提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
前言
1. 链表的概念及结构
2. 单链表的实现
2.1单链表头文件——功能函数的定义
2.2单链表源文件——功能函数的实现
2.3 单链表源文件——功能的测试
3.具体的理解操作图
4. 链表的分类
总结
前言
世上有两种耀眼的光芒,一种是正在升起的太阳,一种是正在努力学习编程的你!一个爱学编程的人。各位看官,我衷心的希望这篇博客能对你们有所帮助,同时也希望各位看官能对我的文章给与点评,希望我们能够携手共同促进进步,在编程的道路上越走越远!
提示:以下是本篇文章正文内容,下面案例可供参考
1. 链表的概念及结构
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表 中的指针链接次序实现的 。
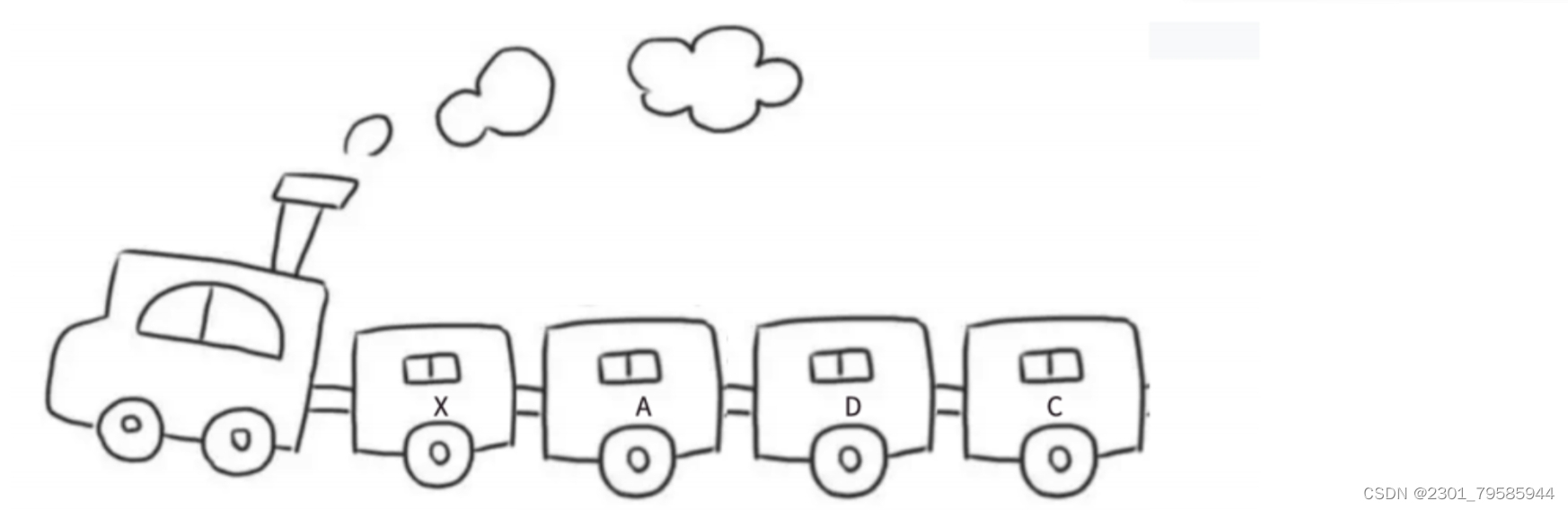

链表的结构跟火车车厢相似,淡季时车次的车厢会相应减少,旺季时车次的车厢会额外增加几节。只需要将火车里的某节车厢去掉/加上,不会影响其他车厢,每节车厢都是独立存在的。
车厢是独立存在的,且每节车厢都有车门。想象一下这样的场景,假设每节车厢的车门都是锁上的状态,需要不同的钥匙才能解锁,每次只能携带一把钥匙的情况下如何从车头走到车尾?
最简单的做法:每节车厢里都放一把下一节车厢的钥匙。
在链表里,每节“车厢”是什么样的呢?

与顺序表不同的是,链表里的每节"车厢"都是独立申请下来的空间,我们称之为“结点/节点”
节点的组成主要有两个部分:当前节点要保存的数据和保存下一个节点的地址(指针变量)。
图中指针变量 plist保存的是第一个节点的地址,我们称plist此时“指向”第一个节点,如果我们希望plist“指向”第二个节点时,只需要修改plist保存的内容为0x0012FFA0。
为什么还需要指针变量来保存下一个节点的位置?
