枚举与Sized 数据
一般数据类型的布局是其大小(size)、对齐方式(align)及其字段的相对偏移量。
1. 枚举(Enum)的布局:
枚举类型在内存中的布局通常是由编译器来确定的。不同的编译器可能有不同的实现方式。一般来说,枚举的大小通常与其底层表示的整数类型相同,例如 enum 定义为 int 类型的大小。对于不同的枚举成员,编译器会分配不同的整数值。但是具体如何进行编码和布局是由编译器实现规定的。
在某些情况下,编译器可能会优化枚举类型的大小,特别是当枚举类型的取值在一个较小的范围内时,编译器可能会选择使用较小的整数类型来表示。
2. Sized 数据类型:
在 Rust 编程语言中,Sized 是一个特性(trait),用于表示大小在编译时是已知的类型。所有 Rust 中的类型默认都是 Sized 的,除非使用特殊的语法标记为 ?Sized,表示可能是动态大小的类型。
Rust 中的 size_of 和 align_of 函数可以用于获取类型的大小和对齐方式:
std::mem::size_of::<T>()返回类型T的大小(以字节为单位)。std::mem::align_of::<T>()返回类型T的对齐方式(以字节为单位)。
这些函数返回的结果是在编译时已知的常量值。
需要注意的是,对于不同的平台和编译器,类型的大小和对齐方式可能会有所不同。例如,在32位和64位系统上,同一类型的大小可能不同。
数字类型
在 Rust 中,数字类型的内存布局是按照它们的大小和规范来定义的。这些类型的内存布局通常受到硬件架构和编译器实现的影响。
在 Rust 中,常见的数字类型包括整数类型和浮点数类型。下面是一些常见的数字类型和它们的内存布局特征:
整数类型(Integer Types):
-
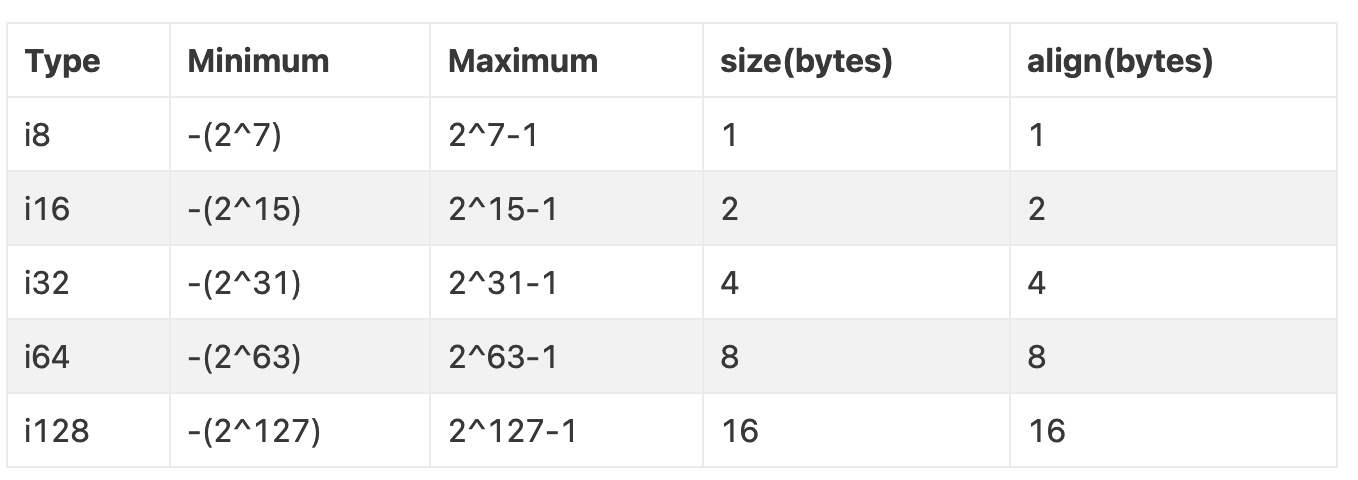
有符号整数:
i8、i16、i32、i64、i128:根据其名称指示的位数存储有符号整数,例如,i32是一个32位的有符号整数,i64是一个64位的有符号整数。- 内存布局:按照补码表示存储。即最高位为符号位,其余位表示数值。
-
无符号整数:
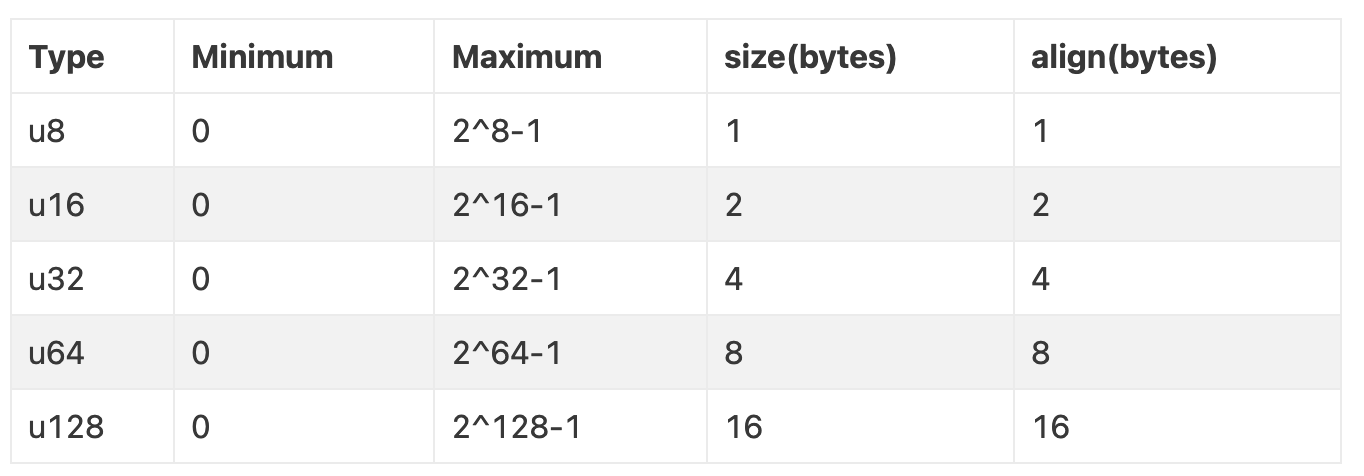
u8、u16、u32、u64、u128:根据其名称指示的位数存储无符号整数,例如,u32是一个32位的无符号整数,u64是一个64位的无符号整数。- 内存布局:使用全部位来表示数值。
浮点数类型(Floating-Point Types):
-
单精度浮点数:
f32:32位的单精度浮点数。- 内存布局:采用IEEE 754标准,其中1位表示符号位,8位表示指数部分,23位表示尾数部分。
-
双精度浮点数:
f64:64位的双精度浮点数。- 内存布局:同样采用IEEE 754标准,其中1位表示符号位,11位表示指数部分,52位表示尾数部分。
 这些数字类型在内存中以固定大小进行存储,其具体的字节顺序和布局可能因编译器和硬件平台而异。一般来说,这些数字类型在内存中是连续存储的,并且其大小和布局遵循相应的标准,比如整数的补码表示和浮点数的IEEE 754标准。
