目录
- 容器技术
- 容器技术概述
- 要区分好共享与隔离的概念
- 容器技术的三大核心
- 容器对比虚拟机
- namespace
- UnionFs
- 容器操作系统的来源
- 操作系统的来源
- 完整操作系统的镜像
- docker image是什么?如何构成的
- 如何为容器安装操作系统
- UnionFS(联合文件系统)的由来
- 同一个镜像启动多个容器的本质
- 容器内如何写入数据
- 容器overlay读写有三种场景
- runtime
- OCI的由来
- docker的分层
- docker的构成
- 为什么需要有containerd-shim这个进程
- containerd、containerd-shim及容器进程的关系
- runtime容器运行时
- 容器运行时分类
- Low-Level和High-Level容器运行时
- Low-Level容器运行时之Runc
- High-Level容器运行时之containred
- k8s为何"抛弃"docker
- 容器里的进程管理
- 容器内的两个特殊进程
- 容器内的0号进程
- 容器内的1号进程
- 完整操作系统的1号进程
- 容器内的1号进程
- 僵尸进程与孤儿进程
- 系统中进程的状态
- 僵尸进程
- 僵尸进程示例代码
- 孤儿进程
- 容器内的僵尸进程
- 容器内残留僵尸进程的原因
- CPU Cgroup的使用
- CPU CGROUP介绍
- 进程管理
- 进程介绍
- 查看进程
- ps aux查看
- top命令查看
- cpu usage是什么
- CPU Cgroup的使用
- 监控容器cpu真实使用率
- 在容器内无法通过top命令获取真实cpu使用率
- 获取单个进程对cpu的使用率
- 不可中断睡眠对容器的影响
- Load Average的统计方式
- 在k8s中限制pod的pid数
- 使用 Cgroups 限制 Kubernetes Pod 进程数
容器技术
容器技术概述
-
物理机部署成千上万应用的时代:
- 物理机利用率上去了;
- 服务器宕机了,所有应用都会宕机;
- 需求:1. 把单台物理机的利用率提高;2. 把应用分散到逻辑上不同的主机中,应该做到不同应用的环境隔离,分离出不同职能的应用,如负责负载均衡,负责数据库…的应用
-
虚拟化技术:
-
为了同时满足上述两个需求,于是诞生了虚拟化技术,例如win下的vmware workstation,linux下的kvm,还有esxi、xen等;
-
虚拟化技术可以在单台物理机的操作系统上虚拟出多台虚拟的机器,以此达到隔离的目的(运行在每个虚拟机里的应用肯定互相隔离的,此时一台虚拟机挂掉了也不会影响另外一台),同时因为多台虚拟机都寄生在物理机上,所以物理机的利用率也提升了上来;
-
问题:虚拟机太繁重了,不够轻量级;
-
-
轻量级虚拟化技术:
- 利用虚拟机达到上述目标太繁重了,仔细分析一下,虚拟机隔离的是什么?不同的虚拟机隔离的关键部分在于它们彼此有各自独立的磁盘、主机名、IPC、PID、网络、用户等,既然是这样那有没有什么方法可以抛弃虚拟机的实现,采用更轻量级的方法去实现这些隔离呢?
- 进程的内存空间天生就彼此隔离,但其进程之间的其他资源都是共享的,比如硬盘,网络等,所以如果可以在进程内存隔离的基础上,通过技术手段让一个进程的网络空间、硬盘空间、pid等与其他进程隔离开,那此进程就达到了虚拟机一样的隔离效果了!启动一个进程,与启动一台虚拟机,哪个更轻量级!!!
- 有人会说,隔离你是实现了,那操作系统怎搞,虚拟机里可以安装自己独有的操作系统,但是你怎么让一个进程里有自己独立的操作系统?其实道理都一样,虚拟机里可以安装操作系统,而操作系统来源于系统镜像,所以,完全可以仿照操作系统镜像制作类似的容器的镜像,然后把容器镜像内容“放”到进程里,这个进程也就有了操作系统,理论上完全行得通。
- 围绕上述需求有人开发了一款软件,并将该软件命名为docker,值得说一嘴的是,类似的技术早就有了比如lxc,docker也只是在它的基础上发扬光大。
- 所以启动一个容器其实就是启动一个进程,该进程与普通进程不同的是,该进程出了内存空间与其他进程隔离之外,该进程内可以拥有自己的root文件系统、自己的网络配置、自己的进程空间、甚至自己的用户ID,所以其使用起来,就好像在一个独立于宿主的系统下操作一样。
- 容器的轻量级带来了另外一个优点的大幅度提升,就是可迁移性,一次打包到处使用(之前的虚拟机方案当然也可以,但打包一个虚拟机数据量太大了,动不动十几个g,而打包一个容器就少很多了,少的几十m就行)
要区分好共享与隔离的概念
-
此处所说的共享与隔离的概念,指的都是在使用时,而不是申请时。
- 申请时:在虚拟化大背景下,一台物理机的资源对寄生在它身上的虚拟机或容器都是公共的,大家都可以去申请,这叫申请时大家是共享的。
- 使用时:针对申请到的资源,如果A申请到的,B同样可以对其进行读写,那就代表这一申请到的资源是共享的。如果A与B申请到的资源,各自的读写互不干扰,那就是隔离的。我们谈到的隔离指的就是这一使用时的概念,即申请时都去物理机申请,而使用时则互不干扰
-
如何理解进程的内存空间隔离,磁盘共享呢?
- 在申请时,物理机的所有资源对进程们都是公开的,也就说在资源的申请上,大家是共享的。
- 如何理解进程的内存空间是隔离的呢?多个进程都去申请物理机的物理内存,但是申请到一块内存之后,只要不释放,其他进程便无法对该内存进行读写,这就是隔离,即在内存的使用上,进程之间默认隔离。
- 那么为何说默认进程的磁盘空间是共享的呢?我们操作磁盘都是通过文件,一个文件映射到一块磁盘空间,进程A打开一个磁盘文件a.txt进程读写,进程B同样可以对a.txt进行读写,所以在磁盘的使用上,进程之间默认是共享的。
容器技术的三大核心
-
容器技术的产生背景,说白了就是追求一个轻量级的虚拟化方案,来达到隔离的目的(同时提高硬件利用率),这个空间隔离就是容器技术的第一个核心技术:namespace名称空间;
-
此外需要注意的是,光有隔离还不够,因为空间隔离之后,多个容器寄生在一台机器之上,虽然容器之间是隔离的,但归根结底都是在共用或者说共同消耗该物理主机的硬件资源,比如内存,如果不加以限制,当内存不足时会触发linux的OOM机制,杀掉一些进程。为了解决这个问题,于是容器技术在隔离的基础之上引入来cgroup机制,来对资源进行限制(包括磁盘、cpu等资源);
-
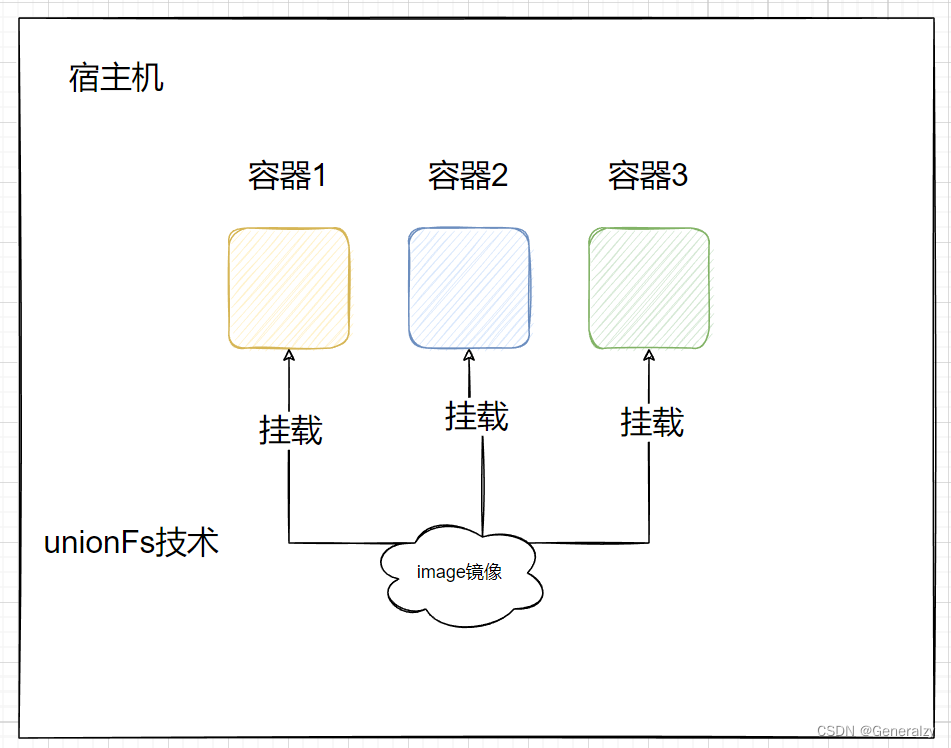
一个容器的启动需要有一个容器镜像,容器的镜像与操作系统的镜像还是有很大区别的,系统镜像的主要构成是bootfs(包含内核)+ rootfs,而容器镜像里没有bootfs内存相关、只有一个rootfs,而且容器的rootfs文件系统并非传统文件系统ext4、xfs等,而是一种采用一种联合文件系统技术称之为UnionFS,该技术会在启动时把容器镜像挂载到(而不是拷贝到)容器里使用的。UnionFS是一个技术概念而不是某一种具体的技术,多个目录联合挂载到同一个目录下。
总结,容器技术有三大核心:
-
namespace名称空间:保证容器之间的运行环境(使用时资源)互相隔离,彼此互不影响
- linux内核2.4.19引入namespace,是内核强大的特性;
- 可以使每个进程看起来都拥有自己的隔离的全局系统资源,即每个进程都有自己的命名空间;
- 每个进程中运行的应用程序都像是运行在一个独立的系统中一样;
-
cgroup机制:限制资源使用
- 容器的本质就是进程,多个进程不受限制地占用系统资源,如cpu、磁盘、内存、网络等
- 当某个进程占用过多资源,以致于将主机系统资源耗尽时,linux内核会触发OOMout of memory killer机制
- OOM会在系统内存耗尽的情况下跳出来,选择性的干掉一些进程以求释放一些内存)这会让一些被杀掉的进程成了无辜的替死鬼,
- 因此为了让容器中的进程更加可控,Docker使用Linux cgroups来限制容器中的进程允许使用的系统资源 Linux Cgroup可以让系统中所运行任务(进程)的用户定义组分配资源,比如CPU时间、系统内存、网络带宽;
-
UnionFS联合文件系统:镜像、分层挂载
- UnionFS顾名思义,可以把主机文件系统上多个目录(分支)内容联合挂载到同一个目录下,而主机上文件系统的多个目录的物理位置是分开的,这可以让多个容器进程共享同一份镜像,而不是向传统虚拟化那样每台vm都有一个完整的操作系统,把轻量级追求到极致。
容器对比虚拟机
docker是容器技术的一种,docker也称之为docker守护进程、docker引擎,可以创建出容器(下图中docker守护进程上层的bins/libs与app代表的就是容器里的内容),容器与虚拟机类似,但是更轻量级,架构如下:
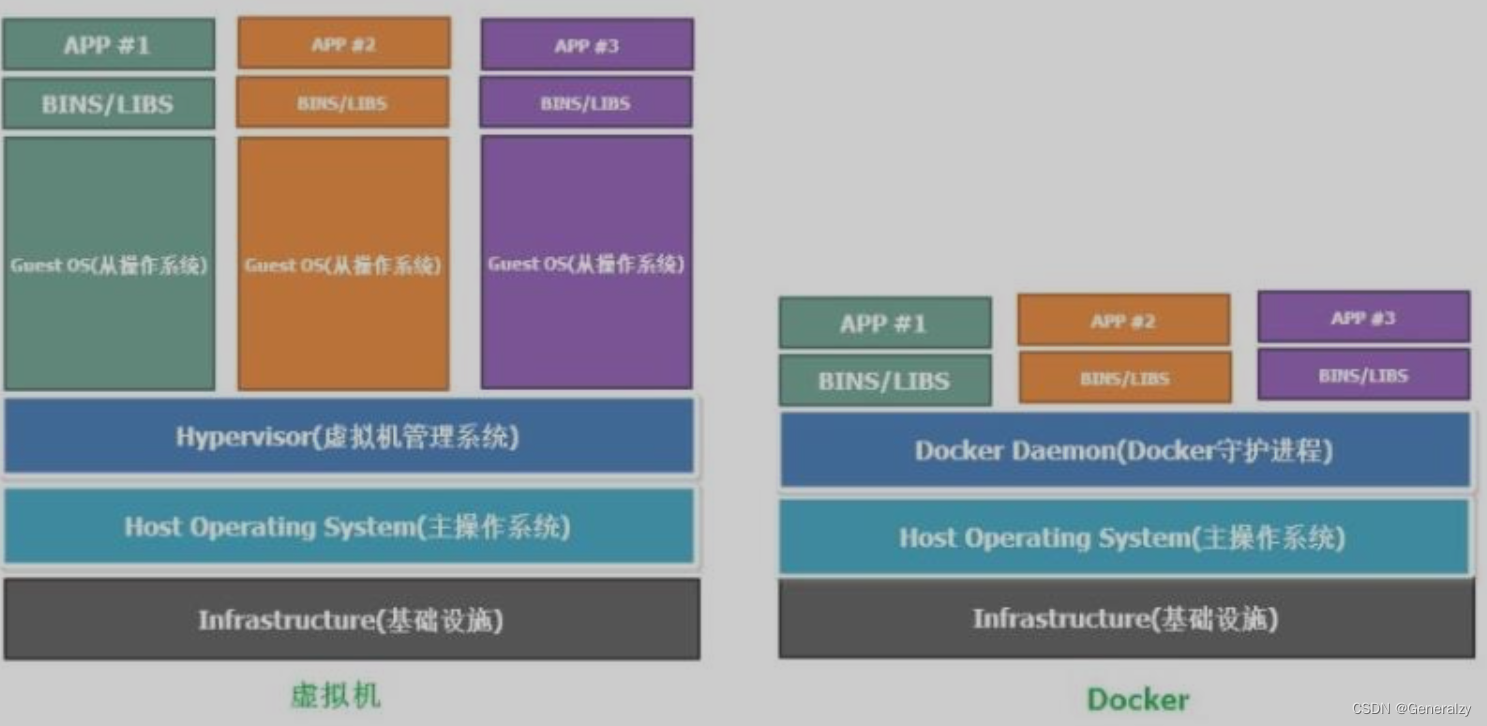
1、虚拟机架构
app
Bins/Libs文件系统及可执行命令+依赖库
Guest os虚拟机操作系统
Hypervisor虚拟机管理系统
主机操作系统
计算机硬件
2、docker容器架构
app
Bins/Libs文件系统及可执行命令+依赖库
docker守护进程
主机操作系统
计算机硬件
3、docker也可以运行在虚拟机操作系统,即Guest os中,如下架构
app
Bins/Libs文件系统及可执行命令+依赖库
===》docker守护进程《===
Guest os虚拟机操作系统
Hypervisor虚拟机管理系统
主机操作系统
计算机硬件
总结虚拟机与容器的区别:
-
容器适用场景更广
- 虚拟机里通常不会再跑虚拟机(即便支持,那也会因为虚拟机的繁重拉胯效率),但是虚拟机里可以继续跑容器
- 虚拟化技术依赖的是物理CPU和内存,是硬件级别的;
- Docker是构建在操作系统层面的,利用操作系统的容器化技术,是进程级别,所以Docker同样的可以运行在虚拟机上面
-
容器更加轻量级
- 一个虚拟机需要具备三要素:虚拟硬件、bootfs、rootfs,而一个容器的启动只需要有一个rootfs,那什么是bootfs与rootfs呢?
- 虚拟机操作系统来源于操作系统镜像,操作系统镜像由bootfs(包含系统内核)与rootfs(bin目录、etc目录、home目录等一系列目录)构成
- 容器中的“操作系统“源自于容器的镜像,该镜像只包含了rootfs(rootfs就是容器镜像),所以容里是没有操作系统内核的。
- 总结容器不需要虚拟硬件、不需要安装操作系系统,只有一个rootfs,所以更加轻量级。
- 容器内只有rootfs相当于欺骗了上层的应用,上层的应用看到rootfs的内容还以为自己就工作在操作系统之上。
- 此外,在传统的虚拟化技术是通过快照来保存的;而Docker引用了类似于源码的管理机制,将容器的快照历史版本一一记录下来。
-
容器可移植性/跨平台性更强
- 容器本质就是一个进程,不依赖硬件,只要硬件之上的操作系统支持docker容器技术,那么容器就可以跑起来,所以其可移植性强,但是虚拟机依赖硬件,可移植性差;
- 对于linux系统,不同的发行版bootfs基本一致,主要不同就是rootfs,也就是容器镜像,所以如果一个容器的镜像打包的是linux系统的rootfs,那么它可以在不同的发行版上运行良好。
- (别问能不能在windows上跑这么愚蠢的问题,当然不能了,linux系统=bootfs+rootfs,容器镜像打包的是rootfs,windows系统的内核与linux的bootfs肯定不一样啊。当然如果在windows系统里装个虚拟机工具vmware workstation然后创建出一台虚拟机装个linux系统,然后在这个linux系统里跑此处提到的容器,那么肯定是可以跑起来的。)
传统的虚拟化技术在构建系统的时候非常复杂;而Docker可以通过一个简单的Dockerfile文件来构建整个容器,更重要的是Dockerfile可以手动编写,这样应用开发人员可以通过发布Dockerfile来定义应用的环境和依赖,这样对于持续交付非常有利;
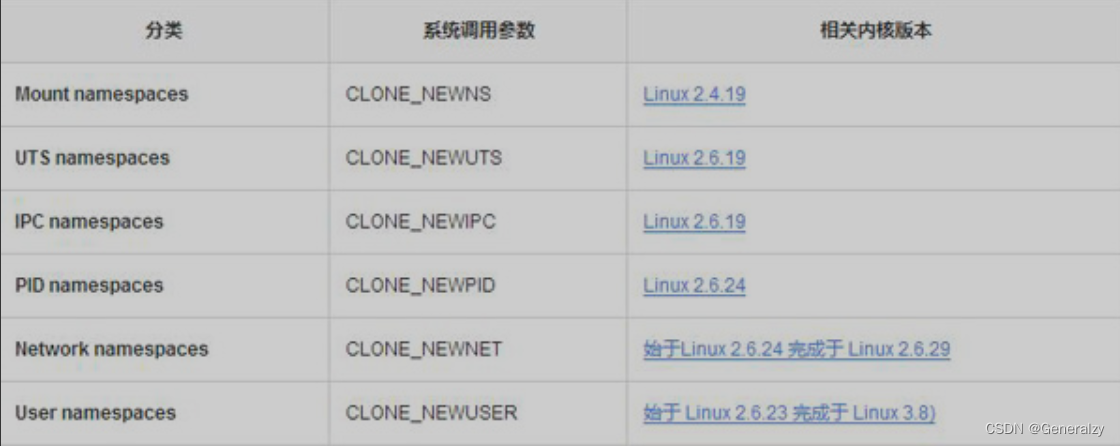
namespace
可以简单理解namespace技术做到让不同容器在UTS、IPC、PID、Mount、Network、User六种资源的隔离即可。
如果把linux操作系统比作一个大房子,那命名空间指的就是这个房子中的一个个房间,住在每个房间里的人都自以为独享了整个房子的资源,但其实大家仅仅只是在共享的基础之上互相隔离,共享指的是全局资源是共享的比如cpu、内存、磁盘等,而隔离指的是局部上彼此保持隔离比如容器内的pid、用户名等;
因而命名空间的本质就是指:一种在空间上隔离的概念,当下盛行的许多容器虚拟化技术(典型代表如LXC、Docker)就是基于linux命名空间的概念而来的。
Linux 内核2.4.19中开始陆续引用了namespace概念。目的是将某个特定的全局系统资源(global system resource)通过抽象方法使得namespace中的进程看起来拥有它们自己的隔离的全局系统资源实例。
命名空间是Linux内核强大的特性。每个容器都有自己的命名空间,运行在其中的应用都是在独立操作系统中运行一样。命名空间保证了容器之间彼此互不影响。
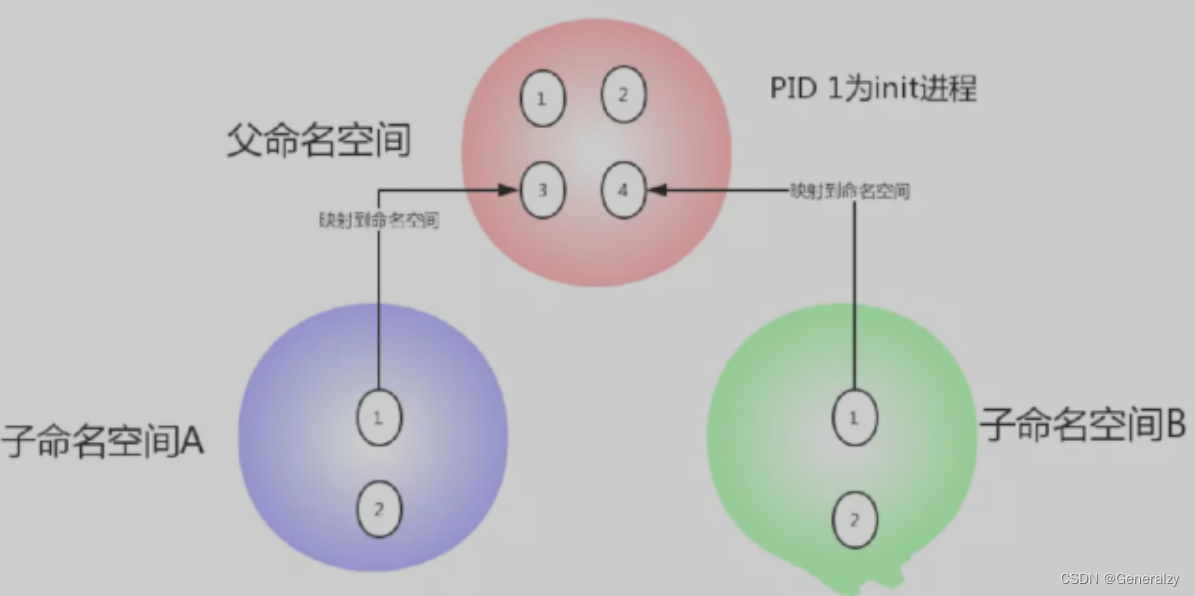
Linux Namespace是Linux提供的一种内核级别环境隔离的方法(关于隔离的概念其实大家早已接触过:比如在光盘修复模式下,可以用chroot切换到其他的文件系统,chroot提供了一种简单的隔离模式:chroot内部的文件系统无法访问外部的内容。Linux Namespace在此基础上又提供了很多其他隔离机制。)
当前,Linux 支持6种不同类型的命名空间。它们的出现,使用户创建的进程能够与系统分离得更加彻底,从而不需要使用更多的底层虚拟化技术。
UnionFs
容器操作系统的来源
操作系统的来源
如何为物理机/虚拟机安装操作系统?
