对话式 AI 类产品,已经在各行各业中实现规模化的应用。随着科技创新支撑下的高质量行业发展,人工智能已成为数字经济时代的核心生产力。其中对话式 AI,作为人工智能技术的一个分支,随着深度学习、预训练模型等技术的突破,逐渐在各行各业中实现了从产品测试到规模化应用的落地。比如:智能客服、外呼机器人、语音助手等产品应用。
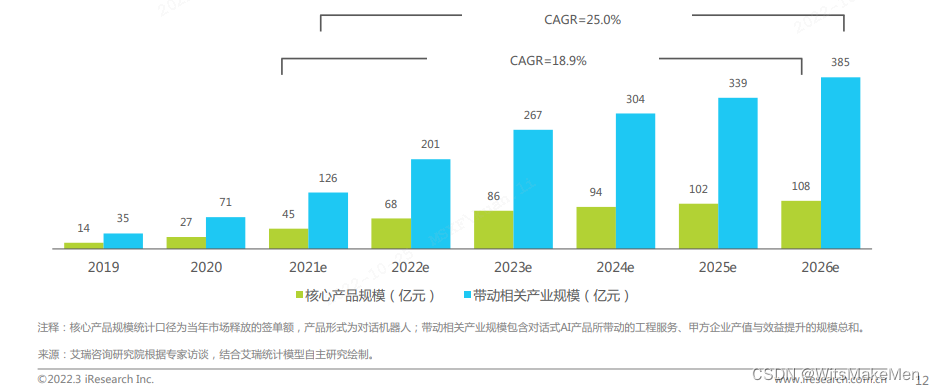
据艾瑞咨询 2022 年《中国对话式 AI 行业发展白皮书》所示,预计到 2026 年,对话式 AI 的核心产品规模将达到 108 亿元,带动相关产业规模超 385 亿元,2021~2026 年的年均复合增长率(CAGR)分别为 18.9%和 25%;对话式 AI 作为“替代与辅助人工”的核心应用,为市场最原始直观的“降本增效”价值诉求提供了先行落地的有效解决方案。众多企业将引入“对话式 AI”作为智能化转型的首要试验田。
企业在应用对话式 AI 产品中,通常会遇到以下两个痛点:
- 部署阶段-问答知识库构建周期长,用户冷启动门槛高。主要表现在:1、企业数据分散在会话日志、网页等多种文档中,需要人工收集。2、企业数据积累较少,需要业务专家介入梳理。3、人工标注成本居高不下,易受个人主观意识左右,影响模型训练效果。
- 运营阶段-AI 服务效果不稳定,且缺乏有效的监控手段,不能及时进行模型调优。主要表现在:1、系统中人工构建知识库质量不可控,导致 AI 服务效果不稳定。2、系统对未覆盖知识无法做到及时发现,导致无法回答,用户体验差。3、系统无法对错误案例(BadCase)及时分析,模型无法及时更新。
上述两个痛点说明,对话式 AI 产品若要实际满足用户需求,仅拥有对话能力是不够的,更需要完善的问答知识库作为底层支撑。换句话说,问答知识库的规模和质量直接决定了对话式 AI 产品的整体服务效果。然而仅靠人力堆积的模式来构建和运营知识库,不仅服务质量得不到保证,而且项目运营成本也存在失控的风险,早已无法适应市场的要求和增速。
问答知识库的快速构建及闭环运营能力,是解决上述两个痛点的关键。
问答知识库快速构建及闭环运营的核心技术介绍