这些数字类型在内存中以固定大小进行存储,其具体的字节顺序和布局可能因编译器和硬件平台而异。一般来说,这些数字类型在内存中是连续存储的,并且其大小和布局遵循相应的标准,比如整数的补码表示和浮点数的IEEE 754标准。
usized 、isized
在 Rust 中,usize 和 isize 是特殊的整数类型,其大小取决于运行 Rust 代码的操作系统的位数。这两种类型的大小会根据不同系统的位数而变化。
-
usize:代表无符号整数,它的大小等于指针大小,即在 64 位系统上通常是 8 字节,在 32 位系统上通常是 4 字节。它用于表示内存中的索引、大小和指针偏移等。在 Rust 中,usize类型通常用于索引集合或表示内存中对象的大小。 -
isize:代表有符号整数,同样,它的大小也等于指针大小。在 64 位系统上通常是 8 字节,在 32 位系统上通常是 4 字节。它可以用来表示可以为负数的索引或偏移量。
这两种类型在不同位数的系统上都是与机器字长相关的,这样可以更好地适应不同平台上的内存寻址和指针大小。它们的大小是 Rust 编译器根据目标平台自动确定的,并且在不同平台上可能会有所不同。
bool
bool 类型在 Rust 中用于表示布尔值,只能取 true 或 false。它在内存中的长度和对齐长度都是 1 字节,在存储时占用一个字节的内存空间。
数组
在 Rust 中,数组是固定大小的相同类型元素的集合。Rust 中的数组具有连续的内存布局,并且元素是按照其定义顺序依次存储的。
内存布局:
-
连续存储:数组中的元素按照顺序在内存中连续存放。这意味着如果有一个包含多个元素的数组,它们会依次存储在内存中相邻的位置。
-
相同类型元素:数组中的所有元素必须是相同的类型。例如,一个
i32类型的数组必须只包含i32类型的元素。 -
索引访问:通过索引可以访问数组的元素。Rust 中的数组索引从 0 开始,可以使用
[]操作符来访问数组中特定索引的元素。
示例:
// 创建一个包含 4 个整数的数组
let my_array: [i32; 4] = [10, 20, 30, 40];
假设有一个名为 my_array 的数组,包含四个 i32 类型的整数。在内存中,这个数组的存储方式可能如下所示(这里只是示意,不考虑实际内存地址):
my_array: [10, 20, 30, 40]
Memory: | 10 | 20 | 30 | 40 |
这表示这个数组中的四个整数元素在内存中是连续存储的,每个整数占据相应的内存空间。数组的第一个元素 10 存储在第一个内存位置,第二个元素 20 存储在紧随其后的内存位置,以此类推。
通过索引可以访问数组中的元素,例如 my_array[0] 会返回第一个元素 10,my_array[1] 返回第二个元素 20,以此类推。
str类型
1. char 类型:
char表示一个 Unicode 字符,占据 32 位长度(4 字节)。- Unicode 标量值(Unicode Scalar Value)范围在
0x0000 - 0xD7FF或0xE000 - 0x10FFFF。
2. str 类型:
str是一个不可变的 UTF-8 编码字符串片段(slice)。它是对 UTF-8 编码字节序列的引用。- Rust 的标准库假设
