前言
意图识别(Intent Recognition)是自然语言处理(NLP)中的一个重要任务,它旨在确定用户输入的语句中所表达的意图或目的。简单来说,意图识别就是对用户的话语进行语义理解,以便更好地回答用户的问题或提供相关的服务。
在NLP中,意图识别通常被视为一个分类问题,即通过将输入语句分类到预定义的意图类别中来识别其意图。这些类别可以是各种不同的任务、查询、请求等,例如搜索、购买、咨询、命令等。
下面是一个简单的例子来说明意图识别的概念:
用户输入: "我想订一张从北京到上海的机票。
意图识别:预订机票。
在这个例子中,通过将用户输入的语句分类到“预订机票”这个意图类别中,系统可以理解用户的意图并为其提供相关的服务。
意图识别是NLP中的一项重要任务,它可以帮助我们更好地理解用户的需求和意图,从而为用户提供更加智能和高效的服务。
在智能对话任务中,意图识别是一种非常重要的技术,它可以帮助系统理解用户的输入,从而提供更加准确和个性化的回答和服务。
模型
意图识别和槽位填充是对话系统中的基础任务。本仓库实现了一个基于BERT的意图(intent)和槽位(slots)联合预测模块。想法上实际与JoinBERT类似(GitHub:BERT for Joint Intent Classification and Slot Filling),利用 [CLS] token对应的last hidden state去预测整句话的intent,并利用句子tokens的last hidden states做序列标注,找出包含slot values的tokens。你可以自定义自己的意图和槽位标签,并提供自己的数据,通过下述流程训练自己的模型,并在JointIntentSlotDetector类中加载训练好的模型直接进行意图和槽值预测。
源GitHub:https://github.com/Linear95/bert-intent-slot-detector
