遥感领域的通用大模型 2023.11.13在CVPR发表
原文地址:[2311.07113] SpectralGPT: Spectral Foundation Model (arxiv.org)
实验
在本节中,我们将严格评估我们的SpectralGPT模型的性能,并对其进行基准测试SOTA基础模型:ResNet50 [36]、SeCo [37]、ViT[22]和SatMAE[30]。此外,我们评估了其在四个下游EO任务中的能力,包括单标签场景分类、多标签场景分类、语义分割和变化检测,以及广泛的消融研究。
我们定量评估了预训练基础模型在4个下游任务中的性能,包括单标签RS场景分类任务的识别精度、多标签RS场景分类任务的宏观和微观平均精度(mAP),即宏观mAP (micro-mAP)、语义分割任务的总体精度(OA)和平均交联(mIoU),以及变化检测的精度、召回率和F1分数。此外,我们还进行了有见地的消融研究,探索了掩蔽比、解码器深度、模型大小、补丁大小和训练时代等关键因素。利用4个NVIDIA GeForce RTX 4090 gpu的计算能力,我们精心微调下游任务和消融研究的预训练基础模型,从而提供对SpectralGPT在RS域中的能力和适应性的全面见解。
A. EuroSAT上的单标签RS场景分类
对于下游单标签RS场景分类任务,我们使用EuroSAT数据集[38]。这个数据集包括从34个欧洲国家收集的27000张哨兵2号卫星图像。这些图像被分为10个土地使用类别,每个类别包含2000到3000个标记图像。该数据集中的每张图像分辨率为64 × 64像素,包含13个光谱带。值得注意的是,为了与之前的数据处理保持一致,所有图像都排除了B10波段。此外,我们遵循[39]中建议的训练/验证分割。