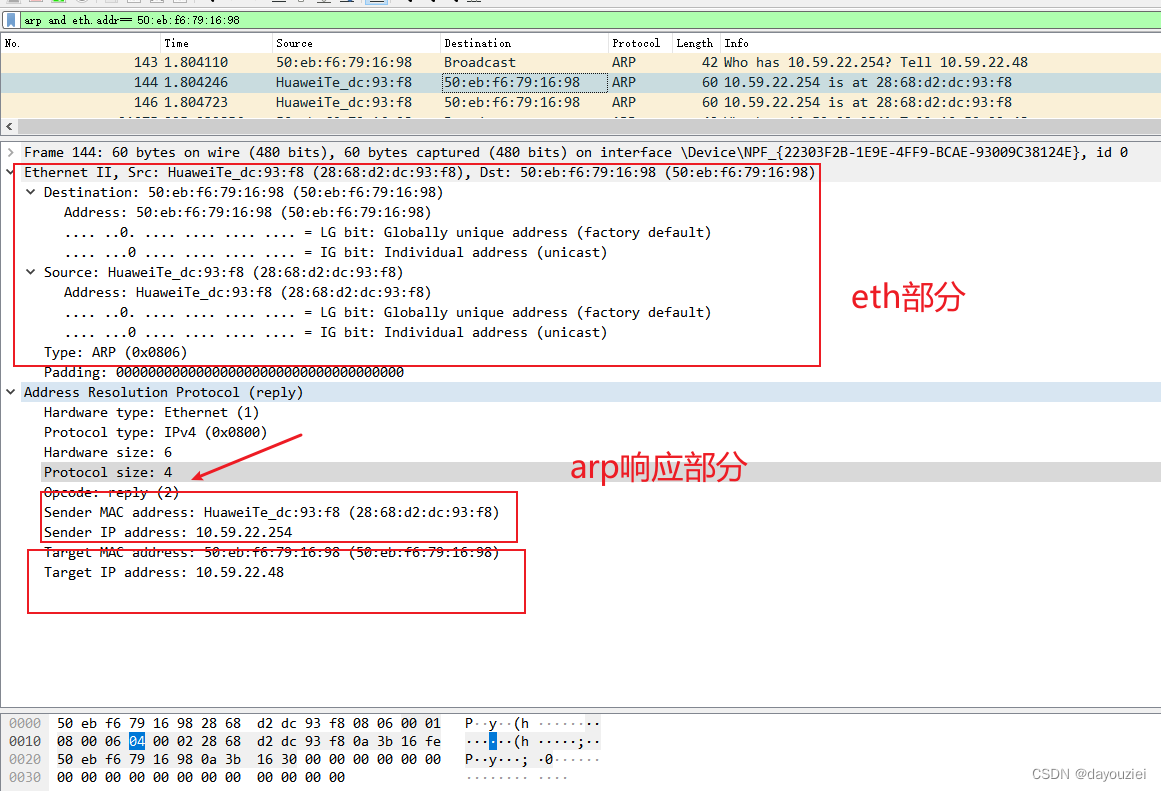
讲解 MySQL 中索引、触发器、存储过程、存储函数的使用
文章目录
- 1. 索引
- 1.1 索引的分类
- 1.2 索引的设计原则
- 1.3 如何使用(create index)
- 2. 触发器
- 2.1 触发器的分类
- 2.2 如何使用(create trigger)
- 3. 存储过程
- 3.1 如何使用(create procedure)
- 3.1.1 存储过程主体
- 4. 存储函数
- 4.1 与存储过程的区别
- 4.2 如何使用(create function)
1. 索引
-
索引是一种特殊的数据结构。(就像书的目录一样)
-
索引是提高数据库性能的重要方式,所有字段都可以添加索引。
给某个字段添加索引,就相当于给这个字段添加目录,下次再通过这个字段查的时候,就会直接找到该位置,而不是从头开始查。
-
使用索引,可以快速查询表中的记录。但索引会占用内存空间
1.1 索引的分类
1、普通索引:不需要任何限制条件的索引,可在任意数据类型上创建
2、唯一索引:添加索引的字段,该字段的值必须唯一,比如:主键索引
3、全文索引:针对文本类型。只能创建在 char、varchar、text 数据类型的字段上
实际应用: 查询数据量较大的字符串类型的字段时,使用全文索引可以提高速度。但 InnoDB (mysql默认的数据存储引擎)不支持全文索引
4、单列索引:只对应一个字段的索引
5、多列索引:在一张表的多个字段上创建一个索引
注意: 多列索引,查询时只需要使用第一个字段即可触发索引。
6、空间索引:只能建立在空间数据类型上(比如:GIS(地理信息系统),因为地理信息的数据就是空间数据,描述的是空间位置,如经纬度)
注意: InnoDB 不支持空间索引
主键自带索引,其它字段可以手动添加索引(但一般不会添加)
1.2 索引的设计原则
1、添加索引时,是出现在 where 语句中的字段,不是 select 后面要查询的字段。
select name from user where id=1; -- 给id添加,而不是给name
2、添加索引的字段,这一列的值尽量唯一,效率更高(因为本身就是通过这个值查询的,而现在有多个,还需要判断是哪个)
3、不要添加过多的索引,因为索引占用内存空间,没有用的索引也占用,所以维护成本高。
通常情况下,就用主键自带的索引
1.3 如何使用(create index)
-- 1. 添加索引:索引名可自定义,一般为:idx_添加索引的字段名
-- 方式一:
alter table 表名 add index 索引名(字段名);
-- 方式二(推荐):
