文章目录
- 1、STL简介
- 2、STL算法分类及常用函数
- 2.1、非变序算法
- 2.1.1 计数算法(2个)
- 2.1.2 搜索算法(7个)
- 2.1.3 比较算法(2个)
- 3、总结
============================ 【说明】 ===================================================
大家好,本专栏主要是跟学C++内容,自己学习了这位博主【 AI菌】的【C++21天养成计划】,讲的十分清晰,适合小白,希望给这位博主多点关注、收藏、点赞。
主要针对所学内容,通过自己的理解进行整理,希望大家积极交流、探讨,多给意见。后面也会给大家更新,其他一些知识。若有侵权,联系删除!共同维护网络知识权利!
=======================================================================================
写在前面
至此,我们了解了C++的基本语法,但是进一步学习C++,数据结构是必不可少的内容。 数据结构与算法决定了代码测存储方式,以及代码执行效率。
数据结构的重要性不言而喻, 关于数据结构的基本知识可以转至本人另一专栏====>【 数据结构】。同样也可以阅读博主【 AI菌】写的【 数据结构与算法】,比较通俗易懂,可以学习学习!
1、STL简介
前面几节,我们学了很多模板类,包括list、stack、queue、vector、string、set、map等等都是属于STL模板库。
同时,STL模板库也提供了很多实用的函数,这些函数通过引用头文件#include<algorithm>即可方便使用,它和之前讲的各种类的成员函数使用方法一致,有效的提升代码效率。
在程序设计过程中,我们会常用到查找、删除、搜素、计数等算法。C++中在STL模板库中已经提供这些函数,但是在使用之前必须加上头文件:
#include<algorithm>
2、STL算法分类及常用函数
STL算法模板库分为两大类:非变序与变序。对于这两种类别如何理解?下面就详细介绍两大类以及各函数的具体应用。
2.1、非变序算法
非变序算法就是不会改变容器内元素的书顺序与内容。常见的非变序算法有:
2.1.1 计数算法(2个)
| 函数名 | 解释 |
|---|---|
| count() | 在一定范围内,查找与指定值匹配的所有元素。 |
| count_if() | 在一定范围内,产值满足条件的所有元素。 |
count()和count_ if()计算给定范围内的元素数。
count():计算包含给定值的元素值。
count_ if():计算满足通过参数传递的一元谓词(可以是函数对象,也可以是lambda表达式)。
#include <iostream>
#include <map>
#include<list>
#include<functional>
#include<string>
#include<vector>
#include<algorithm>
using namespace std;
//初始vec
void Display(vector<int> vec) {
for (int i = 0; i < vec.size(); i++)
{
cout << vec[i] << " ";
}
cout << endl;
}
//偶数判断
template <typename elementType>
bool IsEven(const elementType &number) {
return ((number % 2) == 0);
}
int main计数() {
vector<int> vec;
for (int value = 0; value < 10; ++value)
vec.push_back(value);
cout << "原始的vec是:" << endl;
Display(vec);
//===============计数算法==================
//1、count
size_t nNumZero = count(vec.begin(), vec.end(), 0);
cout << "数组vec中值为0的个数:" << nNumZero << endl;
//2、count_if
size_t nNumEvenElements = count_if(vec.begin(),vec.end(),IsEven<int>);
cout << "数组vec中偶数的个数:" << nNumEvenElements << endl;
return 0;
}

2.1.2 搜索算法(7个)
| 函数名 | 解释 |
|---|---|
| search() | 在一定范围内,根据元素相等性(或指定二元谓词)搜索第一个满足条件的元素。 |
| search_n() | 在一定范围内,搜索与指定值相等或满足指定谓词的n个元素。 |
| find() | 在一定范围内,搜索与指定值相等/匹配的第一个元素。 |
| find_if() | 在一定范围内,搜索满足条件的第一个元素。 |
| find_end() | 在一定范围内,搜索最后一个满足特定条件的元素。 常用于在序列 A 中查找序列 B 最后一次出现的位置。 |
| find_first_of() | 在一定范围内,搜索指定序列中的任何一个元素第一次出现的位置;在另一重载版本中,搜索满足指定条件的第一个元素。常用于在 A 序列中查找和 B 序列中任意元素相匹配的第一个元素 |
| adjacent_find() | 在集合中搜索两个相等或满足条件的元素。常用于在指定范围内查找 2 个连续相等的元素 |
