想尝试这个FastSam的部署,但至今还没跑通,一个问题能带出一片问题,感觉挺心情挺郁闷的。后来和学长交流的时候,说那就是学少了,没必要急着将跑通它作为目的。也很有道理,这个任务还不太适合我当前的水平,我决定先晾一晾它。
有时候心情陷入低迷了,也挺需要一些外在力量的帮助与干预,拉上我一把。
文章目录
- 一、FastSam下载与体验
- 1 问题记录
- 小问题合集
- 2 知识记录
- pip导出requirements.txt
- 二、FastSam部署
- 1 了解模型的部署流程-onnx
- 2 尝试使用openvino部署
- 三、FastSam了解与学习
- 1 FastSam论文解读
- 2 Sam相关项目
- 3 Sam论文解读
- 4 FastSam & Sam & MobileSam
- 5 YOLACT
一、FastSam下载与体验
1 问题记录
似乎从网页上下载压缩包,会比使用git clone要方便很多。
1 CLIP是什么?
参考:openai clip安装 - 知乎 (zhihu.com)
2 运行带提示词的指令时,突然就开始下载什么东西,它下载到哪儿啦?
(fastsam) PS D:\code_all\gitCode\FastSAM-main> python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --text_prompt "the yellow dog"
0: 576x1024 21 objects, 3532.2ms
Speed: 14.6ms preprocess, 3532.2ms inference, 85.6ms postprocess per image at shape (1, 3, 1024, 1024)
22%|████████▍ | 75.3M/338M [00:32<03:59, 1.15MiB/s]
我使用everything工具,通过文件创建时间排序,找到了如下文件路径,这个文件有300MB作用。.cache目录下还有名为paddle的文件夹。
C:\Users\ThinkPad\.cache\clip\ViT-B-32.pt
3 点提示词的指令效果是什么?
补:原来这里也是给黄狗加了mask(掩码)的,原图中黄狗是明亮的色彩,下图中给它套了一层灰色。下图中点提示*应该左蓝点表示前景,右紫点表示背景。*

4 运行segment.py时报错了
prompt_process.plot(
annotations=ann,
output='./output/',
mask_random_color=True,
better_quality=True,
retina=False,
withContours=True,
)
查看plot()方法的文档中并没有output参数。
(method) plot(annotations: Any, output_path: Any, bboxes: Any | None = None, points: Any | None = None, point_label: Any | None = None, mask_random_color: bool = True, better_quality: bool = True, retina: bool = False, withContours: bool = True) -> None
改成output_path后出现另一个报错:
File "d:\code_all\gitCode\FastSAM-main\fastsam\prompt.py", line 219, in plot
cv2.imwrite(output_path, result)
cv2.error: OpenCV(4.8.1) D:\a\opencv-python\opencv-python\opencv\modules\imgcodecs\src\loadsave.cpp:696: error: (-2:Unspecified error) could not
find a writer for the specified extension in function 'cv::imwrite_'
然后又修改output_path参数的值,指定了文件名后成功。
output_path='./output/dogs_2.jpg',
参考:(已解决)could not find a writer for the specified extension in function ‘cv‘-CSDN博客
5 从这张图的效果看,有点像只是从图片中寻找边缘而已?

6 运行
app_gradio.py出问题。
不知道是出什么状况了,运行之后的页面可以打开,但无法成功在上面进行图片分割。
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
ERROR: Exception in ASGI application
......
File "D:\anaconda\envs\FastSAM\lib\site-packages\gradio\blocks.py", line 518, in get_api_info
serializer = serializing.COMPONENT_MAPPING[type]()
KeyError: 'dataset'
小问题合集
- 开梯子时conda会报错,比如此时使用
conda create -n 名字 python=3.9。 - cpu下推理得很慢,大概需要6秒。
- 不能读取中文文件名的图片。
- 似乎由于图片尺寸问题?有的图片运行后不报错也不产生输出。
- clip模型与fast-sam之间是怎么一种关系?
- 点提示词的使用?
