EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention
- 1、介绍
- 2、使用 Vision Transformer 加快速度
- 2.1 内存效率
- 2.2 计算效率
- 2.3 参数效率
- 3、Efficient Vision Transformer
- 3.1 EfficientViT 构建模块
- 3.3 EfficientViT 网络架构
- 4、实验
- 5、结论
我们发现现有的变压器模型的速度通常受到内存低效操作的限制,特别是在MHSA中张量重塑和元素方向的函数。因此,我们设计了一种新的夹层布局的构建块,即在高效FFN层之间使用单一的内存约束MHSA,提高了内存效率,同时增强了信道通信。
此外,我们发现,注意力特征图在不同头部之间具有高度的相似性,从而导致计算冗余。
为了解决这一问题,我们提出了一种级联的群注意模块,该模块提供了具有不同分块特征的注意头,不仅节省了计算成本,而且提高了注意的多样性。
1、介绍
不断提高的精度是以增加模型尺寸和计算开销为代价的。
为了解决这个问题,在本文中,我们探索如何更快地使用视觉变压器,寻找设计高效变压器架构的原则。基于当前流行的视觉转换器DeiT[69]和Swin[44],我们系统地分析了影响模型推理速度的三个主要因素,包括内存访问、计算冗余和参数使用。
特别地,我们发现变压器模型的速度通常是内存限制的。换句话说,内存访问延迟阻碍了GPU/ cpu计算能力的充分利用[21,32,72],从而对变压器运行速度产生了严重的负面影响[15,31]。
记忆效率最低的运算是多头自注意(MHSA)中频繁的张量重塑和元素智能函数。我们观察到,通过适当调整MHSA和FFN(前馈网络)层之间的比例,内存访问时间可以显著减少而不影响性能。此外,我们发现一些注意力头倾向于学习类似的线性投影,从而导致在注意力特征图中的冗余。
分析表明,通过给每个头输入不同的特征来显式分解每个头的计算可以在提高计算效率的同时缓解这一问题。此外,不同模块的参数分配往往被现有的轻量级模型所忽略,因为它们主要遵循标准变压器模型中的配置[44,69]。为了提高参数的效率,我们采用了结构化剪枝[45]算法来识别最重要的网络组件,并总结了参数重新分配对模型加速的经验指导。
基于上述分析和发现,我们提出了一种名为EfficientViT的新型高效存储变压器模型。具体来说,我们设计了一个带有三明治布局的新块体来建立模型。三明治布局块在FFN层之间应用一个单一的内存绑定MHSA层。它减少了MHSA中内存受限操作所带来的时间开销,并应用了更多的FFN层来实现不同通道之间的通信,从而提高了内存效率。然后,我们提出了一种新的级联组注意(CGA)模块来提高计算效率。游戏的核心理念是增强玩家注意力的多样性。与之前对所有头部使用相同特征的自注意相比,CGA为每个头部提供不同的输入分割,并跨头部级联输出特征。该模块不仅减少了多头注意力的计算冗余,而且通过增加网络深度提高了模型容量。最后但并非最不重要的是,我们通过扩大关键网络组件(如值投影)的通道宽度来重新分配参数,同时缩小ffn中重要性较低的组件(如隐藏维数)。这种重新分配最终提高了模型参数的效率。