-
先下载了一个系统镜像文件,然后把该镜像写到u盘或光盘里称之为启动盘,然后用来为机器安装操作系统。
-
也就说一台机器的操作系统来自于一个镜像文件,称之为系统镜像。
一个容器就相当于一台“虚拟机”,既然虚拟机的操作系统来源于镜像,那么容器内的操作系统必然也来源于镜像了!!
但因为容器要做到全方位的轻量级,所以容器的操作系统镜像必然也要是在一个完整操作系统镜像的基础上做精简。具体如何实现?请看下文:
完整操作系统的镜像
镜像的本质就是一个iso格式的压缩包,操作系统镜像里面存放了该系统所有的内容,具体来说分为两大部分,
一个典型的 Linux 文件系统由 bootfs 和 rootfs 两部分组成:
-
bootfs(boot file system) 主要包含 bootloader 和 kernel,bootloader 主要用于引导加载 kernel,当 kernel 被加载到内存中后 bootfs 会被 umount 掉,从而释放内存,同样的内核版本不同Linux发行版,其bootfs都是一致的。
-
rootfs (root file system) 包含的就是典型 Linux 系统中的/dev,/proc,/bin,/etc 等标准目录和文件。Linux系统在启动时,rootfs首先会被挂载为只读模式,然后在启动完成后被修改为读写模式,随后它们就可以被修改了。不同的 linux 发行版(如 ubuntu 和 CentOS ) 在 rootfs 这一层会有所区别,体现发行版本的差异性。
docker image是什么?如何构成的
一个完整的文件系统是由bootfs+rootfs组成的,而容器image镜像其实就是把rootfs打包到一起(镜像的本质就是一种压缩包),这个rootfs系统里包含了各种依赖文件,以及你的应用程序文件都在一起。
也就说世界上第一个镜像是怎么产生的呢?
就是某人在一台物理机上安装了一个linux操作系统,包括bootfs,也包括rootfs,然后他在rootfs里安装了各种依赖包,做好了软件启动的一切配置,然后他把这个rootfs(译:根文件系统)打包压缩成了一个文件,这个文件就称之为docker的image,也就是镜像。
启动一个容器,必须指定一个镜像,镜像里包含的是rootfs,目的就是把镜像文件共享给了容器的名称空间里,在容器内,可以看到完全独立的文件系统,查看容器中的根文件系统 (rootfs)。然后,你会发现,它和宿主机上的根文件系统也是不一样的。所以此时你应该知道了,在容器里看到的根文件系统,就是镜像里的东西。下图docker image 中最基础的两层结构,不同的 linux 发行版(如 ubuntu 和 CentOS ) 在 rootfs 这一层会有所区别,体现发行版本的差异性。
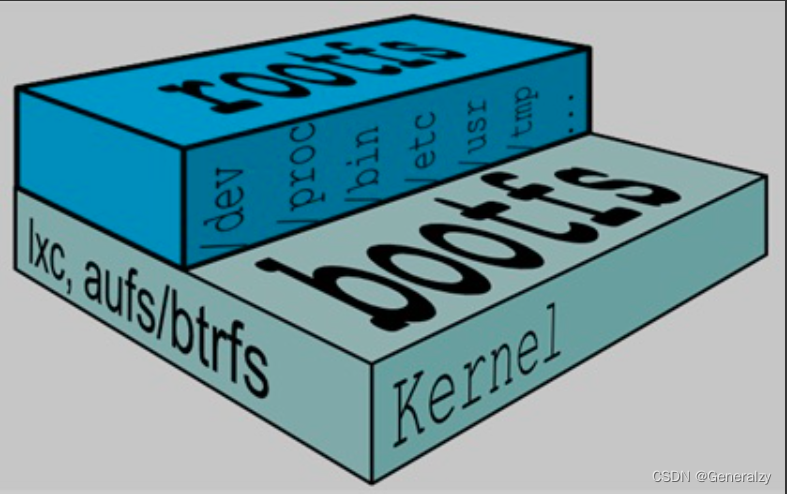
容器本质是没有内核的、它只有rootfs,至于下层的bootfs内核部分是共享自物理机的,并且所有容器共享的都是物理主机上的运行系统的内核即bootfs相关内容。
物理机运行的文件系统内核如果有漏洞,那么必然会影响到容器。
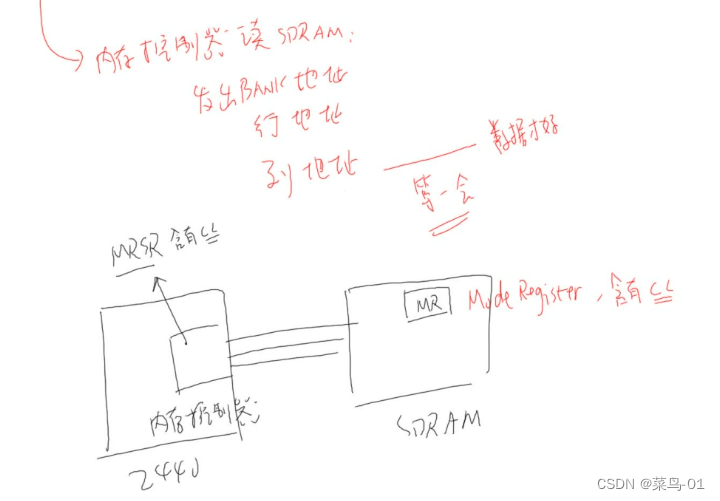
如何为容器安装操作系统
UnionFS(联合文件系统)的由来
容器就相当于一台虚拟机,以虚拟机为例,安装操作系统的原理本质很简单,操作系统的开发者在他们自己的机器上把操作系统代码写好了之后,要放到机器上跑起来,基本就是以下两步:
-
第一步:操作系统的开发者们会把自己编写的操作系统代码打包成一个压缩包,格式为iso,称之为系统镜像,意思就是说,该文件就是完全拷贝了开发者们开发的操作系统代码文件,一模一样。
-
第二步:把iso文件“释放/解压”到目标主机,这就是安装操作系统。如何释放呢?如果目标位置是一块裸盘,那就需要借助一个传输介质,也就是我们说的U启、系统光盘等传输介质。
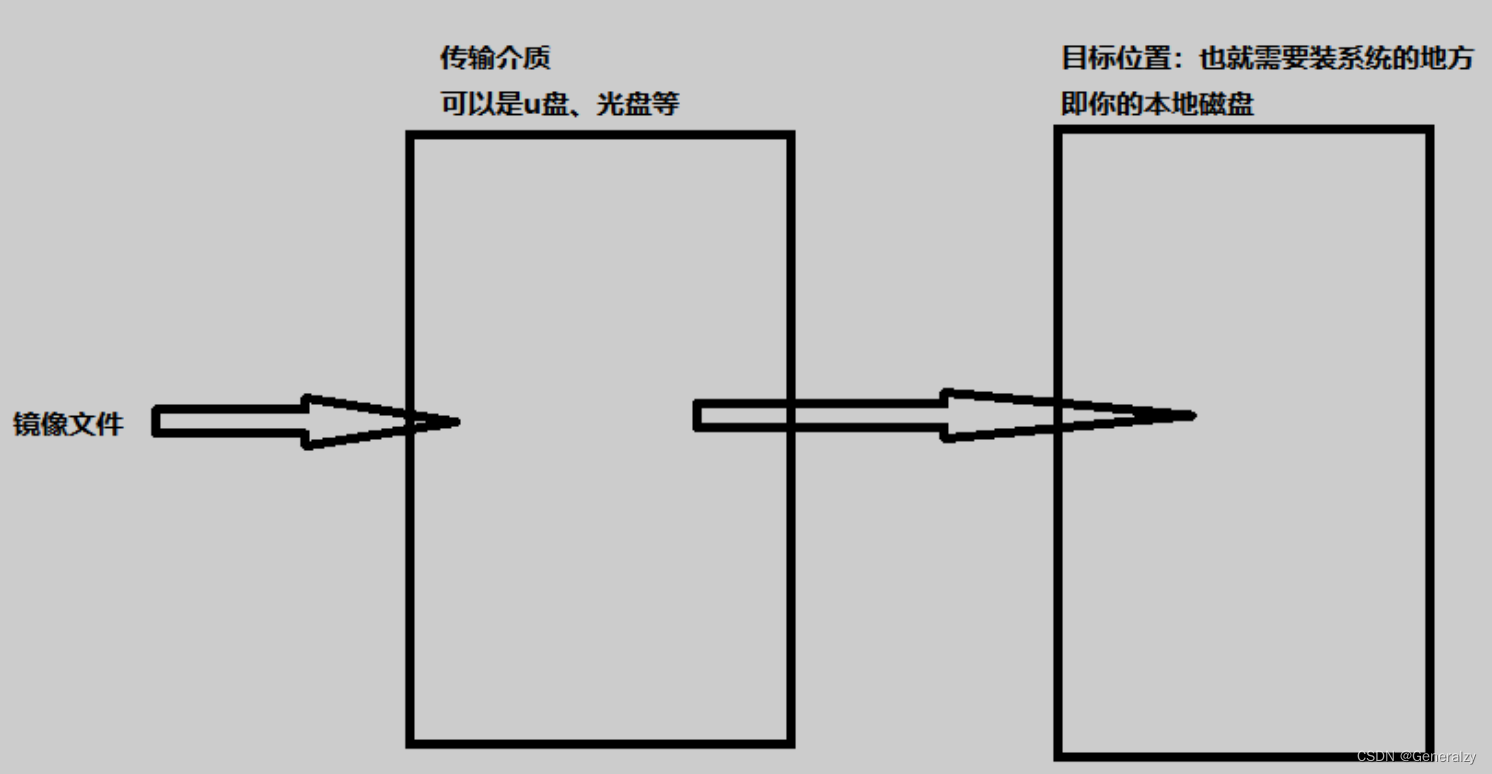
如何为容器安装操作系统呢?原理都是一样的,对于容器来说,想在宿主机上启动多个容器,让它们拥有操作系统,所以宿主机就是我们的传输介质,目标位置就是容器。需要做的就是把容器的镜像下载到宿主机就可以,让把容器的镜像文件关联给每个容器就行,如果想让容器有不同的系统,那就关联不同的镜像就可以,不同的镜像就是不同的系统。
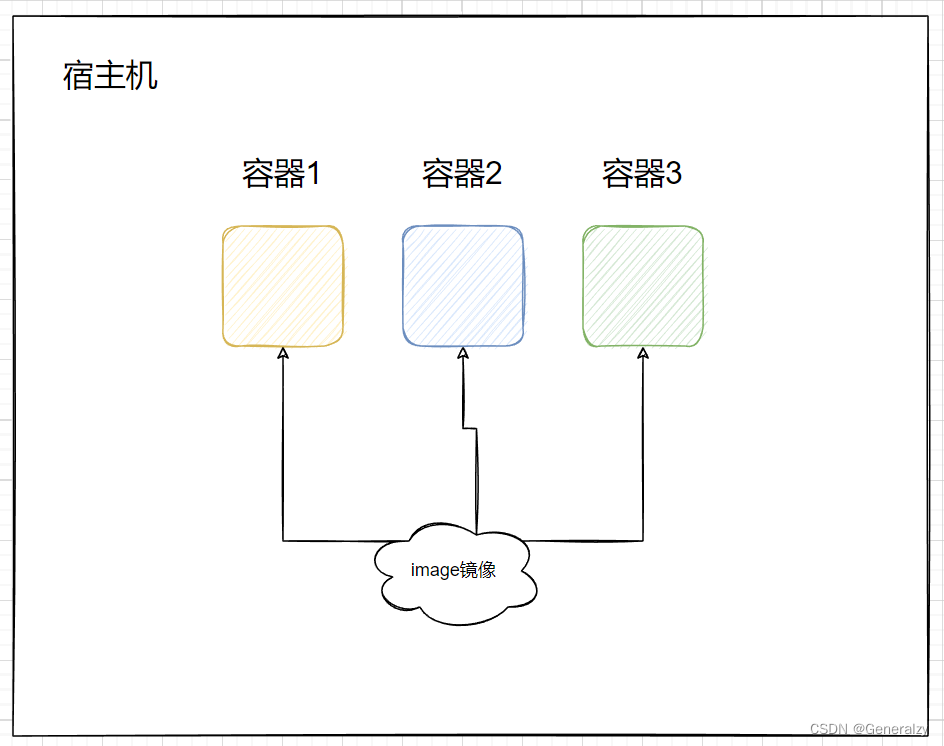
但对于虚拟机来说,系统镜像很笨重,每个虚拟机要想拥有自己的操作系统,都需要把一份操作系统镜像的内存完整地拷贝给它,如果一个镜像为1G,部署了10台虚拟机,就需要耗费10G的空间,而这10G的内容都是冗余的。
所以对于容器来说,具体做法并不是把容器镜像直接拷贝给每个容器的名称空间,而是通过挂载的方式完成的,而且是以只读的方式挂载的,至于容器内只负责存自己新增的改动就可以,不影响其他容器,这就用到了UnionFS(联合文件系统)技术。
同一个镜像启动多个容器的本质
容器的镜像的本质就是rootfs,启动容器,指定镜像的意义,就是为了把rootfs共享给容器的名称空间,这就如同给容器安装了一个操作系统一样。
共享的意思指的就是,用一个镜像启动容器,其实是把该镜像里的目录都mount挂载到了容器名称空间内,并且设置为只读,也就说,我们用同一个镜像启动了10个容器,其实本质就是把这个镜像里的目录mount给了10个容器名称空间而已,因此大家是共享镜像的。
与namespace联合在一起思考,namespace中隔离的诸多资源中就包括mount挂载,如此,哪怕是同一个镜像,mount到了不同的容器或者说名称空间里,肯定是与其他容器/名称空间隔离的。
容器内如何写入数据
多个容器用一个镜像启动,本质是以只读方式把镜像目录都mount到了每个容器的名称空间里。要想理解明明启动容器是以只读方式把rootfs里包含的目录挂载到容器里,但是却可以在容器里执行增删改查操作,那就需要了解一下UnionFS联合文件系统。
容器内的rootfs根文件系统类型,并不是在普通linux节点上看到的Ext4或者XFS之类的常见文件系统,而是Overlay,Overlay是一种联合文件系统UnionFS(OverlayFS简称overlay 是 UnionFS 的一种具体实现),联合文件系统顾名思义,可以把文件系统上多个目录(分支)内容联合挂载到同一个目录下,使用者也就是容器看起来认为是一个目录,而实际上在物理机里是由多个目录构成的。
OverlayFS使用两个目录,把一个目录置放于另一个之上,并且对外提供单个统一的视角。这两个目录通常被称作层,这个分层的技术被称作union mount。术语上,下层的目录叫做lowerdir,上层的叫做upperdir。对外展示的统一视图称作merged。
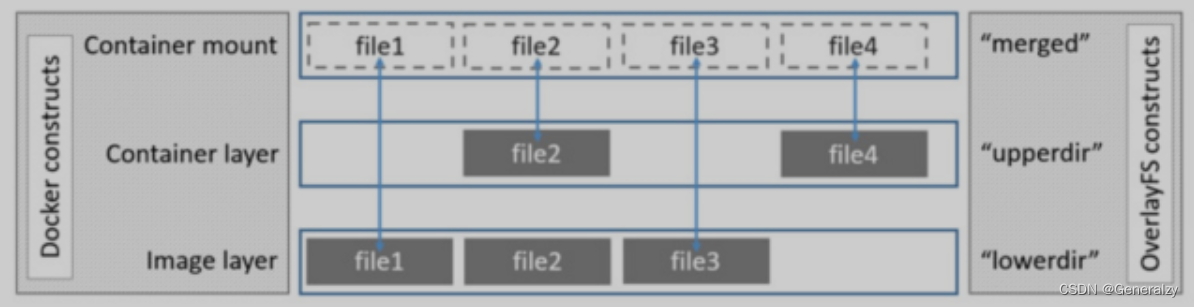
lowerdir—>镜像层,只读,
upperdir—->容器层,修改相关的内容都在这里放着,
merged—->容器映射层,在容器里看到的就是这一层,所以该层也可以称之为展现层。
针对这三层,从下往下看,看到的merged里的内容来自与upperdir与lowdir,upperdir里的内容会遮挡住lowerdir里的内容。
image 里面是一层层文件系统,叫做 Union FS(联合文件系统)。联合文件系统,可以将几层目录挂载到一起,形成一个虚拟文件系统。虚拟文件系统的目录结构就像普通 linux 的目录结构一样,docker 通过这些文件再加上宿主机的内核提供了一个 linux 的虚拟环境。每一层文件系统我们叫做一层 layer,联合文件系统可以对每一层文件系统设置三种权限,只读(readonly)、读写(readwrite)和写出(whiteout-able),但是 docker 镜像中每一层文件系统都是只读的。
lowerDir:挂载的是镜像层,init里放的是一些hosts、hostname、resolv.conf文件,因为每个容器启动
可能指定的网络,还有主机名都不一样,所以这些文件会单独挂载,docker引擎启动时候会动态修改保证每个容器的主机名等信息不一样,后面的diff目录就是镜像的rootfs,有几个就是代表这个镜像有几层(初始情况就一层,
有可能该镜像是别人基于基础的centos镜像commit了很多次,即被制作了很多次,那么镜像的层级就会很多)
upperdir:是容器的可写层,改动的文件都在这里,upperdir的内容+lowerdir的内容共同构成了merged的内容,一切以upperdir为准,没有的去lowerdir中要。如果是读,upperdir中没有则直接读lowerdir;如果是写,则将文件从lowerdir中拷贝到upperdir中才能写,写完后,下次再写就直接从upperdir中取; 如果是删除,则在upperdir中将文件设置为隐藏,并不会真的删除掉lowerdir中的文件:
- 容器会在镜像层创建一个whiteout文件,而镜像层的文件并没有删除,但是whiteout文件会隐藏它。
- 容器中删除一个目录,容器层会创建一个不透明目录,这和whiteout文件隐藏镜像层的文件类似
如果是重命名目录 只有在源文件和目的路径都在顶层容器层upperdir时,才允许执行rename操作。
容器overlay读写有三种场景
-
lowerdir里有,upperdir里没有
容器会通过overlay只读访问文件 容器层不存在的文件 如果容器只读打开一个文件,但该容器不在容器层(upperdir),就要从镜像层(lowerdir)中读取。这会引起很小的性能消耗。
-
lowerdir里没有,upperdir里有
只存在于容器层的文件 如果容器只读权限打开一个文件,并且容器只存在于容器层(upperdir)而不是镜像层(lowerdir),那么直接从镜像层读取文件,无额外的性能损耗
-
lowerdir里有,upperdir里也有
文件同时存在于容器层和镜像层 那么会读取容器层的文件,因为容器层(upperdir)隐层了镜像层(lowerdir)的同名文件,因此,也没有额外的性能损耗
总结一句话就是,lowerdir镜像层里的内容是只读的(可以通过挂载配置只读),增删改的文件都写到upperdir里,upperdir里的同名文件会遮挡住lowdir里的内容、优先级更高,lowerdir+upperdir联合挂载到了merged里.
