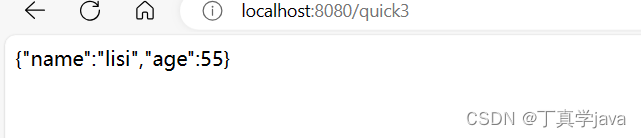
本篇文章主要讲解logstash的有关内容,包括filter的grok、date、user_agent、geoip、mutate插件,多个输入输出方案(多实例+if多分支语句),每个知识点都涉及实战练习,在实战中学习,事半功倍!
Filter常用插件详解
一、grok使用官方模块采集nginx日志
参考官网链接:https://www.elastic.co/guide/en/logstash/7.17/plugins-filters-grok.html
1、删除缓存数据,删除后会重新读取文件,注意删除前先停掉logstash
[root@ELK102 ~]# ll /usr/share/logstash/data/plugins/inputs/file/.sincedb_
.sincedb_d527d4fe95e50e89070186240149c8bb
.sincedb_df5ae0d18161177fc305494571a52fca
.sincedb_e516aafddd2f065b257550d46b8c954c
[root@ELK102 ~]# rm -rf /usr/share/logstash/data/plugins/inputs/file/.sincedb_*2、编写配置文件
[root@ELK102 ~]# cat /etc/logstash/conf.d/04-nginx-to-es.conf
input {
file {
start_position => "beginning"
path => ["/var/log/nginx/access.log*"]
}
}
filter{
grok{
match => {
"message" => "%{COMMONAPACHELOG}" #官方自带的Apache转换模块,与nginx格式一致
}
}
}
output {
elasticsearch {
hosts => ["10.0.0.101:19200","10.0.0.102:19200","10.0.0.103:19200"]
index => "koten-nginx-%{+yyyy.MM.dd}"
}
stdout {}
}
3、执行logstash查看grok转换结果
[root@ELK102 ~]# logstash -rf /etc/logstash/conf.d/04-nginx-to-es.conf
......
{
"@version" => "1",
"message" => "10.0.0.1 - - [29/May/2023:11:26:09 +0800] \"GET / HTTP/1.1\" 304 0 \"-\" \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.50\" \"-\"",
"path" => "/var/log/nginx/access.log",
"clientip" => "10.0.0.1",
"host" => "ELK102",
"request" => "/",
"@timestamp" => 2023-05-29T03:26:20.756Z,
"verb" => "GET",
"response" => "304",
"auth" => "-",
"httpversion" => "1.1",
"ident" => "-",
"timestamp" => "29/May/2023:11:26:09 +0800",
"bytes" => "0"
}
二、grok自定义正则案例
1、准备待匹配文本数据
[root@ELK102 ~]# cat /tmp/haha.log
welcome to kotenedu linux, 2023
2、编写自定义的匹配模式
[root@ELK102 ~]# mkdir koten-patterns/koten-patterns
[root@ELK102 ~]# cat koten-patterns/koten.patterns
SCHOOL [a-z]{8}
SUBJECT [a-z]{5}
YEAR [\d]{4}
3、编写grok的使用自定义匹配模式
[root@ELK102 ~]# cat config/05-file-grok-stdout.conf
input {
file {
start_position => "beginning"
path => ["/tmp/haha.log"]
}
}
filter {
# 基于正则匹配任意文本
grok {
# 加载自定义变量的存储目录
patterns_dir => ["./koten-patterns/"]
match => {
"message" => "welcome to %{SCHOOL:school} %{SUBJECT:subject}, %{YEAR:year}"
}
}
}
output {
stdout {
codec => rubydebug
}
}
4、启动logstash,注意,启动logstasg案例,为防止写入时多个案例调用同一个id的文档,导致数据少写,官方限制了多个案例同时启动,需要单独指定数据路径
[root@ELK102 ~]# logstash -rf /etc/logstash/conf.d/05-nginx_file-grok-stdout.conf
......
{
"message" => "welcome to kotenedu linux, 2023",
"school" => "kotenedu",
"subject" => "linux",
"year" => "2023",
"@timestamp" => 2023-05-29T12:01:33.003Z,
"host" => "ELK102",
"@version" => "1",
"path" => "/tmp/haha.log"
}
[root@ELK102 ~]# logstash -rf /etc/logstash/conf.d/05-nginx_file-grok-stdout.conf --path.data /tmp/new-data #单独指定数据路径三、date插件修改日期时间
参考官网链接:https://www.elastic.co/guide/en/logstash/7.17/plugins-filters-date.html
[root@ELK102 ~]# cat config/06-file-filter-es.conf
input {
file {
start_position => "beginning"
path => ["/var/log/nginx/access.log"]
}
}
filter {
grok {
match => "%{COMMONAPACHELOG}"
}
}
output {
elasticsearch{
hosts => ["10.0.0.101:19200","10.0.0.102:19200","10.0.0.103:19300"]
index => "koten-nginx-access-%{+yyyy.MM.dd}"
}
stdout {
codec => rubydebug
}
}
[root@ELK102 ~]# logstash -rf config/06-file-filter-es.conf
由于在kinbana中,若更改索引名字有日期,添加索引模式,下拉时间戳字段会显示@timestamp
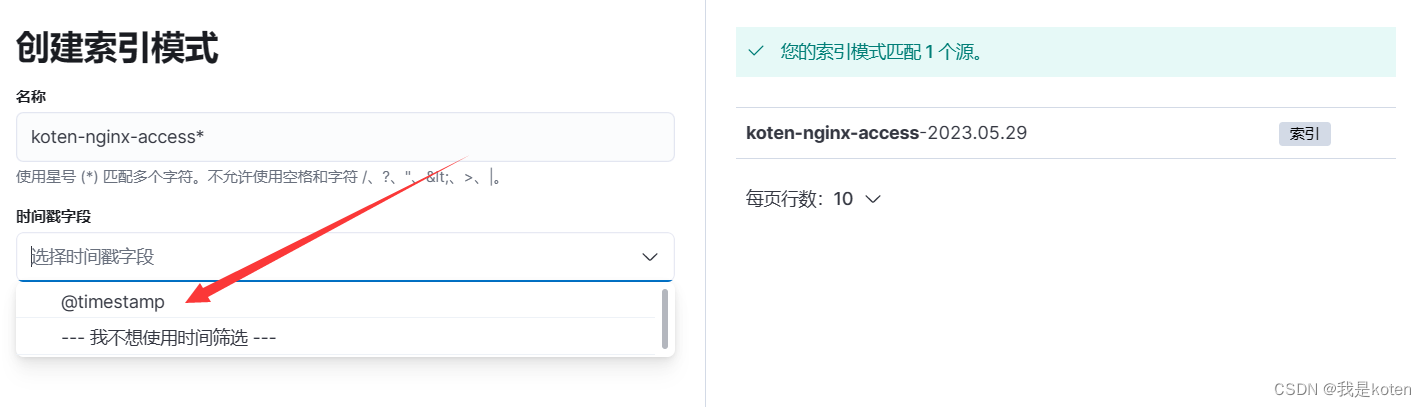
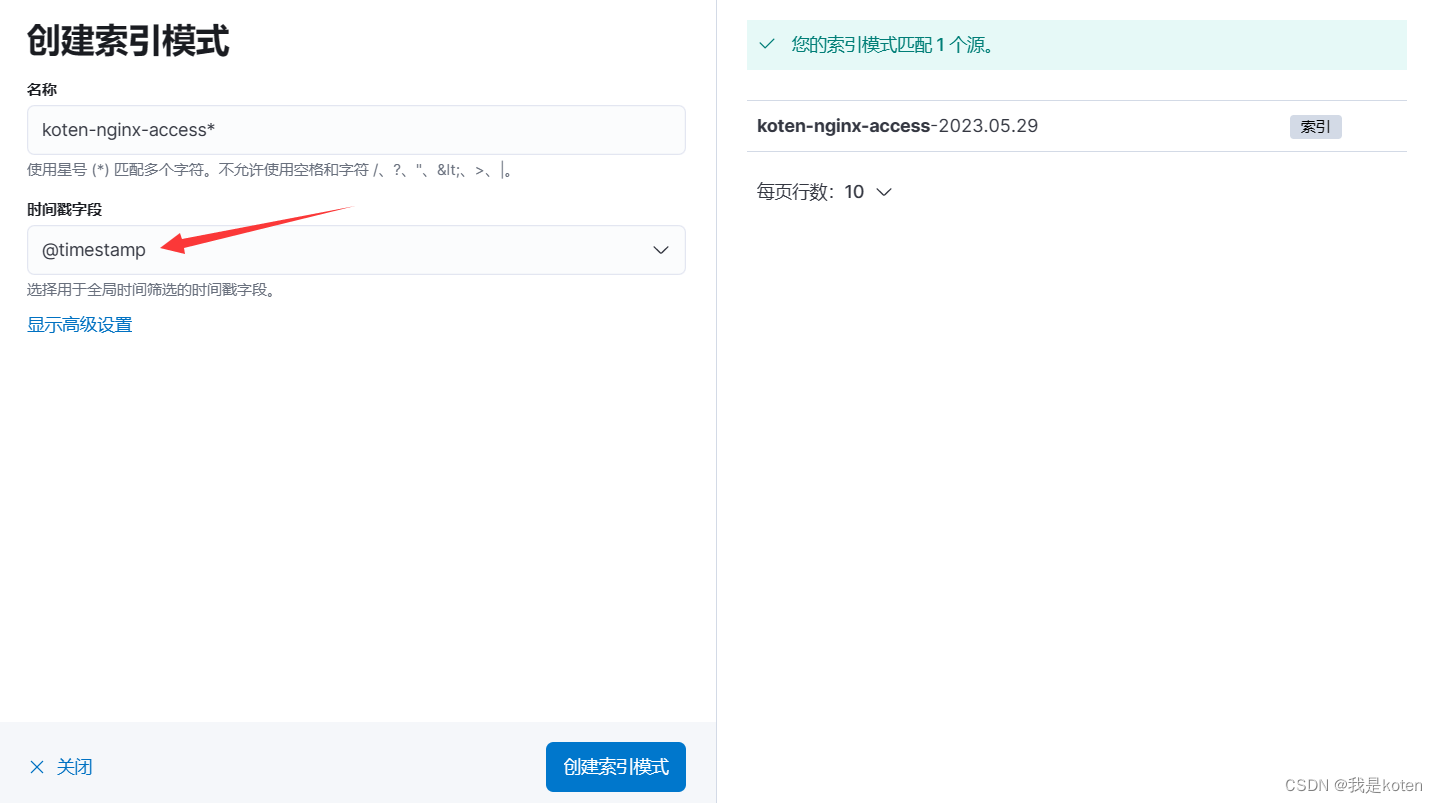
@timestamp 字段是logstash读取到日志的时间
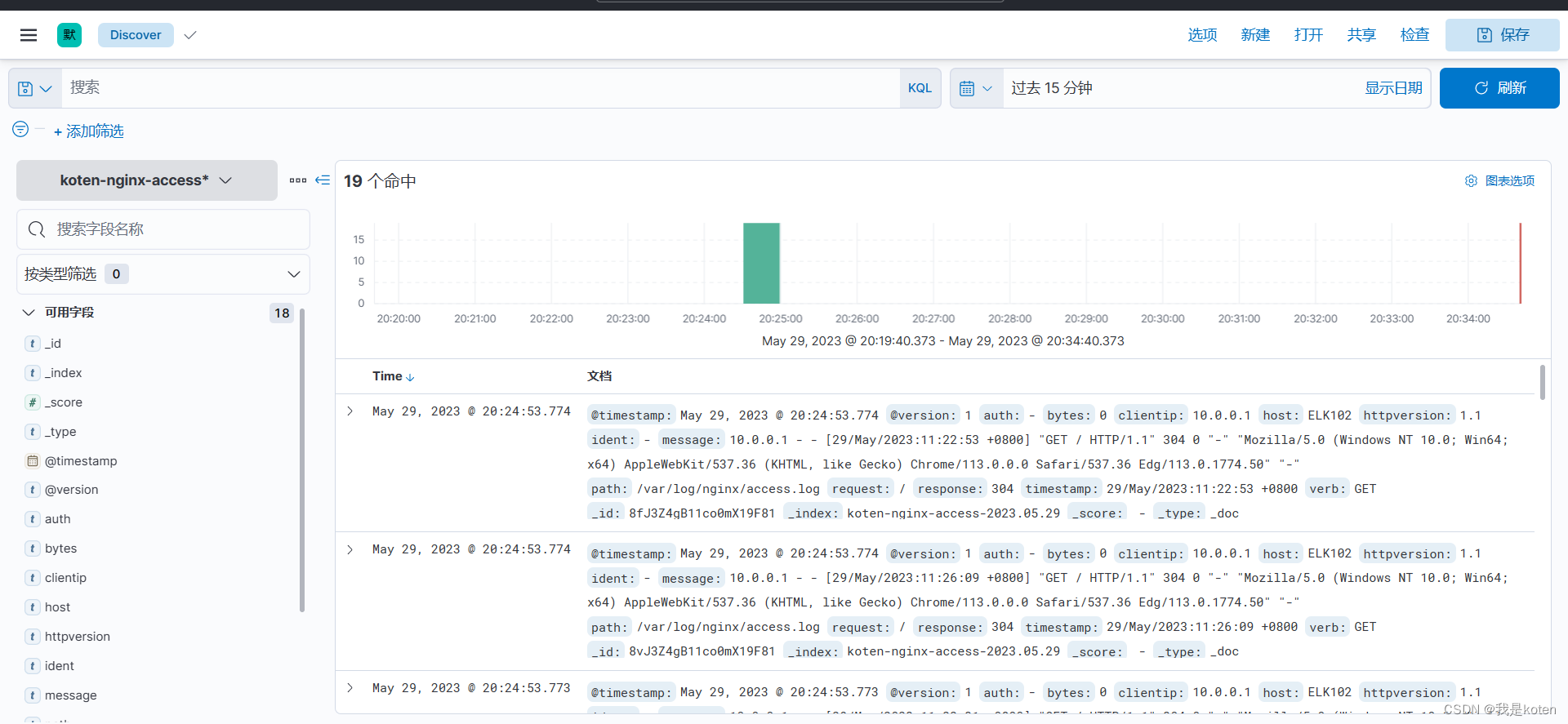
我们可以根据该时间进行筛选,但是该时间并不是日志的时间,有些时候我们想针对日志中的时间筛选,就需要date插件来定义日志中的时间
我们根据官网提供的时间符号来定义自己的时间格式
[root@ELK102 ~]# cat config/07-file-filter-es.conf
input {
file {
start_position => "beginning"
path => ["/var/log/nginx/access.log"]
}
}
filter {
grok {
match => {
"message" => "%{COMMONAPACHELOG}"
}
}
date {
match => [
# "28/May/2023:16:46:15 +0800"
"timestamp", "dd/MMM/yyyy:HH:mm:ss Z"
]
target => "koten-timestamp"
}
}
output {
elasticsearch{
hosts => ["10.0.0.101:19200","10.0.0.102:19200","10.0.0.103:19300"]
index => "koten-nginx-access-%{+yyyy.MM.dd}"
}
stdout {
codec => rubydebug
}
}
删除之前加入的索引和索引模式,删除logstash记录的添加收集记录,运行新的配置文件
[root@ELK102 ~]# rm -rf /usr/share/logstash/data/plugins/inputs/file/.sincedb_*
[root@ELK102 ~]# logstash -rf config/07-file-filter-es.conf
......