链表中每个节点都是独立申请的(即需要插入数据时才去申请一块节点的空间),我们需要通过指针变量来保存下一个节点位置才能从当前节点找到下一个节点。
结合前面学到的结构体知识,我们可以给出每个节点对应的结构体代码:
假设当前保存的节点为整型:
struct SListNode
{
int data; //节点数据
struct SListNode* next; //指针变量⽤保存下⼀个节点的地址
};当我们想要保存一个整型数据时,实际是向操作系统申请了一块内存,这个内存不仅要保存整型数 据,也需要保存下一个节点的地址(当下一个节点为空时保存的地址为空)。
当我们想要从第一个节点走到最后一个节点时,只需要在前一个节点拿上下一个节点的地址(下一个节点的钥匙)就可以了。
给定的链表结构中,如何实现节点从头到尾的打印?

思考:当我们想保存的数据类型为字符型、浮点型或者其他自定义的类型时,该如何修改?
补充说明:
1、链式机构在逻辑上是连续的,在物理结构上不一定连续
2、节点一般是从堆上申请的
3、从堆上申请来的空间,是按照一定策略分配出来的,每次申请的空间可能连续,可能不连续
顺序表的缺点:
1:顺序表需要申请的空间是连续的,可能造成程序的消耗;
2:扩容存在一定的空间浪费。
2. 单链表的实现
2.1单链表头文件——功能函数的定义
Slist.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <stdbool.h>
//定义链表节点的结构:
typedef int SLDatatype;
typedef struct SlistNode
{
SLDatatype data;//这个节点(结构体)内的数据
struct SlistNode* next;//存放的是下一个节点(结构体)的地址
}SLNode;
//我们来创建几个节点组成一个链表,并打印链表
//phead:第一个节点的地址
void SLprint(SLNode* phead);
//尾插
void SLPushBack(SLNode** pphead, SLDatatype x);
//头插
void SLPushFront(SLNode** pphead, SLDatatype x);
//尾删
void SLPopBack(SLNode** pphead);
//头删
void SLPopFront(SLNode** pphead);
//找节点,这里的第一个参数是一级指针还是二级指针
//这里穿一级指针实际就可以了,因为不改变节点
//但是这里要写二级指针,因为要保持接口的一致性
SLNode* SLFind(SLNode** pphead, SLDatatype x);
//在指定位置之前插入数据
void SLInsert(SLNode** pphead, SLNode* pos, SLDatatype x);
//在指定位置之后插入数据
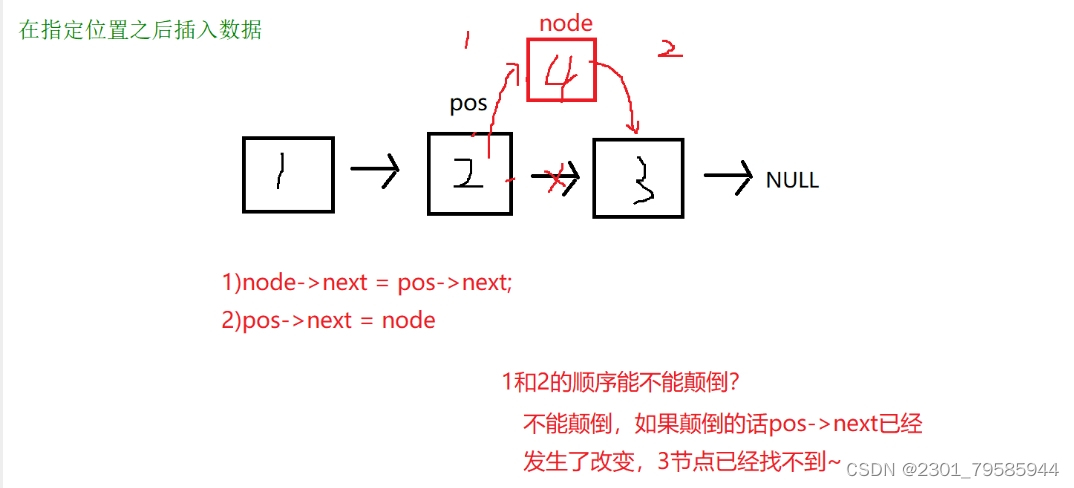
void SLInsertAfter(SLNode* pos, SLDatatype x);
//删除pos节点
void SLErase(SLNode** pphead, SLNode* pos);
//删除pos节点之后
void SLEraseAfter(SLNode* pos);
//链表的销毁
void SLDesTroy(SLNode** pphead);2.2单链表源文件——功能函数的实现
Slist.c
#define _CRT_SECURE_NO_WARNINGS 1
#include "Slist.h"
//顺序表在逻辑上是线性的,在物理空间上也是线性的,顺序表中的数据都是连续的
//链表在逻辑结构上是线性的,在物理空间上不是线性的,链表中的数据不是连续的
