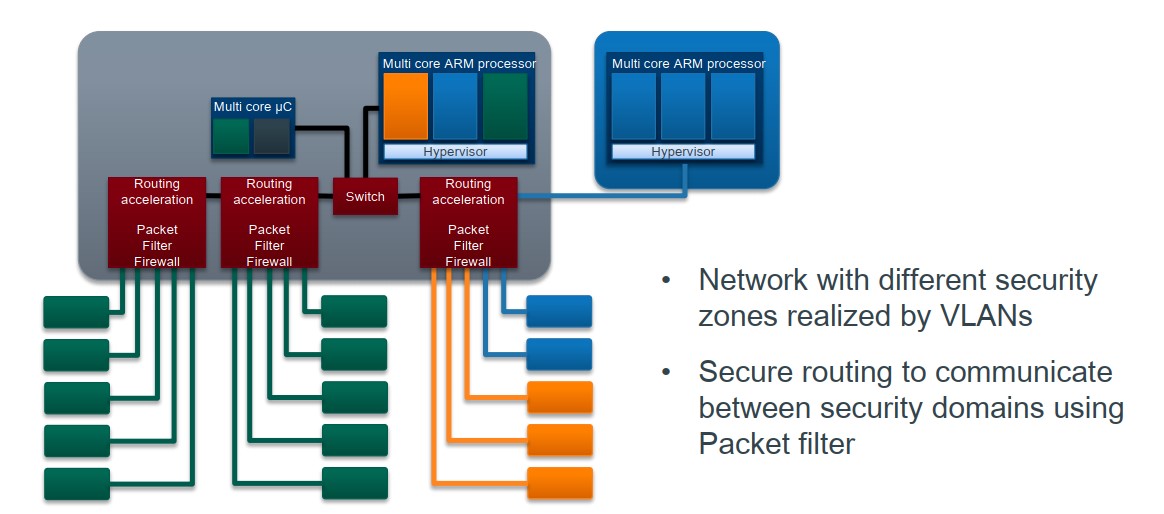
本文通过整理李宏毅老师的机器学习教程的内容,介绍 RNN(recurrent neural network)的网络结构。
RNN 网络结构, 李宏毅
RNN
RNN 的特点在于存储功能,即可以记忆前面时刻的信息。
最简单的 RNN 结构如下:

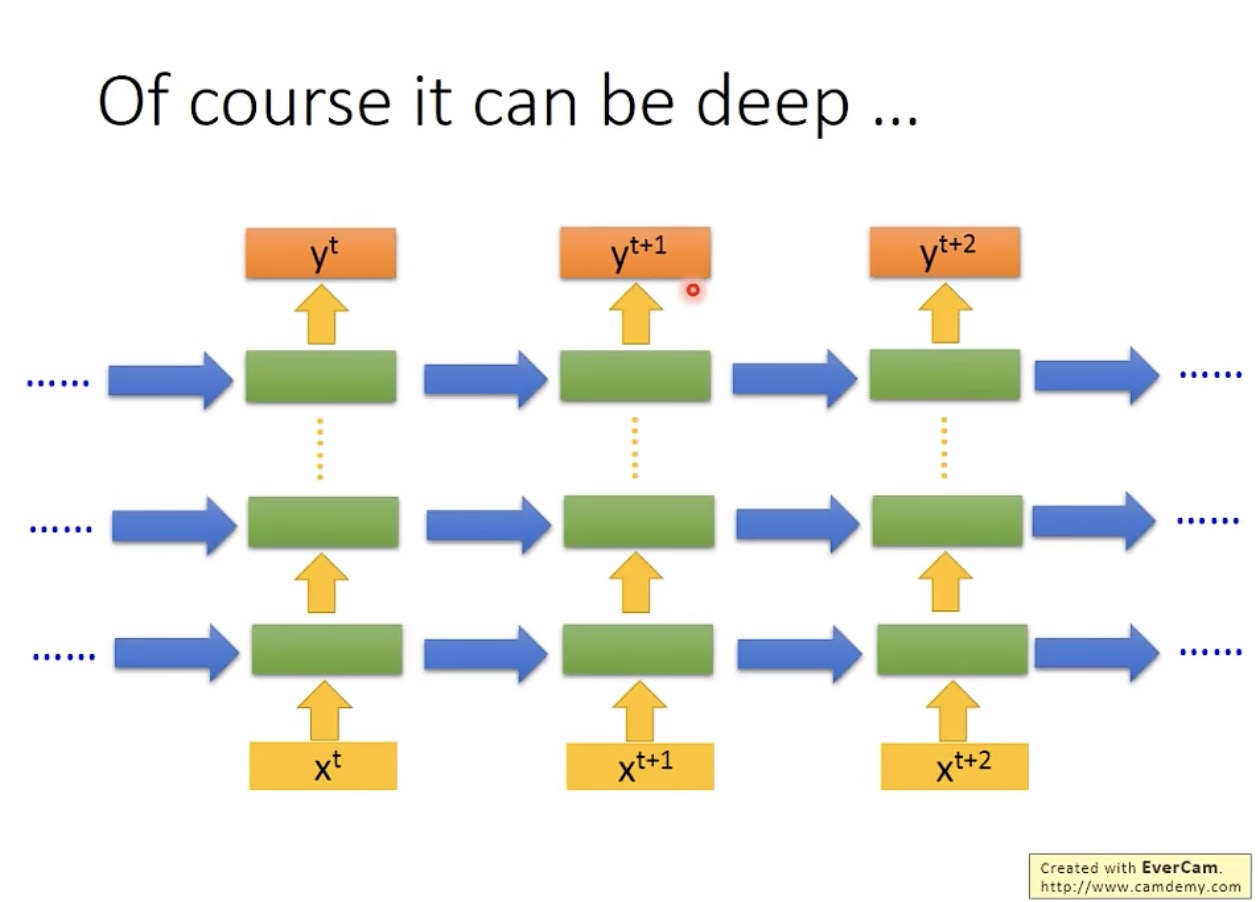
当然,网络结构可以很深,多少层都可以:
如果存储的是隐藏层(hidden layer)的值,则称为 Elman Network;
