隔离性问题
若不考虑隔离性则会出现以下问题
1.
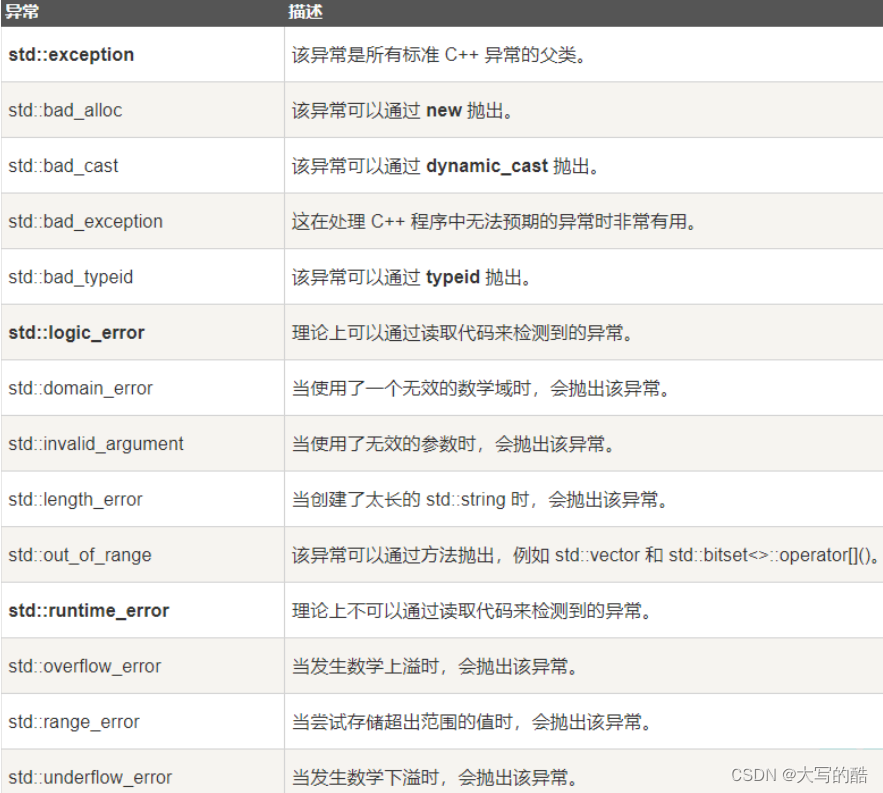
脏读:指⼀个事务在处理数据的过程中,读取到另⼀个 未提交 事务的数据
2.
不可重复读:指对于数据库中的某个数据(同⼀个数据项),⼀个事务内的多次查询却返回了不同
的结果。这是由于在查询过程中,数据被另外⼀个事务修改并 提交 了。可通过 锁⾏ 解决
3.
幻读:指事务⾮独⽴执⾏时发⽣的⼀种现象。例如事务T1对⼀个表中所有的⾏的某个数据做了修改,这时事务T2⼜向这个表中插⼊了⼀⾏数据项,⽽这个数据项的数据是以修改前的值 提交 到数据库的。⽽操作事务T1的⽤户如果查看刚刚修改的数据,会发现还有⼀⾏没有修改,其实这⾏是事务T2刚刚添加的,就好像产⽣幻觉⼀样,这就是幻读(针对⼀整批数据,即数据的个数)。可通过锁表 解决
Next-Key锁解决幻读
为了解决“当前读”中的幻读问题,MySQL事务使⽤了Next-Key锁。Next-Key锁是⾏锁和间隙锁的合并。间隙锁指的是锁加在不存在的空闲空间,可能是第⼀个索引记录之前或最后⼀个索引之后的空间。当InnoDB扫描索引记录的时候,会⾸先对选中的索引记录加上⾏锁,再对索引记录两边的间隙(向左扫描扫到第⼀个⽐给定参数⼩的值, 向右扫描扫描到第⼀个⽐给定参数⼤的值, 然后以此为界,构建⼀个区间)加上间隙锁。如果⼀个间隙被事务T1加了锁,其它事务是不能在这个间隙插⼊记录的。这样就 防⽌了幻读
隔离级别
1.
