PP-OCRv1
PP-OCR中,对于一张图像,需要完成以下3个步骤提取其中的文字信息:
- 使用文本检测方法,获取文本区域多边形信息(PP-OCR中文本检测使用的是DBNet,因此获取的是四点信息)。
- 对上述文本多边形区域进行裁剪与透视变换校正,将文本区域转化成矩形框,再使用方向分类器对方 向进行校正。
- 基于包含文字区域的矩形框进行文本识别,得到最终识别结果。
经过以上3个步骤便完成了对于一张图像的文本检测与识别过程。 PP-OCR的系统框图如下所示。
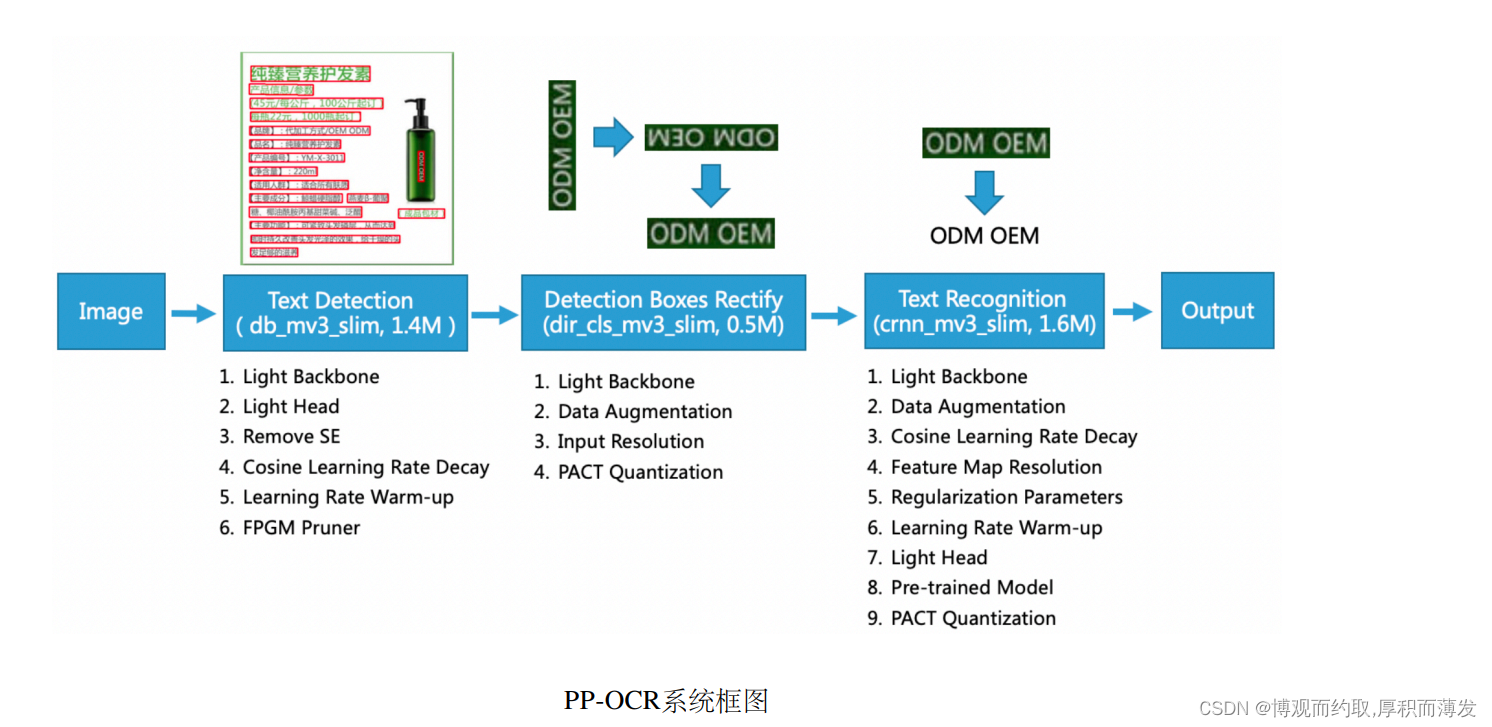
文本检测基于后处理方案比较简单的DBNet,文字区域校正使用几何变换以及方向分类器,文本识别使用基 于融合卷积特征与序列特征的CRNN模型,采用CTC loss解决预测结果与标签不一致的问题。
DBNet算法详解
DB是一个基于分割的文本检测算法,其提出可微分阈值Differenttiable Binarization module(DB module)采用 动态的阈值区分文本区域与背景
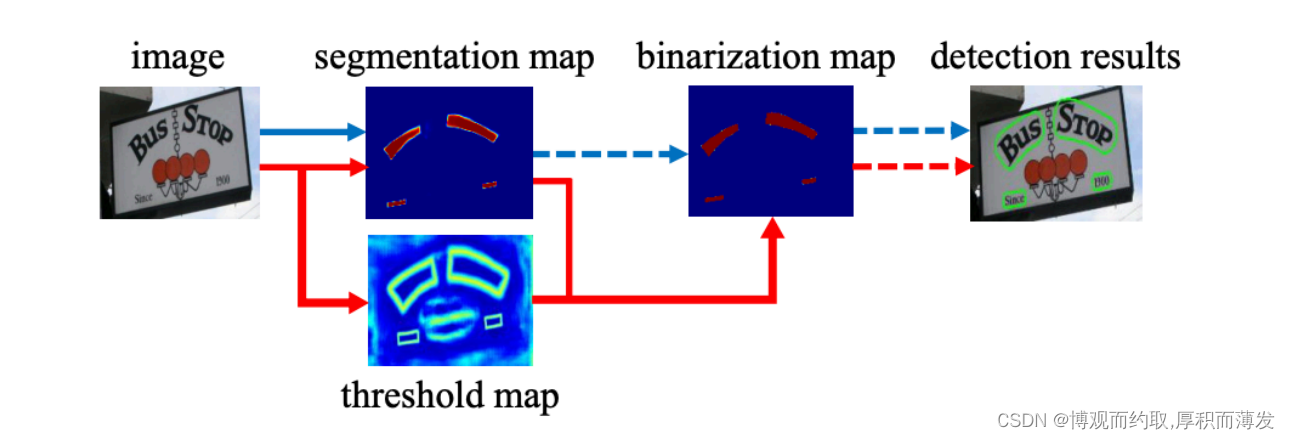
基于分割的普通文本检测算法其流程如上图中的蓝色箭头所示,此类方法得到分割结果之后采用一个固定的 阈值得到二值化的分割图,之后采用诸如像素聚类的启发式算法得到文本区域。 DB算法的流程如图中红色箭头所示,最大的不同在于DB有一个阈值图,通过网络去预测图片每个位置处的 阈值,而不是采用一个固定的值,更好的分离文本背景与前景。标准的二值化方法是不可微的,导致网络无法端对端训练。为了解决这个问题,DB算法提出了可微二值 化(Differentiable Binarization,DB).
