服务端给的 JWT 有效期设置为 30 分钟,服务端每次进行校验时,如果发现 JWT 的有效期马上快过期了,服务端就重新生成 JWT 给客户端。客户端每次请求都检查新旧 JWT,如果不一致,则更新本地的 JWT。这种做法的问题是仅仅在快过期的时候请求才会更新 JWT ,对客户端不是很友好。
2、每次请求都返回新 JWT
这种方案的的思路很简单,但是,开销会比较大,尤其是在服务端要存储维护 JWT 的情况下。
3、JWT 有效期设置到半夜
这种方案是一种折衷的方案,保证了大部分用户白天可以正常登录,适用于对安全性要求不高的系统。
4、用户登录返回两个 JWT
第一个是 accessJWT ,它的过期时间 JWT 本身的过期时间比如半个小时,另外一个是 refreshJWT 它的过期时间更长一点比如为 1 天。客户端登录后,将 accessJWT 和 refreshJWT 保存在本地,每次访问将 accessJWT 传给服务端。服务端校验 accessJWT 的有效性,如果过期的话,就将 refreshJWT 传给服务端。如果有效,服务端就生成新的 accessJWT 给客户端。否则,客户端就重新登录即可。
这种方案的不足是:
- 需要客户端来配合;
- 用户注销的时候需要同时保证两个 JWT 都无效;
- 重新请求获取 JWT 的过程中会有短暂 JWT 不可用的情况(可以通过在客户端设置定时器,当 accessJWT 快过期的时候,提前去通过 refreshJWT 获取新的 accessJWT);
- 存在安全问题,只要拿到了未过期的 refreshJWT 就一直可以获取到 accessJWT。
SSO 介绍
什么是 SSO?
SSO 英文全称 Single Sign On,单点登录。SSO 是在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用系统。
SSO 有什么好处?
- 用户角度 :用户能够做到一次登录多次使用,无需记录多套用户名和密码,省心。
- 系统管理员角度 : 管理员只需维护好一个统一的账号中心就可以了,方便。
- 新系统开发角度: 新系统开发时只需直接对接统一的账号中心即可,简化开发流程,省时。
SSO 设计与实现
本篇文章也主要是为了探讨如何设计&实现一个 SSO 系统
以下为需要实现的核心功能:
- 单点登录
- 单点登出
- 支持跨域单点登录
- 支持跨域单点登出
核心应用与依赖