读未提交(Read uncommitted):这种事务隔离级别下,select 语句不加锁。可能读到不⼀致的数据,即脏读。这是并发最⾼,⼀致性最差的隔离级别。
2.
读已提交(Read committed):每次查询返回当前的快照。有不可重复读的问题。
3.
可重复读(Repeatable read):多次读取同⼀范围的数据会返回第⼀次查询的快照。MySQL默认隔离级别。
4.
串⾏化(Serializable):InnoDB 隐式地将全部的查询语句加上共享锁,解决了幻读的问题
读已提交、可重复读实现⽅式:MVCC。
4.7 数据库中的锁
按锁的粒度划分:
●
表级锁:表级锁分为表共享锁和表独占锁。表级锁开销⼩,加锁快,锁定粒度⼤,发⽣锁冲突最
⾼,并发度最低
●
⻚级锁:⻚级锁是MySQL中锁定粒度介于⾏级锁和表级锁中间的⼀种锁,⼀次锁定相邻的⼀组记录。
●
⾏级锁:⾏级锁分为共享锁和排他锁。⾏级锁是MySQL中锁定粒度最细的锁。InnoDB引擎⽀持⾏级锁和表级锁,只有在通过索引条件检索数据的时候,才使⽤⾏级锁,否就使⽤表级锁。⾏级锁开销⼤,加锁慢,锁定粒度最⼩,发⽣锁冲突的概率最低,并发度最⾼。
按锁级别划分:
●
共享锁:共享锁⼜叫读锁,如果事务T对A加上共享锁,则其他事务只能对A再加共享锁,不能加其他锁。共享锁的事务只能读数据,不能写数据。
●
排它锁:排他锁⼜叫写锁,如果事务T对A加上排它锁,则其他事务都不能对A加任何类型的锁。获得排它锁的事务既能读数据,⼜能写数据
●
意向锁:意向锁是⼀种不与⾏级锁冲突的表级锁。意向锁是由数据库引擎⾃⼰维护的,⽤户⽆法⼿动操作意向锁,在为数据⾏加共享 / 排他锁之前,InnoDB 会先获取该数据⾏所在数据表的对应意向锁。意向锁的⽬的是为了快速判断表⾥是否有记录被加锁。
意向锁(Intention Locks)
意向锁分为两种:
意向共享锁(intention shared lock, IS):事务有意向对表中的某些⾏加共享锁(S锁)。事务要获取某些⾏的 S 锁,必须先获得表的 IS 锁。
意向排他锁(intention exclusive lock, IX):事务有意向对表中的某些⾏加排他锁(X锁)。事务要获取某些⾏的 X 锁,必须先获得表的 IX 锁。

注意
●
上图的排他 / 共享锁指的都是表锁!!!意向锁不会与⾏级的共享 / 排他锁互斥!!!