如果存储的是输出值,则称为 Jordan Network:
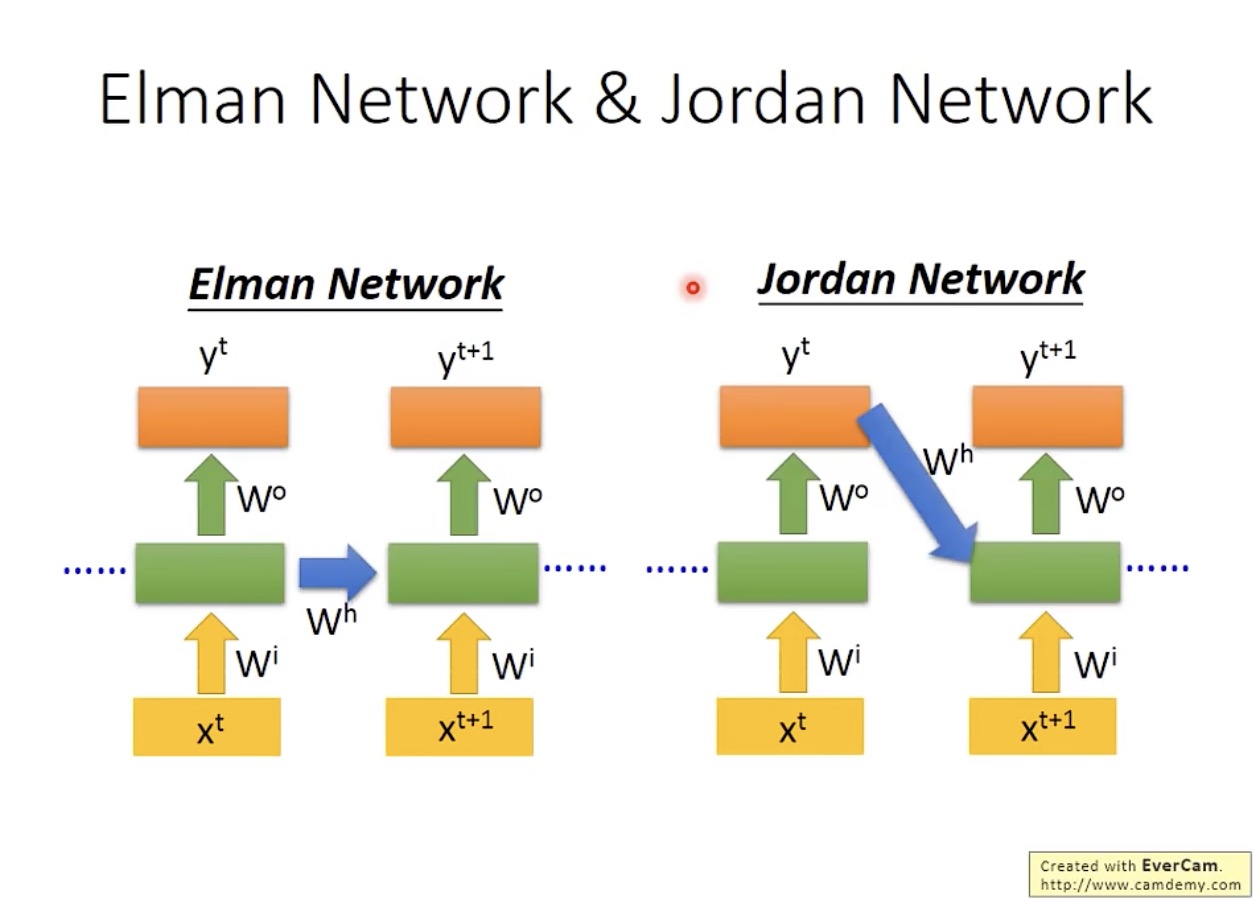
据说 Jordan Network 的表现更好,因为所存储的是输出值,其中包含了优化目标的信息。
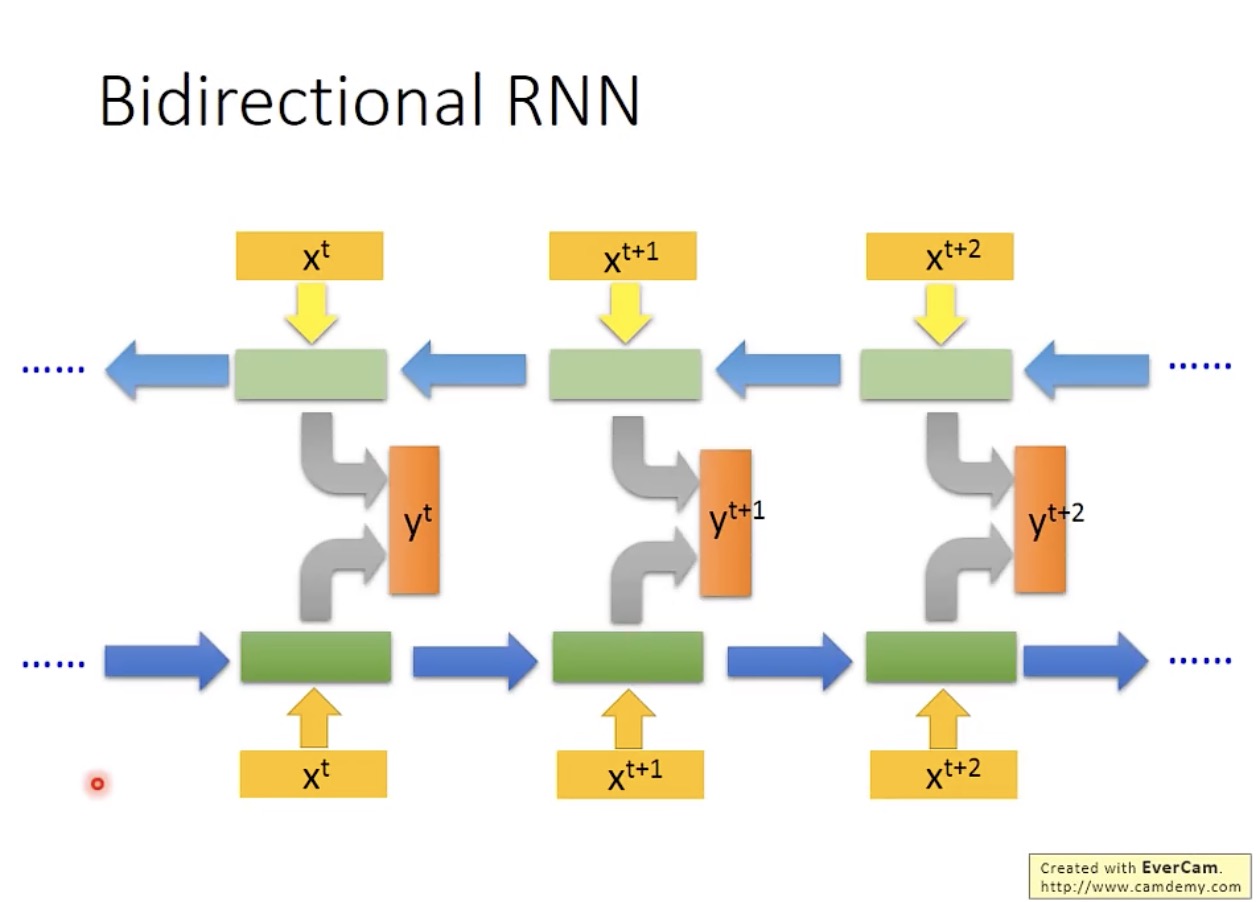
RNN 可以是双向的:
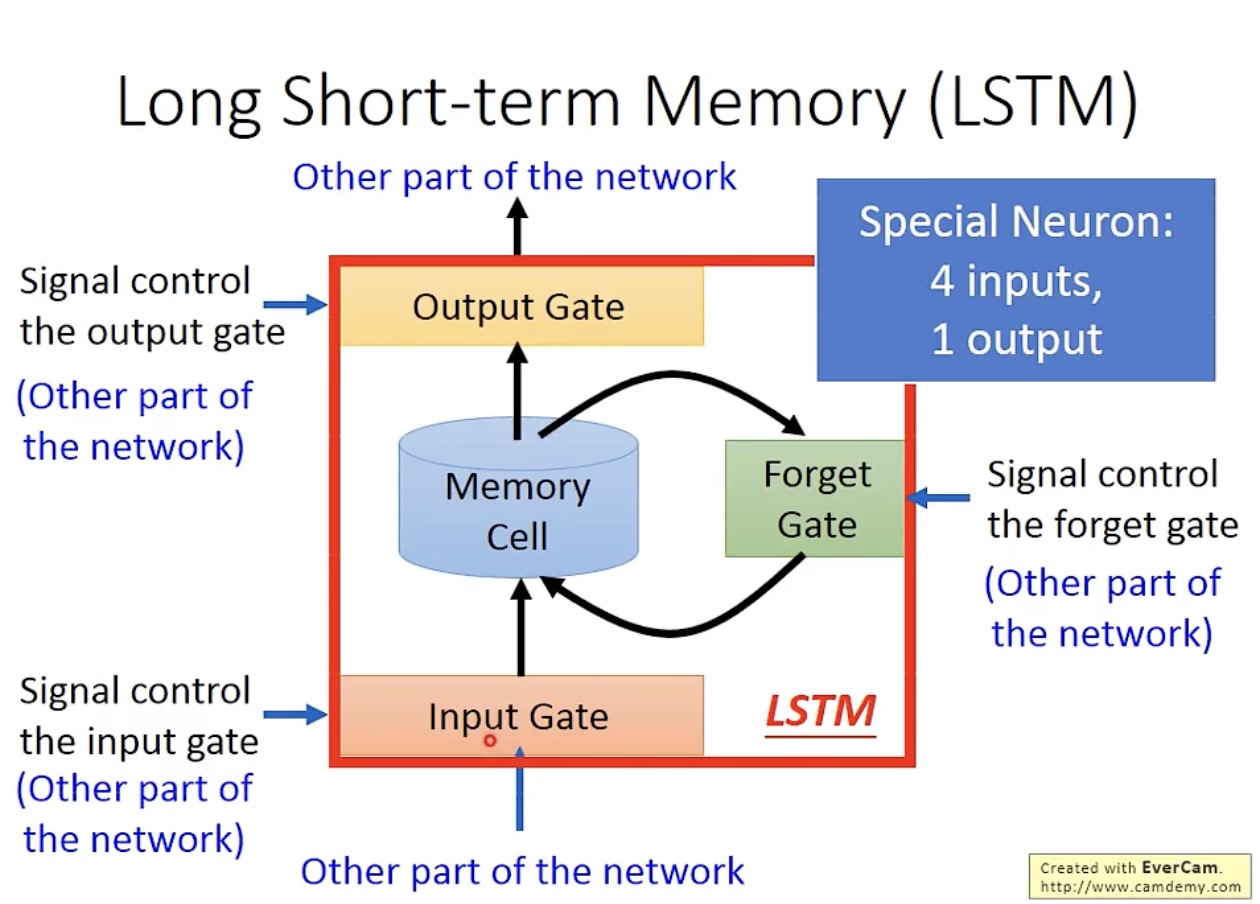
LSTM(Long Short-Term Memory)
LSTM 单元的结构简图如下:
其内部的具体结构如下:

需要注意的是,遗忘门(forget gate)这个称呼与我们的直觉相反,即打开时数据保留,关闭时数据清除。
将上述 LSTM 单元视为神经网络中的神经元,即可构成网络结构,其输入数量是普通神经元的 4 倍:
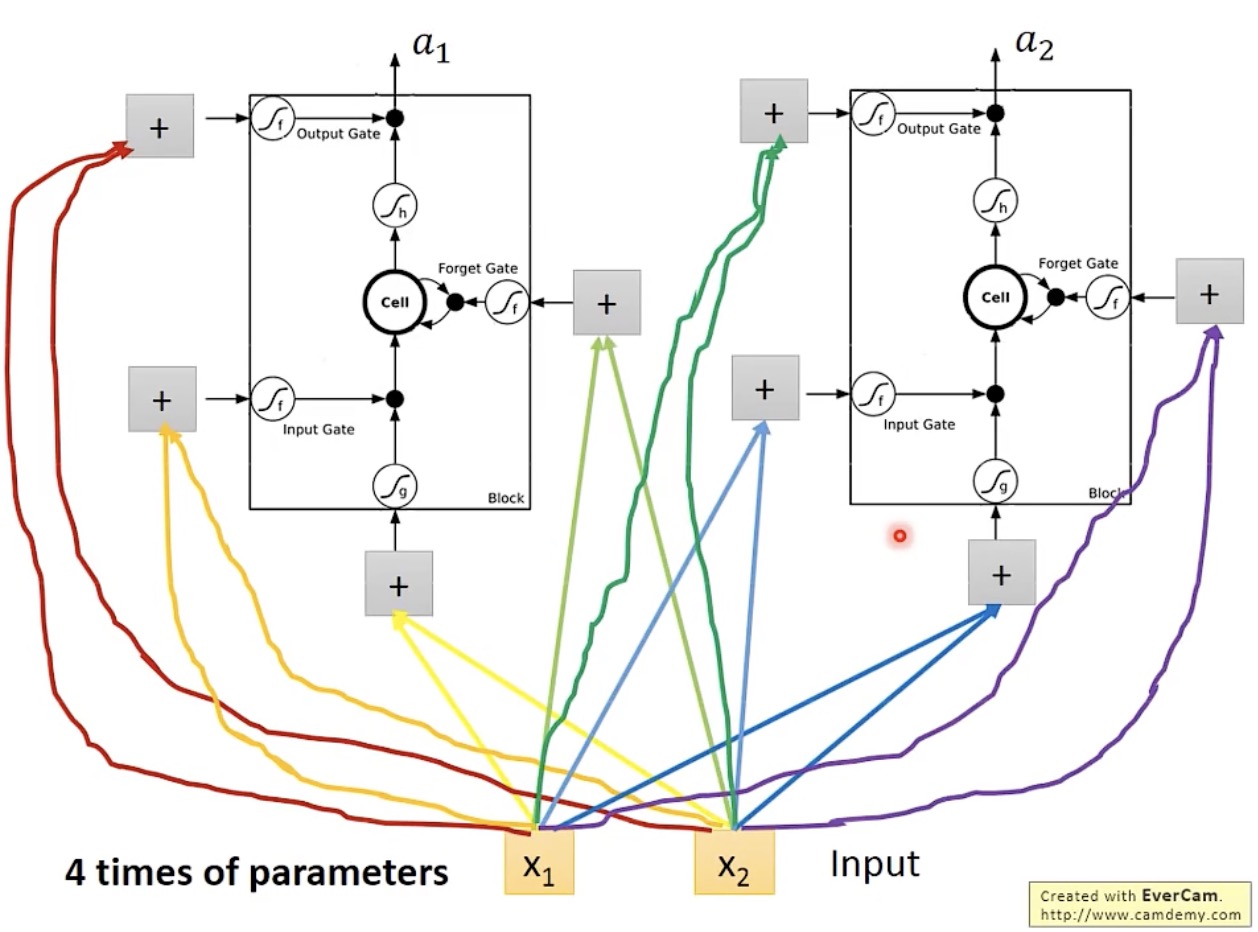
在实际计算过程中,输入数据在进入三个门之前会分别乘三个矩阵:
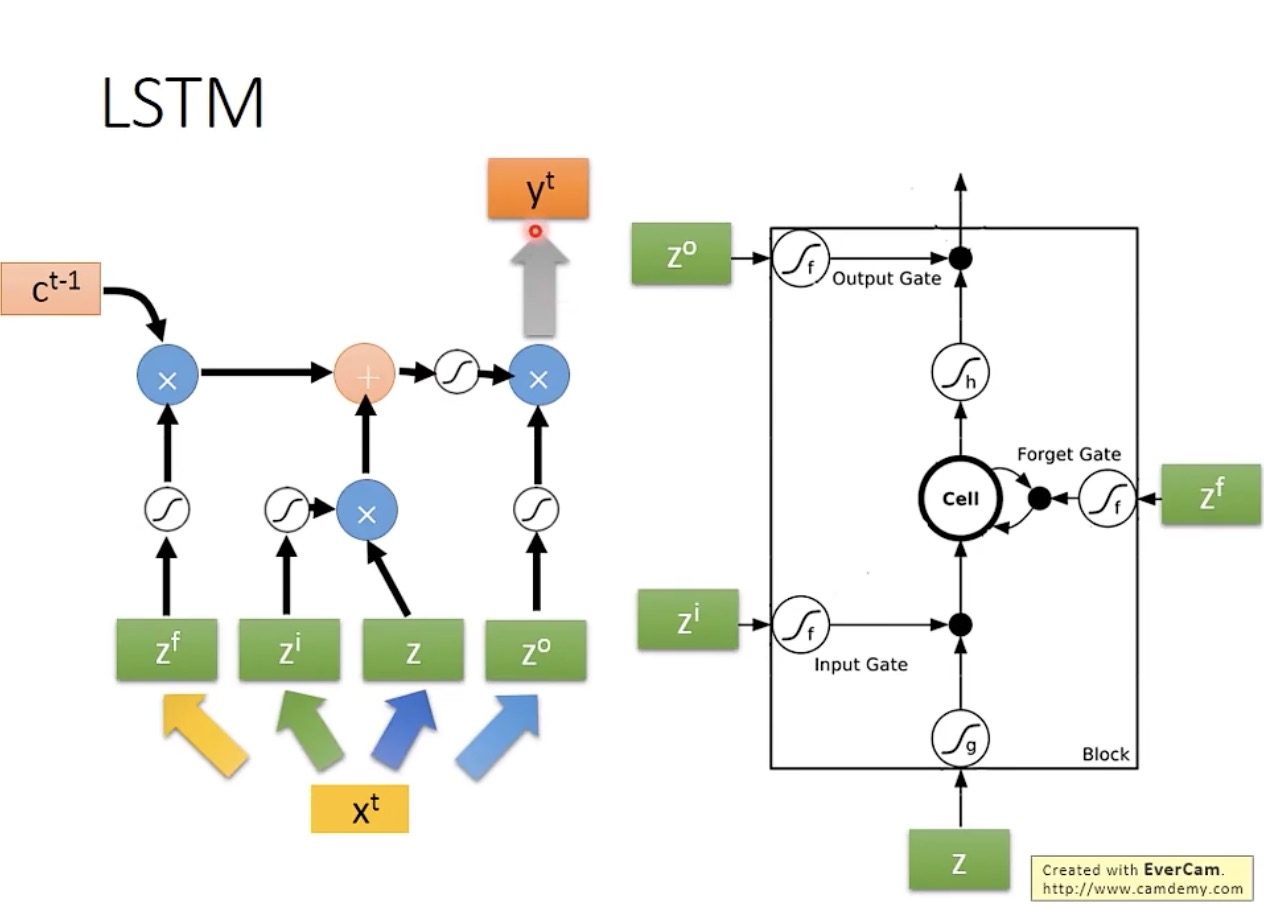
