随着问问题的同学越来越多,公众号内部私信回答问题已经很困难了,所以建立了一个群,关于各种数据库的问题都可以,目前主要是 POSTGRESQL, MYSQL ,MONGODB ,POLARDB ,REDIS 等,期待你的加入,加群请添加微信liuaustin3.
这个问题的从下面的这个SQL 来开始,这是一个典型的说复杂不复杂,说写的好,写的不怎么好的一个SQL。
select fi.title,fi.film_id from film as fi
left join film_category as fc on fi.film_id = fc.film_id
and exists (select 1 from film_actor as fa where fa.film_id = fi.film_id and fa.film_id = 200);
执行计划
——————————————————————————————
| -> Nested loop left join (cost=453.00 rows=1000) (actual time=0.045..1.954 rows=1000 loops=1)
-> Covering index scan on fi using idx_title (cost=103.00 rows=1000) (actual time=0.028..0.236 rows=1000 loops=1)
-> Nested loop inner join (cost=100.35 rows=1) (actual time=0.002..0.002 rows=0 loops=1000)
-> Filter: (fi.film_id = 200) (cost=0.25 rows=1) (actual time=0.001..0.001 rows=0 loops=1000)
-> Covering index lookup on fc using PRIMARY (film_id=200) (cost=0.25 rows=1) (actual time=0.001..0.001 rows=1 loops=1000)
-> Filter: (`<subquery2>`.film_id = 200) (cost=18.27..18.27 rows=1) (actual time=0.018..0.018 rows=1 loops=1)
-> Single-row index lookup on <subquery2> using <auto_distinct_key> (film_id=fi.film_id) (actual time=0.001..0.001 rows=1 loops=1)
-> Materialize with deduplication (cost=1.35..1.35 rows=5) (actual time=0.018..0.018 rows=1 loops=1)