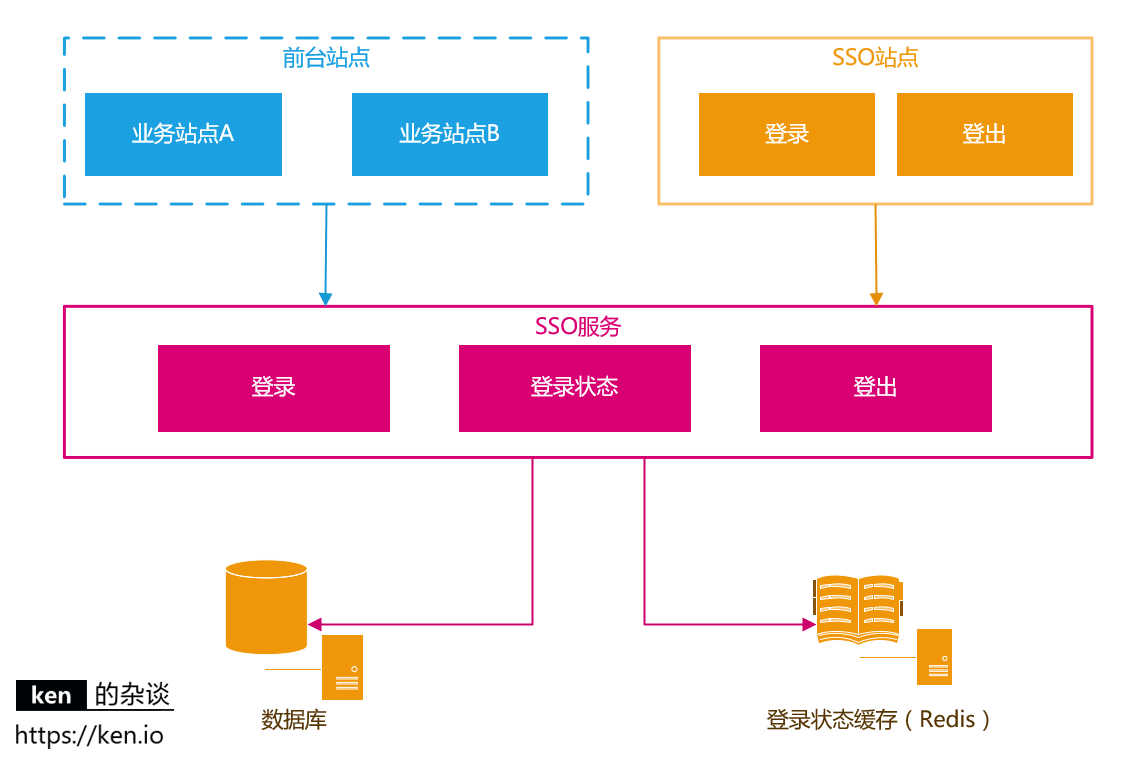
单点登录(SSO)设计
| 应用/模块/对象 | 说明 |
|---|---|
| 前台站点 | 需要登录的站点 |
| SSO 站点-登录 | 提供登录的页面 |
| SSO 站点-登出 | 提供注销登录的入口 |
| SSO 服务-登录 | 提供登录服务 |
| SSO 服务-登录状态 | 提供登录状态校验/登录信息查询的服务 |
| SSO 服务-登出 | 提供用户注销登录的服务 |
| 数据库 | 存储用户账户信息 |
| 缓存 | 存储用户的登录信息,通常使用 Redis |
用户登录状态的存储与校验
常见的 Web 框架对于 Session 的实现都是生成一个 SessionId 存储在浏览器 Cookie 中。然后将 Session 内容存储在服务器端内存中,这个 ken.ioopen in new window 在之前Session 工作原理open in new window中也提到过。整体也是借鉴这个思路。
用户登录成功之后,生成 AuthToken 交给客户端保存。如果是浏览器,就保存在 Cookie 中。如果是手机 App 就保存在 App 本地缓存中。本篇主要探讨基于 Web 站点的 SSO。