2 知识记录
pip导出requirements.txt
pip freeze > requirements.txt #可能会丢失依赖包的版本号
pip list --format=freeze> requirements.txt
二、FastSam部署
1 了解模型的部署流程-onnx
模型部署指让训练好的模型在特定环境中运行的过程。两个需求:
- 模型通常使用特定的深度学习框架编写,以及需要一些特定的依赖。它们在实际的运行环境中可能不便于安装,需要脱离这些依赖。
- 加速。
小知识:模型部署时通常把模型转换成静态的计算图,即没有控制流(如分支结构)的计算图。可用追踪导出的方法。
参考:✔ 模型部署入门教程(一):模型部署简介 - 知乎 (zhihu.com)
1 尝试超分辨率模型SRCNN
期间下载示例的利用requests库下载face.png图片还报错了,但其实我现在不必太关注这个问题。
-
好像原始文件大一些,就会一直卡着出不了结果,输入从30kb到50kb,速度就慢了好多倍。感觉模型的效果不太行,该糊还是糊。不过,体验这个模型本就不是我的目的,我只是想走一下部署的流程而已。
-
好像放大倍数小一些,比如2,反而比放大3倍、6倍的效果更好。(放大倍数设置为2,下面右图为模型输入,左图为输出)

2 尝试使用openvino部署
参考文档:(1)FastSAM Awsome Openvino
(2)入门 — OpenVINO™ documentation — Version(2023.0)
我电脑中FastSam虚拟环境是直接安装的官方requirements.txt,cpu版本。我在其中再次安装了openvino的开发环境。
pip install openvino-dev
“ultralytics是为 YOLO 模型发布了一个全新的存储库。它被构建为用于训练对象检测、实例分割和图像分类模型的统一框架”,在fastsam awsome openvino的模型转换代码中,也用到了它。
问题:from ultralytics.utils import ...报错,但pip install ultralytics又显示satisfied。我只好卸掉重装。
(FastSAM) PS D:\code_all\gitCode\FastSAM_Awsome_Openvino-main> pip install ultralytics
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Requirement already satisfied: ultralytics in d:\anaconda\envs\fastsam\lib\site-packages (8.0.120)
模型转换流程:pt --> onnx --> ir
# 1 pt --> onnx
python pt2onnx.py --weights models/FastSAM-s.pt --output clf/FastSAM-s.onnx
# 2 onnx --> ir,生成两个文件~.xml和~.bin
mo --input_model clf/FastSAM-s.onnx --output_dir clf/ --framework onnx
# 3 运行转换后的模型
cd src/python
python FastSAM.py --model_path ../../clf/FastSAM-s.onnx --img_path ../../images/coco.jpg --output ../../clf/
