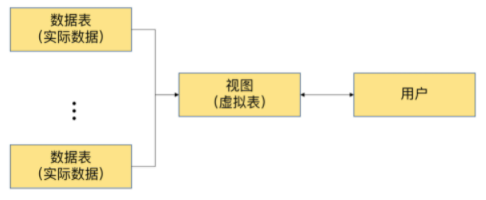
1. 数仓基本概念
-
1- 什么是数据仓库呢?
存储数据的仓库, 主要用于存储过去历史发生过的数据,面向主题, 对数据进行统计分析的操作, 从而能够对未来提供决策支持
-
2- 数据仓库最大的特点是什么呢?
数据仓库既不生产数据, 也不消耗数据, 数据来源于各个数据源
-
3- 数据仓库的四大特征:
1- 面向主题: 分析什么 什么就是我们的主题 2- 集成性: 数据从各个数据源汇聚而来, 数据的结构都不一定一样 3- 非易失性(稳定性): 存储都是过去历史的数据, 不会发送变更, 甚至某些数据仓库都不支持修改操作 4- 时变性: 随着时间推移, 将最近发生的数据也需要放置到数据仓库中, 同时分析的方案也无法满足当前需求, 需要变更分析的手段 主题域通常是联系较为紧密的数据主题的集合。 数据域是指面向业务分析,将业务过程或者维度进行抽象的集合。 主题域和数据域的区别: 1)主题域:面向业务过程,将业务活动事件进行抽象的集合,如下单、支付、退款都是业务过程,针对公共明细层(DWD 及 DWM)进行主题划分。 2)数据域:面向业务分析,将业务过程或者维度进行抽象的集合,针对公共汇总层(DWS)进行数据域划分。
-
4- OLAP 和 OLTP区别:
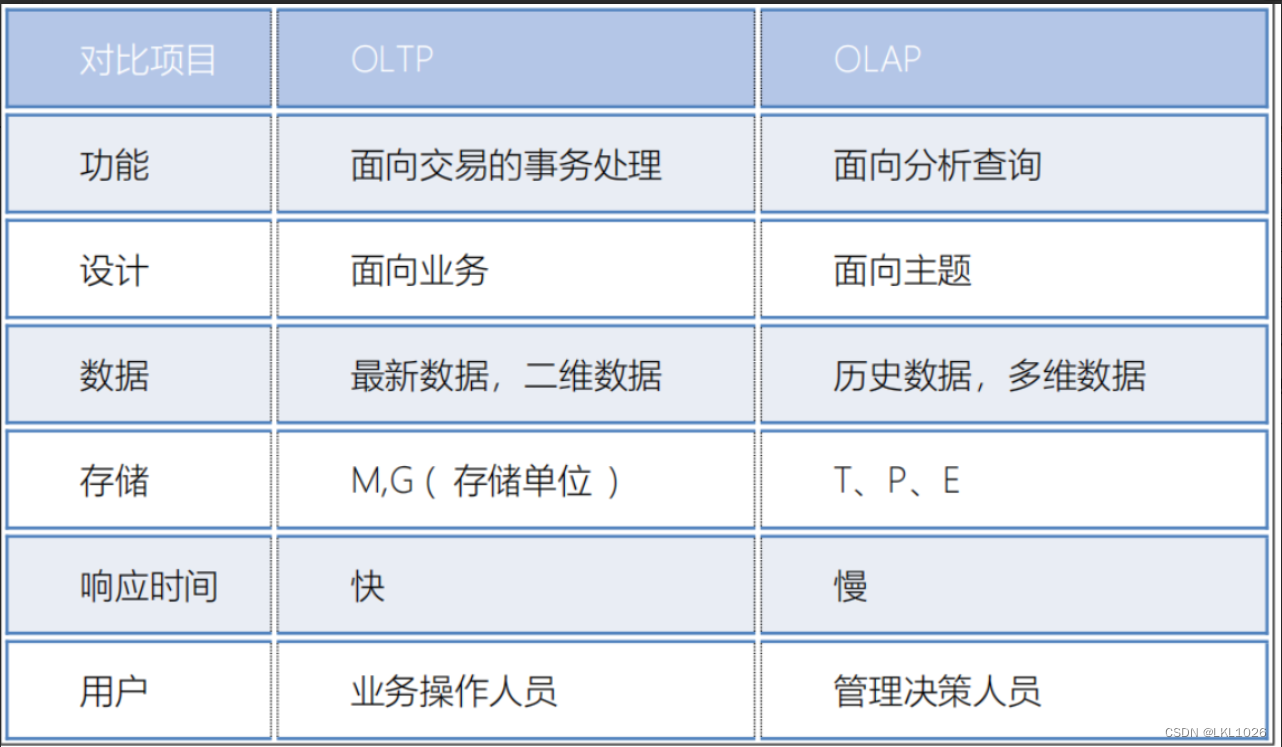
-
5- 什么是ETL:
ETL: 抽取 转换 加载
狭义上ETL:
指的数据从ODS层抽取出来, 对ODS层的数据进行清洗转换处理的操作, 将清洗转换后的数据加载到DW层过程
宽泛的ETL:
指的是数仓的全过程
-
6- 什么是数据仓库 和 数据集市
数据仓库是包含数据集市的, 在一个数据仓库中可以有多个数据集市
数据仓库: 一般指的构建集团数据中心, 基于业务形成各种业务的宽表或者统计宽表
数据集市: 基于部门或者基于主题, 形成主题或者部门相关的统计宽表
2. 数仓分层介绍
回顾:
ODS: 源数据层(临时存储层) 贴源层
作用: 对接数据源, 用于将数据源的数据完整的导入到ODS层中, 一般ODS层的数据和数据源的数据保持一致, 类似于一种数据迁移的操作, 一般在ODS层建表的时候, 会额外增加一个 日期的分区, 用于标记何时进行数据采集
DW: 数据仓库层
作用: 用于进行数据统计分析的操作, 数据来源于 ODS层
APP(DA|ADS | RPT |ST) : 数据应用层(数据展示层)
作用: 存储分析的结果信息, 用于对接相关的应用, 比如 BI图表
数仓分层的作用:
1- 清晰数据结构 2- 复杂问题简单化 3- 便于维护 4- 减少重复开发 5- 高性能
3. 数仓建模方案
3.1 关系模型
