目录
多元线性回归模型
总体回归函数
样本回归函数
线性回归模型的假定
普通最小二乘法(Ordinary Least Squares,OLS)
拟合优度指标
F检验
回归系数的t检验
Python中构建多元线性回归模型
数据理解
数据读取
数据清洗
相关分析
回归分析
附录
参考文献
阅读本文时,建议先阅读《第7章-使用统计方法进行变量有效性测试-7.4.1-简单线性回归》。
多元线性回归模型
总体回归函数
多元线性回归是在一元线性回归的基础之上,增加更多的自变量(两个或两个以上),其表达形式如下:
其中是因变量,
是
个自变量。
是干扰项或随机误差项。
是回归系数,特别的
是截距。
样本回归函数
和一元线性回归类似,其表达形式如下:
其中是
个自变量,
是回归系数的估计。
称为样本剩余项,或残差。
假设现在样本数据如下:
| 自变量 | 自变量 | ...... | 自变量 | 因变量 |
|---|---|---|---|---|
| ...... | ||||
| ...... | ||||
| ...... | ...... | ...... | ...... | ...... |
| ...... |
表格中每一行表示一个样本,总共个样本。对于第
个样本
预测值如下:
对于上面n个样本,可以使用如下矩阵形式表示。
真实值
预测值
自变量值
回归系数
回归系数估计量
残差
干扰项
有了上面矩阵形式的约定后,容易得到
总体回归函数变为
样本回归函数变为
线性回归模型的假定
(1)线性于参数
即讨论的模型是关于参数的线性函数:
(2)扰动项与自变量不相关,期望值为0
数学表述如下:
该假设提示我们,只要扰动项与自变量相关,就应该继续从扰动项中分析出新的自变量纳入模型中。
(3)扰动项之间相互独立且服从方差相等的同一个正态分布
数学表述如下:
,
其中分别表示第
个体的干扰项。扰动项代表个体的差异性,如果其不独立,则说明个体之间相互影响,并且仍旧有重要的信息蕴含在其中未被提取出来。
(4)自变量之间相互独立
数学表述如下:
自变量之间如果不相互独立,多元线性回归就会出现多重共线性,会导致回归系数的估计值不稳定。关于多重共线性,后面再说。
普通最小二乘法(Ordinary Least Squares,OLS)
普通最小二乘法就是找到,是的残差平方和最小。也就是:
如果使用矩阵来表示,假设,则上式可以写成如下矩阵形式:
后面为了表述方便,对于多元线性回归,我们将采用向量或者矩阵的形式。如没特别说明,向量均为列向量。现在残差平方和就可以如下转换了:
可以看到是一个常数,对常数进行转置是不改变其大小的,于是
这里求残差平方和最小值,就涉及矩阵微积分的知识。可以参见《机器学习之矩阵微积分及其性质》标量-向量求导性质(4)。现在将上式两边对求导。
上式两边转置
当可逆时,得到:
可以看到上式右边均和样本数据有关,也就是说,给定样本,我们就可以计算出回归系数估计值了。因为预测值与自变量有如下关系:
将估计量代入,记得到预测值与真实值之间的关系:
如果令,即得到
注意到只与自变量
有关。
拟合优度指标
首先,我们看一下,在多元线性回归模型中,如下恒等式是否还成立:
其中,为总离差平方和,或者总平方和(Total Sum of Squares),如下计算:
为回归平方和,或者解释平方和(Explained Sum of Squares),如下计算:
为残差平方和,或者剩余平方和(Residual Sum of Squares),如下计算:
下面来证明。还是采用矩阵的形式。先令。
(1)第一步:将写成矩阵形式,如下:
将后三项展开成向量的形式,得到:
注意到
所以:
(2)第二步,将写成矩阵形式,同理得到:
(3)第三步,将写成矩阵形式
(4)根据前3步,要想证明,就是要证明:
即:
因为,代入上式左边,得到
因为,替换上式第一项,得到
下面只需要证明中间项为即可。
因为,
则,
即
,两边转置有
于是得到恒等式成立。
于是和一元线性回归拟合优度指标类似,如下定义
我们注意到(R-squared)中并未考虑自变量的个数。在实际问题中,当增加自变量的个数时,
就会增加,即随着自变量的增多,
会越来越大,会显得回归模型精度很高,有较好的拟合效果。而实际上可能并非如此,有些自变量与因变量完全不相关,增加这些自变量,并不会提升拟合水平和预测精度。为避免这种现象,调整的
则会惩罚多余的自变量,避免模型过度拟合。调整后的
(Adj. R-squared)如下:
其中
(1)n是用于拟合回归模型的样本数量,
(2)p为模型中的自变量的个数,
(3)i表示是否有截距,当有截距时为1,否则为0。
可以证明调整后的小于
,并且调整后
的值不会由于自变量个数的增加而越来越接近1。
F检验
原假设:
,
备择假设:
不全为0,
参见《第7章-使用统计方法进行变量有效性测试-7.2.1-单因素方差分析》,关于,可以得到如下关于自由度的结论:
(1)总离差平方和自由度为
,其中n为全部观察值的个数,
(2)回归平方和自由度为
,其中
为自变量个数,
(3)残差平方和自由度为
,
发现自由度满足此恒等式:。
可以如下定义各平方和的平均值:
(1)平均离差平方和,
(2)平均回归平方和,
(3)平均残差平方和
构造F统计量
可以参见《第7章-使用统计方法进行变量有效性测试-7.2.1-单因素方差分析》,证明该统计服从如下F分布:
回归系数的t检验
回归系数的t检验是对每个回归系数检验。如果对第i个回归系数估计量进行检验,那么假设问题如下:
原假设
备择假设
扰动项,
的估计为
。
构造如下统计量:
其中是向量
的第i个值,
,
为矩阵
的第i行j列元素,
。
对于每个,都服从自由度为n-k-1的t分布。关于细节证明可以仿照一元线性回归中的证明思路,只不过这里需要改成矩阵形式,后面有时间我们再不上。
Python中构建多元线性回归模型
数据理解
LR_practice.xlsx文件中给出的是一份汽车贷款的相关数据。希望使用多元线性回归模型分析用户年龄、用户年收入、用户所住小区房屋均价、当地人均等因素与信用卡月均支出的关系。
这里信用卡月均支出是多元线性回归的因变量,而用户年龄、用户年收入、用户所住小区房屋均价、当地人均等因素是多元线性回归的自变量。
Excel中的部分数据如下:
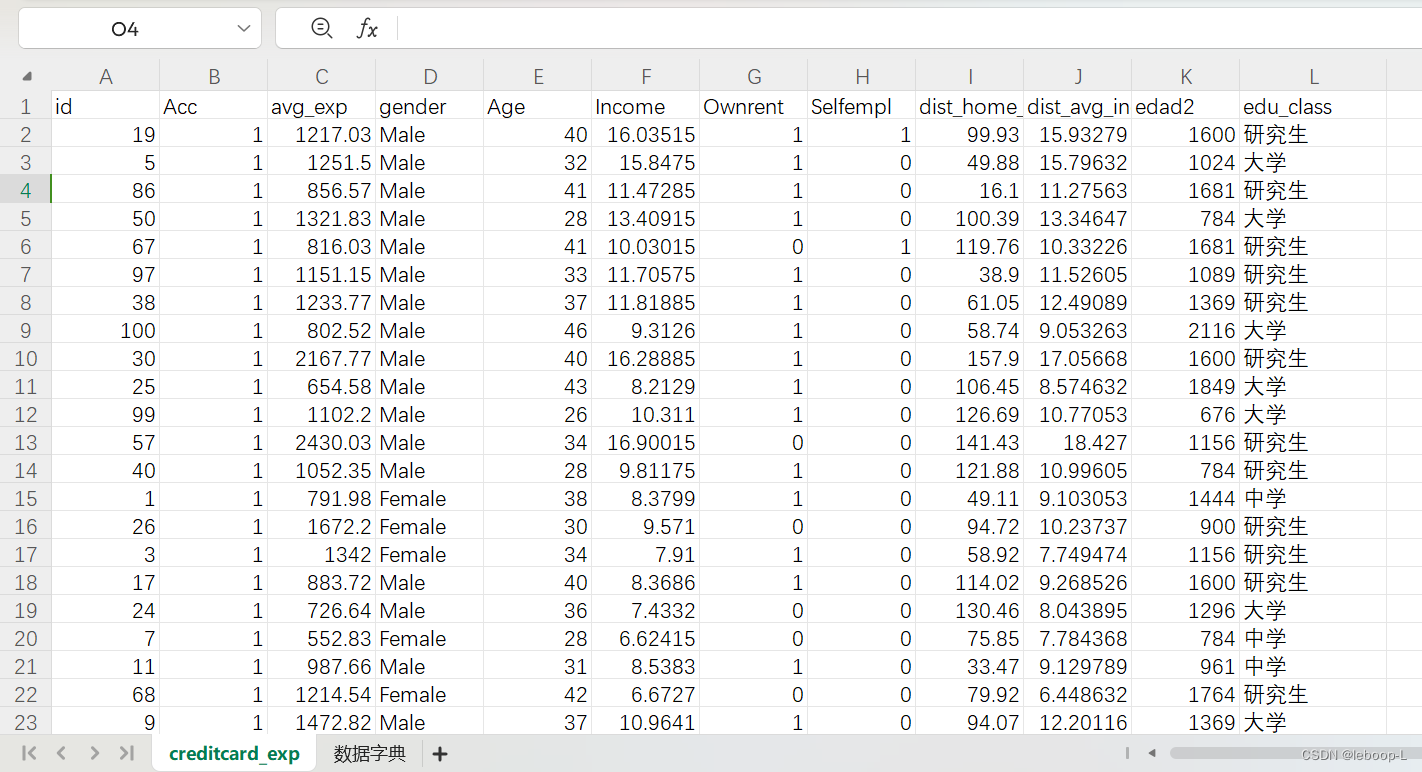
全部数据如下:
id Acc avg_exp gender Age Income Ownrent Selfempl dist_home_val dist_avg_income edad2 edu_class
