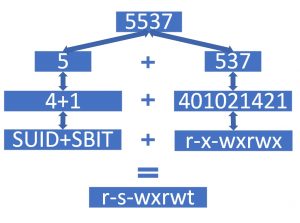
主要有以下几方面的内容:
- 对于多步长训练需要保存lr_schedule
- 初始化随机数种子
- 保存每一代最好的结果
简单详细介绍
最近在尝试用CIFAR10训练分类问题的时候,由于数据集体量比较大,训练的过程中时间比较长,有时候想给停下来,但是停下来了之后就得重新训练,我们学习断点继续训练及继续训练的时候注意epoch的改变等。
Epoch: 9 | train loss: 0.3517 | test accuracy: 0.7184 | train time: 14215.1018 s
Epoch: 9 | train loss: 0.2471 | test accuracy: 0.7252 | train time: 14309.1216 s
Epoch: 9 | train loss: 0.4335 | test accuracy: 0.7201 | train time: 14403.2398 s
Epoch: 9 | train loss: 0.2186 | test accuracy: 0.7242 | train time: 14497.1921 s
Epoch: 9 | train loss: 0.2127 | test accuracy: 0.7196 | train time: 14591.4974 s
Epoch: 9 | train loss: 0.1624 | test accuracy: 0.7142 | train time: 14685.7034 s
Epoch: 9 | train loss: 0.1795 | test accuracy: 0.7170 | train time: 14780.2831 s
绝望!!!!!训练到了一定次数发现训练次数少了,或者中途断了又得重新开始训练
一、模型的保存与加载
PyTorch中的保存(序列化,从内存到硬盘)与反序列化(加载,从硬盘到内存)
torch.save主要参数: obj:对象 、f:输出路径
torch.load 主要参数 :f:文件路径 、map_location:指定存放位置、 cpu or gpu
模型的保存的两种方法:
1、保存整个Module
torch.save(net, path)
2、保存模型参数
state_dict = net.state_dict()
torch.save(state_dict , path)
二、模型的训练过程中保存
checkpoint = {
"net": model.state_dict(),
'optimizer':optimizer.state_dict(),
"epoch": epoch
}
将网络训练过程中的网络的权重,优化器的权重保存,以及epoch 保存,便于继续训练恢复
在训练过程中,可以根据自己的需要,每多少代,或者多少epoch保存一次网络参数,便于恢复,提高程序的鲁棒性。
checkpoint = {
"net": model.state_dict(),
'optimizer':optimizer.state_dict(),
"epoch": epoch
}
if not os.path.isdir("./models/checkpoint"):
os.mkdir("./models/checkpoint")
torch.save(checkpoint, './models/checkpoint/ckpt_best_%s.pth' %(str(epoch)))
通过上述的过程可以在训练过程自动在指定位置创建文件夹,并保存断点文件
三、模型的断点继续训练
if RESUME:
path_checkpoint = "./models/checkpoint/ckpt_best_1.pth" # 断点路径
checkpoint = torch.load(path_checkpoint) # 加载断点
model.load_state_dict(checkpoint['net']) # 加载模型可学习参数
optimizer.load_state_dict(checkpoint['optimizer']) # 加载优化器参数
start_epoch = checkpoint['epoch'] # 设置开始的epoch
指出这里的是否继续训练,及训练的checkpoint的文件位置等可以通过argparse从命令行直接读取,也可以通过log文件直接加载,也可以自己在代码中进行修改。关于argparse参照我的这一篇文章:
四、重点在于epoch的恢复
start_epoch = -1
if RESUME:
path_checkpoint = "./models/checkpoint/ckpt_best_1.pth" # 断点路径
checkpoint = torch.load(path_checkpoint) # 加载断点
model.load_state_dict(checkpoint['net']) # 加载模型可学习参数
optimizer.load_state_dict(checkpoint['optimizer']) # 加载优化器参数