数据仓库之父 Bill Inmon 提出的建模方法是从全企业的高度,用实体关系(Entity Relationship,ER)模型来描述企业业务,并用规范化的方式表示出来,在范式理论上符合3NF。
-
关系模式: ER模型图
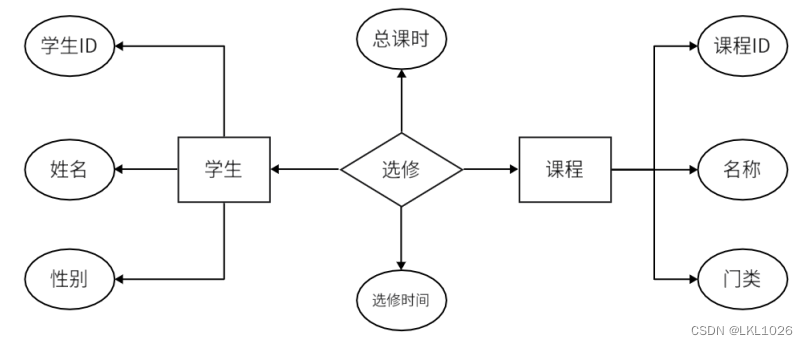
模型范式:
范式是关系模式满足不同程度的规范化要求的标准, 范式的目的是减少数据冗余,增强数据的一致性。遵循的范式级别越高,数据冗余性就越低。
-
第一范式(1NF): 如果关系模式R的每个关系r的属性都是不可分的数据项,那么就称R是第一范式的模式
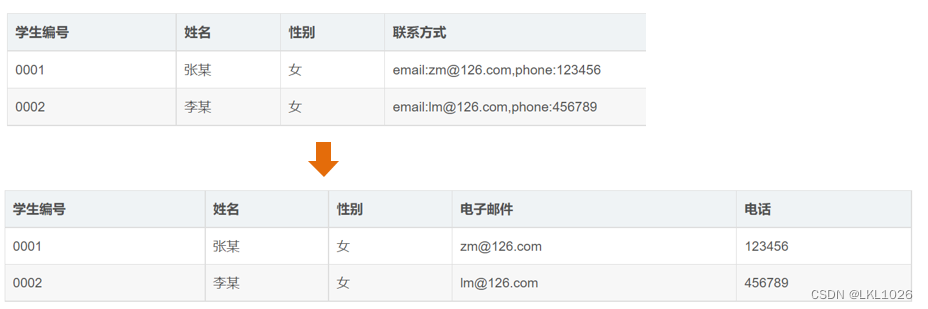
-
第二范式(2NF): 如果关系模式R是1NF,且每个非主属性完全函数依赖于候选键,那么就称R是第二范式。

-
第三范式(3NF): 首先要满足第二范式,其次非主属性之间不存在函数依赖。
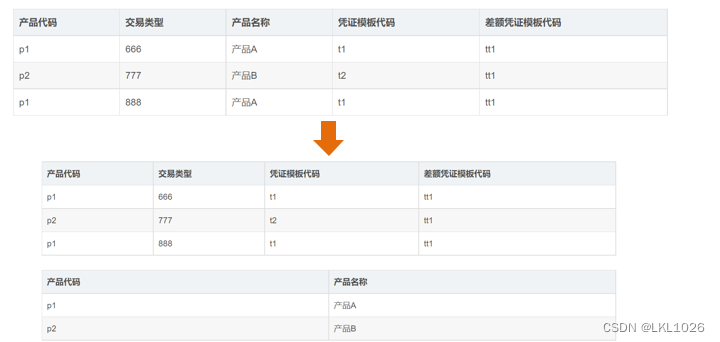
实体关系模型的基本假设是数据仓库的需求会发生变化,因此实体关系模型设计所要求的高度抽象、独立性,在面对频繁变化时体现出了其优势。另外,实体关系模型所遵循的三范式在减少数据冗余方面有天然优势,在数据量不断膨胀增长的背景下,规范化的数据模型对于降低不必要的数据存储十分有意义。
但是在面对现代OLAP模型中, 数据体量增大, 数据分析体系的完整形成, 关系模式也有着二大问题:
1) 实体关系模型对数仓建模者的视野有较高要求,需要对企业的业务系统和架构充分理解,因此模型构建在学习成本方面有一定的劣势。
2) 对于分析型需求来说,实体关系模型较为松散、零碎,物理表数量多,需要进行大量的关联、查询的性能问题非常凸显。
因此,实体关系模型在OLAP建设体系中更适合基础数据层的建设,目的是将各个系统中的数据以整个企业角度按主题进行相似性组合和合并,并进行一致性处理。
3.2 维度建模
维度模型将复杂的业务通过事实和维度两个概念进行呈现。事实通常对应业务过程,而维度通常对应业务过程发生时所处的环境。
什么是事实表:
事实表: 指的主题,要统计的主题是什么, 对应事实就是什么, 而主题所对应的表, 其实事实表
事实表一般是一堆主键(外键)的聚集
事实表一般是反应了用户某种行为表
比如说:
订单表, 收藏表, 登录表, 购物车表 ...
事实表分类:
事务事实表 : 最初始确定的事实表 其实就是事务事实表
周期快照事实表: 指的对数据进行提前聚合后表, 比如将事实表按照天聚合统计 结果表
累计快照事实表: 每一条数据, 记录了完整的事件 从开始 到结束整个流程, 一般有多个时间组成
什么是维度表:
维度表: 当对事实表进行统计分析的时候, 可能需要关联一些其他表进行辅助, 这些表其实就是维度表
维度表一般是由平台或者商家来构建的表, 与用户无关, 不会反应用户的行为
比如说: 地区表 商品表 时间表, 分类表...
