笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~
属性级情感分析
- 简介
- 数据集介绍
- 数据加载和预处理(data_utils.py)
- 预训练模型(skep)
- 模型定义模块(model.py)
- 训练配置(config.py)
- 模型训练(train.py)
- 模型测试(test.py)
- 准确率、精确率、召回率和F1值
- 模型预测(predict.py)
- 参考
简介
属性级情感分析是指在文本情感分析的基础上,进一步对文本中涉及的具体属性或方面进行情感分析。传统的文本情感分析通常只关注整体文本的情感极性(如正面、负面、中性),而属性级情感分析则致力于识别文本中针对特定属性或方面的情感倾向,从而更细粒度地理解用户对产品、服务或事件各个方面的态度和情感。
属性级情感分析通常涉及以下几个主要步骤:
-
属性抽取:首先需要从文本中提取出与具体属性相关的词语或短语,这些属性可以是产品的特定特征(如外观、性能、价格)、服务的某个方面(如客户服务、物流配送)、事件的具体方面等。
-
情感分类:针对每个提取出的属性,对文本中表达的情感进行分类,通常包括积极的、消极的、中性的情感极性。这一步通常需要使用文本分类或情感分类模型来识别文本中针对特定属性的情感倾向。
-
结果汇总:将针对不同属性的情感分类结果进行汇总,形成对整体文本的属性级情感分析结果。这样可以更清晰地了解用户对各个属性的态度和情感倾向,为产品改进、服务优化或舆情监控提供更详细的参考信息。
属性级情感分析在产品评测、社交媒体舆情分析、消费者意见挖掘等领域具有重要应用,可以帮助企业更全面地了解用户需求和反馈,从而有针对性地改进产品和服务。