{
"koten-timestamp" => 2023-05-29T03:22:53.000Z, #格林威治时间
"bytes" => "0",
"verb" => "GET",
"timestamp" => "29/May/2023:11:22:53 +0800", #日志中的时间
"@timestamp" => 2023-05-29T12:47:30.415Z, #logstash读取到日志的时间
"path" => "/var/log/nginx/access.log",
"host" => "ELK102",
"ident" => "-",
"response" => "304",
"@version" => "1",
"httpversion" => "1.1",
"request" => "/",
"auth" => "-",
"message" => "10.0.0.1 - - [29/May/2023:11:22:53 +0800] \"GET / HTTP/1.1\" 304 0 \"-\" \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.50\" \"-\"",
"clientip" => "10.0.0.1"
}
此时timestamp字段已经由text字段,子字段是keyword字段转换成了date字段
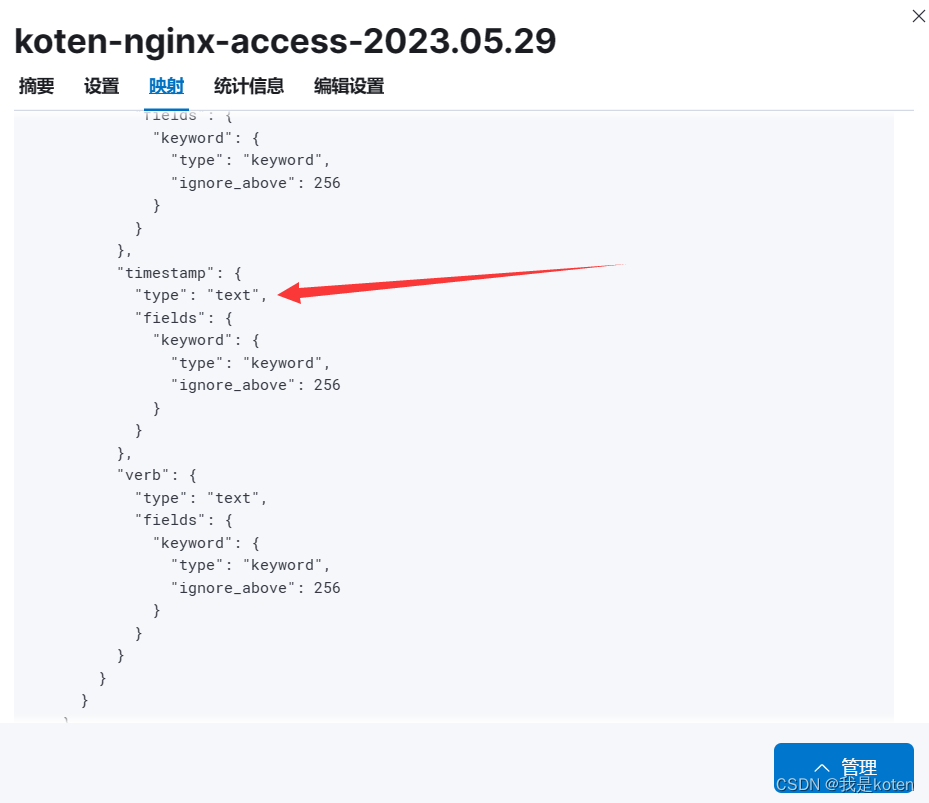
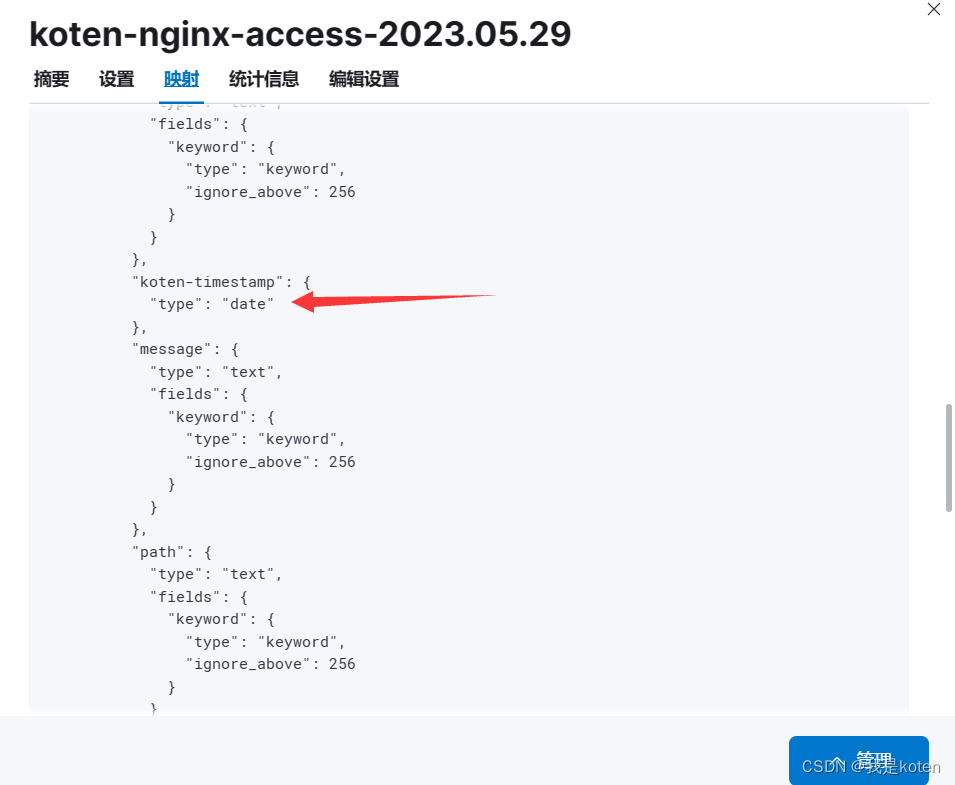
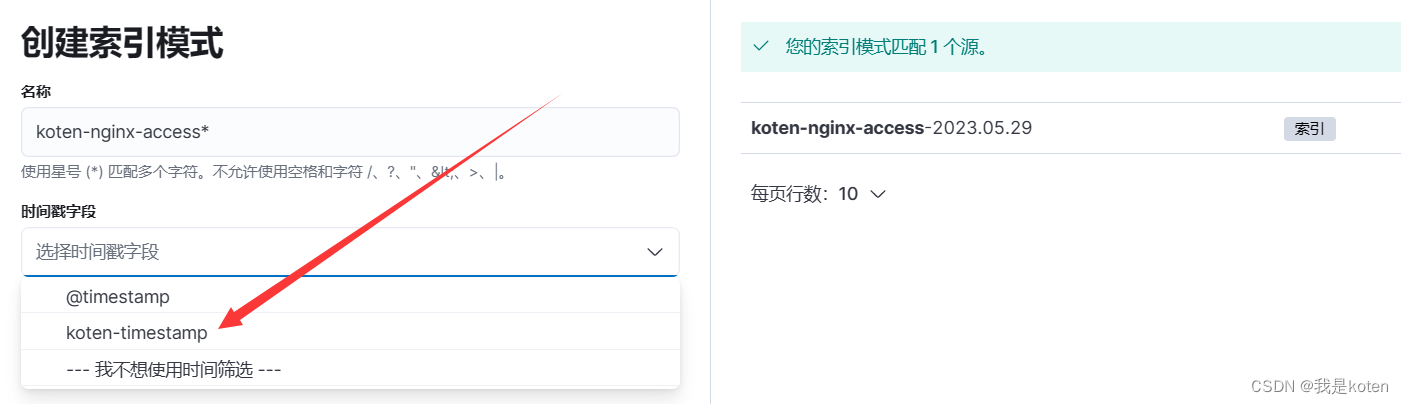
选择自己自定义的日志中的时间戳格式
观察字段发现右上角筛选日期变成了按照日志时间进行筛选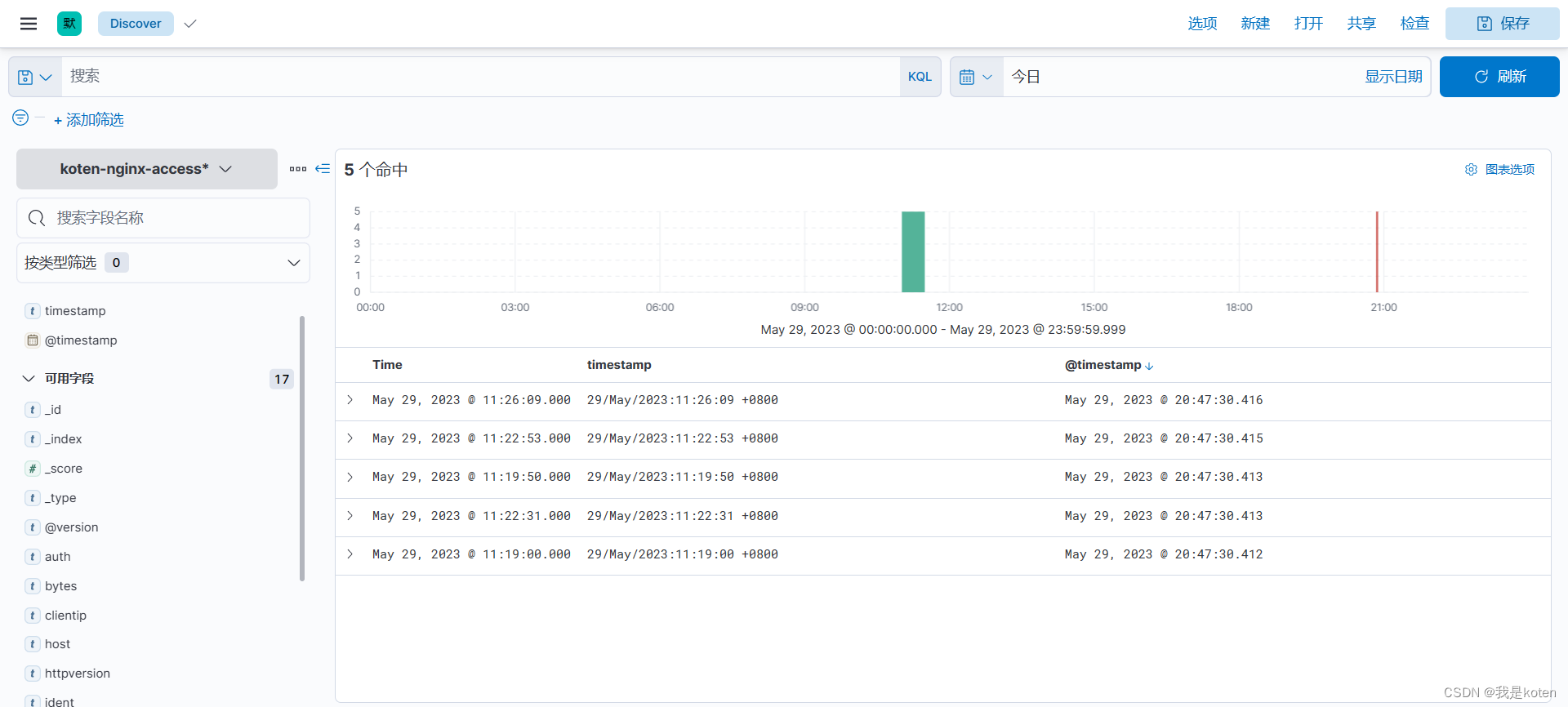
四、useragent插件
参考官网链接:https://www.elastic.co/guide/en/logstash/7.17/plugins-filters-useragent.html
分析"/tmp/nginx.log"日志,采集后写入ES,并分析2011~2021的访问量pv,设备类型
1、将一些nginx记录提前准备好,放到/tmp/下,命名为nginx.log
[root@ELK102 ~]# ll -h /tmp/nginx.log
-rw-r--r-- 1 root root 63M May 29 20:57 /tmp/nginx.log
[root@ELK102 ~]# wc -l /tmp/nginx.log
294549 /tmp/nginx.log