我用它给的.pt模型,转出来后,推理时遇到了一个错误:
ValueError: get_shape was called on a descriptor::Tensor with dynamic shape
如果我将pt2onnx.py中的torch.onnx.export()中的dynamic_axes参数去掉,得到一个静态输入的onnx模型,推理时又遇到了另一个错误:
RuntimeError: mat1 and mat2 shapes cannot be multiplied (100x32 and 65x6400)
小结:总之尝试失败。感觉对于整个模型从转换到运行的过程缺乏了一些认知,以至于感觉像在玩弄一个黑盒子。花时间搜索bug、调来调去,但整个人一直处于比较懵的状态。严重缺少前置知识,感觉就像在浪费生命。
当前问题:
- 不懂openvino及其部署流程,以及相关的各种概念及其影响。如静态、动态输入。
- 不懂fast-sam的模型结构细节。模型部署并不是转一下模型结构就完了,推理也要有相应的推理代码,包括输入前处理(preprocess),输出后处理(postprocess),但我不懂这些处理是在干嘛,为什么要这样写,那么出了问题自然懵圈。
三、FastSam了解与学习
其它参考:
- 原论文pdf
- Segment Anything(sam)项目整理汇总
相关:
- fastsam的Web在线体验
1 FastSam论文解读
阅读:中科院自动化所发布Fast SAM | 精度相当,速度提升50倍!!! - 知乎 (zhihu.com)
名词:
常规的cnn检测器,实例分割分支,人工先验结构,segment anything领域,端到端的Transformer方法,特征融合模块,形态学操作,文本提示的图像嵌入,AR(召回率),AUC,zero-shot(零样本),YOLACT方法,
摘句:
- 这种计算开销主要来自于处理高分辨率输入的Transformer架构。
- SAM架构的主要部分Transformer(ViT)
- 本文将segment anything任务分解为两个连续的阶段,即全实例分割和提示引导选择。
- 对于特定任务来说,特定的模型仍然可以利用优势来获得更好的效率-准确性平衡。
- 先使用YOLOv8-seg 对图像中的所有对象或区域进行分割。
- YOLOv8的主干网络和特征融合模块(neck module)将YOLOv5的C3模块替换为C2f模块。更新后的头部模块采用解耦结构,将分类和检测分开。
- 在FastSAM中,本文直接使用YOLOv8-seg方法进行全实例分割阶段。
- FastSAM的运行速度与提示数量无关
- 在COCO的所有类别上与无需学习的方法进行比较。
- 相比SAM,FastSAM在大对象的狭窄区域上可以生成更精细的分割掩码。
- FastSAM在生成框上具有明显的优势,但其掩码生成性能低于SAM
- 局限性:(1)低质量的小尺寸分割掩码具有较高的置信度分数。(2)一些微小尺寸对象的掩码倾向于接近正方形。
- FastSAM还存在一些可以改进的弱点,例如评分机制和实例掩码生成范式。
草记:
提示引导选择:(1)点提示通过设置前景点、背景点,来对掩码进行选择。(2)框提示通过与第一阶段中边界框进行iou(交并比)匹配。(3)文本提示,通过CLIP模型提取文本的相应嵌入,然后 根据相似度度量选择掩码。