维度表分类:
高基数维度表: 如果数据量达到几万 或者几十万 甚至几百万的数据量, 一般这样维度表称为高基数维度表
比如: 商品表 , 用户表
低基数维度表: 如果数据量只有几条 或者 几十条 或者几千条, 这样称为低基数维度表
比如: 地区表 时间表 分类表 配置表
数据发展模式y以及对应的模型
● 星型模型: ○ 特点: 只有一个事实表, 也就意味着只有一个分析的主题, 在事实表周围围绕了多张维度表, 维度表与维度表没有任何关联 ○ 数仓发展阶段: 初期 ● 雪花模型: ○ 特点: 只有一个事实表, 也就意味着只有一个分析的主题, 在事实表周围围绕了多张维度表, 维度表可以接着关联其他的维度表 ○ 数仓发展阶段: 异常, 出现畸形状态 在实际数仓中, 这种模型建议越少越好, 尽量避免这种模型产生 ● 星座模型: ○ 特点: 有多个事实表, 也就意味着有了多个分析的主题, 在事实表周围围绕了多张维度表, 在条件吻合的情况下, 事实表之间是可以共享维度表 ○ 数仓发展阶段: 中期 和 后期
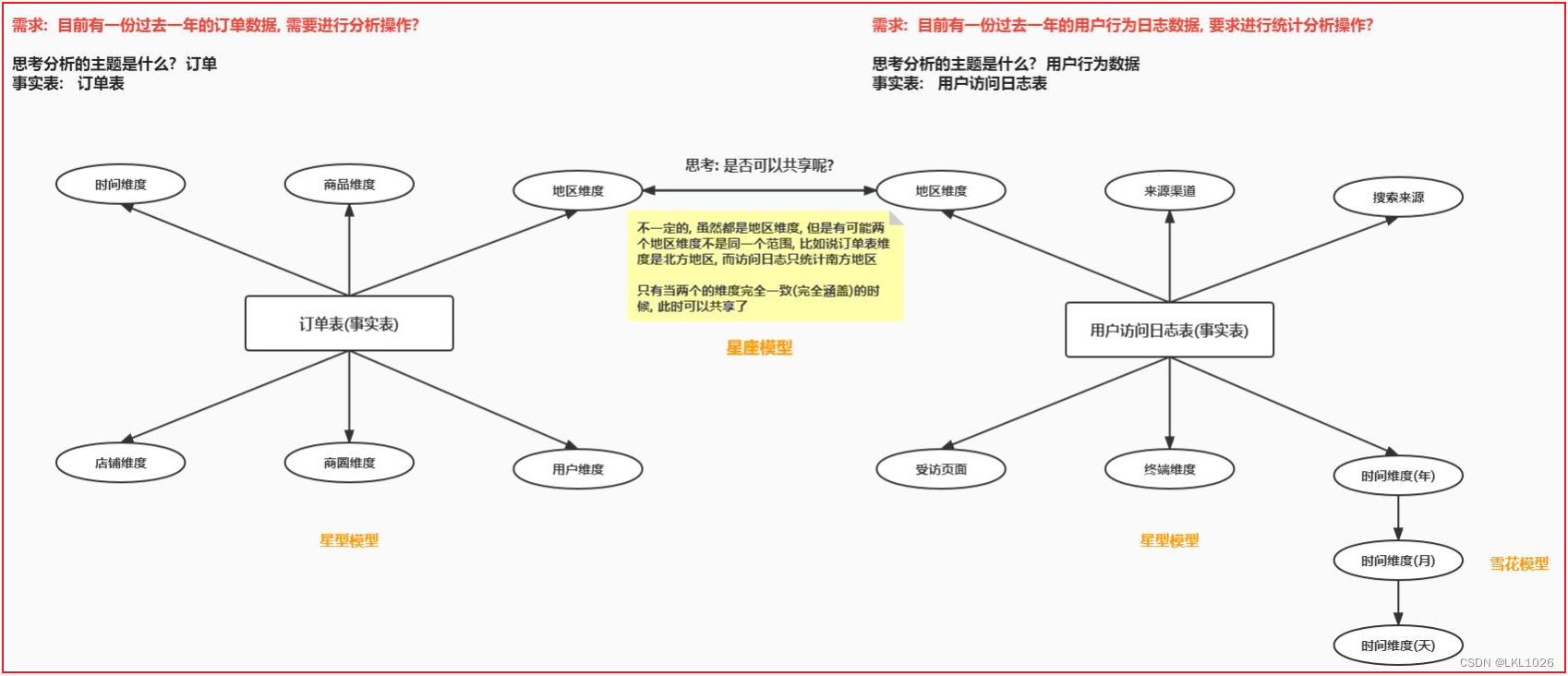
维度建模从需求出发,重点关注快速完成需求分析,围绕性能和易理解性构建模型,以事实表与维度表的形式重新组织数据。 在OLAP应用中主要有两大优势: 1):前期建模成本较低,从业务需求出发,快速迭代; 2):查询性能高,通过数据冗余降低查询的复杂度。 主要劣势: 数据冗余, 数据一致性维护增大 因此,从整体来说维度建模的开发和使用成本较低,但是维护成本较高,比较适合在接近业务分析的数据集市层、分析层来使用。
4.数仓建设规范
4.1 数据库划分规范
MySQL:dim/sale/member
SQL Server: order/stock
Hive:
dim:用于存放 维表 表信息及数据
ods:用于存放 ods层 表信息及数据
dwd:用于存放 dwd层 表信息及数据
dwm:用于存放 dwm层 表信息及数据
dws:用于存放 dws层 表信息及数据
ads:用于存放 ads层 表信息及数据
PostgreSQL: dm
4.2 表命名规范
命名规则: 分层_主题_实体+业务+维度_分区
分层:ods dwd dwm dws ads
主题:dim/sale/sold/sell/mem/shop/order/stock
数据域:dim/goods/category/store/marketing/saleorder/abnormal/pay/mem/shop/order
实体+业务+维度:
示例:
store_goods_statistics_day
store_member_statistics_day
分区:
i : 分区表(increment增量)
f : 全量表(full全量)
4.3 表字段类型规范
数量类型整数为:bigint 金额类型为:decimal(27, 2),表示:27位有效数字,其中小数部分2位 字符串(名字,描述信息等)类型为:string 日期类型为:string 时间类型为:timestamp
在实际中, 关于数据规范的处理形式
中小公司中: 一般通过文档约束的形式, 告知命名规范, 大家在建设过程中, 基于规范来建设即可 (从某种角度,即使你不这么建设, 其实也能创建成功的) 大型企业: 数据治理平台 (数据治理工程师) 元数据管理: 约束数仓建设的标准, 不断的检测程序员在建设过程中是否满足了规范要求, 如果不满足 治理平台会弹出警告, 并会通知相关人员进行处理
5.数仓建设方案
5.1 甄选数仓分层
回顾:
ODS: 源数据层(临时存储层) 贴源层
作用: 对接数据源, 用于将数据源的数据完整的导入到ODS层中, 一般ODS层的数据和数据源的数据保持一致, 类似于一种数据迁移的操作, 一般在ODS层建表的时候, 会额外增加一个 日期的分区, 用于标记何时进行数据采集
DW: 数据仓库层
作用: 用于进行数据统计分析的操作, 数据来源于 ODS层
APP(DA|ADS | RPT |ST) : 数据应用层(数据展示层)
作用: 存储分析的结果信息, 用于对接相关的应用, 比如 BI图表
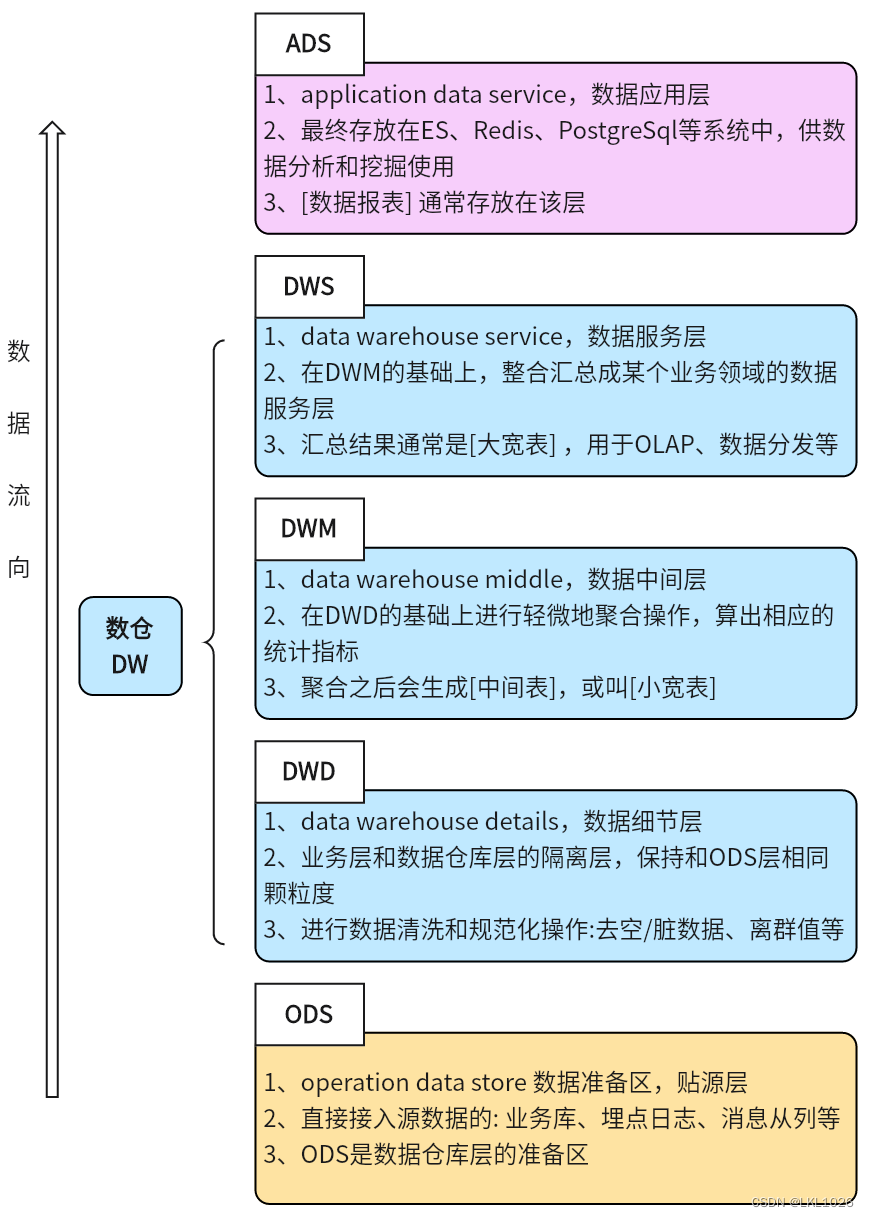
-
ODS层: 源数据层
-
作用: 对接数据源, 将数据源中数据加载到ODS层中, 形成一张张表, 一般和数据源中数据保持同样粒度(数据一致)
-
主要用于放置事实表数据, 和少量维度表数据
-
注意: 在导入到ODS层, 可能也会对数据进行预处理工作(清洗) -- 并不一定存在
-
例如:
1) 如果数据直接来源于MYSQL数据源, 可能一般不需要进行预处理工作 本身数据就是结构化数据 2) 如果数据直接来源于某个文件的, 可能需要对文件中数据进行判定, 如果有一些脏乱差的数据, 可能需要提前进行预处理工作, 转换为结构化数据
-
-
DW层: 数据仓库层
-
作用: 进行数据的分析工作 数据来源于ODS层
-
细化分层:
-
DWD层: 明细层
-
作用: 根据要分析的主题, 从ODS层抽取相关的数据, 对数据进行清洗转换处理工作, 然后将数据加载到DWD层, 一般将此层称为 大聚合层, 一般将所有相关的数据全部糅杂在一个表中, 在此过程中, 可以进行一定的维度退化操作
什么叫转换处理呢? 比如说: 对于时间而言, 在ODS表中有一个时间字段, 字段数据为: 2020-12-10 15:30:30 说明: 在ODS层这个时间字段上, 糅杂了太多字段数据, 包含 年 月 日 小时 分钟 秒 此时, 需要将字段导入到DWD层时候, 将其转换为 年 月 日 小时 ... -
-
DWM层: 中间层
-
作用: 主要是用于对DWD层进行进一步聚合操作, 同时此层可以进行维度退化的操作, 此层的表一般就是周期快照事实表
例如: 比如分析的维度中有时间维度: 需要分别计算 年 月 日 小时 可以先将数据按照 小时进行聚合操作, 形成一张按照小时聚合的表, 当需要按照日来聚合的时候, 只需要将每个小时数据进行累加在一起即可, 从而提升效率 -
-
DWS层: 业务层
-
作用: 主要对DWM层或者DWD层数据, 进行再次细化的聚合统计操作, 在此层需要针对各个维度都进行聚合统计结构了, 将所有维度统计的结果, 放置在一起, 形成宽表数据
-
注意: 此层一般就是最终分析结果的数据了
-
-
-
-
APP(DA/ADS/RPT)层: 数据应用层
-
作用: 主要是用于存储DW层分析之后的结果数据, 用于对接后续的应用(图表, 机器学习, 推荐 .....)
-
注意: 如果不需要在针对DWS层, 在此进行统计工作, 注意DWS层就是最终结果数据
什么时候需要使用APP层: 当DWS层统计结果, 被划分在多个不同结果表, 需要对DWS层数据进行再次的统计工作, 此时需要将统计的结果存储在APP层
-
-
DIM层: 维度层
-
作用: 存储维度表数据
-
说明: 当维度表较多的时, 建议将其放置在DIM层
-
5.2 建模设计
本项目ODS层使用关系建模开发,DW层和ADS层采用维度建模开发。

维度建模一般按照以下四个步骤:选择业务过程→声明粒度→确认维度→确认事实 1)选择业务过程 在业务系统中,挑选业务方感兴趣的业务线,比如下单业务,支付业务,退款业务,物流业务,一条业务线对应一张事实表。 2)声明粒度 数据粒度指数据仓库的数据中保存数据的细化程度或综合程度的级别。 声明粒度意味着精确定义事实表中的一行数据表示什么,应该尽可能选择最小粒度,以此来应各种各样的需求。 典型的粒度声明如下: 订单事实表中一行数据表示的是一个订单中的一个商品项。 支付事实表中一行数据表示的是一个支付记录。 3)确定维度 维度的主要作用是:描述业务的事实情况。主要表示的是“谁,何处,何时”等信息。 确定维度的原则是:后续需求中是否要分析相关维度的指标。例如,需要统计什么时间下的订单多,哪个地区下的订单多,哪个用户下的订单多。需要确定的维度就包括:时间维度、地区维度、用户维度。 4)确定事实 此处的“事实”一词,指的是业务中的度量值(次数、个数、件数、金额,可以进行累加),例如订单金额、下单次数等。 在DWD层,以业务过程为建模驱动,基于每个具体业务过程的特点,构建最细粒度的明细层事实表。事实表可做适当的宽表化处理。 事实表和维度表的关联比较灵活,但是为了应对更复杂的业务需求,可以将能关联上的表尽量关联上。