(1) search()/search_n()
如果需要查找一个序列或模式; 在这种情况下,应该使用serach()和search_n()。
1、search():用于在一个序列中查找另一个序列,比如在数组vec中查找list序列的位置。search() 函数也提供有以下 2 种语法格式:
序列 A:1,2,3,4,5,1,2,3,4,5
序列 B:1,2,3
//查找 [first1, last1) 范围内第一个 [first2, last2) 子序列
ForwardIterator search (ForwardIterator first1, ForwardIterator last1,ForwardIterator first2,
ForwardIterator last2);
//查找 [first1, last1) 范围内,和 [first2, last2) 序列满足 pred 规则的第一个子序列
ForwardIterator search (ForwardIterator first1, ForwardIterator last1, ForwardIterator first2,
ForwardIterator last2,BinaryPredicate pred);
其中,各个参数的含义分别为:
first1、last1:都为正向迭代器,其组合 [first1, last1) 用于指定查找范围(也就是上面例子中的序列 A);
first2、last2:都为正向迭代器,其组合 [first2, last2) 用于指定要查找的序列(也就是上面例子中的序列 B);
pred:用于自定义查找规则。该规则实际上是一个包含 2 个参数且返回值类型为 bool 的函数(第一个参数接收 [first1, last1) 范围内的元素,第二个参数接收 [first2, last2) 范围内的元素)。函数定义的形式可以是普通函数,也可以是函数对象。
2、search_n():和 search() 一样,search_n() 用于在指定区域内查找第一个符合要求的子序列。不同之处在于,前者查找的子序列中可包含多个不同的元素,而后者查找的只能是包含多个相同元素的子序列。用于在一个容器中查找n个相邻的指定值。search_n() 函数的语法格式如下:
序列 A:1,2,3,4,4,4,1,2,3,4,4,4
序列 B:1,2,3
序列 C:4,4,4
//在 [first, last] 中查找 count 个 val 第一次连续出现的位置
ForwardIterator search_n (ForwardIterator first, ForwardIterator last,
Size count, const T& val);
//在 [first, last] 中查找第一个序列,该序列和 count 个 val 满足 pred 匹配规则
ForwardIterator search_n ( ForwardIterator first, ForwardIterator last,
Size count, const T& val, BinaryPredicate pred );
其中,各个参数的含义分别为:
first、last:都为正向迭代器,其组合 [first, last) 用于指定查找范围(也就是上面例子中的序列 A);
count、val:指定要查找的元素个数和元素值,以上面的序列 B 为例,该序列实际上就是 3 个元素 4,其中 count 为 3,val 为 4;
pred:用于自定义查找规则。该规则实际上是一个包含 2 个参数且返回值类型为 bool 的函数(第一个参数接收[first, last) 范围内的元素,第二个参数接收 val)。函数定义的形式可以是普通函数,也可以是函数对象。
关于search()和search_n()案例如下:
#include <iostream>
#include <map>
#include<list>
#include<functional>
#include<string>
#include<vector>
#include<algorithm>
using namespace std;
template <typename T>
//初始ec
void Display2(const T& Input) {
for (auto i = Input.begin(); i != Input.end(); i++)
{
cout << *i << " ";
}
cout << endl;
}
int main() {
vector<int> vec;
for (int value = 0; value < 10; ++value)
vec.push_back(value);
vec.push_back(9);
vec.push_back(9);
cout << "原始的vec是:" << endl;
Display2(vec);
list <int> listNums;
for (int j = 4; j < 9; j++)
{
listNums.push_back(j);
}
cout << "原始的list是:" << endl;
Display2(listNums);
//===============查找算法==================
//1、search
auto isRange = search(vec.begin(), vec.end(), listNums.begin(), listNums.end());
if (isRange != vec.end())
cout << "listNums find in vec at position:" << distance(vec.begin(), isRange) << endl;