CTC算法
CRNN
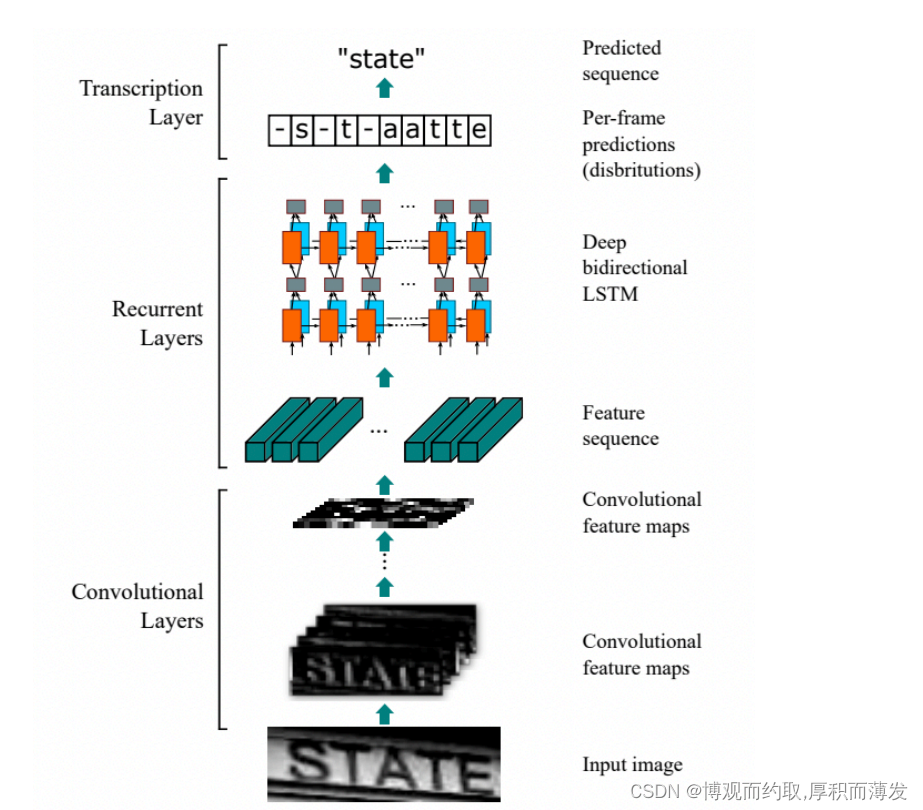
基于 CTC 最典型的算法是CRNN (Convolutional Recurrent Neural Network),它的特征提取部分使用主流的卷 积结构,常用的有ResNet、MobileNet、VGG等。由于文本识别任务的特殊性,输入数据中存在大量的上下文信 息,卷积神经网络的卷积核特性使其更关注于局部信息,缺乏长依赖的建模能力,因此仅使用卷积网络很难 挖掘到文本之间的上下文联系。为了解决这一问题,CRNN文本识别算法引入了双向 LSTM(Long Short-Term Memory) 用来增强上下文建模,通过实验证明双向LSTM模块可以有效的提取出图片中的上下文信息。最终 将输出的特征序列输入到CTC模块,直接解码序列结果。该结构被验证有效,并广泛应用在文本识别任务中。
CRNN属于规则文本识别,即文字不能弯曲。CRNN 的网络结构体系如下所示,从下往上分别为卷积层、递归层和转录层三部分:
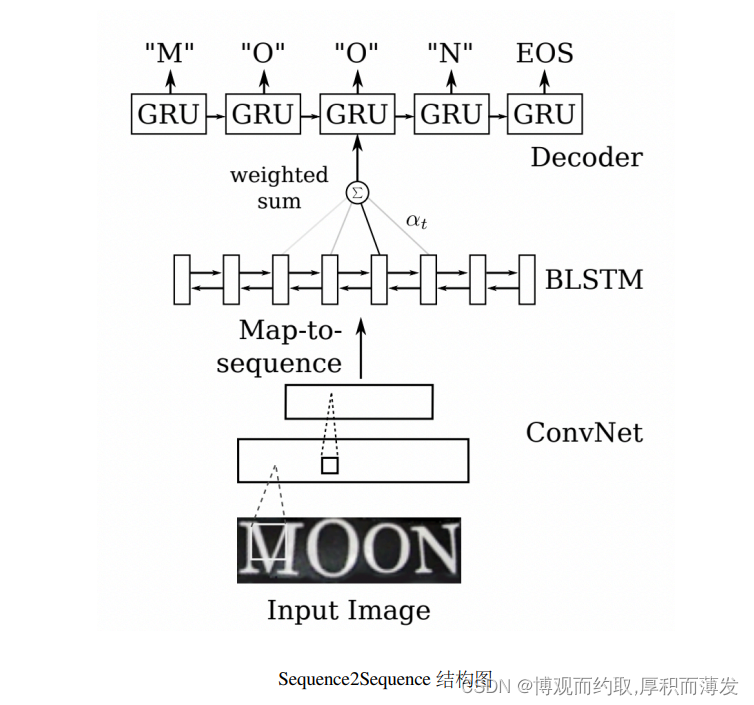
Sequence2Sequence
Sequence2Sequence 算法是由编码器 Encoder 把所有的输入序列都编码成一个统一的语义向量,然后再由解码 器Decoder解码。在解码器Decoder解码的过程中,不断地将前一个时刻的输出作为后一个时刻的输入,循环 解码,直到输出停止符为止。一般编码器是一个RNN,对于每个输入的词,编码器输出向量和隐藏状态,并 将隐藏状态用于下一个输入的单词,循环得到语义向量;解码器是另一个RNN,它接收编码器输出向量并输 出一系列字以创建转换。