至此,你应该明白,镜像层里的内容肯定是只读的,但是读写的内容其实都放到了upperdir里,并且因为upperdir对lowerdir有遮挡效果,在当前容器里,可以看到修改,在其他容器里可能没有修改、于是在upperdir里看不到修改,没有遮挡,则看到的仍是lowerdir里的内容。
runtime
Docker、Containerd、RunC 间的联系和区别
OCI的由来
容器技术起源于1979年,发展至今已经超过40年,docker 只能说是目前为止,其中一种比较著名而流行的实现。
Docker 于 2013 年发布,解决了开发人员在端到端运行容器时遇到的许多问题,让应用分发变得十分便捷。这里是docker包含的所有东西:
- 容器镜像格式
- 一种构建容器镜像的方法(Dockerfile/docker build);
- 一种管理容器镜像(docker image、docker rm等);
- 一种管理容器实例的方法(docker ps, docker rm 等);
- 一种共享容器镜像的方法(docker push/pull);
- 一种运行容器的方式(docker run);
在当时,Docker是一个单体系统,并没有考虑到要与其他系统比如k8s对接,所以docker本身提供了尽可能完善的功能。但是,docker设计巧妙之处在于,上述这些功能中没有一个是真正相互依赖的、都是解耦合的。也就是说这些功能中的每一个都能够在、可以一起使用的、更小、更集中的工具中实现。每个工具都可以通过使用一种通用格式、一种容器标准来协同工作。
自从docker发布之后,便一炮而红,很快用的人越来越多,大家都意识到容器时代的到来,很多人从这里面嗅到了金钱的味道,你能发布一个docker容器技术,我也能发布一个fucker容器技术,就好比是CS游戏火了,我立马抄一个穿越火线一个道理。于是很多组织或个人都参与到了容器的开发工作中来,导致容器由很多不同的实现,但长此以往必然会引起混乱、不兼容。
为了解决这一问题,Docker、Google、CoreOS 和其他供应商于 2015-6-22 建立的一个开源组织,名为OCI,全称 Open Container Initiative开放容器倡议 ,隶属于Linux基金会,其目的主要是为了制定容器技术的通用技术标准。
目前OCI旗下主要有两个标准文档:
1. 容器运行时标准 (runtime spec)
2. 容器镜像标准(image spec)
OCI 对容器 runtime 的标准主要是指定容器的运行状态,和 runtime 需要提供的命令。下图可以是容器状态转换图:
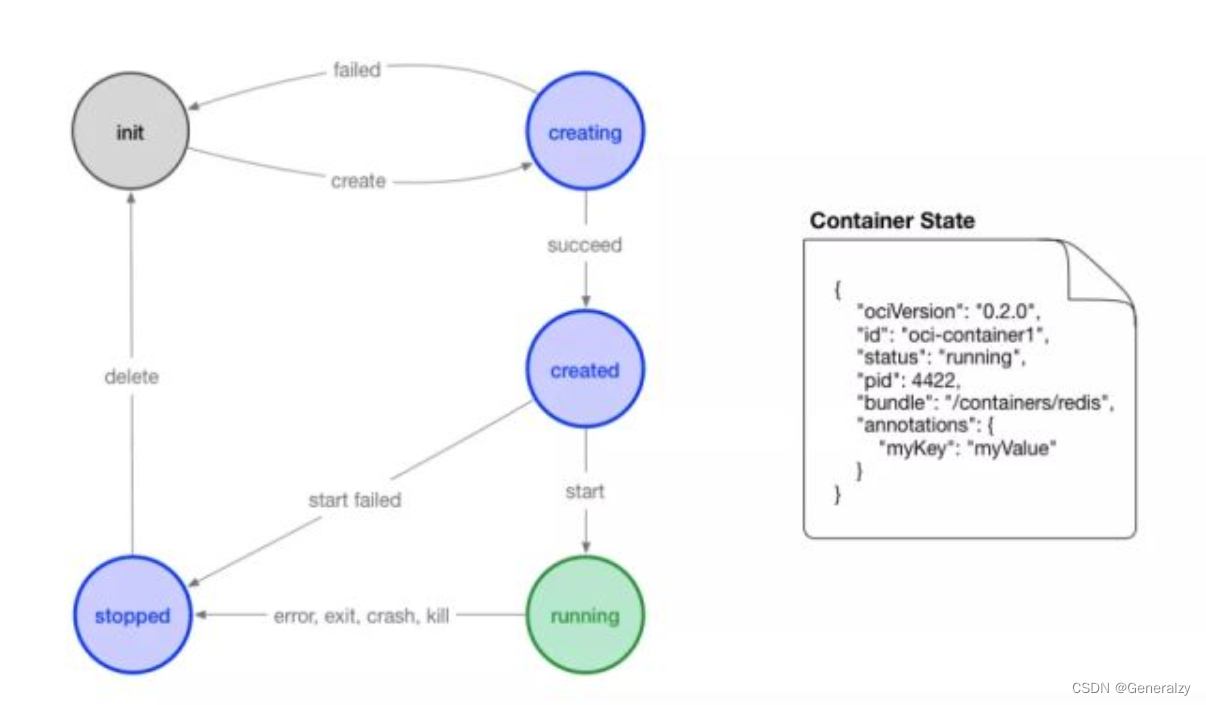
- init 状态:该状态并不在标准中,表示没有容器存在的初始状态
- creating:使用 create 命令创建容器,这个过程称为创建中
- created:容器创建出来,但是还没有运行,表示镜像和配置没有错误,容器能够运行在当前平台
- running:容器的运行状态,里面的进程处于 up 状态,正在执行用户设定的任务
- stopped:容器运行完成,或者运行出错,或者 stop 命令之后,容器处于暂停状态。这个状态,容器还有很多信息保存在平台中,并没有完全被删除
docker的分层
docker的构成
从 Docker 1.11 之后,Docker Daemon由当年的单体实现被分成了多个标准的模块。标准化的目的是模块是可被其他实现替换的,不由任何一个厂商控制。
拆分之后,docker的结构分成了以下5个部分/模块:
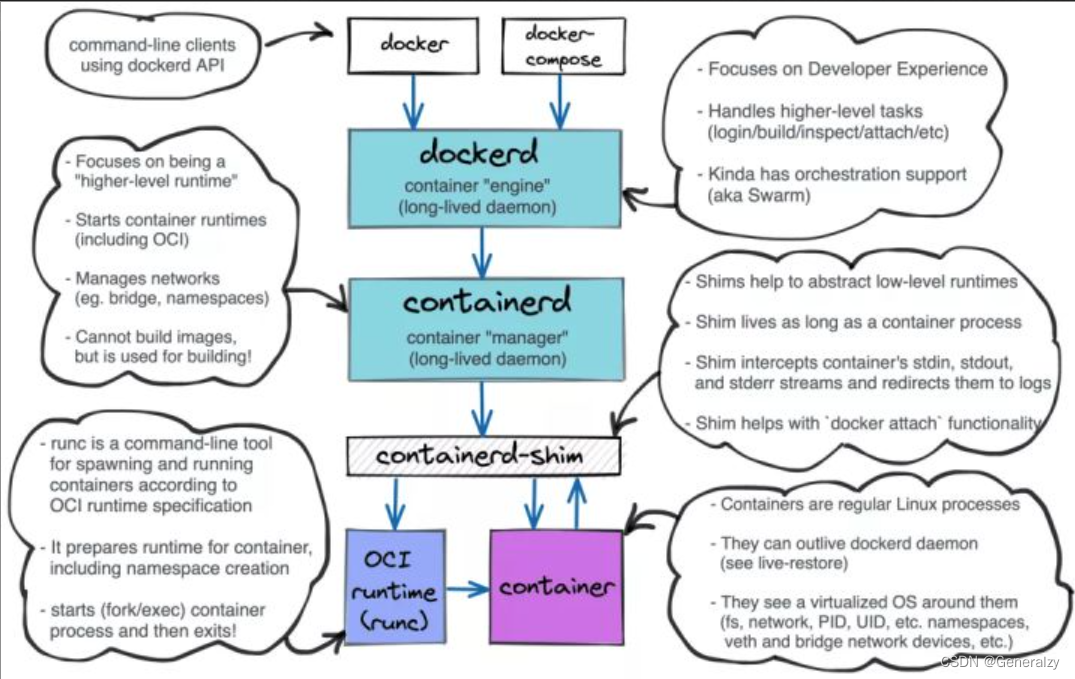
-
docker-client:客户端命令
-
dockerd守护进程,全称docker daemon
提供客户端命令接口 -
containerd服务
containerd 独立负责容器运行时和生命周期(如创建、启动、停止、中止、信号处理、删除等),其他一些如镜像构建、卷管理、日志等由 dockerd(docker daemon) 的其他模块处理。 -
containerd-shim进程:该进程由containerd服务创建
每创建一个容器,都会启动一个containerd-shim进程,然后由该进程调用runc来具体创建容器 -
runc组成:由container-shim进程调用runc创建出的容器进程
最早docker只是把RunC 单拿出来,捐赠给 OCI 作为OCI 容器运行时标准的参考实现(因为docker的设计就是比大多数容器技术的实现优秀一些,所以docker说我把我的实现分享出来,大家也就别创造了,照着我的来就行),即runc就是安装oci标准实现的,使用runc可以创建一个符合oci规范的容器。
为什么需要有containerd-shim这个进程
现在创建一个docker容器的时候(注意我说的是docker容器而不是其他种类的容器),Docker Daemon 并不能直接帮我们创建了,而是请求 containerd 服务来创建一个容器。
当 containerd 收到请求后,也不会直接去操作容器,而是创建一个叫做 containerd-shim 的进程。让这个进程去操作容器,我们指定容器进程是需要一个父进程来做状态收集、维持 stdin 等 fd 打开等工作的,假如这个父进程就是 containerd,那如果 containerd 挂掉的话(例如重启docker服务时),整个宿主机上所有的容器都得退出了,而引入 containerd-shim 这个垫片就可以来规避这个问题了。
也就说真正启动容器是通过 containerd-shim 去调用 runc 来启动容器的,启动容器需要做一些 namespaces 和 cgroups 的配置,以及挂载 root 文件系统等操作。runc 会按照OCI 标准来创建一个符合规范的容器。
runc 启动完容器后本身会直接退出,containerd-shim 则会成为容器进程的父进程, 负责收集容器进程的状态, 上报给 containerd, 并在容器中 pid 为 1 的进程退出后接管容器中的子进程进行清理, 确保不会出现僵尸进程。
containerd、containerd-shim及容器进程的关系
containerd,containerd-shim和容器进程(即容器主进程)三个进程,是有依赖关系的。
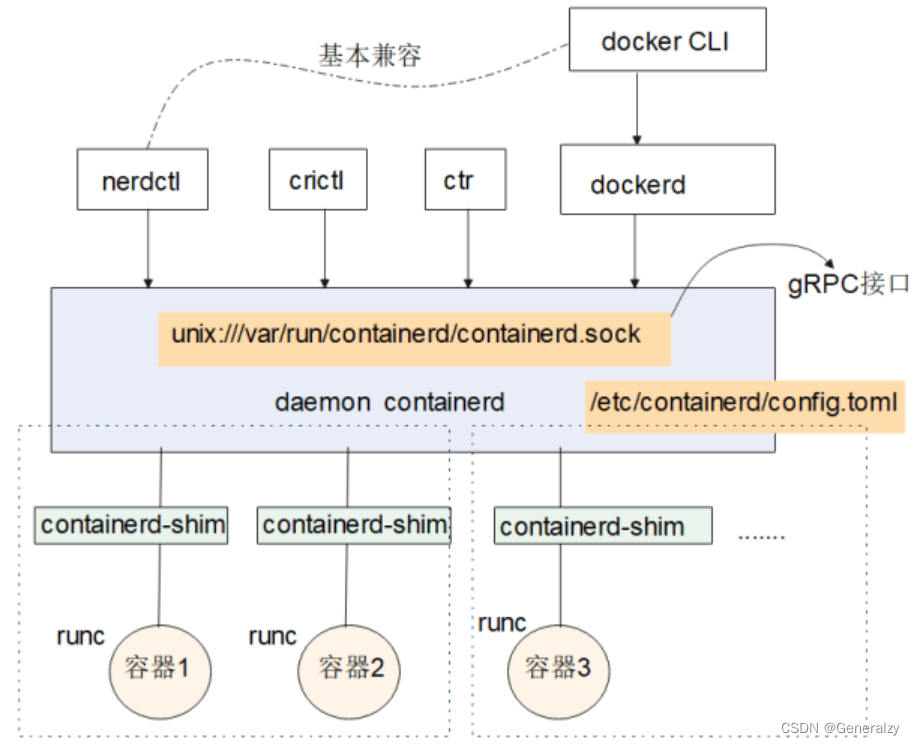
层级关系总结如下:
dockerd
containerd
containerd-shim----runc---->容器进程
containerd-shim----runc---->容器进程
containerd-shim----runc---->容器进程
runtime容器运行时
容器运行时分类
runtime翻译为容器运行时,指的是用来管理镜像或容器的软件,之所以起名为“容器运行时“,大概是想表达此类软件是用于容器运行时期的涉及到管理操作,例如管理镜像、容器等。
从docker的构成图中,只标注了runc为runtime容器运行时,但事实上,用于管理容器运行时的诸多操作的软件都可以称之为为runtime软件,所以你看到的docker构成中的dockerd、containerd都应该属于runtime。
但dockerd、containerd还有runc各自负责的事情不同,所以为了更好的区分开他们,我们将容器运行时软件分为两大类:
-
Low-Level容器运行时:比如lxc、runc、gvisor、kata等,只涉及到容器运行的一些基础细节,比如namespace创建、cgroup设置,
-
High-Level容器运行时:比如docker、containerd、podman等,支持更多高级功能(如镜像管理和gRPC / Web API),对于高级别运行时来说,他们是通过调用低级别运行时来管理容器(可以简单的理解为高级别是在低级别基础上的上层封装),一般可以是runc作为低级别运行时。
通常情况下,开发人员想要运行一个容器不仅仅需要Low-Level容器运行时提供的这些特性,同时也需要与镜像格式、镜像管理和共享镜像相关的API接口和特性,而这些特性一般由High-Level容器运行时提供。就日常使用来说,Low-Level容器运行时提供的这些特性可能满足不了日常所需,因为这个缘故,唯一会使用Low-Level容器运行时的人是那些实现High-Level容器运行时以及容器工具的开发人员。那些实现Low-Level容器运行时的开发者会说High-Level容器运行时比如containerd和cri-o不像真正的容器运行时,因为从他们的角度来看,他们将容器运行的实现外包给了runc。但是从用户的角度来看,它们只是提供容器功能的单个组件,可以被另一个的实现替换。
Low-Level和High-Level容器运行时
当人们想到容器运行时,可能会想到一系列示例;runc、lxc、lmctfy、Docker(容器)、rkt、cri-o。这些中的每一个都是为不同的情况而构建的,并实现了不同的功能。有些,如 containerd 和 cri-o,实际上使用 runc 来运行容器,在High-Level实现镜像管理和 API。与 runc 的Low-Level实现相比,可以将这些功能(包括镜像传输、镜像管理、镜像解包和 API)视为High-Level功能。
考虑到这一点,可以看到容器运行时空间相当复杂。每个运行时都涵盖了这个Low-Level到High-Level频谱的不同部分。这是一个非常直观的图表:
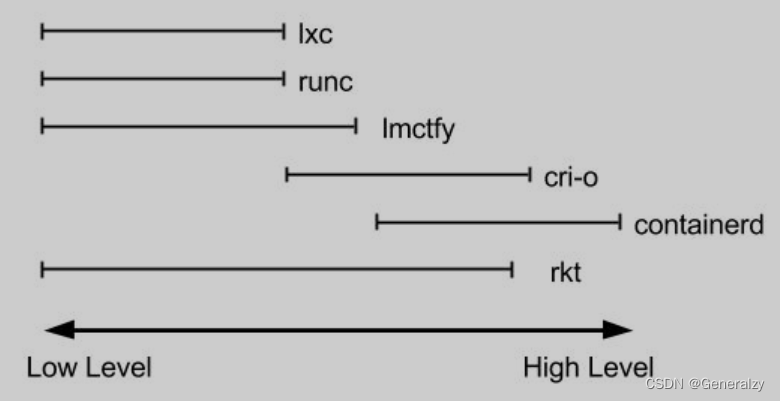
因此,从实际出发,通常只专注于正在运行的容器的runtime通常称为“Low-Level容器运行时”,支持更多高级功能(如镜像管理和gRPC / Web API)的运行时通常称为“High-Level容器运行时”,“High-Level容器运行时”或通常仅称为“容器运行时”,我将它们称为“High-Level容器运行时”。值得注意的是,Low-Level容器运行时和High-Level容器运行时是解决不同问题的、从根本上不同的事物。
Low-Level容器运行时:
容器是通过Linux nanespace和Cgroups实现的,Namespace能让你为每个容器提供虚拟化系统资源,像是文件系统和网络,Cgroups提供了限制每个容器所能使用的资源的如内存和CPU使用量的方法。在最低级别的运行时中,容器运行时负责为容器建立namespaces和cgroups,然后在其中运行命令。Low-Level容器运行时支持在容器中使用这些操作系统特性。目前来看低级容器运行时有:
- runc :我们最熟悉也是被广泛使用的容器运行时,代表实现Docker。
- runv:runV 是一个基于虚拟机管理程序(OCI)的运行时。它通过虚拟化 guest kernel,将容器和主机隔离开来,使得其边界更加清晰,这种方式很容易就能帮助加强主机和容器的安全性。代表实现是kata和Firecracker。
- runsc:runsc = runc + safety ,典型实现就是谷歌的gvisor,通过拦截应用程序的所有系统调用,提供安全隔离的轻量级容器运行时沙箱。截止目前,貌似并没有生产环境使用案例。
- wasm : Wasm的沙箱机制带来的隔离性和安全性,都比Docker做的更好。但是wasm 容器处于草案阶段,距离生产环境尚有很长的一段路。
High-Level容器运行时:
通常情况下,开发人员想要运行一个容器不仅仅需要Low-Level容器运行时提供的这些特性,同时也需要与镜像格式、镜像管理和共享镜像相关的API接口和特性,而这些特性一般由High-Level容器运行时提供。就日常使用来说,Low-Level容器运行时提供的这些特性可能满足不了日常所需,因为这个缘故,唯一会使用Low-Level容器运行时的人是那些实现High-Level容器运行时以及容器工具的开发人员。那些实现Low-Level容器运行时的开发者会说High-Level容器运行时比如containerd和cri-o不像真正的容器运行时,因为从他们的角度来看,他们将容器运行的实现外包给了runc。但是从用户的角度来看,它们只是提供容器功能的单个组件,可以被另一个的实现替换,因此从这个角度将其称为runtime仍然是有意义的。即使containerd和cri-o都使用runc,但是它们是截然不同的项目,支持的特性也是非常不同的。dockershim, containerd 和cri-o都是遵循CRI的容器运行时,我们称他们为高层级运行时(High-level Runtime)。
Low-Level容器运行时之Runc
RunC 是从 Docker 的 libcontainer 中迁移而来的,实现了容器启停、资源隔离等功能。Docker将RunC捐赠给 OCI 作为OCI 容器运行时标准的参考实现。Docker 默认提供了 docker-runc 实现。事实上,通过 containerd 的封装,可以在 Docker Daemon 启动的时候指定 RunC的实现。最初,人们对 Docker 对 OCI 的贡献感到困惑。他们贡献的是一种“运行”容器的标准方式,仅此而已。它们不包括镜像格式或注册表推/拉格式。当你运行一个 Docker 容器时,这些是 Docker 实际经历的步骤:
- 下载镜像
- 将镜像文件解开为bundle文件,将一个文件系统拆分成多层
- 从bundle文件运行容器
Docker标准化的仅仅是第三步。在此之前,每个人都认为容器运行时支持Docker支持的所有功能。最终,Docker方面澄清:原始OCI规范指出,只有“运行容器”的部分组成了runtime。这种“概念失联”一直持续到今天,并使“容器运行时”成为一个令人困惑的话题。希望我能证明双方都不是完全错误的,并且在本文中将广泛使用该术语。RunC 就可以按照这个 OCI 文档来创建一个符合规范的容器,既然是标准肯定就有其他 OCI 实现,比如 Kata、gVisor 这些容器运行时都是符合 OCI 标准的。
High-Level容器运行时之containred
当安装好containerd之后,会有一个服务器进程containerd,他所使用的配置文件是/etc/containerd/config.toml。这个服务器进程会生成一个接口并客户端来连接(通过gRPC协议),这个接口就是/var/run/containerd/containerd.sock。
因为在操作系统里目录/var/run是/run的软连接(快捷方式),所以/run/containerd/containerd.sock和/var/run/containerd/containerd.sock是同一个文件。
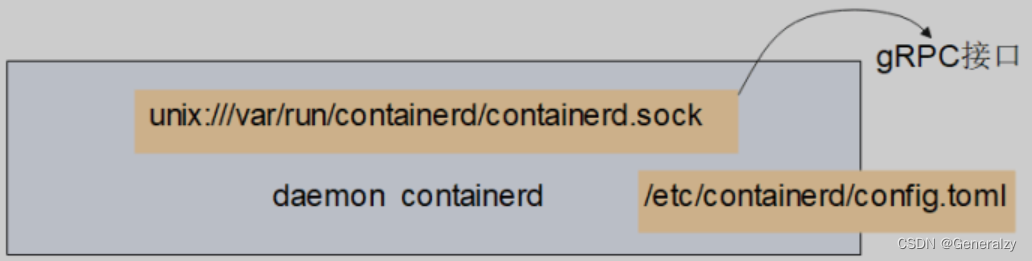
kubernetes1.20的kubelet就是通过gRPC协议连接/var/run/containerd/containerd.sock,是它的一个客户端。
与RunC,我们又可以在这里看到一个docker公司的开源产品containerd,曾经是开源docker项目的一部分。尽管containerd是另一个自给自足的软件。
-
一方面,containerd 称自己为容器运行时,但与运行时 RunC 不同。不仅 containerd 和 runc 的职责不同,组织形式也不同。显然 runc 只是一个命令行工具,而 containerd 是一个长期居住的守护进程。runc 的实例不能超过底层容器进程。通常它在 create 调用时开始它的生命周期,然后只是在容器的 rootfs 中的指定文件中运行。
-
另一方面,containerd 可以管理超过数千个 runc 容器。它更像是一个服务器,它侦听传入请求以启动、停止或报告容器的状态。在引擎盖下 containerd 使用 RunC。然而,containerd 不仅仅是一个容器生命周期管理器。它还负责镜像管理(从注册中心拉取和推送镜像,在本地存储镜像等)、跨容器网络管理和其他一些功能。
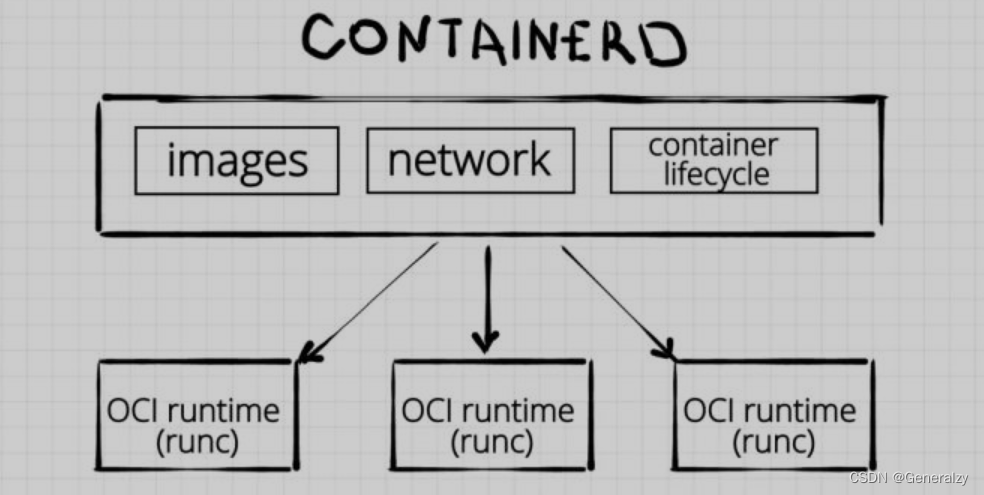
containerd 是一个工业级标准的容器运行时,它强调简单性、健壮性和可移植性,containerd 可以负责干下面这些事情:
1 .管理容器的生命周期(从创建容器到销毁容器)
2. 拉取/推送容器镜像
3. 存储管理(管理镜像及容器数据的存储)
4. 调用 runc 运行容器(与 runc 等容器运行时交互)
5. 管理容器网络接口及网络
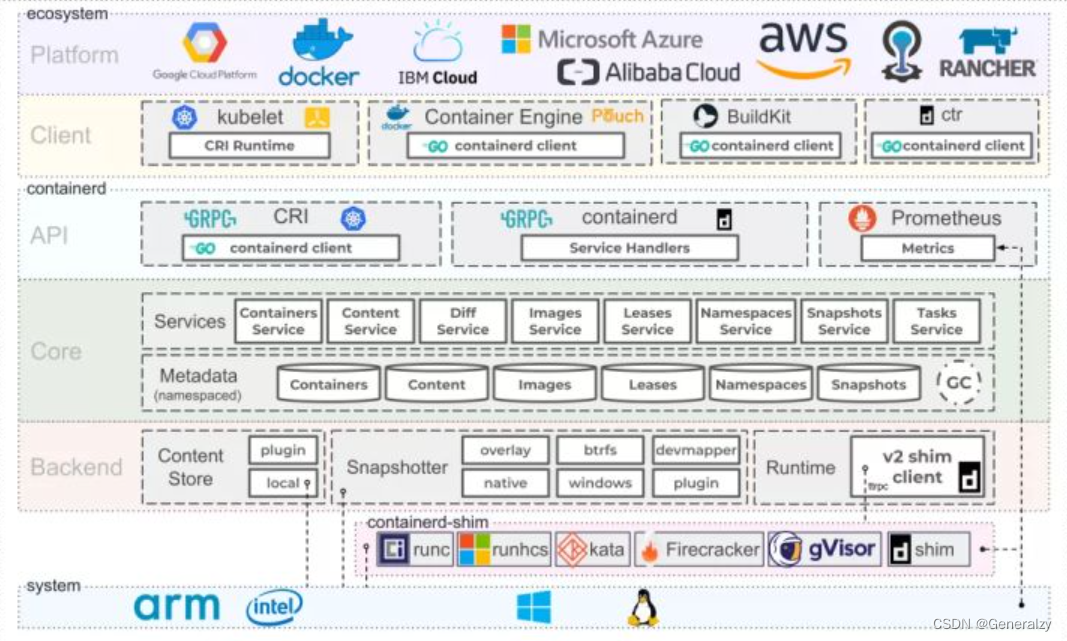
上图是 Containerd 整体的架构。由下往上,Containerd支持的操作系统和架构有 Linux、Windows 以及像 ARM 的一些平台。在这些底层的操作系统之上运行的就是底层容器运行时,其中有上文提到的runc、gVisor 等。在底层容器运行时之上的是Containerd 相关的组件,比如 Containerd 的 runtime、core、API、backend、store 还有metadata 等等。构筑在 Containerd 组件之上以及跟这些组件做交互的都是 Containerd 的 client,Kubernetes 跟 Containerd 通过 CRI 做交互时,本身也作为 Containerd 的一个 client。Containerd 本身有提供了一个 CRI,叫 ctr,不过这个命令行工具并不是很好用。
在这些组件之上就是真正的平台,Google Cloud、Docker、IBM、阿里云、微软云还有RANCHER等等都是,这些平台目前都已经支持 containerd, 并且有些已经作为自己的默认容器运行时了。
从 k8s 的角度看,选择 containerd作为运行时的组件,它调用链更短,组件更少,更稳定,占用节点资源更少。
第一条链接是k8s1.20以前的,第二条链路是k8s1.20以后的,这就是我们所说的所谓k8s抛弃docker的原因:
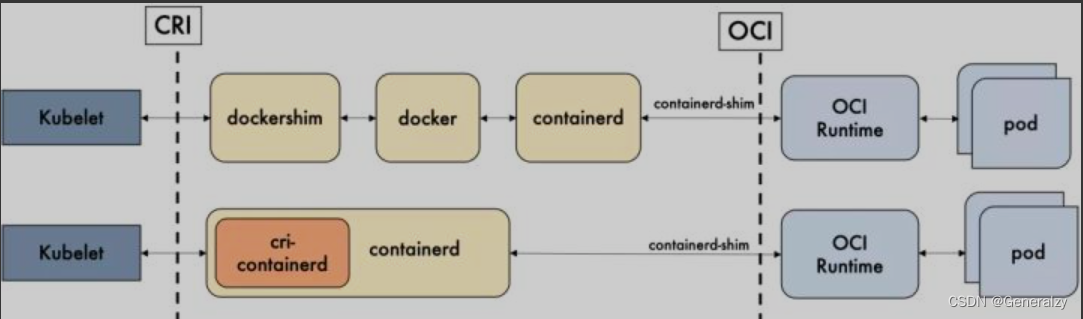
调用链:
1、Docker 作为 k8s 容器运行时,调用关系如下:
kubelet –> docker shim (在 kubelet 进程中) –> dockerd –> containerd
2、Containerd 作为 k8s 容器运行时,调用关系如下:
kubelet –> cri plugin(在 containerd 进程中) –> containerd
k8s为何"抛弃"docker
原因如下:
- docker比k8s发布的早;
- Docker 本身不兼容 CRI 接口,官方并没有实现 CRI 的打算,同时也不支持容器的一些新需求,社区想要摆脱Dockershim的高维护成本。
- k8s不能直接与docker通信,只能与 CRI 运行时通信,要与 Docker 通信,就必须使用桥接服务(dockershim),4. k8s要与docker通信是通过节点代理Kubelet的Dockershim(k8s社区维护的)将请求转发给管理容器的 Docker 服务。
- Dockershim 一直都是 Kubernetes 为了兼容 Docker 获得市场采取的临时方案(决定)。
- k8s在过去因为 Docker 的热门而选择它,现在又因为高昂的维护成本而放弃它,我们能够从这个过程中体会到容器领域的发展和进步。
- 对于已经统治市场的k8s来说,Docker 的支持显得非常鸡肋,移除代码也就顺理成章。
- 在集群中运行的容器运行时往往不需要docker这么复杂的功能,k8s需要的只是 CRI 中定义的那些接口。
- Mirantis公司未来会和Docker共同维护Dockershim,并作为一个开源组件提供;对于正式生产环境还是建议采用兼容CRI的containerd之类的底层运行时。
2020 年 12 月,Kubernetes 社区决定着手移除仓库中 Dockershim 相关代码,对于k8s和 Docker 两个社区来说都意义重大。K8s决定在 1.20 开始放弃 Docker,并在1.21完全抛弃 Docker 的支持。