create index 索引名 on 表名(字段名);
-- 2. 删除索引
-- 方式一:
alter table 表名 drop index 索引名;
-- 方式二(推荐):
drop index 索引名 on 表名;
2. 触发器
1、触发器中定义了一系列操作,在对指定的表进行 插入、更新或删除 (没有查询)的同时自动执行这些操作。触发器是不需要调用的
2、为什么有这个机制?
举个例子:因为有些时候对一个表的操作,不仅仅是单表,还有跟它关联的其它表,比如:删除一个班级的时候,你在班级表中把对应的班级删除了,但是学生你也应该进行相应的操作,因为班级都没有了,这个学生对应的班级也就没有了。所以触发器中就可以定义这些操作。
3、触发器的优点:
-
开发更快。因为触发器是存储在数据库中的,在应用程序中不用每次都编写触发器中的操作。
比如:不需要每次删一个班级,你就要编写对学生操作的 SQL
-
更容易维护。定义触发器后,访问目标表会自动调用触发器。
比如:假如关联的不是学生了,是教师,怎么办?那只需要修改触发器中的内容即可
-
业务的全局实现。如果修改业务代码,只需要修改触发器。
就是不需要改 Java 程序中的代码,只需要修改触发器即可
2.1 触发器的分类
- 前置触发器: 在 更新或插入 操作之前执行,关键字为:before
- 后置触发器: 在 更新、插入或删除 后执行,关键字为:after
- before delete 触发器: 在 删除之前 执行,关键字为:before delete
- insted of 触发器: 对复杂的视图执行 插入、更新、删除时执行,关键字为:insted of
2.2 如何使用(create trigger)
1、创建
create trigger 触发器名(可自定义:一般为t_触发器类型操作名称_on_哪个表)
触发时刻 什么操作 on 哪个表上制定触发器 for each row
触发器需要执行的操作
触发器需要执行的操作:如果要执行多个语句,可使用:begin 语句 end
提示:触发器需要执行的操作,这一部分肯定包含多个语句,每个语句都是以分号结尾,这时服务器处理程序的时候遇到第一个分号就会认为程序结束,这肯定不行。所以使用
delimiter 结束符号(比如:$$)命令讲 MySQL 中的结束标志修改为其它符号。最后使用opdelimiter ;或者delimiter ;恢复即可。比如:delimiter $$ create trigger t_afterInsert_on_tab1 after insert on tab1 for each row begin insert into tab2(name,age) values(new.name,new.age); end$$ delimiter;假如运行不报错,结果也符合预期,一般不需要设置。