-> Filter: (fa.film_id is not null) (cost=0.80 rows=5) (actual time=0.008..0.010 rows=3 loops=1)
-> Covering index lookup on fa using idx_fk_film_id (film_id=200) (cost=0.80 rows=5) (actual time=0.007..0.009 rows=3 loops=1)
这里执行计划出现了 Materialize with deduplication ,这个到底是一个什么意思,今天的问题就从这里开始了。
这里Materialize with deduplication 的意思是,当第一次MYSQL需要这个子查询的结果的情况下,会将临时结果产生为一个临时表,当再次需要这个结果的时候会再次调用。通过给临时表用散列表对表进行索引,索引为唯一索引去除重复值。
这样的好处有两个
1 可以尽量不进行语句的改写
2 可以重复的调用

这个功能本身 materialization=on 设置为ON 才能在查询中使用这个功能
mysql> SELECT @@optimizer_switch\G
*************************** 1. row ***************************
@@optimizer_switch: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on,use_invisible_indexes=off,skip_scan=on,hash_join=on,subquery_to_derived=off,prefer_ordering_index=on,hypergraph_optimizer=off,derived_condition_pushdown=on
下面我们分析一下,什么时候会出现 materialize with deduplication
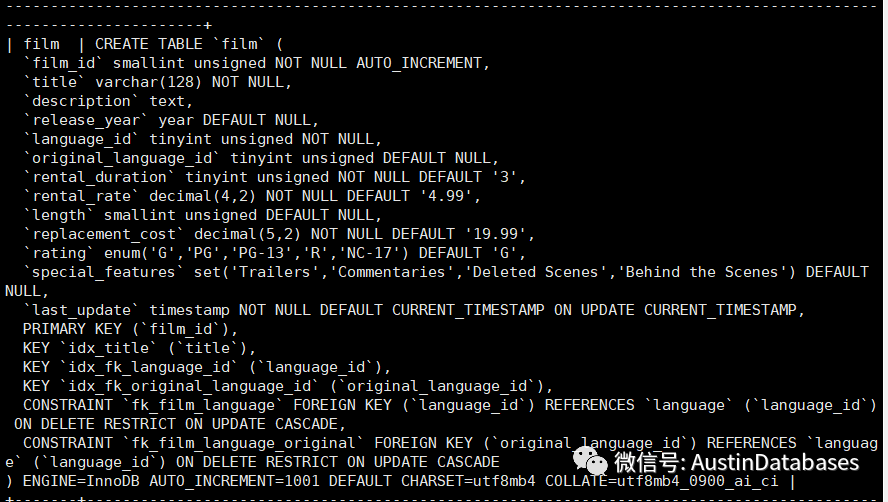
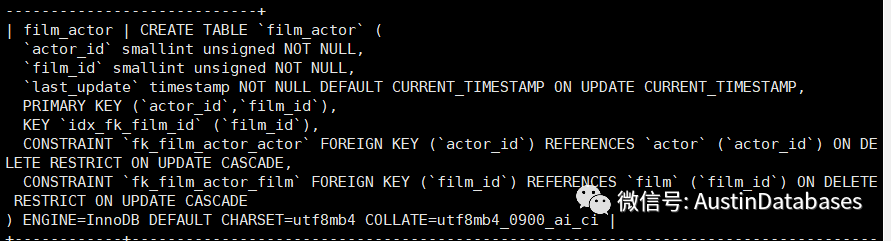
语句1 select film_id,title,last_update from film as fi where fi.film_id in (select fa.film_id from film_actor as fa where fa.film_id = 200);
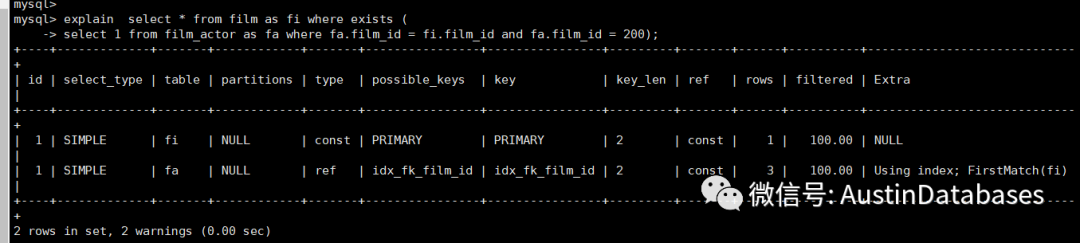
第一个语句并没有出现materialize with deduplication,而是通过索引连接的方式将子查询进行了处理,原因是因为两个表的主键都包含了 film_id 并且子查询中的条件也是主键包含,所以语句优化的过程中并没有出现 materialize with deduplication.
那么我们将条件更换,将子查询中的条件更换为lat_update