6.维度主题开发
6.1 维度表结构说明
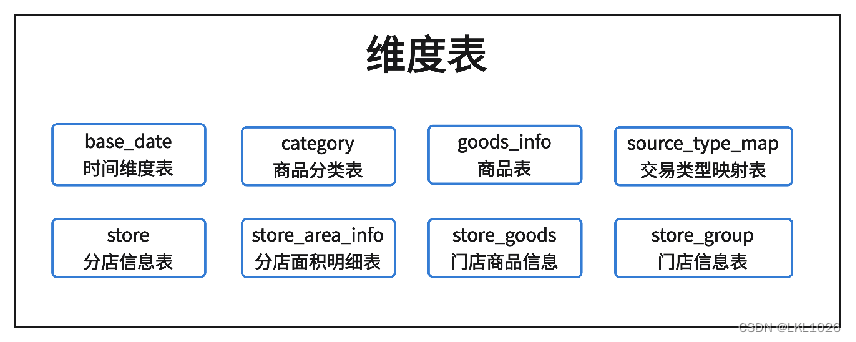
关系说明:

6.2 DWD层建表操作
DWD层: 明细层 根据要分析的主题, 从ODS层抽取相关的数据, 对数据进行清洗转换处理工作, 然后将数据加载到DWD层, 一般将此层称为大聚合层, 一般将所有相关的数据全部糅杂在一个表中,在此过程中,可以进行一定的维度退化操作. 维度层数据都是系统基础数据, 数据质量比较高, 顾一般不需要进行清洗处理操作
特别提示: 当在DWD层建表操作的时候, 如果明确未来一定不会用到此字段, 可以直接去除掉, 如果不明确建议保留(避免未来真的需要了, 需要重构表)
需要做的转换操作:
-
商品分类表(category): 需要进行分类拉平操作

-
商品表(goods_info): 将分类ID替换为对应一二三级分类ID、编码和名称

-
商品表(goods_info): 将分类ID替换为对应一二三级分类ID、编码和名称

降维操作:
-
门店表: 在门店宽表构建时,就添加了门店面积信息和区域名称信息,门店面积信息可以用来计算坪效等,区域名称信息可以用来上卷时显示区域名称。
-
其中门店面积信息可以从分店面积明细表中获取。先取实际经营面积,如果取不到(实际经营面积为空或0)再取经营面积。
-
其中区域名称信息从店组信息表中取,store_group_type_no = ‘04’即对应区域的编码和名称。
-
其中 store_type_code和management_type_code 需要转换为整数类型
-
新增表操作:
-
门店日清商品表: 需要在门店商品表的基础上筛选出日清数据, 便于后续统计日清数据指标
-
表结构与门店商品表一致
-

设计表:
-
内外表: 内部表
-
分区分桶: 不需要分区也不需要分桶
-
存储格式和压缩方案: ORC + Snappy
-
表字段选择:
-
DWD层需要保持相同的粒度, 所以主表中字段都需要保留, 合并降维的字段主要以核心为主
-
建表操作参考: dim建表-dwd.sql
CREATE TABLE dim.dwd_dim_date_f (
trade_date STRING COMMENT '日期编码',
year_code BIGINT COMMENT '年编码',
month_code BIGINT COMMENT '月份编码',
day_code BIGINT COMMENT '日编码',
quanter_code BIGINT COMMENT '季度编码',
quanter_name STRING COMMENT '季度名称',
week_trade_date STRING COMMENT '周一时间',
month_trade_date STRING COMMENT '月一时间',
week_end_date STRING COMMENT '周末时间',
month_end_date STRING COMMENT '月末时间',
last_week_trade_date STRING COMMENT '上周一时间',
last_month_trade_date STRING COMMENT '上月一时间',
last_week_end_date STRING COMMENT '上周末时间',
last_month_end_date STRING COMMENT '上月末时间',
year_week_code BIGINT COMMENT '一年中第几周',
week_day_code BIGINT COMMENT '周几code',
day_year_num BIGINT COMMENT '一年第几天',
month_days BIGINT comment '本月有多少天',
is_weekend BIGINT COMMENT '是否周末(周六和周日)',
days_after1 STRING COMMENT '1天后的日期',
days_after2 STRING COMMENT '2天后的日期',
days_after3 STRING COMMENT '3天后的日期',
days_after4 STRING COMMENT '4天后的日期',
days_after5 STRING COMMENT '5天后的日期',
days_after6 STRING COMMENT '6天后的日期',
days_after7 STRING COMMENT '7天后的日期'
)
comment '时间维度表'
row format delimited fields terminated by ','
stored as orc
tblproperties ('orc.compress'='SNAPPY');
CREATE TABLE IF NOT EXISTS dim.dwd_dim_store_i(
id BIGINT COMMENT '自增主键',
store_no STRING COMMENT '分店编号',
store_name STRING COMMENT '分店名称',
store_sale_type BIGINT COMMENT '门店销售类型',
store_type_code BIGINT COMMENT '分店类型',
city_id BIGINT COMMENT '城市ID',
city_name STRING COMMENT '城市名称',
region_code STRING COMMENT '区域ID',
region_name STRING COMMENT '区域名称',
worker_num BIGINT COMMENT '员工人数',
manager_name STRING COMMENT '经理姓名',
telephone STRING COMMENT '分店电话',
opening_date STRING COMMENT '开店日期',
open_time STRING COMMENT '营业开始时间',
close_time STRING COMMENT '营业结束时间',
`status` BIGINT COMMENT '状态 1:开店 2:闭店',
is_deleted BIGINT COMMENT '是否删除 0:否 1:是',
create_time TIMESTAMP COMMENT '创建时间',
update_time TIMESTAMP COMMENT '更新时间',
store_area DECIMAL(27,2) COMMENT '经营面积',
decoration_code STRING COMMENT '装修标识',
is_day_clear BIGINT COMMENT '是否日清,1-日清,0-非日清'
)
comment '门店表'
partitioned by (dt STRING COMMENT '写入日期')
row format delimited fields terminated by ','
stored as orc
tblproperties ('orc.compress'='SNAPPY');
CREATE TABLE IF NOT EXISTS dim.dwd_dim_category_statistics_i(