//一个节点中存放两个东西:1:存储的数据;2:下一个节点的地址
链表节点的结构:
//struct SlistNode
//{
// int data;//这个节点(结构体)内的数据
// struct SlistNode* next;//存放的是下一个节点(结构体)的地址
//};
void SLprint(SLNode* phead)//phead:是形参,指向第一个节点的地址
{
//循环打印
//可以使用phead直接来访问,但是注意,当代码走到
//第27行的时候,此时的phead就是NULL了,
//若代码没有写完,我们还要继续使用指向第一个节点的地址时,
//这时我们就找不到第一个节点的地址了
SLNode* pcur = phead;//申请一个变量,用来存放第一个节点的地址
while (pcur != NULL)
{
printf("%d ->", pcur->data);
pcur = pcur->next;//pcur:是第一个节点的地址,在节点中找到下一个节点的地址,赋值给pcur
}
printf("NULL\n");
}
//申请新节点插入数据
SLNode* SLBuyNode(SLDatatype x)
{
SLNode* node = (SLNode*)malloc(sizeof(SLNode));
node->data = x;
node->next = NULL;
return node;
}
//尾插
void SLPushBack(SLNode** pphead, SLDatatype x)
{
//对指针加以限制
assert(pphead);//传过来的指针不能为空
SLNode* node = SLBuyNode(x);
if (*pphead == NULL)
{
*pphead = node;
return;
}
//当链表不为空时,找尾
SLNode* pcur = *pphead;
while (pcur->next)
{
pcur = pcur->next;
}
pcur->next = node;
}
//头插
void SLPushFront(SLNode** pphead, SLDatatype x)
{
assert(pphead);
//链表为空和不为空的代码是一样的
SLNode* node = SLBuyNode(x);
//让新节点跟头节点连接起来
node->next = *pphead;//*pphead:第一个节点的地址
//让新的节点成为头节点
*pphead = node;
}
//尾删
void SLPopBack(SLNode** pphead)
{
assert(pphead);
//第一个节点不能为空(链表为空,不能尾删)
assert(*pphead);
//只有一个节点的情况下
if ((*pphead)->next == NULL)
{
//直接把头节点删除
free(*pphead);
*pphead = NULL;
}
else
{
//有多个节点的情况下
//找到尾节点和尾节点的前一个节点
SLNode* prev = NULL;
SLNode* ptail = *pphead;//第一个节点的地址
while (ptail->next != NULL)
{
prev = ptail;
ptail = ptail->next;
//当ptail->next == NULL的时候,prev刚好是尾节点的前一个节点
}
//prev的next指针不在指向ptail,而是指向ptail的下一个节点
prev->next = ptail->next;//next指向NULL
free(ptail);
//为什么必须要置为空?代码后面明明没有在使用ptail?
ptail = NULL;
