总览

协同过滤算法,就是一种完全依赖用户和物品之间行为关系的推荐算法。
从字面理解,协同大家的反馈、评价和意见一起对海量的信息进行过滤,从中筛选出用户可能感兴趣的信息。
知识概括
从这几个方面进行分析。
一、基于用户的协同过滤
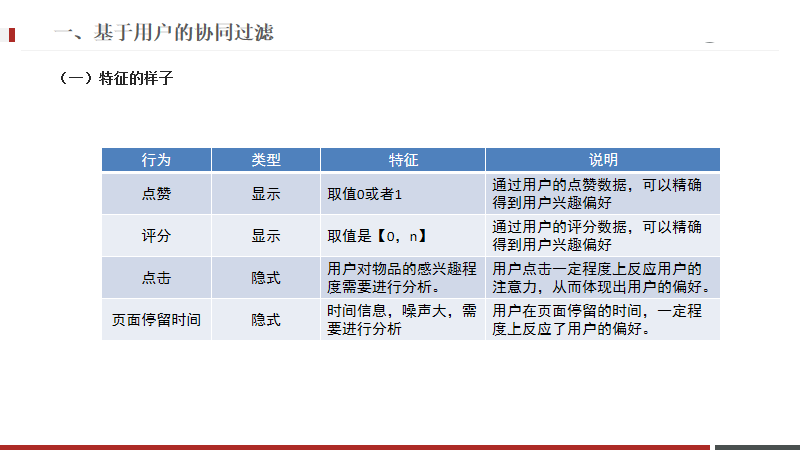
显示能够直接看出用户的偏好,
隐式需要自己动手挖掘数据,如果方法不够准确,可能找的会有问题。
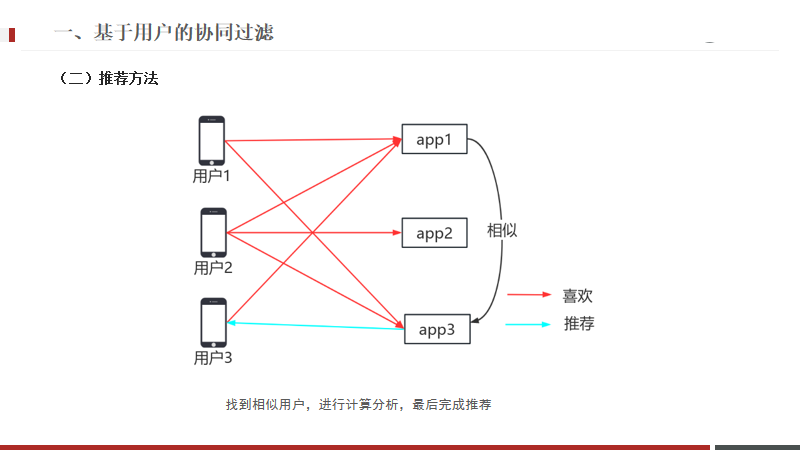
从这个图中可以看出,用户一与用户三都喜欢APP1,
这两位用户的兴趣可能是一样的,可以做出推测,用户3可能是喜欢app3的
 稀疏是说通常商品非常多,用户购买的只是其中极小一部分
稀疏是说通常商品非常多,用户购买的只是其中极小一部分
计算讲的是用户和物品的矩阵会非常庞大,此外还有增量数据的同步问题。人们的兴趣一直在变,去同步这种变化的数据就是一种计算问题。
冷启动是指新用户到来,本身没有和其他用户有关联,这种情况该如何推荐
二、基于物品的协同过滤
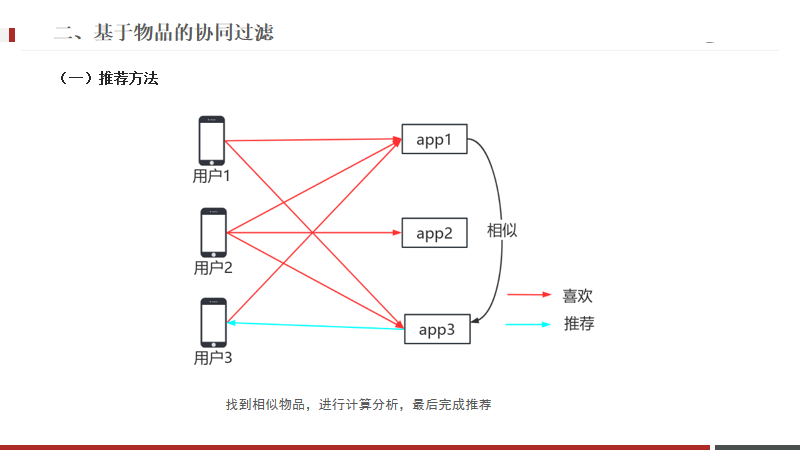
在推荐中,如果用物品1和物品3经常一起出现,也就是说用户购买1的时候也大概率会买3,
那么出现新用户3喜欢物品1,同时也用户3推荐物品3.
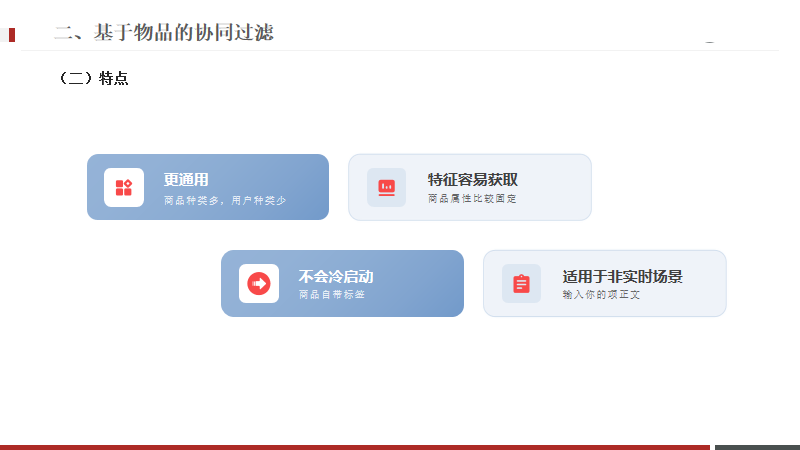
更流行,现阶段各大网站基本都是用户较多,
商品(种类)比用户少的多商品属性通常比较固定,特征获取容易,而且基本不会改变
即便上架了新商品,它自身也有各种标签,不会像用户一样是张白纸
应用场景更适合当下各种网站,APP(实时的除外,例如新闻)的、
三、矩阵分解