first_category_id BIGINT COMMENT '一级分类ID',
first_category_no STRING COMMENT '一级分类编码',
first_category_name STRING COMMENT '一级分类',
second_category_id BIGINT COMMENT '二级分类ID',
second_category_no STRING COMMENT '二级分类编码',
second_category_name STRING COMMENT '二级分类',
third_category_id BIGINT COMMENT '三级分类ID',
third_category_no STRING COMMENT '三级分类编码',
third_category_name STRING COMMENT '三级分类',
`status` BIGINT)
comment '分类等级表'
partitioned by (dt STRING COMMENT '写入日期')
row format delimited fields terminated by ','
stored as orc
tblproperties ('orc.compress'='SNAPPY');
CREATE TABLE IF NOT EXISTS dim.dwd_dim_goods_i(
goods_id BIGINT COMMENT '商品ID',
goods_no STRING COMMENT '商品编码',
goods_name STRING COMMENT '名称',
first_category_id BIGINT COMMENT '一级分类ID',
first_category_no STRING COMMENT '一级分类编码',
first_category_name STRING COMMENT '一级分类',
second_category_id BIGINT COMMENT '二级分类ID',
second_category_no STRING COMMENT '二级分类编码',
second_category_name STRING COMMENT '二级分类',
third_category_id BIGINT COMMENT '三级分类ID',
third_category_no STRING COMMENT '三级分类编码',
third_category_name STRING COMMENT '三级分类',
brand_no STRING COMMENT '品牌编号',
spec STRING COMMENT '商品规格',
sale_unit STRING COMMENT '销售单位',
life_cycle_status STRING COMMENT '生命周期状态',
tax_rate_status BIGINT COMMENT '税率审核状态 (0:未提交审核 1:待财务审核 2:税率已审核 3:未通过)',
tax_rate STRING COMMENT '税率code',
tax_value DECIMAL(27, 3) COMMENT '税率',
order_multiple DECIMAL(27, 2) COMMENT '订货倍数',
pack_qty DECIMAL(27, 3) COMMENT '箱装数量',
split_type STRING COMMENT '分割属性',
is_sell_by_piece BIGINT COMMENT '是否拆零,0:不拆;1:拆',
is_self_support BIGINT COMMENT '是否自营 0:非自营;1:自营',
is_variable_price BIGINT COMMENT '分店可变价 0:不可;1:可以',
is_double_measurement BIGINT COMMENT '是否双计量商品 0:否;1:是',
is_must_sell BIGINT COMMENT '必卖品 0:非;1:是',
is_seasonal BIGINT COMMENT '季节性商品 0:非;1:是',
seasonal_start_time STRING COMMENT '季节性开始时间',
seasonal_end_time STRING COMMENT '季节性结束时间',
is_deleted BIGINT COMMENT '是否删除0:正常;1:删除',
goods_type STRING COMMENT '商品类型 1-国产食品 2-进口食品 3-国产非食品 4-进口非食品',
create_time TIMESTAMP COMMENT '该记录创建时间',
update_time TIMESTAMP COMMENT '该记录最后更新时间')
comment '商品表'
partitioned by (dt STRING COMMENT '写入日期')
row format delimited fields terminated by ','
stored as orc
tblproperties ('orc.compress'='SNAPPY');
CREATE TABLE IF NOT EXISTS dim.dwd_dim_store_goods_i(
uid STRING COMMENT '唯一标识',
store_no STRING COMMENT '门店编码',
goods_no STRING COMMENT '商品编码',
goods_name STRING COMMENT '商品简称',
first_category_no STRING COMMENT '一级分类编码',
first_category_name STRING COMMENT '一级分类',
second_category_no STRING COMMENT '二级分类编码',
second_category_name STRING COMMENT '二级分类',
third_category_no STRING COMMENT '三级分类编码',
third_category_name STRING COMMENT '三级分类',
is_clear BIGINT COMMENT '商品是否日清,0-否,1-是',
is_must_order BIGINT COMMENT '是否必订品,0-否,1-是',
is_orderable BIGINT COMMENT '是否可订,0-否,1-是',
order_multiple DECIMAL(27,2) COMMENT '订货倍数',
min_order_qty DECIMAL(27,2) COMMENT '最小起订量',
vendor_no STRING COMMENT '主供应商编码',
vendor_name STRING COMMENT '主供应商名称',
group_no STRING COMMENT '采购柜组编码',
group_name STRING COMMENT '采购柜组名称',
dc_no STRING COMMENT '采购仓库编码',
dc_name STRING COMMENT '采购仓库名称',
tag BIGINT COMMENT '商品标识,1-传智鲜标品;2-黑马标品;3-生鲜品;4-其它',
create_time TIMESTAMP COMMENT '创建时间',
update_time TIMESTAMP COMMENT '最后修改时间',
is_deleted BIGINT COMMENT '是否删除0:正常;1:删除')
comment '门店商品信息'
partitioned by (dt STRING COMMENT '写入日期')