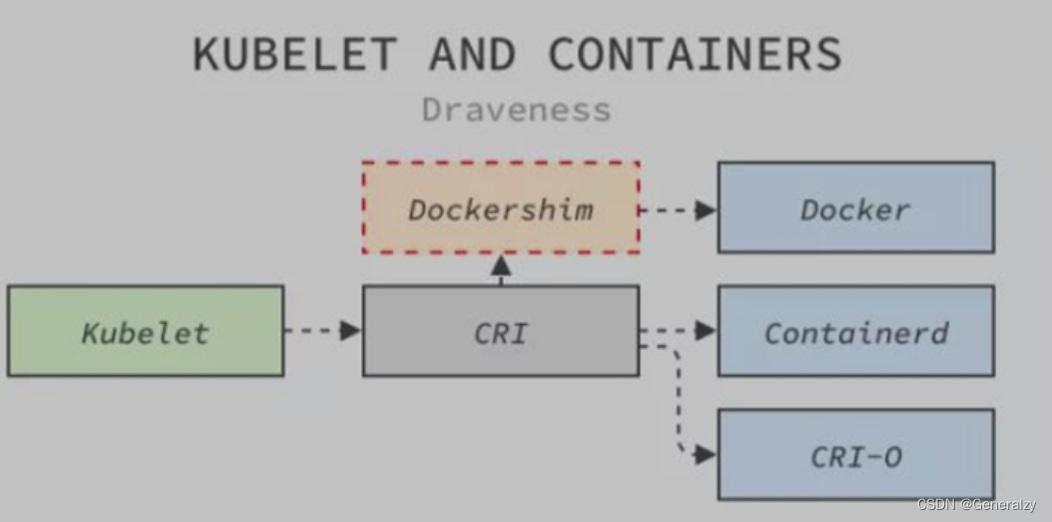
如上图所示,Kubernetes节点代理 Kubelet为了访问Docker提供的服务需要先经过社区维护的 Dockershim,Dockershim 会将请求转发给管理容器的 Docker 服务。
容器里的进程管理
容器内的两个特殊进程
容器正常启动后,使用docker exec contaienrID bash进入容器后,使用ps命令,一般有两个特殊进程:
-
1号进程 为容器首启动进程,容器的pid namespcae就是由1号进创建的,容器内其余进程基本都是首启动进程的子进程。只要1号进程挂掉那容器便会关闭,pid namespace会被回收。
-
0号进程 为1号进程的父进程,也为docker exec…携带指令的父进程(即从外部向running容器内发起的指令)。当然你要干掉了0号进程,容器一样完蛋。
1、tail -f /dev/null是容器内的1号进程,而1号进程的父进程则是0号进程
2、docker exec执行的命令是sh,该命令是在容器已经running之后运行的,产生的sh进程的父进程为0号进程
3、在sh环境里执行的新命令如下所示sleep 1000 &,当然都是sh的儿子。
[root@test01 init5]# docker container run -d --name test centos:7 tail -f /dev/null
[root@test01 init5]#
[root@test01 init5]# docker exec -ti test sh
sh-4.2# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 04:27 ? 00:00:00 tail -f /dev/null
root 6 0 0 04:27 pts/0 00:00:00 sh
root 13 6 0 04:27 pts/0 00:00:00 ps -ef
sh-4.2#
sh-4.2# sleep 1000 &
[1] 14
sh-4.2# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 04:27 ? 00:00:00 tail -f /dev/null
root 6 0 0 04:27 pts/0 00:00:00 sh
root 14 6 0 04:27 pts/0 00:00:00 sleep 1000
root 15 6 0 04:28 pts/0 00:00:00 ps -ef
sh-4.2#
容器内的0号进程
=====>对于linux系统来说:
- linux启动的第一个进程是0号进程,是静态创建的;
- 在0号进程启动后会接连创建两个进程,分别是1号进程和2和进程。
- 1号进程最终会去调用可init可执行文件,init进程最终会去创建所有的应用进程。
- 2号进程会在内核中负责创建所有的内核线程
- 所以说0号进程是1号和2号进程的父进程;1号进程是所有用户态进程的父进程;2号进程是所有内核线程的父进程。
===========>对于容器来说:
- 在容器平台上,无论你是用k8s去删除一个pod,或者用docker关闭一个容器,都会用到Containerd这个服务。
- 在k8s里,创建pod会时,kubelet收到创建pod的请求后,会调用dockerDaemon发起创建容器请求,然后由containerd接收请求来创建containerd-shim进程,然后containerd-shim去调用runc来启动容器。
- 真正启动容器是通过 containerd-shim 去调用 runc 来启动容器的,runc 启动完容器后本身会直接退出,containerd-shim 则会成为容器进程的父进程, 负责收集容器进程的状态, 上报给 containerd, 并在容器中 pid 为 1 的进程退出后接管容器中的子进程进行清理, 确保不会出现僵尸进程。containerd,containerd-shim和容器进程(即容器主进程)三个进程,是有依赖关系的。
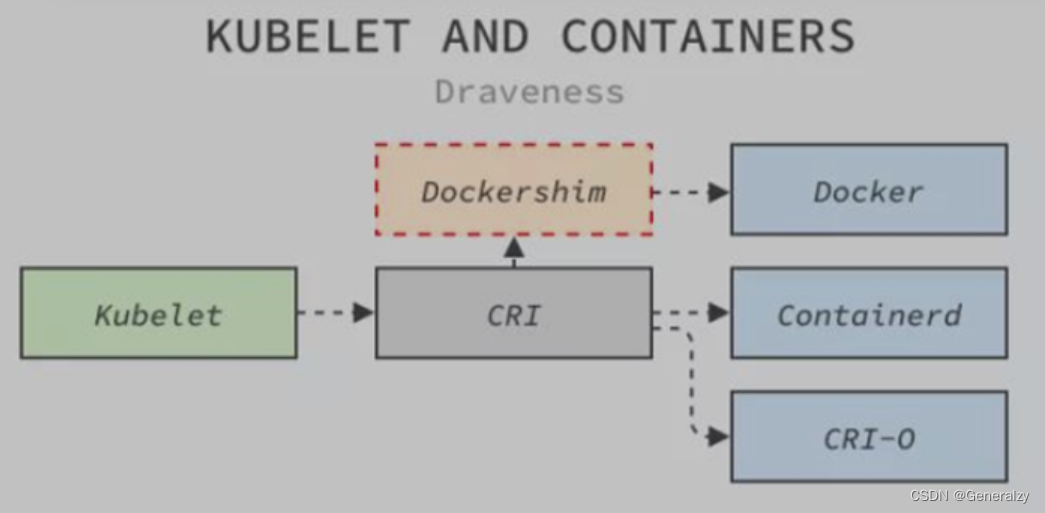
- 如果只是用docker创建容器,那就是直接调用dockerDaemon发起创建容器请求,然后由containerd接收请求来创建containerd-shim进程,然后containerd-shim去调用runc来启动容器。
containerd-shim就是上面提到的0号进程,关于containerd-shim需要掌握3个关键知识点:
- 实际的创建容器、容器内执行指令等都实际上是由
containerd-shim进程在执行。 containerd-shim进程是容器的父进程,具备回收僵尸进程的功能。当容器的1号进程退出后,内核会清理其下的子孙进程,这些子孙进程会被containerd-shim收养并清理。但如果容器内的1号进程没有被杀死,那么其下的僵尸进程将无法被处理。因此,用户开发的容器首进程需要注意回收退出的进程。- Containerd在stop停止容器的时候,会向容器的1号进程发送一个-15信号,如果容器内的1号进程没有信号转发能力,那在回收pid namespce时会向该namespace里的所有其他进程发送SIGKILL信号信号强制杀死。
1. 当我们使用 `kill pid` 时,实际上相当于 `kill -15 pid`。也就是说默认信号是15。使用 `kill -15` 时,系统会发送一个 SIGTERM 信号给对应的程序。程序接收到该信号后可以决定如何处理。
2. 应用程序可以选择:
- 立即停止程序
- 释放响应资源后停止程序
- 忽略该信号,继续执行程序
3. 因为 `kill -15` 信号只是通知对应的进程进行 "安全、干净的退出",程序接收到信号后,通常会进行一些 "准备工作",如资源释放、临时文件清理等。如果准备工作完成,再进行程序的终止。
4. 如果在 "准备工作" 过程中遇到阻塞或其他问题导致无法成功,应用程序可以选择忽略该终止信号。
5. 有时候使用 `kill` 命令无法 "杀死" 应用的原因是,默认的 `kill` 信号是 SIGTERM(15),而 SIGTERM(15)的信号是可以被阻塞和忽略的。
6. 与 `kill -15` 相比,`kill -9` 相对强硬,系统会发送 SIGKILL 信号,要求接收到该信号的程序立即结束运行,不能被阻塞或忽略。
7. 因此,`kill -9` 执行时,应用程序没有时间进行 "准备工作",通常会带来一些副作用,如数据丢失或终端无法恢复到正常状态等。
启动一个容器
docker run -d --name test1 centos:7 sh -c
如何查看容器内0号进程对应宿主机的pid号
[root@node1 ~]# docker container ls |grep test1 | awk '{print $1}'
09e4114ddd9d
# 注意,下面查看的是容器内部0号进程,对应宿主机上的pid号
[root@node1 ~]# ps aux |grep containerd-shim |grep 09e4114ddd9d
root 5439 0.0 0.6 712056 12836 ? Sl 12:27 0:00 /usr/bin/containerd-shim-runc-v2 -namespace moby -id 09e4114ddd9d9747244352637949ade8c61082627984b3381d37a589d92c4bc3 -address /run/containerd/containerd.sock
如果你干死了容器的containerd-shim进程,那站在操作系统角度,容器下的所有进程都被操作系统的init收养然后回收了
如何查看容器内1号进程对应物理机的pid号
[root@node1 ~]# docker container ls |grep test1 | awk '{print $1}'
09e4114ddd9d
[root@node1 ~]# docker inspect 09e4114ddd9d |grep -i pid
"Pid": 5458,
"PidMode": "",
"PidsLimit": null,
如何查看容器内其他进程在宿主机中的PID
[root@node1 ~]# docker container ls |grep test1 | awk '{print $1}'
09e4114ddd9d
# 注意,下面查看的是容器内部的进程对应宿主机对应的pid号,具体查看目录可能是system.slice或docker目录
[root@node1 ~]# cat /sys/fs/cgroup/memory/system.slice/docker-09e4114ddd9d9747244352637949ade8c61082627984b3381d37a589d92c4bc3.scope/cgroup.procs
5458
5484
5485
# 也可以执行命令查看
docker top 容器名/或ID
# 上述结果包含了容器内1号进程在宿主机的映射,要确定其他进程号与容器内进程的对应关系,可以在宿主机上用ps aux |grep 号码,来过滤进行确认
=============》宿主机
[root@node1 ~]# ps aux |grep 5458 |grep -v grep
root 5458 0.0 0.0 11688 1336 ? Ss 12:27 0:00 sh -c (sleep 10d &) ; tail -f /dev/null
[root@node1 ~]# ps aux |grep 5484 |grep -v grep
root 5484 0.0 0.0 4364 356 ? S 12:27 0:00 sleep 10d
[root@node1 ~]# ps aux |grep 5485 |grep -v grep
root 5485 0.0 0.0 4400 352 ? S 12:27 0:00 tail -f /dev/null
=============》在容器内,看一眼与上面的对应关系
可以执行docker exec -ti test1 sh进入容器内执行ps -ef来查看与上面的的结果是一一对应的
补充:
由于容器采用了Linux的namespace机制, 对pid进行了隔离. 因此容器内的pid将会从1开始重新编号, 并且不会看到其他容器或宿主机的进程pid。本质上容器就是宿主机上的一个普通的Linux进程, 因此在宿主机中是可以看到容器内进程的pid, 只不过这个pid是在宿主机上显示的, 而非容器内的(因为隔离了)
[root@node1 ~]# docker exec -ti test1 sh
sh-4.2# ps -elf
F S UID PID PPID C PRI NI ADDR SZ WCHAN STIME TTY TIME CMD
4 S root 1 0 0 80 0 - 2922 do_wai 04:27 ? 00:00:00 sh -c (sleep 10d &) ; tail -f /dev/null
0 S root 8 1 0 80 0 - 1091 hrtime 04:27 ? 00:00:00 sleep 10d
0 S root 9 1 0 80 0 - 1100 wait_w 04:27 ? 00:00:00 tail -f /dev/null
4 S root 10 0 0 80 0 - 2956 do_wai 04:35 pts/0 00:00:00 sh
4 R root 16 10 0 80 0 - 12933 - 04:35 pts/0 00:00:00 ps -elf
小结:
-
每启动一个容器都会在宿主机产生一个docker-shim进程,它就是容器内的0号进程,是容器内1号进程的爹。
-
当容器已经running之后,exec进入容器里执行命令产生的新进程,都是0号进程的儿子,而不是1号进程的儿子。所以说容器中的1号进程并不会像宿主机的1号进程那样直接或间接地领导所有其它进程。
-
docker top 显示的容器中的进程可能不太全,与是否该进程归属于1号进程没有任何关系;与进程是否最终归属于该容器的管理进程docker-containerd-shim也没有关系,如果是nsenter进入容器,则启动的进程在docker top中是看不到的,虽然该进程在容器中显示的ppid也是0,其实同样是0的ppid却可能不是同一个进程,因为,只要父进程在容器外部,则容器内部显示的ppid就统一为0; 为什么docker top可能看到的不全?docker top是如何实现的呢?参考:https://phpor.net/blog/post/4420。
# 终端1
docker container run -d --name test centos:7 tail -f /dev/null
docker top test
# 终端2
docker exec -ti test sh # 进入容器后启动几个进程,可以在终端1用top命令看到
# 终端3
# 进入后启动的新进程用top看不到,但是exec进入容器是可以看到的
nsenter -t 容器的pid --mount --uts --ipc --net --pid
容器内的1号进程
完整操作系统的1号进程
以物理机上运行的那个完整的操作系统为例,一个 Linux 操作系统的启动流程:
-
通电后,执行 BIOS
-
找到启动盘
-
bios根据自己的配置,找到启动盘,读取第一个扇区512bytes,即mbr(主引导记录)的内容,这里放的前446是boot-loader程序,后64是分区信息,后2字节是结束的标志位。
-
bootloader 负责把磁盘里的内核读入内存执行
Linux 内核执行文件一般会放在 /boot 目录下,文件名类似 vmlinuz*,如下
[root@yq01-aip-aikefu19 base]# ls /boot/|grep vm vmlinuz-0-rescue-53574fee080a44d49195c9f831019258 vmlinuz-3.10.0-514.el7.x86_64 vmlinuz-4.17.11-1.el7.elrepo.x86_64 -
在内核完成了系统的各种初始化之后,**这个程序需要执行的第一个用户态程就是 init 进程,PID号为1,该进程是系统中所有其他进程的祖宗,**在centos6中该祖宗进程称之为init,在centos7之后该祖宗进程名为systemd。
即:操作系统启动时是先执行内核态代码,然后在内核里调用1号进程的代码,从内核态切换到用户态。
ps:目前linux的好嗯多发行版,如红帽、debian等,都会把/sbin/init作为软连接指向Systemd,Systemd是目前最流行 的linux init进程,在此之前还有SysVinit、UpStart等linux init进程 但无论是哪种 Linux init 进程,它最基本的功能都是创建出 Linux 系统中其他所有的进 程,并且管理这些进程** 在 Linux 上有了容器的概念之后,一旦容器建立了自己的 Pid Namespace(进程命名空 间),这个 Namespace 里的进程号也是从 1 开始标记的。所以,容器的 init 进程也被称 为 1 号进程。 1 号进程是第一个 用户态的进程,由它直接或者间接创建了 Namespace 中的其他进程。
总结操作系统的1号进程拥有如下特点:
- 它是系统的第一个进程,负责产生其他所有用户进程。
- init 以守护进程方式存在,是所有其他进程的祖先。
操作系统的1号进程拥有如下重要功能:
- 启动守护进程
- 收养孤儿
- 会定期发起wait或waitpid的功能去回收成为僵尸的儿子(这不是该进程独有的功能,但它的确有该功能)
- 将操作系统信号转发给子进程
容器内的1号进程
容器内的操作系统来自于镜像,而镜像并非一个完整的操作系统(只拥有rootfs),通常docker的镜像为了节省空间,是没有安装systemd或者sysvint这类初始化系统的进程的,所以当启动容器时,我们CMD执行的命令是啥,容器里的1号进程就是啥。
# 以下dockerfile为例,当docker容器启动时,PID 1即容器启动程序将会是nginx,
FROM nginx
ENTRYPOINT ["nginx", "-c"]
CMD ["/etc/nginx/nginx.conf"]
容器内的1号进程与操作系统的1号进程的相同点与不同点如下:
-
相同之处:只要容器里的1号进程停止,容器就会结束,就好比是操作系统的1号进程挂掉操作系统就挂掉了是一个道理。所以容器里的1号进程应该是一个一直运行不会停止的进程,而且必须在在前台运行,总结一下就是:1号进程需要在前台一直运行。
# 错误示范1:容器的1号进程不是一直运行的 # 1.1 run.sh内容 echo "123" # 1.2 dockerfile内容 FROM centos:7 ADD run.sh /opt CMD sh /opt/run.sh # 1.3 构建镜像 docker build -t test:v1 ./ # 1.4 启动测试 docker container run -d --name test111 test:v1 # 1.5 会发现容器启动之后立刻挂掉 [root@test01 test]# docker container ls -a |grep test111 ...... Exited (0) 33 seconds ago ......# 错误示范2:容器的1号进程放在了后台运行,那么无论它里面是啥代码,也都是一下就运行过去了,然后运行下一行代码,发现没有,容器也就结束了 # 2.1 run.sh 内容 while true;do echo 123 >> /tmp/a.log;sleep 1;done # 2.2 dockerfile内容 FROM centos:7 ADD run.sh /opt CMD sh /opt/run.sh & # 2.3 构建镜像 docker build -t test:v2 ./ # 2.4 启动测试 docker container run -d --name test222 test:v2 # 2.5 会发现容器启动之后立刻挂掉 [root@test01 test]# docker container ls -a |grep test222 ...... Exited (0) 33 seconds ago ......# 正确示范:CMD的代码放到一个文件里然后运行也是一样,只要是在前台然后一直运行就都可以 # 3.1 run.sh 内容 while true;do echo 123 >> /tmp/a.log;sleep 1;done # 3.2 dockerfile内容 FROM centos:7 ADD run.sh /opt CMD sh /opt/run.sh # 3.3 构建镜像 docker build -t test:v3 ./ # 3.4 启动测试 docker container run -d --name test333 test:v3 # 3.5 会发现容器正常启动,可以切入到容器里查看 docker exec -ti test333 sh -
不同之处
使用者为容器启动的1号进程通常不具备操作系统的init进程一样的功能:
- 比如收养孤儿,定期发起wait或waitpid系统调用来回收僵尸儿子
- 再比如信号转发的功能
建议容器设计原则是一个容器只运行一个进程,但在现实工作中往往做不到,还是会生出一些子进程,操作系统的init进程是操作系统的开发者开发的,它有一个非常重要的功能就是:会充当孤儿院的作用去回收孤儿进程,并且会定期发起wait或者waitpid的系统调用去回收僵尸的儿子,但是容器里的1号是用户开发的,一般没有实现上面的功能,所以容器里有僵尸进程而无法被回收也就一点也不奇怪了,那容器里一旦产生僵尸进程该如何应对呢?
