论文地址:官方论文地址
代码地址:官方代码地址

一、本文介绍
本文给大家带来的改进机制是Focused Linear Attention(聚焦线性注意力)是一种用于视觉Transformer模型的注意力机制(但是其也可以用在我们的YOLO系列当中从而提高检测精度),旨在提高效率和表现力。其解决了两个在传统线性注意力方法中存在的问题:聚焦能力和特征多样性。这种方法通过一个高效的映射函数和秩恢复模块来提高计算效率和性能,使其在处理视觉任务时更加高效和有效。简言之,Focused Linear Attention是对传统线性注意力方法的一种重要改进,提高了模型的聚焦能力和特征表达的多样性。通过本文你能够了解到:Focused Linear Attention的基本原理和框架,能够在你自己的网络结构中进行添加(需要注意的是一个FLAGFLOPs从8.9涨到了9.1)。
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备
实验效果对比:放在了第三章,有对比试验供大家参考
目录
一、本文介绍
二、Focused Linear Attention的机制原理
2.1 Softmax和线性注意力机制的对比
2.2 Focused Linear Attention的提出
2.3 效果对比
三、实验效果对比
四、FocusedLinearAttention代码
五、添加Focused Linear Attention到模型中
5.1 Focused Linear Attention的添加教程
5.2 Focused Linear Attention的yaml文件和训练截图
5.2.1 Focused Linear Attention的yaml文件
5.2.2 Focused Linear Attention的训练过程截图
六、全文总结
二、Focused Linear Attention的机制原理
2.1 Softmax和线性注意力机制的对比

上面的图片是关于比较Softmax注意力和线性注意力的差异。在这张图中,Q、K、V 分别代表查询、键和值矩阵,它们的维度为 R N×d。这里提到的几个关键点包括:
1. Softmax注意力:它需要计算查询和键之间的成对相似度,导致计算复杂度为 O(N^2 d)。这种方法在计算上是昂贵的,特别是当处理大规模数据时。
2. 线性注意力:通过适当的近似手段,线性注意力可以解耦Softmax操作,并通过先计算来改变计算顺序,从而将复杂度降低到 O(
)。由于在现代视觉Transformer设计中通道维度 d 通常小于标记数 N(例如,在DeiT中d=64, N=196,在Swin Transformer中d=32, N=49),线性注意力模块实际上降低了总体计算成本。
此处提出了线性注意力机制的优势(为了后面提出论文提到的注意力机制在线性注意力机制上的优化):线性注意力模块因此能够在节省计算成本的同时,享受更大的接收域和更高的吞吐量的好处。
总结:这张图片可能是在说明线性注意力如何在保持注意力机制核心功能的同时,提高计算效率,尤其是在处理大规模数据集时的优势。这种方法对于改善视觉Transformer的性能和效率具有重要意义(我下面会出将其用在RT-DETR的模型上看看效果)。