[root@ELK102 ~]# head -1 /tmp/nginx.log
54.94.14.30 - - [15/Sep/2010:02:16:14 +0800] "POST /zhibo.html HTTP/1.1" 200 555 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36" "-"
2、清空logstash缓存,方便其自动添加
[root@ELK102 ~]# rm -rf /usr/share/logstash/data/plugins/inputs/file/.since*
3、编写配置文件采集日志,并按照指定格式加入ES索引
[root@ELK102 ~]# cat config/08-file-filter-es.conf
input {
file {
start_position => "beginning"
path => ["/tmp/nginx.log"]
}
}
filter {
grok { #分析文本并解析提取需要的字段
match => { #匹配文本字段,可以引用内置的正则变量
"message" => "%{COMMONAPACHELOG}"
}
}
date { #解析日期的字段
match => [ #对时间进行格式化匹配并转换成ES的date字段
# "28/May/2023:16:46:15 +0800"
"timestamp", "dd/MMM/yyyy:HH:mm:ss Z"
]
#将转换后的结果存储在指定字段,若不指定,则默认覆盖@timestamp字段
target => "koten-timestamp"
}
# 分析客户端设备类型
useragent {
# 指定要分析客户端的字段
source => "message"
# 指定将分析的结果放在哪个字段中,若不指定,则放在顶级字段中。
target => "koten-agent"
}
}
output {
elasticsearch{
hosts => ["10.0.0.101:19200","10.0.0.102:19200","10.0.0.103:19300"]
index => "koten-nginx-access-%{+yyyy.MM.dd}"
}
#stdout { #数据量过大,挨个输出到屏幕上浪费时间
# codec => rubydebug
#}
}
4、运行logstash
[root@ELK102 ~]# logstash -rf config/08-file-filter-es.conf

这些都是useragent插件生成的设备信息的字段
