用Python批量处理Excel文件,实现自动化办公
一、具体需求
有以下N个表,每个表的结构一样,如下:
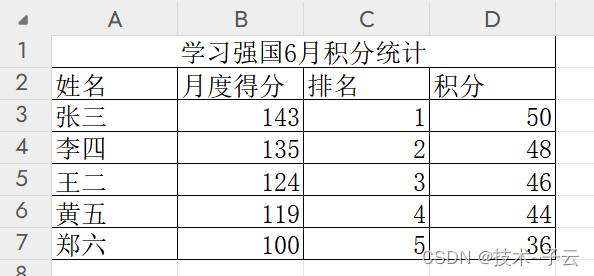
需要把所有表数据汇总,把每个人的得分、积分分别加起来,然后按总积分排名,总积分一致时,名次一致且非连续排序;积分一致的前提下,按总得分降序展示,但不改变排名,结果如下:

二、Python开发
1、导入所需的包
import pandas as pdimport glob
2、获取所有Excel文件的文件路径
excel_files = glob.glob("./样例数据/*.xlsx")3、将各表数据合并到主DataFrame
# 初始化一个空DataFramemerged_df = pd.DataFrame()# 循环读取每个Excel文件并合并到DataFramefor file in excel_files:df = pd.read_excel(file, header=1) # 读取Excel文件,跳过第一行数据merged_df = merged_df._append(df, ignore_index=True) # 合并到主DataFrame
4、计算总积分和总排名
merged_df['总得分'] = merged_df.groupby('姓名')['月度得分'].transform('sum') # 计算得分总和merged_df['总积分'] = merged_df.groupby('姓名')['积分'].transform('sum') # 计算积分总和merged_df.drop_duplicates(subset=['姓名', '总积分'], keep='first', inplace=True) # 去重
5、以总积分排名
merged_df['总排名'] = merged_df['总积分'].rank(ascending=False, method='min')6、按总积分列的值进行排序,重置索引
merged_df = merged_df.sort_values(by=['总积分','总得分'], ascending=[False,False]).reset_index(drop=True)7、获取需要输出的结果
result_df = pd.DataFrame()result_df = merged_df.loc[:, ['姓名','总得分','总积分','总排名']].copy()
8、将合并后的DataFrame输出到一个新Excel文件
result_df.to_excel("总积分及排名.xlsx", index=False)汇总代码展示如下
import pandas as pd
import glob
excel_files = glob.glob("./样例数据/*.xlsx")
# 初始化一个空DataFrame
merged_df = pd.DataFrame()
# 循环读取每个Excel文件并合并到DataFrame append() 方法在DataFrame的末尾添加一行或一列数据 新版本修改为 _append()
for file in excel_files:
df = pd.read_excel(file, header=1) # 读取Excel文件,跳过第一行数据
merged_df = merged_df._append(df, ignore_index=True) # 合并到主DataFrame
merged_df['总得分'] = merged_df.groupby('姓名')['月度得分'].transform('sum') # 计算得分总和
merged_df['总积分'] = merged_df.groupby('姓名')['积分'].transform('sum') # 计算积分总和
merged_df.drop_duplicates(subset=['姓名', '总积分'], keep='first', inplace=True) # 去重
merged_df['总排名'] = merged_df['总积分'].rank(ascending=False, method='min')
merged_df = merged_df.sort_values(by=['总积分','总得分'], ascending=[False,False]).reset_index(drop=True)
result_df = pd.DataFrame()
result_df = merged_df.loc[:, ['姓名','总得分','总积分','总排名']].copy()
result_df.to_excel('./样例数据/总排名.xlsx', index=False)







![[C++历练之路]优先级队列||反向迭代器的模拟实现](https://img-blog.csdnimg.cn/8475506697b048c4b924ed996f92cf5c.png)