例1: 给 tab1 表添加一条数据后,然后 tab2 表自动添加这个数据:
create trigger t_afterInsert_on_tab1
after insert on tab1 for each row
begin
insert into tab2(name,age) values(new.name,new.age);
end;
这样执行 insert into tab1(name,age) values('abc',23); 后,tab2 表中也有数据了。
注意:
① new.字段名 用来引用新行的一列,old.字段名 用来引用更新或删除它之前的已有行的一列。
② 对于 insert,只有 new 是合法的,对于 delete,只有 old 是合法的,对于 update,new、old
都合法。
例2: 删除 tab1 表的后,然后 tab2 表也删除:
create trigger t_afterDelete_on_tabl
after delete on tab1 for each row
begin
delete from tab2 where tab2.id = old.id;
end;
这样执行 delete from tab1 where id=2; 后,tab2 表中对应 id=2 的数据也删除了。
2、删除触发器:drop trigger 触发器名;
3. 存储过程
在实际开发中用的比较多的一种方式
1、存储过程是一组为了完成特定功能的 SQL 的集合。经过编译后存储在数据库中,用户可以通过存储过程的名称调用(可传参)。
跟触发器有点像,但是触发器需要有一张目标表。存储过程跟 java 中的方法一样,可以根据需要调用。
2、一次编写,多次调用,避免重复编写相同的SQL,存储过程和函数(函数:跟存储过程类似)都是在数据库执行的,可以减少 java 程序和数据库之间的数据传输,提高效率。
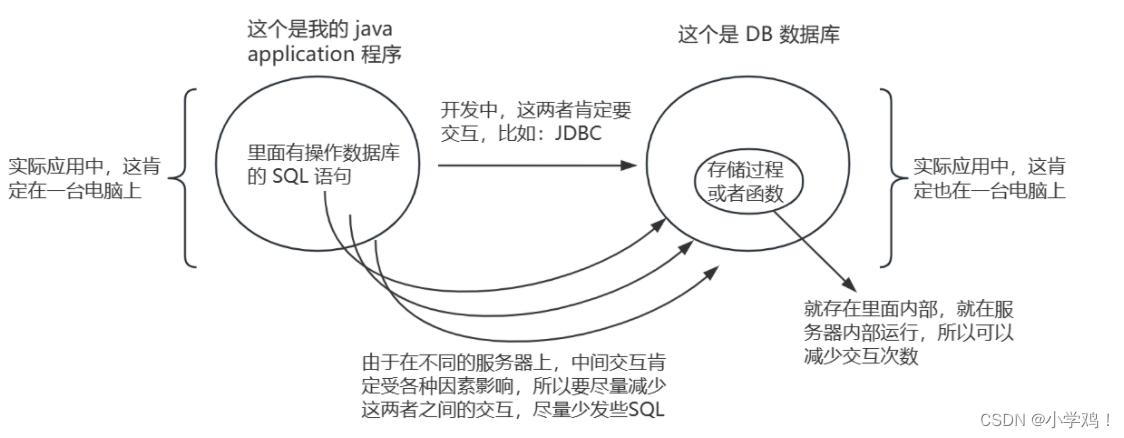
3、存储过程的优点:
- 模块化程序设计。把一些语句组装在一起。
- 执行速度更快。如果某个操作需要执行大量的 SQL,存储过程比直接执行 SQL 效率更高(假如 SQL 重复,对于重复的 SQL,存储过程优势更为明显)
- 更好的安全机制。对于没有权限存储过程的用户,可以通过授权的方式执行存储过程。
3.1 如何使用(create procedure)
1、创建
create procedure 存储过程名([参数,...])