else
cout << "No Find!" << endl;
cout << "================" << endl;
//===============查找算法==================
//1、search_n
auto iFound = search_n(vec.begin(), vec.end(), 3, 9);
if (iFound != vec.end())
cout << "999 found in vec at position:" << distance(vec.begin(), iFound) << endl;
else
cout << "No Find!" << endl;
return 0;
}

(2) find()/find_if()
1、find():在相关容器中查找与值匹配的元素。 find() 函数的语法格式:
InputIterator find (InputIterator first, InputIterator last, const T& val);
其中,first 和 last 为输入迭代器,[first, last) 用于指定该函数的查找范围;val 为要查找的目标元素。
2、find_ if(): 和find() 函数相同,find_if() 函数也用于在指定区域内执行查找操作。不同的是,前者需要明确指定要查找的元素的值,而后者则允许自定义查找规则。
自定义查找规则,实际上指的是有一个形参且返回值类型为 bool 的函数。值得一提的是,该函数可以是一个普通函数(又称为一元谓词函数),比如:
bool mycomp(int i) {
return ((i%2)==1);
}
上面的 mycomp() 就是一个一元谓词函数,其可用来判断一个整数是奇数还是偶数。也可以是一个函数对象,比如:
//以函数对象的形式定义一个 find_if() 函数的查找规则
class mycomp2 {
public:
bool operator()(const int& i) {
return ((i % 2) == 1);
}
};
此函数对象的功能和 mycomp() 函数一样。确切地说,find_if() 函数会根据指定的查找规则,在指定区域内查找第一个符合该函数要求(使函数返回 true)的元素。
find_if() 函数的语法格式如下:
InputIterator find_if (InputIterator first, InputIterator last, UnaryPredicate pred);
其中,first 和 last 都为输入迭代器,其组合 [first, last) 用于指定要查找的区域;pred 用于自定义查找规则。
关于find()和find_if()案例如下:
#include <iostream>
#include <map>
#include<list>
#include<functional>
#include<string>
#include<vector>
#include<algorithm>
using namespace std;
//初始vec
void Display(vector<int> vec) {
for (int i = 0; i < vec.size(); i++)
{
cout << vec[i] << " ";
}
cout << endl;
}
//偶数判断
template <typename elementType>
bool IsEven(const elementType &number) {
return ((number % 2) == 0);
}
//===========查找1---find()/find_if()====================
int main()
{
vector<int> vec;
for (int value = 0; value < 10; ++value)
vec.push_back(value);
cout << "原始的vec是:" << endl;
Display(vec);
//===============查找算法==================
//1、find
auto isFind = find(vec.begin(), vec.end(), 5);
if (isFind != vec.end())
cout << "Find the number:" << *isFind << endl;
else
cout << "No find!" << endl;
//===============查找算法==================
//1、find_if
//查找第一个偶数元素
auto isFindEven = find_if(vec.begin(), vec.end(), IsEven<int>);
if (isFindEven != vec.end())
cout << "The first even number is " << *isFindEven << endl;
else
cout << "No Find!" << endl;
return 0;
}

(3) find_end()
find_end() 函数常用于在序列 A 中查找序列 B 最后一次出现的位置。find_end() 函数的语法格式有 2 种:
序列 A:1,2,3,4,5,1,2,3,4,5
序列 B:1,2,3
//查找序列 [first1, last1) 中最后一个子序列 [first2, last2)
ForwardIterator find_end (ForwardIterator first1, ForwardIterator last1,