僵尸进程与孤儿进程
系统中进程的状态
在linux系统中,无论是进程还是线程,内核都是用task_struct{}结构体来表示的,称之为任务task,task是linux里基本的调度单位,通过ps aux会查看到一系列进程的状态,其实就是task的状态。
进程的状态分为两大类,活着的与死亡的:
一、活着的:
- 1.1 运行着的进程
- (1)、运行态,正占用着CPU资源在运行着,状态为R
- (2)、就绪态,没有申请到CPU资源,处于运行队列中,一旦申请到CPU就可以立即投入运行,状态也为R
- 1.2 睡眠的进程
- (1)、可中断睡眠(TASK_INTERRUPTIBLE),状态为S,等待某个资源而进入的状态,比如等待本地或网络用户输入,也可以等待一个信号量(Semaphore),执行的IO操作可以得到硬件设备的响应
- (2)、不可中断睡眠(TASK_UNINTERRUPTIBLE),状态为D,处于睡眠状态,但是此刻进程是不可中断的,意思是不响应异步信号,执行的IO操作得不到硬件设备的响应(可能是因为硬件繁忙,因此导致内存里的一些缓存数据无法及时刷入磁盘,所以肯定不允许中断该睡眠状态,并且处于D状态的进程kill -9也杀不死,就是为了保证数据安全)
二、死亡的:即执行do_exit()结束进程
- (1)EXIT_DEAD:也就是进程真正结束退出那一瞬间的状态,通常我们看不到,因为很快就没了
- (2)EXIT_ZOMBIE,这个是进程进入EXIT_DEAD状态前的一个状态,该状态称之为僵尸进程,状态显示为Z,也就是说所有进程在死前都会进入僵尸进程的状态。
所有的进程在死前都会进入僵尸进程的状态,它的父进程负责回收该状态,若没有及时回收,就会残留。
僵尸进程
#1、什么是僵尸进程
操作系统负责管理进程
应用程序若想开启子进程,都是在向操作系统发送系统调用
当一个子进程开启起来以后,它的运行与父进程是异步的,彼此互不影响,谁先死都不一定
linux操作系统的设计规定:父进程应该具备随时获取子进程状态的能力
如果子进程先于父进程运行完毕,此时若linux操作系统立刻把该子进程的所有资源全部释放掉,那么父进程来查看子进程状态时,会突然发现自己刚刚生了一个儿子,但是儿子没了!!!
这就违背了linux操作系统的设计规定
所以,linux系统出于好心,若子进程先于父进程运行完毕/死掉,那么linux系统在清理子进程的时候,会将子进程占用的重型资源都释放掉(比如占用的内存空间、cpu资源、打开的文件等),但是会保留一部分子进程的关键状态信息,比如进程号the process ID,退出状态the termination status of the process,运行时间the amount of CPU time taken by the process等,此时子进程就相当于死了但是没死干净,因而得名"僵尸进程",其实僵尸进程是linux操作系统,为父进程准备的一些子进程的状态数据,专门供父进程查阅,也就是说"僵尸进程"是linux系统的一种数据结构,所有的子进程结束后都会进入僵尸进程的状态
# 2、那么问题来了,僵尸进程残存的那些数据不需要回收吗???
当然需要回收了,但是僵尸进程毕竟是linux系统为父进程准备的数据,至于回收操作,应该是父进程觉得自己无需查看僵尸进程的数据了,父进程觉得留着僵尸进程的数据也没啥用了,然后由父进程发起一个系统调用wait / waitpid来通知linux操作系统说:可以回收掉了。然后操作系统再清理掉僵尸进程的残余状态。
# 3、分三种情况讨论
1、linux系统自带的一些优秀的开源软件,这些软件在开启子进程时,父进程内部都会及时调用wait/waitpid来通知操作系统回收僵尸进程,所以,通常看不到优秀的开源软件堆积僵尸进程,因为很及时就回收了,与linux系统配合的很默契。
2、一些水平良好的程序员开发的应用程序,这些程序员技术功底深厚,知道父进程要对子进程负责,会在父进程内考虑调用wait/waitpid来通知操作系统回收僵尸进程,但是发起系统调用wait/waitpid的时间可能慢了些,于是可以在linux系统中通过命令查看到僵尸进程状态
[root@egon ~]# ps aux | grep [Z]+
3、一些垃圾程序员,技术非常垃圾,只知道开子进程,父进程也不结束,就在那傻不拉几地一直开子进程,也压根不知道啥叫僵尸进程,至于wait/waitpid的系统调用更是没听说过,这个时候,就真的垃圾了,操作系统中会堆积很多僵尸进程,此时我们的计算机会进入一个奇怪的现象,就是内存充足、硬盘充足、cpu空闲,但是,启动新的软件就是无法启动起来,为啥,因为操作系统负责管理进程,每启动一个进程就会分配一个pid号,而pid号是有限的,正常情况下pid也用不完,但怕就怕堆积一堆僵尸进程,他吃不了多少内存,但能吃一堆pid。
# 4、如何清理僵尸进程
针对情况3,只有一种解决方案,就是杀死父进程,那么僵尸的子进程会被linux系统中pid为1的顶级进程(init或systemd)接管,顶级进程很靠谱、它是一定会定期发起系统调用wait/waitpid来通知操作系统清理僵尸儿子的
针对情况2,可以发送信号给父进程,通知它快点发起系统调用wait/waitpid来清理僵尸的儿子
kill -CHLD 父进程PID
# 5、结语
僵尸进程是linux系统出于好心设计的一种数据结构,一个子进程死掉后,相当于操作系统出于好心帮它的爸爸保存它的遗体,之说以会在某种场景下有害,是因为它的爸爸不靠谱,儿子死了,也不及时收尸(发起系统调用让操作系统收尸)
说白了,僵尸进程本身无害,有害的是那些水平不足的程序员,他们总是喜欢写bug,好吧,如果你想看看垃圾程序员是如何写bug来堆积僵尸进程的,可以看一下这篇博客https://www.cnblogs.com/linhaifeng/articles/13567273.html
父进程发起的wait或waitpid调用只能回收僵尸儿子,无法回收孙子辈,只能是儿子,只能是儿子,只能是儿子。
僵尸进程示例代码
#coding:utf-8
from multiprocessing import Process
import os
import time
def task(n):
print("father--->%s son--->%s" %(os.getppid(),os.getpid()))
time.sleep(n)
if __name__ == "__main__":
# 首选必须知道一个知识点:一个python进程,就是一个python解释器进程,python代码本质都是字符串最终运行与调用的
# 其实都是解释器的代码
# 对于开启的子进程,即便不去执行p.join()方法,也不用担心,因为只要python解释器还在运行着,它就会定期定期定期,
# 注意是定期,去执行
# 回收僵尸进程的功能,
# 当如果你没有执行p.join(),同时也time.sleep(100000)住了主进程,那肯定就没有人来回收僵尸儿子了
# 所以,如果你开启了一千个子进程,每个子进程都是运行一行打印功能然后在极短的时间内进入僵尸进程状态
# 主进程在一个个开启这一千个子进程的过程中就会定期回收一部分僵尸儿子,当运行到最后执行到time.sleep(100000)时,主进程就停住了
# 剩下的没来得及回收的僵尸儿子也就残留了
for i in range(1000):
Process(target=task,args=(0,)).start()
time.sleep(100000)
=====================窗口2中:大概过个十几秒后查看======================
[root@egon ~]# ps aux |grep Z
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 104482 0.0 0.0 0 0 pts/2 Z 18:24 0:00 [python] <defunct>
root 104483 0.0 0.0 0 0 pts/2 Z 18:24 0:00 [python] <defunct>
root 104484 0.0 0.0 0 0 pts/2 Z 18:24 0:00 [python] <defunct>
root 104488 0.0 0.0 112828 960 pts/4 R+ 18:24 0:00 grep --color=auto Z
=====================如下,我们可以看到僵尸对应的资源都已经没有了======================
# cat /proc/104482/cmdline
# cat /proc/104482/smaps
# cat /proc/104482/maps
# ls -l /proc/104482/fd
任何进程的退出都是调用do_exit()系统接口,do_exit()内部会释放进程task_struct里的mm/shm/sem/files等文件资源,只留下一个stask_struct instance空壳,如上所示
并且,这个进程也已经不响应任何的信号了,无论 SIGTERM(15) 还是 SIGKILL(9)
kill -9 104482
kill -15 104482
ps aux |grep Z # 会发现104482这个僵尸进程依然存在
# 补充
可以去查看p1.join()的代码,里面有一个关于wait的调用,在主进程里调用p1.join()的目的就是等子进程挂掉后
而回收它的尸体,所以python代码多进程编程,在主进程里建议在主进程里一个个join主子进程。
而上例中,主进程在进入sleep前,我们并没有调用join方法,于是僵尸进程就产生了,因为主进程一直停在原地,并没有发起wait系统调用的机会
孤儿进程
孤儿进程指的是一个进程的父进程死掉了,它就成了孤儿,孤儿会被1号进程收养,而不是被它爷爷进程、或者太爷爷进程收养,这一点很关键
父进程先死掉,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被进程号为1的顶级进程(init或systemd)所收养,并由顶级进程对它们完成状态收集工作。
此处需要强调一句:不管子进程时什么状态,哪怕它是僵尸状态也一样,只要它的父进程挂掉了,它就会被1号进程收养。
import os
import sys
import time
pid = os.getpid()
ppid = os.getppid()
print 'im father', 'pid', pid, 'ppid', ppid
pid = os.fork()
#执行pid=os.fork()则会生成一个子进程
#返回值pid有两种值:
# 如果返回的pid值为0,表示在子进程当中
# 如果返回的pid值>0,表示在父进程当中
if pid > 0:
print 'father died..'
sys.exit(0)
# 保证主线程退出完毕
time.sleep(1)
print 'im child', os.getpid(), os.getppid()
执行文件,输出结果:
im father pid 32515 ppid 32015
father died..
im child 32516 1
子进程已经被pid为1的顶级进程接收了,所以僵尸进程在这种情况下是不存在的,存在只有孤儿进程而已,孤儿进程声明周期结束自然会被顶级进程来销毁。
小结:
一个完整操作系统自带的init进程是会定期发起wait或waitpid系统调用来回收僵尸儿子的,这里需要强调的是:
-
wait或waitpid只能回收儿子,只能是儿子、只能是儿子,只能是儿子,孙子及孙子。。都不行。
-
当kill -9无法杀掉僵尸进程。
-
当杀掉一个进程时(假设它以被kill -9杀掉,僵尸进程时不能被kill -9的):
-
如果它的父进程存在并且没有发起wait或waitpid那么该进程就会停留在僵尸进程的状态,此时我们杀死该父进程,那么该父进程的僵尸儿子就会被pid为1的进程收养,pid为1的进程会负责回收。
-
如果它的父进程会发起wait或waitpid那么该进程就会被回收,你就看不到什么僵尸进程的状态。
-
容器内的僵尸进程
容器内残留僵尸进程的原因
操作系统内有1号进程,容器内也有一个1号进程
区别是操作系统内的1号进程里的代码是别人开发的,开发者为其加入了两个个重要的功能:
- 当进程称为孤儿进程后,1号进程会收养该孤儿、称为他的爹。
- 定义发起wait或waitpid的系统调用去1号进程的僵尸儿子。
而容器里的1号进程的代码是你开发的(执行的启动命令就是1号进程),你并没有考虑发起wait与waitpid这个系统调用的操作。
于是,在容器运行一段时间后,如果有子进程先挂掉了,它爹又没有负责回收,那么僵尸进程的状态就残留了下来,pid资源就被白白占住了,那如果我关掉容器,或者删掉k8s里的pod,容器里的僵尸进程还会残留吗,答案是肯定不会残留:
在容器平台上,无论是用k8s去删除一个pod,或者用docker关闭一个容器,都会用到Containerd这个服务
1、创建容器时:kubelet调用`dockerDaemon`发起创建容器请求,然后由`containerd`接收并创建`containerd-shim`,`containerd-shim`即容器内的0号进程。所以实际的创建容器、容器内执行指令等都是此进程在做
2、同时,`containerd-shim`具有回收僵尸进程的功能,容器1号进程退出后,内核清理其下子孙进程,这些子孙进程被`containerd-shim`收养并清理。 注意:如果1号进程不被Kill,那么其下进程如果有僵尸进程,是无法被处理的。所以用户开发的容器首进程要注意回收退出进程。
ps: 在所有容器都清理后,k8s中的pod也就被删除了。
所以说,你要知道的是,即便容器内的1号进程没有回收僵尸儿子的能力,0号进程是为其兜底的。
而接下来要讨论的不是容器内1号进程挂掉的情况,而是要讨论在1号进程活着的情况下,它若没有回收僵尸进程的能力容器内会产生何种现象,应该如何处理。
用python解释器作为1号进程来测试(强调,python解释器与bash解释一样都具备定期回收僵尸儿子的功能,但是用sleep将python父进程停住,它不动弹了也就不会发起回收了,也就能看到僵尸儿子了)
# 1、创建工作目录
mkdir /test
cd /test
# 2、创建脚本文件run1.sh
cat >> test.py << EOF
#coding:utf-8
from multiprocessing import Process
import os
import time
def task1(n):
print("儿子,PID:%s PPID:%s" %(os.getpid(),os.getppid()))
pp1=Process(target=task2,args=(10,))
pp2=Process(target=task2,args=(10,))
pp3=Process(target=task2,args=(10,))
pp1.start()
pp2.start()
pp3.start()
time.sleep(n)
def task2(n):
print("孙子,PID:%s PPID:%s" %(os.getpid(),os.getppid()))
time.sleep(n)
if __name__ == "__main__":
p=Process(target=task1,args=(10000,))
p.start()
print("爸爸,PID: %s" %os.getpid())
time.sleep(10000)
EOF
# 3、创建dockerfile
cat > dockerfile << EOF
FROM centos:7
ADD test.py /opt
CMD python /opt/test.py
EOF
# 4、构建镜像并运行
docker build -t test_defunct:v1 ./
docker run -d --name test1 test_defunct:v1
# 5、进入容器会发现有僵尸进程产生: 因为1号进程一直sleep在原地,根本没有机会去回收僵尸的儿子,如此,效果就模拟出来了
[root@test01 test]# docker exec -ti test1 sh
sh-4.2# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 07:50 ? 00:00:00 python /opt/test.py
root 7 1 0 07:50 ? 00:00:00 python /opt/test.py
root 8 7 0 07:50 ? 00:00:00 [python] <defunct>
root 9 7 0 07:50 ? 00:00:00 [python] <defunct>
root 10 7 0 07:50 ? 00:00:00 [python] <defunct>
root 11 0 0 07:50 pts/0 00:00:00 sh
root 18 11 0 07:51 pts/0 00:00:00 ps -ef
此时你是无法杀死那三个僵尸的,那我们杀死他们的爹,即pid为7的进程
sh-4.2# kill -9 7
sh-4.2# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 07:50 ? 00:00:00 python /opt/test.py
root 7 1 0 07:50 ? 00:00:00 [python] <defunct>
root 8 1 0 07:50 ? 00:00:00 [python] <defunct>
root 9 1 0 07:50 ? 00:00:00 [python] <defunct>
root 10 1 0 07:50 ? 00:00:00 [python] <defunct>
root 11 0 0 07:50 pts/0 00:00:00 sh
root 19 11 0 07:52 pts/0 00:00:00 ps -ef
此时你会发现两个非常有趣的现象
1、又多一个僵尸进程
2、pid为7、8、9、10的进程的ppid都变成了1,也就是说他们都被1号进程收养了
很简单,当我们杀死pid为7的进程的时候,它爹也就是1号进程在原地sleep呢,并不会回收它,所以它停留在僵尸状态
而pid为7的进程一旦撕掉,它的三个僵尸儿子们就成了孤儿,自然会被pid为1的进程收养,再说一句,这里的pid为1的进程被sleep住了,肯定
不会 回收他们,于是它们三也残留着,这就是你看到的4个僵尸进程
最后,不能再杀了,而且你kill -9 1也是无效的,1号进程是无法被强制杀死的
CPU Cgroup的使用
CPU CGROUP介绍
Cgroup是用于限制进程对资源使用的一种机制,而Cpu Cgroup是Cgroup机制的一种,即cpu cgroup是cgroups的一个子系统,具体用来限制进程对cpu资源的使用的。
k8s里pod的request与limit底层其实就是在配置cpu cgroup。
进程管理
进程介绍
- 程序:存放代码的文件=》静态
- 进程:程序的运行过程=》动态
同一个程序可能对应多个进程
父进程:程序运行时产生的第一个进程
子进程:由父进程衍生fork()出来的进程
注意:如果父进程终止,子进程也会随之被终止
[root@localhost yum.repos.d]# yum install nginx -y
[root@localhost yum.repos.d]#
[root@localhost yum.repos.d]# systemctl start nginx
[root@localhost yum.repos.d]# ps aux |grep nginx
root 27482 0.0 0.1 120896 2096 ? Ss 16:50 0:00 nginx: master process /usr/sbin/nginx
nginx 27483 0.0 0.1 123364 3544 ? S 16:50 0:00 nginx: worker process
root 27500 0.0 0.0 112724 988 pts/0 S+ 16:50 0:00 grep --color=auto nginx
进程-进程之进程状态(R、S、D、T、Z、X)
#1、进程概念:
1)正在执行的程序
2)正在计算机上执行的程序实例
3)能分配处理器并由处理器执行的实体
进程的两个基本元素是程序代码和代码相关联的数据集。进程是一种动态描述,但并不代表所有的进程都在运行。这就可以引入‘进程状态’。
进程在内存中因策会略或调度需求,
会处于各种状态:
#2、Linux下的进程状态:
static const char * const task_state_array[] = {
"R (running)", /* 0 */
"S (sleeping)", /* 1 */
"D (disk sleep)", /* 2 */
"T (stopped)", /* 4 */
"t (tracing stop)", /* 8 */
"X (dead)", /* 16 */
"Z (zombie)", /* 32 */
};
# R- -可执行状态(运行状态)
只有在运行状态的进程才有可能在CPU上运行,注意是可能,并不意味着进程一定在运行中。同一时刻可能有多个进程处在可执行状态,这些进程的PCB(进程控制块)被放入对应CPU的可执行队列中。然后进程调度器从各个可执行队列中分别选择一个进程在CPU上运行。