2.2 Focused Linear Attention的提出
线性注意力的限制和改进: 尽管线性注意力降低了复杂度,但现有的线性注意力方法仍存在性能下降的问题,并可能因映射函数带来额外的计算开销。为了解决这些问题,作者提出了一个新颖的聚焦线性注意力(Focused Linear Attention)模块。该模块通过简单的映射函数调整查询和键的特征方向,使注意力权重更加明显。此外,还通过深度卷积(DWC)应用于原始注意力矩阵的秩恢复模块来增加特征多样性。
Focused Linear Attention(聚焦线性注意力)是一种用于视觉Transformer模型的注意力机制(但是其也可以用在我们的YOLO系列当中从而提高检测精度),旨在提高效率和表现力。它解决了传统线性注意力方法的两个主要问题:
1. 聚焦能力: 以往的线性注意力缺乏足够的聚焦能力,导致模型难以有效地关注重要特征。Focused Linear Attention通过改进的机制增强了这种聚焦能力。
2. 特征多样性: 传统方法在特征表达上缺乏多样性,影响了模型的表现力。Focused Linear Attention通过特殊的设计来增加特征的多样性和丰富性。
这种方法通过一个高效的映射函数和秩恢复模块来提高计算效率和性能,使其在处理视觉任务时更加高效和有效。
总结:Focused Linear Attention是对传统线性注意力方法的一种重要改进,提高了模型的聚焦能力和特征表达的多样性。
2.3 效果对比
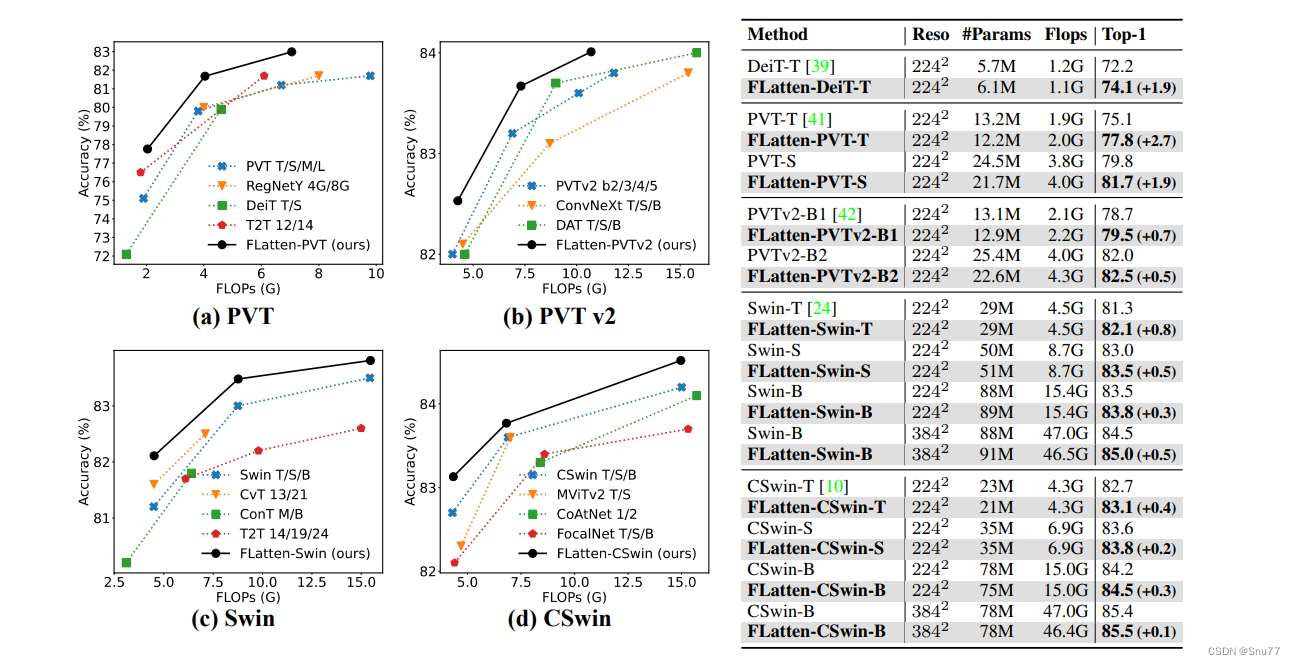
上面的图片显示了多个视觉Transformer模型的性能和计算复杂度的比较。图中分为四个部分:
1. PVT: 对比了不同版本的PVT(Pyramid Vision Transformer),DeiT(Data-efficient Image Transformer),以及T2T(Tokens-to-Token ViT)的Top-1准确率和计算量(FLOPs)。
2. PVT v2: 类似地,展示了PVT v2、ConvNext、DAT(Deformable Attention Transformer)的性能对比。
3. Swin: 对比了Swin Transformer、CvT(Convolutional vision Transformer),以及CoTNet(Contextual Transformer Network)的模型。
4. CSwin: 展示了CSwin Transformer、MViTv2、CoAtNet的性能对比。
在每个图中,还包括了作者提出的FLatten版本的Transformer模型(标记为“Ours”),其在每个分类中都显示了相对较高的准确率或者在相似的FLOPs计算量下具有竞争力的准确率。
右侧的表格详细列出了不同模型的分辨率(Reso)、参数数量(#Params)、计算量(Flops)和Top-1准确率。表中突出了FLatten版本的Transformer模型在Top-1准确率上相对于原始模型的提升(括号中的百分点)。
个人总结:这张图片展示了通过改进的线性注意力模块,即FLatten模型,在保持或稍微增加计算量的前提下,提高了Transformer架构的图像识别准确率。