以上两个算法在规则文本上都有很不错的效果,但由于网络设计的局限性,这类方法很难解决弯曲和旋转的 不规则文本识别任务。
PP-OCRv2
相比于PP-OCR,PP-OCRv2 在骨干网络、数据增广、损失函数这三个方面进行进一步优化,解决端侧预测效 率较差、背景复杂和相似字符误识等问题,同时引入了知识蒸馏训练策略,进一步提升模型精度。具体地:
- 检测模型优化: (1) 采用 CML 协同互学习知识蒸馏策略;(2) CopyPaste 数据增广策略;
- 识别模型优化: (1) PP-LCNet 轻量级骨干网络;(2) U-DML 改进知识蒸馏策略;(3) Enhanced CTC loss 损 失函数改进。 从效果上看,主要有三个方面提升:
- 在模型效果上,相对于 PP-OCR mobile 版本提升超7%;
- 在速度上,相对于 PP-OCR server 版本提升超过220%;
- 在模型大小上,11.6M 的总大小,服务器端和移动端都可以轻松部署。
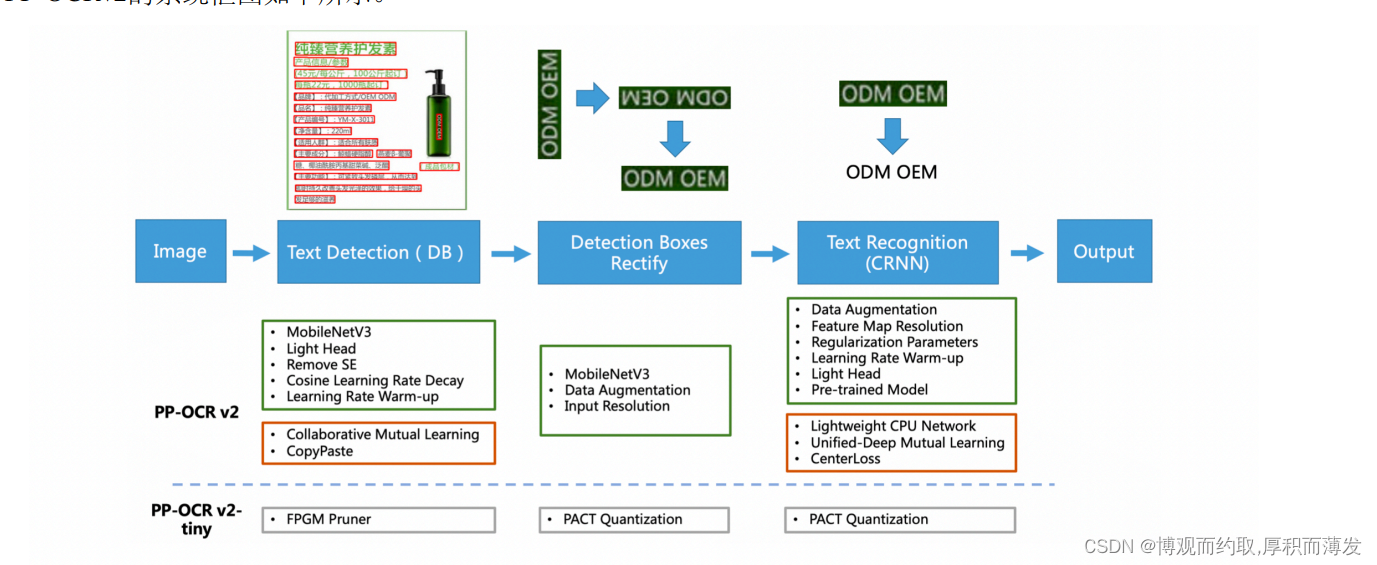
PP-OCRv3
具体的优化策略包括:
检测模块
- LK-PAN:大感受野的PAN结构
- DML:教师模型互学习策略
- RSE-FPN:残差注意力机制的FPN结构
识别模块
- SVTR_LCNet:轻量级文本识别网络
- GTC:Attention指导CTC训练策略
- TextConAug:挖掘文字上下文信息的数据增广策略
- TextRotNet:自监督的预训练模型