19 1 1217.03 Male 40 16.03515 1 1 99.93 15.93278947 1600 研究生
5 1 1251.5 Male 32 15.8475 1 0 49.88 15.79631579 1024 大学
86 1 856.57 Male 41 11.47285 1 0 16.1 11.27563158 1681 研究生
50 1 1321.83 Male 28 13.40915 1 0 100.39 13.34647368 784 大学
67 1 816.03 Male 41 10.03015 0 1 119.76 10.33226316 1681 研究生
97 1 1151.15 Male 33 11.70575 1 0 38.9 11.52605263 1089 研究生
38 1 1233.77 Male 37 11.81885 1 0 61.05 12.49089474 1369 研究生
100 1 802.52 Male 46 9.3126 1 0 58.74 9.053263158 2116 大学
30 1 2167.77 Male 40 16.28885 1 0 157.9 17.05668421 1600 研究生
25 1 654.58 Male 43 8.2129 1 0 106.45 8.574631579 1849 大学
99 1 1102.2 Male 26 10.311 1 0 126.69 10.77052632 676 大学
57 1 2430.03 Male 34 16.90015 0 0 141.43 18.427 1156 研究生
40 1 1052.35 Male 28 9.81175 1 0 121.88 10.99605263 784 研究生
1 1 791.98 Female 38 8.3799 1 0 49.11 9.103052632 1444 中学
26 1 1672.2 Female 30 9.571 0 0 94.72 10.23736842 900 研究生
3 1 1342 Female 34 7.91 1 0 58.92 7.749473684 1156 研究生
17 1 883.72 Male 40 8.3686 1 0 114.02 9.268526316 1600 研究生
24 1 726.64 Male 36 7.4332 0 0 130.46 8.043894737 1296 大学
7 1 552.83 Female 28 6.62415 0 0 75.85 7.784368421 784 中学
11 1 987.66 Male 31 8.5383 1 0 33.47 9.129789474 961 中学
68 1 1214.54 Female 42 6.6727 0 0 79.92 6.448631579 1764 研究生
9 1 1472.82 Male 37 10.9641 1 0 94.07 12.20115789 1369 大学
77 1 744.66 Female 24 7.3733 0 0 22.72 8.424 576 中学
98 1 1344.05 Female 25 7.02025 0 0 136.05 7.090263158 625 研究生
36 1 1778.3 Female 43 9.1315 1 0 33.21 9.705789474 1849 研究生
39 1 834.47 Male 27 7.62235 0 0 41.38 8.689315789 729 研究生
73 1 648.15 Male 33 6.14075 0 0 28.49 6.992894737 1089 中学
10 1 884.58 Female 28 5.9229 0 0 51.89 6.946210526 784 大学
16 1 1606.43 Female 41 7.93215 1 0 86.11 8.761210526 1681 研究生
32 1 959.83 Male 29 7.79915 0 0 58.59 8.411210526 841 大学
58 1 1992.39 Female 33 9.84195 0 0 60.52 11.06257895 1089 研究生
33 0 Female 25 3.15 0 1 6.31 2.76 625 小学及以下
70 1 1752.47 Female 25 8.53235 0 0 85.08 9.339842105 625 研究生
79 1 1434.55 Female 36 6.92275 0 0 57.75 7.766578947 1296 研究生
61 1 565.8 Female 25 5.729 0 0 75.25 5.912631579 625 中学
41 1 1581.94 Female 26 7.6097 1 0 61.72 8.332315789 676 研究生
56 1 711.89 Female 33 6.45945 0 0 58.63 7.071526316 1089 中学
18 0 Female 30 3 0 1 106.8 3.7 900 中学
35 1 994.54 Female 24 6.2727 0 0 17.41 7.194947368 576 大学
78 1 888.46 Female 25 5.6223 0 0 71.7 6.046631579 625 大学
92 0 Female 999 2.81 0 1 119.98 2.56 2025
63 1 701.07 Female 26 6.20535 0 0 123.52 6.694578947 676 中学
54 1 806.13 Female 24 5.13065 0 0 112.93 5.863315789 576 大学
74 1 1299.37 Female 37 5.91685 0 0 118.77 5.975105263 1369 研究生
64 1 809.51 Female 22 5.04755 0 0 98.92 5.801105263 484 大学
82 1 610.25 Female 55 3.99125 1 0 116.93 4.932368421 3025 大学
45 0 Female 38 2.6 0 0 29.83 3.11 1444 小学及以下
42 1 485.65 Female 23 4.91825 0 0 50.15 5.470789474 529 中学
80 1 963.68 Female 33 5.6684 0 0 100.92 6.192526316 1089 大学