数据集介绍
训练集 len(train_ds)=800
验证集 len(dev_ds)=100
测试集 len(test_ds)=100
第1列是标签
第2列是属性观点
第3列是原文

数据加载和预处理(data_utils.py)
数据加载和预处理部分:
- 加载数据集:从文件中加载训练、验证和测试数据集

- 数据映射:使用预训练模型skep_ernie_1.0_large_ch的分词器对文本进行分词和编码,将每个样本的文本转换成特征形式。

- 构造DataLoader:创建训练、验证和测试数据的批次采样器,构造数据加载器。
len(train_loader) 200= len(train_ds) 800 / batch_size 4 # batch_size每个批次(batch)包含的样本数
预训练模型(skep)
Skep模型作为基础模型
SKEP(Sentiment Knowledge Enhanced Pre-training)是一种基于情感知识增强的预训练模型。百度自然语言处理实验室
Skep采用的预训练语言模型是Ernie(Enhanced Representation through kNowledge IntEgration)模型
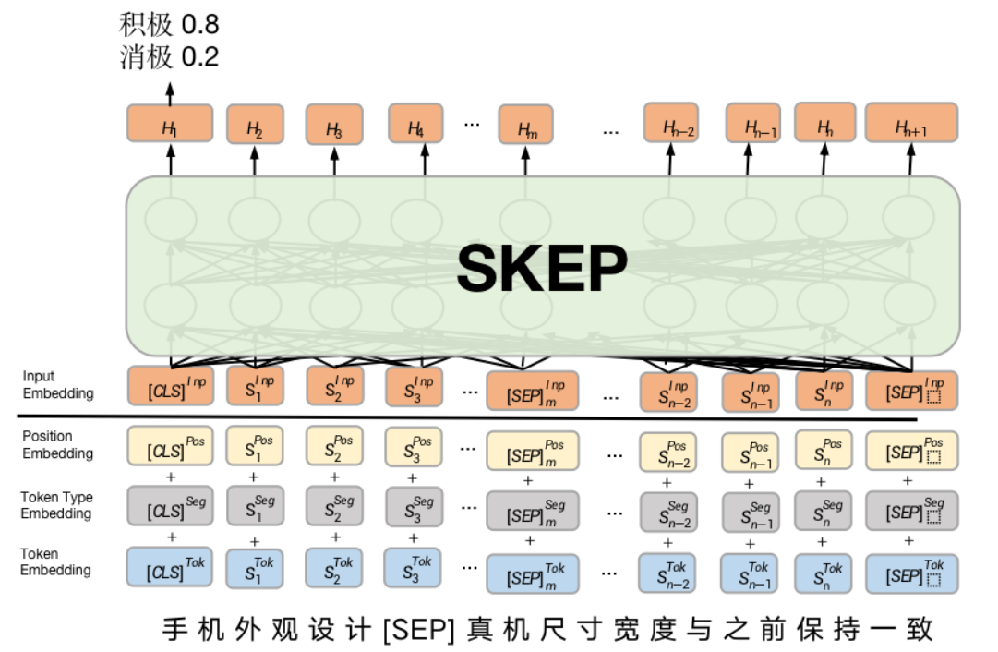
输入有两部分:
评价的属性(Aspect)、相应的评论文本
将两者拼接之后便可以传入SKEP模型中,SKEP模型对该文本串进行语义编码
根据该语义编码向量进行情感分类
模型定义模块(model.py)