●
意向锁在保证并发性的前提下,实现了⾏锁和表锁共存且满⾜事务隔离性的要求。
●
事务 B 检测到事务 A 持有某表的意向排他锁,就可以得知事务 A 必然持有该表中某些数据⾏的排他锁,那么事务 B 对该表的加锁请求就会被排斥(阻塞),⽽⽆需去检测表中的每⼀⾏数据是否存在排他锁。
多版本并发控制(MVCC)
MySQL 的⼤多数事务型存储引擎实现的都不是简单的⾏锁。⽽是基于提升并发性能的考虑,实现了多版本并发控制(MVCC)。可以认为,MVCC是⾏锁的⼀个变种,但它在很多情况下避免了加锁操作,减少了开销。MVCC实现了⾮阻塞的读操作,写操作也只锁定必要的⾏。
MVCC 实现⽅式:Read View
Read View 有四个重要的字段:
creator_trx_id :指的是创建该 Read View 的事务的事务 id。
m_ids :指的是在创建 Read View 时,当前数据库中「活跃事务」的事务 id 列表,“活跃事务”指
的就是启动了但还没提交的事务。
min_trx_id :指的是在创建 Read View 时,当前数据库中「活跃事务」中事务 id 最⼩的事务,也
就是 m_ids 的最⼩值。
max_trx_id :这个并不是 m_ids 的最⼤值,⽽是创建 Read View 时当前数据库中应该给下⼀个事
务的 id 值,也就是全局事务中最⼤的事务 id 值 + 1;
对于使⽤ InnoDB 存储引擎的数据库表,它的聚簇索引记录中都包含下⾯两个隐藏列:
trx_id,当⼀个事务对某条聚簇索引记录进⾏改动时,就会把该事务的事务 id 记录在 trx_id 隐藏列
⾥;roll_pointer,每次对某条聚簇索引记录进⾏改动时,都会把旧版本的记录写⼊到 undo ⽇志中,然后这个隐藏列是个指针,指向每⼀个旧版本记录,于是就可以通过它找到修改前的记录。
在创建 Read View 后,⼀个事务去访问记录的时候,除⾃⼰的更新记录总是可⻅之外,还有如下情况:如果当前⾏的 trx_id 值⼩于 Read View 中的 min_trx_id 值,表示这个版本的记录是在创建 Read View 前已经提交的事务⽣成的,所以该版本的记录对当前事务可⻅。
如果当前⾏的 trx_id 值⼤于等于 Read View 中的 max_trx_id 值,表示这个版本的记录是在创建
Read View 后启动的事务⽣成的,所以该版本的记录对当前事务不可⻅。
如果当前⾏的 trx_id 值在 Read View 的 min_trx_id 和 max_trx_id 之间,需要判断 trx_id 是否
在 m_ids 列表中:- 如果当前⾏的 trx_id 在 m_ids 列表中,表示⽣成该版本记录的活跃事务依然活跃着(还没提交事务),所以该版本的记录对当前事务不可⻅。
- 如果当前⾏的 trx_id 不在 m_ids列表中,表示⽣成该版本记录的活跃事务已经被提交,所以该
版本的记录对当前事务可⻅。
当记录不可⻅时会通过roll_pointer指针找到可⻅的第⼀个记录读取。这种通过「版本链」来控制并发事务访问同⼀个记录时的⾏为就叫 MVCC(多版本并发控制)。
读已提交隔离级别是在每次读取数据时,都会⽣成⼀个新的 Read View。意味着,事务期间的多次读取同⼀条数据,前后两次读的数据可能会出现不⼀致,因为这期间另外⼀个事务可能修改了该记录,并提交了事务。
可重复读
隔离级别是在执⾏第⼀个查询语句后⽣成⼀个 Read View,然后整个事务期间都在⽤这个
Read View
快照读与当前读
1.
快照读:读取历史数据的⽅式,如普通的select语句。
2.