问答知识库的构建和运营是一项系统工程,冷启动阶段运用系统工具辅助人工快速构建知识体系,推进对话式 AI 落地;运营阶段运用大数据挖掘技术,实现价值数据自动回流,知识库持续更新。两套体系搭建完成后将形成数据闭环,并相辅相成,逐步形成“双飞轮”的自运营体系。其整体运行逻辑如下图:
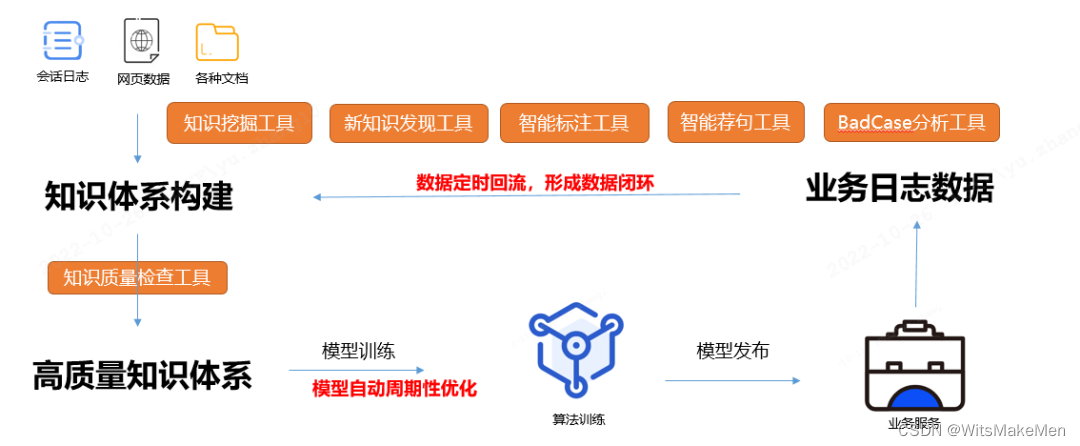
如图所示:冷启动阶段运用知识挖掘、智能标注、智能荐句、质量检查等工具辅助人工快速构建知识体系;运营阶段运用新知识发现、BadCase 分析、质量检查等工具保持模型持续迭代。其中用到的核心技术主要有文本聚类、样本增广、知识质量检查等。下面就针对这些核心技术做下介绍。
1、文本聚类技术,可以为知识库持续挖掘和发现新的知识:
文本聚类技术在知识构建及闭环运营工具中,主要用于新知识的发现(无法聚到现有的任何一个意图类别中)和拒识问题的归纳(可以聚到现有意图体系中,但是现在无法应答,需要人工处理)。当前的主流算法为无监督句向量表示+聚类算法,聚类算法常采用 K-means、DBSCAN 等,目前常用的无监督句向量表示方法有:

随着深度学习的发展,预训练模型目前是向量表示的主流方法。最简单的方式是使用 BERT 的[CLS]token 对应的 embedding 作为整句话的句向量表示。但是该向量存在向量坍塌的问题,即使差异性非常大的两个句子,相似度得分也可能会比较高。因此引入了对比学习,对比学习主要思想是让相似的文本对应的向量表示尽可能接近,不相似的文本对应的向量尽可能远离,目前预训练+对比学习是获取无监督句向量的主流方法。
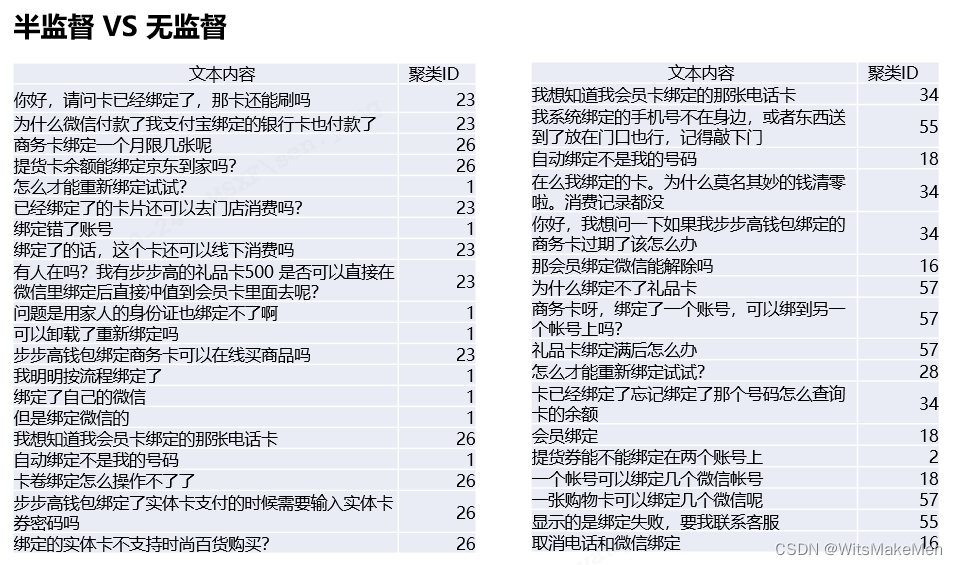
经过调研,研究院团队将句向量的获取方式由无监督升级为了半监督,将少量带标注的先验知识融入模型,使模型能够学习到更具区分性的向量表示,从而进一步提升了文本聚类的效果。下图为某电商场景半监督聚类和无监督聚类效果对比,可以明显看出半监督聚类结果更加内聚(半监督对于相似的文本只聚出了 3 类,而无监督聚出了 7 类)。
我们也在公开数据集上对比了各种聚类算法的效果,半监督模型+对比学习的效果提升明显。
