前言:
DQN 就是结合了深度学习和强化学习的一种算法,最初是 DeepMind 在 NIPS 2013年提出,它的核心利润包括马尔科夫决策链以及贝尔曼公式。
Q-learning的核心在于Q表格,通过建立Q表格来为行动提供指引,但这适用于状态和动作空间是离散且维数不高时,当状态和动作空间是高维连续时Q表格将变得十分巨大,对于维护Q表格和查找都是不现实的。
1: DQN 历史
2: DQN 网络参数配置
3:DQN 网络模型搭建
一 DQN 历史
DQN 跟机器学习的时序差分学习里面的Q-Learning 算法相似
1.1 Q-Learning 算法


在Q Learning 中,我们有个Q table ,记录不同状态下,各个动作的Q 值
我们通过Q table 更新当前的策略
Q table 的作用: 是我们输入S,通过查表返回能够获得最大Q值的动作A.
但是很多场景状态S 并不是离散的,很难去定义
1.2 DQN 发展史
Deep network+Q-learning = DQN
DQN 和 Q-tabel 没有本质区别:
Q-table: 内部维护 Q Tabel
DQN: 通过神经网络 , 替代了 Q Tabel

二 网络模型
2.1 DQN 算法



2.1 模型

模型参数
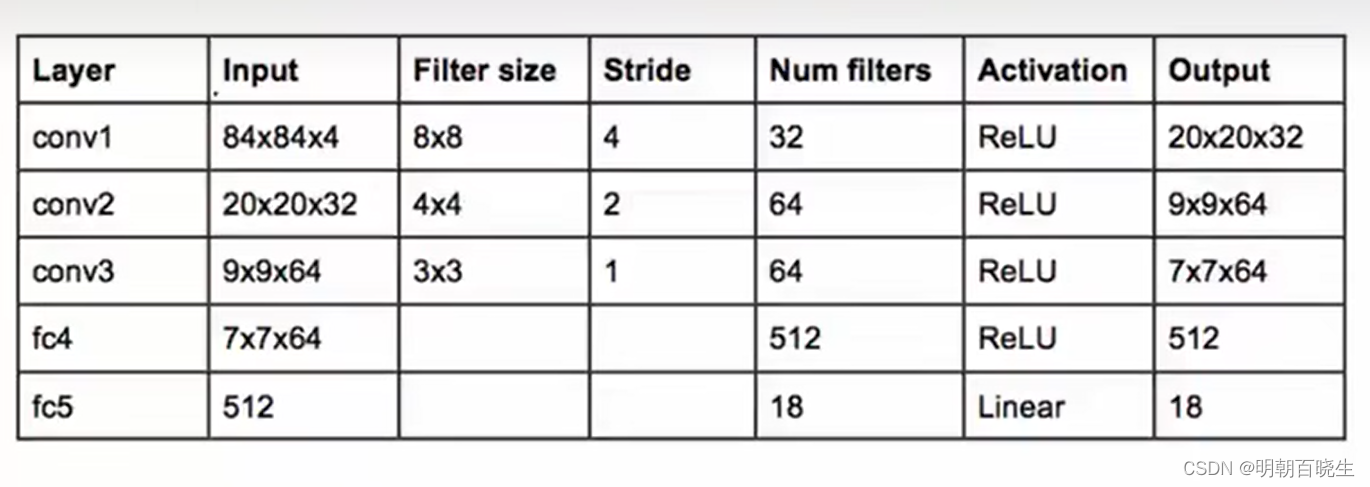
三 代码实现:
5.1 main.py
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 17 16:53:02 2023
@author: chengxf2
"""
import numpy as np
import torch
import gym
import random
from Replaybuffer import Replay
from Agent import DQN
import rl_utils
import matplotlib.pyplot as plt
from tqdm import tqdm #生成进度条
lr = 5e-3
hidden_dim = 128
num_episodes = 500
minimal_size = 500
gamma = 0.98
epsilon =0.01
target_update = 10
buffer_size = 10000
mini_size = 500
batch_size = 64
device = torch.device("cuda") if torch.cuda.is_available() else torch.device(
"cpu")
if __name__ == "__main__":
env_name = 'CartPole-v0'
env = gym.make(env_name)
random.seed(0)
np.random.seed(0)
env.seed(0)
torch.manual_seed(0)
replay_buffer = Replay(buffer_size)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = DQN(state_dim, hidden_dim, action_dim, lr, gamma, epsilon,
target_update, device)
return_list = []
for i in range(10):
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)):
episode_return = 0
state = env.reset()
done = False
while not done:
action = agent.take_action(state)
next_state, reward, done, _ = env.step(action)
replay_buffer.add(state, action, reward, next_state, done)
state = next_state
episode_return += reward
# 当buffer数据的数量超过一定值后,才进行Q网络训练
if replay_buffer.size() > minimal_size:
b_s, b_a, b_r, b_ns, b_d = replay_buffer.sample(batch_size)
transition_dict = {
'states': b_s,
'actions': b_a,
'next_states': b_ns,
'rewards': b_r,
'dones': b_d
}
agent.update(transition_dict)
return_list.append(episode_return)
if (i_episode + 1) % 10 == 0:
pbar.set_postfix({
'episode':
'%d' % (num_episodes / 10 * i + i_episode + 1),
'return':
'%.3f' % np.mean(return_list[-10:])
})
pbar.update(1)
episodes_list = list(range(len(return_list)))
plt.figure(1)
plt.subplot(1, 2, 1) # fig.1是一个一行两列布局的图,且现在画的是左图
plt.plot(episodes_list, return_list,c='r')
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('DQN on {}'.format(env_name))
plt.figure(1) # 当前要处理的图为fig.1,而且当前图是fig.1的左图
plt.subplot(1, 2, 2) # 当前图变为fig.1的右图
mv_return = rl_utils.moving_average(return_list, 9)
plt.plot(episodes_list, mv_return,c='g')
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('DQN on {}'.format(env_name))
plt.show()
5.2 Agent.py
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 17 16:00:46 2023
@author: chengxf2
"""
import random
import numpy as np
from torch import nn
import torch
import torch.nn.functional as F
class QNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim):
super(QNet, self).__init__()
self.net = nn.Sequential(
nn.Linear(state_dim, hidden_dim),
nn.Linear(hidden_dim, action_dim)
)
def forward(self, state):
qvalue = self.net(state)
return qvalue
class DQN:
def __init__(self,state_dim, hidden_dim, action_dim,learning_rate,
discount, epsilon, target_update, device
):
self.action_dim = action_dim
self.q_net = QNet(state_dim, hidden_dim, action_dim).to(device)
self.target_q_net = QNet(state_dim, hidden_dim, action_dim).to(device)
#Adam 优化器
self.optimizer = torch.optim.Adam(self.q_net.parameters(),
lr=learning_rate)
self.gamma = discount #折扣因子
self.epsilon = epsilon # e-贪心算法
self.target_update = target_update # 目标网络更新频率
self.device = device
self.count = 0 #计数器
def take_action(self, state):
rnd = np.random.random() #产生随机数
if rnd <self.epsilon:
action = np.random.randint(0, self.action_dim)
else:
state = torch.tensor([state], dtype=torch.float).to(self.device)
qvalue = self.q_net(state)
action = qvalue.argmax().item()
return action
def update(self, data):
states = torch.tensor(data['states'],
dtype=torch.float).to(self.device)
actions = torch.tensor(data['actions']).view(-1, 1).to(
self.device)
rewards = torch.tensor(data['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(data['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(data['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
#从完整数据中按索引取值[64]
#print("\n actions ",actions,actions.shape)
q_value = self.q_net(states).gather(1,actions) #Q值
#下一个状态的Q值
max_next_q_values = self.target_q_net(next_states).max(1)[0].view(-1,1)
q_targets = rewards + self.gamma * max_next_q_values * (1 - dones)
loss = F.mse_loss(q_value, q_targets)
loss = torch.mean(loss)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
if self.count %self.target_update ==0:
#更新目标网络
self.target_q_net.load_state_dict(
self.q_net.state_dict()
)
self.count +=1
5.3 Replaybuffer.py
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 17 15:50:07 2023
@author: chengxf2
"""
import collections
import random
import numpy as np
class Replay:
def __init__(self, capacity):
#双向队列,可以在队列的两端任意添加或删除元素。
self.buffer = collections.deque(maxlen = capacity)
def add(self, state, action ,reward, next_state, done):
#数据加入buffer
self.buffer.append((state,action,reward, next_state, done))
def sample(self, batch_size):
#采样数据
data = random.sample(self.buffer, batch_size)
state,action, reward, next_state,done = zip(*data)
return np.array(state), action, reward, np.array(next_state), done
def size(self):
return len(self.buffer)
5.4 rl_utils.py
from tqdm import tqdm
import numpy as np
import torch
import collections
import random
class ReplayBuffer:
def __init__(self, capacity):
self.buffer = collections.deque(maxlen=capacity)
def add(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size):
transitions = random.sample(self.buffer, batch_size)
state, action, reward, next_state, done = zip(*transitions)