下图为前后两个时刻的输入数据之间的关系,可以看出,实际的 LSTM 输入数据还要加上前一时刻的隐藏层(hidden layer)的输出
h
t
h^t
ht,以及前一时刻的存储数据
c
t
c^t
ct(该操作称为 peephole):
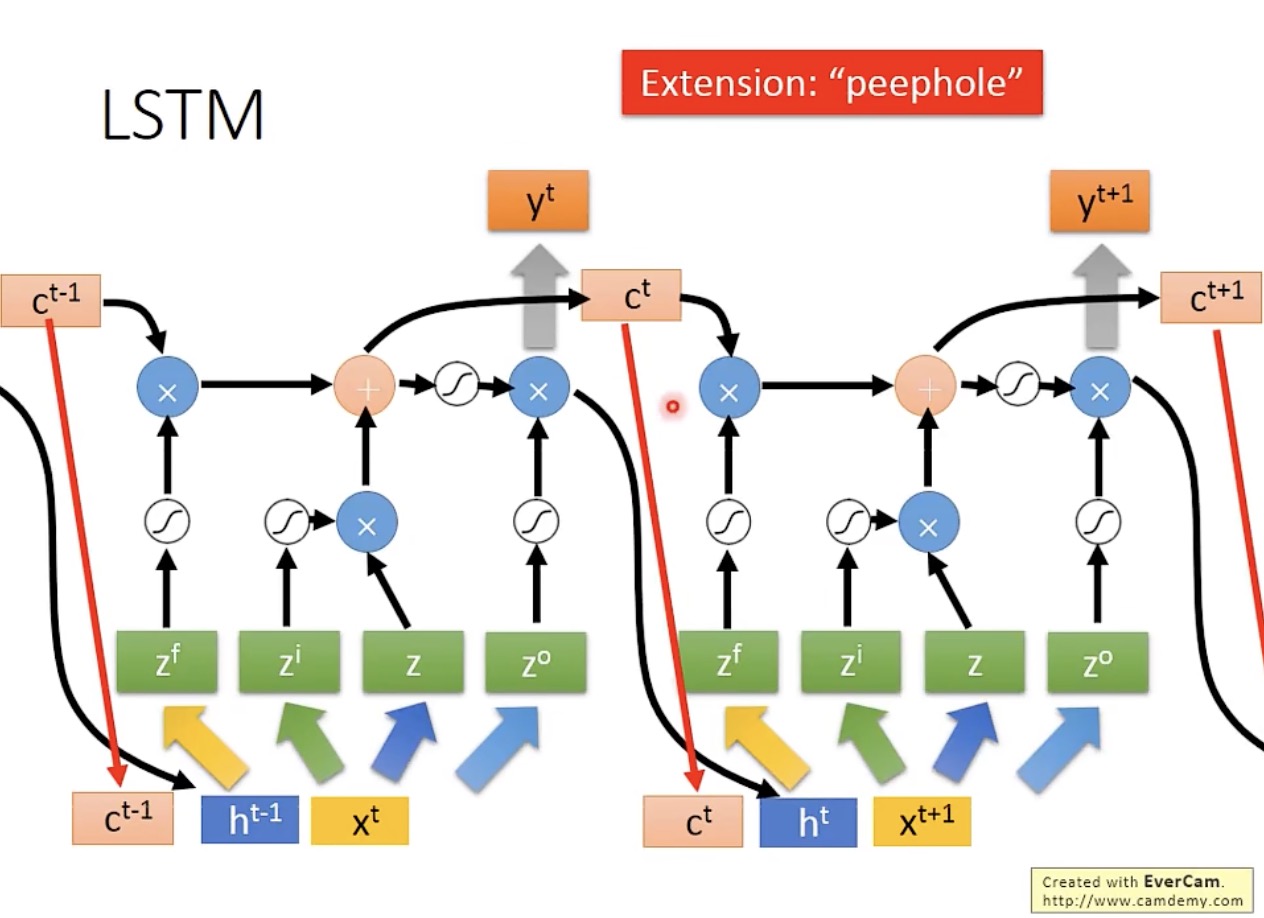
LSTM 不会只有一层,现在通常都会有至少五六层,其层级之间的连接结构如下:
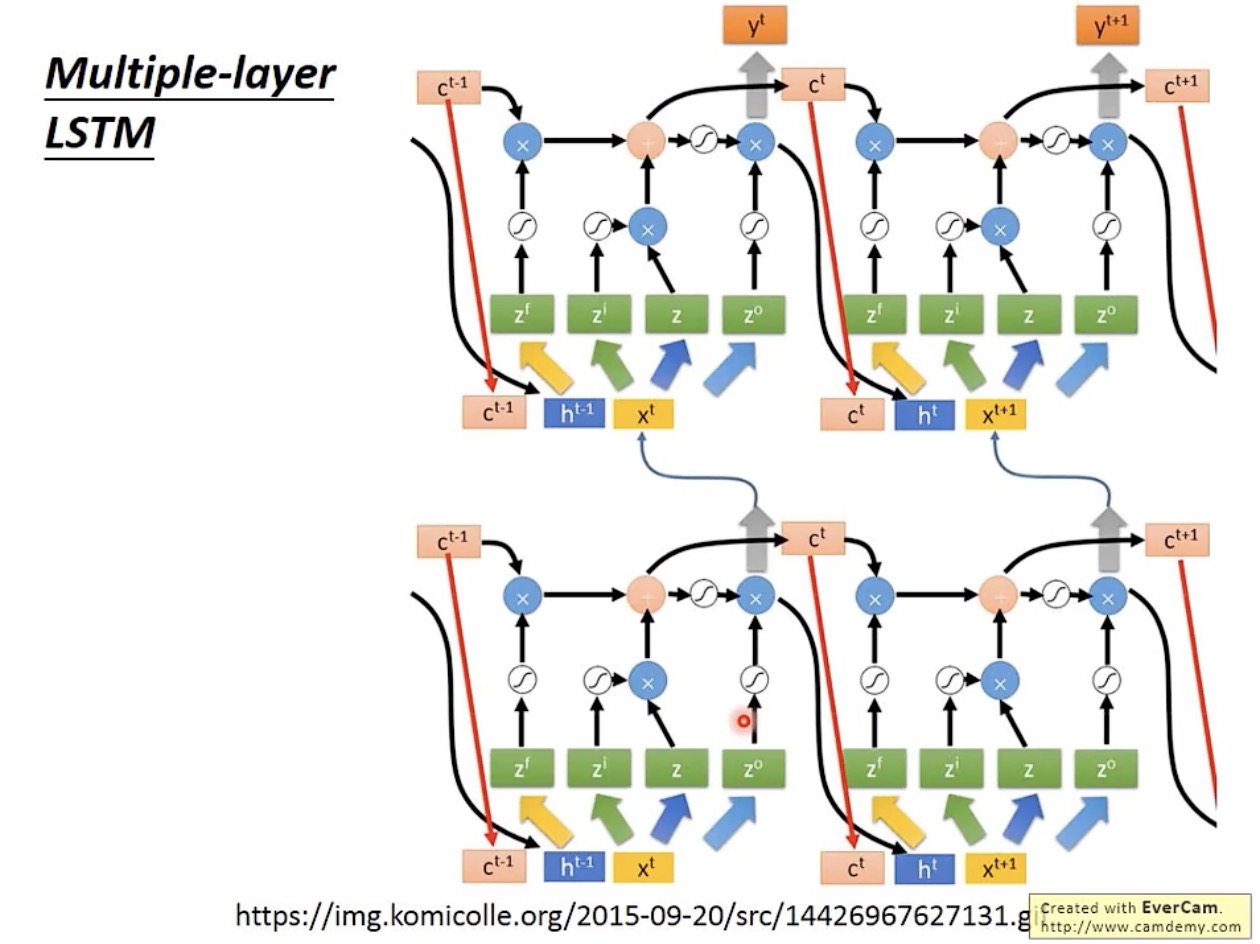
现在通常讲的 RNN 都是 LSTM。
Keras 框架支持三种 RNN:
- LSTM