疑惑:
可是我下载的fastsam模型大小为138mb,我不会下错了吧?

2 Sam相关项目
阅读:Segment Anything(sam)项目整理汇总
新鲜名词:点云分割,
有趣的项目:
Grounded-Segment-Anything:包含图像编辑,此外还有其它不少东西。
Personalize-SAM:仅给定一张带有参考mask的图像,PerSAM 无需任何训练即可在其他图像或视频中分割特定的目标,例如您的宠物狗。也提供了微调,但是只训练了2个参数。
Inpaint-Anything:图像编辑,包含移除目标,填充目标,替换目标等。
EditAnything:重新生成图像中的一部分。
小结:文章各种项目挺多的,不过好些都有些相似。包括对SAM模型的微调与场景移植,与视频处理结合,与文字提示结合(如CLIP),3d,以及一些相关的部署优化项目。此外还有辅助标注工具。
3 Sam论文解读
阅读:【论文解读】MetaAi SAM(Segment Anything) 分割一切
Sam模型的输出是无标记的纯掩码。
名词:prompt engineering,embedding,tokken,nms
摘句:
- 在网络数据集上预训练的大语言模型具有强大的zero-shot(零样本)和few-shot(少样本)的泛化能力,这些"基础模型"可以推广到超出训练过程中的任务和数据分布,这种能力通过“prompt engineering”实现
- 比如CLIP和ALIGN利用对比学习,将文本和图像编码进行了对齐,通过提示语生成image encoder,就可以扩展到下游任务
- 论文的目的是建立一个图像分割的基础模型,开发一个具有提示能力的模型。
- 先标注数据进行训练模型,然后用模型辅助标注数据,如此建立一个数据循环。
- 训练时模拟交互分割的过程,从目标mask中随机选取前景点或者box,点是从gt mask选取,box增加长边10%的噪声,最大20像素。
- 在第一次prompt预测mask之后,后续是从预测mask和gt mask有差异的区域采样点,
- mask 用focal loss和dice loss进行线性组合,系数(20:1),iou 用mse loss。
小结:感觉好像看了很多东西,但如果让我回忆一下,我脑子里面好像又没有什么东西。文中陌生的东西太多了,很多我都没什么概念,可能也就无法将它们联系起来而在我脑海里面生成一个整体的图景。
4 FastSam & Sam & MobileSam
阅读:(1)【Paper日记】FastSAM vs. MobileSAM vs. SAM
(2)【SAM】SAM & Fast SAM & Mobile SAM
名词:ViT-H,freeze解码器,知识蒸馏,对象提议,object-level
摘句:
- FS虽然里面有SAM,但其实本质上并不是在SAM上进行优化架构,而是选择了一条完全不同的道路——采用带有实例分割分支的CNN网络。
- 一方面,按原始SAM的训练方法来训练一个新的SAM模型极不划算;另一方,由于图像编码器和分割掩码解码器之间的耦合优化,很难复现甚至改进FAIR他们的成果。
- MS指出FS的工作achieved superior performance,而MS比FS的模型小7倍,速度快4倍,且mIoU远高于FS。
- FastSAM经常无法预测一些对象;此外,有时很难解释掩模提议;其次,FastSAM经常生成具有非平滑边界的掩模。
