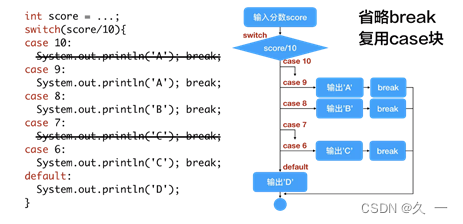
文章目录
- 1.整体结构
- 2.卷积层
- 1)全连接层存在的问题
- 2)卷积运算
- 3)填充
- 4)步幅
- 5)3维数据的卷积运算
- 6)结合方块思考
- 7)批处理
- 3.池化层
- 1)池化层的特征
- 4.卷积层和池化层的实现
- 1)im2co
- 2)卷积层的实现
- 3)池化层的实现
- 5.CNN的实现
- 6.CNN的可视化
- 1)第1层权重的可视化
- 2)基于分层结构的信息提取
- 7.具有代表性的CNN
- 1)LeNet
- 2)AlexNet
1.整体结构
卷积神经网络(Convolutional Neural Network,CNN)和神经网络一样,可以像乐高积木一样通过组装层来构建。不过,CNN 中新出现了卷积层(Convolution 层)和池化层(Pooling 层)。相邻层的所有神经元之间都有连接,这称为全连接(fully-connected)。Affine层实现了全连接层。
CNN 的层的连接顺序是“Convolution - ReLU -(Pooling)”(Pooling 层有时会被省略)。
2.卷积层
1)全连接层存在的问题
形状被“忽视”了。输入数据是图像时,图像通常是高、长、通道方向上的3维形状。但是,向全连接层输入时,需要将3维数据拉平为1维数据。
图像是3维形状,这个形状中应该含有重要的空间信息。比如,空间上邻近的像素为相似的值、RBG的各个通道之间分别有密切的关联性、相距较远的像素之间没有什么关联等,3维形状中可能隐藏有值得提取的本质模式。但是,因为全连接层会忽视形状,将全部的输入数据作为相同的神经元(同一维度的神经元)处理,所以无法利用与形状相关的信息。
而卷积层可以保持形状不变。当输入数据是图像时,卷积层会以 3 维数据的形式接收输入数据,并同样以3 维数据的形式输出至下一层。因此,在CNN中,可以(有可能)正确理解图像等具有形状的数据。
有时将卷积层的输入输出数据称为特征图(feature map)。其中,卷积层的输入数据称为输入特征图(input feature map),输出数据称为输出特征(output feature map)。
2)卷积运算
卷积层进行的处理就是卷积运算。卷积运算相当于图像处理中的“滤波器运算”。

对于输入数据,卷积运算以一定间隔滑动滤波器的窗口并应用。
将各个位置上滤波器的元素和输入的对应元素相乘,然后再求和(有时将这个计算称为乘积累加运算)。然后,将这个结果保存到输出的对应位置。将这个过程在所有位置都进行一遍,就可以得到卷积运算的输出。
并且,CNN中也存在偏置。
3)填充
在进行卷积层的处理之前,有时要向输入数据的周围填入固定的数据(比如0等),这称为填充(padding),是卷积运算中经常会用到的处理。
使用填充主要是为了调整输出的大小。
4)步幅
应用滤波器的位置间隔称为步幅(stride)。
综上,增大步幅后,输出大小会变小。而增大填充后,输出大小会变大。
5)3维数据的卷积运算
通道方向上有多个特征图时,会按通道进行输入数据和滤波器的卷积运算,并将结果相加,从而得到输出
6)结合方块思考
将数据和滤波器结合长方体的方块来考虑,3维数据的卷积运算会很容易理解。
把3维数据表示为多维数组时,书写顺序为(channel, height, width)。
滤波器也一样,要按(channel, height, width)的顺序书写。
7)批处理
需要将在各层间传递的数据保存为4维数据。按(batch_num, channel, height, width)的顺序保存数据。
3.池化层
池化是缩小高、长方向上的空间的运算。
除了Max池化之外,还有Average池化等。相对于Max池化是从目标区域中取出最大值,Average池化则是计算目标区域的平均值。在图像识别领域,主要使用Max池化。
1)池化层的特征
没有要学习的参数:池化层和卷积层不同,没有要学习的参数。池化只是从目标区域中取最大值(或者平均值),所以不存在要学习的参数。
通道数不发生变化:经过池化运算,输入数据和输出数据的通道数不会发生变化。计算是按通道独立进行的。
对微小的位置变化具有鲁棒性(健壮):输入数据发生微小偏差时,池化仍会返回相同的结果。
4.卷积层和池化层的实现
1)im2co
im2col 是一个函数,将输入数据展开以适合滤波器(权重)。
在文件util.py, 添加代码如下:
def im2col(input_data, filter_h, filter_w, stride=1, pad=0):
"""
将输入的4维张量进行im2col操作,转换为一维向量。
主要用于卷积神经网络的前向传播。
参数:
input_data : 由(数据量, 通道, 高, 长)的4维数组构成的输入数据
filter_h : 滤波器的高
filter_w : 滤波器的长
stride : 步幅,卷积步长
pad : 填充大小
返回:
col : 2维数组,转换后的一维向量
"""
N, C, H, W = input_data.shape # 获取输入数据的形状(N, C, H, W),其中N是批量大小,C是通道数,H和W分别是高和宽。
out_h = (H + 2*pad - filter_h)//stride + 1 # 计算输出数据的高,使用了步长和填充来计算。
out_w = (W + 2*pad - filter_w)//stride + 1 # 计算输出数据的宽,同样使用了步长和填充来计算。
img = np.pad(input_data, [(0,0), (0,0), (pad, pad), (pad, pad)], 'constant') # 在输入数据的边缘添加填充,保证滤波器可以平滑地应用到整个数据上。