另外如果计算机只有一个处理器,那么一次最多只有一个进程处于这种状态。
linux的两种睡眠状态S与D是一个重点知识,此处先赞做了解,后续我们将详细介绍
# S- -可中断睡眠状态(sleeping)
进程等待某个资源处于sleep状态,此时可以通过发送信号将这个进程唤醒。例如发送kill 信号。
# D- -不可中断睡眠(disk sleep)
进程在内核中某些不能被信号打断,例如对某些硬件设备进行操作时刻(等待磁盘Io,等待网络io等等)。进程处于D状态一般情况下很短暂,不应该被top或者ps看到。如果进程在top和ps看到长期处于D状态,那么可能进程在等待IO时出现了问题导致进程一直等待不到IO资源 此时如果要处理掉这个D进程,那么只能重启整个系统才会恢复。因为此时整个进程无法被kill 掉。
# T- -暂停状态
给进程发送一个SIGSTOP信号,进程就会响应信号进入T状态,除非该进程正处在D状态。
再通过发送SIGCONT信号让进程继续运行。
kill -SIGSTOP
kill -SIGCONT
# Z- -僵死状态
僵死状态是一个比较特殊的状态。进程在退出的过程中,处于TASK_DEAD状态。
在这个退出过程中,进程占有的所有资源将被回收,除了task_struct结构(以及少数资源)以外。于是进程就只剩下task_struct这么个空壳,故称为僵尸。
X- -死亡状态或退出状态(dead)
死亡状态是内核运⾏ kernel/exit.c ⾥的 do_exit() 函数返回的状态。这个状态只是⼀个返回状态,你不会在任务列表⾥看到这个状态
进程状态切换
进程在运行中不断的改变运行状态;
1)就绪状态
当进程已分配到除CPU以外的所有必要的资源,只要获得处理机便可立即执行,这时的进程状态称为就绪状态。
2)执行(Running)状态
当进程已获得处理机,其程序正在处理机上执行,此时的进程状态称为执行状态
3) 阻塞(Blocked)状态
正在执行的进程,由于等待某个事件发生而无法执行时,便放弃处理机而处于阻塞状态。引起进程阻塞的事件可有多种,例如,等待I/O完成、申请缓冲区不能满足、等待信件(信号)等。
就绪–>执行
处在就绪状态的进程,当调度器为其分配了处理机后,就变成了执行状态。
执行–>就绪
执行状态的进程在其执行过程中,时间片跑完了不得不让出处理机,于是从执行变成就绪状态。
执行–>阻塞
正在执行的进程等待某种事件而无法继续执行时,便从执行状态变成阻塞状态。
阻塞–>就绪
处在阻塞状态的进程,如果等待的时间发生,则从阻塞状态转变成就绪状态。
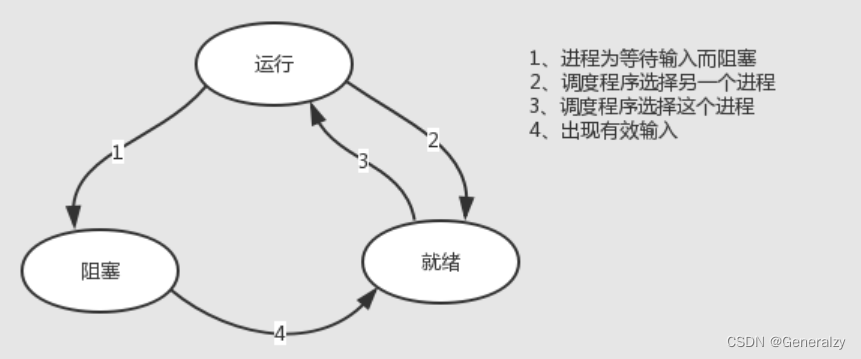
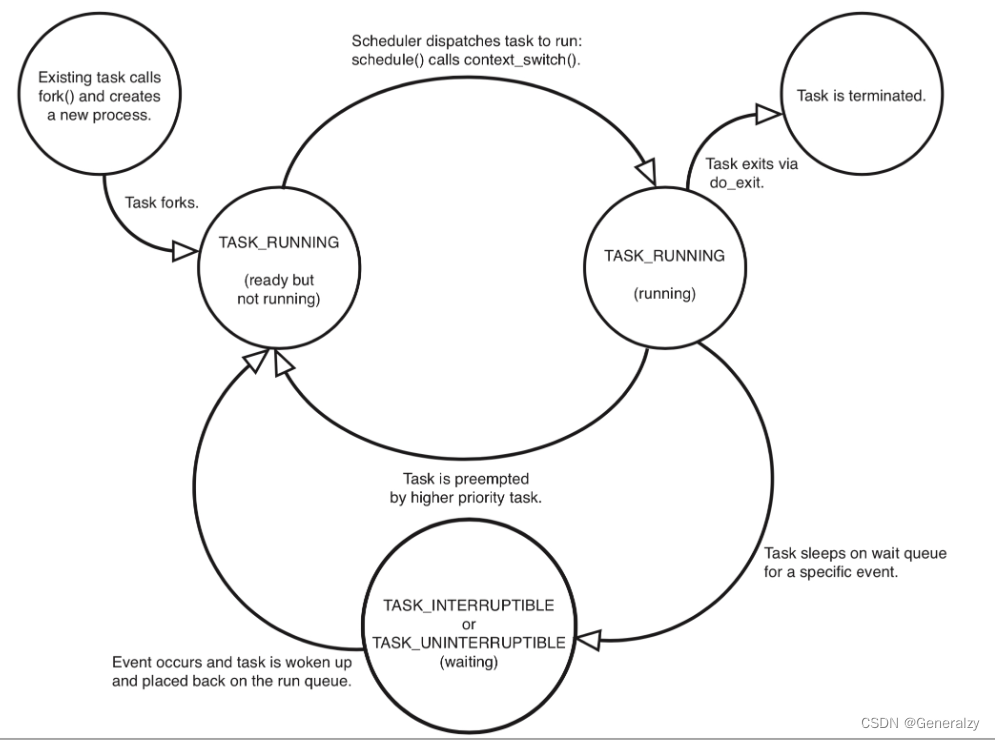
进程活着的状态就两种
1、运行着(运行+就绪,统称TASK_RUNNING)
2、睡眠着(TASK_INTERRUPTIBLE,TASK_UNINTERRUPTIBLE)
1、运行着的进程分为两种:一种是真的拿到cpu资源真的在运行,另外一种就是在运行队列里、随时可以运行,处于R状态的进程泛指这两种情况
2、睡眠着是指,进程需要等待某种资源而进入的状态,要等的资源可以是一个信号量Semaphore), 或者是磁盘 I/O,这个状态的进程会被放入到 wait queue 队列里。睡眠着的进程具体还包括两个子状态:一个是可以被打断的(TASK_INTERRUPTIBLE),用 ps 查看到的进程,显示为 S stat。还有一个是不可被打断的(TASK_UNINTERRUPTIBLE),用 ps 查看进程,就显示为 D stat。
3、除了上面进程在活的时候的两个状态,进程在调用 do_exit() 退出的时候,还有两个状态
(1)一个是 :EXIT_DEAD,也就是进程在真正结束退出的那一瞬间的状态;
(2)另外一个是:EXIT_ZOMBIE 状态,这是进程在 EXIT_DEAD 前的一个状态,即僵尸进程
查看进程
ps aux查看
ps aux是常用组合,查看进程用户、PID、占用CPU百分比、占用内存百分比、状态、执行的命令等。
-a #显示一个终端的所有进程
-u #选择有效的用户id或者是用户名
-x #显示没有控制终端的进程,同时显示各个命令的具体路径。
[root@localhost ~]# ps aux |head -5
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.3 128400 7104 ? Ss 8月12 0:05 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
root 2 0.0 0.0 0 0 ? S 8月12 0:00 [kthreadd]
root 4 0.0 0.0 0 0 ? S< 8月12 0:00 [kworker/0:0H]
root 5 0.0 0.0 0 0 ? S 8月12 0:01 [kworker/u256:0]
结果
USER: 运行进程的用户
PID: 进程ID
%CPU: CPU占用率
%MEM: 内存占用率
VSZ: 占用虚拟内存,单位:kb(killobytes)
VSZ是指已分配的线性空间大小,这个大小通常并不等于程序实际用到的内存大小,产生这个的可能性很多
比如内存映射,共享的动态库,或者向系统申请了更多的堆,都会扩展线性空间大小。
RSS: 占用实际内存,单位:kb(killobytes)
RSZ是Resident Set Size,常驻内存大小,即进程实际占用的物理内存大小
TTY: 进程运行的终端
STAT: 进程状态 man ps (/STATE)
R 运行
S 可中断睡眠 Sleep,即在睡眠的过程中可以接收信号唤醒=》执行的IO操作可以得到硬件设备的响应
D 不可中断睡眠,即在睡眠的过程中不可以接收信号唤醒=》执行的IO操作得不到硬件设备的响应
T 停止的进程
Z 僵尸进程
X 死掉的进程(几乎看不见,因为死了就立即回收了)
< 标注了<小于号代表优先级较高的进程
N N代表优先级较低的进程
s 包含子进程
+ +表示是前台的进程组
l 小写字母l,代表以线程的方式运行,即多线程
| 管道符号代表多进程
START: 进程的启动时间
TIME: 进程占用CPU的总时间
COMMAND: 进程文件,进程名
带[]号的代表内核态进程
不带[]号的代表用户态进程
Linux进程有两种睡眠状态
# 1、S (TASK_INTERRUPTIBLE)(可中断睡眠,在ps命令中显示“S”)
处于这个状态的进程因为等待某某事件的发生(比如等待socket连接、等待信号量),而被挂起。这些进程的task_struct结构被放入对应事件的等待队列中。当这些事件发生时(由外部中断触发、或由其他进程触发),对应的等待队列中的一个或多个进程将被唤醒。
例如:处在这种睡眠状态的进程是可以通过给它发送signal来唤醒的,比如发HUP信号给nginx的master进程可以让nginx重新加载配置文件而不需要重新启动nginx进程;
通过ps命令我们会看到,一般情况下,进程列表中的绝大多数进程都处于TASK_INTERRUPTIBLE状态(除非机器的负载很高)。毕竟CPU就这么一两个,进程动辄几十上百个,如果不是绝大多数进程都在睡眠,CPU又怎么响应得过来。
# 2、D (TASK_UNINTERRUPTIBLE)(不可中断睡眠,在ps命令中显示“D”)
与TASK_INTERRUPTIBLE状态类似,进程处于睡眠状态,但是此刻进程是不可中断的。不可中断,指的并不是CPU不响应外部硬件的中断,而是指进程不响应异步信号。
绝大多数情况下,进程处在睡眠状态时,总是应该能够响应异步信号的。否则你将惊奇的发现,kill -9竟然杀不死一个正在睡眠的进程了!于是我们也很好理解,为什么ps命令看到的进程几乎不会出现TASK_UNINTERRUPTIBLE状态,而总是TASK_INTERRUPTIBLE状态。
而TASK_UNINTERRUPTIBLE状态存在的意义就在于,内核的某些处理流程是不能被打断的。如果响应异步信号,程序的执行流程中就会被插入一段用于处理异步信号的流程(这个插入的流程可能只存在于内核态,也可能延伸到用户态),于是原有的流程就被中断了。
在进程对某些硬件进行操作时(比如进程调用read系统调用对某个设备文件进行读操作,而read系统调用最终执行到对应设备驱动的代码,并与对应的物理设备进行交互),可能需要使用TASK_UNINTERRUPTIBLE状态对进程进行保护,以避免进程与设备交互的过程被打断,造成设备陷入不可控的状态。这种情况下的TASK_UNINTERRUPTIBLE状态总是非常短暂的,通过ps命令基本上不可能捕捉到。
不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的I/O响应,也就是我们在ps命令中看到的D状态(Uninterruptible Sleep,也称为Disk Sleep)的进程。
比如,当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的,这个时候的进程就处于不可中断状态。如果此时的进程被打断了,就容易出现磁盘数据与进程数据不一致的问题。
!!!!!!!!!!!!!!!!!!!!所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制!!!!!!!!!!。
!!!!!!!!!!!!!!!!!!!!所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制!!!!!!!!!!
linux系统中也存在容易捕捉的TASK_UNINTERRUPTIBLE状态。执行vfork系统调用后,父进程将进TASK_UNINTERRUPTIBLE状态,直到子进程调用exit或exec 通过下面的代码就能得到处于TASK_UNINTERRUPTIBLE状态的进程:
[root@localhost ~]# cat test.c
void main() {
if (!vfork()) sleep(100);
}
[root@localhost ~]# gcc -o test test.c
[root@localhost ~]# ./test
[root@localhost ~]# ps -aux | grep test
root 19454 0.0 0.0 4212 352 pts/6 D+ 10:02 0:00 ./test
root 19455 0.0 0.0 4212 352 pts/6 S+ 10:02 0:00 ./test
# 进程为什么会被置于uninterruptible sleep状态呢?
进程为什么会被置于D状态呢?处于uninterruptible sleep状态的进程通常是在等待IO,比如磁盘IO,网络IO,其他外设IO,如果进程正在等待的IO在较长的时间内都没有响应,那么就很会不幸地被ps看到了,同时也就意味着很有可能有IO出了问题,可能是外设本身出了故障,也可能是比如NFS挂载的远程文件系统已经不可访问了。
正是因为得不到IO的响应,进程才进入了uninterruptible sleep状态,所以要想使进程从uninterruptible sleep状态恢复,就得使进程等待的IO恢复,比如如果是因为从远程挂载的NFS卷不可访问导致进程进入uninterruptible sleep状态的,那么可以通过恢复该NFS卷的连接来使进程的IO请求得到满足。
# 强调
D与Z状态的进程都无法用kill -9杀死
# D状态,往往是由于 I/O 资源得不到满足,而引发等待
在内核源码 fs/proc/array.c 里,其文字定义为“ "D (disk sleep)", /* 2 */ ”(由此可知 D 原是Disk的打头字母),对应着 include/linux/sched.h 里的“ #define TASK_UNINTERRUPTIBLE 2 ”。举个例子,当 NFS 服务端关闭之时,若未事先 umount 相关目录,在 NFS 客户端执行 df 就会挂住整个登录会话,按 Ctrl+C 、Ctrl+Z 都无济于事。断开连接再登录,执行 ps axf 则看到刚才的 df 进程状态位已变成了 D ,kill -9 无法杀灭。正确的处理方式,是马上恢复 NFS 服务端,再度提供服务,刚才挂起的 df 进程发现了其苦苦等待的资源,便完成任务,自动消亡。若 NFS 服务端无法恢复服务,在 reboot 之前也应将 /etc/mtab 里的相关 NFS mount 项删除,以免 reboot 过程例行调用 netfs stop 时再次发生等待资源,导致系统重启过程挂起。
Nginx举例一则,只是举个例子大概看看就行
第二客户端机器我们将运行另一个副本的wrk,但是这个脚本我们使用50的并发连接来请求相同的文件。因为这个文件被经常访问的,它将保持在内存中。在正常情况下,NGINX很快的处理这些请求,但是工作线程如果被其他的请求阻塞性能将会下降。所以我们暂且叫它“加载恒定负载”。
性能将由服务器上ifstat监测的吞吐率(throughput)和从第二台客户端获取的wrk结果来度量。
现在,没有线程池的第一次运行不会给我们带来非常令人兴奋的结果
top - 10:40:47 up 11 days, 1:32, 1 user, load average: 49.61, 45.77 62.89
Tasks: 375 total, 2 running, 373 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.3 sy, 0.0 ni, 67.7 id, 31.9 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem: 49453440 total, 49149308 used, 304132 free, 98780 buffers
KiB Swap: 10474236 total, 20124 used, 10454112 free, 46903412 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
4639 vbart 20 0 47180 28152 496 D 0.7 0.1 0:00.17 nginx
4632 vbart 20 0 47180 28196 536 D 0.3 0.1 0:00.11 nginx
4633 vbart 20 0 47180 28324 540 D 0.3 0.1 0:00.11 nginx
4635 vbart 20 0 47180 28136 480 D 0.3 0.1 0:00.12 nginx
4636 vbart 20 0 47180 28208 536 D 0.3 0.1 0:00.14 nginx
4637 vbart 20 0 47180 28208 536 D 0.3 0.1 0:00.10 nginx
4638 vbart 20 0 47180 28204 536 D 0.3 0.1 0:00.12 nginx
4640 vbart 20 0 47180 28324 540 D 0.3 0.1 0:00.13 nginx
4641 vbart 20 0 47180 28324 540 D 0.3 0.1 0:00.13 nginx
4642 vbart 20 0 47180 28208 536 D 0.3 0.1 0:00.11 nginx
4643 vbart 20 0 47180 28276 536 D 0.3 0.1 0:00.29 nginx
4644 vbart 20 0 47180 28204 536 D 0.3 0.1 0:00.11 nginx
4645 vbart 20 0 47180 28204 536 D 0.3 0.1 0:00.17 nginx
4646 vbart 20 0 47180 28204 536 D 0.3 0.1 0:00.12 nginx
4647 vbart 20 0 47180 28208 532 D 0.3 0.1 0:00.17 nginx
4631 vbart 20 0 47180 756 252 S 0.0 0.1 0:00.00 nginx
4634 vbart 20 0 47180 28208 536 D 0.0 0.1 0:00.11 nginx<
4648 vbart 20 0 25232 1956 1160 R 0.0 0.0 0:00.08 top
25921 vbart 20 0 121956 2232 1056 S 0.0 0.0 0:01.97 sshd
25923 vbart 20 0 40304 4160 2208 S 0.0 0.0 0:00.53 zsh
在这种情况下,吞吐率受限于磁盘子系统,而CPU在大部分时间里是空转状态的。从wrk获得的结果来看也非常低:
Running 1m test @ http://192.0.2.1:8000/1/1/1
12 threads and 50 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 7.42s 5.31s 24.41s 74.73%
Req/Sec 0.15 0.36 1.00 84.62%
488 requests in 1.01m, 2.01GB read
Requests/sec: 8.08
Transfer/sec: 34.07MB
请记住,文件是从内存送达的!第一个客户端的200个连接创建的随机负载,使服务器端的全部的工作进程忙于从磁盘读取文件,因此产生了过大的延迟,并且无法在合适的时间内处理我们的请求。
top命令查看
top命令动态查看进程:
(1) 基本用法
[root@localhost ~]# top
[root@localhost ~]# top -d 1 # 1秒刷新一次
[root@localhost ~]# top -d 1 -p 进程的pid
[root@localhost ~]# top -d 1 -p `pgrep nginx | head -1`
[root@localhost ~]# top -d 1 -p `pgrep sshd | head -1`,33 # 查看sshd以及pid为33的进程
[root@localhost ~]# top -d 1 -u nginx # 查看指定用户进程
[root@localhost ~]# top -b -n 2 > top.txt # 将2次top信息写入到文件
(2) 显示信息解释
第一部分:系统整体统计信息
up左边的代表当前的时间
up右边代表运行了多长时间
load average: 0.86, 0.56, 0.78 CPU 1分钟,5分钟,15分钟平均负载
平均负载解释如下:
'''
===========>什么是平均负载?
平均负载是指,单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数
===========>平均负载多少合理?
假设现在在4,2,1核的CPU上,如果平均负载为2时,意味着什么呢?
------------------------------------------------
核心数 平均负载 含义
4 2 有一半(50%)的CPU是空闲状态
2 2 CPU刚好完全被占用
1 2 至少一半的进程是抢不到CPU
-------------------------------------------------
===========>平均负载的三个数值我们该关注哪一个?
三个值相当于三个样本,我们应该统筹地看
1、如果1分钟,5分钟,15分钟的负载数值相差不大,代表系统的负载很'稳定'
2、如果1分钟的值,远小于15分钟的值,那么证明系统的平均负载逐渐降低,即我们的系统刚刚经历过大风浪,但目前已逐渐趋于平均。至于15分钟区间内,系统负载上升的原因,还需要我们认真查明
3、如果15分钟的值,远小于1分钟的值,那么证明系统的平均负载逐渐升高,有可能是临时的也有可能持续上升,需要观察
4、一旦1分钟的平均负载接近或超过了CPU的个数,就意味着,系统正在发生过载的问题,这时候就得分析问题了, 并且要想办法优化。
==========>平均负载实验:4个CPU跑满
[root@egon ~]# cat /proc/cpuinfo | grep processor
processor : 0
processor : 1
processor : 2
processor : 3
打开窗口1:执行top命令,然后按1,观察四个核的id几乎为100%,然后在窗口2执行命令观察负载情况
[root@egon ~]# top
[root@egon ~]# 按1
打开窗口2:依次执行下述命令,然后在窗口来观察变化
[root@egon ~]# while true;do ((1+1));done &
[root@egon ~]# while true;do ((1+1));done &
[root@egon ~]# while true;do ((1+1));done &
[root@egon ~]# while true;do ((1+1));done &
用ps aux | grep bash会看到一系列R的bash进程,然后一个个杀掉,观察cpu的负载逐步恢复平静
思考:如果把测试命令换成下述命令,一直连续执行n次,cpu负载都不会很高,为什么??