定义了一个基于Skep模型的序列分类器(Sequence Classification)。它使用预训练的Skep模型作为基础,并在其顶部添加了一层线性分类器。
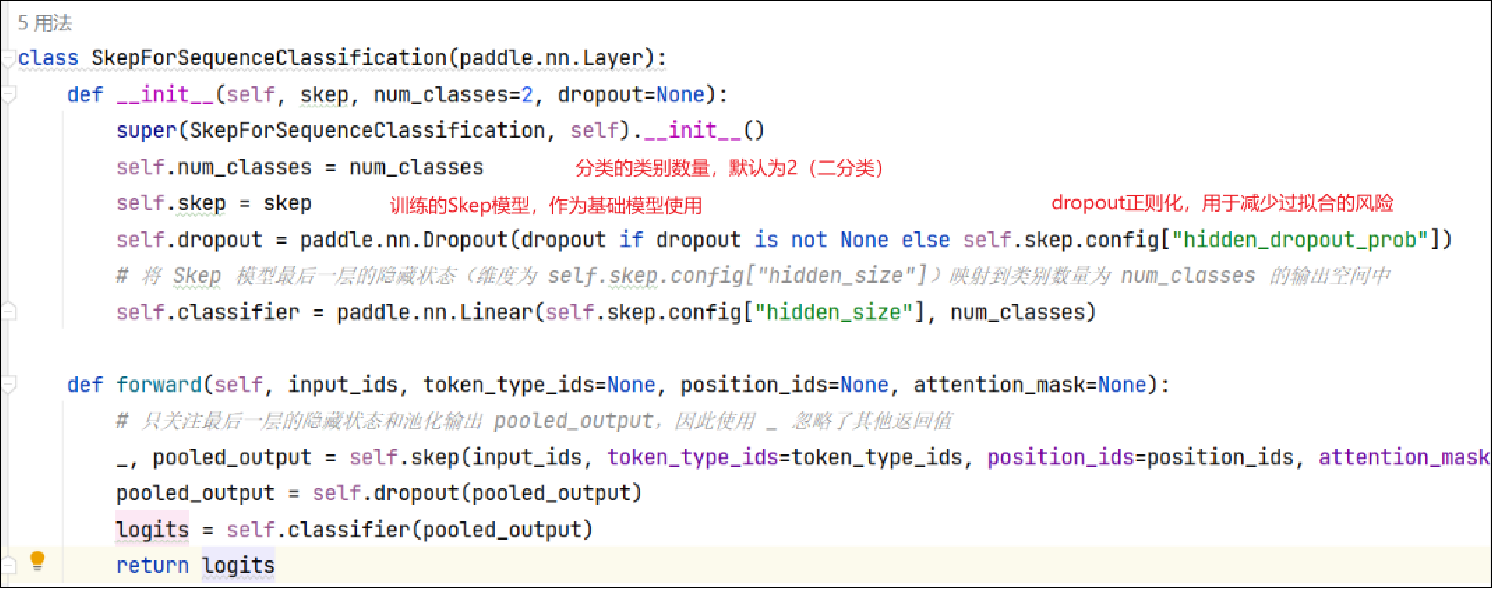
- 初始化方法(
__init__)接受Skep模型、类别数量和可选的dropout参数作为输入。 - 在初始化方法中,首先调用父类的
__init__方法,然后设置类别数量和Skep模型。 - 初始化方法还通过检查dropout参数是否提供来确定是否使用默认的隐藏层dropout概率。
forward方法实现了正向传播逻辑。接受输入的文本序列(input_ids)以及可选的token_type_ids、position_ids和attention_mask参数。- 在正向传播过程中,它通过调用Skep模型获取最后一层的隐藏状态和池化输出(pooled_output)。
- 然后,将池化输出应用于dropout操作,并通过线性分类器将结果映射到类别数量为num_classes的输出空间中。
- 最终,返回分类器的输出(logits)。
训练配置(config.py)
# 训练配置:设置训练超参数,如学习率、权重衰减、最大梯度范数等,并创建优化器、学习率调度器和评估指标
num_epoch = 20 # 训练的轮数,即遍历整个训练数据集的次数
learning_rate = 4e-5 # 初始学习率,表示每次参数更新时的步长大小
weight_decay = 0.01 # 正则化项的权重衰减系数,用于防止过拟合
warmup_proportion = 0.1 # 学习率预热的比例,用于在训练初期逐渐增加学习率,以提高训练的稳定性