- GRU:少了一个门的 LSTM,会把输入门(input gate)和遗忘门(forget gate)联动起来,其中一个打开,则另一个关闭,这样相当于减少了三分之一的参数,但据说表现跟 LSTM 差不多
- SimpleRNN:前一节介绍的最基本的 RNN
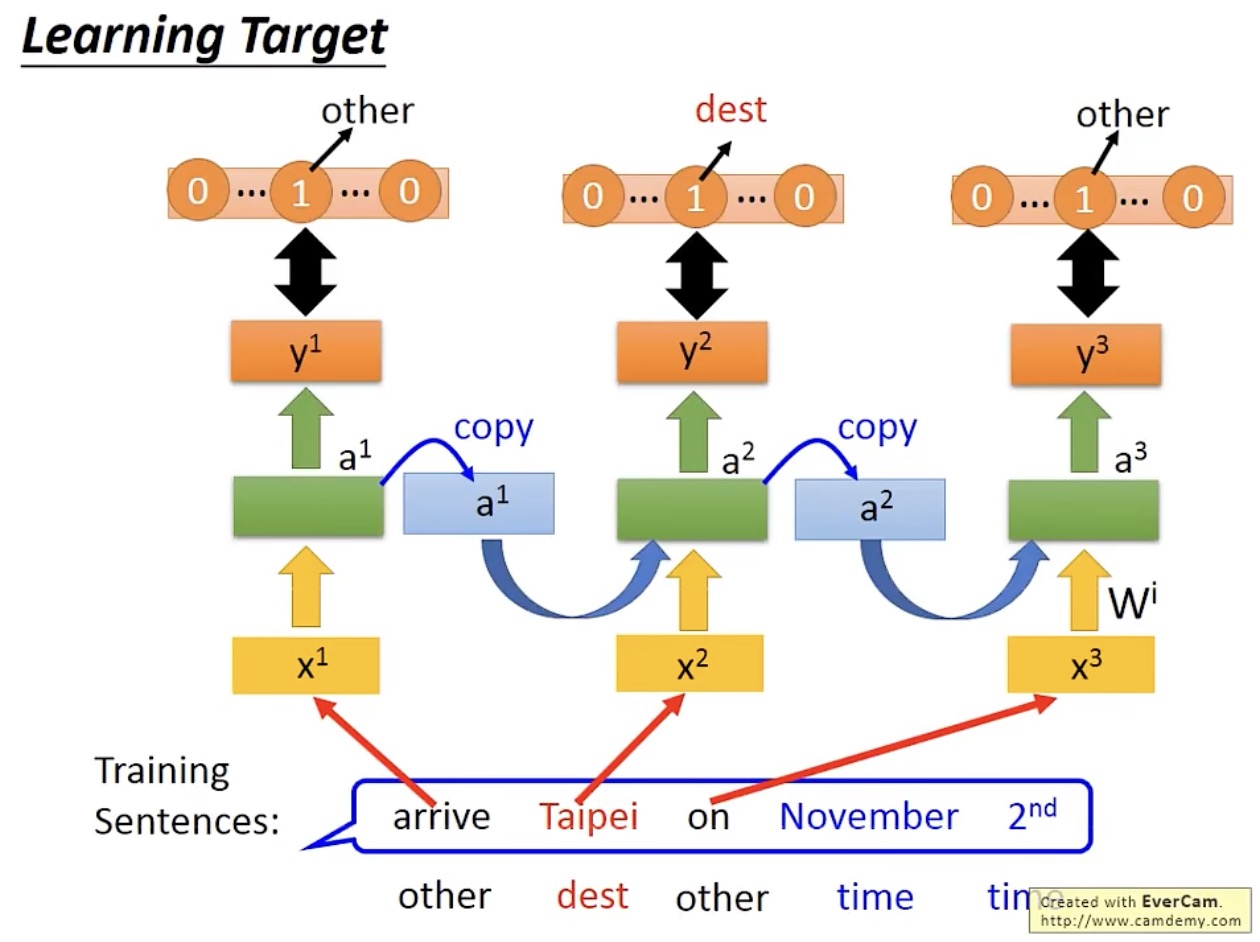
训练过程
以句法分析为例,优化目标为最小化交叉熵(cross entropy):
训练过程中,更新参数的方法叫 BPTT(backpropagation through time),即考虑时间信息的反向传播法。