- UDML:联合互学习策略
- UIM:无标注数据挖掘方案
超轻量OCR系统PP-OCRv3技术解读 - 知乎 (zhihu.com)
PP-OCRv4
PP-OCRv4在PP-OCRv3的基础上进一步升级。整体的框架图保持了与PP-OCRv3相同的pipeline,针对检测模型和识别模型进行了数据、网络结构、训练策略等多个模块的优化。 PP-OCRv4系统框图如下所示:
从算法改进思路上看,分别针对检测和识别模型,进行了共10个方面的改进:
- 检测模块:
- LCNetV3:精度更高的骨干网络
- PFHead:并行head分支融合结构
- DSR: 训练中动态增加shrink ratio
- CML:添加Student和Teacher网络输出的KL div loss
- 识别模块:
- SVTR_LCNetV3:精度更高的骨干网络
- Lite-Neck:精简的Neck结构
- GTC-NRTR:稳定的Attention指导分支
- Multi-Scale:多尺度训练策略
- DF: 数据挖掘方案
- DKD :DKD蒸馏策略
从效果上看,速度可比情况下,多种场景精度均有大幅提升:
- 中文场景,相对于PP-OCRv3中文模型提升超4%;
- 英文数字场景,相比于PP-OCRv3英文模型提升6%;
- 多语言场景,优化80个语种识别效果,平均准确率提升超8%。
PP-StructureV1
PP-Structure是一个可用于复杂文档结构分析和处理的OCR工具包,旨在帮助开发者更好的完成文档理解相关任务
PP-Structure的主要特性如下:
- 支持对图片形式的文档进行版面分析,可以划分文字、标题、表格、图片以及列表5类区域(与Layout-Parser联合使用)
- 支持文字、标题、图片以及列表区域提取为文字字段(与PP-OCR联合使用)
- 支持表格区域进行结构化分析,最终结果输出Excel文件
- 支持python whl包和命令行两种方式,简单易用
- 支持版面分析和表格结构化两类任务自定义训练
- 支持文档视觉问答(Document Visual Question Answering,DocVQA)任务-语义实体识别(Semantic Entity Recognition,SER)和关系抽取(Relation Extraction,RE)
PP-StructureV2
PP-StructureV2在PP-StructureV1的基础上进一步改进,主要有以下3个方面升级:
- 系统功能升级 :新增图像矫正和版面复原模块,图像转word/pdf、关键信息抽取能力全覆盖!
- 系统性能优化 :
- 版面分析:发布轻量级版面分析模型,速度提升11倍,平均CPU耗时仅需41ms!
- 表格识别:设计3大优化策略,预测耗时不变情况下,模型精度提升6%。
- 关键信息抽取:设计视觉无关模型结构,语义实体识别精度提升2.8%,关系抽取精度提升9.1%。
- 中文场景适配 :完成对版面分析与表格识别的中文场景适配,开源开箱即用的中文场景版面结构化模型!
PP-StructureV2系统流程图如下所示,文档图像首先经过图像矫正模块,判断整图方向并完成转正,随后可以完成版面信息分析与关键信息抽取2类任务。