在EuroSAT数据集上,这些预训练的模型经过微调,跨越150个epoch,批量大小为512。这一微调过程采用了基本学习率为2 × 1 0 − 4 10^{-4} 10−4的AdamW优化器,并结合了与先前工作[24]一致的数据增强,包括权重衰减(0.05)、drop path(0.1)、repb(0.25)、mixup(0.8)和cutmix(1.0)。利用预训练模型的基础编码器,将其输出通过平均池化层进行预测。训练目标是最小化交叉熵损失。图4给出了下游单标签场景分类任务的网络架构。
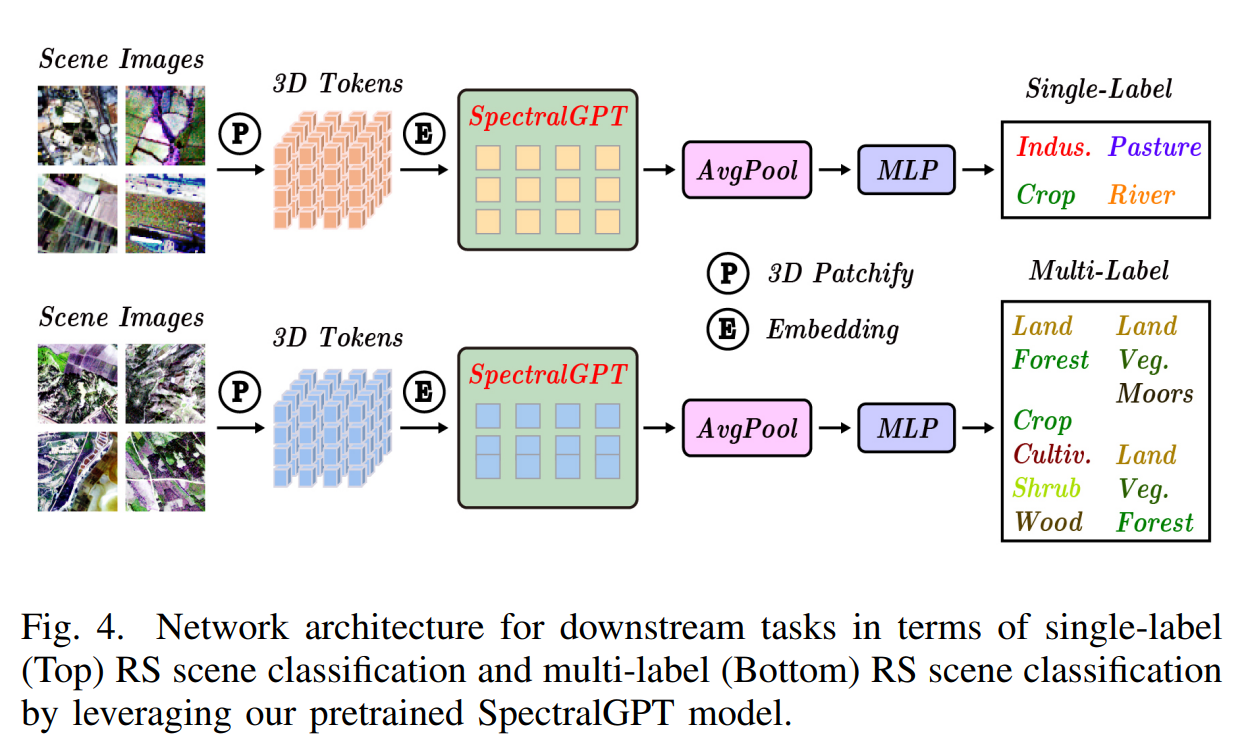
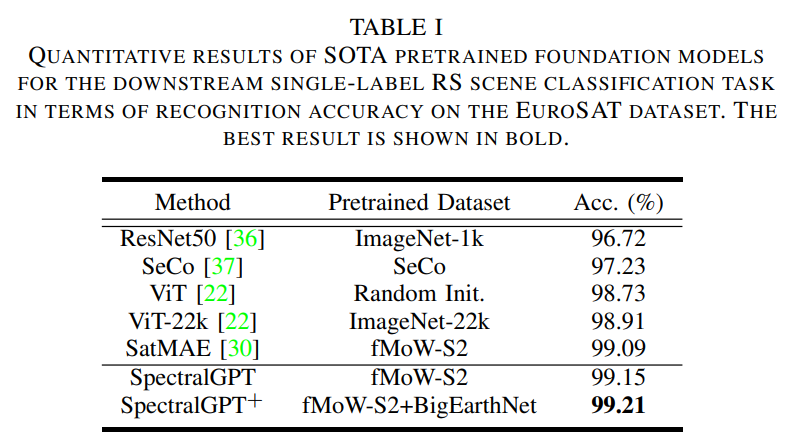
预训练模型的编码器作为基础骨干,其输出服从于平均池化层以生成预测。训练目标包括最小化交叉熵损失。在表1中,我们对我们提出的方法与其他预训练模型进行了比较分析,报告了验证集上最高的Top 1 精度。获得的结果突出了所提出方法的有效性,实现了令人印象深刻的精度99.15%。此外,当模型在fMoW-S2和BigEarthNet数据集上进行预训练时,可以观察到显著的性能提升,最终达到99.21%的显着准确率。这强调了利用不同数据源来改进模型性能的优势。
B. BigEarthNet上的多标签遥感场景分类
对于多标签RS场景分类任务,我们使用bigearth - s2数据集[34]。这个广泛的数据集由125个Sentinel-2 tiles组成,包括590,326张12波段图像,跨越19个类别,用于多标签分类。这些图像的分辨率从10米到60米不等,12%的低质量图像被排除在外。训练和验证集与先前的研究[39]一致,有354,196个训练样本和118,065个验证样本。为了准备模型训练,使用双线性插值将不同分辨率的图像标准化为128 × 128像素的统一尺寸。