//因为打印的时候会判断地址是否为空,如果不置为空,那么会造成非法访问
}
}
//头删
void SLPopFront(SLNode** pphead)
{
assert(pphead);
assert(*pphead);
//无论是一个节点或者是多个节点都是可以的
SLNode* del = *pphead;//第一个节点的地址
*pphead = (*pphead)->next;//->的优先级高于*
free(del);
del = NULL;//出于代码规范的写法
}
//查找第一个为x的节点
SLNode* SLFind(SLNode** pphead, SLDatatype x)
{
assert(pphead);
SLNode* pcur = *pphead;
while (pcur)
{
if (pcur->data == x)
{
return pcur;
}
pcur = pcur->next;
}
return NULL;
}
//在指定位置之前插入数据
void SLInsert(SLNode** pphead, SLNode* pos, SLDatatype x)
{
assert(pphead);
//我们约定链表不能为空,pos也不能为空(链表为空,pos也绝对为空)
assert(*pphead);
assert(pos);
SLNode* node = SLBuyNode(x);
//只有一个节点的情况下(pos必须指向第一个节点的位置)
//pos刚好是头节点,头插
if ((*pphead)->next == NULL || pos == *pphead)
{
node->next = *pphead;
*pphead = node;
return;
}
//找pos的前一个节点
SLNode* prev = *pphead;
while (prev->next != pos)//第一次循环的时候(缺少pos刚好是第一个节点的位置)
{
prev = prev->next;
}
prev->next = node;
node->next = pos;
}
//在指定位置之后插入数据
void SLInsertAfter(SLNode* pos, SLDatatype x)
{
assert(pos);
SLNode* node = SLBuyNode(x);
node->next = pos->next;
pos->next = node;
}
//删除pos节点
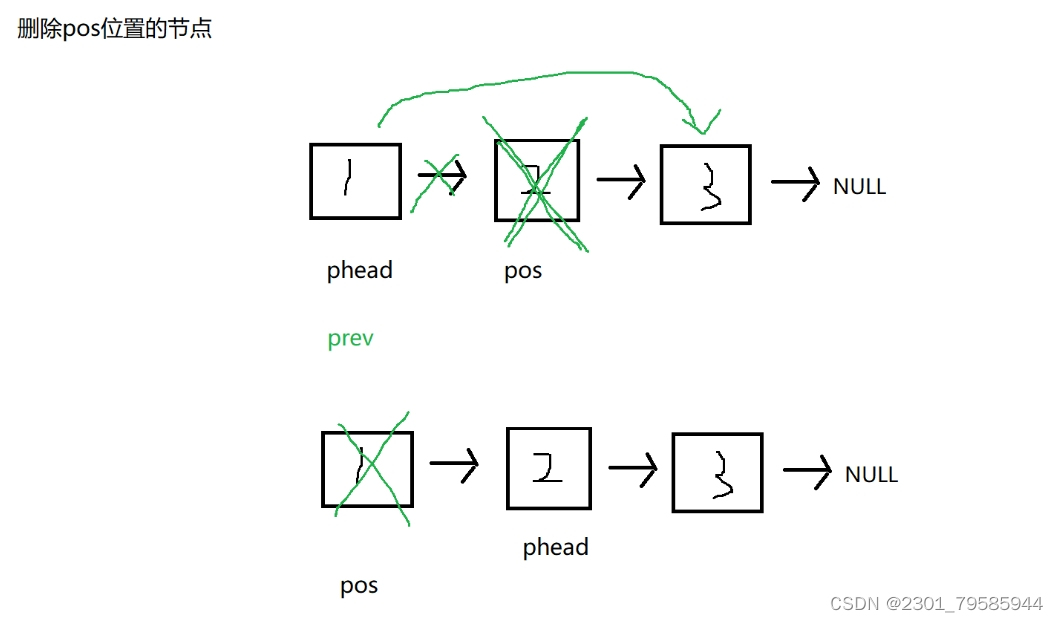
void SLErase(SLNode** pphead, SLNode* pos)
{
assert(pphead);
assert(*pphead);
assert(pos);
//pos刚好是头节点
if (pos == *pphead)
{
*pphead = (*pphead)->next;
free(pos);
pos = NULL;
return;
}
//当pos不是头节点,找pos的前一个节点
SLNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
pos = NULL;//只是规范
}
//删除pos节点之后
void SLEraseAfter(SLNode* pos)
{
//pos节点不能为空,pos之后的节点不能为空
assert(pos && pos->next);
SLNode* del = pos->next;
pos->next = del->next;
free(del);
del = NULL;
}
//链表的销毁
void SLDesTroy(SLNode** pphead)
{
assert(pphead);
SLNode* pcur = *pphead;