在本文使用的模型中对数据进行了扩充、对代码进行注释、对部分代码进行了修改。
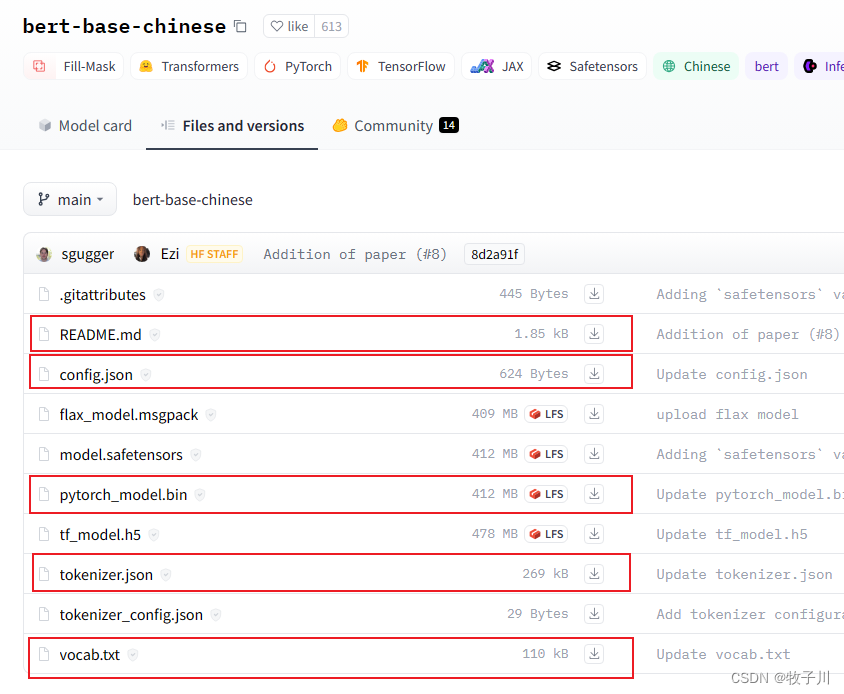
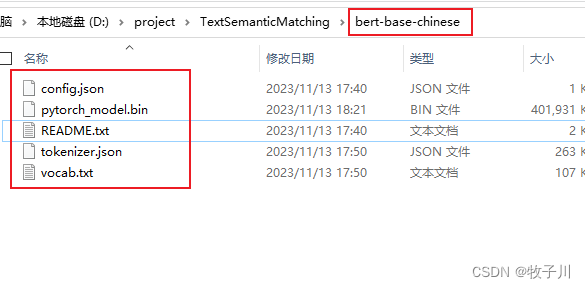
Bert模型下载
Bert模型下载地址:https://huggingface.co/bert-base-chinese/tree/main
下载下方红框内的模型即可。
数据集介绍
训练数据以json格式给出,每条数据包括三个关键词:text表示待检测的文本,intent代表文本的类别标签,slots是文本中包括的所有槽位以及对应的槽值,以字典形式给出。
{
"text": "搜索西红柿的做法。",
"domain": "cookbook",
"intent": "QUERY",
"slots": {"ingredient": "西红柿"}
}
原始数据集:https://conference.cipsc.org.cn/smp2019/
本项目中在原始数据集中新增了部分数据,用来平衡数据。
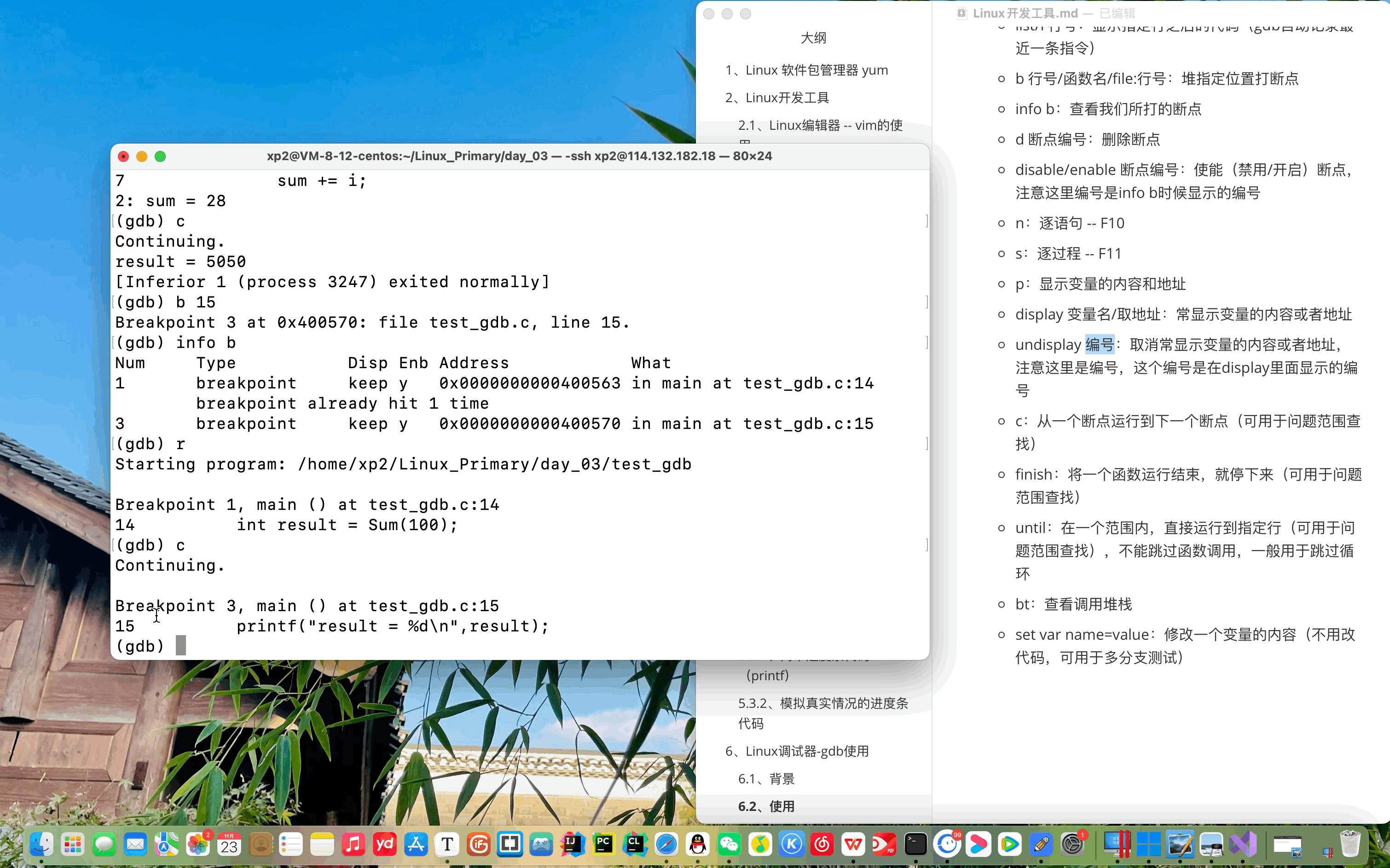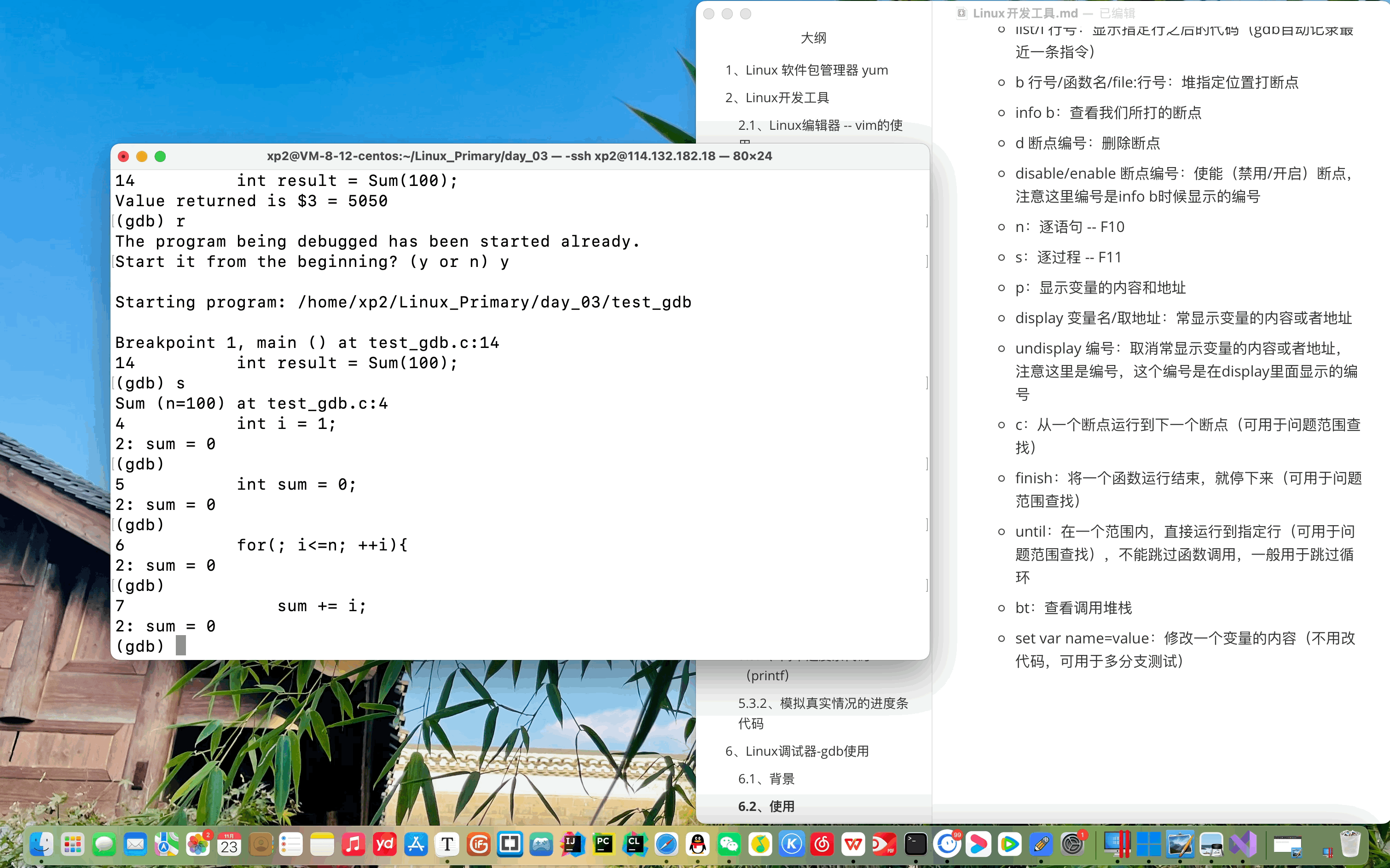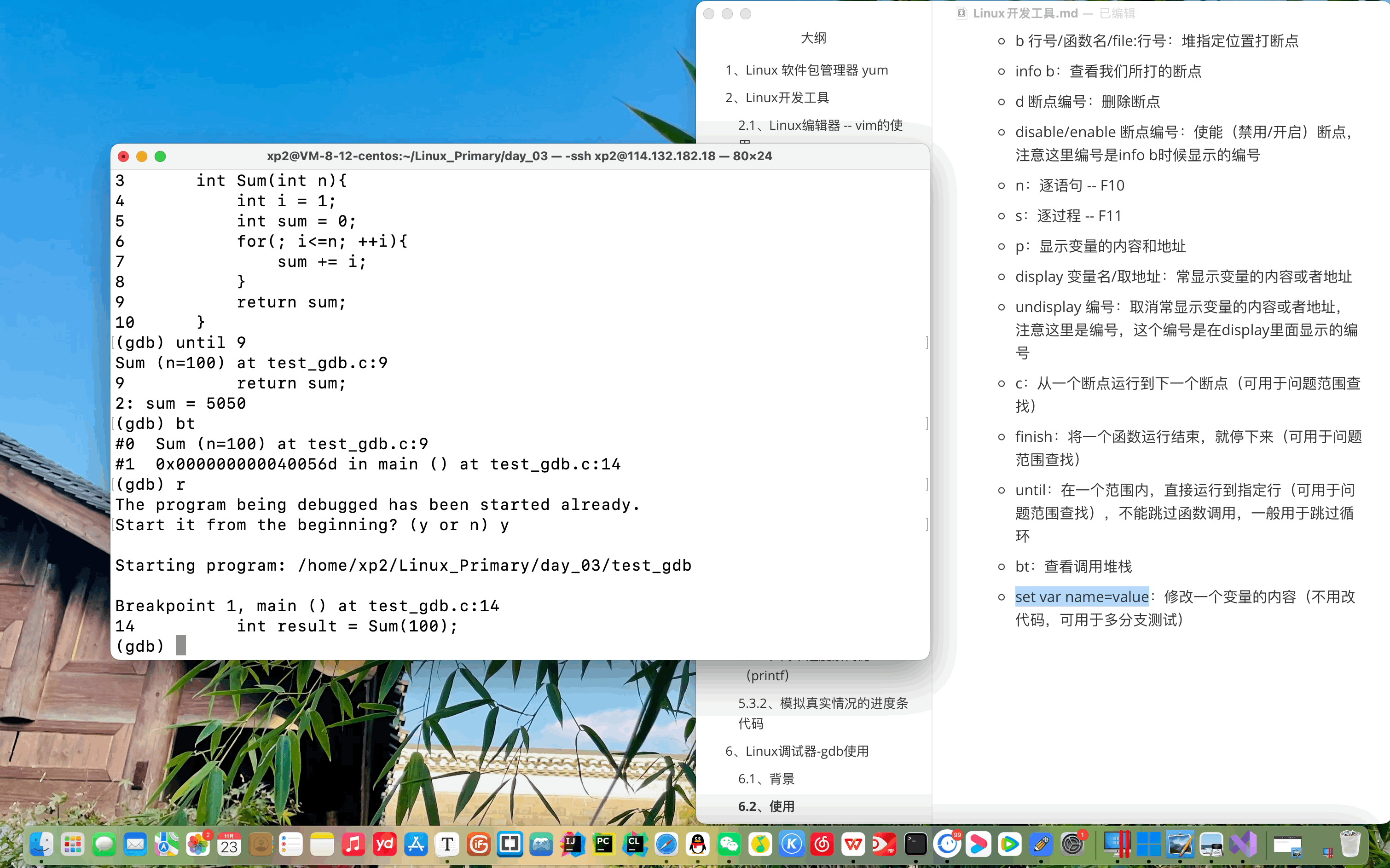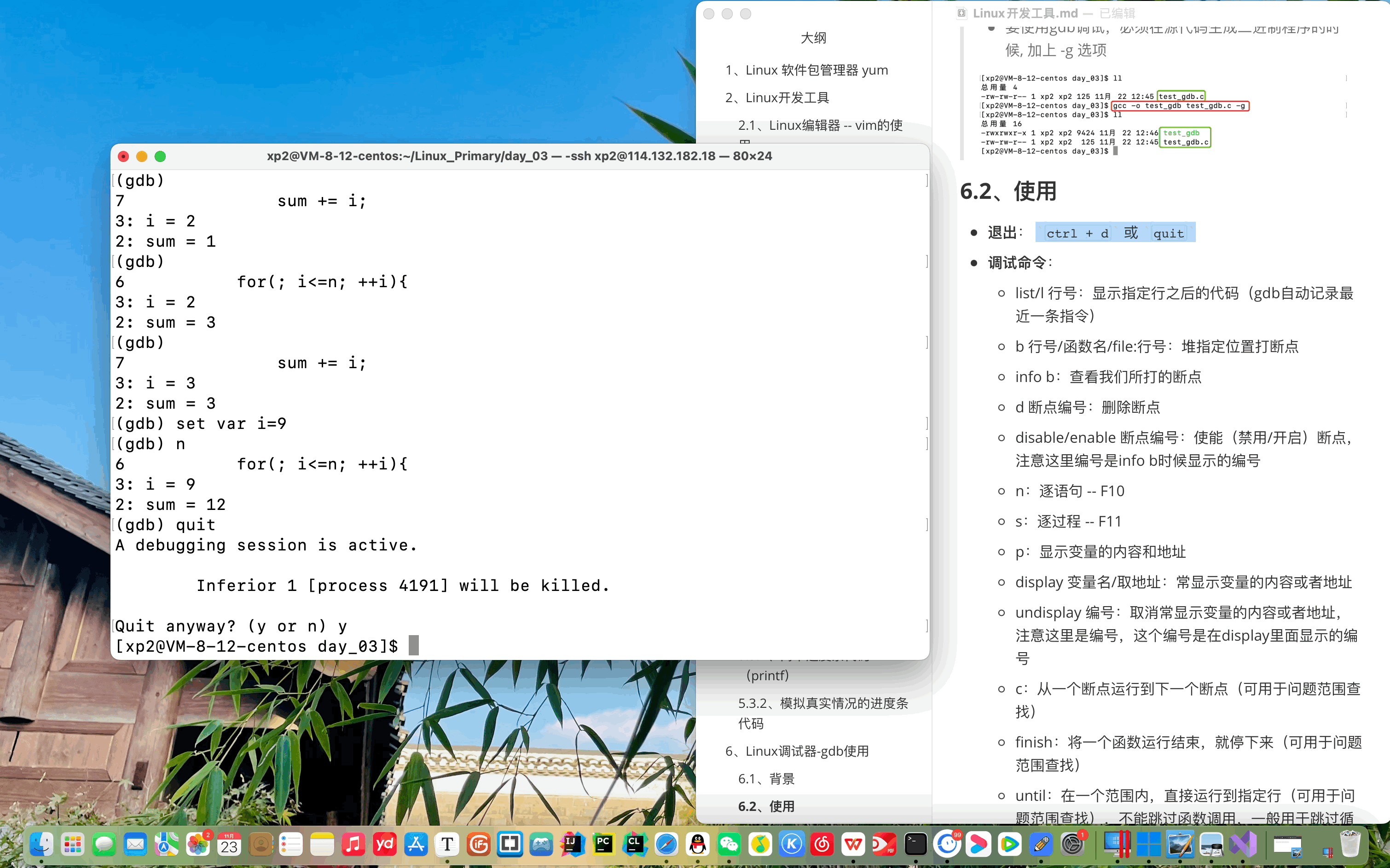
模型训练
python train.py
# -----------training-------------
max_acc = 0
for epoch in range(args.train_epochs):
total_loss = 0
model.train()
for step, batch in enumerate(train_dataloader):