col = np.zeros((N, C, filter_h, filter_w, out_h, out_w)) # 初始化一个零矩阵,用于存储卷积结果。
for y in range(filter_h): # 遍历滤波器的高。
y_max = y + stride*out_h # 计算y的最大值,作为卷积操作的边界。
for x in range(filter_w): # 遍历滤波器的宽。
x_max = x + stride*out_w # 计算x的最大值,作为卷积操作的边界。
col[:, :, y, x, :, :] = img[:, :, y:y_max:stride, x:x_max:stride] # 在输入数据上进行卷积操作并将结果存储到col中。
col = col.transpose(0, 4, 5, 1, 2, 3).reshape(N*out_h*out_w, -1) # 将col中的数据重新排列维度并转换为一维数组,方便后续的计算。
return col # 返回转换后的一维数组。
2)卷积层的实现
在文件layers.py, 添加代码如下:
"""
实现了卷积神经网络中的卷积操作及其反向传播。在前向传播过程中,输入数据x经过卷积操作得到输出数据out,
中间保存了im2col的结果以及卷积核矩阵的转置,用于反向传播。在反向传播过程中,根据链式法则计算参数的梯度,并保存到dW和db属性中。
同时,通过矩阵乘法和col2im操作计算出梯度dx,即卷积的梯度。最后返回dx。
"""
class Convolution:
# 定义一个名为Convolution的类
def __init__(self, W, b, stride=1, pad=0):
# 初始化函数,接收四个参数:W(卷积核的权重矩阵),b(偏置向量),stride(步长),pad(填充大小)
self.W = W
self.b = b
self.stride = stride
self.pad = pad
# 中间数据(backward时使用)
self.x = None
self.col = None
self.col_W = None
# 定义三个属性,用于保存中间计算数据,这些数据在反向传播时会被使用
# 权重和偏置参数的梯度
self.dW = None
self.db = None
# 定义两个属性,用于保存参数的梯度,这些梯度在反向传播时会被使用
# 定义前向传播函数
def forward(self, x):
FN, C, FH, FW = self.W.shape # 获取卷积核的形状
N, C, H, W = x.shape # 获取输入数据的形状
out_h = 1 + int((H + 2 * self.pad - FH) / self.stride) # 计算输出数据的高
out_w = 1 + int((W + 2 * self.pad - FW) / self.stride) # 计算输出数据的宽
# 对输入数据进行im2col操作,将数据展平为一维数组,并保存结果到col属性中
col = im2col(x, FH, FW, self.stride, self.pad)
# 将卷积核矩阵展平为一维数组,并转置后保存结果到col_W属性中
col_W = self.W.reshape(FN, -1).T
# 进行矩阵乘法运算:col * col_W,将结果保存到out属性中
out = np.dot(col, col_W) + self.b # 进行矩阵乘法并加上偏置项b
# 将输出结果重新整理为和输入数据一样的形状,然后转置维度顺序,保存结果到out属性中
out = out.reshape(N, out_h, out_w, -1).transpose(0, 3, 1, 2)
# 将输入数据保存到x属性中,卷积结果保存到out属性中,im2col的结果保存到col属性中,卷积核矩阵的转置保存到col_W属性中
self.x = x
self.col = col
self.col_W = col_W
return out # 返回卷积结果
# 定义反向传播函数
def backward(self, dout):
FN, C, FH, FW = self.W.shape # 获取卷积核的形状
dout = dout.transpose(0, 2, 3, 1).reshape(-1, FN) # 改变dout的维度顺序并重新整理形状,以便与矩阵乘法相适应
# 计算偏置项的梯度,并保存到db属性中
self.db = np.sum(dout, axis=0)
# 计算卷积核的梯度,并保存到dW属性中
self.dW = np.dot(self.col.T, dout) # 进行矩阵乘法运算,结果保存到dW属性中
# 将dW的形状变换为原来的卷积核的形状,并保存结果到dW属性中
self.dW = self.dW.transpose(1, 0).reshape(FN, C, FH, FW) # 将dW的形状变换为原来的卷积核的形状,并保存结果到dW属性中
# 对偏置项和卷积核的梯度进行矩阵乘法运算,得到dcol属性中,即dx的展开形式的一部分dcol = np.dot(dout, self.col_W.T)
# 进行矩阵乘法运算,结果保存到dcol属性中
dcol = np.dot(dout, self.col_W.T)
# 进行矩阵乘法运算,结果保存到dcol属性中 定义一个名为Col2Im的类来将dx的计算结果重新整理
dx = col2im(dcol, self.x.shape, FH, FW, self.stride, self.pad)
# 将dcol重新整理为与输入数据x相同的形状,并保存结果到dx属性中
return dx # 返回dx,即卷积的梯度