ForwardIterator first2, ForwardIterator last2);
//查找序列 [first2, last2) 中,和 [first2, last2) 序列满足 pred 规则的最后一个子序列
ForwardIterator find_end (ForwardIterator first1, ForwardIterator last1,
ForwardIterator first2, ForwardIterator last2,
BinaryPredicate pred);
其中,各个参数的含义如下:
first1、last1:都为正向迭代器,其组合 [first1, last1) 用于指定查找范围(也就是上面例子中的序列 A);
first2、last2:都为正向迭代器,其组合 [first2, last2) 用于指定要查找的序列(也就是上面例子中的序列 B);
pred:用于自定义查找规则。该规则实际上是一个包含 2 个参数且返回值类型为 bool 的函数(第一个参数接收 [first1, last1) 范围内的元素,第二个参数接收 [first2, last2) 范围内的元素)。函数定义的形式可以是普通函数,也可以是函数对象。
关于find_end()案例如下:
#include <iostream>
#include <map>
#include<list>
#include<functional>
#include<string>
#include<vector>
#include<algorithm>
using namespace std;
//===========查找2---find_end()=====================
//以普通函数的形式定义一个匹配规则
bool mycomp1(int i, int j) {
return (i%j == 0);
}
//以函数对象的形式定义一个匹配规则
class mycomp2 {
public:
bool operator()(const int& i, const int& j) {
return (i%j == 0);
}
};
int main() {
vector<int> myvector{ 1,2,3,4,8,12,18,1,2,3 };
int myarr[] = { 1,2,3 };
//调用第一种语法格式
vector<int>::iterator it = find_end(myvector.begin(), myvector.end(), myarr, myarr + 3);
if (it != myvector.end()) {
cout << "最后一个{1,2,3}的起始位置为:" << it - myvector.begin() << ",*it = " << *it << endl;
}
int myarr2[] = { 2,4,6 };
//调用第二种语法格式
it = find_end(myvector.begin(), myvector.end(), myarr2, myarr2 + 3, mycomp2());
if (it != myvector.end()) {
cout << "最后一个能分别被 {2、4、6} 中的元素整除的起始位置为:" << it - myvector.begin() << ",*it = " << *it<<endl;
}
return 0;
}

上面程序中共调用了 2 次 find_end() 函数:
第一次调用了第一种语法格式的 find_end() 函数,其功能是在 myvector 容器中查找和 {1,2,3} 相等的最后一个子序列,显然最后一个 {1,2,3} 中元素 1 的位置下标为 7(myvector 容器下标从 0 开始);
第二次调用了第二种格式的 find_end() 函数,其匹配规则为 mycomp2,即在 myvector 容器中找到最后一个子序列,该序列中的元素能分别被 {2、4、6} 中的元素整除。显然,myvector 容器中 {4,8,12} 和 {8,12,18} 都符合,该函数会找到后者并返回一个指向元素 8 的迭代器。
(4) find_first_of()
find_first_of():在某些情境中,我们可能需要在 A 序列中查找和 B 序列中任意元素相匹配的第一个元素,这时就可以使用 find_first_of() 函数。find_first_of() 函数有 2 种语法格式,分别是:
//以判断两者相等作为匹配规则
InputIterator find_first_of (InputIterator first1, InputIterator last1,
ForwardIterator first2, ForwardIterator last2);
//以 pred 作为匹配规则
InputIterator find_first_of (InputIterator first1, InputIterator last1,
ForwardIterator first2, ForwardIterator last2,
BinaryPredicate pred);
其中,各个参数的含义如下:
first1、last1:都为输入迭代器,它们的组合 [first1, last1) 用于指定该函数要查找的范围;
first2、last2:都为正向迭代器,它们的组合 [first2, last2) 用于指定要进行匹配的元素所在的范围;
pred:可接收一个包含 2 个形参且返回值类型为 bool 的函数,该函数可以是普通函数(又称为二元谓词函数),也可以是函数对象。