用户在浏览需要登录的页面时,客户端将 AuthToken 提交给 SSO 服务校验登录状态/获取用户登录信息
对于登录信息的存储,建议采用 Redis,使用 Redis 集群来存储登录信息,既可以保证高可用,又可以线性扩充。同时也可以让 SSO 服务满足负载均衡/可伸缩的需求。
| 对象 | 说明 |
|---|---|
| AuthToken | 直接使用 UUID/GUID 即可,如果有验证 AuthToken 合法性需求,可以将 UserName+时间戳加密生成,服务端解密之后验证合法性 |
| 登录信息 | 通常是将 UserId,UserName 缓存起来 |
用户登录/登录校验
登录时序图
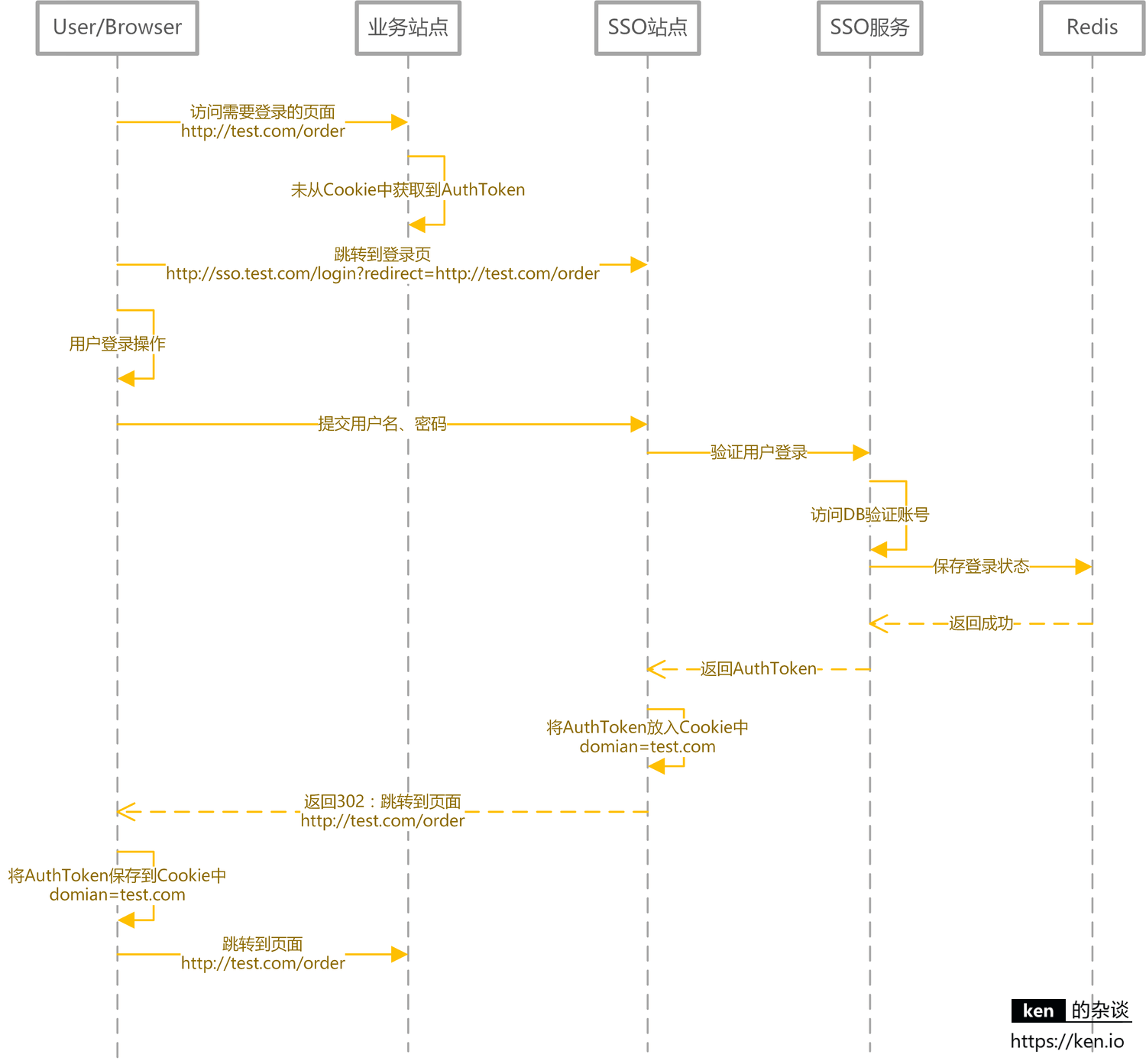
按照上图,用户登录后 AuthToken 保存在 Cookie 中。 domain=test.com 浏览器会将 domain 设置成 .test.com,
这样访问所有 *.test.com 的 web 站点,都会将 AuthToken 携带到服务器端。 然后通过 SSO 服务,完成对用户状态的校验/用户登录信息的获取
