一.介绍
为什么会出现Redis这个中间件,从原始的磁盘存储到Redis中间又发生了哪些事,下面进入正题
二.发展史
2.1 磁盘存储
最早的时候都是以磁盘进行数据存储,每个磁盘都有一个磁道。每个磁道有很多扇区,一个扇区接近512Byte。
那要从磁盘中读取数据,有两个指标很重要就是:寻址速度 和 带宽
磁盘:寻址速度是ms的,带宽是GB/M的。
内存:寻址速度是ns级的,带宽也比磁盘大上好几个数量级。
结论:磁盘比内存在寻址上慢了接近10W倍。
当数据文件很大的时候,存储的时候我们的面临的问题是,I/O问题。在读写文件时,我们常常面临很大的I/O成本问题。但是最初的解决方案是加一个buffer。
I/O 成本问题是指:假设 1T的数据存储在硬盘,每个扇区512Byte,上层创建很大的索引才能索引住每个扇区数据。操作系统无论都多少,都是最少从4k拿
总结:数据很大的时候,I/O 会越慢,最终磁盘会成为瓶颈。
2.2 数据库时代
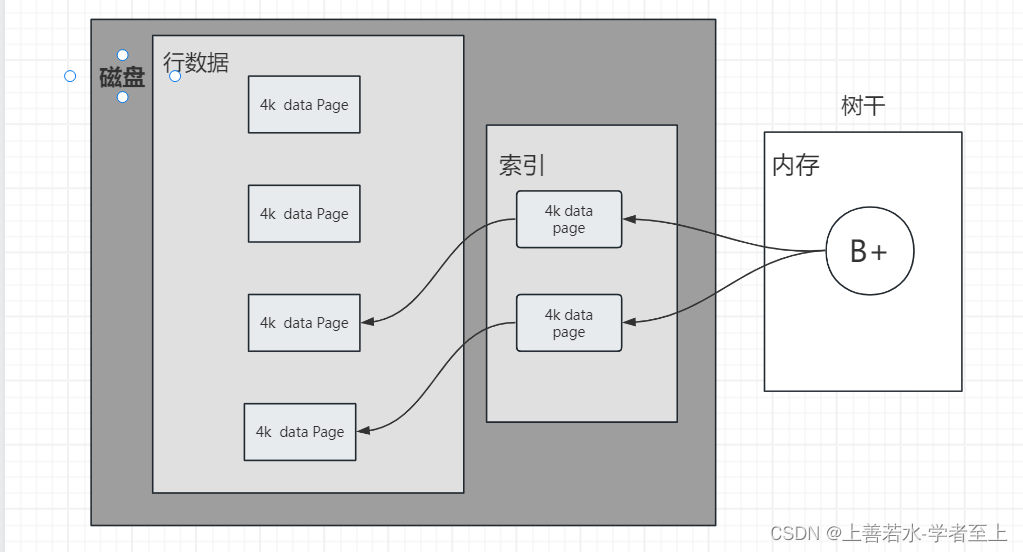
当关系型数据库出现,创建了一个data page 概念,data page 大小是4k,这个4k和磁盘的4k对应上,正好是一次 I/O.
数据存储在数据库的时候,就是很多4k的data page 小格子,如果只存数据不建索引,数据的读取还是会很慢,因为读取的时候都是全量I/O.所以关系型数据库会再创建4k的索引,提高查询的效率,索引的 结构是B+树。
B+树是B树的一种变体,也属于平衡多路查找树,大体结构与B树相同,包含根节点、内部节点和叶子节点。多用于数据库和操作系统的文件系统中,由于B+树内部节点不保存数据,所以能在内存中存放更多索引,增加缓存命中率。另外因为叶子节点相连遍历操作很方便,而且数据也具有顺序性,便于区间查找创建表的时候,每个列会设定数据类型,数据类型决定了字节宽度,当所有列的类型确定,则一行的数据宽度是固定的,往4k的data page 里面整体存储,所以数据库倾向于行级存储,好处就是修改数据的时候不需要移动数据,在原本的位置复写就可以了。
数据和索引都是在磁盘里,select 语句的where 条件命中内存的B+树的树干,然后走索引读取数据到内存里,内存是比较快的。
2.3 key-value数据库的产生
我们将数据库发展到极致,产生出类似SAP公司的HANA数据库。这种数据库,硬件需求大,内存约2T,硬件服务费很贵。不适合小中型公司选择。
随着互联网的发展,我们面临了一个新的问题。如何才能抵挡高并发,大数据量导致的查找变慢呢?(注意,数据量变大,仅仅影响多范围数据查找,单主键索引数据查找并不会影响性能。我们的业务逻辑,通常是多条数据查找,所以才会有瓶颈)
于是我们的k-v数据库产生了,redis 应运而生。
三.总结
redis的诞生,解决了应对实际业务中对高并发,大数量业务,提供更丰富API使用以及丰富多样的数据结构。后续会从数据结构开始,一步步揭开redis的面纱。
如有侵权请联系 15996365528@163.com 删除,谢谢。