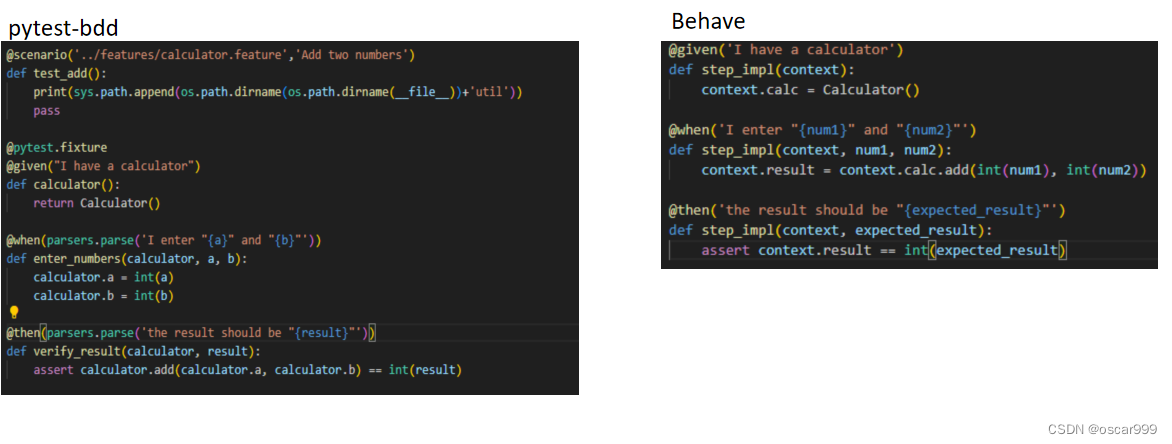
一、简要介绍

大型语言模型(LLMs)中的上下文学习(ICL)已经成为一种强大的新的学习范式。然而,其潜在的机制仍未被很好地了解。特别是,将其映射到“标准”机器学习框架是具有挑战性的,在该框架中,人们使用训练集S在某些假设类中找到最佳拟合函数f (x)。在这里,论文通过展示ICL学习到的函数通常有一个非常简单的结构:它们对应于transformerLLM,它的唯一输入是查询x和从训练集计算出的单个“任务向量”。因此,ICL可以看作是将S压缩为一个单个的任务向量θ(S),然后使用这个任务向量来调制transformer以产生输出。论文通过对一系列模型和任务的全面实验来支持上述主张。
二、研究背景
大型语言模型在过去的几年中有了显著的改进。这些模型的一个显著特性是,它们可以从很少的演示中学习新的规则。例如,一个模型可以提示输入“苹果→红色,石灰→绿色,玉米→”,并产生输出“黄色”。因此,该模型仅学习了一个基于两个例子的映射,它可以正确地应用于新的例子。这种能力,被称为上下文学习(ICL),已被广泛使用,产生了令人印象深刻的实证结果。


目前还不清楚ICL是否以这种方式运行,因为预测是通过T([S,x])执行的,其中T通常是一个自回归transformer,而[S,x]是S和x中的令牌的连接。因此,在一般情况下,它可以是一个任意的函数,通过这个函数来产生输出。这可以包括“非参数”方法,如最近邻方法。最近的工作已经开始探索这个问题。例如,研究表明,当从头训练transformer在上下文中执行线性回归时,新兴的学习算法类似于随机梯度下降。然而,对于执行更复杂的自然语言任务的LLM,论文根本不清楚假设空间可能是什么。

论文的观点也与软提示有关,因为这两种方法都针对特定的任务调节transformer的功能。然而,在ICL中,任务向量是通过正向传递来计算的,而不是进行微调。
论文的贡献包括提出一个基于假设类的ICL机制观点,并进行实验来验证论文对一系列公开的LLM和一组不同的任务的看法。论文的研究结果进一步加深了对ICL的理解,并可能对LLM有效适应执行特定任务具有实际意义。
三、ICL的假设类视图(A Hypothesis Class View of ICL)
受学习理论的假设类观点的启发,论文的目标是了解ICL是否将演示集S映射到查询x上的一个函数,以及这个映射是如何发生的。具体来说,论文试图看看ICL是否将S转换为θ——某个假设空间内的函数的“参数”。论文的实证研究结果表明,这一观点是适用的,阐明了假设空间的结构,其中ICL可以被看作是运作的。
3.1理论框架
论文使用T表示仅限解码器的transformerLLM,S表示用作ICL输入的演示集(即训练示例)集,x表示要求ICL提供输出的查询。论文使用T([S,x])来表示ICL在S和x的连接上的输出。
为了证明ICL在一个假设空间内运作,论文的目的是证明其潜在的机制可以分为两部分:
一种“学习算法”(用A表示),它将S映射到一个“任务向量”θ,独立于查询x。考虑到注意层可以同时访问S和x,这种独立性并非简单。
一个“规则应用程序”(用f表示),它基于θ≡A (S)将查询x映射到输出,而不直接依赖于S。同样,这种独立性并非简单。
因此,论文考虑从一组演示和查询到预测输出的以下映射:

3.2一个被提出的假设类
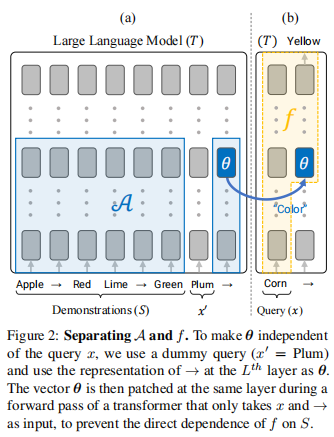
上述框架有许多可能的实现,它们对应于A和f的不同选择。接下来,论文将描述论文所关注的实现,这自然地遵循transformer架构。论文考虑一个如图1所示的ICL设置,其中输入以一个查询x(即Corn)结束,后面跟着一个“→”符号。如上所述,论文认为学习由两个步骤组成:基于训练样本S计算一个参数向量θ,并将由该参数向量定义的规则应用于查询x。对于transformer来说,一个大概简单的方法是让→表示的第一个L层计算θ,然后让剩下的层将θ和x作为输入并产生一个输出。见图1。回想一下,S和x在任何层都可以访问transformer,这对论文的观点是一个挑战。

在下面的章节中,作者将解决这个挑战,并提出实验来验证论文的观点。也就是说,论文证明了可以在执行ICL的LLMs的正向传递中隔离A和f。论文还表明,θ向量是可解释的,并对应于学习到的任务。
四、假设类视图的有效性(Validity of the Hypothesis Class View)
论文首先证明,将前向传递分离成3.2中定义的两个不同的分量A和f,保持了ICL的高精度。
4.1分离A和f
论文在常规的正向传递中面临着一些挑战:首先,对应于A的初始L层,更新→的表示来创建θ,可以处理查询x。因此,它们可能依赖于x,产生θ对x的不必要的依赖。第二,对应于f的其余层可以直接访问S,而不是只使用x和θ。

