目录
面试官:Redis的内存用完了会发生什么?
面试官:Redis分布式锁如何实现 ?
面试官:好的,那你如何控制Redis实现分布式锁有效时长呢?
面试官:好的,redisson实现的分布式锁是可重入的吗?
面试官:redisson实现的分布式锁能解决主从一致性的问题吗
面试官:好的,如果业务非要保证数据的强一致性,这个该怎么解决呢?
面试官:Redis的内存用完了会发生什么?
候选人:
嗯~,这个要看redis的数据淘汰策略是什么,如果是默认的配置,redis内存用完以后则直接报错。我们当时设置的 allkeys-lru 策略。把最近最常访问的数据留在缓存中。
面试官:Redis分布式锁如何实现 ?
候选人:嗯,在redis中提供了一个命令setnx(SET if not exists)
由于redis的单线程的,用了命令之后,只能有一个客户端对某一个key设置值,在没有过期或删除key的时候是其他客户端是不能设置这个key的

面试官:如何控制Redis实现分布式锁有效时长呢?
候选人:嗯,的确,redis的setnx指令不好控制这个问题,我们当时采用的redis的一个框架redisson实现的。
在redisson中需要手动加锁,并且可以控制锁的失效时间和等待时间,当锁住的一个业务还没有执行完成的时候,在redisson中引入了一个看门狗机制,就是说每隔一段时间就检查当前业务是否还持有锁,如果持有就增加加锁的持有时间,当业务执行完成之后需要使用释放锁就可以了
还有一个好处就是,在高并发下,一个业务有可能会执行很快,先客户1持有锁的时候,客户2来了以后并不会马上拒绝,它会自旋不断尝试获取锁,如果客户1释放之后,客户2就可以马上持有锁,性能也得到了提升。
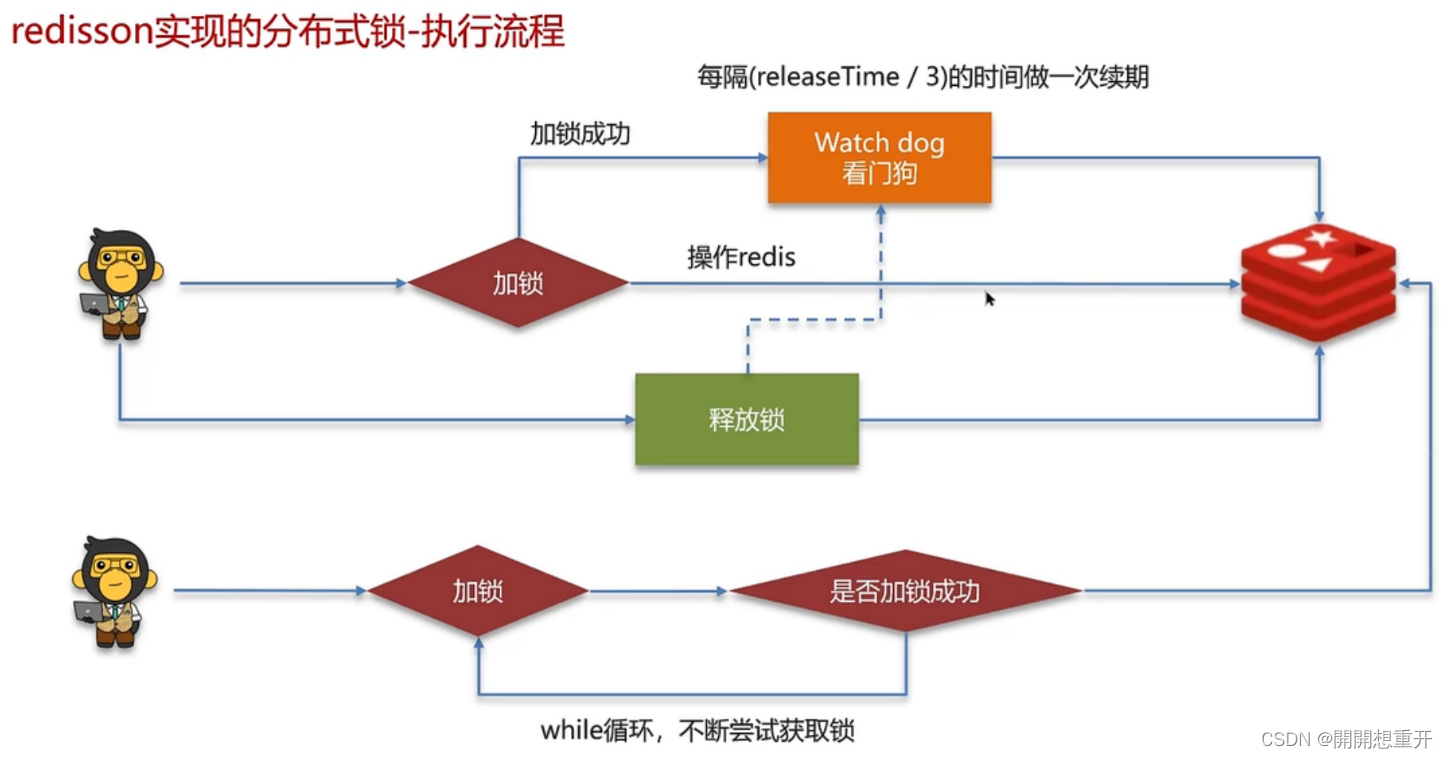
加锁,设置过期时间等操作都是基于lua脚本完成,保证代码的原子性。
面试官:redisson实现的分布式锁是可重入的吗?