3)池化层的实现
在文件layers.py, 添加代码如下:
"""这个Pooling类的实现对应于深度学习中常用的最大池化操作。在前向传播过程中,输入数据x经过池化操作得到输出数据out。这个过程包括对输入数据进行im2col操作,然后进行最大值选择和reshape操作。在反向传播过程中,根据链式法则计算参数的梯度,并保存到dW和db属性中。同时,通过矩阵乘法和col2im操作计算出梯度dx,即池化的梯度。最后返回梯度dx。
"""
class Pooling: # 定义一个名为Pooling的类,用于实现池化操作
def __init__(self, pool_h, pool_w, stride=1, pad=0): # 初始化函数,接收四个参数:池化窗口的高度和宽度,步长,填充大小
self.pool_h = pool_h # 保存池化窗口的高度
self.pool_w = pool_w # 保存池化窗口的宽度
self.stride = stride # 保存步长
self.pad = pad # 保存填充大小
# 初始化两个属性,用于保存中间计算数据,这些数据在反向传播时会被使用
self.x = None # 保存输入数据
self.arg_max = None # 保存最大值的索引
def forward(self, x): # 前向传播函数,接收输入数据x,并返回池化后的结果
N, C, H, W = x.shape # 获取输入数据的形状
out_h = int(1 + (H - self.pool_h) / self.stride) # 计算输出数据的高度
out_w = int(1 + (W - self.pool_w) / self.stride) # 计算输出数据的宽度
# 对输入数据进行im2col操作,将数据展平为一维数组,并保存结果到col属性中
col = im2col(x, self.pool_h, self.pool_w, self.stride, self.pad)
# 将展平的数据reshape为二维数组,并保存结果到col属性中
col = col.reshape(-1, self.pool_h*self.pool_w)
# 找出每列最大值的索引,并保存结果到arg_max属性中
arg_max = np.argmax(col, axis=1)
# 找出每列的最大值,并保存结果到out属性中
out = np.max(col, axis=1)
# 将结果重新整理为和输入数据一样的形状,然后转置维度顺序,保存结果到out属性中
out = out.reshape(N, out_h, out_w, C).transpose(0, 3, 1, 2)
# 将输入数据保存到x属性中,最大值的索引保存到arg_max属性中,池化结果保存到out属性中
self.x = x
self.arg_max = arg_max
return out # 返回池化结果
def backward(self, dout): # 反向传播函数,接收梯度dout,并返回梯度dx
# 将dout的维度顺序转置,并重新整理形状,以便与矩阵乘法相适应
dout = dout.transpose(0, 2, 3, 1)
pool_size = self.pool_h * self.pool_w # 计算池化窗口的数量
# 初始化一个与dout形状相同但全为0的矩阵dmax
dmax = np.zeros((dout.size, pool_size))
# 将dout中对应最大值位置的元素赋值给dmax中对应位置的元素
dmax[np.arange(self.arg_max.size), self.arg_max.flatten()] = dout.flatten()
dmax = dmax.reshape(dout.shape + (pool_size,))
# 对dmax进行矩阵乘法和reshape操作,将其转换为与原输入数据x相同的形状
dcol = dmax.reshape(dmax.shape[0] * dmax.shape[1] * dmax.shape[2], -1)
# 使用col2im函数将dcol转换回与原输入数据x相同的形状,并保存结果到dx属性中
dx = col2im(dcol, self.x.shape, self.pool_h, self.pool_w, self.stride, self.pad)
# 返回梯度dx
return dx
5.CNN的实现
CNN可以有效读取图像中的某种特性,在手写数字识别中,还可以实现高精度的识别。
网络的构成是“Convolution - ReLU - Pooling -Affine - ReLU - Affine - Softmax”,如下所示

创建文件SimpleConvNet.py, 添加代码如下:
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import pickle
import numpy as np
from collections import OrderedDict
from common.layers import *
from common.gradient import numerical_gradient
class SimpleConvNet:
"""简单的ConvNet
conv - relu - pool - affine - relu - affine - softmax
Parameters
----------
input_size : 输入大小(MNIST的情况下为784)
hidden_size_list : 隐藏层的神经元数量的列表(e.g. [100, 100, 100])