//循环删除
while (pcur)
{
SLNode* next = pcur->next;
free(pcur);
pcur = next;
}
*pphead = NULL;
}2.3 单链表源文件——功能的测试
test.c
#define _CRT_SECURE_NO_WARNINGS 1
#include "Slist.h"
void slttest()
{
SLNode* node1 = (SLNode*)malloc(sizeof(SLNode));
node1->data = 1;
SLNode* node2 = (SLNode*)malloc(sizeof(SLNode));
node2->data = 2;
SLNode* node3 = (SLNode*)malloc(sizeof(SLNode));
node3->data = 3;
SLNode* node4 = (SLNode*)malloc(sizeof(SLNode));
node4->data = 4;
node1->next = node2;
node2->next = node3;
node3->next = node4;
node4->next = NULL;
//打印链表
SLNode* plist = node1;
SLprint(plist);
}
//检查一下写的代码是否正确
void slttest01()
{
//plist:是第一个节点的地址
SLNode* plist = NULL;
//尾插
SLPushBack(&plist, 1);
SLPushBack(&plist, 2);
SLPushBack(&plist, 3);
SLPushBack(&plist, 4);
SLprint(plist);
//尾删
//SLPopBack(&plist);
//SLPopBack(&plist);
//SLPopBack(&plist);
//SLPopBack(&plist);
//SLprint(plist);
头删
//SLPopFront(&plist);
//SLPopFront(&plist);
//SLPopFront(&plist);
//SLPopFront(&plist);
//SLNode* find = SLFind(&plist, 2);
//SLInsert(&plist, find, 11);
//SLInsertAfter(find, 100);
SLDesTroy(&plist);
SLprint(plist);
}
int main()
{
//slttest();
slttest01();
return 0;
}3.具体的理解操作图








4. 链表的分类
链表的结构非常多样,以下情况组合起来就有8种(2 x 2 x 2)链表结构:
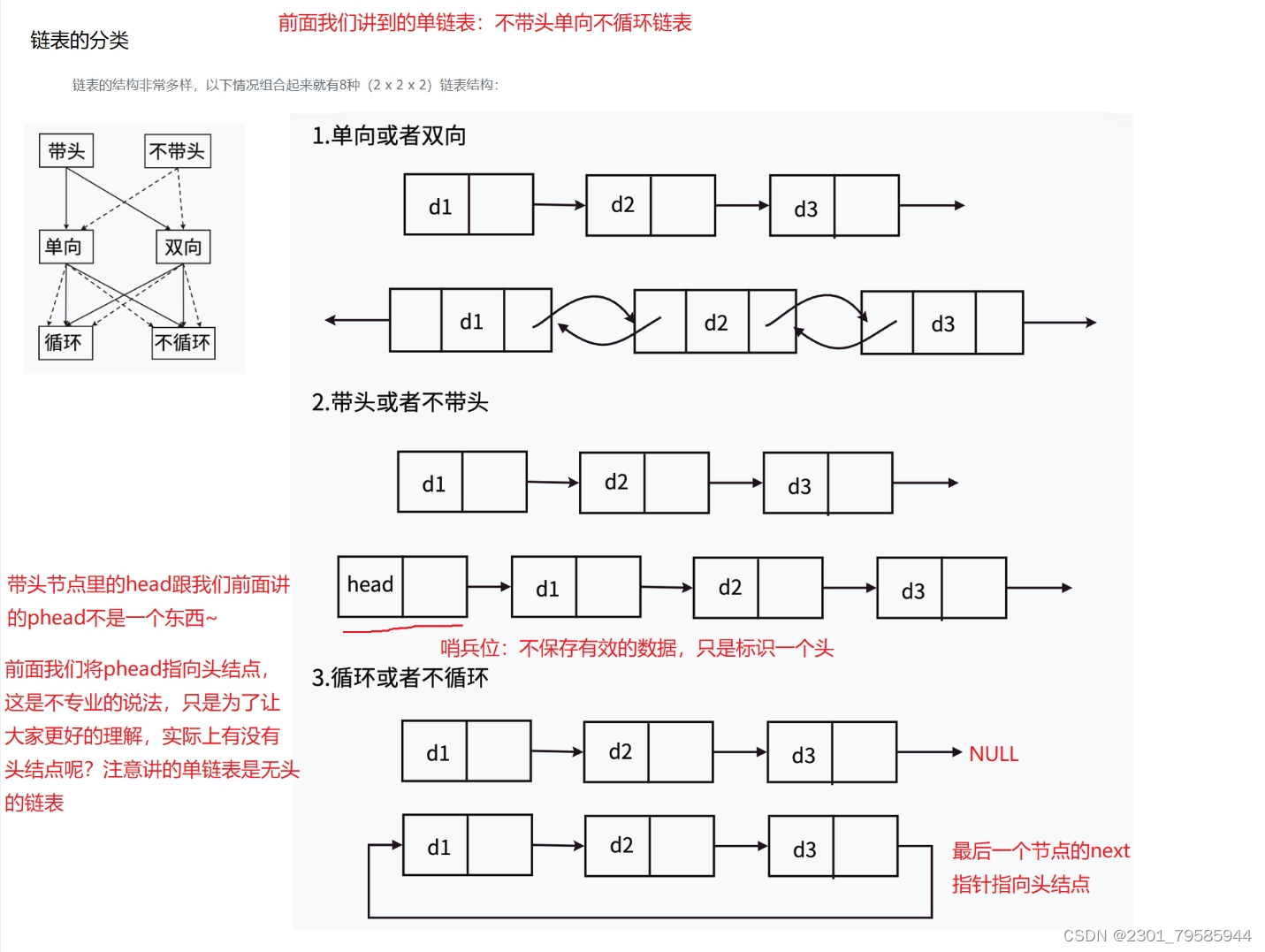
虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构:
单链表 和 双向带头循环链表。
1. 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
2. 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了,后面我们代码实现了就知道了。
总结
好了,本篇博客到这里就结束了,如果有更好的观点,请及时留言,我会认真观看并学习。
不积硅步,无以至千里;不积小流,无以成江海。





![[DASCTF 2023 0X401七月暑期挑战赛] web刷题记录](https://img-blog.csdnimg.cn/5fe6af0eae244a3fa31f3036a7f69fb2.png)