三、实验效果对比
实验效果图如下所示->
因为资源有限我发的文章都要做对比实验所以本次实验我只用了一百张图片检测的是安全帽训练了一百个epoch,该结果只能展示出该机制有效,但是并不能产生决定性结果,因为具体的效果还要看你的数据集和实验环境所影响。

四、FocusedLinearAttention代码
在场的FocusedLinearAttention代码是用于Transformer的想要将其用于YOLO上是需要进行很大改动的,所以我这里进行了挺多的改动的,创作不易而且免费给大家看,所以如果能够帮助到大家希望大家能给点个赞和关注支持一下。
import torch.nn as nn
import torch
from einops import rearrange
class FocusedLinearAttention(nn.Module):
def __init__(self, dim, num_patches=64, num_heads=8, qkv_bias=True, qk_scale=None, attn_drop=0.0, proj_drop=0.0, sr_ratio=1,
focusing_factor=3.0, kernel_size=5):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim)
self.focusing_factor = focusing_factor
self.dwc = nn.Conv2d(in_channels=head_dim, out_channels=head_dim, kernel_size=kernel_size,
groups=head_dim, padding=kernel_size // 2)
self.scale = nn.Parameter(torch.zeros(size=(1, 1, dim)))
# self.positional_encoding = nn.Parameter(torch.zeros(size=(1, num_patches // (sr_ratio * sr_ratio), dim)))
def forward(self, x):
B, C, H, W = x.shape # 输入为四维:[批次大小, 通道数, 高度, 宽度]
dtype, device = x.dtype, x.device
# 调整输入以匹配原始模块的预期格式
x = rearrange(x, 'b c h w -> b (h w) c')
q = self.q(x)
if self.sr_ratio > 1:
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)
x_ = self.norm(x_)
kv = self.kv(x_).reshape(B, -1, 2, C).permute(2, 0, 1, 3)
else:
kv = self.kv(x).reshape(B, -1, 2, C).permute(2, 0, 1, 3)
k, v = kv[0], kv[1]