版面分析任务中,图像首先经过版面分析模型,将图像划分为文本、表格、图像等不同区域,随后对这些区域分别进行识别,如,将表格区域送入表格识别模块进行结构化识别,将文本区域送入OCR引擎进行文字识别,最后使用版面恢复模块将其恢复为与原始图像布局一致的word或者pdf格式的文件;关键信息抽取任务中,首先使用OCR引擎提取文本内容,然后由语义实体识别模块获取图像中的语义实体,最后经关系抽取模块获取语义实体之间的对应关系,从而提取需要的关键信息。
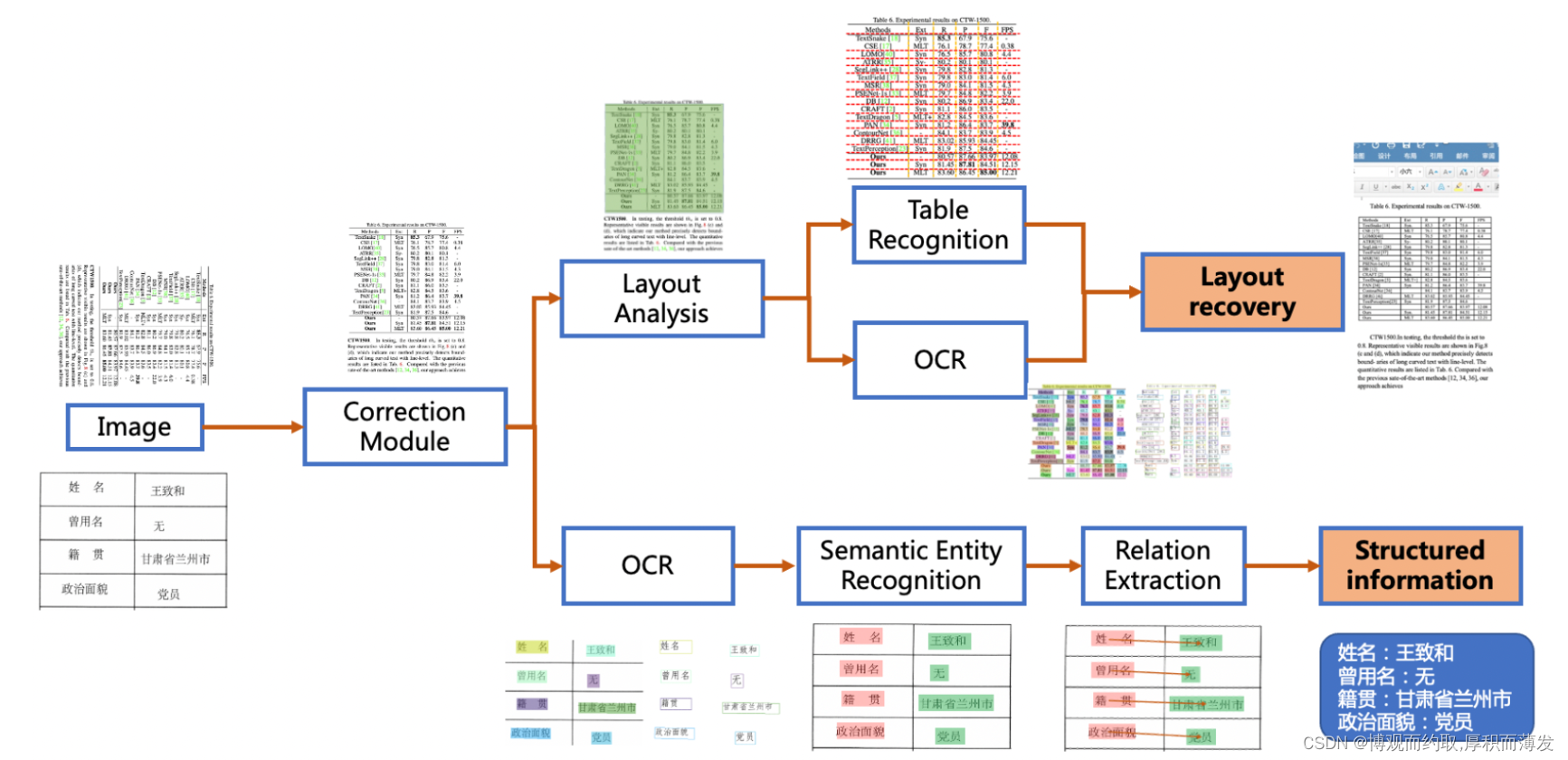
从算法改进思路来看,对系统中的3个关键子模块,共进行了8个方面的改进。
-
版面分析
- PP-PicoDet:轻量级版面分析模型
- FGD:兼顾全局与局部特征的模型蒸馏算法
-
表格识别
- PP-LCNet: CPU友好型轻量级骨干网络
- CSP-PAN:轻量级高低层特征融合模块
- SLAHead:结构与位置信息对齐的特征解码模块
-
关键信息抽取
- VI-LayoutXLM:视觉特征无关的多模态预训练模型结构
- TB-YX:考虑阅读顺序的文本行排序逻辑
- UDML:联合互学习知识蒸馏策略
最终,与PP-StructureV1相比:
- 版面分析模型参数量减少95.6%,推理速度提升11倍,精度提升0.4%;
- 表格识别预测耗时不变,模型精度提升6%,端到端TEDS提升2%;
- 关键信息抽取模型速度提升2.8倍,语义实体识别模型精度提升2.8%;关系抽取模型精度提升9.1%。
PaddleOCR/ppstructure/docs/PP-StructureV2_introduction.md at release/2.7 · PaddlePaddle/PaddleOCR · GitHub