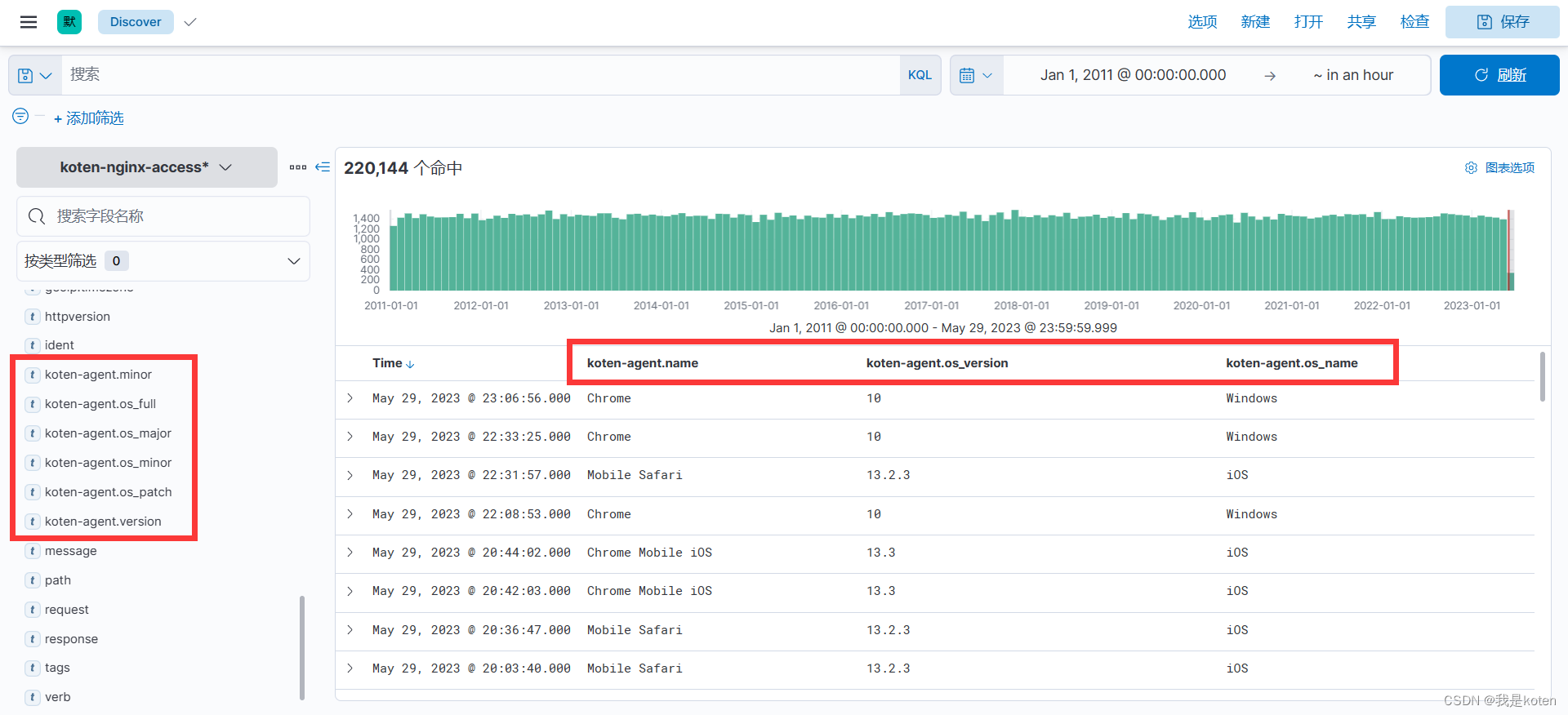
五、geoip插件
参考官网链接:https://www.elastic.co/guide/en/logstash/7.17/plugins-filters-geoip.html
写入地理位置测试数据到ES中,并在kibana中生成地图
1、在postman中创建索引并指定location字段
将location字段定义成geo_point类型
PUT http://10.0.0.101:19200/koten-map
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
2、写入一些测试数据
POST http://10.0.0.101:19200/_bulk
{ "create" : { "_index" : "koten-map" } }
{ "location": { "lat": 24,"lon": 121 }}
{ "create" : { "_index" : "koten-map" } }
{ "location": { "lat": 36.61,"lon": 114.488 }}
{ "create" : { "_index" : "koten-map" } }
{ "location": { "lat": 39.914,"lon": 116.386 }}
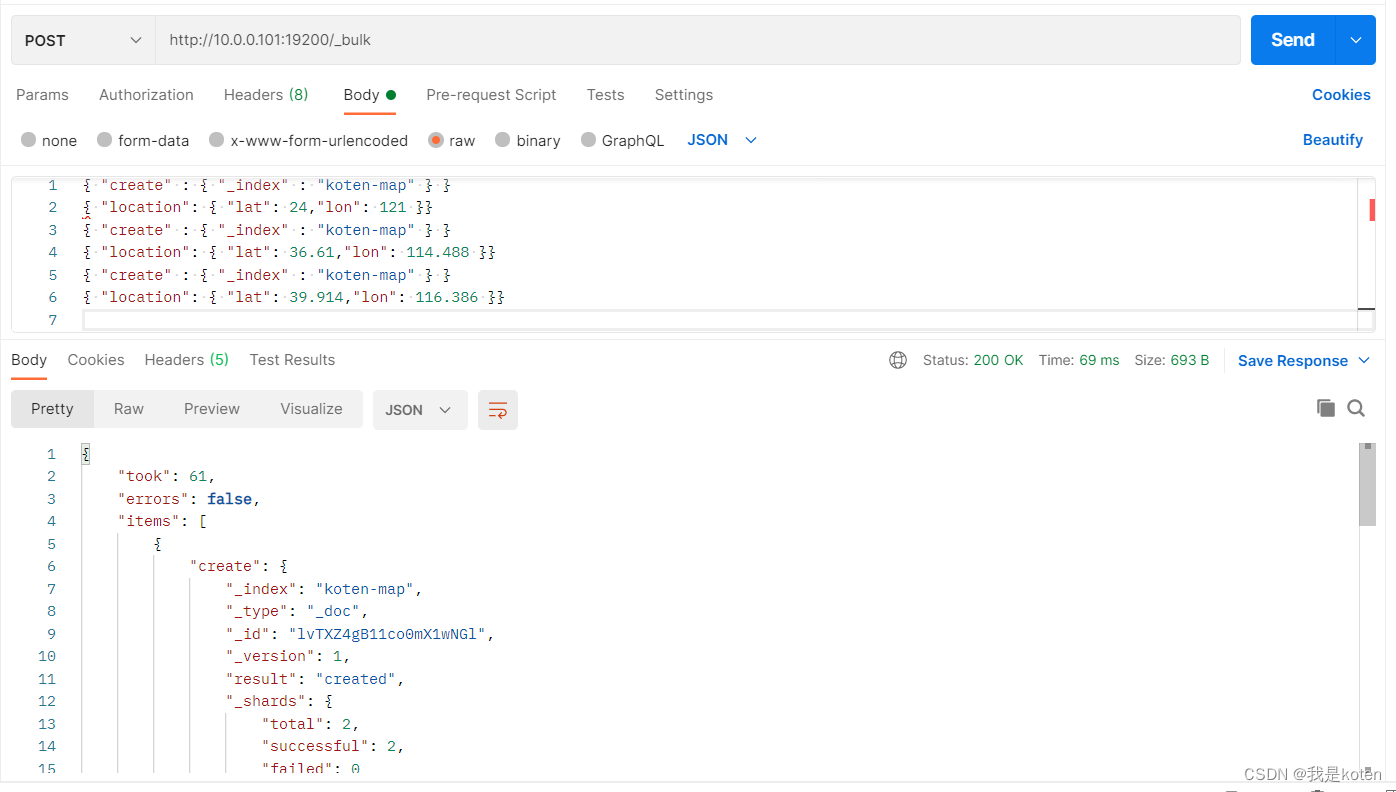
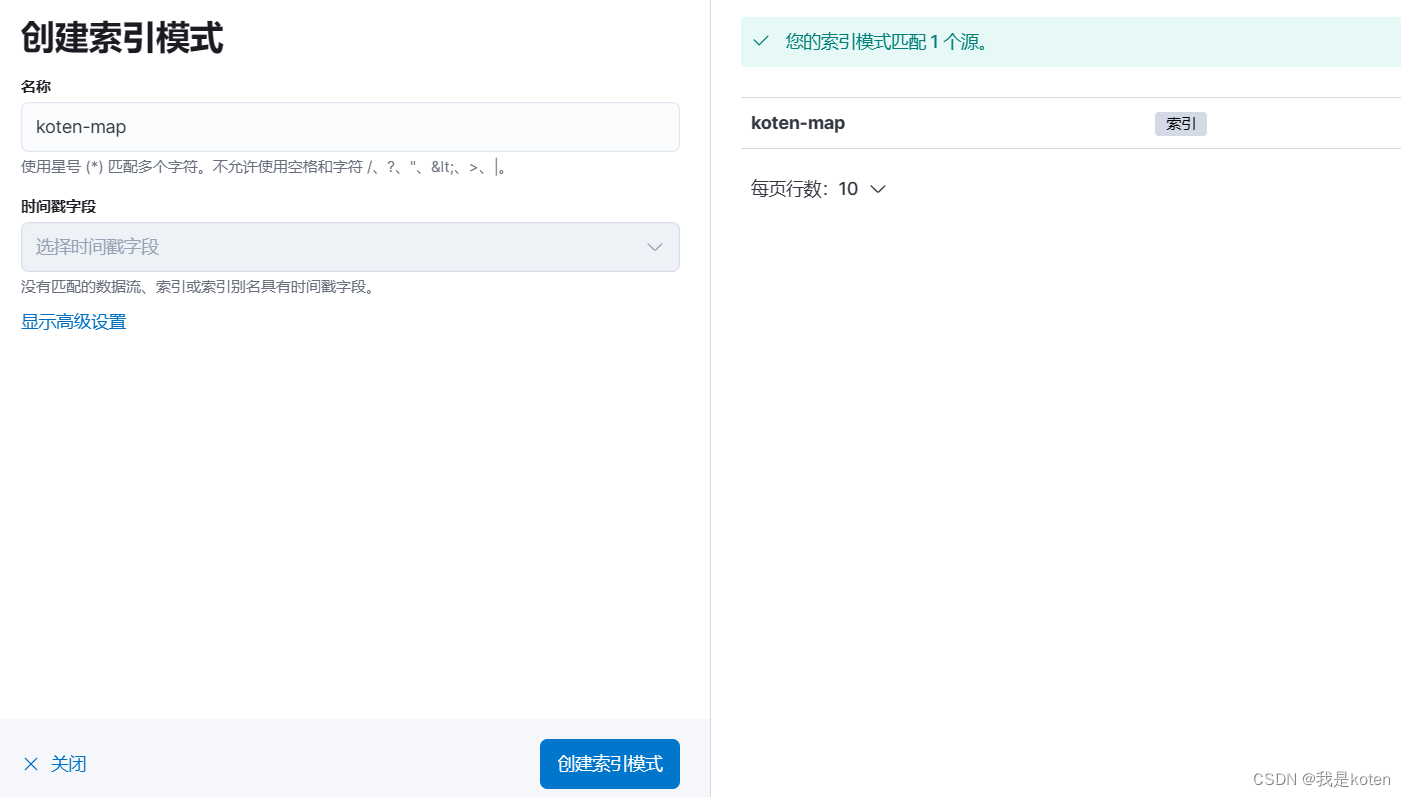
3、kibana添加地图
创建索引模式--->菜单栏 ---> Maps ---> 添加图层 ---> 文档 ---> 选择已添加的索引
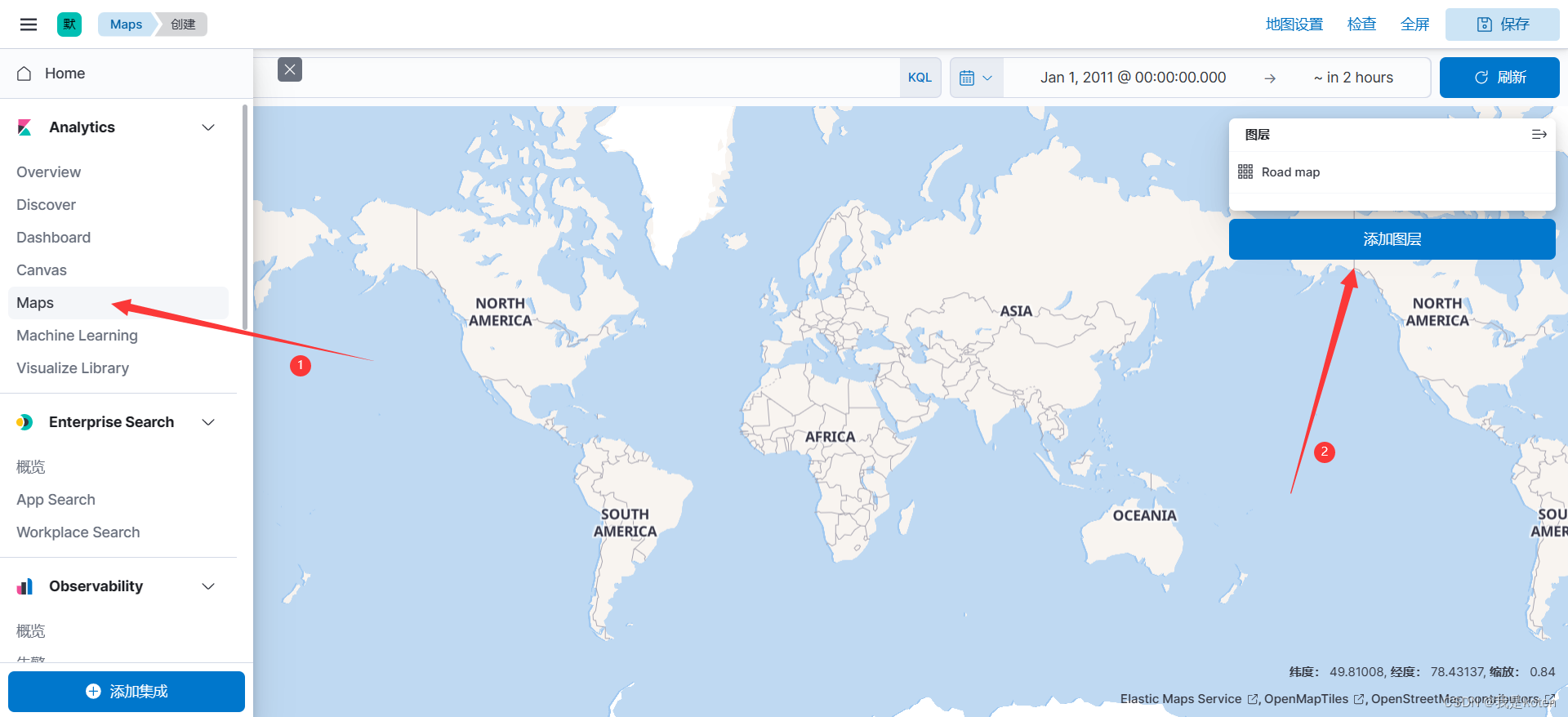
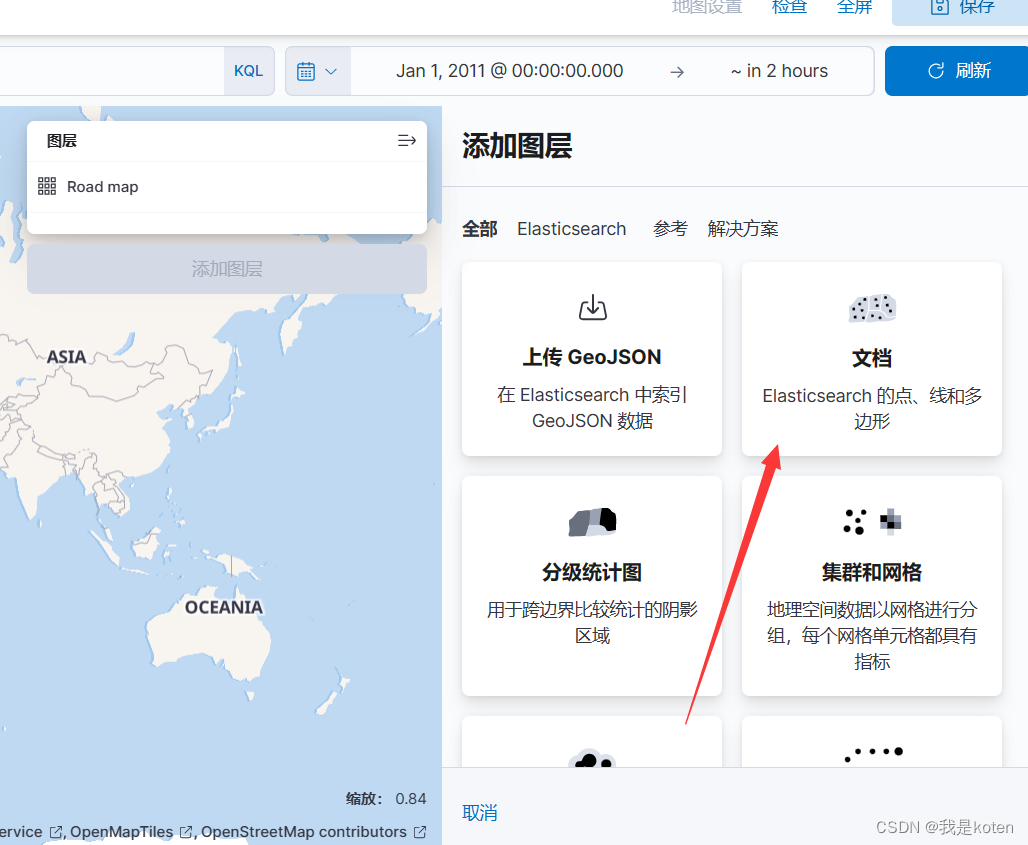

添加图形好后可以做很多图形设置,配置好后点击保存并关闭
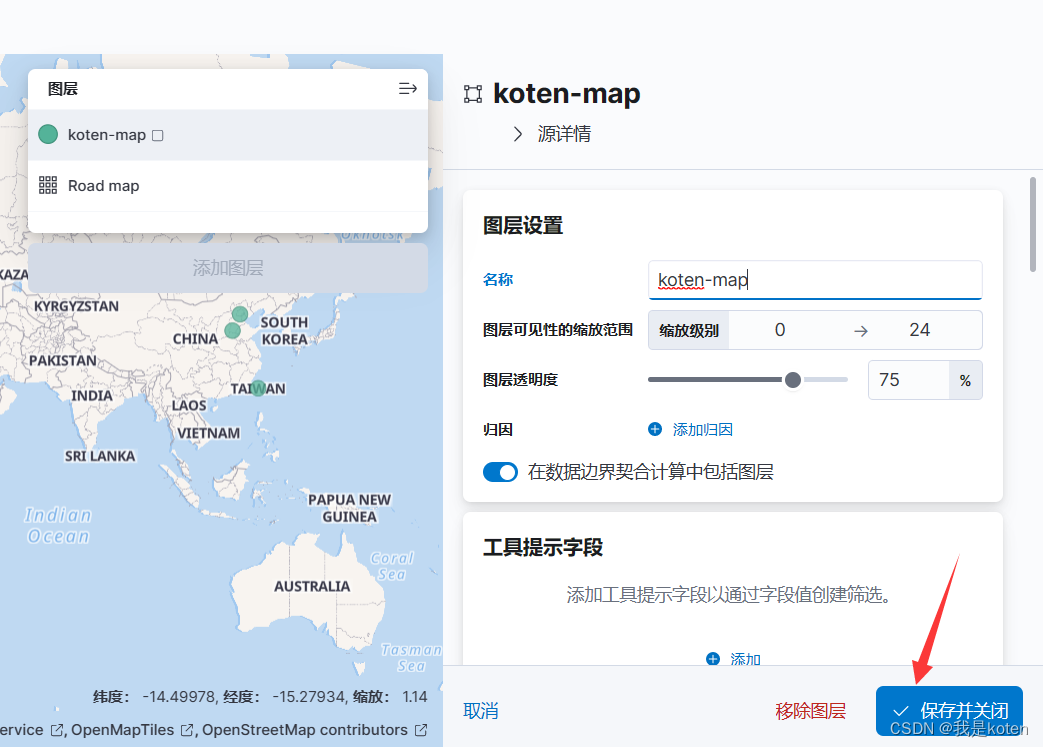
我们可以在地图上看到我们的数据所在的大概位置,数据根据经纬度显示在地图上,可以拖拽地图,可以进行缩放
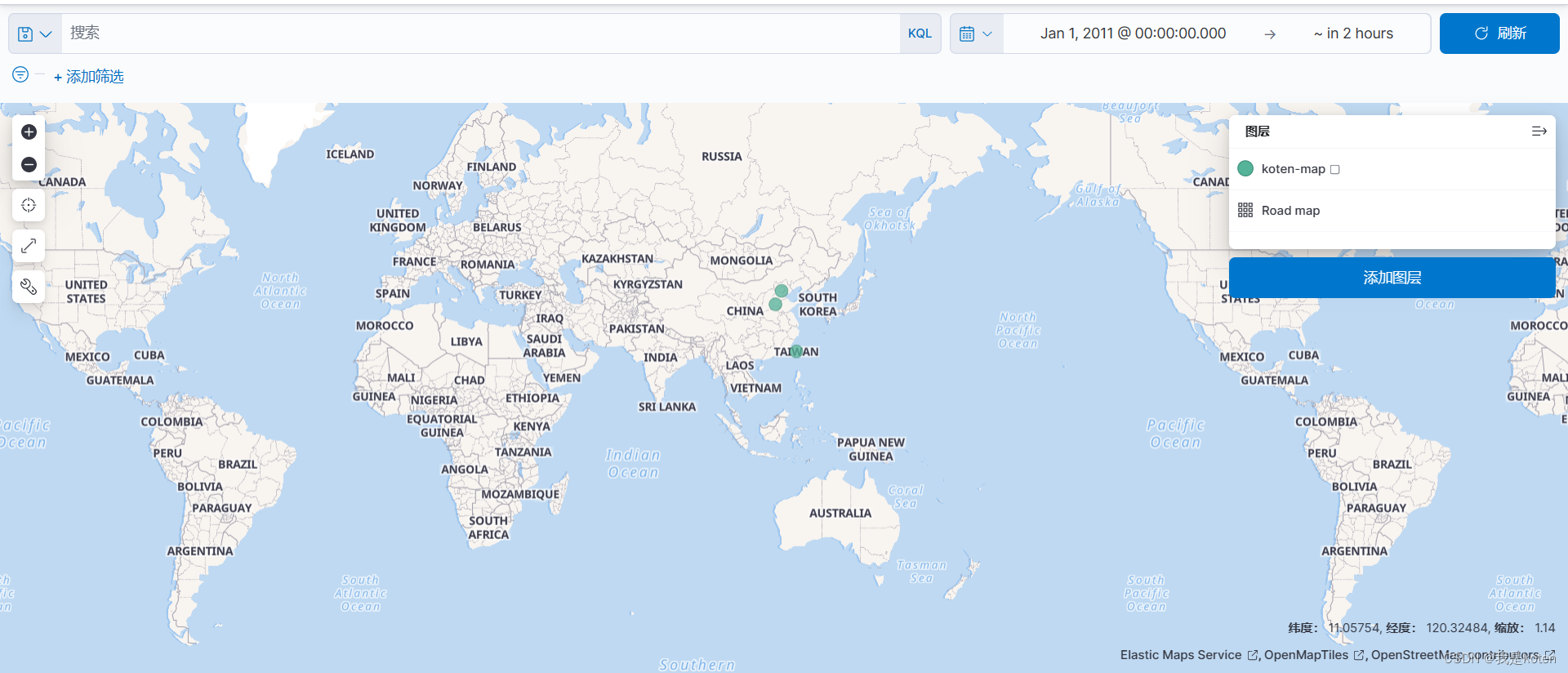
六、geoip插件分析Nginx日志
提取nginx.log中的公网ip,由logstash转成经纬度,写入ES中并在kibana中以地图形式显示
(如果跟着我的操作做的话,请先看第6步)
1、删除先前生成的索引,并删除logstash的提交记录
[root@ELK102 ~]# rm -rf /usr/share/logstash/data/plugins/inputs/file/.since*