input_ids, intent_labels, slot_labels = batch
outputs = model(
input_ids=torch.tensor(input_ids).long().to(device),
intent_labels=torch.tensor(intent_labels).long().to(device),
slot_labels=torch.tensor(slot_labels).long().to(device)
)
loss = outputs['loss']
total_loss += loss.item()
if args.gradient_accumulation_steps > 1:
loss = loss / args.gradient_accumulation_steps
loss.backward()
if step % args.gradient_accumulation_steps == 0:
# 用于对梯度进行裁剪,以防止在神经网络训练过程中出现梯度爆炸的问题。
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
optimizer.step()
scheduler.step()
model.zero_grad()
train_loss = total_loss / len(train_dataloader)
dev_acc, intent_avg, slot_avg = dev(model, val_dataloader, device, slot_dict)
flag = False
if max_acc < dev_acc:
max_acc = dev_acc
flag = True
save_module(model, model_save_dir)
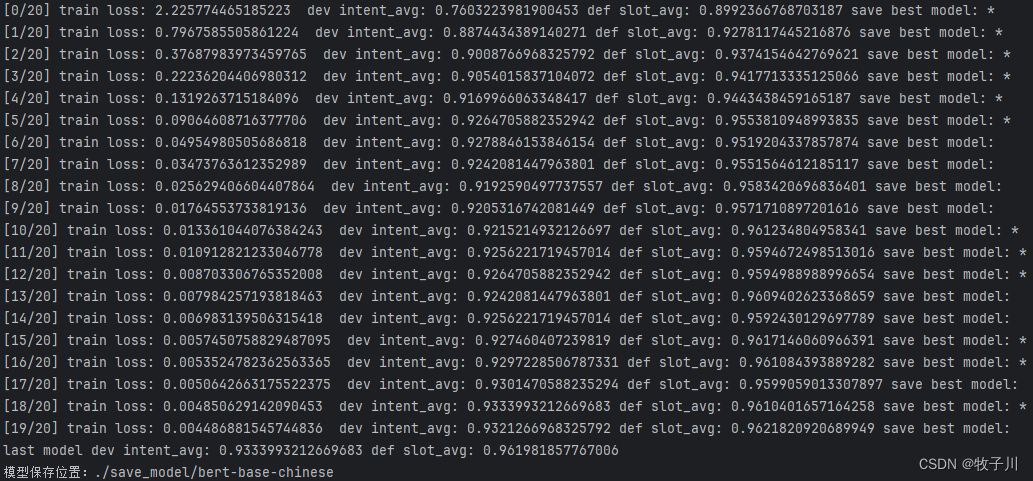