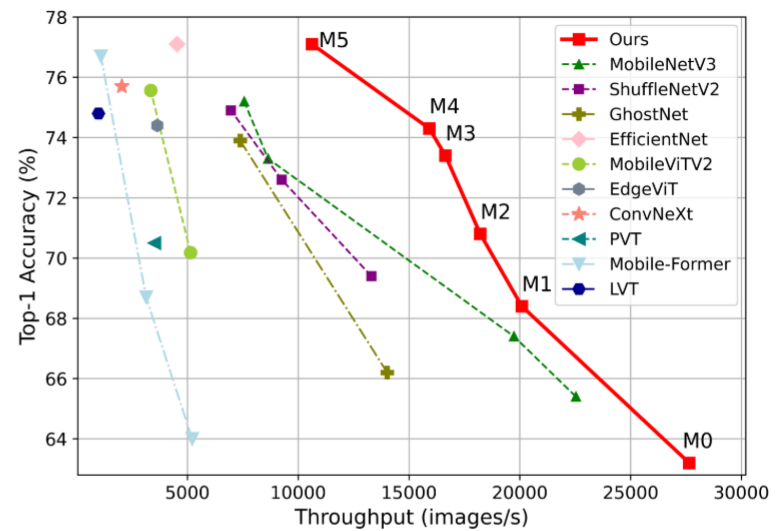
图 1. EfficientViT(我们的)与在 Nvidia V100 GPU 上使用 ImageNet-1K 数据集进行测试的其他高效 CNN 和 ViT 模型之间的速度和准确性比较 [17]。
实验表明,我们的模型在速度和精度方面比现有的高效 CNN 和 ViT 模型有了明显的改进,如图 1 所示。例如,我们的 EfficientViT-M5 在 ImageNet 上获得了 77.1% 的 top-1 精度,吞吐量为 10,621 Nvidia V100 GPU 上的图像/秒和 Intel Xeon E52690 v4 CPU @ 2.60GHz 上的图像/秒为 56.8 个图像/秒,准确度比 MobileNetV3Large [26] 高出 1.9%,GPU 推理速度高出 40.4%,CPU 速度高出 45.2%。此外,EfficientViTM2 的准确率达到 70.8%,比 MobileViT-XXS [50] 提高了 1.8%,同时在 GPU/CPU 上运行速度提高了 5.8×/3.7×,转换为 ONNX [3] 格式时速度提高了 7.4×。当部署在移动芯片组(即 iPhone 11 中的 Apple A13 Bionic 芯片)上时,EfficientViT-M2 模型的运行速度比使用 CoreML [1] 的 MobileViT-XXS [50] 快 2.3 倍。
总之,这项工作的贡献有两个:
1、我们对影响视觉转换器推理速度的因素进行了系统分析,得出了一套高效模型设计的指南。
2、我们设计了一系列新的视觉转换器模型,在效率和准确性之间取得了良好的权衡。这些模型还表现出在各种下游任务上良好的迁移能力。
2、使用 Vision Transformer 加快速度
在本节中,我们从内存访问、计算冗余和参数使用三个角度探讨如何提高视觉转换器的效率。我们寻求通过实证研究来识别潜在的速度瓶颈,并总结有用的设计指南。
2.1 内存效率
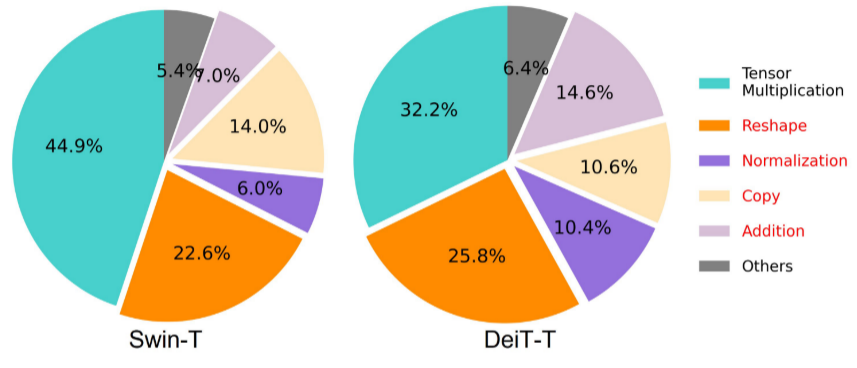
图 2. 两个标准视觉转换器 Swin-T 和 DeiT-T 上的运行时分析。红色文本表示内存限制操作,即操作所花费的时间主要由内存访问决定,而计算所花费的时间要少得多。