start_epoch = checkpoint['epoch'] # 设置开始的epoch
for epoch in range(start_epoch + 1 ,EPOCH):
# print('EPOCH:',epoch)
for step, (b_img,b_label) in enumerate(train_loader):
train_output = model(b_img)
loss = loss_func(train_output,b_label)
# losses.append(loss)
optimizer.zero_grad()
loss.backward()
optimizer.step()
通过定义start_epoch变量来保证继续训练的时候epoch不会变化
断点继续训练
更新于20200426
一、初始化随机数种子
import torch
import random
import numpy as np
def set_random_seed(seed = 10,deterministic=False,benchmark=False):
random.seed(seed)
np.random(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
if deterministic:
torch.backends.cudnn.deterministic = True
if benchmark:
torch.backends.cudnn.benchmark = True
关于torch.backends.cudnn.deterministic和torch.backends.cudnn.benchmark详见
benchmark用在输入尺寸一致,可以加速训练,deterministic用来固定内部随机性
二、多步长SGD继续训练
在简单的任务中,我们使用固定步长(也就是学习率LR)进行训练,但是如果学习率lr设置的过小的话,则会导致很难收敛,如果学习率很大的时候,就会导致在最小值附近,总会错过最小值,loss产生震荡,无法收敛。所以这要求我们要对于不同的训练阶段使用不同的学习率,一方面可以加快训练的过程,另一方面可以加快网络收敛。
采用多步长 torch.optim.lr_scheduler的多种步长设置方式来实现步长的控制,lr_scheduler的各种使用推荐参考如下教程:
所以我们在保存网络中的训练的参数的过程中,还需要保存lr_scheduler的state_dict,然后断点继续训练的时候恢复
#这里我设置了不同的epoch对应不同的学习率衰减,在10->20->30,学习率依次衰减为原来的0.1,即一个数量级
lr_schedule = torch.optim.lr_scheduler.MultiStepLR(optimizer,milestones=[10,20,30,40,50],gamma=0.1)
optimizer = torch.optim.SGD(model.parameters(),lr=0.1)
for epoch in range(start_epoch+1,80):
optimizer.zero_grad()
optimizer.step()
lr_schedule.step()
if epoch %10 ==0:
print('epoch:',epoch)
print('learning rate:',optimizer.state_dict()['param_groups'][0]['lr'])
lr的变化过程如下:
epoch: 10
learning rate: 0.1
epoch: 20
learning rate: 0.010000000000000002
epoch: 30
learning rate: 0.0010000000000000002
epoch: 40
learning rate: 0.00010000000000000003
epoch: 50
learning rate: 1.0000000000000004e-05
epoch: 60
learning rate: 1.0000000000000004e-06
epoch: 70
learning rate: 1.0000000000000004e-06
我们在保存的时候,也需要对lr_scheduler的state_dict进行保存,断点继续训练的时候也需要恢复lr_scheduler
#加载恢复
if RESUME:
path_checkpoint = "./model_parameter/test/ckpt_best_50.pth" # 断点路径
checkpoint = torch.load(path_checkpoint) # 加载断点
model.load_state_dict(checkpoint['net']) # 加载模型可学习参数
optimizer.load_state_dict(checkpoint['optimizer']) # 加载优化器参数
start_epoch = checkpoint['epoch'] # 设置开始的epoch