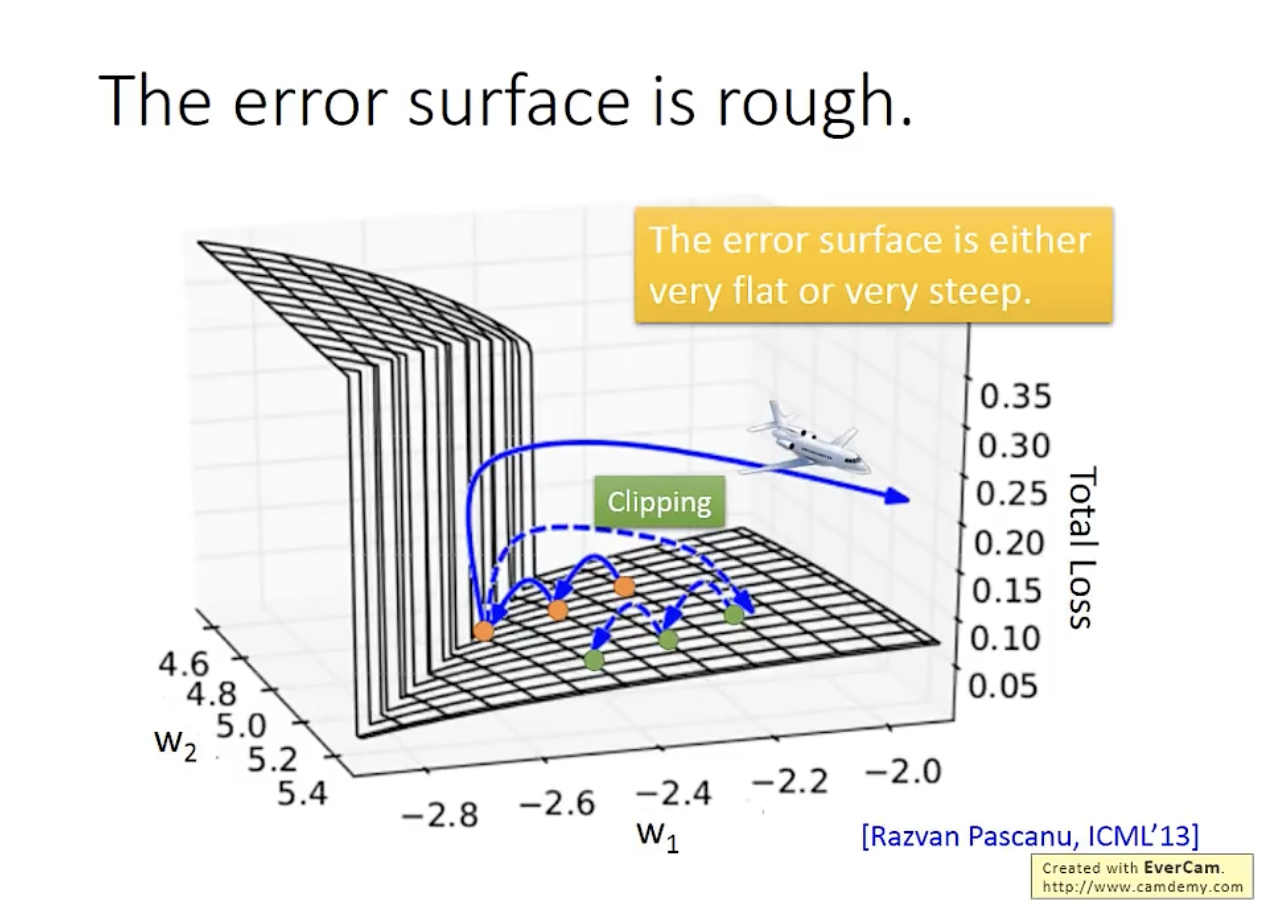
此外,在训练过程中,RNN 的 total loss 容易出现很大的波动:

这是因为,RNN 的 error surface 会有比较陡峭的地方,解决该问题的技巧是对梯度(gradient)做裁剪(clipping):
前述波动的来源并不是 sigmoid 函数,因为如果换成 ReLU 函数也会很差,所以激活函数并不是这里的关键点。
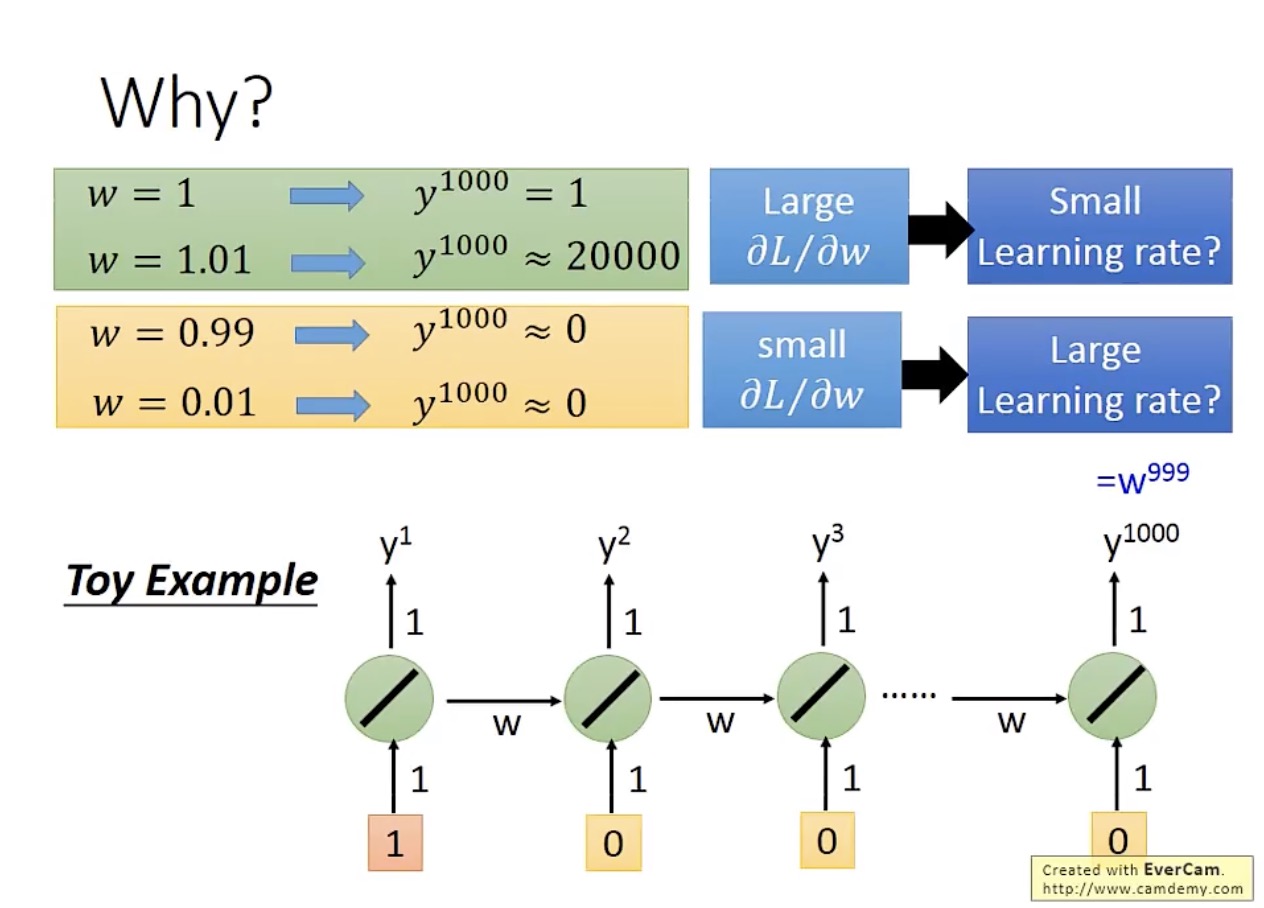