max_grad_norm = 1.0 # 梯度裁剪的最大范数,用于控制梯度的大小,防止梯度爆炸问题
log_step = 20 # 每隔多少步打印一次训练日志信息
eval_step = 100 # 每隔多少步进行一次模型评估
seed = 1000 # 随机种子,用于控制随机过程的可重现性
checkpoint = "./checkpoint/" # 保存模型训练参数的路径
num_training_steps = len(train_loader) * num_epoch
# 学习率调度器 lr_scheduler,使用的是线性衰减加预热的策略。
lr_scheduler = LinearDecayWithWarmup(learning_rate=learning_rate, total_steps=num_training_steps, warmup=warmup_proportion)
# 获取模型中不属于偏置(bias)或归一化(norm)参数的所有其他参数的名称
decay_params = [p.name for n, p in model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])]
# 梯度裁剪器,通过全局梯度范数对梯度进行裁剪,用于控制梯度的最大范数,防止梯度爆炸问题
grad_clip = paddle.nn.ClipGradByGlobalNorm(max_grad_norm)
# 优化器,使用的是 AdamW 优化算法
optimizer = paddle.optimizer.AdamW(learning_rate=lr_scheduler, parameters=model.parameters(), weight_decay=weight_decay, apply_decay_param_fun=lambda x: x in decay_params, grad_clip=grad_clip)
# 同时计算准确率(Accuracy)和 F1 值
metric = AccuracyAndF1()
模型训练(train.py)
训练一个文本分类模型并评估其性能
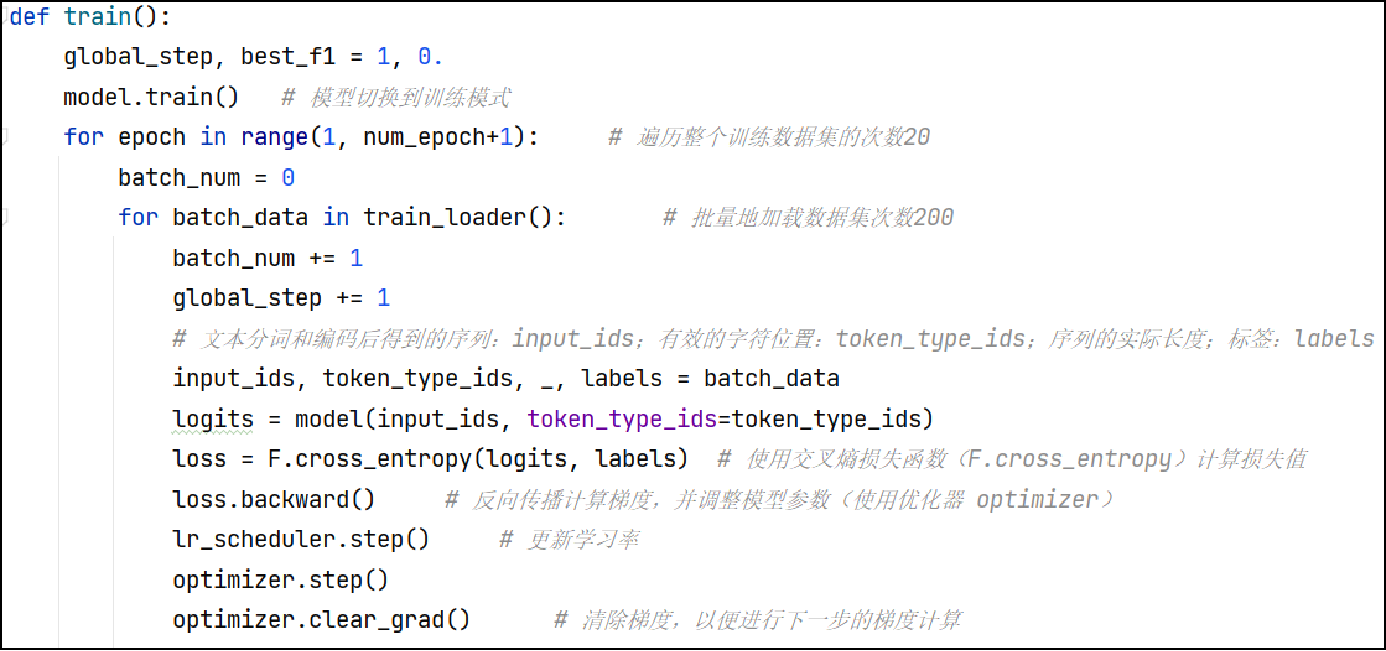
- 定义训练模型的函数train,该函数使用训练集进行模型训练,并在一定步骤上评估模型并保存最佳模型。
- 在train函数中,切换模型到训练模式,然后遍历每个epoch和每个batch的数据。
- 对于每个batch的数据,计算模型的预测结果并计算损失值。
- 根据损失值进行反向传播计算梯度,并使用优化器更新模型参数。
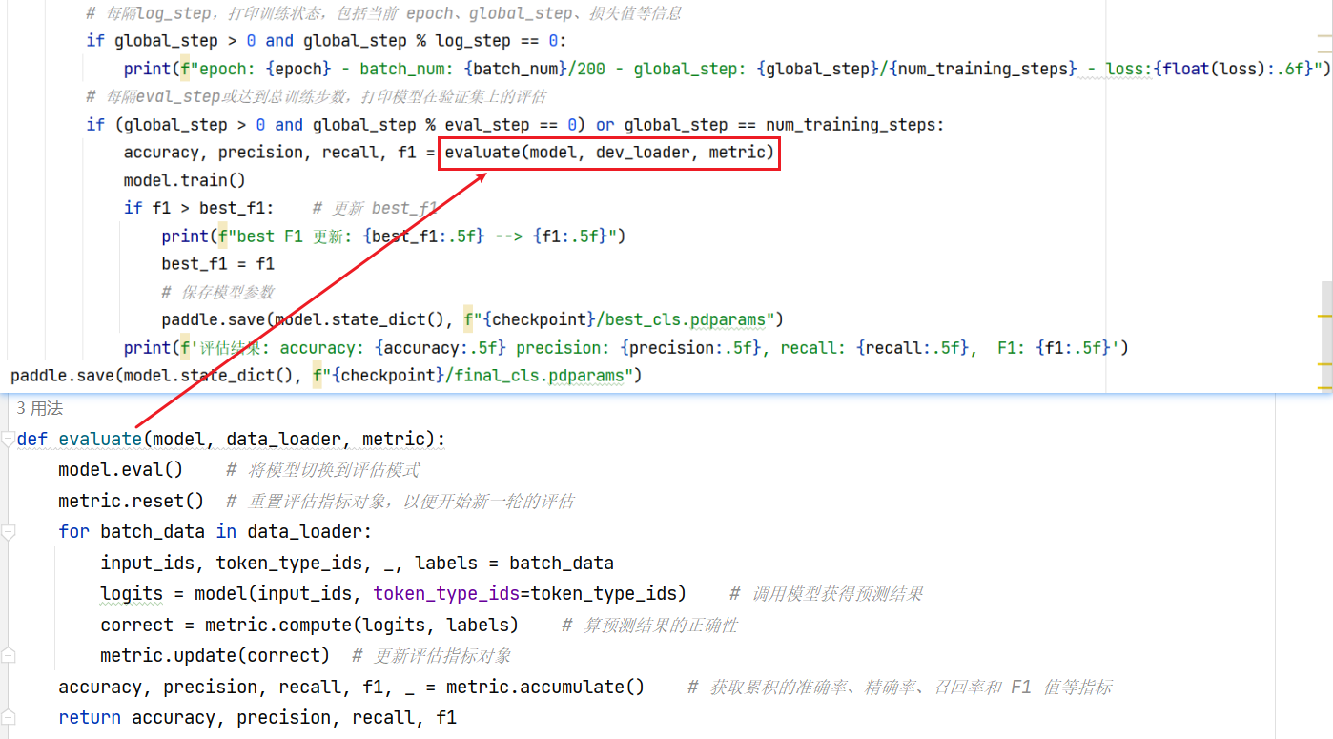
- 定义评估模型的函数evaluate,该函数会在验证集上计算准确率、精确率、召回率和F1值。
- 每隔一定步骤(log_step),打印训练状态信息,包括当前epoch、batch数、global_step和损失值。
- 每隔一定步骤(eval_step)或达到总训练步数(num_training_steps),在验证集上评估模型性能。
调用evaluate函数计算准确率、精确率、召回率和F1值。
如果F1值超过之前记录的最佳F1值,则更新最佳F1值并保存模型参数。