在bigearth - s2数据集上,这些基础模型使用10%的训练数据子集进行微调,遵循与EuroSAT微调实验中应用的设置相似的设置,除了学习率提高了2× 1 0 − 4 10^{-4} 10−4,这与先前的研究结果一致[30],[37]。大多数现有方法,包括那些使用预训练基础模型的方法,通常使用bigearth - s2数据集中的所有可用图像进行训练。相比之下,我们提出的SpectralGPT即使只利用10%的训练样本,也能实现更高的分类性能。考虑到这个的多标签分类性质任务中,我们的训练目标涉及多标签软边际损失,性能评估基于mAP度量。值得注意的是,我们使用macro和micro mAP测量来计算mAP。这种方法特别适用于bigearth - s2数据集,它显示了类的不平衡。多标签分类框架如图4所示。
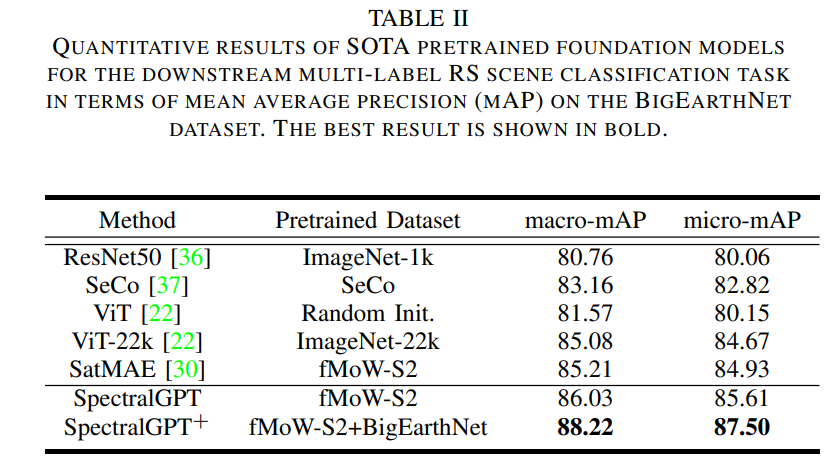
表2给出了我们的预训练模型与其他提出的预训练模型和从零开始训练的模型的比较分析,展示了提出的方法的卓越性能。特别是,与在ImageNet-22k和SatMAE相比,我们的SpectralGPT模型的性能macro-mAP(micro-mAP)比它们高出0.84% (0.82%)和0.71%(0.68%)。值得注意的是,引入了额外的预训练数据(BigEarthNet),即SpectralGPT+,导致了显著的性能提升,模型取得了令人印象深刻的成绩macro-mAP(micro-mAP) 为88.22%(87.50%) ,比仅在fMoW-S2上训练的模型高出2.19%(1.86%)。这种实质性的改善可归因于两个关键因素。