[root@egon ~]# while true;do ((1+1));sleep 0.1;done &
[root@egon ~]# while true;do ((1+1));sleep 0.1;done &
[root@egon ~]# while true;do ((1+1));sleep 0.1;done &
。。。执行好多次
补充1:也可以使用stress工具来取代上述的while命令
stress是Linux系统压力测试工具,可用作异常进程模拟平均负载升高的场景,需要安装yum install stress -y
[root@egon ~]# stress --cpu 4 --timeout 3000 # 3000代表持续执行3000秒
补充2:安装yum install sysstat -y会得到下述两个命令
mpstat 是多核CPU性能分析工具,用来实时检查每个CPU的性能指标,以及所有CPU的平均指标。
[root@egon ~]# mpstat -P ALL 3 # 3s输出一组所有指标
pidstat 是一个常用的进程性能分析工具,用来实时查看进程的CPU,内存,IO,以及上下文切换等性能指标。
[root@egon ~]# pidstat -u 1 5 # 1秒一次,总共输出5次
'''
(3)第三行显示信息解释:
us User,用户态进程占用cpu时间的百分比,不包括低优先级进程的用户态时间(nice值1-19)
sys System,内核态进程占用cpu时间的百分比
ni Nice,nice值1-19的进程用户态占cpu时间的百分比
id Idle,系统空闲cpu的百分比
wa Iowait,系统等待I/O的cpu时间占比,该时间不计入进程的CPU时间
hi Hardware irq,处理硬件中断所占用CPU的时间,该时间同样不计入进程的CPU时间
si Softtirq,处理软件中断的时间,该时间不计入进程的CPU时间
st Steal,表示同一宿主机上的其他虚拟机抢走的CPU时间
linux中断:https://www.cnblogs.com/linhaifeng/articles/13916102.html
下图中箭头Timeline代表一条时间轴,以此为分割,上半部分代表Linux用户态(User space),下半部分代表内核态(Kernel space)。
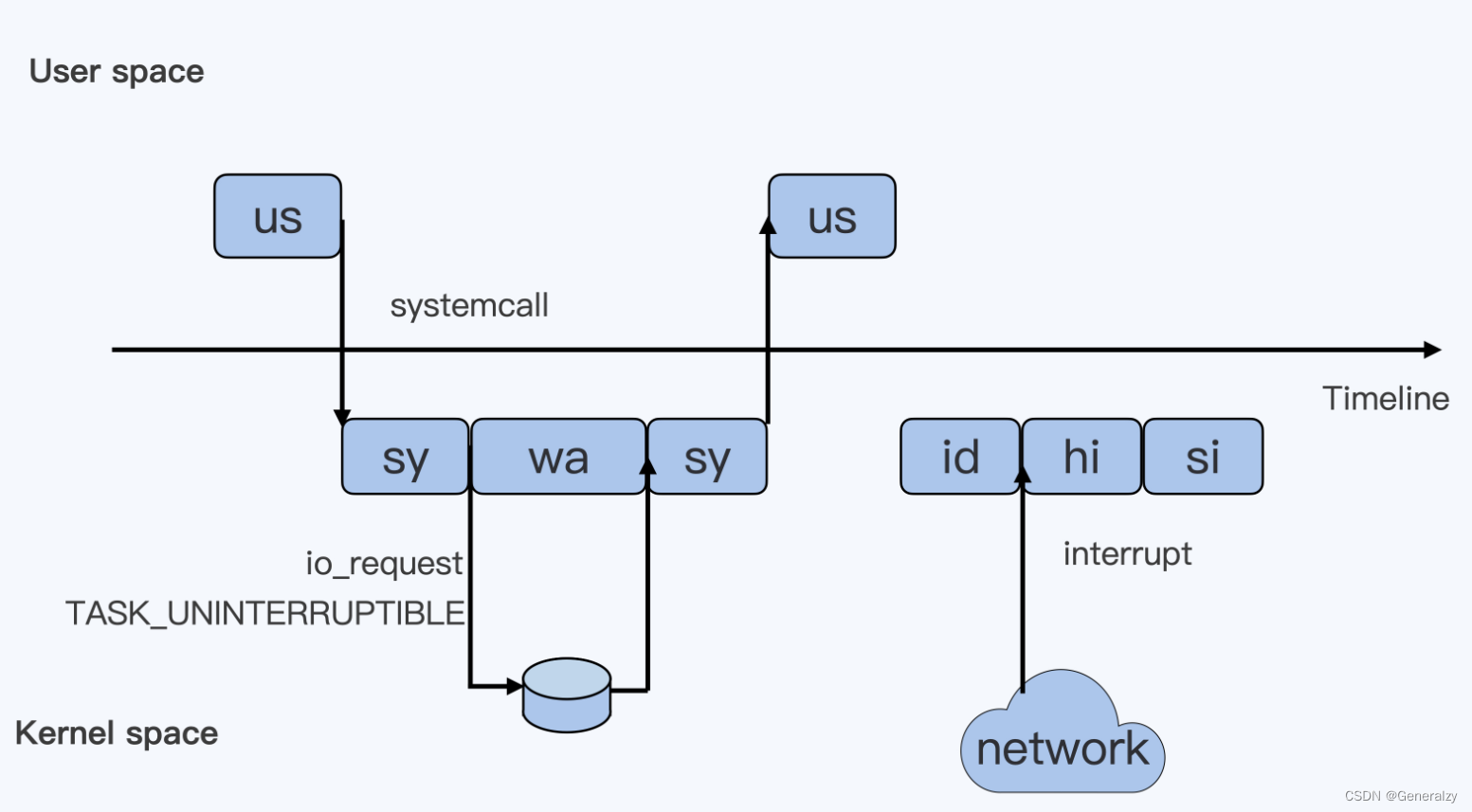
为了便于理解,假设只有一个cpu,按照从上到下从左到右的顺序以此解析每个框的含义:
你提供了关于Linux系统中CPU使用情况的详细解释,以下是提取出的文本内容:
-
第一个框us:一个用户程序开始运行,那么就对应于着第一个“us”框,代表linux用户态的Cpu Usage。普通的用户程序代码中,只要不是调用系统调用(System Call),这些代码的指令消耗的CPU就都属于“us”。
-
第二个框sys:当这个用户程序代码调用了系统调用,比如read()去读取一个文件,这时候这个用户的进程就会从用户态切换到内核态。内核态read()系统调用在读到真正disk上的文件前,就会进行一些文件系统层的操作,那么这些代码指令的消耗就属于“sy”,代表内核cpu使用。
-
第三个框wa:接下来,这个read()系统调用会向linux的Block Layer发出一个I/O Request,触发一个真正的磁盘读取操作,此时,这个进程一般会被置为不可中断睡眠状态TASK_UNINTERUPTIBLE。而linux会把这段时间标识成“wa”。
-
第四个框sys:紧接着,当磁盘返回数据时,进程在内核态拿到数据,这里仍旧是内核态CPU使用中的“sy”。
-
第五个框us:然后进程再从内核态切回用户态,在用户态得到文件数据,这里进程又回到用户态CPU使用,即“us”。
-
第六个框id:好,在这里我们假设一下,这个用户进程在读取数据之后,没事可做就休眠了,并且假设此时在这个CPU上也没有其他需要运行的进程了,那么系统就会进入“id”这个步骤,代表系统处于空闲状态。
-
第七个框hi:如果此时这台机器收到一个网络包,网卡就会发出一个中断(interrupt),该中断为硬中断,cpu必须响应,cpu响应后进入中断服务程序,此时cpu就会进入“hi”,代表cpu处理硬中断的开销。
-
第八个框si:由于我们的中断服务需要关闭中断,所以这个硬中断的时间不能太长。但发生中断之后的工作是必须要完成的,如果这些工作比较耗时怎么办?linux中有一个软中断的概念(softirq),它可以完成这些耗时比较长的工作。从网卡收到的数据包的大部分工作,都是通过软中断来最终处理的。
强调:无论是hi还是si,占用的cpu时间,都不会计入进程的cpu时间,因为本来中断程序就是单独的程序,它们在处理时本就不属于任何一个进程。
此外还有两个类型的cpu:一个是“ni”,另外一个是“st”。"ni"是nice的缩写,这里表示如果进程的nice值是正值(1-19),代表优先级比较低的进程运行时所占用的cpu。“st”是steal的缩写,是虚拟机里用的cpu使用类型,表示有多少时间是被同一个宿主机上的其他虚拟机抢走的。
(4)其余显示信息:关于进程
top 命令 VSZ,RSS,TTY,STAT, VIRT,RES,SHR,DATA的含义
====================================================
VIRT:virtual memory usage 虚拟内存
1、进程“需要的”虚拟内存大小,包括进程使用的库、代码、数据等
2、假如进程申请100m的内存,但实际只使用了10m,那么它会增长100m,而不是实际的使用量
RES:resident memory usage 常驻内存
1、进程当前使用的内存大小,但不包括swap out(当某进程向OS请求内存发现不足时,OS会把内存中暂时不用的数据交换出去,放在SWAP分区中,这个过程称为SWAP OUT。当某进程又需要这些数据且OS发现还有空闲物理内存时,又会把SWAP分区中的数据交换回物理内存中,这个过程称为SWAP IN)
2、包含其他进程的共享
3、如果申请100m的内存,实际使用10m,它只增长10m,与VIRT相反
4、关于库占用内存的情况,它只统计加载的库文件所占内存大小
SHR:shared memory 共享内存
1、除了自身进程的共享内存,也包括其他进程的共享内存
2、虽然进程只使用了几个共享库的函数,但它包含了整个共享库的大小
3、计算某个进程所占的物理内存大小公式:RES – SHR
4、swap out后,它将会降下来,因为内存充裕了,大家就没必要合租内存了
DATA
1、数据占用的内存。如果top没有显示,按f键、然后用空格选中DATA项目、然后按q则可以显示出来。
2、真正的该程序要求的数据空间,是真正在运行中要使用的。
# 三 top 运行中可以通过 top 的内部命令对进程的显示方式进行控制。内部命令如下:
命令
M 按内存的使用排序
P 按CPU使用排序
N 以PID的大小排序
R 对排序进行反转
f 自定义显示字段
1 显示所有CPU的负载
s 改变画面更新频率
h|?帮助
< 向前
> 向后
z 彩色
(5) 调整进程的优先级:
1、r 调整进程的优先级(Nice Level)
优先级的数值为-20~19,其中数值越小优先级越高,数值越大优先级越低,-20的优先级最高,19的优先级最低。
需要注意的是普通用户只能在0~19之间调整应用程序的优先权值,只有超级用户有权调整更高的优先权值(从-20~19)。
2、k 给进程发送信号 1,2(^C),9,15,18,19(^Z)
(6) 更多内部命令
l – 关闭或开启第一部分第一行 top 信息的表示
t – 关闭或开启第一部分第二行 Tasks 和第三行 Cpus 信息的表示
m – 关闭或开启第一部分第四行 Mem 和 第五行 Swap 信息的表示
N – 以 PID 的大小的顺序排列表示进程列表
P – 以 CPU 占用率大小的顺序排列进程列表
M – 以内存占用率大小的顺序排列进程列表
h – 显示帮助
n – 设置在进程列表所显示进程的数量
q – 退出 top
序号 列名 含义
a PID 进程id
b PPID 父进程id
c RUSER Real user name
d UID 进程所有者的用户id
e USER 进程所有者的用户名
f GROUP 进程所有者的组名
g TTY 启动进程的终端名。不是从终端启动的进程则显示为 ?
h PR 优先级
i NI nice值。负值表示高优先级,正值表示低优先级
j P 最后使用的CPU,仅在多CPU环境下有意义
k %CPU 上次更新到现在的CPU时间占用百分比
l TIME 进程使用的CPU时间总计,单位秒
m TIME+ 进程使用的CPU时间总计,单位1/100秒
n %MEM 进程使用的物理内存百分比
o VIRT 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
p SWAP 进程使用的虚拟内存中,被换出的大小,单位kb。
q RES 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
r CODE 可执行代码占用的物理内存大小,单位kb
s DATA 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb
t SHR 共享内存大小,单位kb
u nFLT 页面错误次数
v nDRT 最后一次写入到现在,被修改过的页面数。
w S 进程状态。(D=不可中断的睡眠状态,R=运行,S=睡眠,T=跟踪/停止,Z=僵尸进程)
x COMMAND 命令名/命令行
y WCHAN 若该进程在睡眠,则显示睡眠中的系统函数名
z Flags 任务标志,参考 sched.h
默认情况下仅显示比较重要的 PID、USER、PR、NI、VIRT、RES、SHR、S、%CPU、%MEM、TIME+、COMMAND 列。可以通过下面的快捷键来更改显示内容。
通过 f 键可以选择显示的内容。按 f 键之后会显示列的列表,按 a-z 即可显示或隐藏对应的列,最后按回车键确定。
按 o 键可以改变列的显示顺序。按小写的 a-z 可以将相应的列向右移动,而大写的 A-Z 可以将相应的列向左移动。最后按回车键确定。
按大写的 F 或 O 键,然后按 a-z 可以将进程按照相应的列进行排序。而大写的 R 键可以将当前的排序倒转。
cpu usage是什么
既然cpu cgroup是限制进程对cpu的使用,那么在研究具体如何配置相关限制之前,必须搞清楚进程对cpu的使用都有哪些,因为cpu usage有一些对cpu的使用时不会计入进程对cpu占用的。
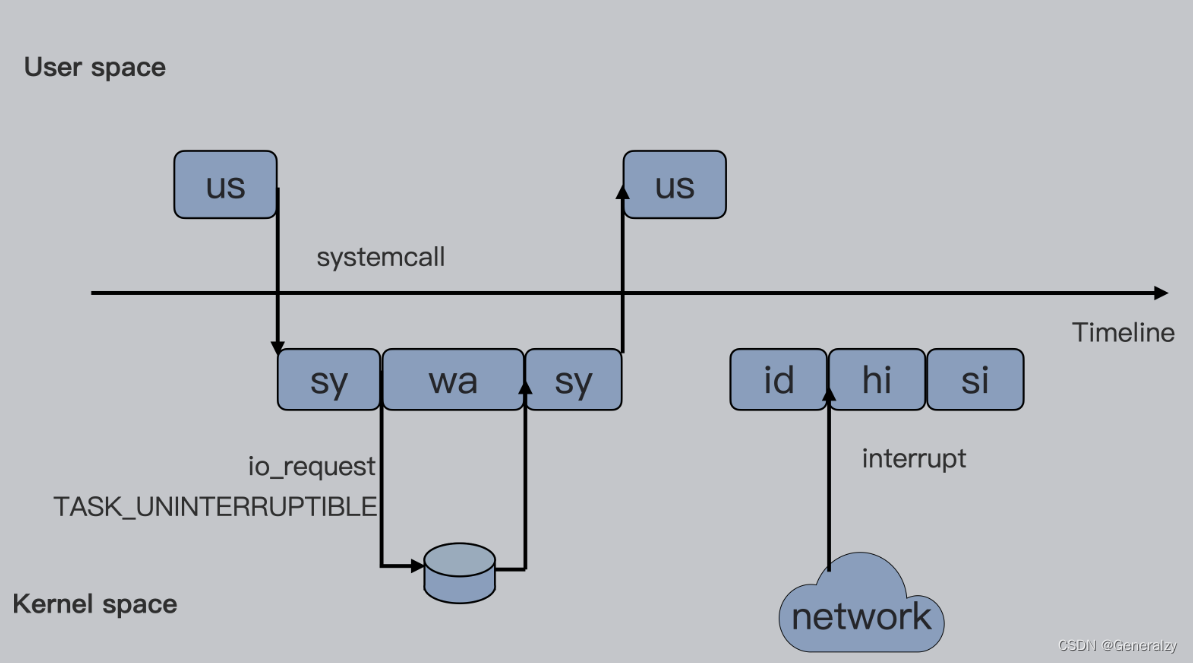
# 可以通过top命令查看到如下关于cpu usage
us User,用户态进程占用cpu时间的百分比,不包括低优先级进程的用户态时间(nice值1-19)
sys System,内核态进程占用cpu时间的百分比
ni Nice,nice值1-19的进程用户态占cpu时间的百分比,注意ni与us一样,都是在用户态
id Idle,系统空闲cpu的百分比
wa Iowait,系统等待I/O的cpu时间占比,该时间不计入进程的CPU时间
hi Hardware irq,处理硬件中断所占用CPU的时间,该时间同样不计入进程的CPU时间
si Softtirq,处理软件中断的时间,该时间不计入进程的CPU时间
st Steal,表示同一宿主机上的其他虚拟机抢走的CPU时间
---------------------------------------------------
强调:
1、无论是hi还是si,占用的cpu时间,都不会计入进程的cpu时间,
因为本来中断程序就是单独的程序,它们在处理时本就不属于任何一个进程,即不属于用户态也不属于内核态,因此cgroup不会限制它们
2、不可中断睡眠D代表的是,进程正在进行的io,我们可以把进程正在进行的IO操作比喻为进程正在取快递,你是进程,快递员是磁盘,你问快递员把快递给我吧,快递员说我有点忙,你等我去车上取过来给你,你别跑啊,你千万别跑啊,我这就给你去取,我真的是很忙,你要说跑了,我取过来你没有收到,那么我可就不管你了啊,于是你就进入了一个等待的状态,此时无论什么事都不能影响你,更不可能直接被kill干掉,因为一旦发生这件事,快递员取来东西你可就收不到了,这种等待就是不可中断睡眠
3、可终端店额睡眠S代表的是,进程就是在原地等待,还是进程"取快递"的例子,你是进程,快递员此时变成了网卡或者是终端的输入操作,你的程序运行到一行代码,等待用户输入才能继续运行,至于用户什么时候输入,不知道,那进程就进入了S状态,你是可以被kill掉的。就好比是你网购完东西后你知道会有快递会送给你,但是什么时候送你根本不知道,那你肯定不必在原地傻等着
---------------------------------------------------
了解:
硬中断hi与软中断si(中断是一种设备数据处理机制,linux通过中断打断一个进程的运行让其处理设备数据,就好比你正在吃饭,送快递的打了一个电话过来让你取快递去,这个电话就是一个中断信号,快递员就好比是网卡这种谁硬件设备
只有硬中断的化,可能会因为需要处理数据的时间过程而明显耽误当前进程的执行,所以有了软中断
软中断是配合硬中断运行的,
你正在吃饭,硬中断就好比是有人拿大铁棒朝着你脑门就是一棒子,你必须要愣一下,然后你先不着急报仇,先在本子上记下来某年某月某日有人拿棒子打了我以后是要报仇的,然后你可以继续吃饭,过了一会你爸爸也就是操作系统看了一眼你的记仇本,然后对你吼了一嗓子赶紧报仇去,这个就是软中断,于是你停止吃饭,开始复仇
cpu用户态进程使用比例包括us与ni
cpu内核态进程使用比例只有sys,不包括hi,si,wait这些都不计入进程信息
总结,进程对cpu的使用包括两部分:
-
Linux CPU 的使用总共分为两类:一类是用户态,包含us与ni,另外一类是内核态也就是sy。
-
至于wa、hi、si,这些I/O或者中断相关的CPU使用,CPU cgroup不会去做限制。
CPU Cgroup的使用
每个Cgroups的子系统都是通过一个虚拟文件系统挂载点的方式,挂到一个缺省的目录下。在linux发行版里,cpu cgroup一般是挂载到/sys/fs/cgroup/cpu目录下。
在该目录下,每个控制组(Control Group)都是一个子目录,各个控制组之间的关系是一个树状的层级关系(hiearchy)
例如,在子系统的最顶层目录开始创建两个控制组,其实就是创建两个目录group1与group2,然后再在group2下面创建两个控制组group3与group4,如此便建立了一个树状的控制组层级,如下图所示
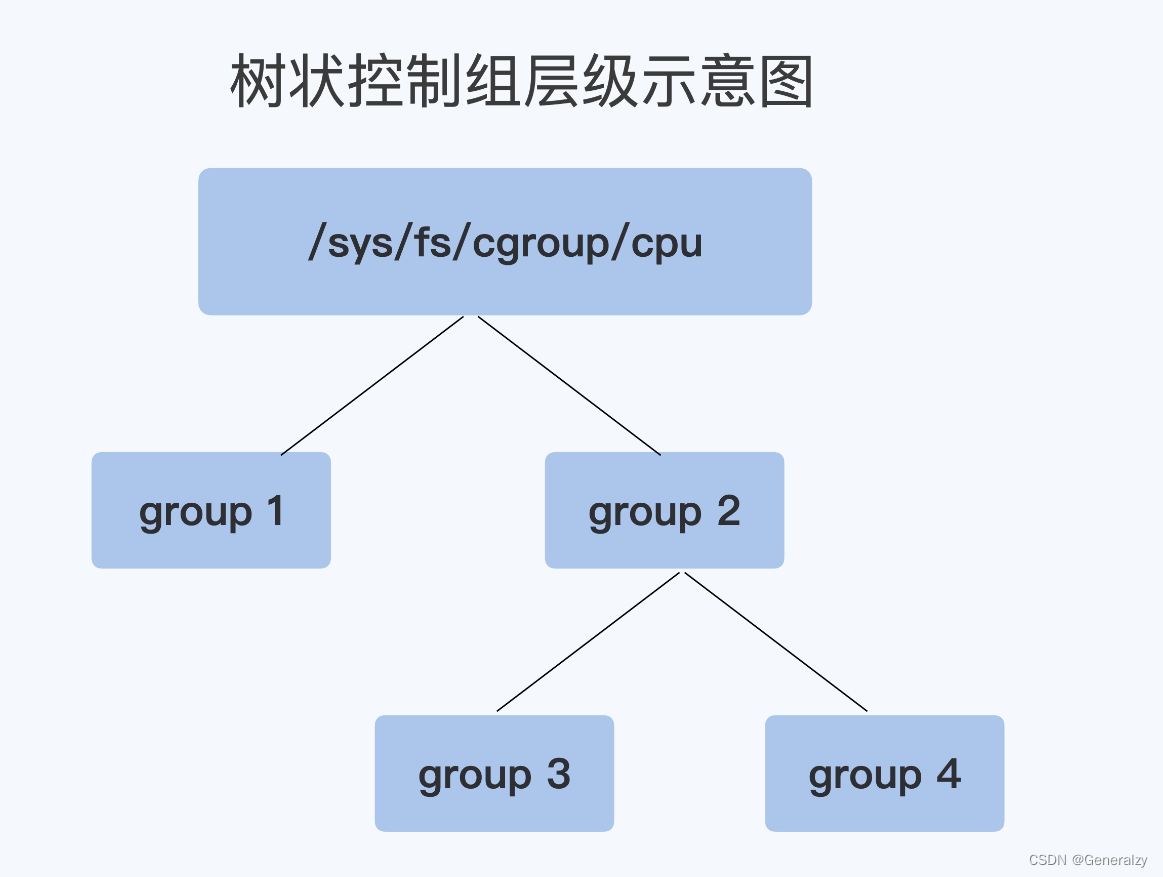
创建控制组后,会在目录下自动生成一系列文件
[root@test04 cgroup]# df -h |grep sys
tmpfs 981M 0 981M 0% /sys/fs/cgroup
[root@test04 cgroup]# cd /sys/fs/cgroup/
[root@test04 cgroup]#
[root@test04 cgroup]#
[root@test04 cgroup]# cd cpu
[root@test04 cpu]#
[root@test04 cpu]# mkdir group1
[root@test04 cpu]# mkdir group2
[root@test04 cpu]# cd group2
[root@test04 group2]# mkdir group3 group4
[root@test04 group2]#
[root@test04 group2]#
[root@test04 group2]#
[root@test04 group2]# ls cpu.*
cpu.cfs_period_us cpu.cfs_quota_us cpu.rt_period_us cpu.rt_runtime_us cpu.shares cpu.stat
删除控制组
rm -rf 控制组目录,会报错不允许删除
# 解决方法
借助libcgroup工具删除目录
# 安装LIBCGROUP工具:使用 libcgroup 工具前,请先安装 libcgroup 和 libcgroup-tools 数据包
# REDHAT系统安装
yum install libcgroup libcgroup-tools -y
# UBUNTU系统安装:
apt-get install cgroup-bin
# 验证是否安装成功
cgdelete -h
cgdelete cpu:/group1
cgdelete cpu:/group2
有子group需要-r删除
cgdelete -r cpu:/group1
在云平台里,大部分程序都不是实时调度的进程,而是普通调度(SCHED_HORMAL)类型进程,对于普通调度用到的算法,在linux系统中目前是CFS(Completely Fair Scheduler,即完全公平调度器)。在CPU Cgroup中和CFS相关的参数,共有三个:
-
cpu.cfs_period_us:它是CFS算法的一个调度周期,以microseconds(微妙)为单位,1微妙等于千分之一毫秒,1毫秒等于千分之一秒,例如值为100 000microseconds,则代表100ms。 -
cpu.cfs_quota_us:它表示CFS算法中,在一个调度周期里,此控制组被允许的运行时间,比如该值为50000时,就是50ms。cpu.cfs_period_us / cpu.cfs_quota_us就是此控制组被允许使用cpu的最大配额,例如50ms / 100ms = 0.5,代表该控制组被允许使用的cpu最大配置为0.5个cpu。 -
cpu.shares:该值用于控制在一个控制组目录树下,同一级控制组关于cpu的分配比例,例如上例中的group3与group4,如果group3下该值为1024,group4下该值为4096,则group3:group4比值为1:4,代表在一个5颗cpu的机器上,当group3与group4都需要5个cpu时,它们实际分配的cpu是:group3是1个,group4是4个。
[root@test04 cpu]# cat /sys/fs/cgroup/cpu/cpu.cfs_quota_us
-1
[root@test04 cpu]# cat /sys/fs/cgroup/cpu/cpu.cfs_period_us
100000
[root@test04 cpu]# cat /sys/fs/cgroup/cpu/cpu.shares
1024
[root@test04 cpu]#
Kubernetes会为每个容器创建一个控制组,然后把容器进程pid写入控制组。在YAML文件中,通过设置limit来控制cpu.cfs_quota_us/cpu.cfs_period_us的比值,从而得到资源使用的上限。
设置Kubernetes的CPU requests实际上是设置了cpu.shares cgroup属性。与内存requests类似,CPU requests会让调度器选择至少拥有那么多可用CPU分片的节点。不同于内存requests,设置CPU requests也会给cgroup设置相应的属性,帮助内核实际给进程分配一样数量的CPU核心分片。对于Limits的处理也与内存不一样。超出内存limits会让你的容器进程成为oom-kill的选项,但是你的进程基本上不可能超出设置的cpu配额,并且永远不会因为试着使用更多CPU而被驱逐。系统在调度器那里加强了配额的使用,所以进程在到达limits后只会被限流。
监控容器cpu真实使用率
在容器内无法通过top命令获取真实cpu使用率
当容器云平台中一些节点出现负载过高、导致应用程序异常时,一个主要的解决方案就是找出对 CPU 占用过高的进程。容器云平台主要跑的都是容器进程,如何查看容器进程对 CPU 的真实使用率就成了一件重要的事情。
在宿主机可以通过top命令查看,但是在容器里,通过top命令是无法查看到容器本身总共占用了多cpu资源的,看到的依然是宿主机的状态。