4 1 993.87 Female 31 5.80935 0 0 66.71 6.111421053 961 大学
29 0 Female 34 2.5 0 1 25.59 2.48 1156 小学及以下
6 1 524 Female 23 5.02 0 0 14.76 5.252631579 529 中学
34 1 1403.72 Female 21 7.7886 1 0 133.18 7.948526316 441 大学
71 1 1629.05 Female 31 7.30525 1 0 64.61 8.310263158 961 研究生
14 1 745.87 Female 29 6.07935 1 0 96.51 7.020368421 841 中学
2 0 Female 33 2.42 0 0 40.57 3.43 1089 中学
55 1 527.19 Female 26 4.93595 0 0 24.95 5.759421053 676 中学
93 1 520.38 Female 43 4.9019 0 0 13.13 5.253578947 1849 中学
84 1 251.56 Female 29 5.1578 0 0 63.23 5.492947368 841 小学及以下
8 1 817.79 Female 29 6.35895 1 0 44.39 6.318894737 841 中学
49 1 889.08 Female 26 5.0954 0 0 50.88 5.909894737 676 大学
21 1 1048.34 Female 35 5.8917 1 0 67.47 7.078105263 1225 大学
62 1 847.78 Female 27 4.8189 0 0 57.69 5.952526316 729 大学
75 1 593.11 Female 27 5.06555 0 0 38.06 5.556368421 729 中学
31 1 772.69 Female 22 4.19345 0 0 62.29 5.237315789 484 大学
52 1 545.2 Female 24 4.626 0 0 119.39 4.454210526 576 中学
23 1 905.52 Female 34 6.4276 1 0 27.82 6.960631579 1156 中学
47 1 1175.49 Female 36 6.17745 0 0 109.06 7.327315789 1296 大学
72 1 1006.35 Female 27 5.33175 0 0 133.26 6.557105263 729 大学
15 1 727.62 Female 35 5.4481 1 0 32.98 5.924315789 1225 中学
44 1 695.85 Female 30 5.22925 0 0 73.69 5.967105263 900 中学
53 1 491.04 Female 21 4.0552 0 0 36.81 4.349157895 441 中学
83 1 468.61 Female 20 3.89305 0 0 66.75 4.551105263 400 中学
43 1 593.92 Female 30 4.3796 0 0 124.23 5.040631579 900 中学
60 1 418.78 Female 21 3.4939 0 0 34.46 3.828842105 441 中学
28 1 163.18 Female 22 3.8159 0 0 63.27 3.997789474 484 小学及以下数据字典如下:
| 字段名称 | 中文含义 |
| id | 编号 |
| Acc | 是否开卡(1=已开通) |
| avg_exp | 月均信用卡支出(元) |
| gender | 性别 |
| Age | 年龄 |
| Income | 年收入(万元) |
| Ownrent | 是否自有住房(有=1;无=0) |
| Selfempl | 是否自谋职业(1=yes, 0=no) |
| dist_home_val | 所住小区房屋均价(万元) |
| dist_avg_income | 当地人均收入 |
| edad2 | |
| edu_class | 教育等级:小学及以下,中学,本科,研究生 |
其中edad2是设置的一项无关数据(以便后面描述清洗使用)。
数据读取
可以使用代码方式读取数据,并查询数据集的基本信息,为后续数据清洗做准备。代码如下:
import pandas as pd
from statsmodels.formula.api import ols
import matplotlib.pyplot as plt
from scipy import stats
if __name__ == '__main__':
# 读取信用卡消费数据
data_path = r'E:\证书认证\CDA\Level2code&data\第7章-假设检验与方差分析、线性回归、逻辑回归\线性回归\LR_practice.xlsx'
data_raw_df = pd.read_excel(data_path)
print('原始数据data_raw_df=', '\n', data_raw_df)
print('-----------------------------------------------------------------')
# 打印原始数据信息
print('原始数据信息data_raw_info=')
data_raw_df.info()
print('-----------------------------------------------------------------')运行结果,如下:
原始数据data_raw_df=
id Acc avg_exp gender ... dist_home_val dist_avg_income edad2 edu_class
0 19 1 1217.03 Male ... 99.93 15.932789 1600 研究生
1 5 1 1251.50 Male ... 49.88 15.796316 1024 大学
2 86 1 856.57 Male ... 16.10 11.275632 1681 研究生
3 50 1 1321.83 Male ... 100.39 13.346474 784 大学
4 67 1 816.03 Male ... 119.76 10.332263 1681 研究生
.. .. ... ... ... ... ... ... ... ...