首先,模型在BigEarthNet上的初始预训练(即使没有标签)使其对数据集的分布有了很强的掌握,加速了微调过程中的收敛,增强了mAP。其次,采用MIM方法作为预训练 pretext 任务,再加上庞大的数据规模,需要与训练策略保持一致,强调随机掩膜框架和90%掩膜比的重要性,以促进更鲁棒的表示学习。此外,由于我们的评估集中在一个多标签分类任务上,并且只使用了10%的训练数据,结果强调了我们提出的模型在处理具有挑战性的下游任务时的优越泛化和少量学习能力。
C.基于SegMunich的RS语义分割
对于语义分割任务,我们创建了一个新的SegMunich数据集,该数据集来自Sentinel-2光谱卫星[41]。该数据集由10波段最佳像素合成,尺寸为3,847 × 2,958像素,空间分辨率为10米。它在2020年4月之前的三年内捕捉了慕尼黑的城市景观,并包括一个分割掩模,精心描绘了13个土地利用和土地覆盖(LULC)类别。这个掩码的数据来自不同的地方,包括OpenStreetMap的街道网络数据和OSMLULC 平台数据为其余12个类别,均以相同的10米空间分辨率获得。为了创建语义分割的综合特征表示,数据集将10米光谱带(B1、B2、B3和B4)与重采样的20米光谱带(B5、B6、B7、B8A、B11、B12)结合起来,并将其上采样以匹配10米分辨率。这种谱带的融合确保了数据集为语义分割任务提供了丰富和信息丰富的数据。
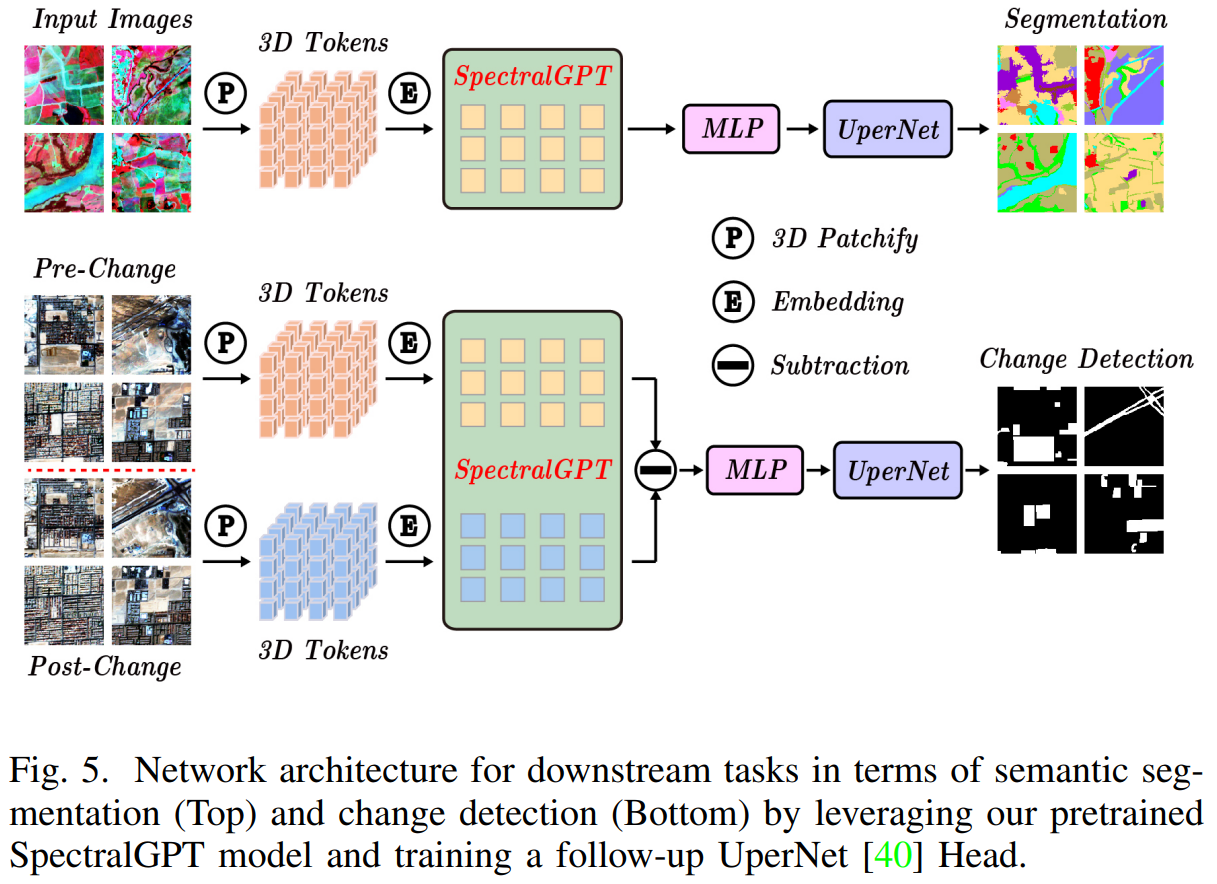
在SegMunich数据集上,我们将UperNet框架[40]与预训练的基础模型结合使用,最初将编码器最后一层的每个像素的四个token合并为一个token。图像数据被分成128 x 128像素的标记,重叠50%。然后将数据集分成8:2的训练验证比,并进行数据增强技术,包括随机翻转和旋转。