Stream load 是一个同步的导入方式,用户通过发送 HTTP 协议发送请求将本地文件或数据流导入到 Doris 中。Stream load 同步执行导入并返回导入结果。用户可直接通过请求的返回体判断本次导入是否成功。
适用场景
Stream load 主要适用于导入本地文件,或通过程序导入数据流中的数据。
目前 Stream Load 支持两个数据格式:CSV(文本)和 JSON。
基本原理
下图展示了 Stream load 的主要流程,省略了一些导入细节。
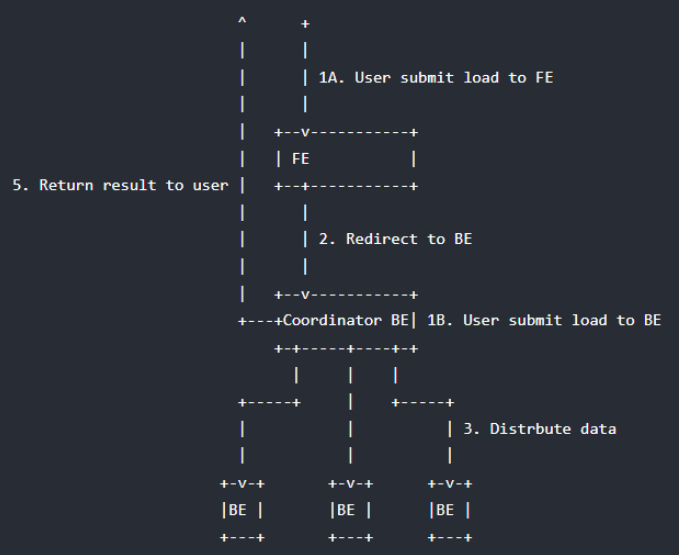
Stream load 中,Doris 会选定一个节点作为 Coordinator 节点。该节点负责接数据并分发数据到其他数据节点。
用户通过 HTTP 协议提交导入命令。如果提交到 FE,则 FE 会通过 HTTP redirect 指令将请求转发给某一个 BE。用户也可以直接提交导入命令给某一指定 BE。
导入的最终结果由 Coordinator BE 返回给用户。
基本语法
Stream load 通过 HTTP 协议提交和传输数据。这里通过 curl 命令展示如何提交导入。
用户也可以通过其他 HTTP client 进行操作。
curl --location-trusted -u user:passwd [-H ""...] -T data.file -
XPUT http://fe_host:http_port/api/{db}/{table}/_stream_load
Header 中支持属性见下面的 ‘导入任务参数’说明。
格式为: -H "key1:value1"
创建导入的详细语法帮助执行 HELP STREAM LOAD 查看, 下面主要介绍创建 Stream load 的部分参数意义。
1)签名参数
user/passwd
Stream load 由于创建导入的协议使用的是 HTTP 协议,通过 Basic access authentication 进行签名。Doris 系统会根据签名验证用户身份和导入权限。
2)导入任务参数
Stream load 由于使用的是 HTTP 协议,所以所有导入任务有关的参数均设置在Header 中。下面主要介绍了 Stream load 导入任务参数的部分参数意义。
Label
导入任务的标识
column_separator
用于指定导入文件中的列分隔符,默认为\t。如果是不可见字符,则需要加\x 作为前缀,使用十六进制来表示分隔符。
如 hive 文件的分隔符\x01,需要指定为-H "column_separator:\x01"。
可以使用多个字符的组合作为列分隔符。
line_delimiter
用于指定导入文件中的换行符,默认为\n。
可以使用做多个字符的组合作为换行符。
max_filter_ratio
导入任务的最大容忍率
where
导入任务指定的过滤条件。Stream load 支持对原始数据指定 where 语句进行过滤。被过滤的数据将不会被导入,也不会参与 filter ratio 的计算,但会被计入num_rows_unselected。
partition
待导入表的 Partition 信息,如果待导入数据不属于指定的 Partition 则不会被导入。这些数据将计入 dpp.abnorm.ALL
columns
待导入数据的函数变换配置,目前 Stream load 支持的函数变换方法包含列的顺序变化以及表达式变换,其中表达式变换的方法与查询语句的一致。
列顺序变换例子:原始数据有三列(src_c1,src_c2,src_c3), 目前 doris 表也有三列(dst_c1,dst_c2,dst_c3)
如果原始表的 src_c1 列对应目标表 dst_c1 列,原始表的 src_c2 列对应目标表 dst_c2 列,原始表的 src_c3 列对应目标表 dst_c3 列,则写法如下:
columns: dst_c1, dst_c2, dst_c3
如果原始表的 src_c1 列对应目标表 dst_c2 列,原始表的 src_c2 列对应目标表 dst_c3 列,原始表的 src_c3 列对应目标表 dst_c1 列,则写法如下:
columns: dst_c2, dst_c3, dst_c1
表达式变换例子:原始文件有两列,目标表也有两列(c1,c2)但是原始文件的两列均需要经过函数变换才能对应目标表的两列,则写法如下:
columns: tmp_c1, tmp_c2, c1 = year(tmp_c1), c2 = month(tmp_c2)
其中 tmp_*是一个占位符,代表的是原始文件中的两个原始列。
exec_mem_limit
导入内存限制。默认为 2GB,单位为字节。
two_phase_commit
Stream load 导入可以开启两阶段事务提交模式。开启方式为在 HEADER 中声明two_phase_commit=true 。默认的两阶段批量事务提交为关闭。 两阶段批量事务提交模式的意思是:Stream load 过程中,数据写入完成即会返回信息给用户,此时数据不可见,事务状态为 PRECOMMITTED,用户手动触发 commit 操作之后,数据才可见。
用户可以调用如下接口对 stream load 事务触发 commit 操作:
curl -X PUT --location-trusted -u user:passwd -H "txn_id:txnId" -H
"txn_operation:commit"
http://fe_host:http_port/api/{db}/_stream_load_2pc
或
curl -X PUT --location-trusted -u user:passwd -H "txn_id:txnId" -H
"txn_operation:commit"
http://be_host:webserver_port/api/{db}/_stream_load_2pc
用户可以调用如下接口对 stream load 事务触发 abort 操作:
curl -X PUT --location-trusted -u user:passwd -H "txn_id:txnId" -H
"txn_operation:abort"
http://fe_host:http_port/api/{db}/_stream_load_2pc
或
curl -X PUT --location-trusted -u user:passwd -H "txn_id:txnId" -H
"txn_operation:abort"
http://be_host:webserver_port/api/{db}/_stream_load_2pc
导入示例
curl --location-trusted -u root -H "label:123" -
H"column_separator:," -T student.csv -X PUT
http://hadoop1:8030/api/test_db/student_result/_stream_load
由于 Stream load 是一种同步的导入方式,所以导入的结果会通过创建导入的返回值直接返回给用户。
注意:由于 Stream load 是同步的导入方式,所以并不会在 Doris 系统中记录导入信息,用户无法异步的通过查看导入命令看到 Stream load。使用时需监听创建导入请求的返回值获取导入结果。
取消导入
用户无法手动取消 Stream load,Stream load 在超时或者导入错误后会被系统自动取消。
Stream Load 是一个同步的导入方式,用户通过发送 HTTP 协议将本地文件或数据流导入到Doris 中,Stream load 同步执行导入并返回结果。用户可以直接通过返回判断导入是否成功。








![【多属性对象“{a:1,b:2}”】与【单属性对象的数组“[{a:1},{b:2}]”】的相互转换](https://img-blog.csdnimg.cn/5425be6aa4e9474cb5cc105429aa8f50.png)