不同语法格式的匹配规则也是不同的:
第 1 种语法格式:逐个取 [first1, last1) 范围内的元素(假设为 A),和 [first2, last2) 中的每个元素(假设为 B)做 A==B 运算,如果成立则匹配成功;
第 2 种语法格式:逐个取 [first1, last1) 范围内的元素(假设为 A),和 [first2, last2) 中的每个元素(假设为 B)一起带入 pred(A, B) 谓词函数,如果函数返回 true 则匹配成功。
关于find_first_of()案例如下:
#include <iostream> // std::cout
#include <algorithm> // std::find_first_of
#include <vector> // std::vector
using namespace std;
//===========查找4---find_first_of=====================
// 自定义二元谓词函数,作为 find_first_of() 函数的匹配规则
bool mycomp3(int c1, int c2) {
return (c2 % c1 == 0);
}
//以函数对象的形式定义一个 find_first_of() 函数的匹配规则
class mycomp4 {
public:
bool operator()(const int& c1, const int& c2) {
return (c2 % c1 == 0);
}
};
int main() {
char url[] = "abcd1dnetstl/";
char ch[] = "stl";
//调用第一种语法格式,找到 url 中和 "stl" 任一字符相同的第一个字符
char *it = find_first_of(url, url + 12, ch, ch + 4);
if (it != url + 12) {
cout << "it find in myvector at position: 【" <<distance(url, it) <<"】."<< endl;
cout << "*it = " << *it << '\n';
}
vector<int> myvector{ 5,7,3,9 };
int inter[] = { 4,6,8 };
//调用第二种语法格式,找到 myvector 容器中和 4,6,8任一元素有 c2%c1=0 关系的第一个元素,即6%3
vector<int>::iterator iter = find_first_of(myvector.begin(), myvector.end(), inter, inter + 3, mycomp4());
if (iter != myvector.end()) {
cout << "iter find in myvector at position: 【" << distance(myvector.begin(), iter) << "】." << endl;
cout << "*iter = " << *iter<<endl;
}
return 0;
}

(5) adjacent_find()
adjacent_find() 函数用于在指定范围内查找 2 个连续相等的元素。该函数的语法格式为:
//查找 2 个连续相等的元素
ForwardIterator adjacent_find (ForwardIterator first, ForwardIterator last);
//查找 2 个连续满足 pred 规则的元素
ForwardIterator adjacent_find (ForwardIterator first, ForwardIterator last,
BinaryPredicate pred);
其中,first 和 last 都为正向迭代器,其组合 [first, last] 用于指定该函数的查找范围;
pred 用于接收一个包含 2 个参数且返回值类型为 bool 的函数,以实现自定义查找规则。
关于adjacent_find()案例如下:
#include <iostream> // std::cout
#include <algorithm> // std::adjacent_find
#include <vector> // std::vector
using namespace std;
//===========查找4---adjacent_find=====================
//以创建普通函数的形式定义一个查找规则
bool mycomp5(int i, int j) {
return (i == j);
}
//以函数对象的形式定义一个查找规则
class mycomp6 {
public:
bool operator()(const int& _Left, const int& _Right) {
return (_Left == _Right);
}
};
int main() {
std::vector<int> myvector{ 5,20,5,30,30,20,10,10,20 };
//调用第一种语法格式
std::vector<int>::iterator it = adjacent_find(myvector.begin(), myvector.end());
if (it != myvector.end()) {
cout << "Position of two consecutive equal elements:【" << distance(myvector.begin(), it) << "】." << endl;