row format delimited fields terminated by ','
stored as orc
tblproperties ('orc.compress'='SNAPPY');
CREATE TABLE IF NOT EXISTS dim.dwd_dim_store_clear_goods_i(
uid STRING COMMENT '唯一标识',
store_no STRING COMMENT '门店编码',
goods_no STRING COMMENT '商品编码',
goods_name STRING COMMENT '商品简称',
first_category_no STRING COMMENT '一级分类编码',
first_category_name STRING COMMENT '一级分类',
second_category_no STRING COMMENT '二级分类编码',
second_category_name STRING COMMENT '二级分类',
third_category_no STRING COMMENT '三级分类编码',
third_category_name STRING COMMENT '三级分类',
is_clear BIGINT COMMENT '商品是否日清,0-否,1-是',
is_must_order BIGINT COMMENT '是否必订品,0-否,1-是',
is_orderable BIGINT COMMENT '是否可订,0-否,1-是',
order_multiple DECIMAL(27,2) COMMENT '订货倍数',
min_order_qty DECIMAL(27,2) COMMENT '最小起订量',
vendor_no STRING COMMENT '主供应商编码',
vendor_name STRING COMMENT '主供应商名称',
group_no STRING COMMENT '采购柜组编码',
group_name STRING COMMENT '采购柜组名称',
dc_no STRING COMMENT '采购仓库编码',
dc_name STRING COMMENT '采购仓库名称',
tag BIGINT COMMENT '商品标识,1-传智鲜标品;2-黑马标品;3-生鲜品;4-其它',
create_time TIMESTAMP COMMENT '创建时间',
update_time TIMESTAMP COMMENT '最后修改时间',
is_deleted BIGINT COMMENT '是否删除0:正常;1:删除')
comment '门店日清商品信息'
partitioned by (dt STRING COMMENT '写入日期')
row format delimited fields terminated by ','
stored as orc
tblproperties ('orc.compress'='SNAPPY');
CREATE TABLE IF NOT EXISTS dim.dwd_dim_source_type_map_i(
company STRING COMMENT '公司:1.传智鲜 2.黑马优选',
original_source_type BIGINT COMMENT '原交易来源 传智鲜1:线下pos;2:线上订单;3:扫码购;4:美团;5:饿了么;6:百度外卖;7:京东到家;8:有赞;9:传智鲜精品;10:黑马;11:团购',
original_source_type_name STRING COMMENT '原交易来源名称',
source_type BIGINT COMMENT '新交易来源:1',
source_type_name STRING COMMENT '新交易来源名称',
is_online BIGINT COMMENT '是否线上交易 0否;1是')
comment '交易类型映射表'
partitioned by (dt STRING COMMENT '写入日期')
row format delimited fields terminated by ','
stored as orc
tblproperties ('orc.compress'='SNAPPY');6.3 DWD层导入操作
6.3.1 时间维度表处理
此表, 不需要进行任何的处理, 直接将ODS层数据导入到DWD层即可
-- HIVE基础参数; 仅在当前会话生效
--hive压缩
--开启中间结果压缩
set hive.exec.compress.intermediate=true;
--开启最终结果压缩
set hive.exec.compress.output=true;
--写入时压缩生效
set hive.exec.orc.compression.strategy=COMPRESSION;
-- 时间维度表
insert overwrite table dim.dwd_dim_date_f
select
trade_date,
year_code,
month_code,
day_code,
quanter_code,
quanter_name,
week_trade_date,
month_trade_date,
week_end_date,
month_end_date,
last_week_trade_date,
last_month_trade_date,
last_week_end_date,
last_month_end_date,
year_week_code,
week_day_code,
day_year_num,
month_days,
is_weekend,
days_after1,
days_after2,
days_after3,
days_after4,
days_after5,
days_after6,
days_after7
from dim.ods_dim_date_f;6.3.2 商品分类表处理
需求说明:

分析如何做呢? 如果看不清, 移步到图片目录下
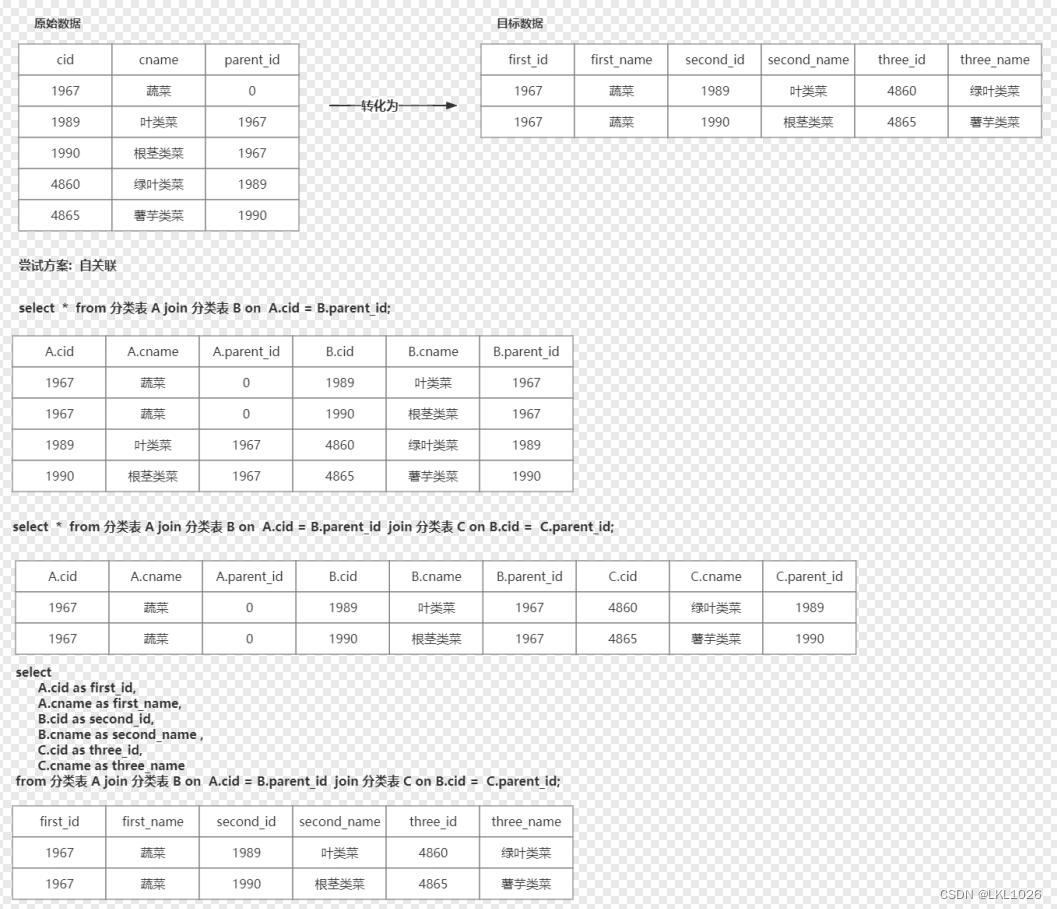
实现:
-- 开启动态分区方案
-- 开启非严格模式
set hive.exec.dynamic.partition.mode=nonstrict;
-- 开启动态分区支持(默认true)
set hive.exec.dynamic.partition=true;
-- 设置各个节点生成动态分区的最大数量: 默认为100个 (一般在生产环境中, 都需要调整更大)
set hive.exec.max.dynamic.partitions.pernode=10000;
-- 设置最大生成动态分区的数量: 默认为1000 (一般在生产环境中, 都需要调整更大)
set hive.exec.max.dynamic.partitions=100000;
-- hive一次性最大能够创建多少个文件: 默认为10w
set hive.exec.max.created.files=150000;
--hive压缩
--开启中间结果压缩
set hive.exec.compress.intermediate=true;
--开启最终结果压缩
set hive.exec.compress.output=true;
--写入时压缩生效
set hive.exec.orc.compression.strategy=COMPRESSION;
-- 分类表拉宽操作
insert overwrite table dim.dwd_dim_category_statistics_i partition (dt)
select
t1.id as first_category_id,