从一个最简单的例子可以看出,问题出在权重参数的变化会在后续时刻被不断放大,即便在学习率(learning rate)很小时也是一样:
然而,LSTM 可以解决梯度消失(gradient vanishing)的问题,也就是 error surface 很平坦的问题,因此可以把学习率设置得比较小,但是并不能解决 error surface 很崎岖的问题(gradient explode):
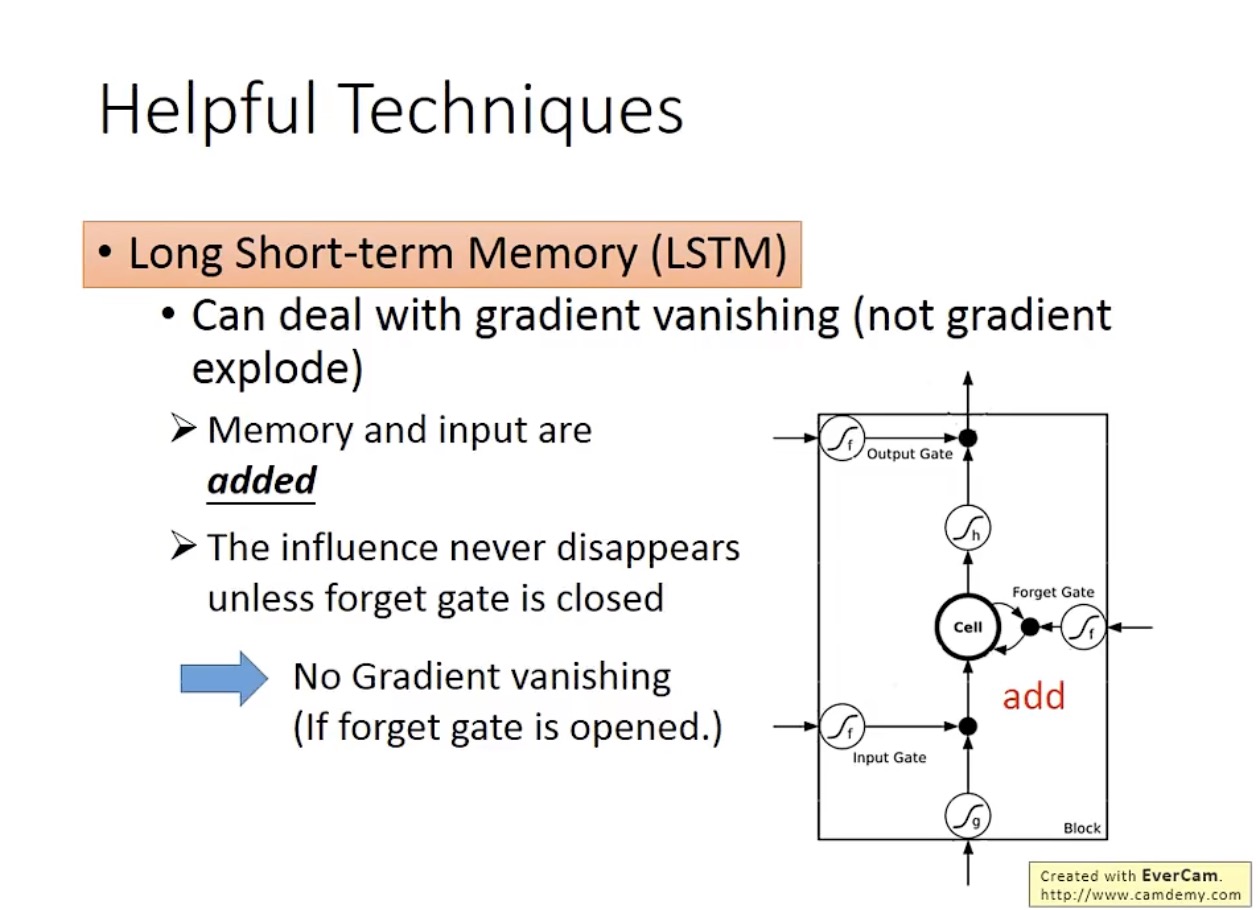