cout << "one : " << *it << '\n';
}
//===============================
//打印匹配范围
cout << "===================" << endl;
vector<int> v1(myvector.begin() + distance(myvector.begin(), it), myvector.end());
cout << " 查找范围为:" << endl;
for (int i = 0; i < v1.size(); i++)cout << v1[i] << " ";
cout << endl;
//调用第二种格式,++it 从上个找到的it位置开始,继续寻找是否有连续 2 个符合 mycomp2 规则的元素,也可以使用 mycomp1
std::vector<int>::iterator it1 = adjacent_find(++it, myvector.end(), mycomp6());
if (it1 != myvector.end()) {
cout << "Position of two consecutive equal elements in myvector :【" << distance(myvector.begin(), it1) << "】." << endl;
cout << "two : " << *it1<<endl;
}
return 0;
}

2.1.3 比较算法(2个)
(1) equal()
equal():可以用和比较字符串类似的方式来比较序列。如果两个序列的长度相同,并且对应元素都相等,equal() 算法会返回 true。有 4 个版本的 equal() 算法,其中两个用 == 运算符来比较元素,另外两个用我们提供的作为参数的函数对象来比较元素,所有指定序列的迭代器都必须至少是输入迭代器。
用 == 运算符来比较两个序列的第一个版本期望 3 个输入迭代器参数,前两个参数是第一个序列的开始和结束迭代器,第三个参数是第二个序列的开始迭代器。如果第二个序列中包含的元素少于第一个序列,结果是未定义的。
用 == 运算符的第二个版本期望 4 个参数:第一个序列的开始和结束迭代器,第二个序列的开始和结束迭代器,如果两个序列的长度不同,那么结果总是为 false。本节会演示这两个版本,但推荐使用接受 4 个参数的版本,因为它不会产生未定义的行为。
关于 equal()案例如下:
// Using the equal() algorithm
#include <iostream> // For standard streams
#include <vector> // For vector container
#include <algorithm> // For equal() algorithm
#include <iterator> // For stream iterators
#include <string> // For string class
using std::string;
int main()
{
std::vector<string> words1 {"one", "two", "three", "four", "five", "six", "seven", "eight", "nine"};
std::vector<string> words2 {"two", "three", "four", "five", "six", "seven", "eight", "nine", "ten"};
auto iter1 = std::begin(words1);
auto end_iter1 = std::end(words1);
auto iter2 = std::begin(words2);
auto end_iter2 = std::end(words2);
std::cout << "Container - words1:";
std::copy(iter1, end_iter1, std::ostream_iterator<string>{std::cout, " "});
std::cout << "\nContainer - words2:";
std::copy(iter2, end_iter2, std::ostream_iterator<string>{std::cout, " "});
std::cout << std::endl;
std::cout << "\n1. Compare from words1[1] to end with words2:";
std::cout << std::boolalpha << std::equal(iter1 + 1, end_iter1, iter2) << std::endl;
std::cout << "2. Compare from words2[0] to second-to-last with words1:";
std::cout << std::boolalpha << std::equal(iter2, end_iter2 - 1, iter1) << std::endl;
std::cout << "3. Compare from words1[1] to words1[5] with words2:";
std::cout << std::boolalpha << std::equal(iter1 + 1, iter1 + 6, iter2) << std::endl;
std::cout << "4. Compare first 6 from words1 with first 6 in words2:";