select film_id,title,last_update from film as fi where fi.film_id in (select fa.film_id from film_actor as fa where fa.last_update > '2006-12-12');
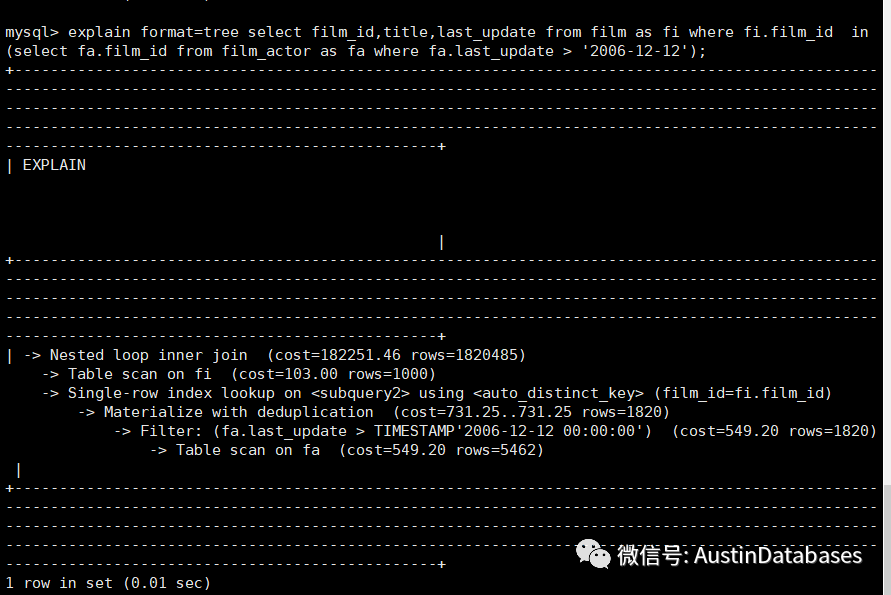
在语句变化后,条件变为了非主键的条件后,就产生了 Materialize with deduplication 同时产生了子查询的结果后,并且结果为一行,将主表和产生的新的临时表进行了 nested loop inner join的操作。
此时我们优化这个查询,因为cost 太高了,我们针对这个查询添加了film_actor 中的字段 last_update的索引。然后在次查看执行计划后,发现整体的cost 大幅度降低。
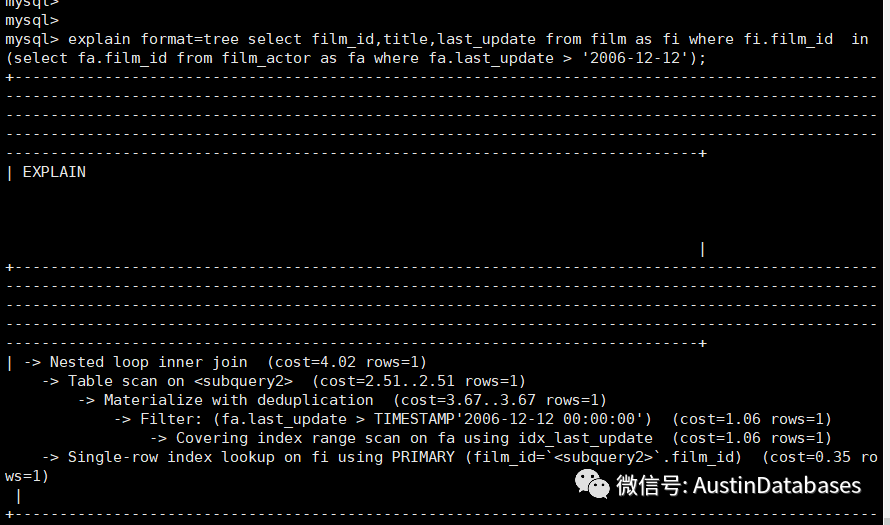
通过这个问题,可以看出虽然有 masterialize with deduplication 但是对于子查询中的数据的过滤还是一个必选项,也可以有效的提高查询的效率。
上面查询中使用了IN 和 EXISTS ,如果我们通过 not in 和 not exists 来看看执行计划是否有变化。通过下面两个语句,可以看到整体的执行计划的改变
explain format=tree select film_id,title,last_update from film as fi where not exists ( select 1 from film_actor as fa where fa.film_id = fi.film_id and fa.last_update > '2005-12-12');
explain format=tree select film_id,title,last_update from film as fi where fi.film_id not in (select fa.film_id from film_actor as fa where fa.last_update > '2005-12-12');
整体的执行计划变更中,虽然使用的 last_update 的索引,但并没有提高查询效率,同时因为是排除在查询中还添加 film_id is not null , 然后使用了MYSQL 8.021 后提供的 antijoin 的方式来进行两个表的反向的数据连接。
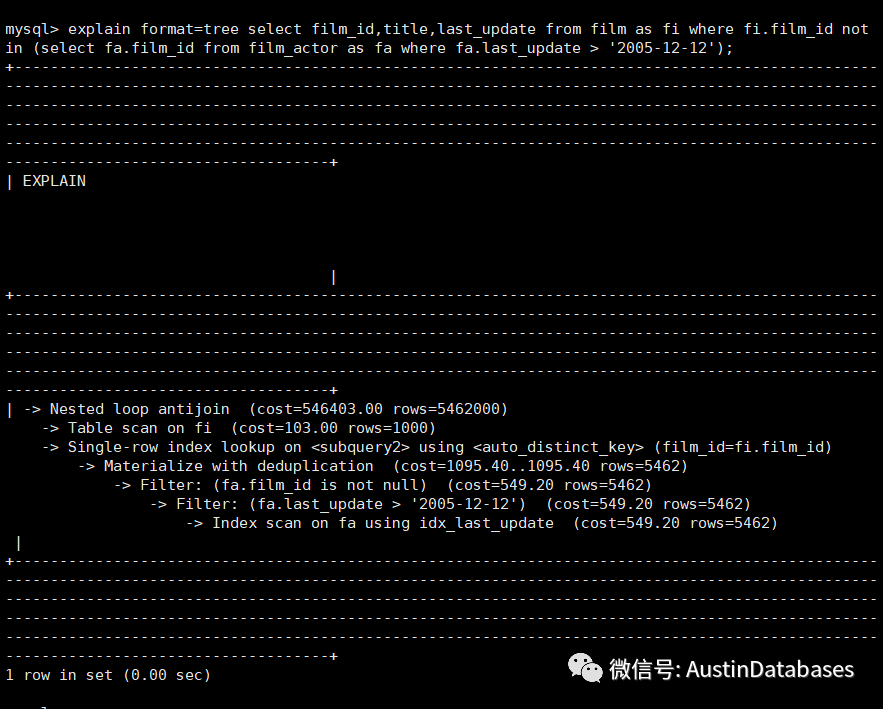
但是整体的数据查询的效率 cost 很高,这也从侧面说明语句在撰写中,尽量还是要避免 NOT IN , NOT EXISTS 。
explain format=tree select count(fi.film_id)
from film as fi
left join film_category as fc on fi.film_id = fc.film_id