71 53 1 491.04 Female ... 36.81 4.349158 441 中学
72 83 1 468.61 Female ... 66.75 4.551105 400 中学
73 43 1 593.92 Female ... 124.23 5.040632 900 中学
74 60 1 418.78 Female ... 34.46 3.828842 441 中学
75 28 1 163.18 Female ... 63.27 3.997789 484 小学及以下
[76 rows x 12 columns]
-----------------------------------------------------------------
原始数据信息data_raw_info=
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 76 entries, 0 to 75
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 76 non-null int64
1 Acc 76 non-null int64
2 avg_exp 70 non-null float64
3 gender 76 non-null object
4 Age 76 non-null int64
5 Income 76 non-null float64
6 Ownrent 76 non-null int64
7 Selfempl 76 non-null int64
8 dist_home_val 76 non-null float64
9 dist_avg_income 76 non-null float64
10 edad2 76 non-null int64
11 edu_class 75 non-null object
dtypes: float64(4), int64(6), object(2)
memory usage: 7.2+ KB
-----------------------------------------------------------------从打印的数据来看,总计有76行数据,共有12个列。从数据集的基本信息,显示了数据的字段编号,字段名称,非空个数统计,数据类型。非空个数统计表明如下两个字段存在空值。
2 avg_exp 70 non-null float64
11 edu_class 75 non-null object 数据清洗
根据数据读取,初步分析的情况,指定如下清洗策略:
(1)删除无关的列
有些列的数据是无实质性意义的,或者和分析无关。比如id,edad2。而Acc字段表示用户是否开卡,只有开卡用户才会有信用卡支出,因此Acc不能进入模型,也需要删除。
(2)删除重复数据
在这份数据中,重复数据可以看成是脏数据,直接删除。
(3)缺失值填充
可以通过代码查看数据缺失情况,然后针对每种情况,使用不同的缺失值填充策略,完成缺失值填充。
(4)数据转换
有些数据可能是文本型的数据,不能直接用于数据分析。需要将其转换成数值型数据,例如gender取值为Male,Female,需要将其转换成数值型,比如Male转换成1,Female转换成0。
(5)异常值处理
有些数据明显是异常数据,影响整体的分析效果,需要将其删除,或者使用正常值填充。这里可以使用原则。本文实现的时候,也是使用的该原则。
(6)对多分类自变量进行哑变量变换
对于多分类自变量,假如直接将其纳入分析模型,得出的结果就会不精确,甚至会得到错误的结论。这是因为多分类自变量直接当作定量数据来计算,人为的拔高了数据的“维度”和丰富程度,此时,我们应当多分类自变量进行哑变量处理。
哑变量(Dummy Variable)是一种用来表示分类变量的方法,它将每个类别转化为一个二进制变量(0和1表示)。基本原理是将有k个类别的多分类自变量转换为k个哑变量(二进制变量)。在实际分析中,一般取一个类别作为参照水平,而将剩下的k-1个哑变量纳入模型。例如本例中有教育程度edu_class,是一个多分类自变量。总共有4个类别,转换成数值型后为0,1,2,3。其中有一些数据edu_class空白,使用其他类别来填充,比如4。现在得到edu_class的类别为0,1,2,3,4。假设上面76行数据中,edu_class这一列数据如下:
| edu_class |
| 0 |
| 1 |
| 1 |
| ... |
| 2 |
| 4 |
进行哑变量变换后,后面增加5列,每一列代表一个哑变量。如下:
| edu_class | dummy_0 | dummy_1 | dummy_2 | dummy_3 | dummy_4 |
| 0 | 1 | 0 | 0 | 0 | 0 |
| 1 | 0 | 1 | 0 | 0 | 0 |
| 1 | 0 | 1 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... |
| 2 | 0 | 0 | 1 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 1 |
比如第一行,edu_class类别为0,那么后面增加的5列,dummy_0为1,其余为0。下面使用代码实现上述清洗策略,如下:
import pandas as pd
from statsmodels.formula.api import ols
import matplotlib.pyplot as plt
from scipy import stats
if __name__ == '__main__':
# 读取信用卡消费数据
data_path = r'E:\证书认证\CDA\Level2code&data\第7章-假设检验与方差分析、线性回归、逻辑回归\线性回归\LR_practice.xlsx'
data_raw_df = pd.read_excel(data_path)
print('原始数据data_raw_df=', '\n', data_raw_df)
print('-----------------------------------------------------------------')
# 打印原始数据信息
print('原始数据信息data_raw_info=')
data_raw_df.info()
print('-----------------------------------------------------------------')