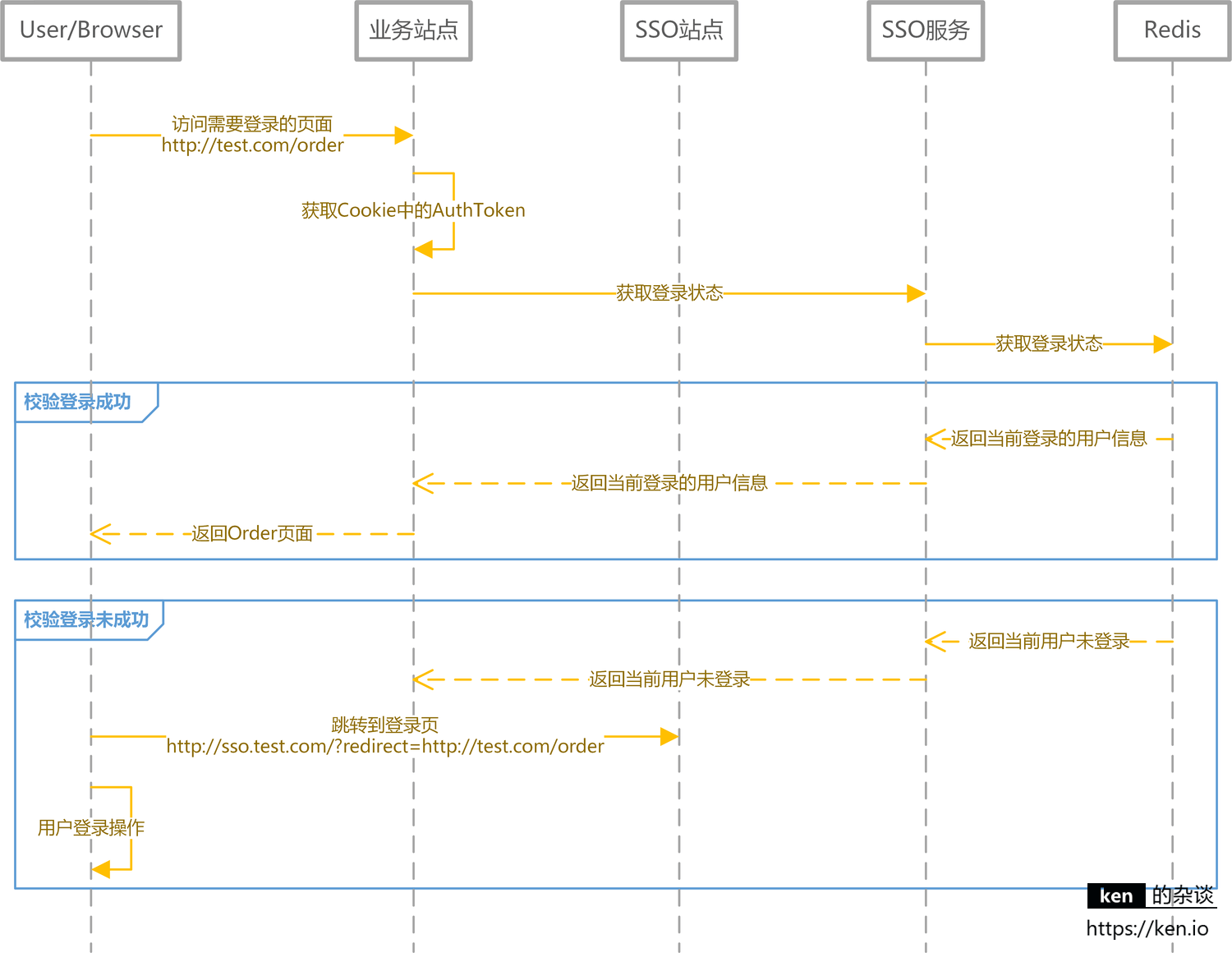
登录信息获取/登录状态校验
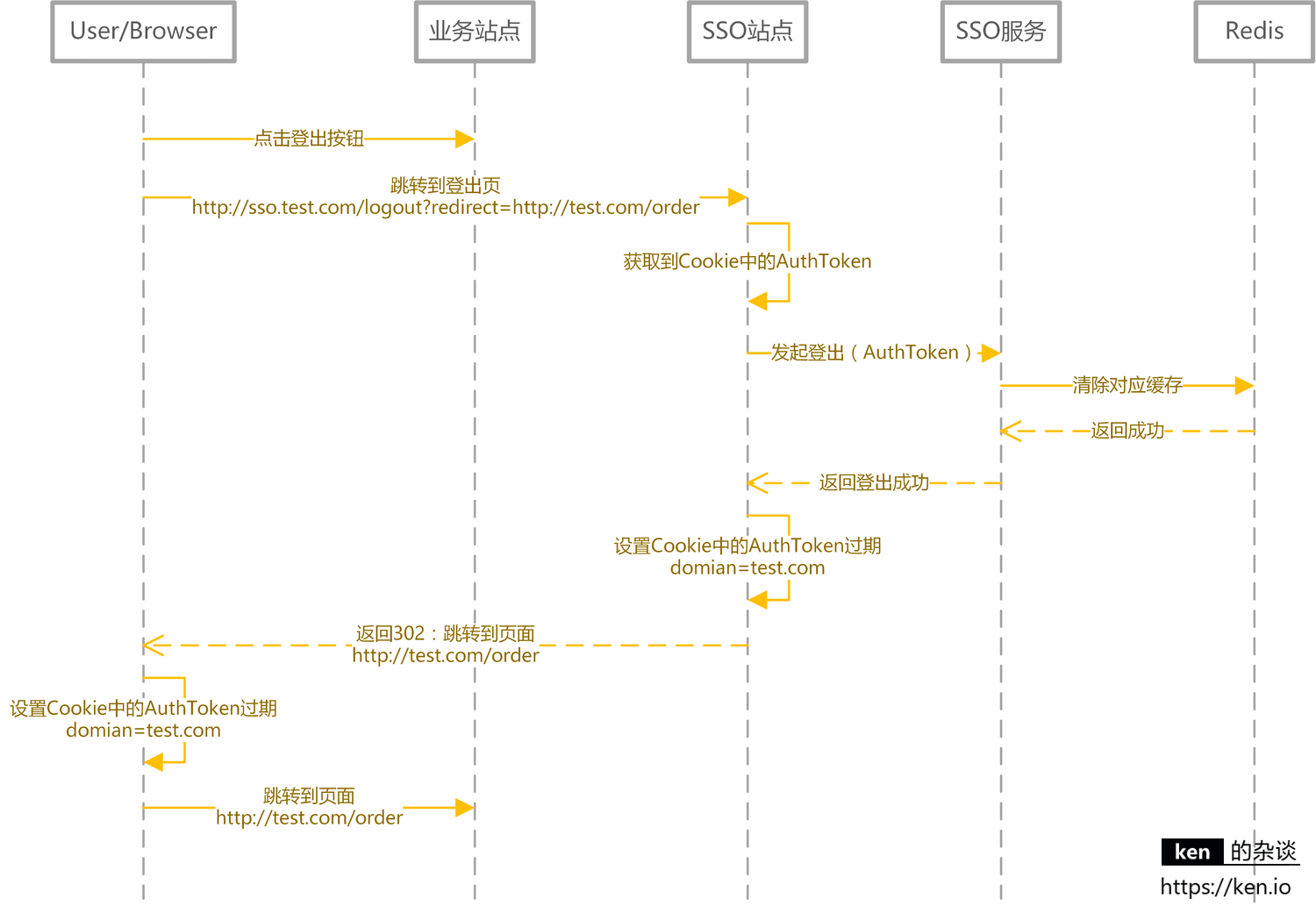
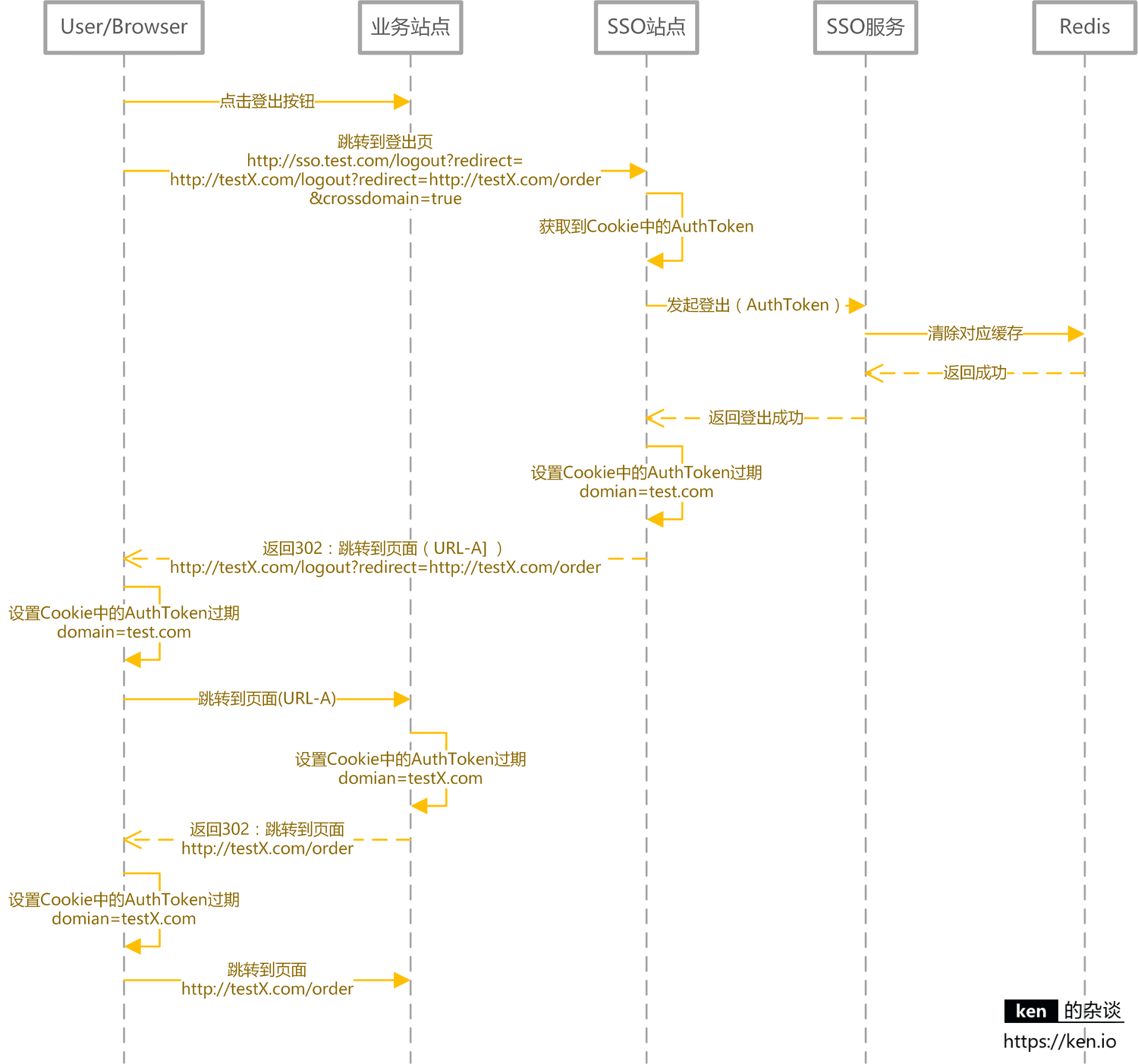
用户登出
用户登出时要做的事情很简单:
- 服务端清除缓存(Redis)中的登录状态
- 客户端清除存储的 AuthToken
登出时序图
跨域登录、登出
前面提到过,核心思路是客户端存储 AuthToken,服务器端通过 Redis 存储登录信息。由于客户端是将 AuthToken 存储在 Cookie 中的。所以跨域要解决的问题,就是如何解决 Cookie 的跨域读写问题。
解决跨域的核心思路就是:
- 登录完成之后通过回调的方式,将 AuthToken 传递给主域名之外的站点,该站点自行将 AuthToken 保存在当前域下的 Cookie 中。
- 登出完成之后通过回调的方式,调用非主域名站点的登出页面,完成设置 Cookie 中的 AuthToken 过期的操作。
跨域登录(主域名已登录)
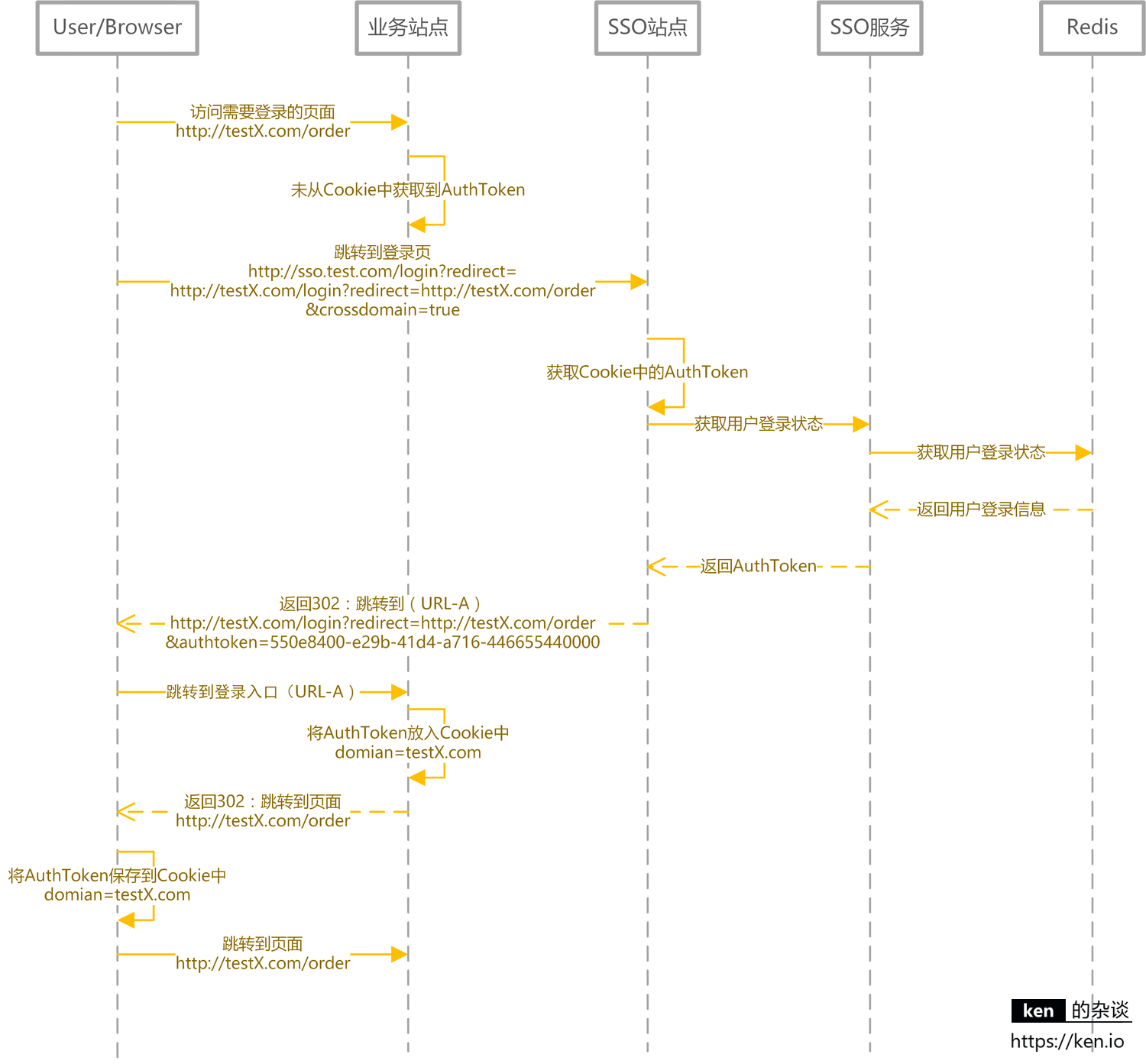