print(f"[{epoch}/{args.train_epochs}] train loss: {train_loss} dev intent_avg: {intent_avg} "
f"def slot_avg: {slot_avg} save best model: {'*' if flag else ''}")
dev_acc, intent_avg, slot_avg = dev(model, val_dataloader, device, slot_dict)
print("last model dev intent_avg: {} def slot_avg: {}".format(intent_avg, slot_avg))运行过程:
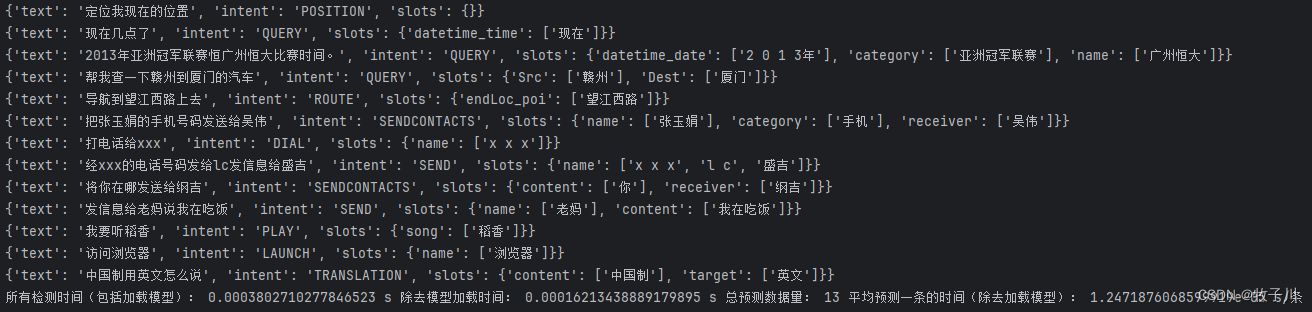
模型推理
python predict.pydef detect(self, text, str_lower_case=True):
"""
text : list of string, each string is a utterance from user
"""
list_input = True
if isinstance(text, str):
text = [text]
list_input = False
if str_lower_case:
text = [t.lower() for t in text]
batch_size = len(text)
inputs = self.tokenizer(text, padding=True)
with torch.no_grad():
outputs = self.model(input_ids=torch.tensor(inputs['input_ids']).long().to(self.device))
intent_logits = outputs['intent_logits']
