✏️✏️✏️今天给各位带来的是关于数据库索引以及事务方面的基础知识
清风的CSDN博客
😛😛😛希望我的文章能对你有所帮助,有不足的地方还请各位看官多多指教,大家一起学习交流!
动动你们发财的小手,点点关注点点赞!在此谢过啦!哈哈哈!😛😛😛


目录
一、索引
1.1 概念
1.2 作用
1.3 使用场景
1.4 使用
1.4.1 创建索引
1.4.2 查看索引
1.4.3 删除索引
二、事务
2.1 为什么使用事务
2.2 事务的概念
2.3 使用
2.4 事务的特性
2.4.1 典型bug1-脏读问题
2.4.2 典型bug2-不可重复读问题
2.4.3 典型bug3-幻读问题
2.4.4 事务的隔离级别
一、索引
1.1 概念
1.2 作用
- 数据库中的表、数据、索引之间的关系,类似于书架上的图书、书籍内容和书籍目录的关系。
- 索引所起的作用类似书籍目录,可用于快速定位、检索数据。
- 索引对于提高数据库的性能有很大的帮助

1.3 使用场景
- 数据量较大,且经常对这些列进行条件查询。
- 该数据库表的插入操作,及对这些列的修改操作频率较低。
- 索引会占用额外的磁盘空间。
满足以上条件时,考虑对表中的这些字段创建索引,以提高查询效率。反之,如果非条件查询列,或经常做插入、修改操作,或磁盘空间不足时,不考虑创建索引。
1.4 使用
create table student(id int, name varchar(20));
1.4.1 创建索引
对于非主键、非唯一约束、非外键的字段,可以创建普通索引 :
语法:
create index 索引名 on 表名(字段名);例如对学生表中的id创建索引:
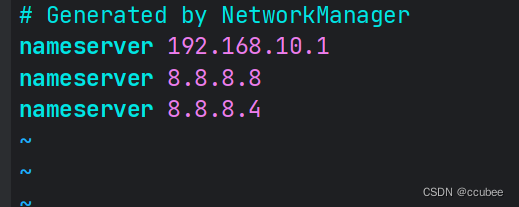
create index id_index on student(id);1.4.2 查看索引
语法:
show index from 表名;例如查看学生表中的索引:
show index from student;
可以看到我们给id创建的索引。
1.4.3 删除索引
语法:
drop index 索引名 on 表名;例如删除学生表中的索引:
drop index id_index from student;二、事务
2.1 为什么使用事务
准备测试表:
create table accout(
id int primary key auto_increment,
name varchar(20) comment '账户名称',
money decimal(11,2) comment '金额'
);
insert into accout(name, money) values
('阿里巴巴', 5000),
('四十大盗', 1000);--阿里巴巴账户减少2000
update accout set money=money-2000 where name = '阿里巴巴';
-- 四十大盗账户增加2000
update accout set money=money+2000 where name = '四十大盗';
2.2 事务的概念
2.3 使用
- 开启事务:start transaction;
- 执行多条SQL语句
- 回滚或提交:rollback/commit;
说明:rollback即是全部失败,commit即是全部成功。
start transaction;
-- 阿里巴巴账户减少2000
update accout set money=money-2000 where name = '阿里巴巴';
-- 四十大盗账户增加2000
update accout set money=money+2000 where name = '四十大盗';
commit;回滚操作,事务的原子性,本质上是依托于回滚机制的。数据库出错,事务执行失败,是怎么恢复回去的呢?是因为数据库对于事务这里有特殊的机制(undo log + redo log),通过日志写到文件里,记录之前的数据。等到数据库重启之后,读取之前的日志,检查是否有执行失败的事务,如果有,就会把这前面的操作进行回滚。
2.4 事务的特性
- 原子性:通过事务,把多个操作打包到一起。(事务最重要的特性)。
- 一致性:相当于原子性的延申,当数据库出错,不会产生像上述这种“钱凭空消失”的不科学情况。
- 持久性:事务任何的修改,都是持久化(写入硬盘)的,无论是重启程序还是重启主机,修改等都不会丢失数据。(数据库本身就是为了持久化存储)。