跨域登录(主域名未登录)
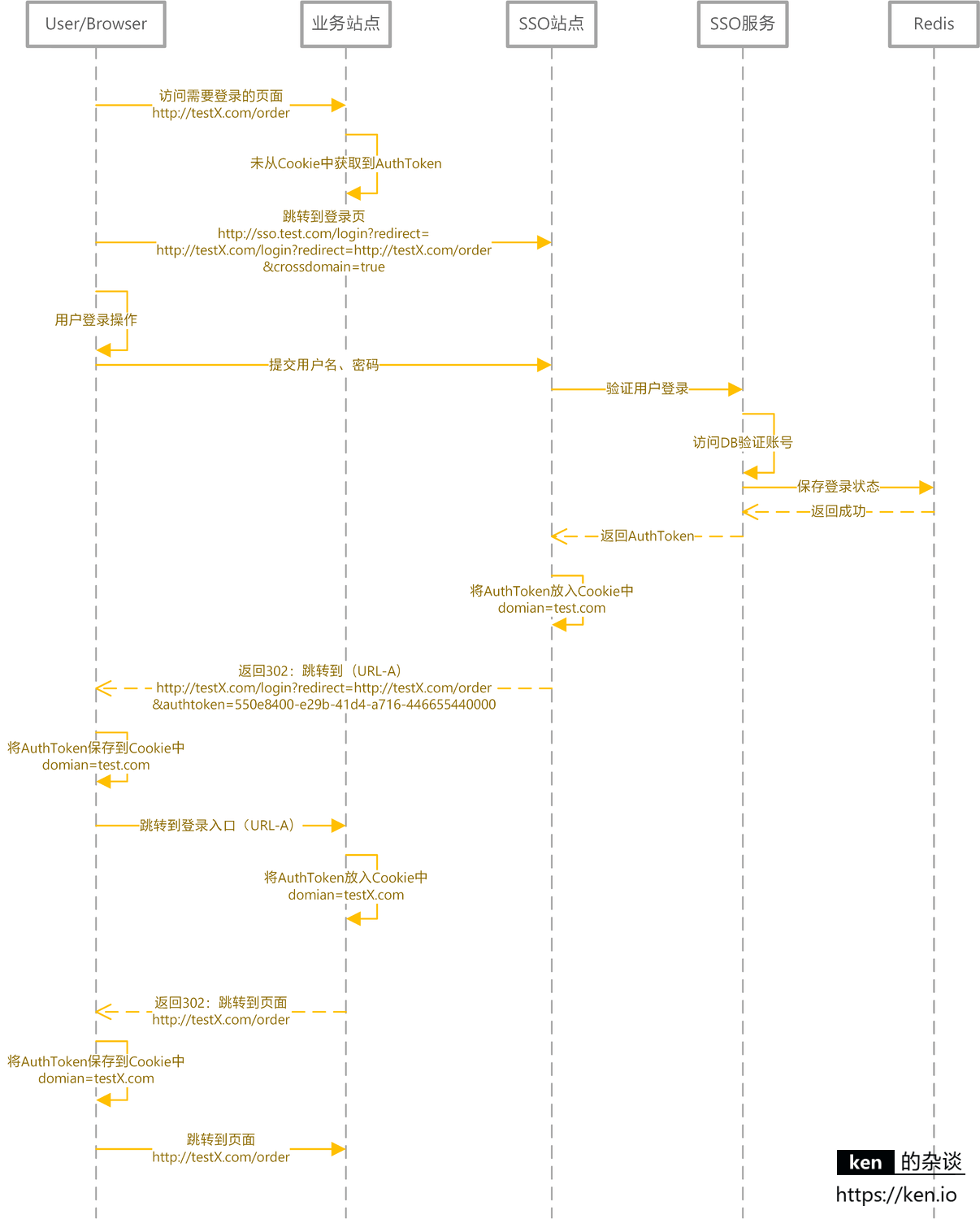
跨域登出
业界权限系统的设计方式
目前业界主流的权限模型有两种,下面分别介绍下:
- 基于角色的访问控制(RBAC)
- 基于属性的访问控制(ABAC)
RBAC 模型
基于角色的访问控制(Role-Based Access Control,简称 RBAC) 指的是通过用户的角色(Role)授权其相关权限,实现了灵活的访问控制,相比直接授予用户权限,要更加简单、高效、可扩展。
一个用户可以拥有若干角色,每一个角色又可以被分配若干权限这样,就构造成“用户-角色-权限” 的授权模型。在这种模型中,用户与角色、角色与权限之间构成了多对多的关系。
用一个图来描述如下:

当使用 RBAC模型 时,通过分析用户的实际情况,基于共同的职责和需求,授予他们不同角色。这种 用户 -> 角色 -> 权限 间的关系,让我们可以不用再单独管理单个用户权限,用户从授予的角色里面获取所需的权限。