2、编辑配置文件提交我们的nginx.log数据
[root@ELK102 ~]# cat config/09-file-filter-es.conf
input {
file {
start_position => "beginning"
path => ["/tmp/nginx.log"]
}
}
filter {
grok { #分析文本并解析提取需要的字段
match => { #匹配文本字段,可以引用内置的正则变量
"message" => "%{COMMONAPACHELOG}"
}
}
date { #解析日期的字段
match => [ #对时间进行格式化匹配并转换成ES的date字段
# "28/May/2023:16:46:15 +0800"
"timestamp", "dd/MMM/yyyy:HH:mm:ss Z"
]
#将转换后的结果存储在指定字段,若不指定,则默认覆盖@timestamp字段
target => "koten-timestamp"
}
# 分析客户端设备类型
useragent {
# 指定要分析客户端的字段
source => "message"
# 指定将分析的结果放在哪个字段中,若不指定,则放在顶级字段中。
target => "koten-agent"
}
#基于IP地址分析地理位置
geoip{
#指定基于哪个字段分析IP地理位置
source => "clientip"
}
}
output {
elasticsearch{
hosts => ["10.0.0.101:19200","10.0.0.102:19200","10.0.0.103:19300"]
index => "koten-nginx-access-%{+yyyy.MM.dd}"
}
# stdout {
# codec => rubydebug
# }
}
3、执行logstash,写入ES数据
[root@ELK102 ~]# logstash -rf config/09-file-filter-es.conf
4、创建索引模式,创建地图图层,发现索引模式不包含任何地理空间字段
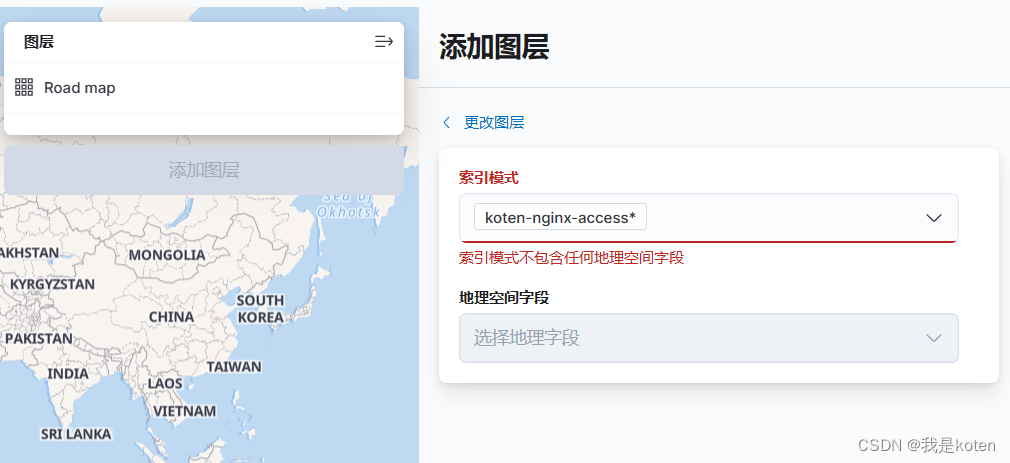
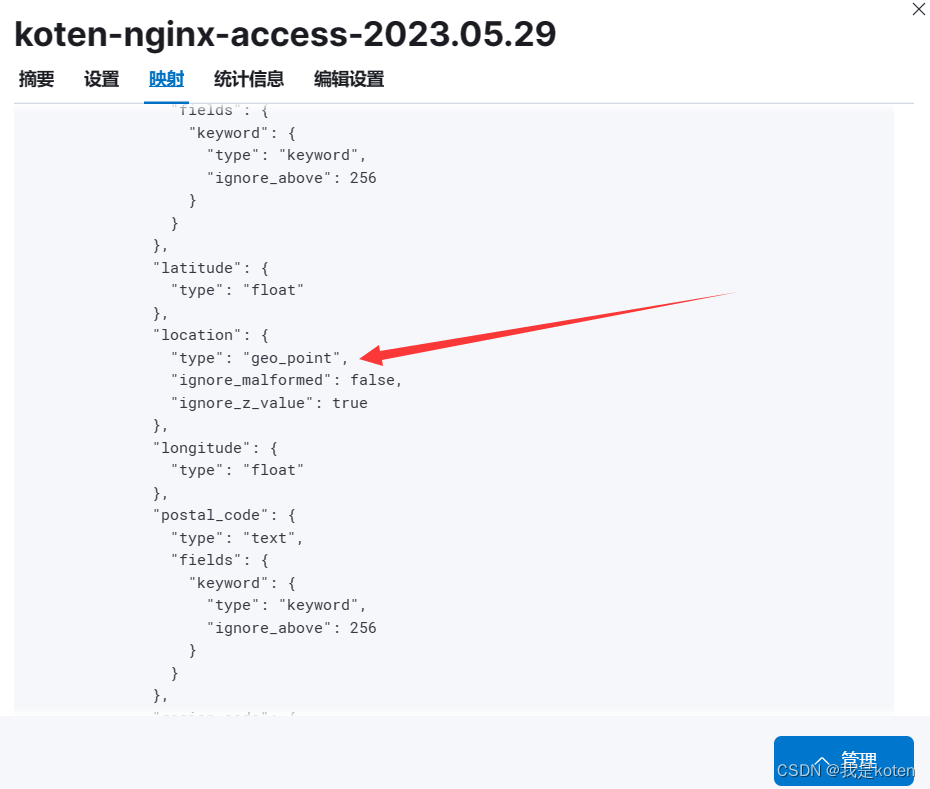
5、原因是字段类型并没有修改,解决办法是创建索引模板
location下的经纬度默认是浮点数
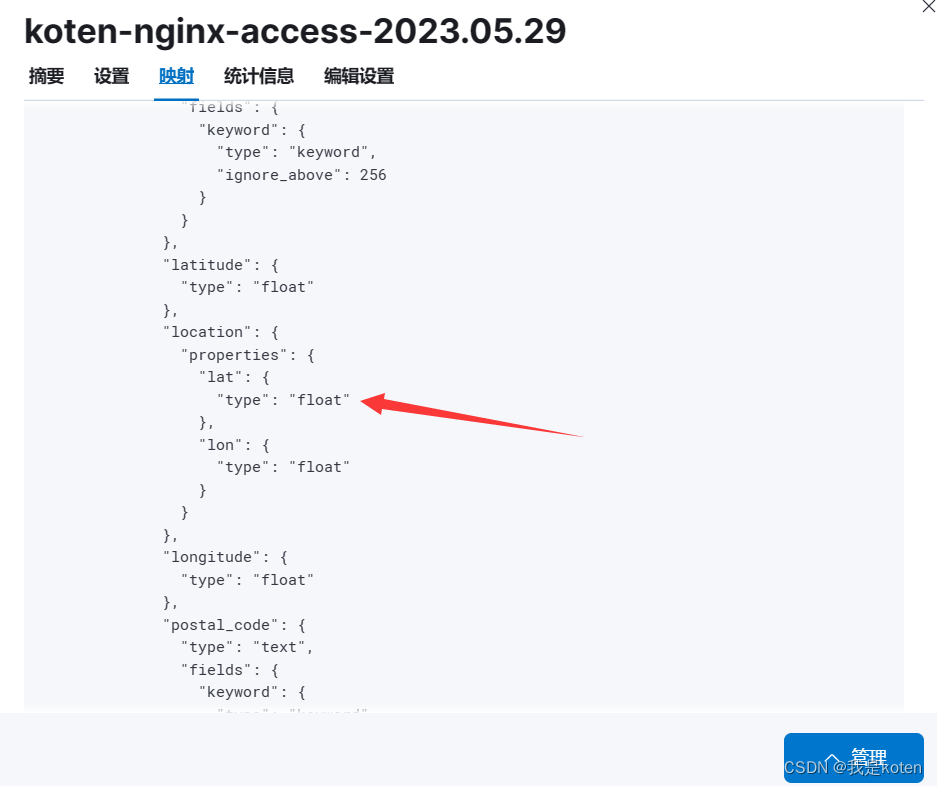
创建索引模板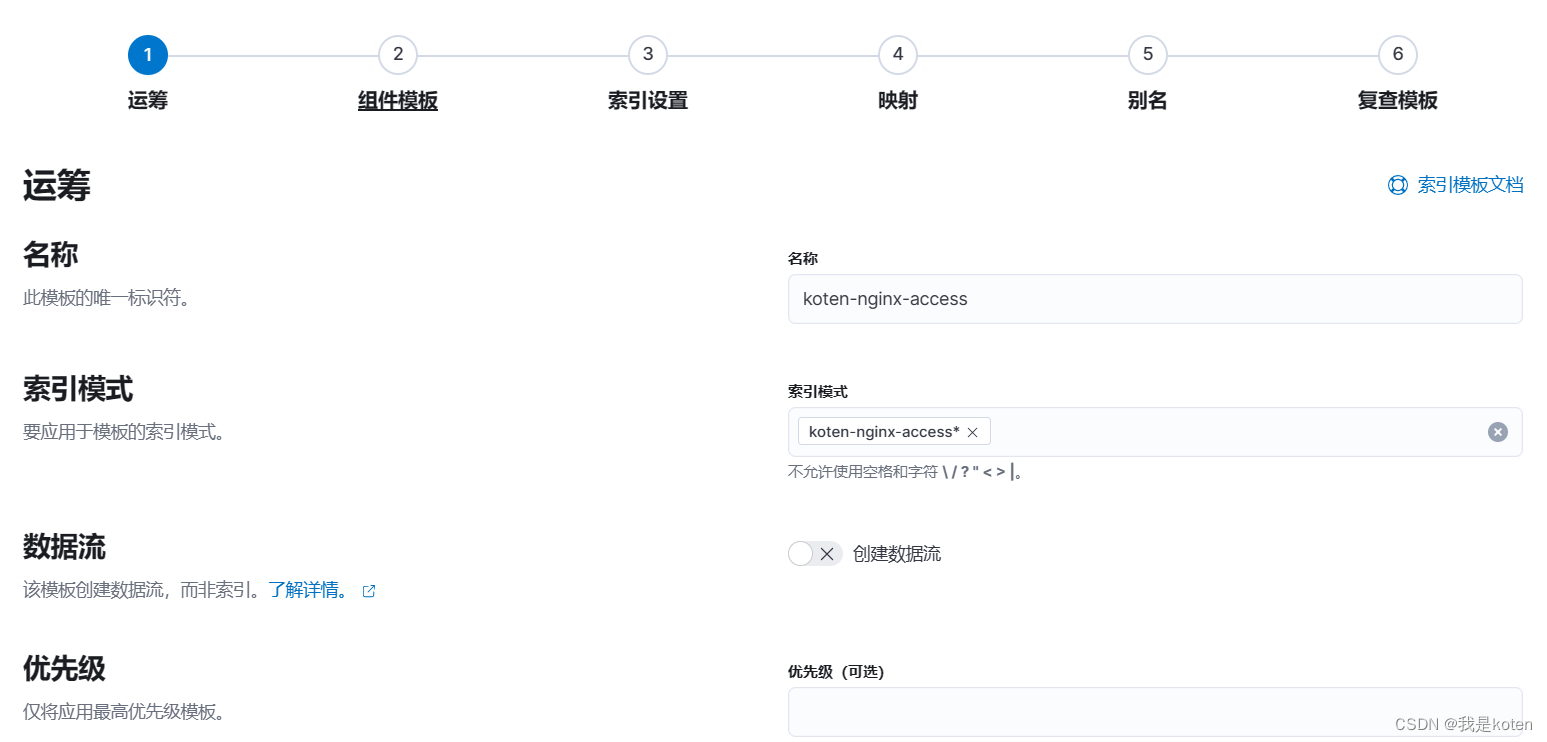