output_size : 输出大小(MNIST的情况下为10)
activation : 'relu' or 'sigmoid'
weight_init_std : 指定权重的标准差(e.g. 0.01)
指定'relu'或'he'的情况下设定“He的初始值”
指定'sigmoid'或'xavier'的情况下设定“Xavier的初始值”
"""
def __init__(self, input_dim=(1, 28, 28),
conv_param={'filter_num':30, 'filter_size':5, 'pad':0, 'stride':1},
hidden_size=100, output_size=10, weight_init_std=0.01):
filter_num = conv_param['filter_num']
filter_size = conv_param['filter_size']
filter_pad = conv_param['pad']
filter_stride = conv_param['stride']
input_size = input_dim[1]
conv_output_size = (input_size - filter_size + 2*filter_pad) / filter_stride + 1
pool_output_size = int(filter_num * (conv_output_size/2) * (conv_output_size/2))
# 初始化权重
self.params = {}
self.params['W1'] = weight_init_std * \
np.random.randn(filter_num, input_dim[0], filter_size, filter_size)
self.params['b1'] = np.zeros(filter_num)
self.params['W2'] = weight_init_std * \
np.random.randn(pool_output_size, hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * \
np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
# 生成层
self.layers = OrderedDict()
self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'],
conv_param['stride'], conv_param['pad'])
self.layers['Relu1'] = Relu()
self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2)
self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2'])
self.layers['Relu2'] = Relu()
self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3'])
self.last_layer = SoftmaxWithLoss()
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
"""求损失函数
参数x是输入数据、t是教师标签
"""
y = self.predict(x)
return self.last_layer.forward(y, t)
def accuracy(self, x, t, batch_size=100):
if t.ndim != 1 : t = np.argmax(t, axis=1)
acc = 0.0
for i in range(int(x.shape[0] / batch_size)):
tx = x[i*batch_size:(i+1)*batch_size]
tt = t[i*batch_size:(i+1)*batch_size]
y = self.predict(tx)
y = np.argmax(y, axis=1)
acc += np.sum(y == tt)
return acc / x.shape[0]
def numerical_gradient(self, x, t):
"""求梯度(数值微分)
Parameters
----------
x : 输入数据
t : 教师标签
Returns
-------
具有各层的梯度的字典变量
grads['W1']、grads['W2']、...是各层的权重
grads['b1']、grads['b2']、...是各层的偏置
"""
loss_w = lambda w: self.loss(x, t)
grads = {}
for idx in (1, 2, 3):
grads['W' + str(idx)] = numerical_gradient(loss_w, self.params['W' + str(idx)])
grads['b' + str(idx)] = numerical_gradient(loss_w, self.params['b' + str(idx)])
return grads
def gradient(self, x, t):
"""求梯度(误差反向传播法)
Parameters
----------
x : 输入数据
t : 教师标签
Returns
-------
具有各层的梯度的字典变量
grads['W1']、grads['W2']、...是各层的权重