以一个简单的场景(Gitlab 的权限系统)为例,用户系统中有 Admin、Maintainer、Operator 三种角色,这三种角色分别具备不同的权限,比如只有 Admin 具备创建代码仓库、删除代码仓库的权限,其他的角色都不具备。我们授予某个用户 Admin 这个角色,他就具备了 创建代码仓库 和 删除代码仓库 这两个权限。
通过 RBAC模型 ,当存在多个用户拥有相同权限时,我们只需要创建好拥有该权限的角色,然后给不同的用户分配不同的角色,后续只需要修改角色的权限,就能自动修改角色内所有用户的权限。
ABAC 模型
基于属性的访问控制(Attribute-Based Access Control,简称 ABAC) 是一种比 RBAC模型 更加灵活的授权模型,它的原理是通过各种属性来动态判断一个操作是否可以被允许。这个模型在云系统中使用的比较多,比如 AWS,阿里云等。
考虑下面这些场景的权限控制:
- 授权某个人具体某本书的编辑权限
- 当一个文档的所属部门跟用户的部门相同时,用户可以访问这个文档
- 当用户是一个文档的拥有者并且文档的状态是草稿,用户可以编辑这个文档
- 早上九点前禁止 A 部门的人访问 B 系统
- 在除了上海以外的地方禁止以管理员身份访问 A 系统
- 用户对 2022-06-07 之前创建的订单有操作权限