候选人:嗯,是可以重入的。这样做是为了避免死锁的产生。这个重入其实在内部就是判断是否是当前线程持有的锁,如果是当前线程持有的锁就会计数,如果释放锁就会在计算上减一。在存储数据的时候采用的hash结构,大key可以按照自己的业务进行定制,其中小key是当前线程的唯一标识,value是当前线程重入的次数
Redis实现的分布式锁是不可重入的,Redisson实现的分布式锁是可重入的。
面试官:redisson实现的分布式锁能解决主从一致性的问题吗
候选人:这个是不能的,比如,当线程1加锁成功后,master节点数据会异步复制到slave节点,此时当前持有Redis锁的master节点宕机,slave节点被提升为新的master节点,假如现在来了一个线程2,再次加锁,会在新的master节点上加锁成功,这个时候就会出现两个节点同时持有一把锁的问题。
我们可以利用redisson提供的红锁来解决这个问题,它的主要作用是,不能只在一个redis实例上创建锁,应该是在多个redis实例上创建锁,并且要求在大多数redis节点上都成功创建锁,红锁中要求是redis的节点数量要过半。这样就能避免线程1加锁成功后master节点宕机导致线程2成功加锁到新的master节点上的问题了。
但是,如果使用了红锁,因为需要同时在多个节点上都添加锁,性能就变的很低了,并且运维维护成本也非常高,所以,我们一般在项目中也不会直接使用红锁,并且官方也暂时废弃了这个红锁

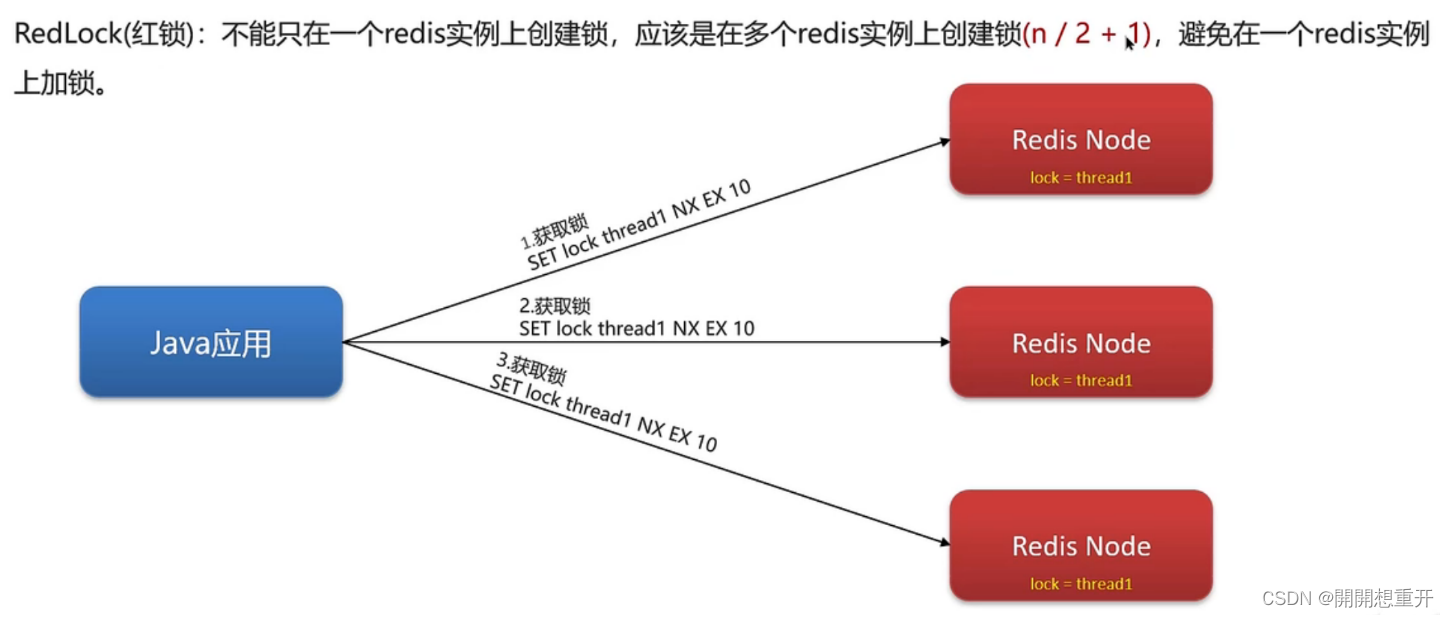
红锁:实现复杂,性能差,运维繁琐。
面试官:如果业务非要保证数据的强一致性,这个该怎么解决呢?
候选人:嗯~,redis本身就是支持高可用的,做到强一致性,就非常影响性能,所以,如果有强一致性要求高的业务,建议使用zookeeper实现的分布式锁,它是可以保证强一致性的。
Redis:AP思想,保证数据的最终一致性。
zookeeper:CP思想,保证数据的强一致性