N = H * W # 序列长度
# 重新生成位置编码
positional_encoding = nn.Parameter(torch.zeros(size=(1, N, self.dim), device=device))
k = k + positional_encoding
focusing_factor = self.focusing_factor
kernel_function = nn.ReLU()
scale = nn.Softplus()(self.scale)
q = kernel_function(q) + 1e-6
k = kernel_function(k) + 1e-6
q = q / scale
k = k / scale
q_norm = q.norm(dim=-1, keepdim=True)
k_norm = k.norm(dim=-1, keepdim=True)
q = q ** focusing_factor
k = k ** focusing_factor
q = (q / q.norm(dim=-1, keepdim=True)) * q_norm
k = (k / k.norm(dim=-1, keepdim=True)) * k_norm
bool = False
if dtype == torch.float16:
q = q.float()
k = k.float()
v = v.float()
bool = True
q, k, v = (rearrange(x, "b n (h c) -> (b h) n c", h=self.num_heads) for x in [q, k, v])
i, j, c, d = q.shape[-2], k.shape[-2], k.shape[-1], v.shape[-1]
z = 1 / (torch.einsum("b i c, b c -> b i", q, k.sum(dim=1)) + 1e-6)
if i * j * (c + d) > c * d * (i + j):
kv = torch.einsum("b j c, b j d -> b c d", k, v)
x = torch.einsum("b i c, b c d, b i -> b i d", q, kv, z)
else:
qk = torch.einsum("b i c, b j c -> b i j", q, k)
x = torch.einsum("b i j, b j d, b i -> b i d", qk, v, z)
if self.sr_ratio > 1:
v = nn.functional.interpolate(v.permute(0, 2, 1), size=x.shape[1], mode='linear').permute(0, 2, 1)
if bool:
v = v.to(torch.float16)
x = x.to(torch.float16)
num = int(v.shape[1] ** 0.5)
feature_map = rearrange(v, "b (w h) c -> b c w h", w=num, h=num)