在对该数据集进行微调期间,我们使用96个批处理大小,并将基本学习率设置为5 x 1 0 − 4 10^{-4} 10−4。优化函数和损失函数与EuroSAT实验中使用的函数保持一致,确保对模型训练和评价采取连贯统一的方法。分割架构如图5所示。
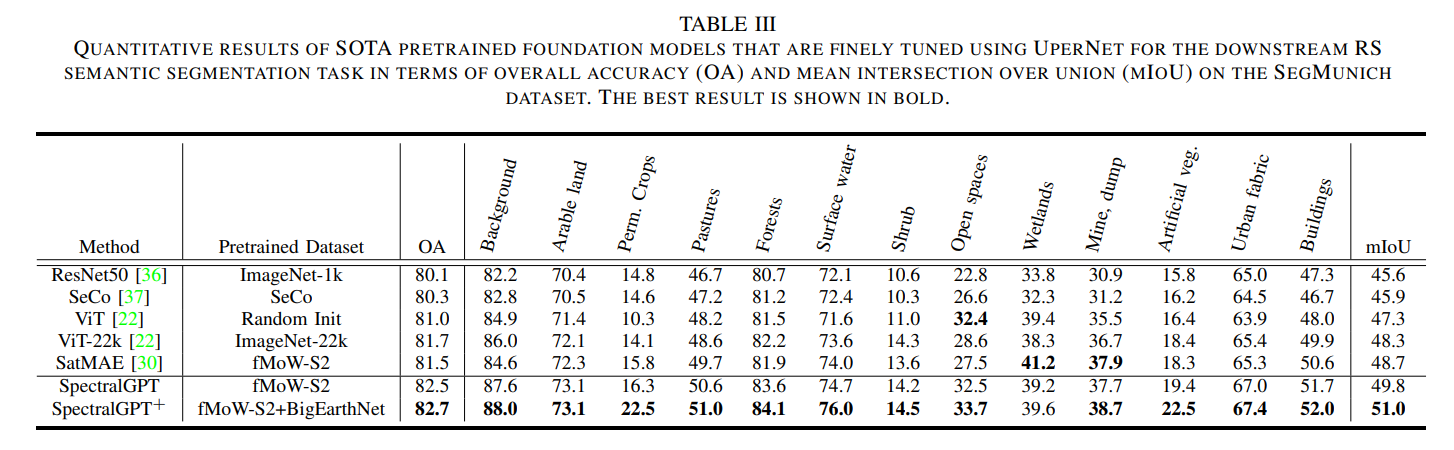
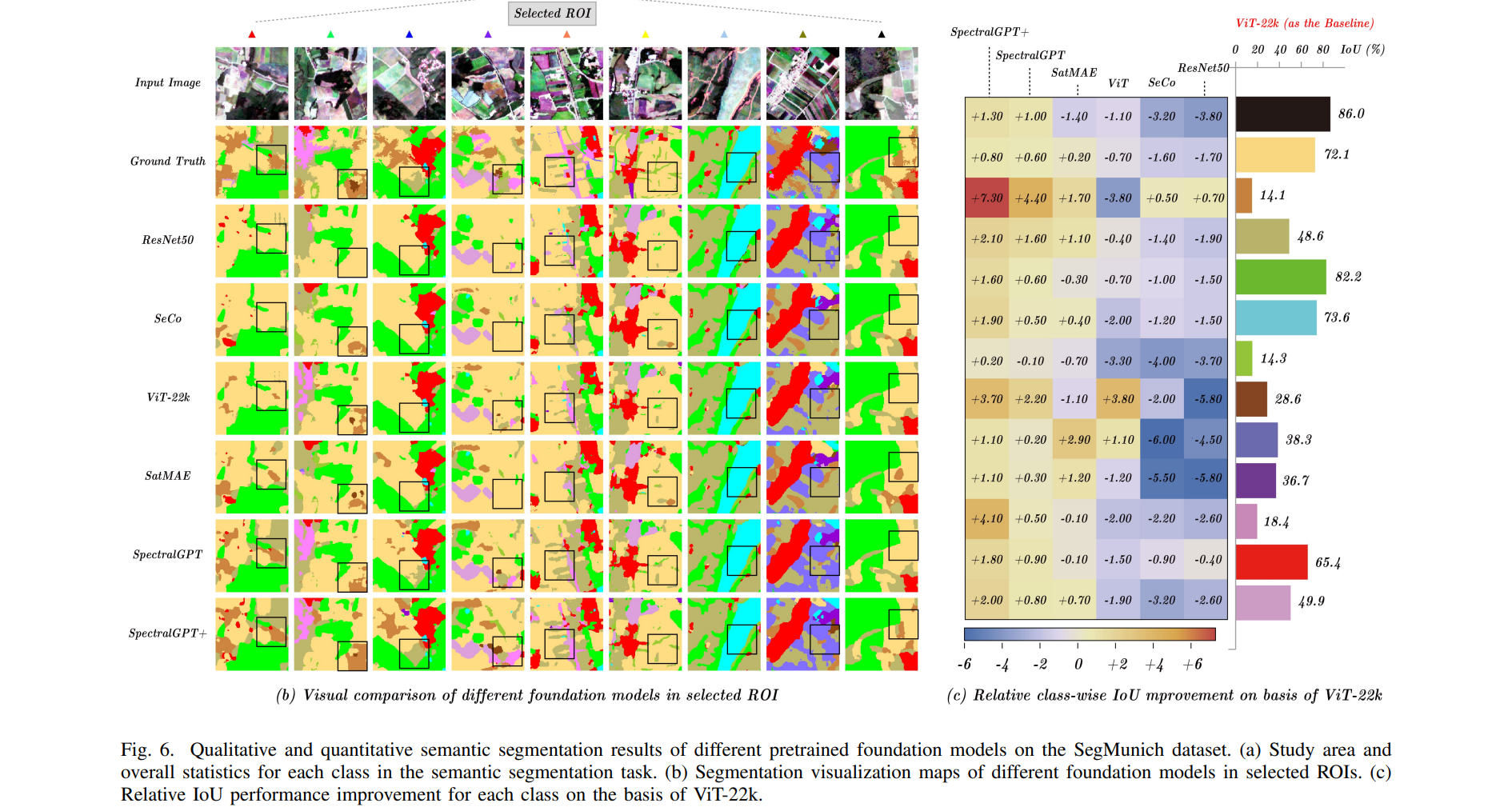
表III列出了语义分割任务的OA和mloU的定量结果。我们的SpectralGPT (SpectralGPT+)表现优于其他所有产品,mIoU比第二名(即SatMAE)高出1.1% (2.3%)。图6(a)提供了分割任务所研究的慕尼黑地区的视觉描述,以及13个类别的比例。如**图6(b)所示,几个roi的定性比较表明,在大多数情况下,与竞争模型相比,我们的模型在识别更广泛的土地利用类别方面具有优越的能力。此外,当考虑将ViT-22k 作为性能比较的基线时,我们的模型在所有分割类别中始终表现出色,如图6©**所示,特别是对于作物、牧场、开放空间、植被等类别。通过将类别统计数据与分类IoU结果相结合,我们的SpectralGPT模型在减轻类别不平衡分类带来的挑战方面表现出色。与其他基础模型相比,这将大大提高性能。

D.对OSCD的RS变化检测
对于变化检测任务,我们使用OSCD数据集[42]。图7(a)显示了几个城市规模的例子。该数据集包括24个城市的Sentinel-2图像,其中14张用于训练,10张用于评估。这些图像拍摄于2015年至2018年之间,包含13个光谱波段,分辨率分别为10米、20米和60米。该数据集在像素级进行了注释,以表明变化,特别是关注城市发展。