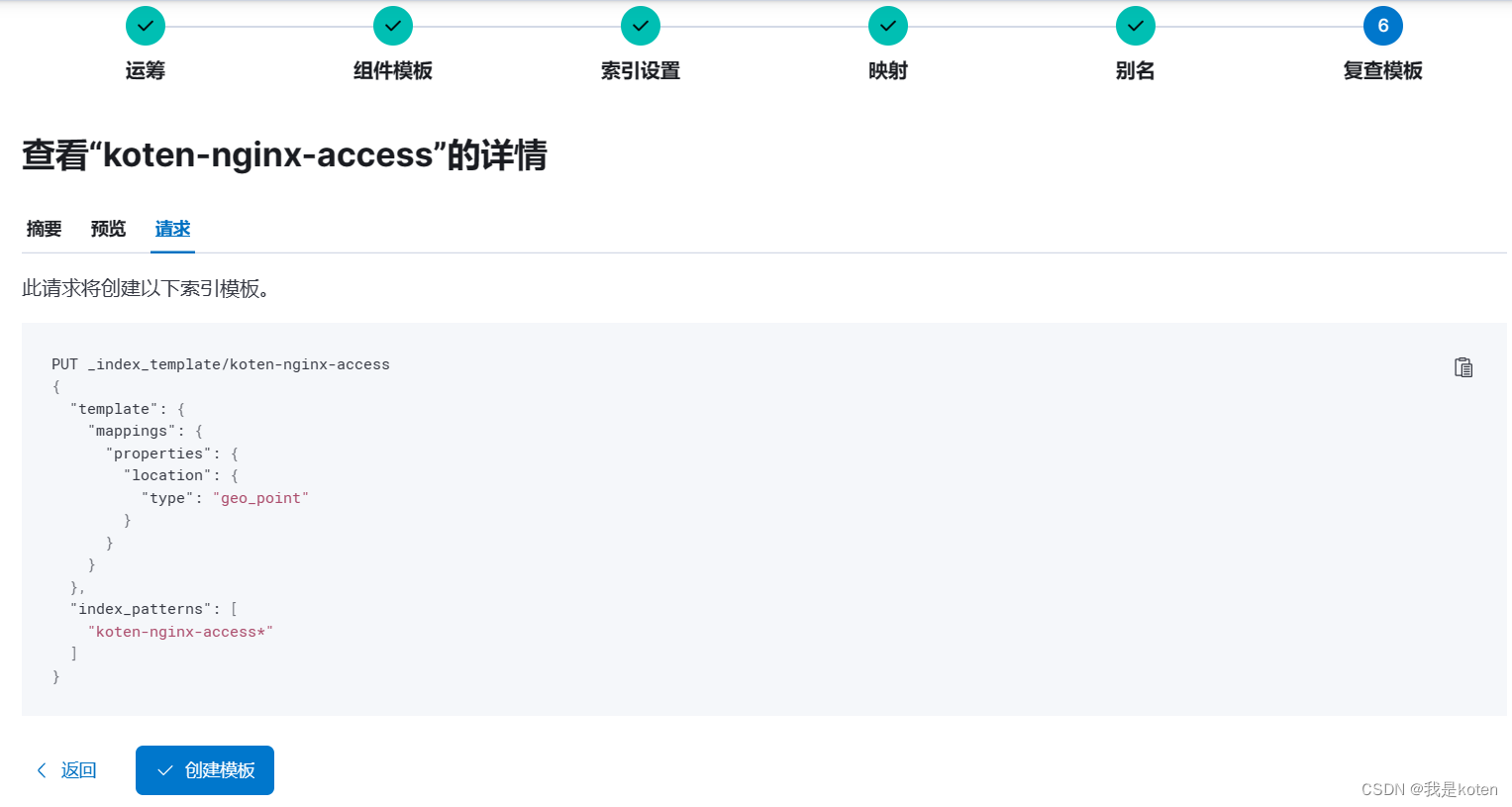
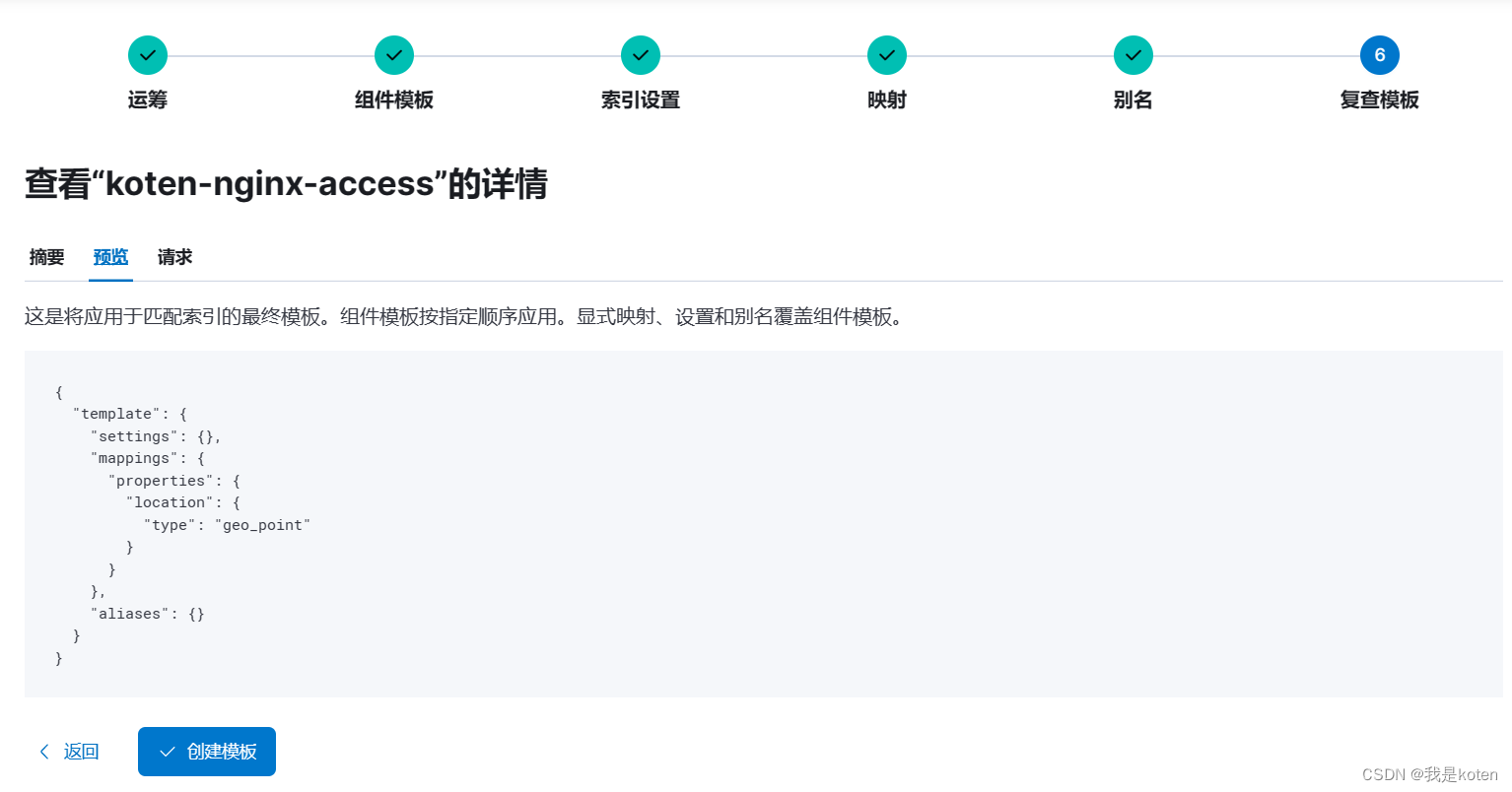
6、添加模板后重复上面删除索引,运行logstash的操作,创建索引模式,再次创建地图图层,成功将数据显示在地图上(因为索引映射一旦确定不能更改,只能删除索引重新添加)
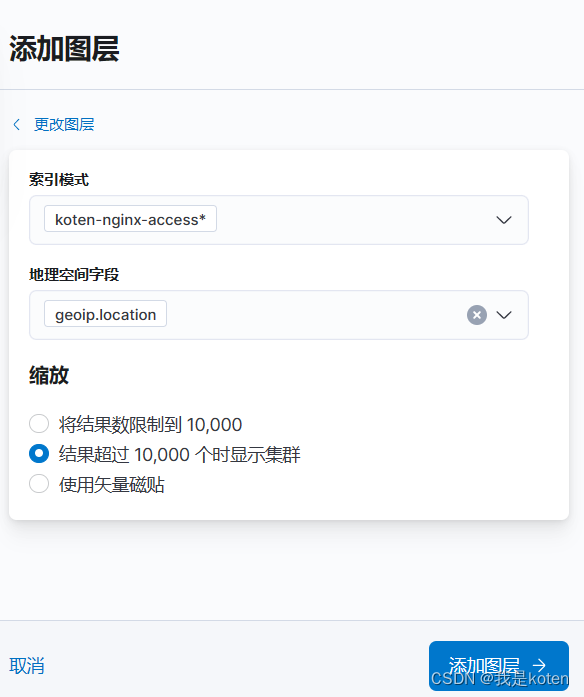

添加好图层后可以看到地图上显示了我们索引中文档的数据
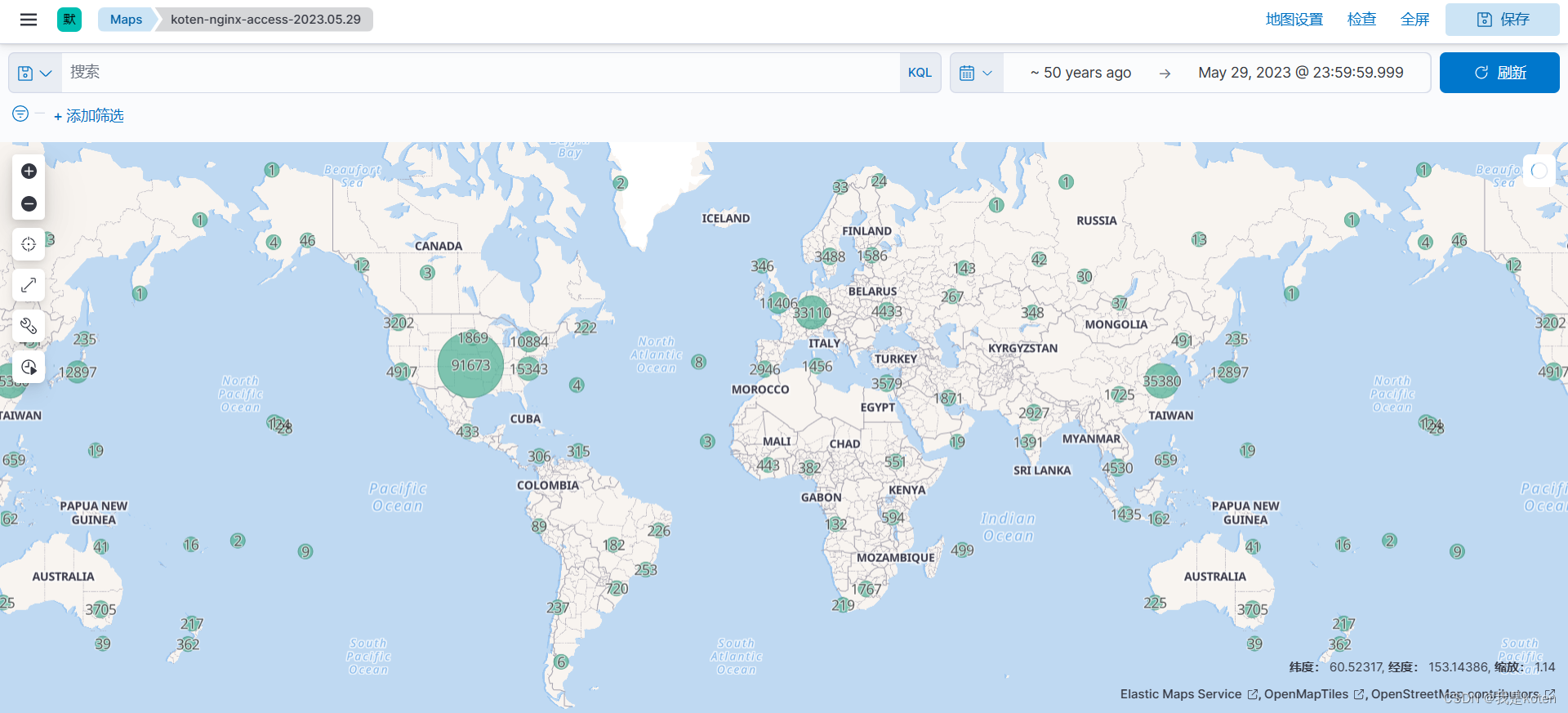
右上角可以保存地图
保存并添加到库,也可以保存到仪表板,我还没有创建就先不添加了,以后想看可以在库中随时调用出来。
七、mutate插件
参考官网链接:https://www.elastic.co/guide/en/logstash/7.17/plugins-filters-mutate.html
当我们的日志中的字段是按照指定字符分割开来时,就需要用到该插件了,mutate插件适合对字段的信息进行分割,通过分割可以很方便的定义添加字段,虽然用grok写正则表达式也可以实现匹配字段,但是写很多表达式还是很麻烦的。
1、编写生成日志的脚本,模拟公司产品的日志
cat > generate_log.py <<EOF
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import datetime
import random
import logging
import time
import sys
LOG_FORMAT = "%(levelname)s %(asctime)s [com.koten.%(module)s] - %(message)s "
DATE_FORMAT = "%Y-%m-%d %H:%M:%S"
# 配置root的logging.Logger实例的基本配置
logging.basicConfig(level=logging.INFO, format=LOG_FORMAT, datefmt=DATE_FORMAT, filename=sys.argv[1]
, filemode='a',)
actions = ["浏览页面", "评论商品", "加入收藏", "加入购物车", "提交订单", "使用优惠券", "领取优惠券",
"搜索", "查看订单", "付款", "清空购物车"]
while True:
time.sleep(random.randint(1, 5))
user_id = random.randint(1, 10000)