可以发现上述的场景通过 RBAC模型 很难去实现,因为 RBAC模型 仅仅描述了用户可以做什么操作,但是操作的条件,以及操作的数据,RBAC模型 本身是没有这些限制的。但这恰恰是 ABAC模型 的长处,ABAC模型 的思想是基于用户、访问的数据的属性、以及各种环境因素去动态计算用户是否有权限进行操作。
ABAC 模型的原理
在 ABAC模型 中,一个操作是否被允许是基于对象、资源、操作和环境信息共同动态计算决定的。
- 对象:对象是当前请求访问资源的用户。用户的属性包括 ID,个人资源,角色,部门和组织成员身份等
- 资源:资源是当前用户要访问的资产或对象,例如文件,数据,服务器,甚至 API
- 操作:操作是用户试图对资源进行的操作。常见的操作包括“读取”,“写入”,“编辑”,“复制”和“删除”
- 环境:环境是每个访问请求的上下文。环境属性包含访问的时间和位置,对象的设备,通信协议和加密强度等
在 ABAC模型 的决策语句的执行过程中,决策引擎会根据定义好的决策语句,结合对象、资源、操作、环境等因素动态计算出决策结果。每当发生访问请求时,ABAC模型 决策系统都会分析属性值是否与已建立的策略匹配。如果有匹配的策略,访问请求就会被通过。
作者声明
如有问题,欢迎指正!