- 虽然说FastSAM中带SAM,但其实已经和SAM的工作没有太大关系了,个人感觉是聚焦于Segment Anythin Task,用传统CNN的架构去解决大模型在实际应用中遇到的问题。而MobileSAM是基于SAM的架构提出了轻量化版本
- sam模型是 promptable,包括 point, bbox, masks, text
- (sam)训练过程中不使用任何数据增强
- (fastsam的text-prompt效果差)个人分析原因为,CLIP 训练是 4 亿图文对特征对齐的训练,而并不是 object-level 与文本的对齐,使用分割数据训练好的 YOLOv8-seg 的图像特征直接与 CLIP 对应的文本特征进行强对齐(没经过训练),由于分割数据和训练 CLIP 的图像数据没有半毛钱关系,所以 mask 的特征与文本特征很难对齐,从而 text prompt 的方式效果很差是可以想通的。其实这一点是我一直想吐槽的,一直感觉将 CLIP 作为打通图文多模态的一个桥梁,多少是有点牵强的。
摘图:
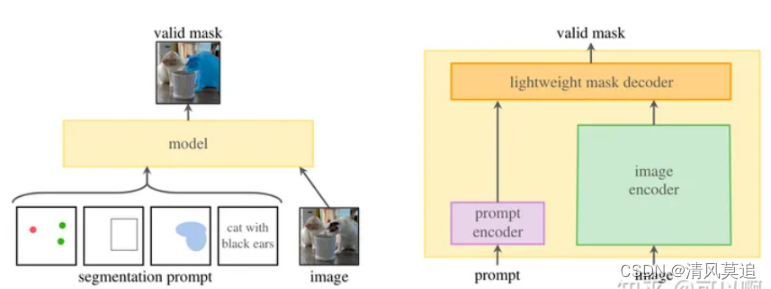
Sam:
FastSam:
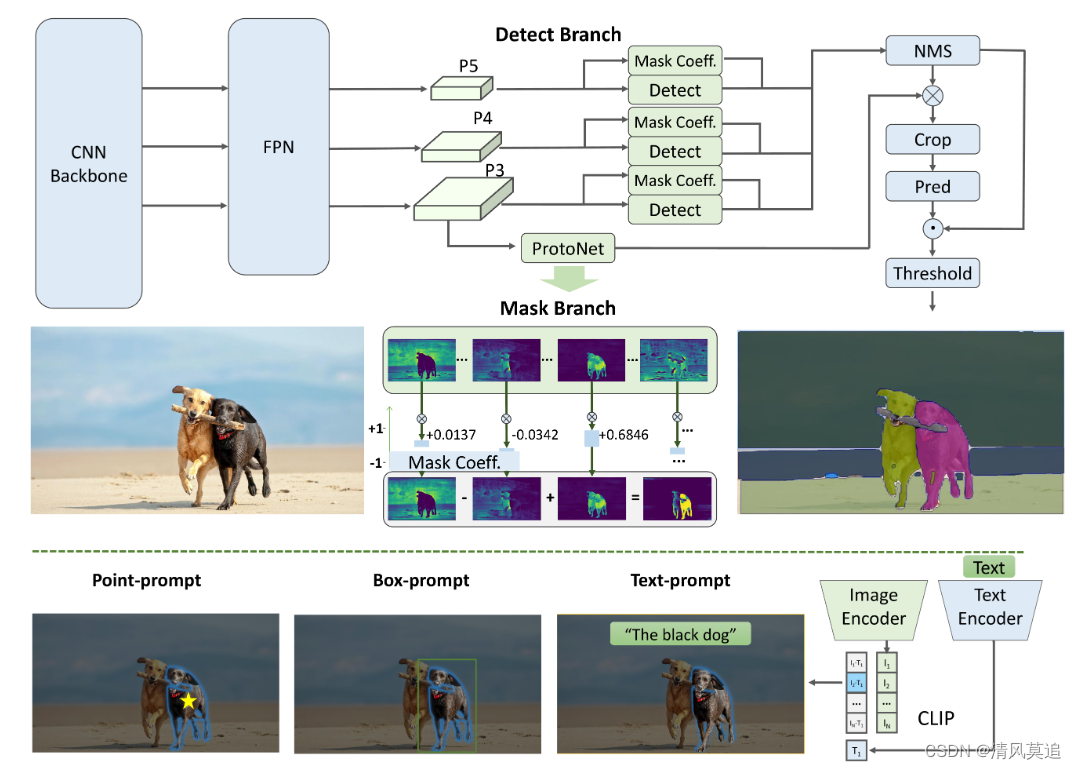
小结:脑子里还是比较模糊,fastsam和sam的区别。
文(2)中有些东西说得更加细致、丰富一些,但用的英文词比较多,比如object-level。
5 YOLACT
阅读:(1)【实例分割】YOLACT: Real-time Instance Segmentation
FastSam对于 all-instance segmentation阶段,网络结构基于YOLOv8-seg(YOLOv8 + YOLACT)
YOLACT:You Only Look At CoefficienTs.
(2)【经典论文解读】YOLACT 实例分割(YOLOv5、YOLOv8实例分割的基础)
这篇文章解释得要更清楚、细致些。
名词:FCN,anchor,NMS(又看见它),protonet,FPN特征金字塔,
摘句:
- mask 模板产生的分支(protonet)针对每幅图像预测 k 个模板mask,用FCN的方式来实现protonet,FCN最后一层有 k 个channel,每个channel对应一个模板。
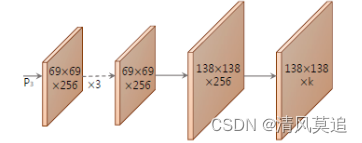
小结:文中说模型分为两个并行的过程(1)产生一系列模板mask,该mask是不基于任何一个实例的,而是基于整张输入图片的;(2)预测对于每个实例mask的系数。之后将模板mask和实例mask系数进行线性组合来获得实例的mask。
可是看了后面的解释,我还是没有懂文中的**”预测mask的系数“和”线性组合“**,具体是在干嘛。
- 将实例分割任务,划分为两个并行任务;(目标检测Detect、实例分割mask 是并行计算的,这样设计的网络是单阶段的,适合YOLO系列,速度快)
- 比如在一张街道场景的图片,图中有行人、车辆、建筑物、树木等,当检测分支框中的是行人,那么行人相关的mask原型图置信度高(头、身体、手、脚、随身物品等的位置、轮廓、编码位置敏感的方向等原型图),其它的类别mask原型图置信度低,这样组合形成实例分割的结果。
- 在 prototype 空间,某些 prototypes 对图片空间分块,某些 prototypes 定位实例······ (不懂这些分工与组合是怎样产生的)
没写完的草稿