文章目录
- 背景
- 错误显示
- 故障原因及处理过程
- 改进措施
- 补偿
- 启发
- 监控和告警
- 容灾备份
- 自动化部署和回滚
- 灰度发布
- 定期演练和测试
- 日志和审计
- 容错性
- 弹性扩展
- 性能优化
- 安全性
- 持续改进
- 稳定业务不动
- 多方验证
- 不要抱着侥幸心理
- 白名单内测
- 留后手
- 总结
- 写在最后

背景
语雀是蚂蚁金服旗下的一款在线文档编辑与协同工具,自2018年上线以来,凭借其强大的功能和优秀的用户体验,吸引了众多个人和企业用户,成为了国内最受欢迎的在线文档平台之一。然而,就在2023年10月23日,语雀遭遇了一场前所未有的P0级事故,导致平台无法正常访问和使用,持续了近8个小时(14时10分至21时45分左右)
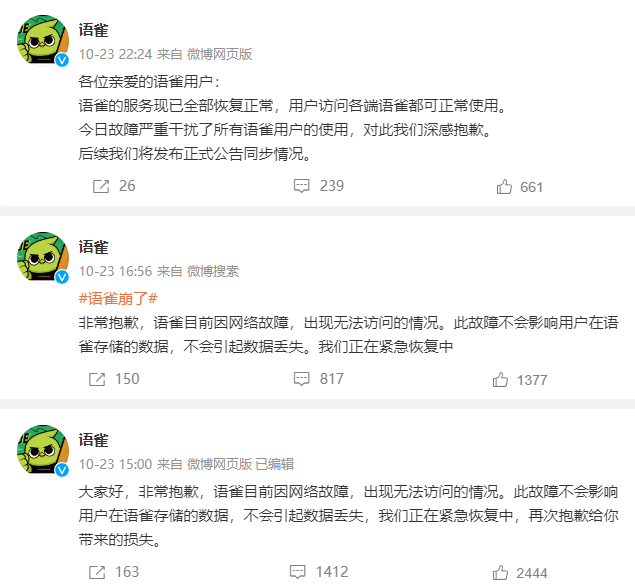
错误显示
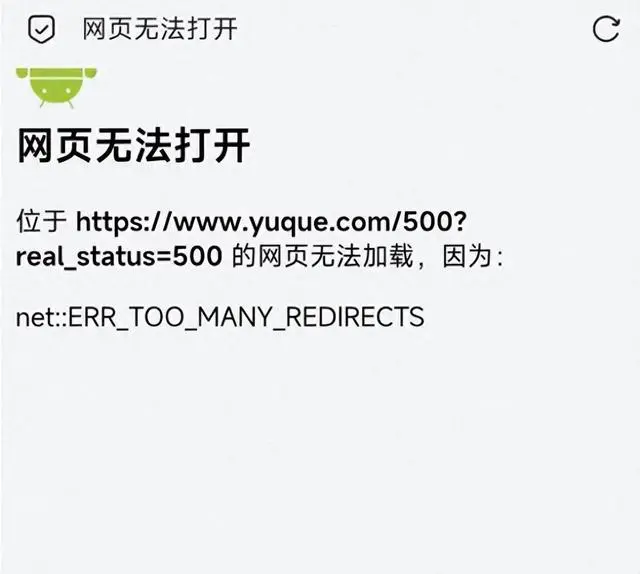
故障原因及处理过程

改进措施
-
1、升级硬件版本和机型,实现离线后的快速上线。该措施在本次故障修复中已完成;
-
2、运维团队加强运维工具的质量保障与测试,杜绝此类运维 bug 再次发生;
-
3、缩小运维动作灰度范围,增加灰度时间,提前发现 bug;
-
4、从架构和高可用层面改进服务,为语雀增加存储系统的异地灾备。
补偿
语雀团队表示,为了表达歉意,团队将向所有受到故障影响的用户提供如下赔偿方案:
- 针对语雀个人用户,我们赠送 6 个月的会员服务。操作流程:进入工作台「账户设置」,点击左侧「会员信息」,在会员信息页面点击「立即领取」,即可获得赠送服务。
启发
那么在这次服务器PO事故上我们能得到什么启发,采取什么样的措施来尽可能避免线上突发的问题,或者尽快恢复线上业务,谈谈个人的见解:
-
高可用架构
采用集群、负载均衡、冗余备份等技术手段,确保服务器的高可用性。当一个服务器出现故障时,其他服务器可以接管其工作,保证服务的连续性。
-
监控和告警
建立完善的监控系统,实时监测服务器的运行状态、性能指标和异常情况。及时发现问题,并设置告警机制,及时通知相关人员进行处理。
-
容灾备份
定期进行数据备份,并将备份数据存储在不同的地理位置或云服务商上,以防止数据丢失。同时,建立容灾方案,当主服务器出现故障时,能够快速切换到备用服务器。
-
自动化部署和回滚
采用自动化部署工具,确保服务器的配置和应用程序的部署过程可重复、可靠。同时,建立回滚机制,当部署出现问题时,能够快速回滚到上一个稳定版本。
-
灰度发布
在发布新版本或更新时,采用灰度发布策略,逐步将流量引导到新版本,以降低发布带来的风险。如果出现问题,可以快速回滚到旧版本。
-
定期演练和测试
定期进行系统演练和压力测试,模拟各种故障和异常情况,验证系统的稳定性和可靠性。同时,进行回滚测试,确保回滚操作的可行性和正确性。
-
日志和审计
记录服务器的运行日志和操作日志,便于故障排查和问题定位。同时,进行审计,监控服务器的访问和操作,防止未授权的访问和恶意操作。
-
容错性
系统应该能够容忍部分故障或异常情况,不会导致整个系统崩溃或无法使用。通过合理的设计和架构,将系统的各个组件解耦,降低单点故障的风险。
-
弹性扩展
系统应该能够根据业务需求和负载情况进行弹性扩展,以满足用户的需求。通过自动化的扩容和缩容机制,根据实际情况调整系统的资源配置。
-
性能优化
对系统进行性能优化,提高系统的响应速度和吞吐量。通过合理的缓存策略、数据库优化、代码优化等手段,提升系统的性能。
-
安全性
确保系统的安全性,防止未授权的访问和恶意攻击。采用安全认证、加密传输、漏洞扫描等措施,保护系统的数据和用户的隐私。
-
持续改进
不断进行系统优化和改进,根据用户反馈和业务需求,及时修复问题和提升系统的功能和性能。通过持续集成和持续交付,快速发布新版本和修复补丁。
-
稳定业务不动
对于线上稳定的业务,一般都不要去动它。
-
多方验证
对于需要上线的业务,需要执行的重要的sql,一定要经过多方的验证。
-
不要抱着侥幸心理
对于生产环境会出现,测试环境不会出现的一些问题,千万不要抱着侥幸心理。
-
白名单内测
重大的变更要做白名单内测,保证正式环境也能有真实的用户去测试。
-
留后手
万事要留后手,并且做响应的应急文档操作手册。
总结
当服务出现问题时,我们应该及时发现并解决问题,并且在设计系统时考虑到容错和恢复能力,以保证系统的稳定性和可靠性。
写在最后
感谢您的支持和鼓励! 😊🙏
如果大家对相关文章感兴趣,可以关注公众号"架构殿堂",会持续更新AIGC,java基础面试题, netty, spring boot, spring cloud等系列文章,一系列干货随时送达!