std::cout << std::boolalpha << std::equal(iter1, iter1 + 6, iter2, iter2 + 6) << std::endl;
std::cout << "5. Compare all words1 with words2:";
std::cout << std::boolalpha << std::equal(iter1, end_iter1, iter2) << std::endl;
std::cout << "6. Compare all of words1 with all of words2:";
std::cout << std::boolalpha << std::equal(iter1, end_iter1, iter2, end_iter2) << std::endl;
std::cout << "7. Compare from words1[1] to end with words2 from first to second-to-last:";
std::cout << std::boolalpha << std::equal(iter1 + 1, end_iter1, iter2, end_iter2 - 1) << std::endl;
}

在这个案例中,对来自于 words1 和 words2 容器的元素的不同序列进行了比较。equal() 调用产生这些输出的原因如下:
第 1 条语句的输出为 true,因为 words1 的第二个元素到最后一个元素都从 words2 的第一个元素开始匹配。第二个序列的元素个数比第一个序列的元素个数多 1,但 第一个序列的元素个数决定了比较多少个对应的元素。
第 2 条语句的输出为 false,因为有直接的不匹配;words2 和 words1 的第一个元素不同。
第 3 条语句的输出为 true,因为 word1 中从第二个元素开始的 5 个元素和 words2 的前五个元素相等。
在第 4 条语句中,words2 的元素序列是由开始和结束迭代器指定的。序列长度相同,但它们的第一个元素不同,所以结果为 false。
在第 5 条语句中,两个序列的第一个元素直接就不匹配,所以结果为 false。
第 6 条语句的输出为 false,因为序列是不同的。这条语句不同于前面的 equal() 调用,因为指定了第二个序列的结束迭代器。
第 7 条语句会从 words1 的第二个元素开始,与 word2 从第一个元素开始比较相同个数的元素,所以输出为 true。
当用 equal() 从开始迭代器开始比较两个序列时,第二个序列用来和第一个序列比较的元素个数由第一个序列的长度决定。就算第二个序列比第一个序列的元素多,equal() 仍然会返回 true。如果为两个序列提供了开始和结束迭代器,为了使结果为 true,序列必须是相同的长度。
(2) mismatch()
equal() 可以告诉我们两个序列是否匹配。mismatch() 也可以告诉我们两个序列是否匹配,而且如果不匹配,它还能告诉我们不匹配的位置。
mismatch() 的 4 个版本和 equal() 一样有相同的参数——第二个序列有或没有结束迭代器,有或没有定义比较的额外的函数对象参数。mismatch() 返回的 pair 对象包含两个迭代器。它的 first 成员是一个来自前两个参数所指定序列的迭代器,second 是来自于第二个序列的迭代器。当序列不匹配时,pair 包含的迭代器指向第一对不匹配的元素;因此这个 pair 对象为 pair<iter1+n,iter2 + n>,这两个序列中索引为 n 的元素是第一个不匹配的元素。
当序列匹配时,pair 的成员取决于使用的 mismatch() 的版本和具体情况。iter1 和 end_iter1 表示定义第一个序列的迭代器,iter2 和 end_iter2 表示第二个序列的开始和结束迭代器。返回的匹配序列的 pair 的内容如下:
(1) 对于 mismatch(iter1,end_iter1,iter2):
返回 pair<end_iter1,(iter2 + (end_ter1 - iter1))>,pair 的成员 second 等于 iter2 加上第一个序列的长度。如果第二个序列比第一个序列短,结果是未定义的。
(2) 对于 mismatch(iterl, end_iter1, iter2, end_iter2):
当第一个序列比第二个序列长时,返回 pair<end_iter1, (iter2 + (end_iter1 - iter1))>,所以成员 second 为 iter2 加上第一个序列的长度。
当第二个序列比第一个序列长时,返回 pair<(iter1 + (end_iter2 - iter2)),end_iter2>, 所以成员 first 等于 iter1 加上第二个序列的长度。
当序列的长度相等时,返回 pair<end_iter1, end_iter2>。
不管是否添加一个用于比较的函数对象作为参数,上面的情况都同样适用。
关于 mismatch()案例如下:
// Using the equal() algorithm
#include <iostream> // For standard streams
#include <vector> // For vector container
#include <algorithm> // For equal() algorithm
#include <iterator> // For stream iterators