如果有100w的用户,1个亿的产品,这两个组合一个矩阵,数据量太大,计算分析困难。
怎么样能通过一种方法降低这个计算复杂度,将最终目标实现,就是矩阵分解要做的事情。

这是用户歌曲之间的行为数据,1代表听过个,0代表没有听过。
可以看出是比较稀疏的矩阵,目标是预测空白值是多少。
如果直接算的话,计算效率比较低
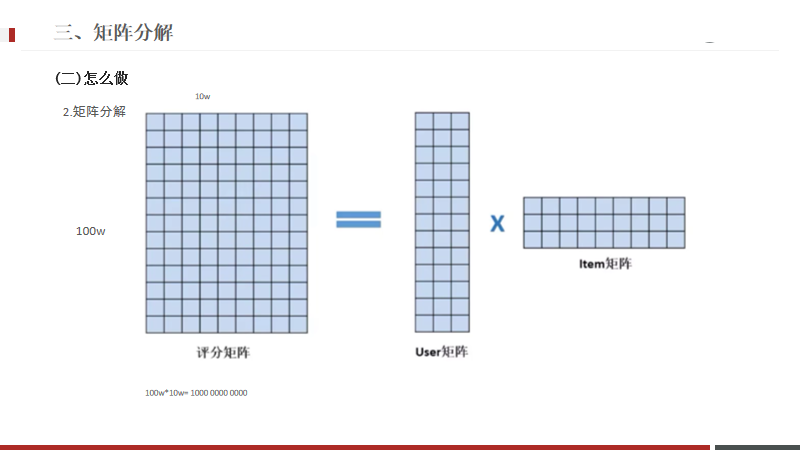
原始矩阵是100w10w,
拆分为两个矩阵:100w3 与 3*10w两个矩阵,这两个矩阵就相对小很多,
这个3是隐向量,