str是有效的 UTF-8 编码,并且对其进行操作时会遵循这个假设。 str的内存布局类似于&[u8],但是假设其内容是有效的 UTF-8 编码。
3. slice:
slice是 Rust 中的动态大小类型(DST),表示一部分数据的视图。&[T]是一个“宽指针”,它存储了指向数据的地址和数据的长度。slice的内存布局与其指向的数据类型相同。
4. String 类型:
String是 Rust 中的可变字符串类型,它拥有所有权,并且存储 UTF-8 编码的文本。String本质上是一个指向存储字符串数据的缓冲区的指针,它也是一个Vec<u8>的封装。String的内存布局包含了指向存储字符串数据的地址以及字符串的长度和容量信息。
在 Rust 中,struct是用于定义自定义数据类型的关键字,它允许组合多个不同类型的字段来创建一个新的复合类型。当涉及到struct的内存布局时,需要考虑其字段的排列和对齐方式。
struct
在 Rust 中,struct 的内存布局通常是紧凑且连续的,它的字段按照声明的顺序依次存储在内存中。然而,Rust 也会根据字段的类型和对齐需求进行内存对齐,以提高访问效率。
例如,考虑以下简单的结构体定义:
struct MyStruct {
a: u8,
b: u16,
c: u32,
}
这个结构体 MyStruct 包含了一个 u8 类型的字段 a、一个 u16 类型的字段 b 和一个 u32 类型的字段 c。Rust 会根据这些字段的类型和对齐要求进行内存布局。
通常情况下,Rust 会按照字段的声明顺序进行内存排列,但也可能根据字段的大小和对齐要求进行调整,以保证每个字段能够按照其对齐规则正确地存储在内存中。
对齐规则是为了提高访问效率和减少内存访问的成本。例如,u16 类型通常需要在内存中对齐到 2 字节边界,u32 类型通常对齐到 4 字节边界,以此类推。因此,结构体的内存布局可能会在字段之间增加填充以满足对齐要求。
需要注意的是,Rust 并没有明确的规范指定结构体的内存布局,这是由编译器根据平台和优化策略进行管理的。因此,在特定情况下,结构体的内存布局可能会因编译器、目标架构或优化设置而有所不同。
tuple
元组(Tuple)是一种可以包含多个不同类型值的复合数据类型。元组的内存布局类似于结构体(struct),但有一些区别。
元组的内存布局:
- 连续存储:元组中的元素按照其定义顺序在内存中连续存储。
- 按照顺序排列:元组的元素按照声明的顺序存储在内存中,与结构体类似。
- 无字段名:不同于结构体,元组的元素没有字段名,仅按照位置(索引)进行访问。
考虑一个简单的元组定义:
let my_tuple = (10, "hello", true);
这个元组 my_tuple 包含了一个 i32 类型的整数 10、一个 &str 类型的字符串 "hello" 和一个 bool 类型的布尔值 true。
元组的内存布局是紧凑的,并且其中的元素按照它们在元组中的位置顺序存储。因为元组的元素没有字段名,访问元素时需要通过索引来获取,例如 my_tuple.0、my_tuple.1、my_tuple.2。
