简述
numpy.unique:用于去除数组中重复元素,并从小到大排序(找到唯一元素并排序)。
def unique(ar, return_index=False, return_inverse=False,
return_counts=False, axis=None):
ar: 这是输入的数组或类数组对象。
return_index: 如果设置为True,函数会同时返回唯一元素的索引数组,这些索引对应于原始数组中的位置。
return_inverse: 如果设置为True,函数会返回一个数组,其中包含输入数组中的元素在处理后的唯一数组中的索引。这可以用于重构原始数组。
return_counts: 如果设置为True,函数将返回一个数组,其中包含输入数组中每个唯一元素的出现次数。
axis: 用于指定在哪个轴上执行操作。如果是None,则表示在整个数组上执行操作。
函数返回一个包含唯一元素的排序数组。根据参数的设置,它可能还返回与唯一元素相关联的索引数组、原始数组元素在唯一数组中的索引数组,以及每个唯一元素的出现次数。
以下是一个简单的例子:
import numpy as np
arr = np.array([2, 1, 6, 6, 4, 8, 5, 5, 6,7])
unique_values = np.unique(arr)
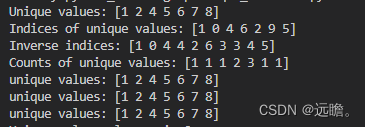
print("Unique values:", unique_values)
# 返回唯一元素的索引数组
unique_indices = np.unique(arr, return_index=True)[1]
print("Indices of unique values:", unique_indices)
# 返回输入数组中的元素在唯一数组中的索引数组
inverse_indices = np.unique(arr, return_inverse=True)[1]
print("Inverse indices:", inverse_indices)
# 返回每个唯一元素的出现次数
unique_counts = np.unique(arr, return_counts=True)[1]
print("Counts of unique values:", unique_counts)
# 以上如果索引是[0],则返回的是处理过后的数组
print("unique values:", np.unique(arr, return_index=True)[0])
print("unique values:", np.unique(arr, return_inverse=True)[0])
print("unique values:", np.unique(arr, return_counts=True)[0])
输出
最后参数axis的含义
在 numpy.unique 函数中,axis 参数用于指定在哪个轴上执行操作,但在默认情况下,该参数通常是 None,表示在整个数组上执行操作。在很多情况下,我们不需要设置 axis 参数,因为默认值已经能够满足大多数需求。
如果你的输入数组是多维的,而且你想在特定轴上找到唯一元素,那么你可以指定 axis 参数。
arr_2d = np.array([[1, 2, 3,2],
[4, 2, 6,5],
[1, 2, 3,1],
[1, 2, 3,1]])
# 在轴 0 上找到唯一元素
unique_values_axis_0 = np.unique(arr_2d, axis=0,return_index=True)[1]
print("Unique values along axis 0:\n", unique_values_axis_0)
# 在轴 1 上找到唯一元素
unique_values_axis_1 = np.unique(arr_2d, axis=1,return_index=True)[1]
print("Unique values along axis 1:\n", unique_values_axis_1)
输出
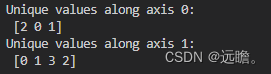
也就是如果选定axis=0,就是从第一个维度arr_2d[i] 中挑选其中最小值,并排序,最小值的排序方式是遍历 arr_2d[i]的每个值,先排第一个数字,再排第二个数字,以此类推。
选定axis=1,就是在第一个维度的第一个向量找到第二维的排序方式,也就是按照arr_2d[0][i]排序,得到的索引,用于其他的维度 arr_2d[i]。