在OSCD数据集上,我们执行图像裁剪以创建大小为128 × 128像素的斑块,重叠率为50%,并且我们应用随机翻转和旋转作为数据增强技术。对于每一对图像,两者都通过共享编码器同时处理,并计算其特征之间的差异,然后传递给UperNet。每个特征像素由4个标记组成,类似于分割方法,我们使用线性层将这4个标记合并为1个标记。该模型以负对数似然损失为训练目标,以批大小为64个,学习率设置为1× 1 0 − 3 10^{-3} 10−3,训练60个epoch。在变更检测任务中利用预训练的SpectralGPT模型的整个框架如图5所示。
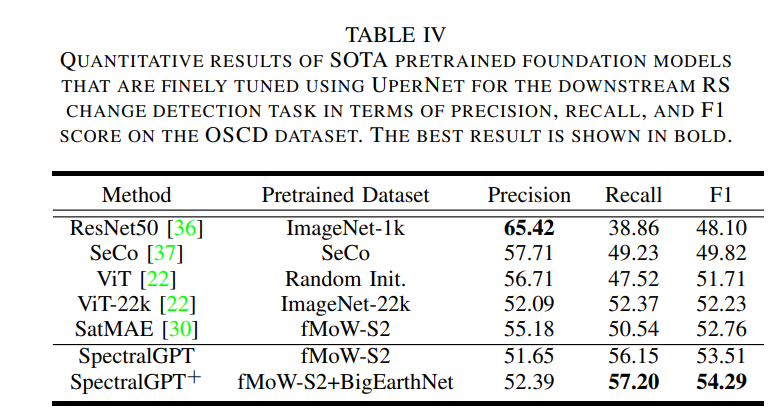
模型性能通过精度、召回率和F1分数来评估,其定量结果如表4所示,在OSCD数据集上,我们提出的模型获得了最高的F1分数,超过了第二好的模型(即SatMAE) 0.75%(1.53%)。然而,值得注意的是,我们的模型在F1得分和召回率方面表现出色,但与其他模型相比,精度相对较低。这种现象可以归因于两个主要因素。首先,变化检测任务内固有数据的极度不平衡(见图7(b)),其中阳性和阴性样本的数量差异显著,可能导致模型将阴性案例分类为阳性,以牺牲精度为代价提高召回率。其次,ViT架构的复杂性需要大量的数据来缓解过拟合。模型可能会与过拟合作斗争,并且对域外数据的适应性变差。解决这一挑战可能需要提供额外的微调数据或者降低模型的等级。在定性结果方面,我们的模型在**图7(d)**的选定roi中预测变化像素方面表现出色,假阴性较少。值得注意的是,**图7©**强调了SpectralGPT的卓越性能,其中我们的模型在一半的测试城市中取得了最好的结果。此外,被比较的模型在10个不同的的城市表现趋势一致,Lasvegas 和 Montpellier分别在F1中获得了最高和第二高的分数