lr_schedule.load_state_dict(checkpoint['lr_schedule'])#加载lr_scheduler
#保存
for epoch in range(start_epoch+1,80):
optimizer.zero_grad()
optimizer.step()
lr_schedule.step()
if epoch %10 ==0:
print('epoch:',epoch)
print('learning rate:',optimizer.state_dict()['param_groups'][0]['lr'])
checkpoint = {
"net": model.state_dict(),
'optimizer': optimizer.state_dict(),
"epoch": epoch,
'lr_schedule': lr_schedule.state_dict()
}
if not os.path.isdir("./model_parameter/test"):
os.mkdir("./model_parameter/test")
torch.save(checkpoint, './model_parameter/test/ckpt_best_%s.pth' % (str(epoch)))
三、保存最好的结果
每一个epoch中的每个step会有不同的结果,可以保存每一代最好的结果,用于后续的训练
第一次实验代码
RESUME = True
EPOCH = 40
LR = 0.0005
model = cifar10_cnn.CIFAR10_CNN()
print(model)
optimizer = torch.optim.Adam(model.parameters(),lr=LR)
loss_func = nn.CrossEntropyLoss()
start_epoch = -1
if RESUME:
path_checkpoint = "./models/checkpoint/ckpt_best_1.pth" # 断点路径
checkpoint = torch.load(path_checkpoint) # 加载断点
model.load_state_dict(checkpoint['net']) # 加载模型可学习参数
optimizer.load_state_dict(checkpoint['optimizer']) # 加载优化器参数
start_epoch = checkpoint['epoch'] # 设置开始的epoch
for epoch in range(start_epoch + 1 ,EPOCH):
# print('EPOCH:',epoch)
for step, (b_img,b_label) in enumerate(train_loader):
train_output = model(b_img)
loss = loss_func(train_output,b_label)
# losses.append(loss)
optimizer.zero_grad()
loss.backward()
optimizer.step()
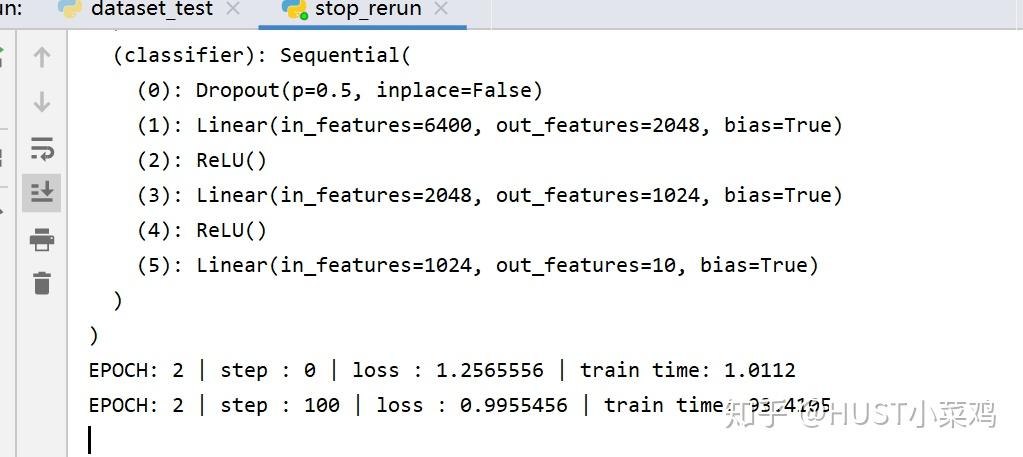
if step % 100 == 0:
now = time.time()
print('EPOCH:',epoch,'| step :',step,'| loss :',loss.data.numpy(),'| train time: %.4f'%(now-start_time))
checkpoint = {
"net": model.state_dict(),
'optimizer':optimizer.state_dict(),
"epoch": epoch
}
if not os.path.isdir("./models/checkpoint"):
os.mkdir("./models/checkpoint")
torch.save(checkpoint, './models/checkpoint/ckpt_best_%s.pth' %(str(epoch)))
更新实验代码
optimizer = torch.optim.SGD(model.parameters(),lr=0.1)
lr_schedule = torch.optim.lr_scheduler.MultiStepLR(optimizer,milestones=[10,20,30,40,50],gamma=0.1)
start_epoch = 9
# print(schedule)
if RESUME:
path_checkpoint = "./model_parameter/test/ckpt_best_50.pth" # 断点路径
checkpoint = torch.load(path_checkpoint) # 加载断点
model.load_state_dict(checkpoint['net']) # 加载模型可学习参数