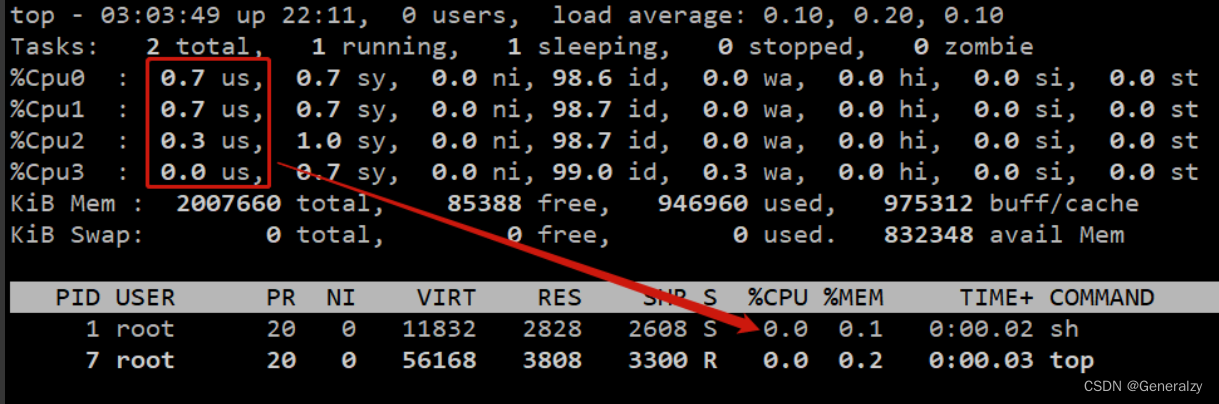
发现容器内进程消耗 0.7+0.7+0.3+0.0,而容器内的 sh 进程与 top 进程都没有消耗这么多 CPU,这就验证了:在容器内是无法通过 top 命令获取容器对 CPU 的占用率的。
获取单个进程对cpu的使用率
前置知识:
-
关于 CPU 使用率
- 某个用户进程对 CPU 的利用率 = 用户进程占用的 CPU 时间(包括用户态 us + 内核态 sy) / CPU 经历的这段总时间
- 进程对 CPU 的利用率为 100% 代表使用 1 颗 CPU,为 200% 代表使用 2 颗 CPU。如果宿主机只有 4 颗 CPU,那么某个进程对 CPU 的利用率最多 400%。
- 总结:CPU 使用率反应的是 CPU 的利用情况
-
关于 Load Average
- 在某段时间内平均活跃的进程数(包含系统处于可运行状态以及不可中断状态的平均进程数)
- 如果宿主机有 4 颗 CPU,那么平均负载是可以超过 4 的。
- 总结:负载反应的是 CPU 的工作量
-
进程从启动那一刻开始 Linux 操作系统就会累积该进程对 CPU 的资源的占用时间,是累加的。
- 举例:开机后时间在一分一秒地走,此时我们发现当前时间为 18:00,某进程占用 CPU 的时间的累积总量为 10s。然后时间来到了 19:00,我们发现该进程对 CPU 的占用时间累积到了 100s。那么在 CPU 经历的这一个小时内,该进程对 CPU 的占用时间为 100s - 10s。
具体来说负责记录进程对cpu资源累积占用的是linux系统中proc文件系统,top命令就是通过查看proc文件系统中每个进程对应stat文件中的2个数值来完成统计的。
# 1、测试脚本
[root@test04 ~]# cat a.sh
i=0
while true;
do
let i++
done
[root@test04 ~]#
# 2、执行
[root@test04 ~]# sh a.sh &
[1] 43157
# 3、查看
[root@test04 ~]# cat /proc/43157/stat | awk '{print $14,$15}'
1314 14
cat /proc/19838/stat 的内容有50多项,包括进程pid、名字、运行状态、ppid、优先级、内存使用等。要统计cpu使用率,主要关注第14项utime与第15项目stime:
utime代表进程的用户态部分在 Linux 系统调度中获取的 CPU 的 ticks。stime代表进程的内核态部分在 Linux 系统调度中获取的 CPU 的 ticks。
ticks 是 Linux 系统的一个时间单位,与人们熟悉的秒、毫秒一样都是时间单位,只不过在 Linux 中,一个 tick 代表一次中断的周期。这个周期需要耗费的时间由中断频率 HZ 决定,HZ 在 Linux 系统中默认为 100,可以用如下命令查看:
[root@test04 ~]# getconf CLK_TCK # HZ为100代表1s内发生100次中断,
100
一个tick具体代表多长时间:1/100 秒,即一次中断耗费的时间是1/100秒,也就是一个tick所代表的的时间。如果utime等于150ticks,就相当于150*1/100=1.5秒,代表进程从启动那一刻到现在总共在用户态运行了1.5秒钟。
统计进程对cpu的占用率,公式如下:
进程的 CPU 使用占比 =((utime_2 – utime_1) + (stime_2 – stime_1)) / (HZ * et * 1 )
上述结果为一个小数,想要得到百分率,需要乘以100,如下
进程的 CPU 使用百分率 = ((utime_2 – utime_1) + (stime_2 – stime_1)) * 100 / (HZ * et * 1 )
et为统计的时间间隔,如果为10s,那么需要在开始获取一下utime_1与stime_1,然后等待10s后,再次获取,即utime_2与stime_2,那么((utime_2 – utime_1) + (stime_2 – stime_1))代表的就是10s内,该进程累积对占用的用户态与内核态的ticks总数。
(HZ * et * 1) 中,1 代表 1 颗 CPU,et 代表时间间隔,HZ 代表中断频率。ticks 是按照固定频率发生的,在 Linux 系统中默认 HZ 为 100,代表 1 秒钟是 100 次。所以,(HZ * et * 1) 即(100 * 10 * 1),代表 10 秒内一个 CPU 总共的 ticks 数。
综上,上面的公式可以简化为:
进程的 CPU 使用百分率 =(某段时间内进程占内核态与用户态ticks/ 该段时间内单个 CPU 总 ticks)*100.0
最后乘以那个100代表转换为百分比
补充:一个 CPU 的完整工作时间,可能服务过多个进程。如下图颜色标注代表 CPU 服务过 3 个进程,红色框代表的进程可能占用的只是 tick3、tick6、tick7 这三个时间片,那么该段时间内,红色框进程对 CPU 的占用率(注意对 CPU 的占用率一定统计的是单颗)就是 3/7。

自己编写脚本来统计该进程对cpu的占用率:
utime1=$(cat /proc/63214/stat | awk '{print $14}')
stime1=$(cat /proc/63214/stat | awk '{print $15}')
sleep 10 # 等待10s后
utime2=$(cat /proc/63214/stat | awk '{print $14}')
stime2=$(cat /proc/63214/stat | awk '{print $15}')
user_ticks=$((utime2-utime1))
sys_ticks=$((stime2-stime1))
process_total_ticks=$((user_ticks+sys_ticks))
cpu_total_ticks=$((100 * 10 * 1))
echo ${process_total_ticks} / ${cpu_total_ticks} | bc -l
输出.07600000000000000000,与用ps命令或者top命令看到的7.6一致
[root@test04 ~]# sh a.sh &
[1] 63214
[root@test04 ~]# ps aux |head -1
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
[root@test04 ~]# ps aux |grep 63214 |grep a.sh
root 63214 7.6 0.1 113552 3316 pts/0 S 12:30 1:43 sh a.sh
不可中断睡眠对容器的影响
一、死了的进程:
进程在调用 do_exit() 退出的时候,有两个状态
(1)一个是 :EXIT_DEAD,也就是进程在真正结束退出的那一瞬间的状态;
(2)另外一个是:EXIT_ZOMBIE 状态,这是进程在 EXIT_DEAD 前的一个状态,即僵尸进程,
二、活着的进程
1、运行着:运行+就绪,统称TASK_RUNNING)
运行着的进程分为两种:一种是真的拿到cpu资源真的在运行,另外一种就是在运行队列里、随时可以运行,处于R状态的进程泛指这两种情况
2、睡眠着:
睡眠着是指,进程需要等待某种资源而进入的状态,要等的资源可以是一个信号量Semaphore), 或者是磁盘 I/O,这个状态的进程会被放入到 wait queue 队列里。
睡眠着的进程具体还包括两个子状态:
(1)一个是不可被打断的(TASK_UNINTERRUPTIBLE),用 ps 查看进程,就显示为 D stat。---》正在进行的io
什么时候进程会处于不可中断睡眠状态,例如,当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,
它是不能被其他进程或者中断打断的,这个时候的进程就处于不可中断状态。如果此时的进程被打断了,就容易出现磁盘数据与进程数据不一致的问题。
所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制
(2)一个是可以被打断的(TASK_INTERRUPTIBLE),我们用 ps 查看到的进程,显示为 S stat。--》正在等待,
就好比是你网购完东西后你知道会有快递会送给你,但是什么时候送你根本不知道,那你肯定不必在原地傻等着
举例:
我们的程序有三行代码,运行到第二行要把一个视频文件读入内存,第三行才能处理,此时因为磁盘速度太慢了,导致io积压,
比如在虚拟机里压缩一个大文件,该压缩进程就有可能进入D状态,总之D与S是有本质区别的,S状态类似python中input接收输入的代码,
代表程序睡眠阻塞住了,什么时候有内容输入并不知道,而D状态代表明确正在做io,
1、关于cpu使用率:
某个用户进程对cpu的利用率 = 用户进程占用的cpu时间(包括用户态us+内核态sy) / cpu经历的这段总时间
进程对cpu的利用率为100%代表使用1颗cpu
进程对cpu的利用率为200%代表使用2颗cpu
如果宿主机只有4颗cpu,那么某个进程对cpu的利用率最多400%
2、关于load average:
在某段时间内平均活跃的进程数(包含系统处于可运行状态以及不可中断状态的平均进程数)
为何不可中断睡眠也属于活跃的进程
一个进程内要做的事可以分为两大类
1、计算任务---》cpu负责运行
2、io任务-----》磁盘、网卡负责处理
只要该进程正在被处理着,那它就属于活跃的进程
cpu在执行该进程的计算机任务,肯定属于活跃
磁盘在处理该进程的io任务,那肯定也属于活跃
总之有事做就属于活跃
而S状态,在等待用户输入内容,而此时用户什么也没有输,即io操作啥事也没做,计算任务也肯定没有
整个进程就是不活跃的
如果你的物理机有1颗cpu,那么满负载为1,代表可以同时运行1个进程,超过1就代表超载,小于1就代表空闲
如果你的物理机有4颗cpu,那么满负载为4,代表可以同时运行4个进程,超过4则代表超载,小于4就代表空闲
以1颗cpu为例,如果处理器上有一个R的进程,同时在系统的进程可运行队列里有9个进程,那么1分钟的load average=1+9
如果宿主机有4颗cpu,那么平均负责是可以超过4的
3、结论
有可能会出现工作量很大,但是利用率很低,比如每个员工手里都有很多活要做,但实际上你问问每个活的进度是啥大家都告诉这些活都在进行着,但是都处于
等待的状态,那怒了,你傻啊,等待的过程你不会干别的事啊,员工也很冤枉,说不行啊老板,我这个io是不可中断的io,不能被中断
必须等着对方送过来数据才行,你别看我很闲,但是这件事确实是正在进行的事情
我们可以使用cpu cgroup对容器的cpu资源进行限制,但是cpu cgroup并非是万能的,它无法限制Load Average,没有这个限制,会影响我们对资源的合理调度,进而导致系统变得很慢。
例如:有时会遇到所有容器进程、以及宿主机的cpu使用率都很低,但是容器里的应用运行速度非常慢,并且查看宿主机的Load Average的平均负载会发现非常高。
这到底是因为什么导致的呢?
其实这与 Linux 系统的 Load Average 的统计方式有关。在 Linux 操作系统中,Load Average 把不可中断睡眠状态的进程也当成是活跃的进程,并计算到了 Load Average 里。所以如果系统中有大量进程处于 D 状态,会导致 Load Average 增高,而 D 状态作为一种睡眠状态是不会消耗 CPU 的,所以 CPU 利用率会很低。
模拟一下,cpu idle剩余率很多、cpu很充足,但是load average非常高
linux系统中也存在容易捕捉的TASK_UNINTERRUPTIBLE状态。
执行vfork系统调用后,父进程将进TASK_UNINTERRUPTIBLE状态,
直到子进程调用exit或exec 通过下面的代码就能得到处于TASK_UNINTERRUPTIBLE状态的进程:
[root@test04 ~]# cat test.c
void main() {
if (!vfork()) while (1) {sleep(1);};
}
[root@test04 ~]# gcc -o test test.c
[root@test04 ~]# for i in `seq 1 100`;do (./test &) ;done # 启动100个D状态的进程
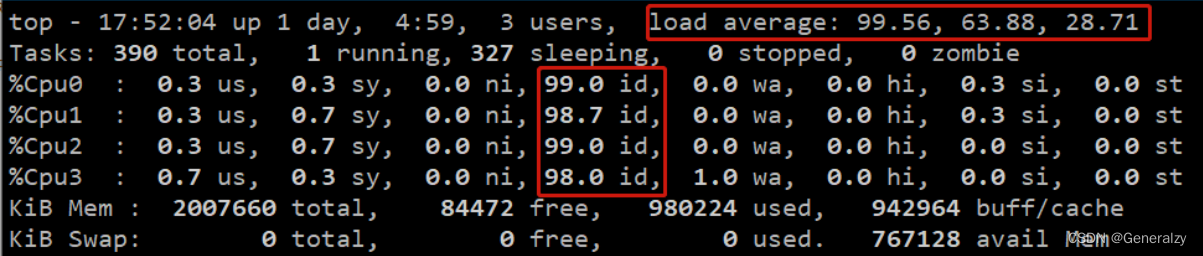
发现cpu剩余率量大很充足,但是平均负载却很高。
Load Average的统计方式
top命令可以看到load average,分别对应1分钟、5分钟、15分钟的cpu平均负载

为何 Linux 操作系统会把不可中断睡眠也计算到 Load Average 里?
答案:Linux 起源于 Unix,早在 Unix 系统里,就有 Load Average 的概念了。但是在 Unix 系统里没有把不可中断睡眠 D 状态的进程数计算到 Load Average 里,而在 Linux 系统里却把不可中断睡眠 D 状态的进程数计算到 Load Average 里了。
-
在大多数 Unix 发行版里:
- Load Average = 正在运行的进程数 + 处于就绪的进程数(即已经存在于操作系统的进程可运行队列里,只要申请到 CPU 资源即可投入运行的进程)
-
而在 Linux 系统里:
- Load Average = 正在运行的进程数 + 处于就绪的进程数 + 休眠队列中处于不可中断睡眠 D 状态的进程数
Linux 系统为何要这么做呢???要解答这个疑问,必须要搞明白 Load Average 这个指标到底要反应什么?
假设你的机器就一个cpu:
- 一个进程都是向前行进的一辆车。
- 既然一个进程可以被比喻为一辆往前行进的车,那负责运行(或者说承载)进程的 CPU 就相当于一条单行车道(同一时间只允许通行一辆车)。
- 而 Load Average 反应的就是整个系统的交通情况,具体是指所有条路的单位时间通过的车辆数(即活跃的进程数)。
- D 状态的进程就好比是车辆在等待红灯,而且是不可中断的等,毫无疑问这辆车应该被认为是处于活跃状态。处于 D 状态,虽然不消耗 CPU、不会统计到 CPU 占用率里,但是它一定是活跃的进程。
- S 状态的进程就好比是车辆停在你的车库里。
如果要反应路况情况,肯定是需要把等待红灯的情况即 D 状态也考虑进去,这种统计更为科学。一条路的路况肯定是需要考虑红绿灯情况的,哪怕有一条路很空(CPU 利用率很低),但是红绿灯特别多,汽车也需要排队,不可能开快。如果这辆车是出租车,作为客户坐在车里的直观感受就是车开得很慢。
所以说 Load Average 反应的是整个系统的任务量/负载量情况,而 CPU 利用率反应的则是每个 CPU 的利用情况。
综上,如果 IO 设备出现瓶颈,势必会造成大量的进程处于等待 IO 的状态。这种情况下,虽然不关 CPU 什么事,整个系统的处理能力其实已经出现了很大的瓶颈。所以把 D 状态的进程算在平均负载里也还算合理。当系统 Load Average 比较高时,首先我们需要去甄别,到底是 CPU 的问题还是 IO 的问题。
有4颗cpu,满负载任务数就为4,超了就要分析原因了,看看是否是D状态带来的影响。因为当D状态过多,就可能程序出一种效果:所有进程的cpu占用率非常低,但是cpu的1分钟5分钟15分钟负载非常高,这个会影响k8s的调度
在k8s中限制pod的pid数
使用 Cgroups 限制 Kubernetes Pod 进程数
Kubernetes 里面的 Pod 资源是最小的计算单元,抽象了一组(一个或多个)容器。容器也是 Linux 系统上的进程,但基于 Namespace 和 Cgroups(Control groups) 等技术实现了不同程度的隔离。简单来说,Namespace 可以让每个进程有独立的 PID, IPC 和网络空间。Cgroups 可以控制进程的资源占用,比如 CPU,内存和允许的最大进程数等等。
Kubernetes 里面的每个节点都会运行一个叫做 Kubelet 的服务,负责节点上容器的状态和生命周期,比如创建和删除容器。根据 Kubernetes 的官方文档 Process ID Limits And Reservations 内容,可以设置 Kubelet 服务的 --pod-max-pids 配置选项,之后在该节点上创建的容器,最终都会使用 Cgroups pid 控制器限制容器的进程数量。
我的Kubernetes 是在 CentOS 7 上使用 kubeadm 部署的 v1.15.9 版本,需要额外设置 SupportPodPidsLimit 的 feature-gate,对应操作如下(其它发行版应该也类似):
# kubelet 使用 systemd 启动的,可以通过编辑 /etc/sysconfig/kubelet
# 添加额外的启动参数,设置 pod 最大进程数为 1024
$ vim /etc/sysconfig/kubelet
KUBELET_EXTRA_ARGS="--pod-max-pids=1024 --feature-gates=\"SupportPodPidsLimit=true\""
# 重启 kubelet 服务
$ systemctl restart kubelet
# 查看参数是否生效
$ ps faux | grep kubelet | grep pod-max-pids
root 104865 10.5 0.6 1731392 107368 ? Ssl 11:56 0:30 /usr/bin/kubelet ... --pod-max-pids=10 --feature-gates=SupportPodPidsLimit=true
通过配置 Kubelet 的 --pod-max-pids=1024 选项,限制了一个容器内允许的最大进程数为 1024 个。现在来测试下如果容器内不断 fork 子进程,数目到达 1024 个时会触发什么行为。
参考 Fork bomb 的内容,可以创建一个 pod,不断 fork 子进程。
# 创建普通的 nginx pod yaml
$ cat <<EOF > test-nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-nginx
spec:
containers:
- name: nginx
image: nginx
EOF
# 创建到 Kubernetes 集群
$ kubectl apply -f test-nginx.yaml
# 进入 nginx 容器模拟 fork bomb
$ kubectl exec -ti test-nginx bash
root@test-nginx:/# bash -c "fork() { fork | fork & }; fork"
environment: fork: retry: Resource temporarily unavailable
environment: fork: retry: Resource temporarily unavailable
environment: fork: retry: Resource temporarily unavailable
通过进入一个 nginx 容器里面使用 bash 运行 fork bomb 命令,我们会发现当 fork 的子进程达到限制的上限数目后,会报 retry: Resource temporarily unavailable 的错误。这个时候再看下宿主机的 fork 进程数目。
# 通过在外部宿主机执行下面的命令,会发现 fork 的进程数目接近 1024 个
$ ps faux | grep fork | wc -l
1019
通过以上的实验,发现能够通过设置 Kubelet 的 --pod-max-pids 选项,限制容器类的进程数,避免容器进程数不断上升最终耗尽宿主机资源,拖垮整个宿主机系统。