#include <string> // For string class
using std::string;
int mainequal()
{
std::vector<string> words1{ "one", "two", "three", "four", "five", "six", "seven", "eight", "nine" };
std::vector<string> words2{ "two", "three", "four", "five", "six", "seven", "eight", "nine", "ten" };
auto iter1 = std::begin(words1);
auto end_iter1 = std::end(words1);
auto iter2 = std::begin(words2);
auto end_iter2 = std::end(words2);
std::cout << "Container - words1:";
std::copy(iter1, end_iter1, std::ostream_iterator<string>{std::cout, " "});
std::cout << "\nContainer - words2:";
std::copy(iter2, end_iter2, std::ostream_iterator<string>{std::cout, " "});
std::cout << std::endl;
std::cout << "\n1. Compare from words1[1] to end with words2:";
std::cout << std::boolalpha << std::equal(iter1 + 1, end_iter1, iter2) << std::endl;
std::cout << "2. Compare from words2[0] to second-to-last with words1:";
std::cout << std::boolalpha << std::equal(iter2, end_iter2 - 1, iter1) << std::endl;
std::cout << "3. Compare from words1[1] to words1[5] with words2:";
std::cout << std::boolalpha << std::equal(iter1 + 1, iter1 + 6, iter2) << std::endl;
std::cout << "4. Compare first 6 from words1 with first 6 in words2:";
std::cout << std::boolalpha << std::equal(iter1, iter1 + 6, iter2, iter2 + 6) << std::endl;
std::cout << "5. Compare all words1 with words2:";
std::cout << std::boolalpha << std::equal(iter1, end_iter1, iter2) << std::endl;
std::cout << "6. Compare all of words1 with all of words2:";
std::cout << std::boolalpha << std::equal(iter1, end_iter1, iter2, end_iter2) << std::endl;
std::cout << "7. Compare from words1[1] to end with words2 from first to second-to-last:";
std::cout << std::boolalpha << std::equal(iter1 + 1, end_iter1, iter2, end_iter2 - 1) << std::endl;
return 0;
}
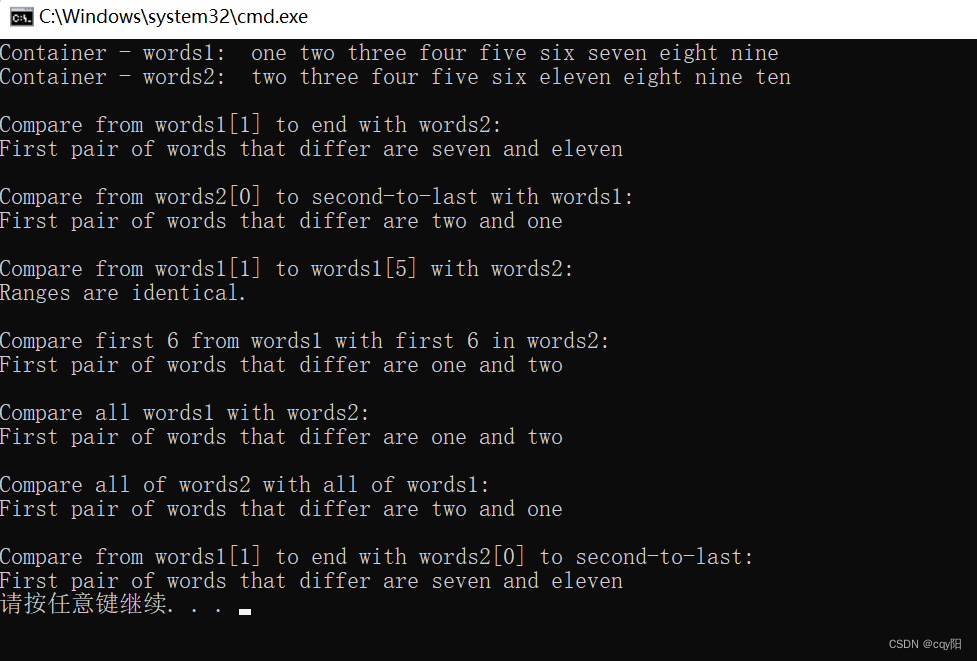
注意 words2 中的内容和前面示例中的有些不同。每一次应用 mismatch() 的结果都是由定义为 print_match 的 lambda 表达式生成的。它的参数是一个 pair 对象和一个 vector 容器的迭代器。使用 using 指令生成 word_iter 别名可以使 lambda 表达式的定义更简单。
在 main() 的代码中使用了不同版本的 mismatch(),它们都没有包含比较函数对象的参数。如果第二个序列只用开始迭代器指定,为了和第一个序列匹配,它只需要有和第一个序列相等长度的元素,但也可以更长。如果第二个序列是完全指定的,会由最短的序列来确定比较多少个元素。
3、总结
最后,长话短说,大家看完就好好动手实践一下,切记不能三分钟热度、三天打鱼,两天晒网。大家也可以自己尝试写写博客,来记录大家平时学习的进度,可以和网上众多学者一起交流、探讨,我也会及时更新,来督促自己学习进度。一开始提及的博主【AI菌】,个人已关注,并订阅了相关专栏(对我有帮助的),希望大家觉得不错的可以点赞、关注、收藏。

![[附源码]java毕业设计咖啡销售管理系统-](https://img-blog.csdnimg.cn/8a415ff63ffb4f6cb33997f86a72fe4d.png)



![[R]第二节 练习一关于数值向量](https://img-blog.csdnimg.cn/img_convert/45df159894ce91e4d676bf728793d9d9.png)