optimizer.load_state_dict(checkpoint['optimizer']) # 加载优化器参数
start_epoch = checkpoint['epoch'] # 设置开始的epoch
lr_schedule.load_state_dict(checkpoint['lr_schedule'])
for epoch in range(start_epoch+1,80):
optimizer.zero_grad()
optimizer.step()
lr_schedule.step()
if epoch %10 ==0:
print('epoch:',epoch)
print('learning rate:',optimizer.state_dict()['param_groups'][0]['lr'])
checkpoint = {
"net": model.state_dict(),
'optimizer': optimizer.state_dict(),
"epoch": epoch,
'lr_schedule': lr_schedule.state_dict()
}
if not os.path.isdir("./model_parameter/test"):
os.mkdir("./model_parameter/test")
torch.save(checkpoint, './model_parameter/test/ckpt_best_%s.pth' % (str(epoch)))
深入解读
如果我们的模型训练到一半因为各种原因中断了,重新训练的话之前就白做了,对于需要训练好几天的模型,这显然无法让人接受。那么该如何重新加载模型继续训练呢?这就是断点续训。
常用代码及注意事项
首先我们要训练模型,代码中需先进行以下几个定义:
# 1.定义模型
self.model = CNN()
self.model.to(device)
# 2.定义损失函数
self.criterion = nn.CrossEntropyLoss()
# 3.定义优化器
self.optimizer = optim.Adam(model.parameters(), #可迭代的参数优化或dicts定义
lr=1e-3, # 学习率(默认1e-3)
betas=(0.9, 0.999), # 用于计算的系数梯度及其平方的运行平均值
eps=1e-8, # 增加分母项以提高数值稳定性
weight_decay=1e-4, # 权重衰减
amsgrad=False # 是否使用“Adam and Beyond收敛”一文中该算法的AMSGrad变体`,默认False
)
# 4.定义动态调整学习率(可不做)
self.lr_scheduler = WarmupMultiStepLR(optimizer=optimizer,
milestones=[100, 300],
gamma=0.1,
warmup_factor=0.1,
warmup_iters=2,
warmup_method="linear",
last_epoch=-1)
注意,model.to(device)将model放入cuda中,这一步一定要在定义optimizer之前做。
训练迭代例子:
self.start_epoch = 0
for self.epoch in range(self.start_epoch, 400):
for input, target in self.dataset:
self.optimizer.zero_grad()
output = self.model(input)
loss = self.criterion(output, target)
loss.backward()
self.optimizer.step()
self.lr_scheduler.step()
注意,optimizer.step()通常在每个batch之中,而lr_scheduler.step()通常在每个epoch之中。
原因:
step()可看做“每次调用才更新一次”。
所以为了在每个batch中loss反向传播能更新模型,optimizer.step()要紧跟在loss.backward()之后,否则模型不会在每个batch里都更新。
由于动态调整学习率如MutiStepLR、CosineAnnealingLR等,通常都设置成随着epoch变化而变化,所以lr_scheduler.step()要放在每个epoch下,如果也放在每个batch下的话,lr_scheduler将会更新epoch num * batch num次。
之前就是因为不小心把lr_scheduler.step()放在了batch里,导致动态调整学习率没起作用,因为前2个epoch就直接将lr调整到设定的最小值了…
训练状态保存
可以在每次best的时候保存模型状态,或者每个epoch之后都保存。
①主要是保存模型参数、optimizer、lr_scheduler、当前epoch、当前最好的结果best_metric。
import os
import glob.glob as glob
self.best_metric = 0.