t1.category_no as first_category_no,
t1.category_name as first_category_name,
t2.id as second_category_id,
t2.category_no as second_category_no,
t2.category_name as second_category_name,
t3.id as third_category_id,
t3.category_no as third_category_no,
t3.category_name as third_category_name,
0 as status,
date_sub(current_date(),1) as dt
from dim.ods_dim_category_f t1
join dim.ods_dim_category_f t2 on t1.id = t2.parent_id
join dim.ods_dim_category_f t3 on t2.id = t3.parent_id;6.3.3 商品表处理
仅需要ods商品表 和 dwd分类表根据 分类id进行关联即可(三级分类ID)
insert overwrite table dim.dwd_dim_goods_i partition (dt)
select
t1.id as goods_id,
t1.goods_no,
t1.goods_name,
t2.first_category_id,
t2.first_category_no,
t2.first_category_name,
t2.second_category_id,
t2.second_category_no,
t2.second_category_name,
t2.third_category_id,
t2.third_category_no,
t2.third_category_name,
t1.brand_no,
t1.spec,
t1.sale_unit,
t1.life_cycle_status,
t1.tax_rate_status,
t1.tax_rate,
t1.tax_value,
t1.order_multiple,
t1.pack_qty,
t1.split_type,
t1.is_sell_by_piece,
t1.is_self_support,
t1.is_variable_price,
t1.is_double_measurement,
t1.is_must_sell,
t1.is_seasonal,
t1.seasonal_start_time,
t1.seasonal_end_time,
t1.is_deleted,
t1.goods_type,
t1.create_time,
t1.update_time,
date_sub(current_date(),1) as dt
from dim.ods_dim_goods_info_f t1
left join (select * from dim.dwd_dim_category_statistics_i where dt = date_sub(current_date(),1)) t2
on t1.category_no = t2.third_category_no;6.3.4 门店商品表处理
仅需要ods门店商品表 和 dwd分类表根据 分类id进行关联即可(三级分类ID)
insert overwrite table dim.dwd_dim_store_goods_i partition (dt)
select
t1.uid,
t1.store_no,
t1.goods_no,
t1.goods_name,
t2.first_category_no,
t2.first_category_name,
t2.second_category_no,
t2.second_category_name,
t2.third_category_no,
t2.third_category_name,
t1.is_clear,
t1.is_must_order,
t1.is_orderable,
t1.order_multiple,
t1.min_order_qty,
t1.vendor_no,
t1.vendor_name,
t1.group_no,
t1.group_name,
t1.dc_no,
t1.dc_name,
t1.tag,
t1.create_time,
t1.update_time,
t1.is_deleted,
date_sub(current_date(),1) as dt
from dim.ods_dim_store_goods_f t1
join (select * from dim.dwd_dim_category_statistics_i where dt = date_sub(current_date(),1)) t2
on t1.category_no = t2.third_category_no;6.3.5 日清门店商品表处理
当门店商品表处理完成后, 再次基础上, 通过 where is_clear = 1 即可
insert overwrite table dim.dwd_dim_store_clear_goods_i partition (dt)
select
uid,
store_no,
goods_no,
goods_name,
first_category_no,
first_category_name,
second_category_no,
second_category_name,
third_category_no,
third_category_name,
is_clear,
is_must_order,
is_orderable,
order_multiple,
min_order_qty,
vendor_no,
vendor_name,
group_no,
group_name,
dc_no,
dc_name,
tag,
create_time,
update_time,
is_deleted,
dt
from dim.dwd_dim_store_goods_i where dt = date_sub(current_date(),1) and is_clear = 1;6.3.6 交易类型映射表
此表与日期表处理模式一样
insert overwrite table dim.dwd_dim_source_type_map_i partition (dt)
select
company,
original_source_type,
original_source_type_name,
source_type,
source_type_name,
is_online,
date_sub(current_date(),1) as dt
from dim.ods_dim_source_type_map_f ;
6.3.7 门店表处理
需求说明:
-
门店表: 在门店宽表构建时,就添加了门店面积信息和区域名称信息,门店面积信息可以用来计算坪效等,区域名称信息可以用来上卷时显示区域名称。
-
其中门店面积信息可以从分店面积明细表中获取。先取实际经营面积,如果取不到(实际经营面积为空或0)再取经营面积。
-
其中区域名称信息从店组信息表中取,store_group_type_no = ‘04’即对应区域的编码和名称。
-
其中 store_type_code和management_type_code 需要转换为整数类型
-
思考的分析:

需求实现:
-- 门店宽表实现
with
t1 as (
select
store_no,
area_type_no,