return np.array(state), action, reward, np.array(next_state), done
def size(self):
return len(self.buffer)
def moving_average(a, window_size):
cumulative_sum = np.cumsum(np.insert(a, 0, 0))
middle = (cumulative_sum[window_size:] - cumulative_sum[:-window_size]) / window_size
r = np.arange(1, window_size-1, 2)
begin = np.cumsum(a[:window_size-1])[::2] / r
end = (np.cumsum(a[:-window_size:-1])[::2] / r)[::-1]
return np.concatenate((begin, middle, end))
def train_on_policy_agent(env, agent, num_episodes):
return_list = []
for i in range(10):
with tqdm(total=int(num_episodes/10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes/10)):
episode_return = 0
transition_dict = {'states': [], 'actions': [], 'next_states': [], 'rewards': [], 'dones': []}
state = env.reset()
done = False
while not done:
action = agent.take_action(state)
next_state, reward, done, _ = env.step(action)
transition_dict['states'].append(state)
transition_dict['actions'].append(action)
transition_dict['next_states'].append(next_state)
transition_dict['rewards'].append(reward)
transition_dict['dones'].append(done)
state = next_state
episode_return += reward
return_list.append(episode_return)
agent.update(transition_dict)
if (i_episode+1) % 10 == 0:
pbar.set_postfix({'episode': '%d' % (num_episodes/10 * i + i_episode+1), 'return': '%.3f' % np.mean(return_list[-10:])})
pbar.update(1)
return return_list
def train_off_policy_agent(env, agent, num_episodes, replay_buffer, minimal_size, batch_size):
return_list = []
for i in range(10):
with tqdm(total=int(num_episodes/10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes/10)):
episode_return = 0
state = env.reset()
done = False
while not done:
action = agent.take_action(state)
next_state, reward, done, _ = env.step(action)
replay_buffer.add(state, action, reward, next_state, done)
state = next_state
episode_return += reward
if replay_buffer.size() > minimal_size:
b_s, b_a, b_r, b_ns, b_d = replay_buffer.sample(batch_size)
transition_dict = {'states': b_s, 'actions': b_a, 'next_states': b_ns, 'rewards': b_r, 'dones': b_d}
agent.update(transition_dict)
return_list.append(episode_return)
if (i_episode+1) % 10 == 0:
pbar.set_postfix({'episode': '%d' % (num_episodes/10 * i + i_episode+1), 'return': '%.3f' % np.mean(return_list[-10:])})
pbar.update(1)
return return_list
def compute_advantage(gamma, lmbda, td_delta):
td_delta = td_delta.detach().numpy()
advantage_list = []
advantage = 0.0
for delta in td_delta[::-1]:
advantage = gamma * lmbda * advantage + delta
advantage_list.append(advantage)
advantage_list.reverse()
return torch.tensor(advantage_list, dtype=torch.float)
DQN 算法
遇强则强(八):从Q-table到DQN - 知乎使用Pytorch实现强化学习——DQN算法_dqn pytorch-CSDN博客
https://www.cnblogs.com/xiaohuiduan/p/12993691.html
https://www.cnblogs.com/xiaohuiduan/p/12945449.html
强化学习第五节(DQN)【个人知识分享】_哔哩哔哩_bilibili
CSDN
组会讲解强化学习的DQN算法_哔哩哔哩_bilibili
3-ε-greedy_ReplayBuffer_FixedQ-targets_哔哩哔哩_bilibili
4-代码实战DQN_Agent和Env整体交互_哔哩哔哩_bilibili
DQN基本概念和算法流程(附Pytorch代码) - 知乎
CSDN
DQN 算法