# 保存最好的模型
def saveBestWeights(self):
if self.current_metric >= self.best_metric:
self.best_metric = self.current_metric
print('best and save')
torch.save({'epoch': self.epoch, 'state_dict': self.model.state_dict(),
'optimizer': self.optimizer.state_dict(),
'scheduler': self.lr_scheduler.state_dict(), 'best_acc': self.best_metric}
, os.path.join(self.checkpoint_dir, 'backbone_best.pth'))
# 每次都保存模型
def saveWeights(self, clean_previous=True):
if clean_previous:
files = glob(os.path.join(self.checkpoint_dir, '*.pth'))
for f in files:
if 'best' not in f:
os.remove(f)
torch.save({'epoch': self.epoch, 'state_dict': self.model.state_dict(),
'optimizer': self.optimizer.state_dict(),
'scheduler': self.lr_scheduler.state_dict(), 'best_acc': self.best_metric}
, os.path.join(self.checkpoint_dir, 'backbone_{}.pth'.format(epoch)))
②除此之外,还可以每次把训练损失、验证损失、验证结果等保存下来,作为调整模型的参考。
def save_process(self):
np.save(os.path.join(self.log_dir, 'train_loss.npy'), self.train_loss_list)
np.save(os.path.join(self.log_dir, 'valid_loss.npy'), self.valid_loss_list)
np.save(os.path.join(self.log_dir, 'valid_acc.npy'), self.valid_acc_list)
这里每个epoch之后都保存一下,这样会一次次覆盖之前保存的npy文件,也就是在训练过程中也可以把这些list拿出来,绘制曲线看看模型有没有收敛或有没有梯度消失爆炸等问题。
状态加载/继续训练
①加载模型参数、optimizer、lr_scheduler、当前epoch、当前最好的结果best_metric。
②加载训练损失、验证损失、验证结果等
if self.resume:
if len(os.listdir(self.checkpoint_dir)) > 0:
target_file = list(glob(os.path.join(self.checkpoint_dir, 'backbone*.pth')))[0]
print('loading weights from', target_file)
weights = torch.load(target_file, map_location=self.device)
# 从哪里开始训练
self.start_epoch = weights['epoch'] + 1
print('train start with epoch', self.start_epoch)
# 上一次最好的结果
self.best_metric = weights['best_acc']
# 在断之前的所有过程输出
self.train_loss_list = np.load(os.path.join(self.log_dir, 'train_loss.npy'),
allow_pickle=True).tolist()[:self.start_epoch]
self.valid_loss_list = np.load(os.path.join(self.my_tb_log_dir, 'valid_loss.npy'),
allow_pickle=True).tolist()[:self.start_epoch]
self.train_acc_list = np.load(os.path.join(self.my_tb_log_dir, 'valid_acc.npy'),
allow_pickle=True).tolist()[:self.start_epoch]
# 加载模型参数、优化器参数和lr_scheduler参数
self.model.load_state_dict(weights['state_dict']) # , strict=True
self.optimizer.load_state_dict(weights['optimizer'])
self.lr_scheduler.load_state_dict(weights['scheduler'])
可以看一下加载进来的是什么:
①optimizer.state_dict()
{'state': {}, 'param_groups': [{'lr': 0.1, 'betas': (0.5, 0.999), 'eps': 1e-08, 'weight_decay': 0.0001, 'amsgrad': False, 'maximize': False, 'foreach': None, 'capturable': False, 'params': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35]}]}
返回一个包含optimizer核心信息的字典。该字典包含两个元素,第一个是optimizer状态参数(state),第二个是optimizer相关参数簇(param_groups)。