# 删除无用字段
# inplace=True表示直接在原始数据上删除列,返回None,inplace=False表示复制一份然后删除列,返回删除后的数据
# axis=1或者columns表示删除按列名删除列,axis=0或者index表示按照索引删除行.
data_drop_col_df = data_raw_df.drop(['id', 'Acc', 'edad2'], axis='columns', inplace=False)
print('删除无用的列后data_drop_col_df=', '\n', data_drop_col_df)
print('-----------------------------------------------------------------')
# 删除重复数据
df = data_drop_col_df.drop_duplicates()
print('删除重复数据df=', '\n', df)
print('-----------------------------------------------------------------')
# 缺失值填补 avg_exp 和 edu_class 存在缺失值.
data_isnull_mean = df.isnull().mean()
print('数据缺失情况data_isnull_mean=', '\n', data_isnull_mean)
# 使用平均值填补avg_exp缺失值
avg_exp_col = 'avg_exp'
df[avg_exp_col] = df[avg_exp_col].fillna(df[avg_exp_col].mean())
# 填补edu_class
edu_class_col = 'edu_class'
edu_class_label = df[edu_class_col].unique().tolist() # 获取教育水平的类别,缺失值显示为nan.
print('教育水平类别edu_class_label=', '\n', edu_class_label)
df[edu_class_col] = df[edu_class_col].apply(lambda x: edu_class_label.index(x)) # 将教育水平转换成数字索引.
# 性别gender数据转换
gender_col = 'gender'
df[gender_col] = df[gender_col].map({'Male': 1, 'Female': 0})
print('df=', '\n', df)
# 打印缺失值填补后的数据
print('缺失值填补后的数据信息如下:')
df.info()
print('-----------------------------------------------------------------')
# 异常值处理
age_col = 'Age'
zscore = stats.zscore(df[age_col])
print('年龄zscore=', '\n', zscore)
my_zscore = (df - df[age_col].mean()) / df[age_col].std() # (每个值-平均值)/标准差
print('自己实现的my_zscore=', '\n', zscore)
z_outlier = (zscore > 3) | (zscore < -3) # 这里使用了3-sigma原则,|xi-u|>3sigma的数据是异常数据.
print('z_outlier=', '\n', z_outlier)
except_index = z_outlier.tolist().index(1) # 异常数据的位置索引.
print('异常数据索引位置except_index=', except_index)
# 异常值填充:排除异常值后,计算均值进行填充.
df_mean = df[age_col].drop(except_index, inplace=False)
df[age_col].iloc[except_index] = df_mean.mean()
print('-----------------------------------------------------------------')
# 哑变量
dummy = pd.get_dummies(df[edu_class_col], prefix='edu').iloc[:, 1:]
print('哑变量dummy=', '\n', dummy)
data = pd.concat([df, dummy], axis=1)
print('拼接哑变量data=', '\n', data)
print('-----------------------------------------------------------------')运行结果如下:
删除无用的列后data_drop_col_df=
avg_exp gender Age ... dist_home_val dist_avg_income edu_class
0 1217.03 Male 40 ... 99.93 15.932789 研究生
1 1251.50 Male 32 ... 49.88 15.796316 大学
2 856.57 Male 41 ... 16.10 11.275632 研究生
3 1321.83 Male 28 ... 100.39 13.346474 大学
4 816.03 Male 41 ... 119.76 10.332263 研究生
.. ... ... ... ... ... ... ...
71 491.04 Female 21 ... 36.81 4.349158 中学
72 468.61 Female 20 ... 66.75 4.551105 中学
73 593.92 Female 30 ... 124.23 5.040632 中学
74 418.78 Female 21 ... 34.46 3.828842 中学
75 163.18 Female 22 ... 63.27 3.997789 小学及以下
[76 rows x 9 columns]
-----------------------------------------------------------------
删除重复数据df=
avg_exp gender Age ... dist_home_val dist_avg_income edu_class
0 1217.03 Male 40 ... 99.93 15.932789 研究生
1 1251.50 Male 32 ... 49.88 15.796316 大学
2 856.57 Male 41 ... 16.10 11.275632 研究生
3 1321.83 Male 28 ... 100.39 13.346474 大学
4 816.03 Male 41 ... 119.76 10.332263 研究生
.. ... ... ... ... ... ... ...
71 491.04 Female 21 ... 36.81 4.349158 中学
72 468.61 Female 20 ... 66.75 4.551105 中学
73 593.92 Female 30 ... 124.23 5.040632 中学
74 418.78 Female 21 ... 34.46 3.828842 中学
75 163.18 Female 22 ... 63.27 3.997789 小学及以下
[76 rows x 9 columns]
-----------------------------------------------------------------
数据缺失情况data_isnull_mean=
avg_exp 0.078947
gender 0.000000
Age 0.000000
Income 0.000000
Ownrent 0.000000
Selfempl 0.000000
dist_home_val 0.000000
dist_avg_income 0.000000
edu_class 0.013158
dtype: float64
教育水平类别edu_class_label=
['研究生', '大学', '中学', '小学及以下', nan]
df=
avg_exp gender Age ... dist_home_val dist_avg_income edu_class
0 1217.03 1 40 ... 99.93 15.932789 0
1 1251.50 1 32 ... 49.88 15.796316 1
2 856.57 1 41 ... 16.10 11.275632 0
3 1321.83 1 28 ... 100.39 13.346474 1
4 816.03 1 41 ... 119.76 10.332263 0
.. ... ... ... ... ... ... ...