打印评估结果,包括准确率、精确率、召回率和F1值。 - 最后,保存最终的模型参数。
模型测试(test.py)
加载已训练好的文本分类模型并在测试集上进行评估
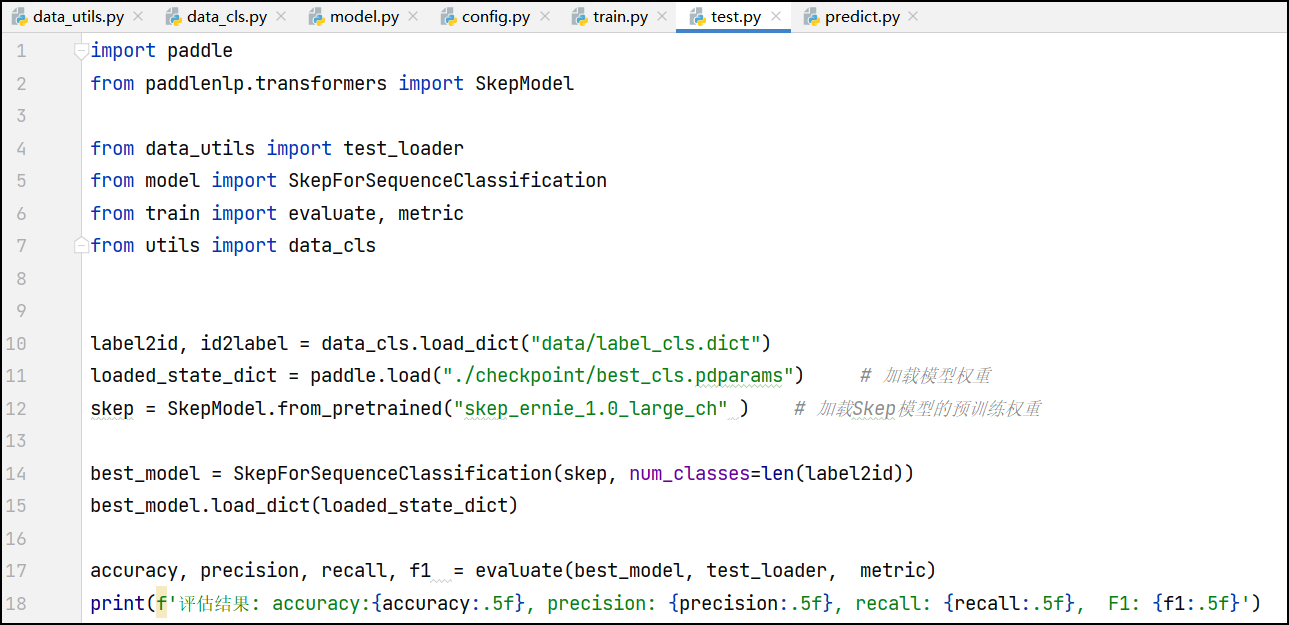
具体的步骤如下:
- 导入所需的库和模块。
- 使用
data_cls.load_dict函数加载训练时使用的标签字典,该字典用于将标签映射为类别id和将类别id映射为标签。 - 使用
paddle.load函数加载之前保存的最佳模型权重。 - 使用
SkepModel.from_pretrained函数加载Skep模型的预训练权重。 - 创建一个新的
SkepForSequenceClassification模型,该模型包含从Skep模型中提取的特征和一个用于分类的全连接层,并根据类别数量设置了输出维度。 - 使用
best_model.load_dict方法加载之前保存的最佳模型权重。 - 调用
evaluate函数,在测试集上评估加载的模型。 - 打印评估结果,包括准确率、精确率、召回率和F1值。
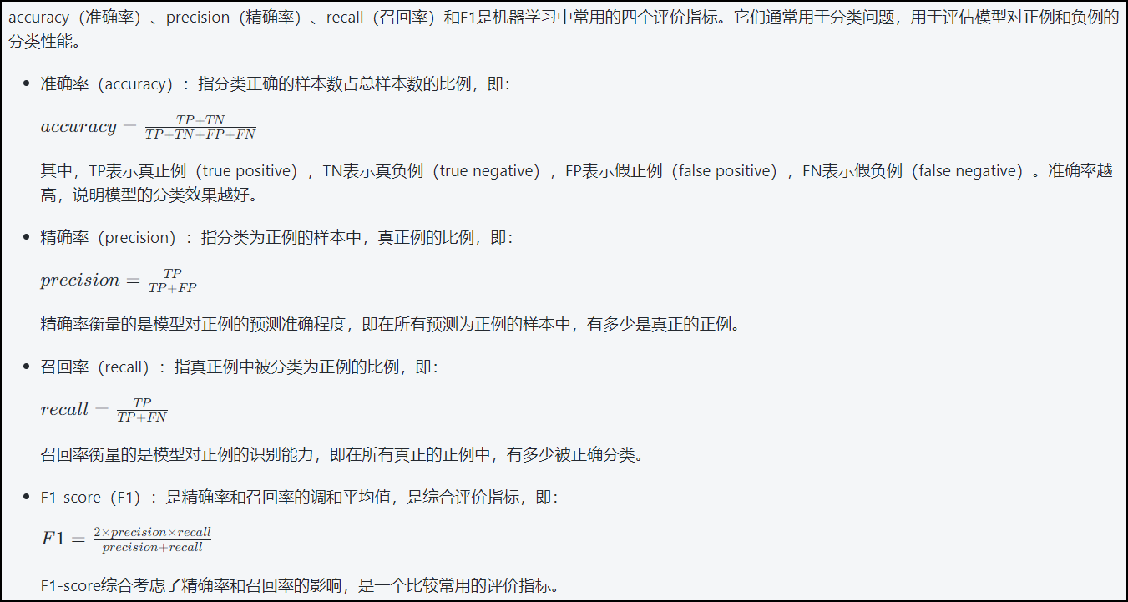
准确率、精确率、召回率和F1值
模型预测(predict.py)
使用加载好的文本分类模型进行预测
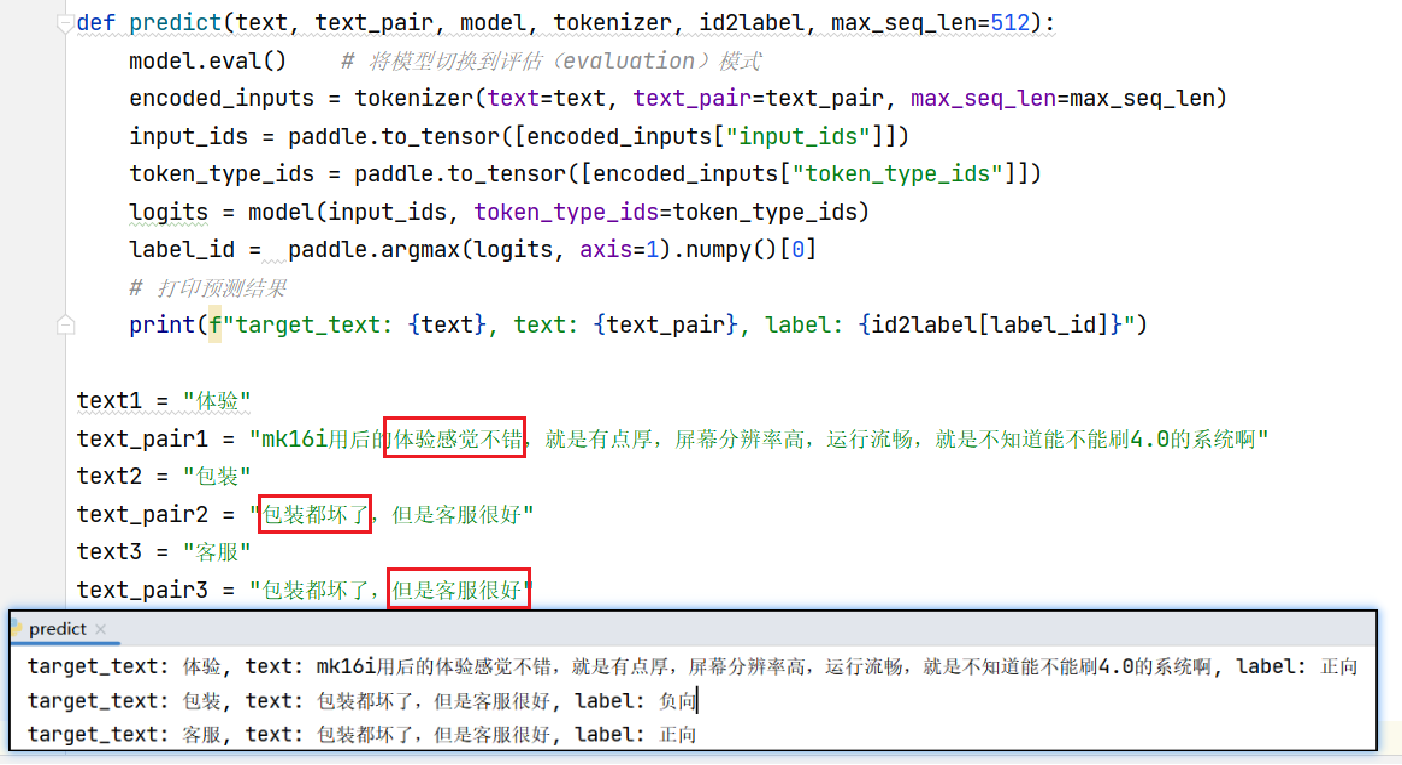
使用加载好的模型对给定的文本进行情感分类预测,并输出预测结果。
具体的步骤如下:
- 导入所需的库和模块,包括
paddle、SkepModel、SkepTokenizer等。 - 使用