内存访问开销是影响模型速度的关键因素[15,28,31,65]。 Transformer [71] 中的许多运算符,例如频繁的整形、逐元素加法和归一化,都是内存效率低下的,需要跨不同内存单元进行耗时的访问,如图 2 所示。尽管有人提出了一些方法来解决这个问题简化标准softmax自注意力的计算,例如稀疏注意力[34,57,61,75]和低秩近似[11,51,74],它们通常以精度下降和有限的加速为代价。
在这项工作中,我们通过减少内存效率低下的层来节省内存访问成本。最近的研究表明,内存效率低下的操作主要位于 MHSA 而不是 FFN 层 [31, 33]。然而,大多数现有的ViT [18,44,69]使用相同数量的这两层,这可能无法达到最佳效率。因此,我们通过快速推理探索小型模型中 MHSA 和 FFN 层的最佳分配。具体来说,我们将 Swin-T [44] 和 DeiT-T [69] 缩小为几个推理吞吐量分别提高 1.25 倍和 1.5 倍的小型子网,并比较具有不同比例 MHSA 层的子网的性能。如图 3 所示,具有 20%-40% MHSA 层的子网络往往会获得更好的精度。这样的比率比采用 50% MHSA 层的典型 ViT 小得多。此外,我们还测量了内存绑定操作的时间消耗,以比较内存访问效率,包括整形、逐元素加法、复制和标准化。在具有 20% MHSA 层的 Swin-T-1.25× 中,内存限制操作减少到总运行时间的 44.26%。该观察结果还推广到 DeiT 和具有 1.5 倍加速的较小模型。事实证明,适当降低 MHSA 层利用率可以在提高模型性能的同时提高内存效率。
2.2 计算效率
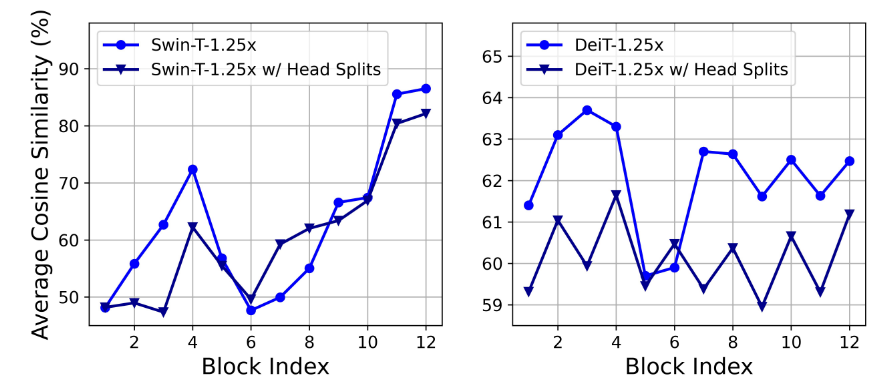
图 4. 不同块中每个头的平均最大余弦相似度。左:缩小尺寸的 Swin-T 模型。右:缩小尺寸的 DeiT-T 模型。蓝线表示 Swin-T-1.25×/DeiT-T1.25× 型号,而深蓝色线表示仅向每个头提供完整功能的一部分的变体。
MHSA 将输入序列嵌入到多个子空间(头)中并分别计算注意力图,这已被证明可以有效提高性能[18,69,71]。然而,注意力图的计算成本很高,而且研究表明其中许多并不是至关重要的[52, 73]。为了节省计算成本,我们探索如何减少小型 ViT 模型中的冗余注意力。我们以 1.25 倍的推理加速训练宽度缩小的 Swin-T [44] 和 DeiT-T [69] 模型,并测量每个块内每个头和其余头的最大余弦相似度。从图 4 中,我们观察到注意力头之间存在高度相似性,尤其是在最后的块中。这种现象表明,许多头学习相同完整特征的相似投影并产生计算冗余。为了明确鼓励头部学习不同的模式,我们应用了一种直观的解决方案,仅向每个头部提供完整特征的一部分,这类似于[10, 87]中的组卷积的想法。我们使用修改后的 MHSA 训练缩小模型的变体,并计算图 4 中的注意力相似度。结果表明,在不同的头部中使用不同通道的特征分割,而不是像 MHSA 那样对所有头部使用相同的完整特征,可以有效减轻注意力计算冗余。