71 491.04 0 21 ... 36.81 4.349158 2
72 468.61 0 20 ... 66.75 4.551105 2
73 593.92 0 30 ... 124.23 5.040632 2
74 418.78 0 21 ... 34.46 3.828842 2
75 163.18 0 22 ... 63.27 3.997789 3
[76 rows x 9 columns]
缺失值填补后的数据信息如下:
<class 'pandas.core.frame.DataFrame'>
Int64Index: 76 entries, 0 to 75
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 avg_exp 76 non-null float64
1 gender 76 non-null int64
2 Age 76 non-null int64
3 Income 76 non-null float64
4 Ownrent 76 non-null int64
5 Selfempl 76 non-null int64
6 dist_home_val 76 non-null float64
7 dist_avg_income 76 non-null float64
8 edu_class 76 non-null int64
dtypes: float64(4), int64(5)
memory usage: 5.9 KB
-----------------------------------------------------------------
年龄zscore=
0 -0.035723
1 -0.108122
2 -0.026673
3 -0.144321
4 -0.026673
...
71 -0.207670
72 -0.216720
73 -0.126221
74 -0.207670
75 -0.198620
Name: Age, Length: 76, dtype: float64
自己实现的my_zscore=
0 -0.035723
1 -0.108122
2 -0.026673
3 -0.144321
4 -0.026673
...
71 -0.207670
72 -0.216720
73 -0.126221
74 -0.207670
75 -0.198620
Name: Age, Length: 76, dtype: float64
z_outlier=
0 False
1 False
2 False
3 False
4 False
...
71 False
72 False
73 False
74 False
75 False
Name: Age, Length: 76, dtype: bool
异常数据索引位置except_index= 40
-----------------------------------------------------------------
哑变量dummy=
edu_1 edu_2 edu_3 edu_4
0 0 0 0 0
1 1 0 0 0
2 0 0 0 0
3 1 0 0 0
4 0 0 0 0
.. ... ... ... ...
71 0 1 0 0
72 0 1 0 0
73 0 1 0 0
74 0 1 0 0
75 0 0 1 0
[76 rows x 4 columns]
拼接哑变量data=
avg_exp gender Age Income ... edu_1 edu_2 edu_3 edu_4
0 1217.03 1 40.0 16.03515 ... 0 0 0 0
1 1251.50 1 32.0 15.84750 ... 1 0 0 0
2 856.57 1 41.0 11.47285 ... 0 0 0 0
3 1321.83 1 28.0 13.40915 ... 1 0 0 0
4 816.03 1 41.0 10.03015 ... 0 0 0 0
.. ... ... ... ... ... ... ... ... ...
71 491.04 0 21.0 4.05520 ... 0 1 0 0
72 468.61 0 20.0 3.89305 ... 0 1 0 0
73 593.92 0 30.0 4.37960 ... 0 1 0 0
74 418.78 0 21.0 3.49390 ... 0 1 0 0
75 163.18 0 22.0 3.81590 ... 0 0 1 0
[76 rows x 13 columns]相关分析
之前我们说过,相关分析是回归分析的基础。如果自变量和因变量毫不相关,进一步回归分析也没有意义。下面计算各变量之间的相关系数。
# 之前我们说相关分析是回归分析的基础。在建立回归分析模型前先,需要做自变量和因变量之间的相关分析.
# 月均信用卡支出(元)、性别(男=1,女=0)、是否有自住房(有=1,无=0)、是否自谋职业(是=1,否=0)、教育等级
corr_col = ['avg_exp', 'gender', 'Ownrent', 'Selfempl', 'edu_class', 'Income']
cor_relation = data[corr_col].corr(method='kendall') # 肯德尔等级相关系数
print('相关系数cor_relation=', '\n', cor_relation)
print('-----------------------------------------------------------------')运行结果如下:
相关系数cor_relation=
avg_exp gender Ownrent Selfempl edu_class Income
avg_exp 1.000000 0.167236 0.290705 0.064150 -0.561243 0.421110
gender 0.167236 1.000000 0.430469 0.046657 -0.351901 0.558598
Ownrent 0.290705 0.430469 1.000000 -0.115370 -0.300133 0.474305
Selfempl 0.064150 0.046657 -0.115370 1.000000 0.154962 -0.135274
edu_class -0.561243 -0.351901 -0.300133 0.154962 1.000000 -0.551915
Income 0.421110 0.558598 0.474305 -0.135274 -0.551915 1.000000
-----------------------------------------------------------------从结果来看,与avg_exp相关性最高的是edu_class,为-0.561243(忽略正负)。从整体来看,各个自变量之间都有一定的相关性,但是相关性不是很高。虽然违背了多元线性模型的假定,但相关性不至于影响到回归模型不能使用。
除了使用相关系数来分析各变量之间的相关程度,也可以使用可视化的方式显示各变量的分布情况,例如散点图。下面看下,avg_exp和Income之间的关系,代码如下:
# 绘制散点图
plt.rcParams["font.sans-serif"] = ["SimHei"] # 显示中文
plt.scatter(data['Income'], data['avg_exp'])
plt.xlabel('Income-年收入(万元)')
plt.ylabel('avg_exp-月均信用卡支出(元)')
plt.title('年收入与月均信用卡支出散点图')
plt.show()
print('-----------------------------------------------------------------')运行结果如下:
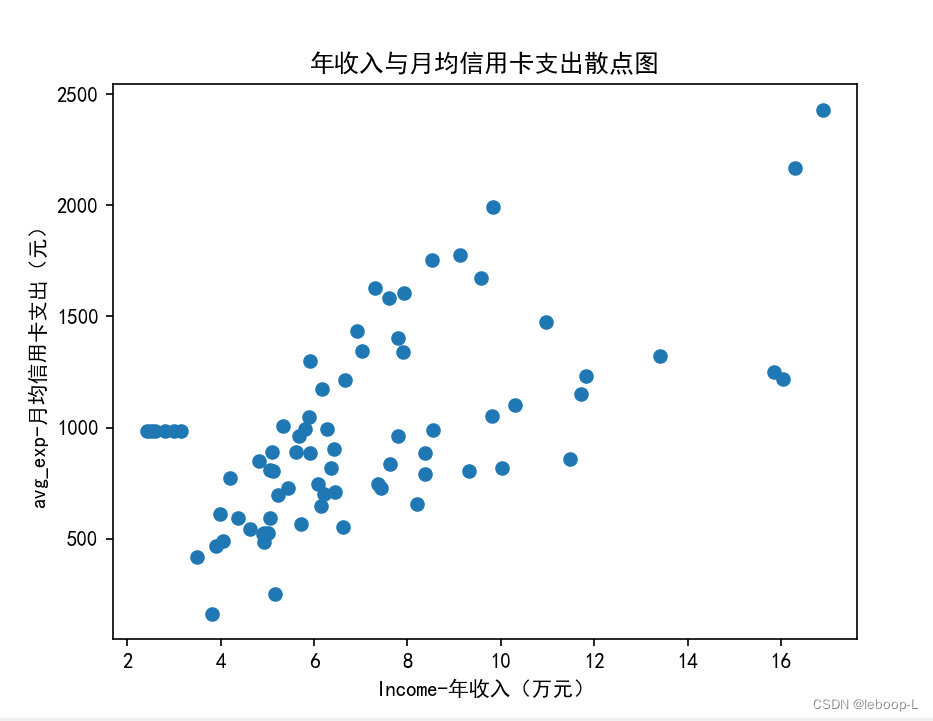
从图中可以看到,Income与avg_exp存在一定的正相关性。
回归分析
经过上面的数据清洗,相关分析,可以进入正式主题了。这里使用statsmodels模块的ols构建多元线性回归模型。代码如下:
# 建立多元线性模型
formula = 'avg_exp~gender+Age+Income+Ownrent+Selfempl+dist_home_val+dist_avg_income+edu_1+edu_2+edu_3+edu_4'