4.2任务和模型
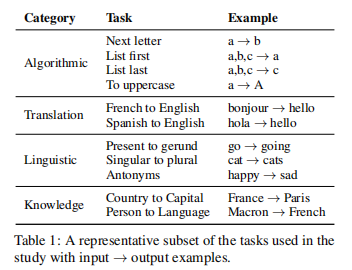
论文考虑了横跨4个类别的18个任务:算法、翻译、语言和事实知识。为简单起见,论文将自己限制在单令牌输出中。在表1中描述了这些任务的一个具有代表性的子集。A.1提供了一个完整的详细表,以及关于数据的更多信息。
论文使用多个开放LLMs: LLaMA 7B、13B、30B和Pythia 2.8B、6.9B和12B。
4.3查找L
论文在3.2中描述的机制有一个自由参数——a结束和f开始的L层。论文使用不同选择L的(A,f)实现,并在开发集上评估准确性,以找到最佳层。
图3显示了L不同选择的开发集上的精度。论文在这里关注LLaMA模型。有趣的是,所有模型在相似的中间层都表现出性能峰值,而不管它们的参数和层数差异。
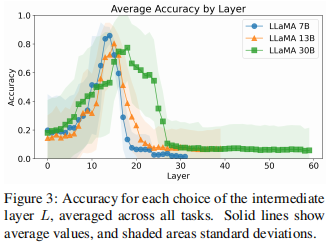
4.4基于假设的预测的准确性
接下来,论文比较(A,f)机制与执行ICL的准确性。对于每个模型和任务,论文评估了以下三个过程:
常规:LLM对演示S和查询x的应用程序。即T([S,x]),如常规ICL。
假设:论文从4.1中提出的过程,其中A使用一个虚拟x'生成θ,f(·;θ)通过在[x,→]上运行transformer,并在→的L层打θ补丁。
基线:LLM仅在x上的向前传递,没有演示s,即T([x,→])。这与论文分离的程序中f的应用相同,但没有修补θ。
图4显示了每个模型的所有任务的平均精度。完整的结果将在表6和A.2中报告。在所有模型中,论文的程序保持了常规ICL的80-90%左右的准确性,而基线仅达到10-20%。这表明论文提出的A和f分离提供了ICL的过程很好的经验近似。
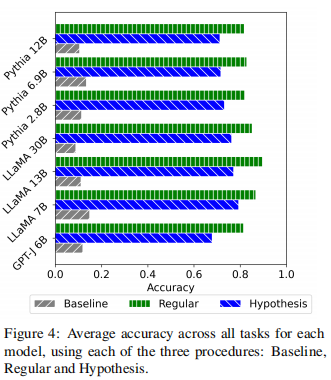
五、任务向量的鲁棒性(Robustness of Task Vectors)
在论文的设置中,θ来自于S和一个虚拟查询x'。检查θ对这些输入的变化的鲁棒性是很自然的。直观地说,如果它代表任务,它应该在不同的S和x'值之间保持稳定。
为了验证这一点,论文使用LLaMA 7B生成每个任务50个不同的任务向量,并进行了两次分析。
θ的几何形状 t-SNE降维(图5)显示,任务向量形成了不同的集群,每个集群都包含单个任务的任务向量。图9进一步显示了同一类别任务之间的接近性,强化了它们封装任务理解的概念。

θ的可变性 图8显示了任务内和任务之间的距离的直方图。可以看出,同一任务中的向量比不同任务之间的向量更接近,说明θ在任务中是稳定的,不受x'或S的高度影响。
六、θ补丁的控制(Dominance of θ Patching)
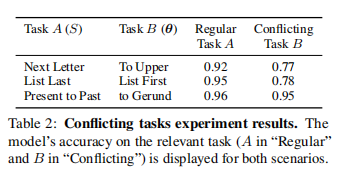
论文阻止f直接访问S。然而,在ICL的常规向前传递中,最后一个令牌可以注意到S。论文验证了即使在这种情况下,f主要使用任务向量θ,而没有直接访问演示S。论文使用一对任务,a和B,共享输入空间但不同的输出。论文首先使用一个“常规”向前传递,其中论文为模型提供了任务A(表示为SA)的演示S,以验证模型是否可以使用ICL执行这个任务。然后,论文做一个“冲突”向前传递,仍然提供SA,同时注入θB。详见A.1中的图6。
在表2“常规”向前传递在任务A上显示出较高的准确性(90%+)。然而,“冲突”向前传递在任务B上产生较高的精度,对应于注入的任务向量θ。这意味着该模型主要依赖于θ,在很大程度上忽略了任务A的演示S。论文注意到任务B的准确性略低,可能与图6中看到的性能下降一致,并可能进一步受到S的影响。
七、解释θ(Interpreting θ)
学习到的向量θ直观地捕获了关于S所证明的任务的信息。在这里,论文提供了支持这种解释的证据。由于θ是transformer的中间隐藏状态,论文可以使用词汇投影方法。也就是说,论文检查了由隐藏状态引起的词汇表分布中的顶部令牌。
表3显示了LLaMA 13B的三个任务的顶部令牌(图7中提供了更多的模型和任务。)。在多种情况下,论文会观察到直接描述任务的令牌。重要的是,这些术语从未明确地出现在上下文中。例如,在从法语到英语的翻译任务中,论文观察到诸如“英语”和“翻译”等标记。这支持了论文的观点,即θ携带关于任务的典型的、重要的语义信息。

八、结论
通过对LLM中ICL的探索,论文揭示了ICL学习机制的新视角。论文揭示了一个简单而优雅的结构: ICL通过将给定的训练集压缩为一个单一的任务向量来实现函数,然后指导transformer生成给定查询的适当的输出。论文的工作为理解LLM如何执行ICL提供了一个垫脚石。根据论文的发现,未来的工作可以集中在理解如何构造任务向量,以及如何使用它来计算输出。
九、附录
见原文:https://arxiv.org/abs/2310.15916