最后可以分解成这样的矩阵,
这里的三个特征,就是隐向量,其实就是特征的高维表达,很难去解释。
这里的民谣、儿歌,是为了方便理解,这样写出来的。但其实没有办法解释,如右下角所示。
优化好小矩阵中的数值,最终合并成一个大表。

如图中所示,通过不断调整参数,最后得到一个计算机能理解的特征,
就是隐向量的一般含义。
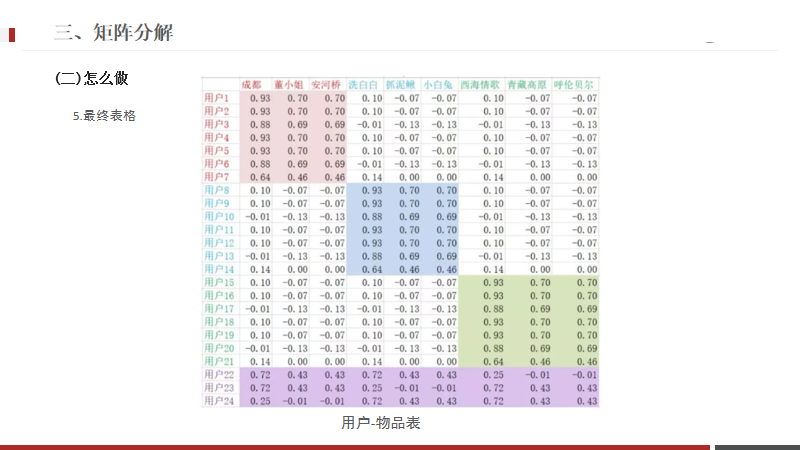
这是最终的表格
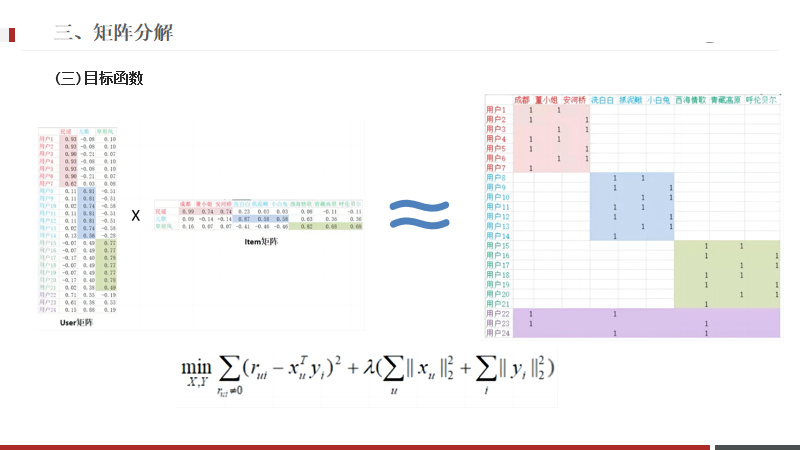
使用矩阵分解,希望还原后的矩阵,和原来是越相似越好。
rui 相当于原来的大矩阵,xy就是分解出来的两个小矩阵,希望他们之间的差异越来越小。

默认为1,rui当前的指标,比如点击次数,阿尔法相当于是系数,就是权重的设置。
行为越多,置信度的值会越来越大。
置信度的值越大,表示预测的越准确。
需要PPT的私聊