slot_logits = outputs['slot_logits']
intent_probs = torch.softmax(intent_logits, dim=-1).detach().cpu().numpy()
slot_probs = torch.softmax(slot_logits, dim=-1).detach().cpu().numpy()
slot_labels = self._predict_slot_labels(slot_probs)
intent_labels = self._predict_intent_labels(intent_probs)
slot_values = self._extract_slots_from_labels(inputs['input_ids'], slot_labels, inputs['attention_mask'])
outputs = [{'text': text[i], 'intent': intent_labels[i], 'slots': slot_values[i]}
for i in range(batch_size)]
if not list_input:
return outputs[0]
return outputs推理结果:
模型检测相关代码
将概率值转换为实际标注值
def _predict_slot_labels(self, slot_probs):
"""
slot_probs : probability of a batch of tokens into slot labels, [batch, seq_len, slot_label_num], numpy array
"""
slot_ids = np.argmax(slot_probs, axis=-1)
return self.slot_dict[slot_ids.tolist()]
def _predict_intent_labels(self, intent_probs):
"""
intent_labels : probability of a batch of intent ids into intent labels, [batch, intent_label_num], numpy array
"""
intent_ids = np.argmax(intent_probs, axis=-1)
return self.intent_dict[intent_ids.tolist()]槽位验证(确保检测结果的正确性)
def _extract_slots_from_labels_for_one_seq(self, input_ids, slot_labels, mask=None):
results = {}
unfinished_slots = {} # dict of {slot_name: slot_value} pairs
if mask is None:
mask = [1 for _ in range(len(input_ids))]
def add_new_slot_value(results, slot_name, slot_value):
if slot_name == "" or slot_value == "":
return results
if slot_name in results:
results[slot_name].append(slot_value)
else:
results[slot_name] = [slot_value]
return results
for i, slot_label in enumerate(slot_labels):
if mask[i] == 0:
continue
# 检测槽位的第一字符(B_)开头
if slot_label[:2] == 'B_':
slot_name = slot_label[2:] # 槽位名称 (B_ 后面)
if slot_name in unfinished_slots:
results = add_new_slot_value(results, slot_name, unfinished_slots[slot_name])
unfinished_slots[slot_name] = self.tokenizer.decode(input_ids[i])
# 检测槽位的后面字符(I_)开头
elif slot_label[:2] == 'I_':
slot_name = slot_label[2:]
if slot_name in unfinished_slots and len(unfinished_slots[slot_name]) > 0:
unfinished_slots[slot_name] += self.tokenizer.decode(input_ids[i])
for slot_name, slot_value in unfinished_slots.items():
if len(slot_value) > 0:
results = add_new_slot_value(results, slot_name, slot_value)
return results源码获取
NLP/bert-intent-slot at main · mzc421/NLP (github.com)![]() https://github.com/mzc421/NLP/tree/main/bert-intent-slot
https://github.com/mzc421/NLP/tree/main/bert-intent-slot
链接作者
欢迎关注我的公众号:@AI算法与电子竞赛
硬性的标准其实限制不了无限可能的我们,所以啊!少年们加油吧!