2.3 参数效率
典型的ViT主要继承了NLP Transformer [71]的设计策略,例如,使用Q、K、V投影的等效宽度、增加各级的头以及将FFN中的扩展比设置为4。对于轻量级模型,需要仔细重新设计这些组件的配置[7,8,39]。受[45, 82]的启发,我们采用泰勒结构剪枝[53]来自动查找Swin-T和DeiT-T中的重要组成部分,并探索参数分配的底层原理。剪枝方法在一定的资源限制下删除不重要的通道并保留最关键的通道以最好地保持准确性。它使用梯度和权重的乘积作为通道重要性,近似去除通道时的损失波动[38]。
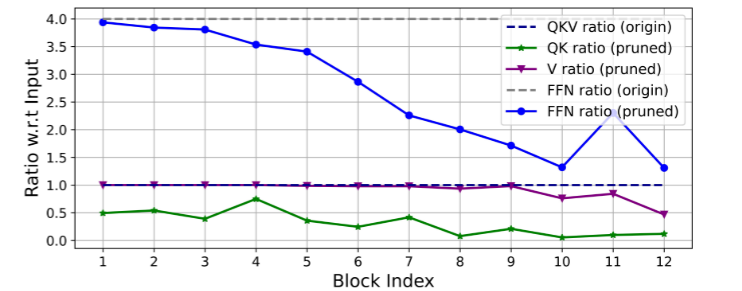
图 5. Swin-T 剪枝前后通道与输入嵌入的比率。基线准确率:79.1%;剪枝准确率:76.5%。 DeiT-T 的结果在补充材料中给出。
剩余输出通道与输入通道之间的比率如图5所示,并且还给出了未剪枝模型中的原始比率以供参考。观察到: 1)前两个阶段保留了更多的维度,而最后一个阶段保留了更少的维度; 2) Q、K 和 FFN 维度被大幅修剪,而 V 维度几乎保持不变,仅在最后几个块处减小。这些现象表明:1)典型的通道配置,即在每个阶段之后将通道加倍[44]或对所有块使用等效通道[69],可能会在最后几个块中产生大量冗余; 2)当维度相同时,Q、K 中的冗余度远大于 V。 V 更喜欢相对较大的通道,接近输入嵌入维度。
3、Efficient Vision Transformer
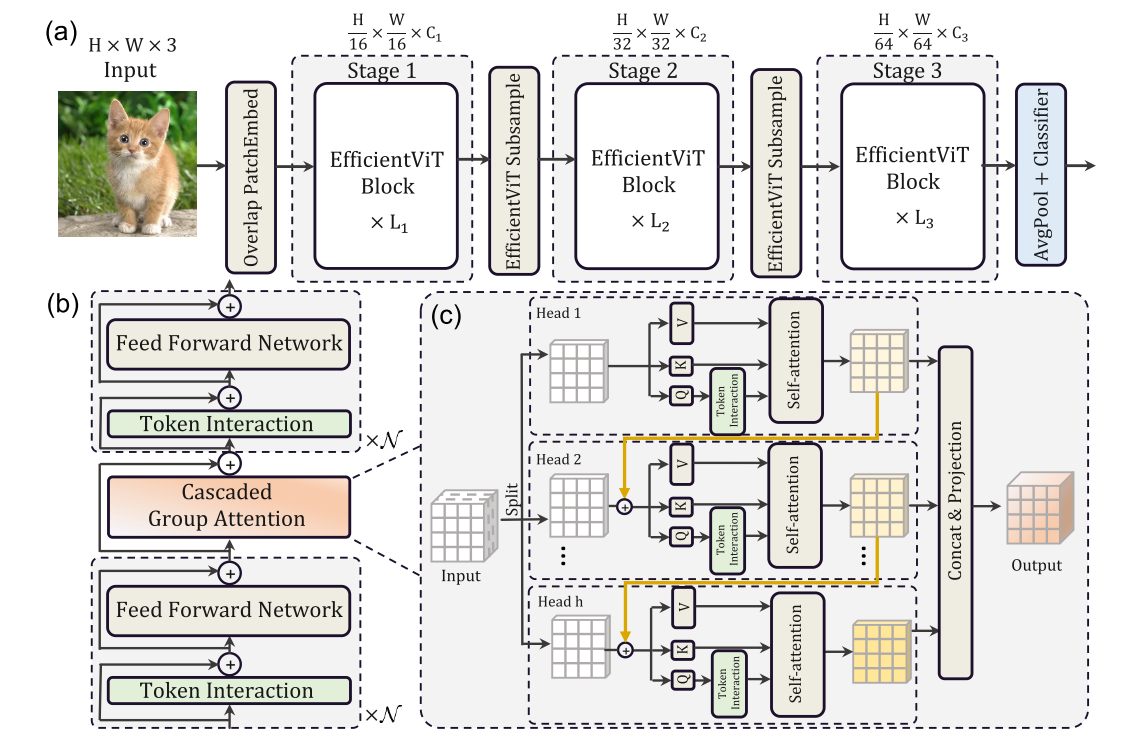
图 6. EfficientViT 概述。 (a) EfficientViT的架构; (b) 三明治布局块; © 级联群体注意力。
3.1 EfficientViT 构建模块
我们提出了一种新的高效视觉转换器构建块,如图 6 (b) 所示。它由内存高效的三明治布局、级联的群体注意力模块和参数重新分配策略组成,分别致力于提高内存、计算和参数方面的模型效率。
三明治布局:
为了构建内存高效的块,我们提出了一种三明治布局,该布局采用更少的内存限制自注意力层和更内存高效的 FFN 层来进行通道通信。具体来说,它应用单个自注意力层 ΦA i 进行空间混合,该层夹在 FFN 层 ΦF i 之间。计算可以表述为:
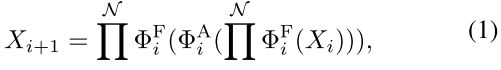
其中 Xi 是第 i 个块的完整输入特征。该块在单个自注意力层之前和之后使用 NFFN 将 Xi 转换为 Xi+1。这种设计减少了模型中自注意力层引起的内存时间消耗,并应用更多的FFN层以允许不同特征通道之间有效地通信。我们还在每个 FFN 之前使用深度卷积 (DWConv) [27] 应用额外的令牌交互层。它引入了局部结构信息的归纳偏差来增强模型能力[14]。