和结构体不同,元组的内存布局没有对齐需求或填充。它们的存储是简单而紧凑的,元素之间紧密相邻。
元组的内存布局和访问方式是由 Rust 编译器管理的,而且 Rust 并未对元组的内存布局进行严格的规范。因此,具体的内存布局可能会因编译器、优化策略和目标平台等因素而有所不同。
closure
闭包(Closure)是一个可以捕获其环境中变量并且可以在稍后调用的匿名函数。闭包的内存布局在 Rust 中并没有直接暴露或详细定义,因为它们是由编译器在编译时根据捕获的环境和使用情况生成的。
尽管闭包的具体内存布局是由 Rust 编译器实现的细节,但闭包的内部实现与结构体有关,并且根据捕获的变量及其使用方式来进行编译。因此,理解闭包内存布局的最佳方式是从其行为和 Rust 的 trait 实现角度来理解闭包。
-
环境捕获:闭包可以捕获周围环境中的变量。这些捕获的变量在闭包被创建时会被包含在闭包的内部。
-
Fn、FnMut 和 FnOnce:闭包的调用方式取决于其捕获的变量和如何使用这些变量。根据捕获变量的所有权或可变性,闭包可能实现了
FnOnce、FnMut或Fntrait 中的其中之一。 -
背后的实现:闭包背后的具体实现通常涉及一个结构体,它包含了捕获的变量作为其字段,并且实现了对应的 trait。这个结构体的内存布局由编译器生成,通常会保证捕获变量的正确性和可访问性。
由于闭包的实现细节是由 Rust 编译器处理的,而不是直接暴露给开发者的,因此在大多数情况下,不需要过多关注闭包的具体内存布局。闭包的内存布局是由编译器根据其捕获的环境变量、使用方式和实现的 trait 来动态生成的,具体的实现细节可能会因编译器和闭包的用法而有所不同。
union
union 是一种特殊的数据结构,其所有字段共享相同的内存空间。每个 union 实例的大小由其最大字段的大小决定。
-
字段共享内存:
union的所有字段共享同一块内存。因此,对一个字段的写入可能会覆盖其他字段的数据。 -
大小由最大字段决定:
union的大小由其最大字段的大小决定。它的大小等于所有字段中最大字段的大小。 -
字段访问和数据有效性:在
union中,程序员可以使用其中的某个字段来读取数据,但要确保读取的字段类型与实际存储的数据类型相匹配。否则,试图解释存储的数据为不匹配类型的行为将导致未定义的行为。
#[repr(C)] 和 union 的声明:
#[repr(C)] 是一个属性,用于指示编译器按照 C 语言的布局规则来布局 union 或结构体的内存。它确保 union 的布局与 C 语言的标准兼容,有利于与 C 代码进行交互或者在 Rust 中实现特定的内存布局。
下面是一个示例 #[repr(C)] 的 union 声明:
#[repr(C)]
union MyUnion {
f1: u32,
f2: f32,
}
在这个 union 中,f1 是一个 u32 类型的字段,f2 是一个 f32 类型的字段。由于这两个字段共享相同的内存空间,因此对一个字段的写入可能会影响另一个字段。
在使用 union 时,确保数据的有效性和正确的字段访问非常重要,否则可能导致不可预期的结果或未定义的行为。