存储过程主体
参数: 不加参数时,存储过程后面的括号不可省略。三部分组成:[in|out|inout] 参数名 参数类型
-
in 输入参数。可以使数据传递给一个存储过程
-
out 输出参数。当需要返回一个答案或结果的时候,存储过程使用输出参数
3.1.1 存储过程主体
存储过程主体: 指在调用存储过程的时候必须执行的语句。如果要执行多个语句,可使用:begin 语句 end
注意:存储过程主体中也有可能包含多个 SQL 语句。同理:只要运行不报错,结果也符合预期,一般不需要修改结束标志。
下面的内容只能使用在存储过程体中:
① 声明局部变量
在存储过程中可以声明局部变量,用来存储临时结果。语法:declare 变量名,... 变量类型 [default 默认值] ,比如:declare num int default 5; 或者 declare num int; 或者 declare str1,str2 varchar(10);
-
局部变量只能在
begin ... end语句中使用,而且必须在存储过程的开头。 -
给局部变量赋值:
set 变量名=表达式; -- 多个 set 变量名=表达式, 变量名=表达式,...;
② select into 语句
把选定的列值直接存储到变量中。如:select 姓名,专业名 into name,project
例子: 总计数据总数后并返回
create procedure countNum(out num int)
begin
select count(*) into num from tab1;
end;
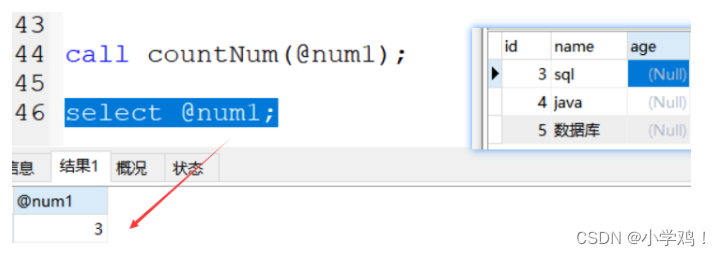
-- 问题1:怎么调?
call countNum(@num1);
-- 其中 @num1 就是定义一个变量来接收返回的结果,@用来定义用户变量
-- 问题2:怎么查看结果?
select @num1;
③ 流程控制语句
-
if 语句
if 条件 then 语句 [elseif 条件 then 语句] .... [else 语句] end if;例子: 根据传进来的值,选择判断后,存入表格
create procedure addData(in target int) begin declare addName varchar(10); -- 赋值 if target=1 then set addName="java"; elseif target=2 then set addName="sql"; else set addName="数据库"; end if; -- 插入 insert into tab1(name) values(addName); end;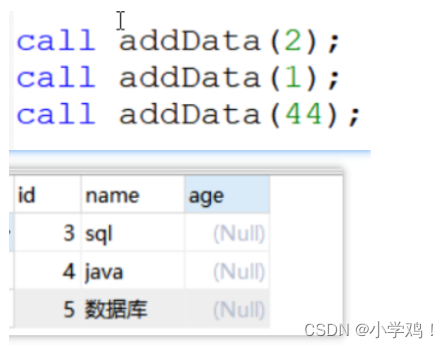
-
case 语句。与之前的分支查询稍微不同
case 要判断的值或表达式 when 与判断的值做比较的值 then 语句 [when 与判断的值做比较的值 then 语句] [else 语句] end case; -- 或者(推荐) case when 条件 then 语句 ... [else 语句] end case; -
循环语句。MySQL 支持 3 中循环:while、repeat、loop。循环开始标识 和 循环结束标识 要有都有,要没有都没有,且自定义的名字要一样。
[循环开始标识:] while 条件 do 语句 end while [循环结束标识]; ============= [循环开始标识:] repeat 语句 until 条件 end repeat [循环结束标识]; ============= [循环开始标识:] loop 语句 end loop [循环结束标识];问题:怎么跳出循环?----> leave(类似 break)、iterate(类似 continue)比如:
create procedure doloop() begin set @a=10; -- @a就是用户变量(前面有@标识) label: loop set @a=@a-1; if @a<0 then leave label; -- 满足条件后跳出循环 end if; end loop label; -- 要有都有 end;
2、调用存储过程:call 存储过程名([参数]);
3、删除存储过程:drop procedure 存储过程名;
4. 存储函数
存储函数与存储过程非常相似
4.1 与存储过程的区别
- 存储函数不能有输出参数,参数只能为 in(可以省略,所以存储函数的参数只有名称和类型)。
- 不能用 call 语句来调用存储函数。而是 select 语句。
- 存储函数必须包含一条 return 语句(也就是函数必须有返回值),而存储过程不允许包含
4.2 如何使用(create function)
1、创建
create function 存储函数名([参数,...])
returns type
存储函数主体
其中:returns type 声明函数返回值的数据类型,比如:
-- 通过id查询名字并返回
create function name_student(student_id int)
returns int
begin
return(select name from tab1 where id=student_id);
end;
begin 里面的 return 就是需要返回的东西,所以将内容放到 () 里面。也可以直接 return ,比如:return true; 或者 return '123';
2、调用:select 存储函数名([参数]);
3、删除:drop function 存储函数名;