model = ols(formula=formula, data=data) # 建立模型
model = model.fit() # 训练
summary = model.summary()
print('summary=', '\n', summary)第一步:定义formula,因变量与自变量之间使用~连接,因变量写在左边,多个自变量之间使用加号+连接。
第二步:定义模型,传入公式和数据。
第三步:使用数据拟合模型,也就是fit()方法。
第四步:模型拟合优度等summary信息查看,主要看下拟合效果如何。
运行结果,如下:
summary=
OLS Regression Results
==============================================================================
Dep. Variable: avg_exp R-squared: 0.720
Model: OLS Adj. R-squared: 0.671
Method: Least Squares F-statistic: 14.93
Date: Thu, 23 Nov 2023 Prob (F-statistic): 8.36e-14
Time: 14:07:25 Log-Likelihood: -519.52
No. Observations: 76 AIC: 1063.
Df Residuals: 64 BIC: 1091.
Df Model: 11
Covariance Type: nonrobust
===================================================================================
coef std err t P>|t| [0.025 0.975]
-----------------------------------------------------------------------------------
Intercept 535.9565 223.038 2.403 0.019 90.387 981.526
gender -447.4828 97.100 -4.608 0.000 -641.463 -253.503
Age 0.6121 4.779 0.128 0.898 -8.936 10.160
Income -119.1929 72.411 -1.646 0.105 -263.850 25.464
Ownrent 41.3184 76.416 0.541 0.591 -111.341 193.977
Selfempl 153.7000 129.424 1.188 0.239 -104.853 412.253
dist_home_val 0.1579 0.859 0.184 0.855 -1.557 1.873
dist_avg_income 211.5250 71.122 2.974 0.004 69.442 353.608
edu_1 -262.5083 82.890 -3.167 0.002 -428.100 -96.916
edu_2 -495.1400 92.266 -5.366 0.000 -679.462 -310.818
edu_3 -292.5211 156.617 -1.868 0.066 -605.400 20.358
edu_4 49.3783 294.618 0.168 0.867 -539.188 637.945
==============================================================================
Omnibus: 0.894 Durbin-Watson: 2.112
Prob(Omnibus): 0.640 Jarque-Bera (JB): 0.613
Skew: -0.219 Prob(JB): 0.736
Kurtosis: 3.044 Cond. No. 1.00e+03
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 1e+03. This might indicate that there are
strong multicollinearity or other numerical problems.
Process finished with exit code 0
考虑到模型的总结结果比较重要。这里做一些详细解释和分析。上面的结果分为两部分
第一步结果如下:
| Dep. Variable: avg_exp | 因变量:avg_exp |
| Model: OLS | 模型名称:OLS |
| Method: Least Squares | 模型方法:最小二乘法 |
| Date: Thu, 23 Nov 2023 | 模型日期信息 |
| Time: 14:21:52 | 模型时间信息 |
| No. Observations: 76 | 观测值数量:n=76 |
| Df Residuals: 64 | 残差自由度n-k-1=76-11-1=64 |
| Df Model: 11 | 自变量个数k=11,对应代码中formula自变量个数 |
| Covariance Type: nonrobust | |
| R-squared: 0.720 |
|
| Adj. R-squared: 0.671 | 调整后的 |
| F-statistic: 14.93 | F统计值 |
| Prob (F-statistic): 8.36e-14 | p-值,大于F统计值的概率 |
| Log-Likelihood: -519.52 | 对数最大似然 |
| AIC: 1063. | AIC准则,评估回归模型优劣的指标 |
| BIC: 1091. | BIC准则,评估回归模型优劣的指标 |
其中Log-Likelihood,AIC,BIC这三个本文未涉及,后续涉及再细说。
第二部分结果详细给出了样本回归函数,以及回归系数估计量的t检验信息。
===================================================================================
coef std err t P>|t| [0.025 0.975]
-----------------------------------------------------------------------------------
Intercept 535.9565 223.038 2.403 0.019 90.387 981.526
gender -447.4828 97.100 -4.608 0.000 -641.463 -253.503
Age 0.6121 4.779 0.128 0.898 -8.936 10.160
Income -119.1929 72.411 -1.646 0.105 -263.850 25.464
Ownrent 41.3184 76.416 0.541 0.591 -111.341 193.977
Selfempl 153.7000 129.424 1.188 0.239 -104.853 412.253
dist_home_val 0.1579 0.859 0.184 0.855 -1.557 1.873
dist_avg_income 211.5250 71.122 2.974 0.004 69.442 353.608
edu_1 -262.5083 82.890 -3.167 0.002 -428.100 -96.916
edu_2 -495.1400 92.266 -5.366 0.000 -679.462 -310.818
edu_3 -292.5211 156.617 -1.868 0.066 -605.400 20.358
edu_4 49.3783 294.618 0.168 0.867 -539.188 637.945
============================================================================== coef列表示样本回归函数的回归系数。其中第一个系数Intercept表示截距,也就是
的值。第3列t表示每个回归系数
对应的t统计量