当前读:读取数据库当前版本数据的⽅式,是特殊的读操作。插⼊、更新、删除操作,都属于当前读,处理的都是当前的数据,需要加锁。不过 select .. for update 语句就不是快照读了,⽽是当
前读了。
4.8 查询优化⽅法
避免向数据库请求不需要的数据
●
在访问数据库时,应该只请求需要的⾏和列。请求多余的⾏和列会消耗MySql服务器的CPU和内存资源,并增加⽹络开销。避免使⽤ SELECT * 这种⽅式进⾏查询,应该只返回需要的列。例如在处理分⻚时,应该使⽤ LIMIT 限制MySql只返回⼀⻚的数据,⽽不是向应⽤程序返回全部数据后,再由应⽤程序过滤不需要的⾏。
优化查询数据的⽅式
●
查询数据的⽅式有全表扫描、索引扫描、范围扫描、唯⼀索引查询、常数引⽤等。这些查询⽅式,速度从慢到快,扫描的⾏数也是从多到少。可以通过 EXPLAIN 语句中的 type 列反应查询采⽤的是哪种⽅式。
●
通常可以通过添加合适的索引改善查询数据的⽅式,使其尽可能减少扫描的数据⾏,加快查询速
度。例如,当发现查询需要扫描⼤量的数据⾏但只返回少数的⾏,那么可以考虑使⽤覆盖索引,即
把所有需要⽤到的列都放到索引中。这样存储引擎⽆须回表获取对应⾏就可以返回结果了。
●
当⼀⾏数据被多次使⽤时可以考虑将数据⾏缓存起来,避免每次使⽤都要到MySql查询。
●
update 语句应使⽤索引查询,否则全表查询会对所有记录加锁(⾮表锁),甚⾄导致业务停滞。分解查询
●
可以将⼀个⼤查询切分成多个⼩查询执⾏,每个⼩查询只完成整个查询任务的⼀⼩部分,每次只返回⼀⼩部分结果
●
分解关联查询,即对每个要关联的表进⾏单表查询,然后将结果在应⽤程序中进⾏关联。优化 LIMIT 分⻚
● 处理分⻚会使⽤到 LIMIT,当翻⻚到⾮常靠后的⻚⾯的时候,偏移量会⾮常⼤,这时LIMIT的效率
⾮常差。例如对于LIMIT 10000,20这样的查询,MySql需要查询10020条记录,将前⾯10000条记
录抛弃,只返回最后的20条。这样的代价⾮常⾼,如果所有的⻚⾯被访问的频率都相同,那么这样
的查询平均需要访问半个表的数据。优化此类分⻚查询的⼀个最简单的办法就是尽可能地使⽤索引
覆盖扫描,⽽不是查询所有的列。然后根据需要与原表做⼀次关联操作返回所需的列。对于偏移量
很⼤的时候,这样的效率提升⾮常⼤。
优化 UNION 查询
●
除⾮确实需要服务器消除重复的⾏,否则⼀定要 使⽤UNION ALL。如果没有ALL关键字,MySql会给临时表加上 DISTINCT 选项,这会导致对整个临时表的数据做唯⼀性检查。这样做的代价⾮常⾼。
group by 查询原理:
在MySQL 中,GROUP BY 的实现同样有多种(三种)⽅式,其中有两种⽅式会利⽤现有的索引信息来完成 GROUP BY,另外⼀种为完全⽆法使⽤索引的场景下使⽤。GroupBy会默认按照分组的字段进⾏排序;如果不需要排序,可使⽤order by null
使⽤松散(Loose)索引扫描实现 GROUP BY
MySQL 完全利⽤索引扫描来实现GROUP BY ,并不需要扫描所有满⾜条件的索引键即可完成操作得出结果。Extra信息中显示:Using index for group-by 要利⽤到松散索引扫描实现 GROUP BY,需要⾄少满⾜以下⼏个条件:
●
GROUP BY 条件字段必须在同⼀个索引中最前⾯的连续位置;
●
在使⽤GROUP BY 的同时,只能使⽤ MAX 和 MIN 这两个聚合函数;
●
如果引⽤到了该索引中 GROUP BY 条件之外的字段条件的时候,必须以常量形式存在; 松散索引扫描需要读取的键值数量与分组的数量⼀样多,尽可能读取最少数量的关键字。
使⽤紧凑(Tight)索引扫描实现 GROUP BY 和松散索引扫描的区别是需要读取所有满⾜条件的索引值,之后取数据完成操作。Extra中不显示for group-by,在 MySQL 中,⾸先会选择尝试通过松散索引扫描来实现 GROUP BY 操作,当发现某些情况⽆法满⾜松散索引扫描实现 GROUP BY 的要求之后,才会尝试通过紧凑索引扫描来实现。(⽐如GROUP BY 条件字段并不连续或者不是索引前缀部分的时候)使⽤临时表实现 GROUP BY 当⽆法找到合适的索引可以利⽤的时候,就不得不先读取需要的数据,然后通过临时表来完成 GROUP BY 操作。Extra:Using temporary; Using filesort。
union、join 区别
1. union 在数据库运算中会过滤掉重复数据,并且合并之后是根据⾏合并的;
2. union all 不对数据进⾏过滤重复数据处理;
3. union 之后列数不变(两张表 union 保证列数和列结构⼀样 join 是进⾏表关联运算的,两个表要有⼀定的关系(某列可连接)。根据某⼀列进⾏笛卡尔运算和条件过滤,如果A表有3列,B表有3列,join 之后可能是5列。
mysql 深度分⻚
mysql 分⻚查询是我们常⻅的需求,但是随着⻚数的增加查询性能会逐渐下降,尤其是到深度分⻚的情况。可以把分⻚分为两个步骤,1.定位偏移量,2.获取分⻚条数的数据。所以当数据较⼤⻚数较深时就涉及⼀次需要耗费较⻓时间的操作。所以mysql深度分⻚的问题该如何解决呢 ?
