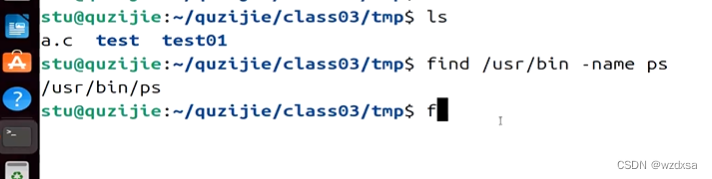
find查找操作
1.文件名
上图中,一共有4个部分,分别是find,搜索路径,-name,文件名
find加上文件的路径(也就是要查找的文件在根目录下的usr目录下的bin目录底下)
加上 -name 加上文件名(要查找的文件的名字)
找到了就显示那个文件的当前路径![]()

要是只有一个大范围的比如/usr,那么它底下的PS就有很多个,在不同路径下面
2.过去的n分钟
也是一共4个部分
分别是find,搜索路径,-cmin,-n(n就是几分钟)
find加上路径
加上 -cmin 加上 -几分钟

例如这个意思就是过去10分钟内在那条路径下,做出修改过的文件
如果过去10分钟内没有做出过修改,则没有显示

在过去30分钟内做出修改的文件一共就是这些
![]()
如果有时候忘记了文件名字,或者只记得名字中的部分,可以像上图中写一个* .c,
* .c,* 就是所有的意思,这句话的意思就是查找所有的带有 .c 的文件

然后这就是所有的 .c 文件
2.过去的n天内

例如查找在quzijie路径下,过去5天做出修改的文件,这个就会有很多了

1天内也有很多

grep:过滤命令
用vim建一个test.c文件,里面写上这些内容
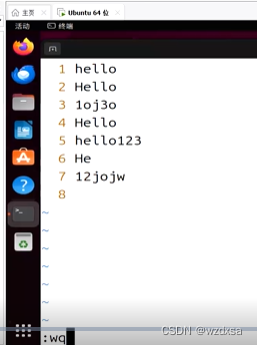
然后用cat命令把文件内容打印出来

现在就用grep命令来过滤出文件里面所包含的一些字符串
例如过滤出上面test.c文件里的hello字符串
grep 加上要过滤的字符串 加上包含字符串的文件名(共3部分,grep 字符串 文件名)

那么所有带有完整的hello字符串(包含hello的也行)的就出来了(必须是完整的,同样的hello)

如果要不区分字符串中字母的大小写,就在grep后面加上 -i
(共4部分,grep -i 字符串 文件名)
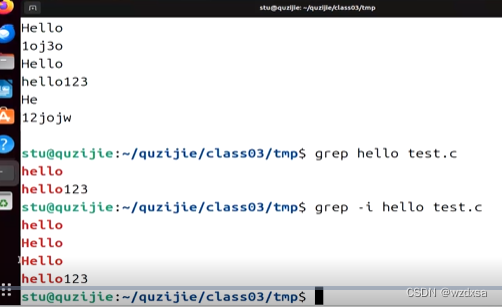
可以看到大写的Hello也出来了
grep后面的参数很多(类似于 -i ),后面用到时用man查找帮助手册就行

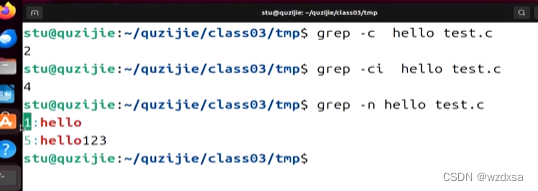
例如,加上 -c,就是包含hello的总共有2行
然后命令参数 i和c 作用叠加使用,就是不区分大小写字母的hello字符串一共有4行

再例如 -n:就是把过滤出来的包含字符串的内容的所在行的行号,也标上告诉你
再例如 -v:就是取反的意思。列找出不包含字符串hello的内容

总结:grep就是用来过滤特定内容的命令

除了过滤,grep还可以用来文件搜索,但这个搜索要结合管道——|
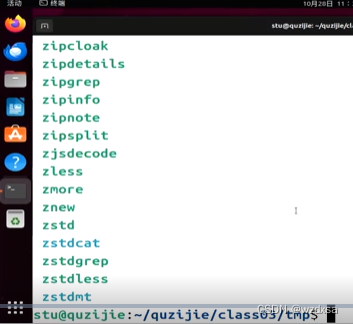
例如,要搜索文件PS


而这句话前半句的意思是显示(ls)usr目录底下的bin目录底下的所有东西,但这个就太多了,如图
那么就可以用grep来过滤一下,只要搜索路径底下的文件名中包含PS字符串的文件,就grep PS来过滤出文件名中包含PS字符串文件,也就是查找出文件名中包含PS字符串文件

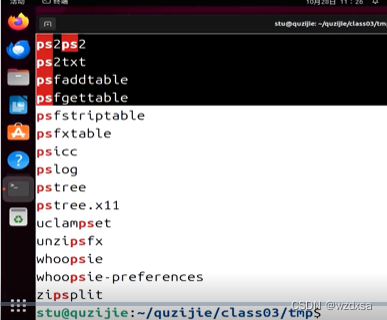

所以这整句话的意思是,显示前半句话的内容,但因为太多了,就通过管道(|)来grep过滤一下想要的(ps)内容,减少不必要的内容显示

管道——|——将前一个命令的输出结果作为后一个命令的输入

看例1:
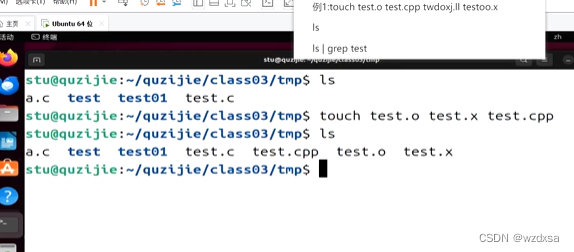
touch(创建普通文件命令)后面可以跟多个文件名,可以一起创建
如上图,一次性创建 test.o test.x test.cpp 共3个文件
然后ls看到创建成功了
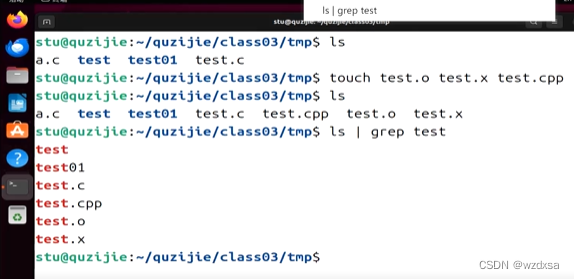
然后通过管道,|前面的就是输出结果,作为 | 后面的输入
再看例2:

输出结果做输入的是


因为输出太多,通过管道来grep过滤,带有sh的
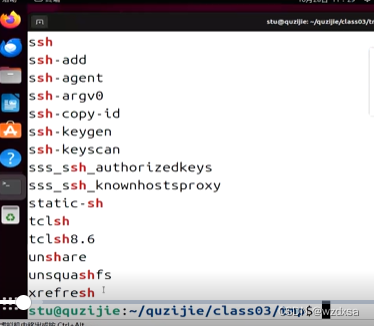

wc:统计文件中某些东西的命令——记不住参数的话就man wc


用这个a.c 文件

wc命令一共有3部分(wc 参数(-w:统计后面文件中单词个数) 文件名)
下图中就是2个单词,hello和world
输出就是单词个数加上文件名,也就是有几个单词 在这个文件中

而 -c:就是告诉你文件中总共有几个字符(一个字母占一个字符,一个空格占2个字符)所以是12


而 -l:就是告诉你文件中总共有几行![]()
可以看到就1行