area
from dim.ods_dim_store_area_info_f t1 where area_type_no = '8'
) ,
t2 as (
select
store_no,
area_type_no,
area
from dim.ods_dim_store_area_info_f t1 where area_type_no = '7'
) ,
t3 as (
select
store_no,
area_type_no,
area
from dim.ods_dim_store_area_info_f t1 where area_type_no = '1'
) ,
t4 as (
select
store_no,
area_type_no,
area
from dim.ods_dim_store_area_info_f t1 where area_type_no = '2'
) ,
t5 as (
select
coalesce(t1.store_no,t2.store_no,t3.store_no,t4.store_no) as store_no,
coalesce(t1.area_type_no,t2.area_type_no,t3.area_type_no,t4.area_type_no) as area_type_no,
coalesce(t1.area,t2.area,t3.area,t4.area) as area
from
t1 full join t2 on t1.store_no = t2.store_no
full join t3 on t2.store_no = t3.store_no
full join t4 on t3.store_no = t4.store_no
),
t6 as (
select
store_no,
collect_list(area_type_no)[0] as area_type_no,
collect_list(area)[0] as area
from t5 group by store_no
)
insert overwrite table dim.dwd_dim_store_i partition (dt)
select
t1.id,
t1.store_no,
t1.store_name,
cast(t1.management_type_code as bigint) as store_sale_type,
cast(t1.store_type_code as bigint) as store_type_code,
t1.city_id,
t1.city_name,
t1.region_code,
t2.store_group_name as region_name, -- 需要关联区域表
t1.worker_num,
t1.manager_name,
t1.telephone,
t1.opening_date,
t1.open_time,
t1.close_time,
t1.status,
t1.is_deleted,
t1.create_time,
t1.update_time,
t6.area as store_area, -- 需要关联分店面积明细表
t1.decoration_code,
if(t1.flag = 16,1,0) as is_day_clear,
date_sub(current_date(),1) as dt
from dim.ods_dim_store_f t1
left join dim.ods_dim_store_group_f t2 on t1.region_code = t2.store_group_no and t2.store_group_type_no = '04'
left join t6 on t1.store_no = t6.store_no;或者
-- 门店宽表实现
with t6 as (
select
store_no,
collect_list(area_type_no)[0] as area_type_no,
collect_list(area)[0] as area
from (
select
coalesce(t1.store_no,t2.store_no,t3.store_no,t4.store_no) as store_no,
coalesce(t1.area_type_no,t2.area_type_no,t3.area_type_no,t4.area_type_no) as area_type_no,
coalesce(t1.area,t2.area,t3.area,t4.area) as area
from
(
select
store_no,
area_type_no,
area
from dim.ods_dim_store_area_info_f t1 where area_type_no = '8'
) t1
full join
(
select
store_no,
area_type_no,
area
from dim.ods_dim_store_area_info_f t1 where area_type_no = '7'
) t2 on t1.store_no = t2.store_no
full join
(
select
store_no,
area_type_no,
area
from dim.ods_dim_store_area_info_f t1 where area_type_no = '1'
) t3 on t2.store_no = t3.store_no
full join
(
select
store_no,
area_type_no,
area
from dim.ods_dim_store_area_info_f t1 where area_type_no = '2'
) t4 on t3.store_no = t4.store_no
) t5 group by store_no
)
insert overwrite table dim.dwd_dim_store_i partition (dt)
select
t1.id,
t1.store_no,
t1.store_name,
cast(t1.management_type_code as bigint) as store_sale_type,
cast(t1.store_type_code as bigint) as store_type_code,
t1.city_id,
t1.city_name,
t1.region_code,
t2.store_group_name as region_name, -- 需要关联区域表
t1.worker_num,
t1.manager_name,
t1.telephone,
t1.opening_date,
t1.open_time,
t1.close_time,
t1.status,
t1.is_deleted,
t1.create_time,
t1.update_time,
t6.area as store_area, -- 需要关联分店面积明细表
t1.decoration_code,
if(t1.flag = 16,1,0) as is_day_clear,
date_sub(current_date(),1) as dt
from dim.ods_dim_store_f t1
left join dim.ods_dim_store_group_f t2 on t1.region_code = t2.store_group_no and t2.store_group_type_no = '04'
left join t6 on t1.store_no = t6.store_no;