级联组注意力:
注意头冗余是 MHSA 中的一个严重问题,它导致计算效率低下。受高效 CNN [10,37,64,87] 中组卷积的启发,我们为视觉变换器提出了一种名为级联组注意力(CGA)的新注意力模块。它为每个头提供完整特征的不同分割,从而明确地分解各个头的注意力计算。形式上,这种注意力可以表述为:
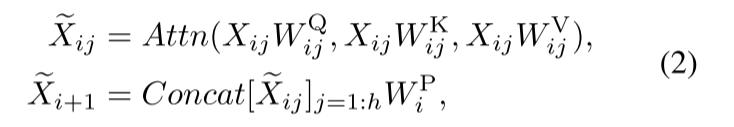
其中第 j 个头计算 Xij 上的自注意力,Xij 是输入特征 Xi 的第 j 个分割,即 Xi = [Xi1,Xi2,…。 。 。 ,Xih] 且 1 ≤ j ≤ h。 h 是头总数,WQ ij 、WK ij 和WV ij 是将输入特征映射到不同子空间的投影层,WP i 是将连接的输出特征投影回与输入一致的维度的线性层。
尽管对每个头使用特征分割而不是完整特征更有效并且节省了计算开销,但我们通过鼓励 Q、K、V 层学习具有更丰富信息的特征的投影来继续提高其容量。我们以级联的方式计算每个头的注意力图,如图6(c)所示,它将每个头的输出添加到后续头以逐步细化特征表示:
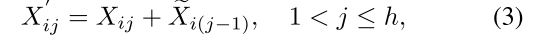
其中 X ′ ij 是第 j 个输入分割 Xij 和第 (j−1) 个头输出 eXi(j−1) 的相加,其中第 (j−1) 个头输出 eXi(j−1) 通过等式计算得出。 公式(2)在计算 self-attention 时,它取代 Xij 作为第 j 个头的新输入特征。此外,在Q投影之后应用了另一个令牌交互层,这使得自注意力能够共同捕获局部和全局关系,并进一步增强特征表示。
这种级联设计有两个优点。首先,为每个头提供不同的特征分割可以提高注意力图的多样性,正如第 2 节中所验证的那样。.与组卷积[10, 87]类似,级联组注意力可以将Flops和参数节省h×,因为QKV层中的输入和输出通道减少了h×。其次,级联注意力头可以增加网络深度,从而进一步提升模型容量,而无需引入任何额外参数。由于每个头中的注意力图计算使用较小的 QK 通道维度,因此它只会产生较小的延迟开销。
参数重新分配。为了提高参数效率,我们通过扩大关键模块的通道宽度同时缩小不重要模块的通道宽度来重新分配网络中的参数。具体来说,基于第二节中的泰勒重要性分析。 我们为所有阶段的每个头中的 Q 和 K 投影设置小通道尺寸。对于 V 投影,我们允许它具有与输入嵌入相同的维度。由于其参数冗余,FFN中的扩展比也从4减少到2。通过所提出的重新分配策略,重要模块具有更多数量的通道来学习高维空间中的表示,这防止了特征信息的丢失。同时,去除不重要模块中的冗余参数,以加快推理速度,提高模型效率。
3.3 EfficientViT 网络架构