data_cls.load_dict函数加载之前保存的标签字典,用于将标签映射为类别id和将类别id映射为标签。 - 使用
paddle.load函数加载之前保存的最佳模型权重。 - 使用
SkepModel.from_pretrained函数加载预训练的Skep模型。 - 使用
SkepTokenizer.from_pretrained函数加载Skep模型对应的分词器。 - 创建一个新的
SkepForSequenceClassification模型,该模型包含从Skep模型中提取的特征和一个用于分类的全连接层,并根据类别数量设置了输出维度。 - 使用
best_model.load_dict方法加载之前保存的最佳模型权重。 - 定义了一个
predict函数,用于对输入的文本进行预测。函数首先将模型切换到评估模式,然后使用Tokenizer对输入进行编码,将编码后的输入转换为Tensor,并通过模型进行推理得到预测结果。最后打印出预测结果。 - 定义了三个文本示例及其对应的文本对。
- 分别调用
predict函数对这三个示例进行预测,并打印预测结果。
预测文本:

预测结果:

参考
[1] 属性级情感分析:https://aistudio.baidu.com/projectdetail/6671795
[2] H. Tian, C. Gao, X. Xiao, H. Liu, B. He, H. Wu, H. Wang, and F. Wu, ‘‘SKEP: Sentiment knowledge enhanced pre-training for sentiment analysis,’’ 2020, arXiv:2005.05635.