其中,参数簇中的‘lr’,代表着下一次模型训练的时候所带入的学习率。
根据optimizer.state_dict()的数据格式,若想知道训练过程中的学习率的话,我们可以:
optimizer.state_dict()['param_groups'][0]['lr']
②lr_scheduler.state_dict()
{'milestones': [100, 300], 'gamma': 0.1, 'warmup_factor': 0.1, 'warmup_iters': 50, 'warmup_method': 'linear', 'base_lrs': [0.1], 'last_epoch': 151, '_step_count': 1, 'verbose': False, '_get_lr_called_within_step': False, '_last_lr': [0.010000000000000002]}
返回一个包含scheduler核心信息的字典。该字典包含scheduler相关参数。
其中,‘milestones’、‘gamma’、‘warmup_factor’、‘warmup_iters’、‘warmup_method’、‘linear’、‘base_lrs’: [0.1]都是最开始便设定好的,‘verbose’和’_get_lr_called_within_step’不用管。
主要是’last_epoch’、‘_step_count’、‘_last_lr’和我们的当前训练状态相关,‘last_epoch’掌管着’_last_lr’,也就是最重要的是’last_epoch’要保证能和我们的断点续上。
‘last_epoch’:上一次epoch,也就是断点epoch。
‘_step_count’:调lr_scheduler.step()的次数。
‘_last_lr’:上一次的学习率。
所以一开始定义lr_scheduler的时候,last_epoch默认是-1,也就是从头开始。
self.lr_scheduler = WarmupMultiStepLR(optimizer=optimizer,
milestones=[100, 300],
gamma=0.1,
warmup_factor=0.1,
warmup_iters=2,
warmup_method="linear",
last_epoch=-1)
举例:
‘last_epoch’: 151就是指,保存的是epoch151的状态,在epoch152的时候因为各种原因程序停止训练了。
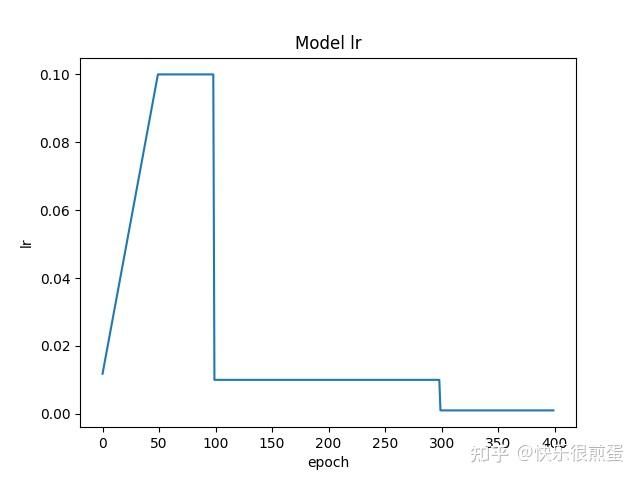
绘制学习率曲线(调整策略:预热学习率)
举例:
绘制学习率曲线,从start_epoch开始到epoch=400(不包含)截止,动态调整学习率策略选择的是“预热学习率”。
初始学习率为0.1(在optimizer内设置),epoch=50(warmup_iters)之前学习率以0.1斜率(warmup_factor)线性(warmup_method)上升到0.1(初始学习率),epoch=50(warmup_iters)到epoch=100(milestones)之间学习率都是0.1(初始学习率),epoch=100(milestones)和300时(milestones)分别降到前一个学习率的0.1倍(gamma)。
import math
import torch.optim as optim
import torch.nn as nn
from bisect import bisect_right
class WarmupLR(optim.lr_scheduler._LRScheduler):
def __init__(self, optimizer, warmup_steps, last_epoch=-1):
self.warmup_steps = warmup_steps
super().__init__(optimizer, last_epoch)
def get_lr(self):
if self.last_epoch < self.warmup_steps:
return [base_lr * (self.last_epoch + 1) / self.warmup_steps for base_lr in self.base_lrs]
else:
return [base_lr * math.exp(-(self.last_epoch - self.warmup_steps + 1) * self.gamma) for base_lr in
self.base_lrs]
class WarmupMultiStepLR(torch.optim.lr_scheduler._LRScheduler):
def __init__(
self,
optimizer,
milestones,
gamma=0.1,
warmup_factor=1/3,
warmup_iters=100,
warmup_method="linear",
last_epoch=-1,
):
if not list(milestones) == sorted(milestones):
raise ValueError(
"Milestones should be a list of" " increasing integers. Got {}",
milestones,
)
if warmup_method not in ("constant", "linear"):
raise ValueError(
"Only 'constant' or 'linear' warmup_method accepted"
"got {}".format(warmup_method)
)
self.milestones = milestones
self.gamma = gamma
self.warmup_factor = warmup_factor
self.warmup_iters = warmup_iters
self.warmup_method = warmup_method