LSTM 能够解决梯度消失问题的原因,是存储数据不会被随时清除,因此也需要保证遗忘门在多数时间是开启的。
另外两种解决梯度消失问题的方法是 Clockwise RNN 和 SCRN:
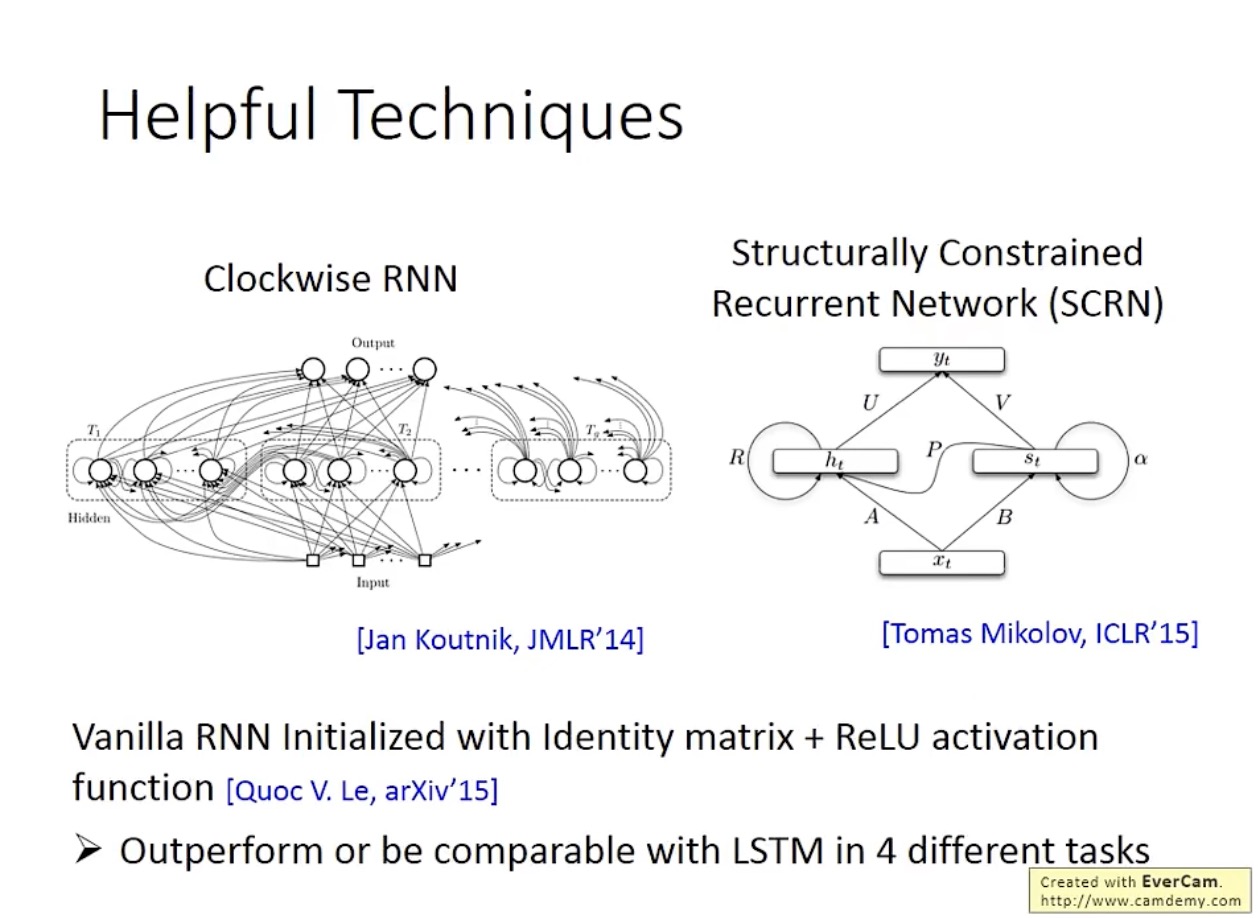
值得一提的是,一篇 Hinton 推荐的论文提到,当使用单位矩阵(identity matrix)初始化参数、并使用 ReLU 函数作为激活函数时,普通 RNN 的表现效果会很好,甚至超过 LSTM。但是如果是通常的训练方式,即使用随机矩阵初始化参数,ReLU 函数的表现效果就不如 sigmoid 函数。