我们的 EfficientViT 的整体架构如图 6 (a) 所示。具体来说,我们引入重叠补丁嵌入[20, 80],将 16×16 补丁嵌入到 C1 维度的标记中,从而增强了低级视觉表示学习中的模型能力。该架构包含三个阶段。每个阶段都堆叠所提出的 EfficientViT 构建块,并且每个子采样层的令牌数量减少 4 倍(分辨率的 2 倍子采样)。为了实现高效的子采样,我们提出了一种 EfficientViT 子采样块,它也具有三明治布局,只是将自注意力层替换为反向残差块以减少子采样期间的信息损失[26, 63]。值得注意的是,我们在整个模型中采用 BatchNorm (BN) [30] 而不是 Layer Norm (LN) [2],因为 BN 可以折叠到前面的卷积层或线性层中,这比 LN 具有运行时优势。我们还使用 ReLU [54] 作为激活函数,因为常用的 GELU [25] 或 HardSwish [26] 速度慢得多,并且有时不能很好地受到某些推理部署平台 [1, 3] 的支持。
我们构建了具有六种不同宽度和深度比例的模型系列,并为每个阶段设置了不同数量的头部。我们在早期阶段使用的块比类似于 MobileNetV3 [26] 和 LeViT [20] 的后期阶段更少,因为在早期阶段具有较大分辨率的处理更耗时。我们用一个小因子(≤ 2)增加阶段的宽度,以减少后期阶段的冗余,如第 2 节中分析的那样。 2.3.我们的模型系列的架构细节如表所示。 1. Ci、Li、Hi 分别指第 i 个阶段的宽度、深度和头数。
4、实验
表 2. ImageNet-1K [17] 上的 EfficientViT 图像分类性能,与无需额外数据训练的最先进的高效 CNN 和 ViT 模型进行比较。吞吐量在用于 GPU 的 Nvidia V100 和用于 CPU 和 ONNX 的 Intel Xeon E5-2690 v4 @ 2.60 GHz 处理器上进行测试,其中较大的吞吐量意味着更快的推理速度。 ↑:以更高分辨率进行微调。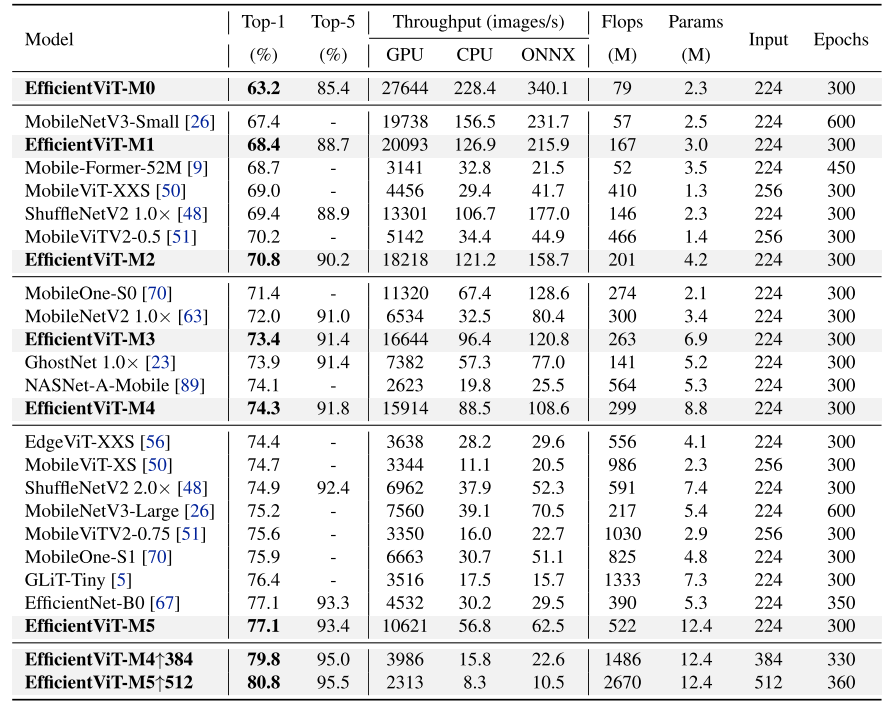
5、结论
在本文中,我们对影响视觉 Transformer 推理速度的因素进行了系统分析,并提出了一种新的快速视觉 Transformer 系列,该家族具有内存高效操作和级联群体注意力,名为 EfficientViT。大量的实验证明了EfficientViT的功效和高速度,并且在各种下游基准测试上也显示了其优越性。
局限性。 EfficientViT 的一个限制是,尽管其推理速度很高,但由于引入的三明治布局中存在额外的 FFN,因此与最先进的高效 CNN [26] 相比,模型尺寸稍大。此外,我们的模型是根据构建高效视觉转换器的派生指南手动设计的。在未来的工作中,我们有兴趣减少模型大小并结合自动搜索技术以进一步提高模型容量和效率。