grads['b1']、grads['b2']、...是各层的偏置
"""
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 设定
grads = {}
grads['W1'], grads['b1'] = self.layers['Conv1'].dW, self.layers['Conv1'].db
grads['W2'], grads['b2'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W3'], grads['b3'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads
def save_params(self, file_name="params.pkl"):
params = {}
for key, val in self.params.items():
params[key] = val
with open(file_name, 'wb') as f:
pickle.dump(params, f)
def load_params(self, file_name="params.pkl"):
with open(file_name, 'rb') as f:
params = pickle.load(f)
for key, val in params.items():
self.params[key] = val
for i, key in enumerate(['Conv1', 'Affine1', 'Affine2']):
self.layers[key].W = self.params['W' + str(i+1)]
self.layers[key].b = self.params['b' + str(i+1)]
创建文件train_convnet.py, 添加代码如下:
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
# 导入numpy库,为数据处理提供支持
import numpy as np
# 导入matplotlib.pyplot库,用于数据可视化
import matplotlib.pyplot as plt
# 从dataset.mnist模块导入load_mnist函数,用于加载MNIST数据集
from dataset.mnist import load_mnist
# 从simple_convnet模块导入SimpleConvNet类,这是一个简单的卷积神经网络模型
from simple_convnet import SimpleConvNet
# 从common.trainer模块导入Trainer类,这是一个通用的训练器,可以对网络进行训练和评估
from common.trainer import Trainer
# 加载MNIST数据集,这里的数据集是带标签的,所以输入数据x_train和标签t_train都是二维的numpy数组
# x_train和t_train分别代表训练集的图像和标签,x_test和t_test分别代表测试集的图像和标签
# load_mnist(flatten=False)表示不将图像数据扁平化处理,保持原有的28x28像素的图片格式
# 读入数据
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=False)
# 另外,为了处理大数据集和减少计算时间,有时候会只取部分数据进行训练和测试
# 以下两行注释掉的数据处理就是取了MNIST数据集的前5000个训练样本和前1000个测试样本
# x_train, t_train = x_train[:5000], t_train[:5000]
# x_test, t_test = x_test[:1000], t_test[:1000]
# 定义最大训练轮数,即最大迭代次数
max_epochs = 20
# 初始化一个SimpleConvNet网络模型,输入数据的维度为(1,28,28),即单通道28x28像素的图像
# 卷积层包含30个大小为5x5的卷积核,padding为0,步长为1
# 隐藏层大小为100,输出层大小为10,权重初始标准差为0.01
network = SimpleConvNet(input_dim=(1, 28, 28),
conv_param={'filter_num': 30, 'filter_size': 5, 'pad': 0, 'stride': 1},
hidden_size=100, output_size=10, weight_init_std=0.01)
# 创建一个Trainer对象,传入网络模型、训练数据、测试数据、训练参数(最大迭代次数、mini batch大小、优化器类型及其参数等)
trainer = Trainer(network, x_train, t_train, x_test, t_test,
epochs=max_epochs, mini_batch_size=100,
optimizer='Adam', optimizer_param={'lr': 0.001},
evaluate_sample_num_per_epoch=1000)
# 使用Trainer对象的train方法对网络进行训练
trainer.train()
# 将网络模型的参数保存到文件中,文件名为"params.pkl"
# 在实际应用中,这些参数可以用于以后的预测或模型的部署
network.save_params("params.pkl")
print("Saved Network Parameters!")