and fi.film_id in (select film_id from film_actor as fa where fa.film_id = fi.film_id and fa.film_id = 2);
explain format=tree select count(fi.film_id)
from film as fi
left join film_category as fc on fi.film_id = fc.film_id
and exists (select * from film_actor as fa where fa.film_id = fi.film_id and fa.film_id = 2);
explain analyze select count(fi.film_id)
from film as fi
left join film_category as fc on fi.film_id = fc.film_id
left join film_actor as fa on fa.film_id = fi.film_id and fa.film_id = 2;
上面的三个SQL 看上去要表达一个目的,实际上从结果上看,1 2 SQL 的结果是一致的,第三个用 LEFT JOIN 表达的SQL 的结果和前两个不一样。
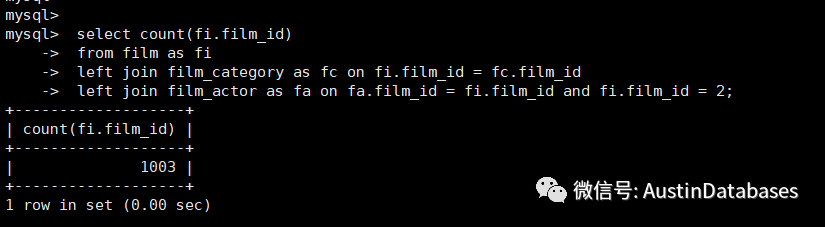
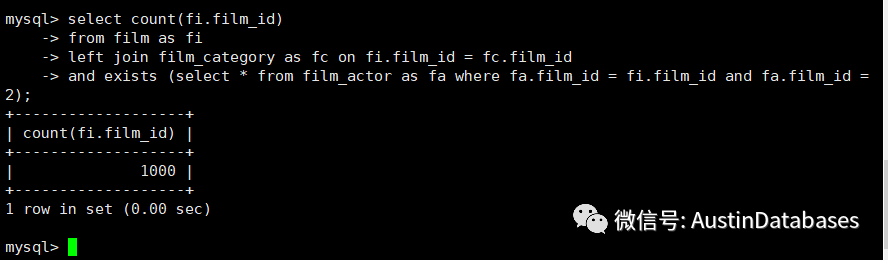
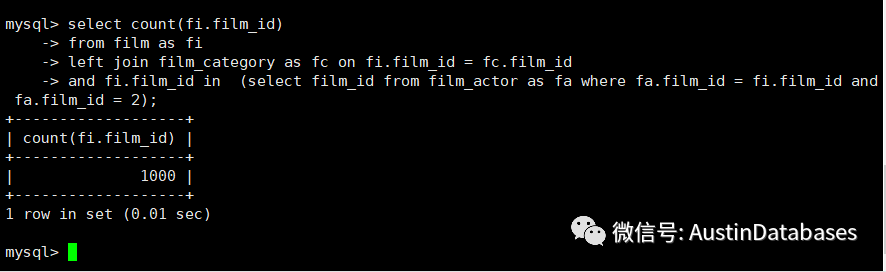
这里结果的不同主要有几个问题
1 IN EXIST 在数据结果查询中,是有去重的功能的。
2 LEFT JOIN 是是存在一对多的关系
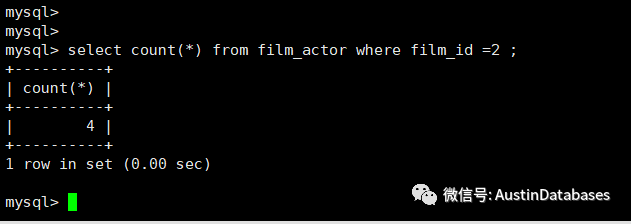
见下图这个就是,通过left JOIN 查询后的数据,明显与上个 EXIST ,IN 的结果中,多个 3个 2 原因是在于

实际上在film_actor 中就存在 4条 film_id =2 的记录,所以LEFT JOIN 如实的包括了4 个2 的记录, 而 EXIST IN 则带有去重的功能,所以在结果中只有一个 2 的记录。
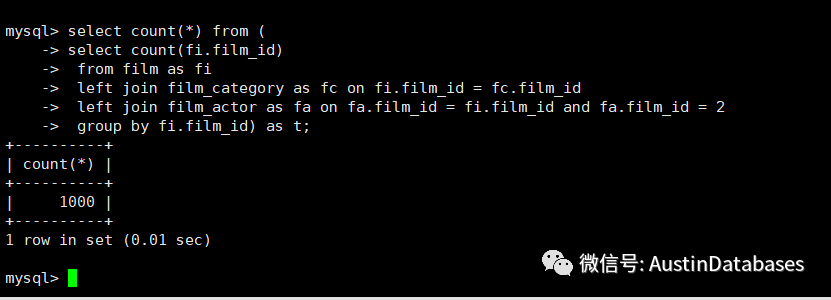
如果要LEFT JOIN 中查询的结果与 EXIST IN 一致则可以在查询语句中加入group by 来去重。
select count(*) from (
select count(fi.film_id)
from film as fi
left join film_category as fc on fi.film_id = fc.film_id
left join film_actor as fa on fa.film_id = fi.film_id and fa.film_id = 2
group by fi.film_id) as t;
所以在撰写语句的时候,要明白 IN EXIST 和 LEFT JOIN 之间的区别,避免结果不是自己要的。