feature_map = rearrange(self.dwc(feature_map), "b c w h -> b (w h) c")
x = x + feature_map
x = rearrange(x, "(b h) n c -> b n (h c)", h=self.num_heads)
x = self.proj(x)
x = self.proj_drop(x)
x = rearrange(x, 'b (h w) c -> b c h w', h=H, w=W)
return x五、添加Focused Linear Attention到模型中
5.1 Focused Linear Attention的添加教程
添加教程这里不再重复介绍、因为专栏内容有许多,添加过程又需要截特别图片会导致文章大家读者也不通顺如果你已经会添加注意力机制了,可以跳过本章节,如果你还不会,大家可以看我下面的文章,里面详细的介绍了拿到一个任意机制(C2f、Conv、Bottleneck、Loss、DetectHead)如何添加到你的网络结构中去。
注意:本文的注意力机制是有参数的!!!
这个注意力机制也可以放在C2f和Bottleneck中进行使用可以即插即用,个人觉得放在Bottleneck中效果比较好。
添加教程->YOLOv8改进 | 如何在网络结构中添加注意力机制、C2f、卷积、Neck、检测头
需要注意的是本文的task.py配置的代码如下(你现在不知道其是干什么用的可以看添加教程)->
from .modules.FocusLinearAttention import FocusedLinearAttention as FLAttention elif m is FLAttention:
args = [ch[f], *args]5.2 Focused Linear Attention的yaml文件和训练截图
5.2.1 Focused Linear Attention的yaml文件
下面的是放在Neck部分的截图,参数我以及设定好了,无需进行传入会根据模型输入自动计算,帮助大家省了一些事。

下面的是放在C2f中的yaml配置。
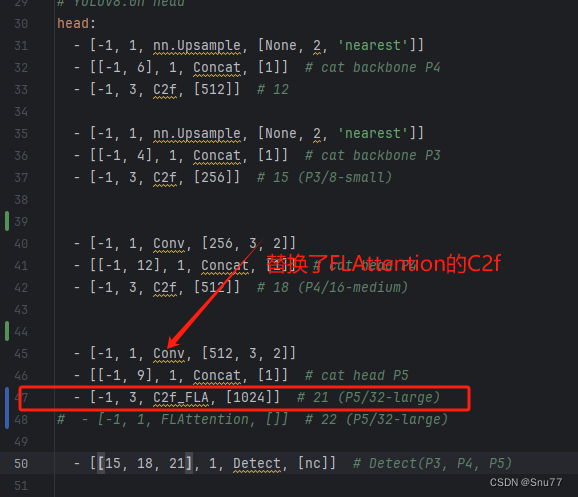
5.2.2 Focused Linear Attention的训练过程截图
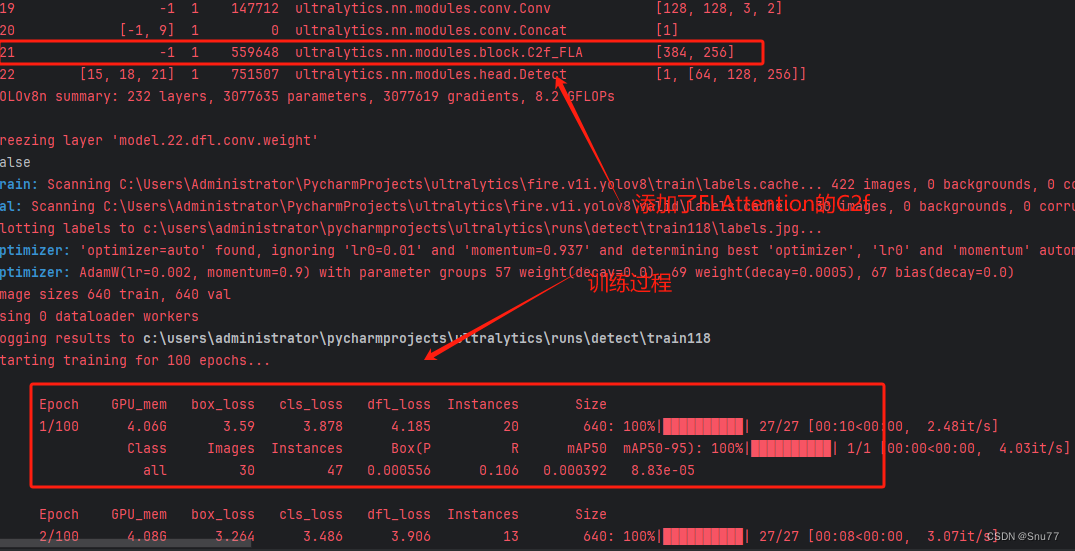
下面是我添加了Focused Linear Attention的训练截图。
下面的是将FLAttention机制我添加到了C2f和Bottleneck。
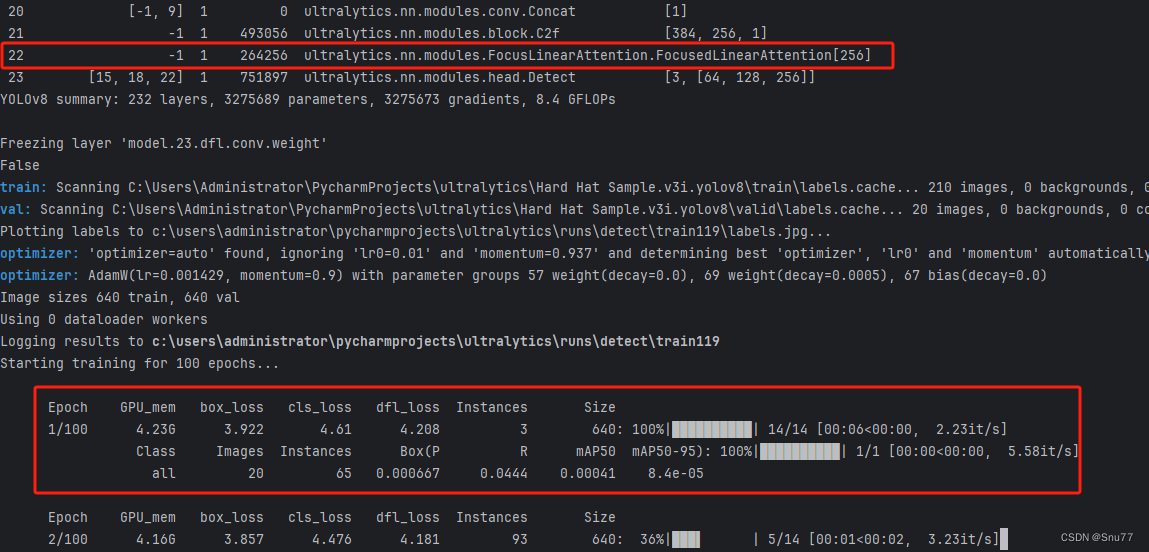
下面的是我将FLAttention放在Neck中的截图。
六、全文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv8改进系列专栏——本专栏持续复习各种顶会内容——科研必备




![pwn:[NISACTF 2022]ReorPwn?](https://img-blog.csdnimg.cn/e1a07b80e15e4234b4d5979634dc5302.png)