# 对生成的浮点数保留2位有效数字.
price = round(random.uniform(15000, 30000),2)
action = random.choice(actions)
svip = random.choice([0,1])
logging.info("DAU|{0}|{1}|{2}|{3}".format(user_id, action,svip,price))
EOF2、生成测试的日志
[root@ELK102 ~]# python generate_log.py /tmp/app.log
[root@ELK102 ~]# cat /tmp/app.log
INFO 2023-05-29 23:34:52 [com.koten.generate_log] - DAU|3849|提交订单|1|15990.11
INFO 2023-05-29 23:34:57 [com.koten.generate_log] - DAU|189|查看订单|0|26263.25
INFO 2023-05-29 23:34:58 [com.koten.generate_log] - DAU|8444|领取优惠券|0|25803.03
INFO 2023-05-29 23:35:03 [com.koten.generate_log] - DAU|5440|搜索|0|20433.35
INFO 2023-05-29 23:35:08 [com.koten.generate_log] - DAU|2913|提交订单|1|22605.35
INFO 2023-05-29 23:35:11 [com.koten.generate_log] - DAU|3708|提交订单|1|28590.17
INFO 2023-05-29 23:35:15 [com.koten.generate_log] - DAU|9296|使用优惠券|0|16057.25
INFO 2023-05-29 23:35:20 [com.koten.generate_log] - DAU|6150|评论商品|1|20976.35
INFO 2023-05-29 23:35:23 [com.koten.generate_log] - DAU|8145|提交订单|0|15477.72
INFO 2023-05-29 23:35:24 [com.koten.generate_log] - DAU|689|搜索|1|24395.35
INFO 2023-05-29 23:35:28 [com.koten.generate_log] - DAU|1439|领取优惠券|1|15574.72
......3、使用mutate组件分析日志,编辑配置文件
[root@ELK102 ~]# cat config/10-file-filter-es.conf
input {
file {
start_position => "beginning"
path => ["/tmp/app.log"]
}
}
filter {
# 对文本数据进行处理
mutate {
# 对message字段按照"|"进行切割
split => { "message" => "|" }
}
mutate {
# 添加字段
add_field => {
user_id => "%{[message][1]}"
action => "%{[message][2]}"
svip => "%{[message][3]}"
price => "%{[message][4]}"
}
}
mutate {
# 进行数据类型转换,将指定字段换成为期望的数据类型
convert => {
"user_id" => "integer"
"svip" => "boolean"
"price" => "float"
}
}
mutate {
# 对字段进行重命名
rename => { "path" => "filepath" }
}
mutate {
# 移除指定的字段
remove_field => [ "@version","message" ]
}
}
output {
elasticsearch{
hosts => ["10.0.0.101:19200","10.0.0.102:19200","10.0.0.103:19300"]
index => "koten-nginx-access-%{+yyyy.MM.dd}"
}
# stdout {
# codec => rubydebug
# }
}4、启用logstash,观察屏幕输出的日志是否按照自定义字段输出
[root@ELK102 ~]# rm -rf /usr/share/logstash/data/plugins/inputs/file/.sincedb_*
[root@ELK102 ~]# logstash -rf config/10-file-filter-es.conf 5、kibana查看数据并创建可视化
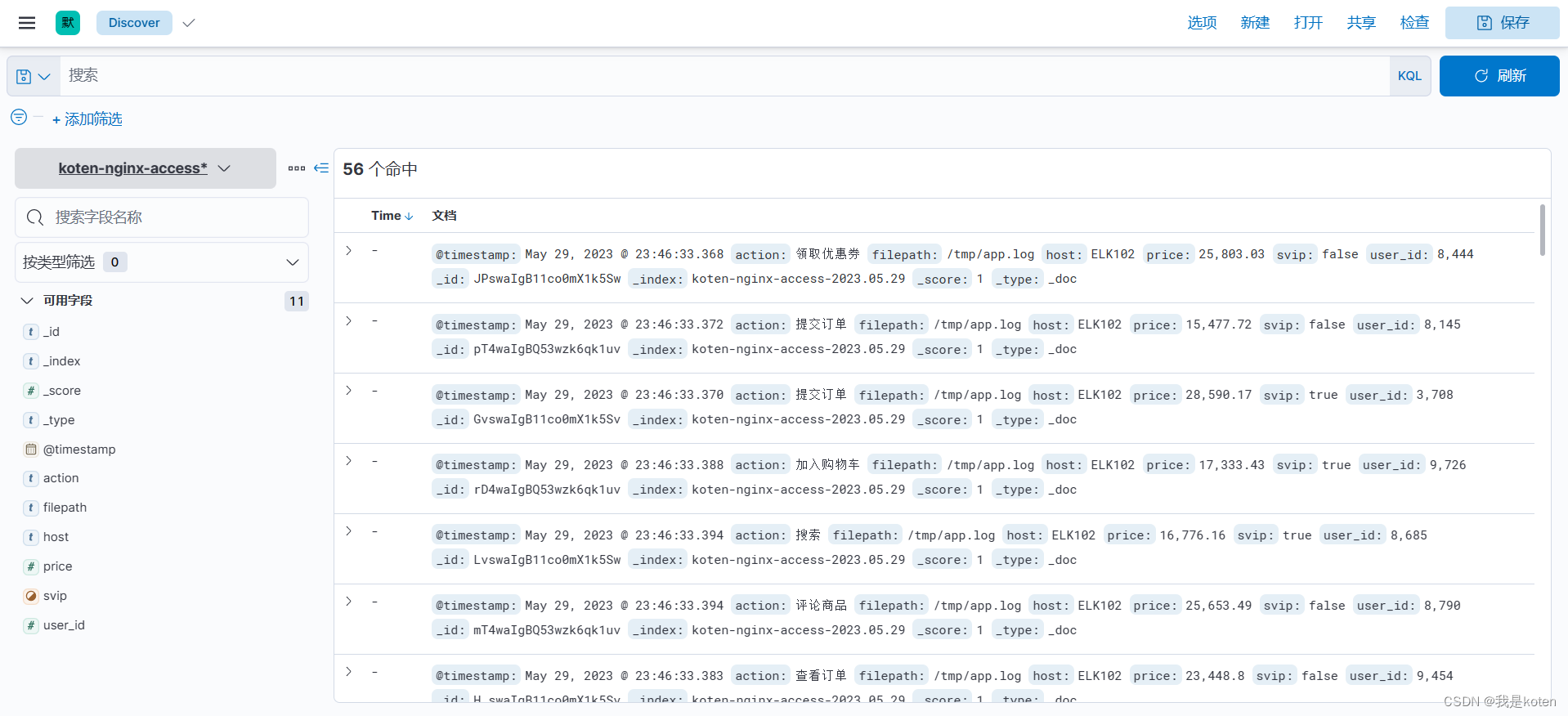
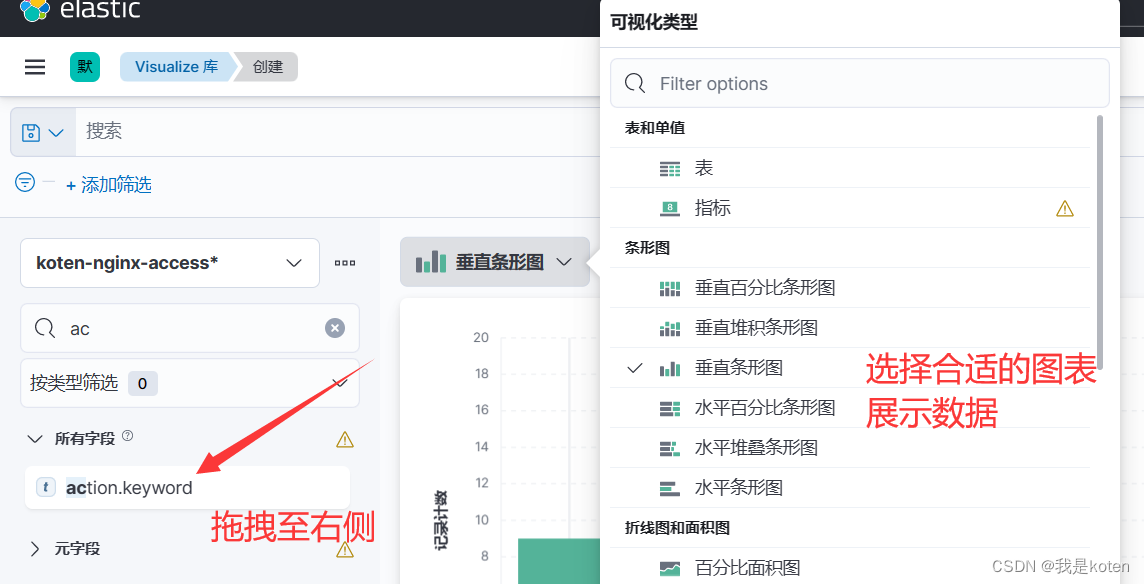
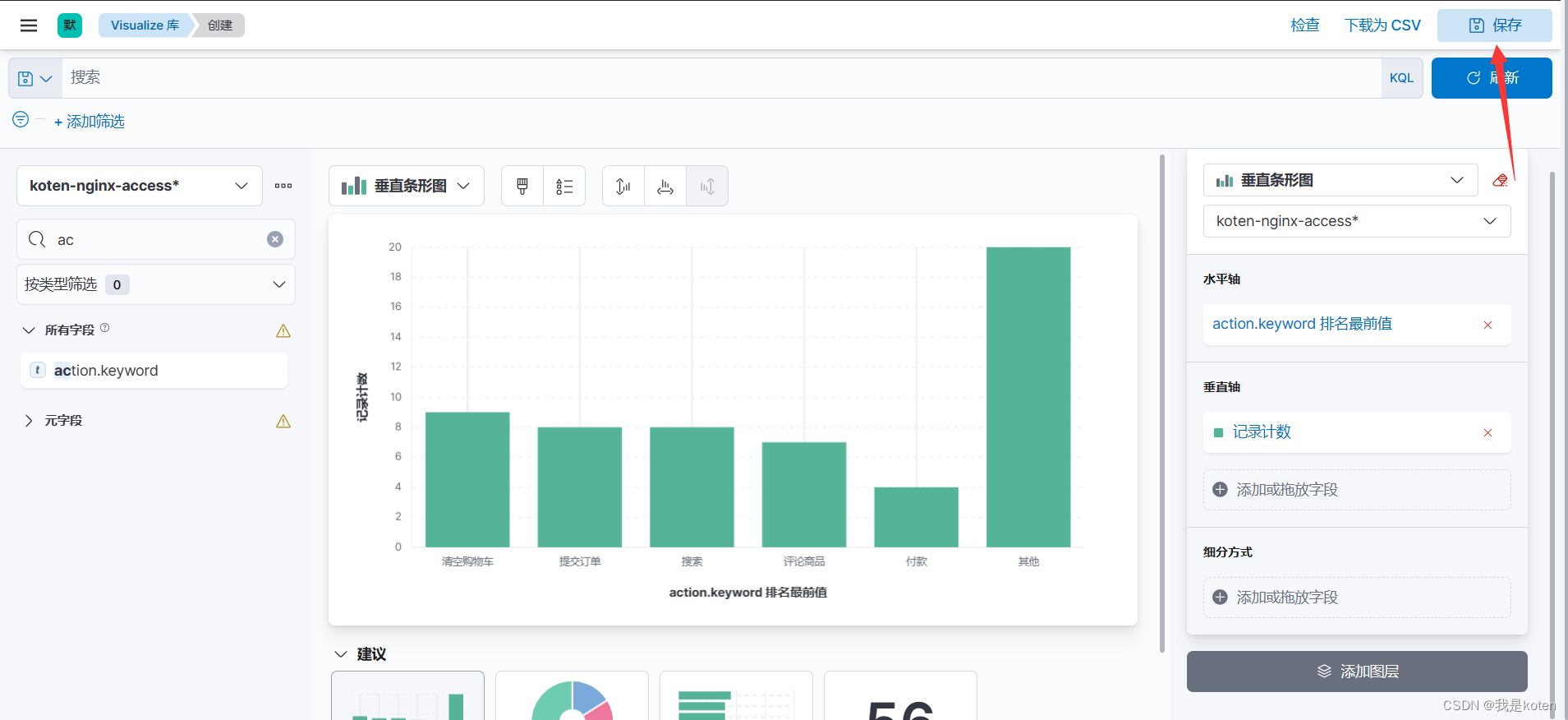
创建数据图表:菜单栏 ---> Visualize library ---> 创建可视化 ---> Lens ---> 根据字段选择即可。

创建聚合图形:菜单栏 ---> Visualize library ---> 创建可视化 ---> 基于聚合 ---> 指标(其他同理) ---> 选择索引

可以修改标签,更新显示,同样右上角可以保存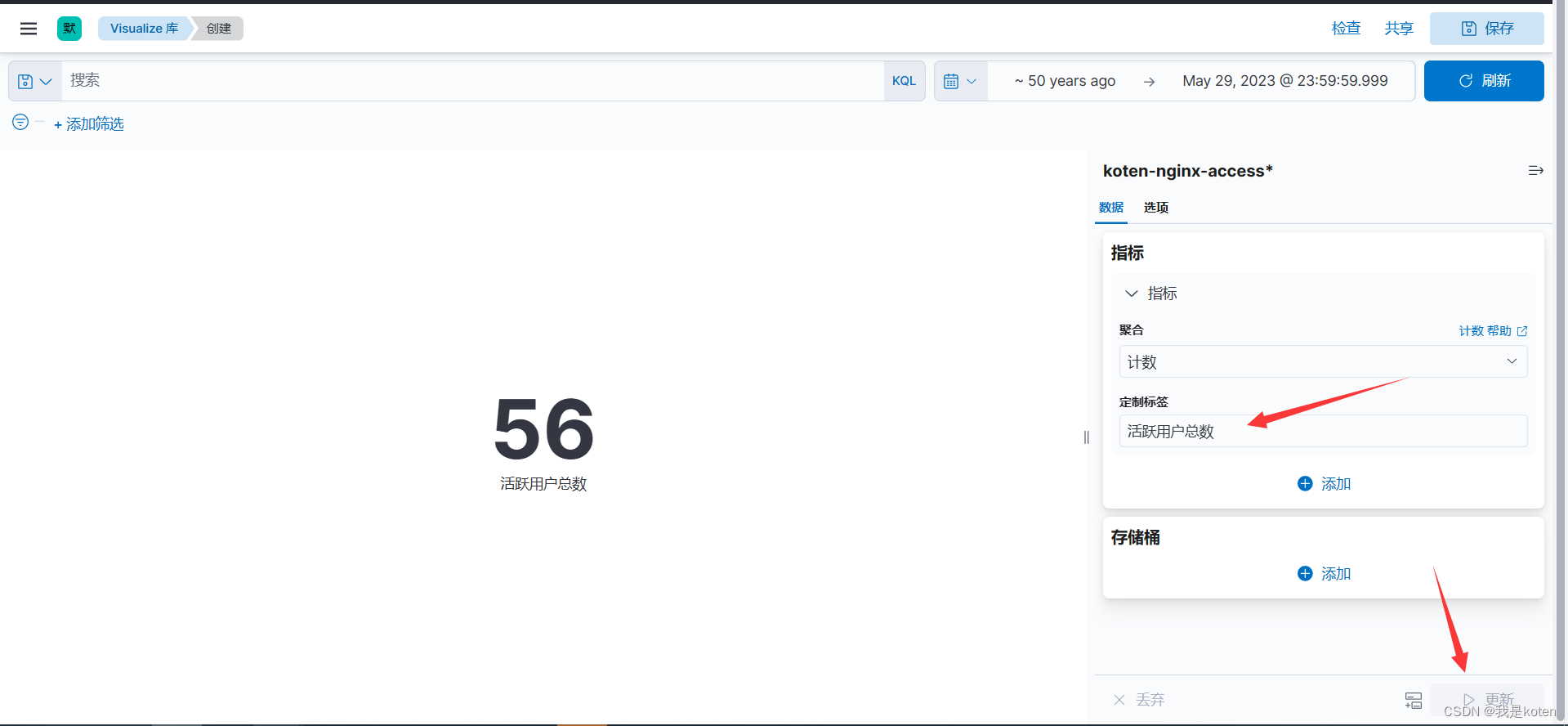
创建仪表板:Overview--->仪表板--->创建新的仪表板--->从库中添加--->保存仪表板
可以添加库中的图形
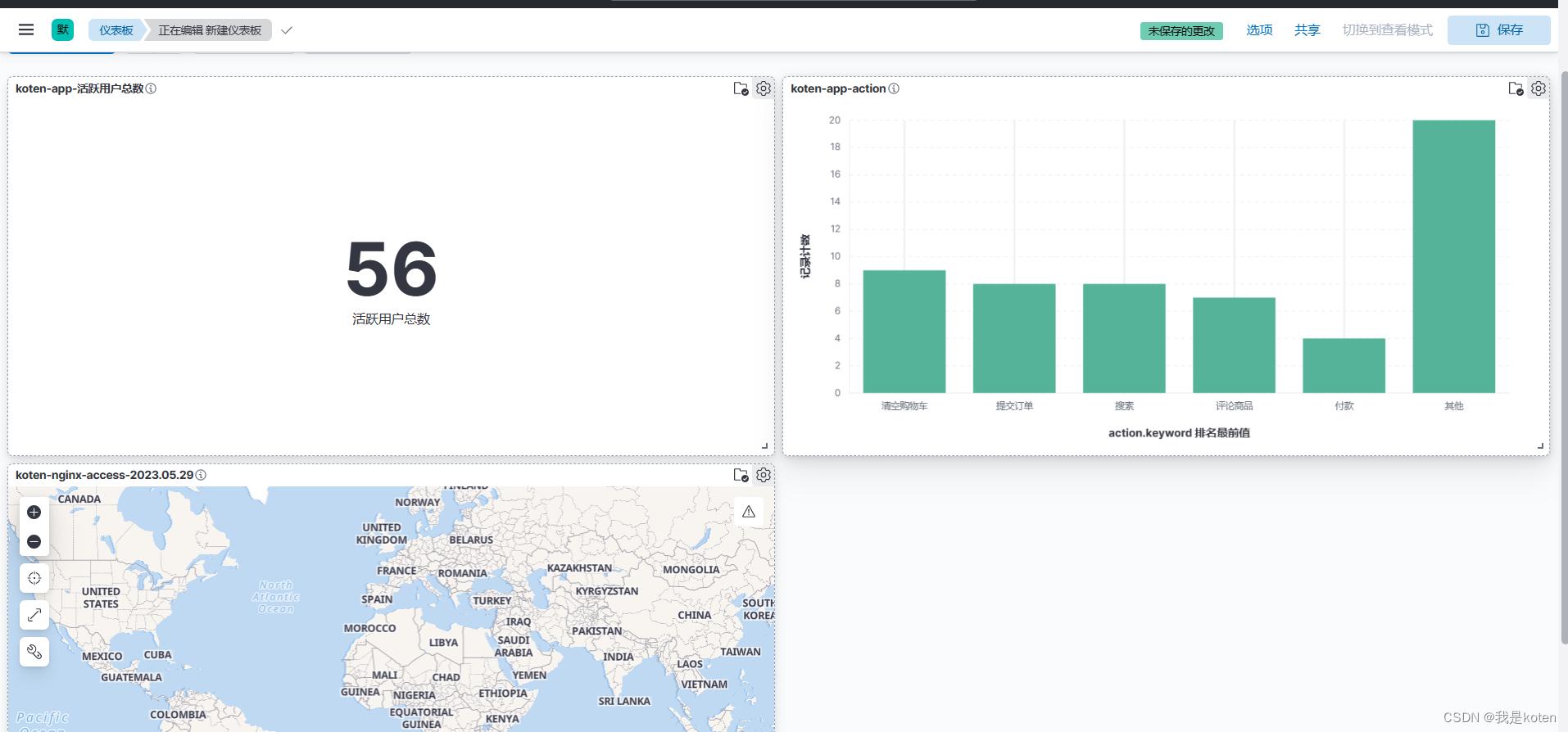
右上角保存仪表板
下次再打开Overview就显示了,可以打开直接看

八、if多分支语句
if多分支语句与--path.data一样,是多个输入多个输出的一种方式
1、准备读入文件
[root@ELK102 ~]# cat /tmp/haha.log
welcome to kotenedu linux, 2023
[root@ELK102 ~]# cat /tmp/app.log
INFO 2023-05-29 23:34:52 [com.koten.generate_log] - DAU|3849|提交订单|1|15990.11
INFO 2023-05-29 23:34:57 [com.koten.generate_log] - DAU|189|查看订单|0|26263.25