- 隔离性:多个事务并发执行的时候,可能会带来一些问题。通过隔离性来对这里的问题进行权衡,看是希望数据尽量准确,还是速度尽量快。
什么是并发?如果多个客户端,同时给数据库服务器发起事务请求,这个时候就叫做“并发执行事务”。如果是多个事务修改不同的表,问题不大。但是如果是修改相同的表,就可能会产生一些bug。
2.4.1 典型bug1-脏读问题
假设场景:我在写博客,跟前有同学在看我在写什么内容。但是他看了一会就走了。他走了之后,我把博客内容又改了,真正我的写完博客发出的时候,他就会发现,他之前看到的内容和现在的内容不一样。
当前有两个事务1,2,事务1修改了某个数据,但是事务还没有提交(提交的意思就是告诉数据库服务器,完毕)。而事务2读取了一个数据,此时事务2读取到的数据,很可能是一个脏的数据。因为事务1后续可能还要再次修改这个数据。
解决脏读问题,核心思路:降低事务的并发程度,给写操作加锁,意味着事务1在释放锁之前,事务2是不能访问的。
2.4.2 典型bug2-不可重复读问题
假设场景:我写完博客了,同学们开始读,这个时候我又把博客内容改了一下。此时同学们就会发现,代码突然就变了。
不可重复读,有点像脏读。但是这是“写操作”前提下导致的问题。虽然写加锁了,但是可以分多个事务,多次提交的方式来修改数据。
当前有事务1,2,其中事务1先修改数据(写加锁),此时事务2想读数据,就需要等事务1提交完成。等到事务1提交之后,事务2开始读数据(事务2可能会多次读数据)。
又来了一个事务3,事务3又修改了上述数据,导致事务2在读的过程中,两次读到的结果不同。
解决不可重复读问题:给读操作加锁(读的时候不能写)。
2.4.3 典型bug3-幻读问题
假设场景:约定我在写博客的时候,同学们不能看。同学们读博客的时候,我也不能修改。但是,同学们在读A博客的时候,我写B博客并发出。此时,A博客的内容没变,但是他们发现博客列表变了,最开始只有A博客,现在变成AB了。
当前有事务1,2,事务1修改数据,提交。事务2开始读数据,此时有事务3,新增了一个其他的数据,此时事务2就可能出现,两次读取的“结果集”不同。
解决幻读问题:串行化,不再进行任何并发了,每个事务都是串行执行的。
2.4.4 事务的隔离级别
- 上述的三个问题,需要看实际的场景,看当前场景更关注数据的准确性,还是更关注效率。
- MySQL在配置中,提供了“隔离级别”这样的选项,我们可以根据需要,调整隔离级别,适应不同的情况。
- read uncommitted 读的时候,写操作未提交。并行程度是最高的,隔离程度是最低的。效率是最高的,数据是最不靠谱的。此时可能出现脏读+不可重复读+幻读。
- read committed 读的时候,写操作已经提交,相当于给写操作加锁,并行程度降低了,隔离程度提高了,效率会降低一些。此时可能会出现不可重复读+幻读。
- repeatable read 相当于给读操作和写操作都加锁,并行程度又降低了,隔离程度提高了,效率又降低了,数据又更靠谱了,此时可能出现幻读。
- serializable 串行化,让所有的事务串行执行,隔离程度最高,效率最低,数据最靠谱。
✨好啦,今天的分享就到这里!
🎉希望各位看官读完文章后,能够有所提升。
✨创作不易,还希望各位大佬支持一下!
👍点赞,你的认可是我创作的动力!
⭐收藏,你的青睐是我努力的方向!
✏️评论:你的意见是我进步的财富!

![[Docker]十一.Docker Swarm集群raft算法,Docker Swarm Web管理工具](https://img-blog.csdnimg.cn/86d781d8cc1d4c5480ab636243ae9f7c.png)

![BUUCTF [GXYCTF2019]gakki 1](https://img-blog.csdnimg.cn/dec872d01cf94e3e967304e1e4251f90.png)


![[SWPUCTF 2021 新生赛]PseudoProtocols](https://img-blog.csdnimg.cn/ea68dc3369864998a84d1ea4348638de.png)




![BUUCTF [MRCTF2020]ezmisc 1](https://img-blog.csdnimg.cn/6d4e55a5407c4c839c44252bbbd4d03f.png#pic_center)