super(WarmupMultiStepLR, self).__init__(optimizer, last_epoch)
def get_lr(self):
warmup_factor = 1
if self.last_epoch < self.warmup_iters:
if self.warmup_method == "constant":
warmup_factor = self.warmup_factor
elif self.warmup_method == "linear":
alpha = self.last_epoch / self.warmup_iters
warmup_factor = self.warmup_factor * (1 - alpha) + alpha
return [
base_lr
* warmup_factor
* self.gamma ** bisect_right(self.milestones, self.last_epoch)
for base_lr in self.base_lrs
]
if __name__ == "__main__":
import matplotlib.pyplot as plt
import numpy as np
start_epoch = 0
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.layer = nn.Linear(10, 2)
self.layer2 = nn.Linear(2, 10)
def forward(self, input):
return self.layer(input)
model = Net() # 生成网络
optimizer = optim.Adam(model.parameters(), lr=0.1) # 生成优化器
lr_scheduler = WarmupMultiStepLR(optimizer=optimizer,
milestones=[100, 300],
gamma=0.1,
warmup_factor=0.1,
warmup_iters=50,
warmup_method="linear",
last_epoch=-1)
lr_list = []
for epoch in range(start_epoch, 400):
optimizer.step()
lr_scheduler.step()
lr_list.append(float(optimizer.state_dict()['param_groups'][0]['lr']))
print('epoch', epoch, 'lr', float(optimizer.state_dict()['param_groups'][0]['lr']))
plt.plot(np.arange(start_epoch, start_epoch + len(lr_list)), lr_list, label="train lr")
plt.xlabel('epoch')
plt.ylabel("lr")
plt.title('Model lr')
plt.show()
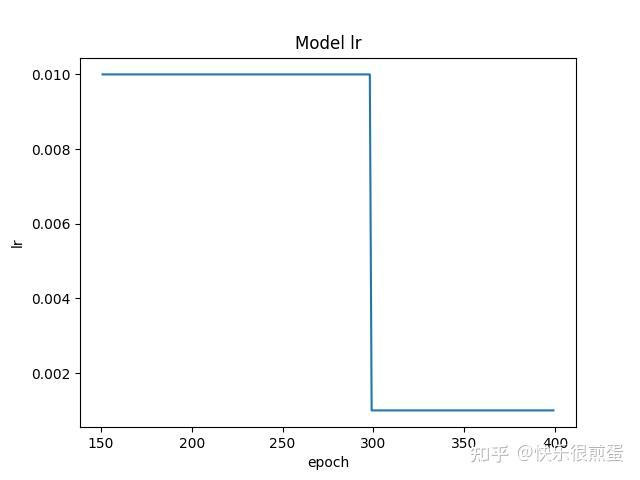
如果从epoch=151开始画:
start_epoch = 151
lr_list = []
for epoch in range(start_epoch, 400):
optimizer.step()
lr_scheduler.step()
lr_list.append(float(optimizer.state_dict()['param_groups'][0]['lr']))
print('epoch', epoch, 'lr', float(optimizer.state_dict()['param_groups'][0]['lr']))
plt.plot(np.arange(start_epoch, start_epoch + len(lr_list)), lr_list, label="train lr")
plt.xlabel('epoch')
plt.ylabel("lr")
plt.title('Model lr')
plt.show()
最后说一嘴,如果发现从断点继续训练之后损失函数和以往的数值相差特别大,那可能是几个load_state_dict()没做,以及epoch不对,还有就是model、optimizer、lr_scheduler的顺序。这里尤其需要注意lr_scheduler,按理说重新定义lr_scheduler,并让last_epoch=断点epoch也是可以继续训练的,但一定要看清lr_scheduler.step()放在了哪里,是不是在epoch下而不是batch下。
optimizer.step()
lr_scheduler.step()
lr_list.append(float(optimizer.state_dict()[‘param_groups’][0][‘lr’]))
print(‘epoch’, epoch, ‘lr’, float(optimizer.state_dict()[‘param_groups’][0][‘lr’]))
plt.plot(np.arange(start_epoch, start_epoch + len(lr_list)), lr_list, label=“train lr”)
plt.xlabel(‘epoch’)
plt.ylabel(“lr”)
plt.title(‘Model lr’)
plt.show()
[外链图片转存中...(img-CVuFkQQV-1700902633479)]
最后说一嘴,如果发现从断点继续训练之后损失函数和以往的数值相差特别大,那可能是几个load_state_dict()没做,以及epoch不对,还有就是model、optimizer、lr_scheduler的顺序。这里尤其需要注意lr_scheduler,按理说重新定义lr_scheduler,并让last_epoch=断点epoch也是可以继续训练的,但一定要看清lr_scheduler.step()放在了哪里,是不是在epoch下而不是batch下。