INFO 2023-05-29 23:34:58 [com.koten.generate_log] - DAU|8444|领取优惠券|0|25803.03
INFO 2023-05-29 23:35:03 [com.koten.generate_log] - DAU|5440|搜索|0|20433.35
INFO 2023-05-29 23:35:08 [com.koten.generate_log] - DAU|2913|提交订单|1|22605.35
INFO 2023-05-29 23:35:11 [com.koten.generate_log] - DAU|3708|提交订单|1|28590.17
INFO 2023-05-29 23:35:15 [com.koten.generate_log] - DAU|9296|使用优惠券|0|16057.25
INFO 2023-05-29 23:35:20 [com.koten.generate_log] - DAU|6150|评论商品|1|20976.35
INFO 2023-05-29 23:35:23 [com.koten.generate_log] - DAU|8145|提交订单|0|15477.72
INFO 2023-05-29 23:35:24 [com.koten.generate_log] - DAU|689|搜索|1|24395.35
INFO 2023-05-29 23:35:28 [com.koten.generate_log] - DAU|1439|领取优惠券|1|15574.72
......2、准备正则表达式
[root@ELK102 ~]# cat config/koten-patterns/koten-patterns
SCHOOL [a-z]{8}
SUBJECT [a-z]{5}
YEAR [\d]{4}3、编辑配置文件
[root@ELK102 ~]# cat config/11-file-filter-es.conf
input {
file {
start_position => "beginning"
path => ["/tmp/haha.log"]
type => "haha"
}
file {
start_position => "beginning"
path => ["/tmp/app.log"]
type => "app"
}
}
filter {
if [type] == "haha" {
grok {
patterns_dir => ["./koten-patterns/"]
match => {
"message" => "welcome to %{SCHOOL:school} %{SUBJECT:subject}, %{YEAR:year}"
}
}
} else if [type] == "app" {
mutate {
split => { "message" => "|" }
}
mutate {
add_field => {
user_id => "%{[message][1]}"
action => "%{[message][2]}"
svip => "%{[message][3]}"
price => "%{[message][4]}"
}
}
mutate {
convert => {
"user_id" => "integer"
"svip" => "boolean"
"price" => "float"
}
}
mutate {
rename => { "path" => "filepath" }
}
mutate {
remove_field => [ "@version","message" ]
}
}
}
output {
if [type] == "haha" {
elasticsearch {
hosts => ["10.0.0.101:19200","10.0.0.102:19200","10.0.0.103:19200"]
index => "koten-if-haha-%{+yyyy.MM.dd}"
}
} else if [type] == "app" {
elasticsearch {
hosts => ["10.0.0.101:19200","10.0.0.102:19200","10.0.0.103:19200"]
index => "koten-if-app-%{+yyyy.MM.dd}"
}
}
stdout {
codec => rubydebug
}
}4、运行logstash,可以观察到两者输入输出的区别,更名的字段等等
[root@ELK102 ~]# rm -rf /usr/share/logstash/data/plugins/inputs/file/.sinced*
[root@ELK102 ~]# logstash -rf config/11-file-filter-es.conf
......
{
"type" => "app",
"filepath" => "/tmp/app.log",
"user_id" => 9389,
"svip" => false,
"host" => "ELK102",
"@timestamp" => 2023-05-29T16:31:25.353Z,
"price" => 26972.71,
"action" => "付款"
}
{
"path" => "/tmp/haha.log",
"type" => "haha",
"subject" => "linux",
"@version" => "1",
"host" => "ELK102",
"year" => "2023",
"@timestamp" => 2023-05-29T16:31:25.240Z,
"message" => "welcome to kotenedu linux, 2023",
"school" => "kotenedu"
}
......
Logstash常用filter插件总结
1、grok:正则匹配任意文本
2、date:处理时间字段
3、user_agent:分析客户端设备
4、geoip:分析客户端IP地理位置
5、mutate:对字符串文本进行处理,转换,字母大小写,切分,重命名,添加字段,删除字段
运行多个输入和输出的方案:
多实例:需要单独指定数据路径,--data.path
if分支语句:
if [type] == "xxx" {
} else if [type] == "xxx" {
} else {
}
pipline:logstash运行时默认就有一个main pipline
我是koten,10年运维经验,持续分享运维干货,感谢大家的阅读和关注!