●
以结果作为条件,已查询条件的变化换取分⻚的不变。分⻚查询⼀般都是逐渐往后翻⻚的,那么可以很清晰的知道,在当前查询⻚的最后⼀条数据的位置,那么,以此位置再查询N条,以位置的推移换取⻚数的不变,减少其偏移量的计算。
●
采⽤⼦查询模式,其原理依赖于覆盖索引,当查询的列均是索引字段时,性能较快,因为其只⽤遍历索引本身。针对复杂的查询逻辑,⼀般从数据的 偏移量着⼿,减少偏移量的定位时间。
简单的查询逻辑,可以从索引覆盖的思想着⼿,先确定查询数据的主键id,再由id找相关的数据。
4.9 主从复制
具体详细过程如下:
●
MySQL 主库在收到客户端提交事务的请求之后,会先写⼊ binlog,再提交事务更新存储引擎中的数据,事务提交完成后,返回给客户端“操作成功”的响应。
●
从库会创建⼀个专⻔的 I/O 线程,连接主库的 log dump 线程,来接收主库的 binlog ⽇志,再把
binlog 信息写⼊ relay log 的中继⽇志⾥,再返回给主库“复制成功”的响应。
●
从库会创建⼀个⽤于回放 binlog 的线程,去读 relay log 中继⽇志,然后回放 binlog 更新存储引
擎中的数据,最终实现主从的数据⼀致性。
在完成主从复制之后,你就可以在写数据时只写主库,在读数据时只读从库,这样即使写请求会锁表或者锁记录,也不会影响读请求的执⾏。
从库是不是越多越好?不是的。因为从库数量增加,从库连接上来的 I/O 线程也⽐较多,主库也要创建同样多的 log dump 线程来处理复制的请求,对主库资源消耗⽐较⾼,同时还受限于主库的⽹络带宽。所以在实际使⽤中,⼀个主库⼀般跟 2~3 个从库(1 套数据库,1 主 2 从 1 备主),这就是⼀主多从的 MySQL 集群结构。MySQL 主从复制还有哪些模型?
●
同步复制:MySQL 主库提交事务的线程要等待所有从库的复制成功响应,才返回客户端结果。这种⽅式在实际项⽬中,基本上没法⽤,原因有两个:⼀是性能很差,因为要复制到所有节点才返回
响应;⼆是可⽤性也很差,主库和所有从库任何⼀个数据库出问题,都会影响业务。
118
119
异步复制(默认模型):MySQL 主库提交事务的线程并不会等待 binlog 同步到各从库,就返回客
户端结果。这种模式⼀旦主库宕机,数据就会发⽣丢失。
半同步复制:MySQL 5.7 版本之后增加的⼀种复制⽅式,介于两者之间,事务线程不⽤等待所有的从库复制成功响应,只要⼀部分复制成功响应回来就⾏,⽐如⼀主⼆从的集群,只要数据成功复制到任意⼀个从库上,主库的事务线程就可以返回给客户端。这种半同步复制的⽅式,兼顾了异步复制和同步复制的优点,即使出现主库宕机,⾄少还有⼀个从库有最新的数据,不存在数据丢失的⻛险。