# 使用matplotlib库绘制训练集和测试集的准确率变化曲线
# 首先定义标记类型和数据范围
markers = {'train': 'o', 'test': 's'}
x = np.arange(max_epochs) # x轴的数据范围从0到最大训练轮数(20)
plt.plot(x, trainer.train_acc_list, marker='o', label='train',
markevery=2) # 绘制训练集准确率曲线,标记为'o'(圆圈),标签为'train',每隔两个点画一个标记
plt.plot(x, trainer.test_acc_list, marker='s', label='test',
markevery=2) # 绘制测试集准确率曲线,标记为's'(正方形),标签为'test',每隔两个点画一个标记
plt.xlabel("epochs") # x轴标签为"epochs"(训练轮数)
plt.ylabel("accuracy") # y轴标签为"accuracy"(准确率)
plt.ylim(0, 1.0) # y轴的数据范围从0到1(即准确率的范围)
plt.legend(loc='lower right') # 图例显示在
#绘制图形
plt.show()
plt.show()
运行结果:

6.CNN的可视化
1)第1层权重的可视化
将卷积层(第 1层)的滤波器显示为图像。
创建文件visualize_filter.py, 添加代码如下:
# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
from simple_convnet import SimpleConvNet
def filter_show(filters, nx=8, margin=3, scale=10):
FN, C, FH, FW = filters.shape
ny = int(np.ceil(FN / nx))
fig = plt.figure()
fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05, wspace=0.05)
for i in range(FN):
ax = fig.add_subplot(ny, nx, i+1, xticks=[], yticks=[])
ax.imshow(filters[i, 0], cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()
network = SimpleConvNet()
# 随机进行初始化后的权重
filter_show(network.params['W1'])
# 学习后的权重
network.load_params("params.pkl")
filter_show(network.params['W1'])
运行结果:
学习前

学习后

学习前的滤波器是随机进行初始化的,所以在黑白的浓淡上没有规律可循,但学习后的滤波器变成了有规律的图像。我们发现,通过学习,滤波器被更新成了有规律的滤波器,比如从白到黑渐变的滤波器、含有块状区域(称为blob)的滤波器等。
卷积层的滤波器会提取边缘或斑块等原始信息。而刚才实现的CNN会将这些原始信息传递给后面的层。
2)基于分层结构的信息提取
最开始的层对简单的边缘有响应,接下来的层对纹理有响应,再后面的层对更加复杂的物体部件有响应。也就是说,随着层次加深,神经元从简单的形状向“高级”信息变化。换句话说,就像我们理解东西的“含义”一样,响应的对象在逐渐变化。
如果堆叠了多层卷积层,则随着层次加深,提取的信息也愈加复杂、抽象,这是深度学习中很有意思的一个地方。最开始的层对简单的边缘有响应,接下来的层对纹理有响应,再后面的层对更加复杂的物体部件有响应。也就是说,随着层次加深,神经元从简单的形状向“高级”信息变化。换句话说,就像我们理解东西的“含义”一样,响应的对象在逐渐变化
7.具有代表性的CNN
1)LeNet
LeNet 在 1998 年被提出,是进行手写数字识别的网络。
它有连续的卷积层和池化层(正确地讲,是只“抽选元素”的子采样层),最后经全连接层输出结果。
和“现在的CNN”相比,LeNet有几个不同点。第一个不同点在于激活函数。LeNet 中使用sigmoid 函数,而现在的 CNN 中主要使用 ReLU函数。此外,原始的LeNet中使用子采样(subsampling)缩小中间数据的大小,而现在的CNN中Max池化是主流。
2)AlexNet
AlexNet 叠有多个卷积层和池化层,最后经由全连接层输出结果。虽然结构上AlexNet和LeNet没有大的不同,但有以下几点差异。
• 激活函数使用 ReLU。
• 使用进行局部正规化的 LRN(Local Response Normalization)层。
• 使用 Dropout。