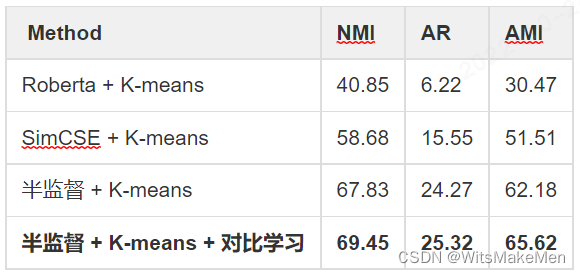
聚类效果评价指标:
NMI(Normalized Mutual Information, 标准化互信息)
AMI(Adjusted Mutual Information, 调整互信息)
AR(Adjusted Rand, 调整兰德指数)
文本聚类在实践中发现的新知识和重新归纳的拒识问题经人工审核,采用率可达 87%。大大降低了运营人员人力投入。为提升聚类速度,我们使用 batch K-means 替换 K-means 算法,在聚类效果不变的情况下,速度提升了近 3 倍。
2、样本增广技术,可以解决知识库语料稀少和不平衡的问题:
样本增广技术,主要应用在智能荐句工具中解决知识库语料稀少和不平衡问题。当前主流样本增广算法如下:
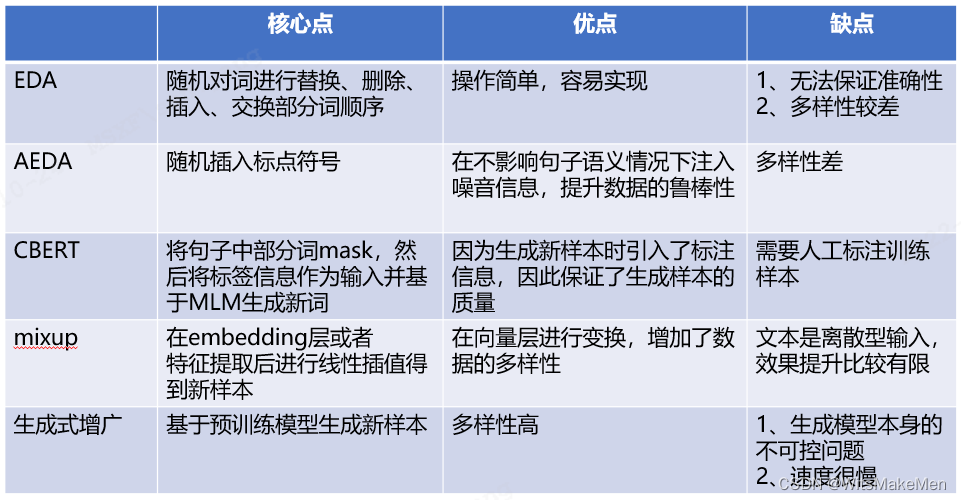
中关村科金人工智能研究院结合一线运营人员与客户的实际应用反馈,系统分析了上述各方案的优缺点之后,创造性地提出了一种融合了文本检索和生成式样本增广的技术,作为最终的样本增广方案。
其中文本检索是利用研究院积累的大量真实行业知识语料(已脱敏)作为检索底库,基于文本语义向量匹配技术从底库中获取语义相似样本,可以同时兼顾增广样本的多样性、准确性和真实性。我们采用融合了对比学习的半监督预训练模型获取文本语义向量,用余弦相似度作为度量指标,为提升检索速度,使用了 milvus 向量索引。生成式样本增广我们采用了 Prefix_LM 结构模型,然后在生成结果基础上做了进一步的数据后处理。
大致流程为:当用户输入待增广样本,系统先从历史积累的语料库中检索相似样本,当检索数量能达到用户需求时,直接返回检索结果;如果数量不足,再通过生成式样本增广算法进行扩充。考虑到生成式样本增广的不可控问题,我们做了两个数据后处理操作,进一步提升生成样本的质量。一是通过计算生成样本与原始样本的相似度,如果相似度太低则不采纳该生成结果;二是通过语言模型对生成样本进行打分,如果分数太低也不采纳。最终增广样本的人工采用率近 70%,大大降低了运营人员人力投入成本。下面以“怎么提现呢”为例,样本增广效果对比如下:

3、知识质量检查技术,可以检测数据标注质量并对潜在错误样本进行矫正:
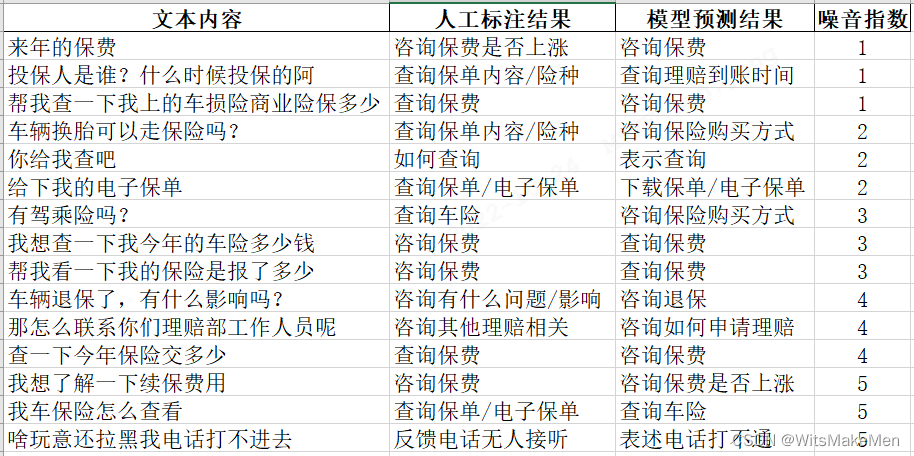
知识质量检查技术主要用于评估数据标注质量并挑选出潜在的标注错误样本。我们采用了 Cleanlab 工具,对标注样本进行了 1~5 的噪音指数评分,值越高说明人工标注结果越有可能存在错误,需要对标注进行复核纠正。经过质量检查和标注矫正后,意图识别准确率平均可提升 6%~15%。以保险领域的一部分知识为例,质量检查结果如下:
问答知识库构建技术助力多行业快速落地对话式 AI
中关村科金人工智能研究院自主研发的问答知识库快速构建工具,目前已在保险、电商、银行、零售等多个行业,永安保险、步步高等多个头部企业中,实现落地应用。在上述场景中,基于文本聚类技术进行新知识发现,可发现占对话日志总量 2%~3%的无法应答的新知识,经人工审核,采用率可达 87%;智能荐句工具通过样本增广技术为每条知识平均增广 10 条相似样本,经过人工审核,采用率近 70%;知识质量检查工具可以在减少 85%人工审核工作量下提升 10%的意图识别准确率;BadCase 分析及回流工具平均每周可以自动回流一次知识库并重新训练一次模型。
实践证明,问答知识库快速构建及闭环运营工具可至少节省 2/3 的知识库运营和维护人力,使冷启动和知识库更新时间缩短近 70%。
总结与展望
现阶段对话式 AI 技术应用的业界难题,主要是新场景中对话机器人的冷启动问题。上面介绍了我们在快速构建问答知识库上的工作,在一定程度上解决了冷启动问题,使冷启动和知识库更新时间缩短近 70%,但是仍然需要一定的人力在工具的辅助下进行知识库审核和构建。目前流行的基于提示学习 prompt 的小样本学习,可充分利用预训练模型在大量无监督数据集上学习到的丰富知识,进一步减少冷启动所需要的数据量和人力投入。
未来,中关村科金将利用现有的知识库快速构建技术,结合最新的小样本学习方法,进一步缩短对话式 AI 的部署周期,为企业的智能化转型和对话式 AI 的大规模快速落地提供有力的支持。