。P>|t|表示p-值,最后两列放在一起表示置信区间。关于置信区间这里暂时不展开讨论。
模型解释
从以上结果中,可以看到模型的为0.720,拟合效果还是不错的。默认显著性水平
,F检验的p值为8.36e-14,接近0,拒绝原假设
:
,说明回归系数不为0。从单个系数的显著性t检验来看,初步判断gender、dist_avg_income及edu_class是显著的,P>|t|的值接近0。对于目前表现不显著的变量,需要进一步对模型调优后作出显著与否的判断。
附录
本文涉及的所有代码如下:
import pandas as pd
from statsmodels.formula.api import ols
import matplotlib.pyplot as plt
from scipy import stats
if __name__ == '__main__':
# 读取信用卡消费数据
data_path = r'E:\证书认证\CDA\Level2code&data\第7章-假设检验与方差分析、线性回归、逻辑回归\线性回归\LR_practice.xlsx'
data_raw_df = pd.read_excel(data_path)
print('原始数据data_raw_df=', '\n', data_raw_df)
print('-----------------------------------------------------------------')
# 打印原始数据信息
print('原始数据信息data_raw_info=')
data_raw_df.info()
print('-----------------------------------------------------------------')
# 删除无用字段
# inplace=True表示直接在原始数据上删除列,返回None,inplace=False表示复制一份然后删除列,返回删除后的数据
# axis=1或者columns表示删除按列名删除列,axis=0或者index表示按照索引删除行.
data_drop_col_df = data_raw_df.drop(['id', 'Acc', 'edad2'], axis='columns', inplace=False)
print('删除无用的列后data_drop_col_df=', '\n', data_drop_col_df)
print('-----------------------------------------------------------------')
# 删除重复数据
df = data_drop_col_df.drop_duplicates()
print('删除重复数据df=', '\n', df)
print('-----------------------------------------------------------------')
# 缺失值填补 avg_exp 和 edu_class 存在缺失值.
data_isnull_mean = df.isnull().mean()
print('数据缺失情况data_isnull_mean=', '\n', data_isnull_mean)
# 使用平均值填补avg_exp缺失值
avg_exp_col = 'avg_exp'
df[avg_exp_col] = df[avg_exp_col].fillna(df[avg_exp_col].mean())
# 填补edu_class
edu_class_col = 'edu_class'
edu_class_label = df[edu_class_col].unique().tolist() # 获取教育水平的类别,缺失值显示为nan.
print('教育水平类别edu_class_label=', '\n', edu_class_label)
df[edu_class_col] = df[edu_class_col].apply(lambda x: edu_class_label.index(x)) # 将教育水平转换成数字索引.
# 性别gender数据转换
gender_col = 'gender'
df[gender_col] = df[gender_col].map({'Male': 1, 'Female': 0})
print('df=', '\n', df)
# 打印缺失值填补后的数据
print('缺失值填补后的数据信息如下:')
df.info()
print('-----------------------------------------------------------------')
# 异常值处理
age_col = 'Age'
zscore = stats.zscore(df[age_col])
print('年龄zscore=', '\n', zscore)
my_zscore = (df - df[age_col].mean()) / df[age_col].std() # (每个值-平均值)/标准差
print('自己实现的my_zscore=', '\n', zscore)
z_outlier = (zscore > 3) | (zscore < -3) # 这里使用了3-sigma原则,|xi-u|>3sigma的数据是异常数据.
print('z_outlier=', '\n', z_outlier)
except_index = z_outlier.tolist().index(1) # 异常数据的位置索引.
print('异常数据索引位置except_index=', except_index)
# 异常值填充:排除异常值后,计算均值进行填充.
df_mean = df[age_col].drop(except_index, inplace=False)
df[age_col].iloc[except_index] = df_mean.mean()
print('-----------------------------------------------------------------')
# 哑变量
dummy = pd.get_dummies(df[edu_class_col], prefix='edu').iloc[:, 1:]
print('哑变量dummy=', '\n', dummy)
data = pd.concat([df, dummy], axis=1)
print('拼接哑变量data=', '\n', data)
print('-----------------------------------------------------------------')
# 之前我们说相关分析是回归分析的基础。在建立回归分析模型前先,需要做自变量和因变量之间的相关分析.
# 月均信用卡支出(元)、性别(男=1,女=0)、是否有自住房(有=1,无=0)、是否自谋职业(是=1,否=0)、教育等级
corr_col = ['avg_exp', 'gender', 'Ownrent', 'Selfempl', 'edu_class', 'Income']
cor_relation = data[corr_col].corr(method='kendall') # 肯德尔等级相关系数
print('相关系数cor_relation=', '\n', cor_relation)
print('-----------------------------------------------------------------')
# 绘制散点图
plt.rcParams["font.sans-serif"] = ["SimHei"] # 显示中文
plt.scatter(data['Income'], data['avg_exp'])
plt.xlabel('Income-年收入(万元)')
plt.ylabel('avg_exp-月均信用卡支出(元)')
plt.title('年收入与月均信用卡支出散点图')
plt.show()
print('-----------------------------------------------------------------')
# 建立多元线性模型
formula = 'avg_exp ~ gender+Age+Income+Ownrent+Selfempl+dist_home_val+dist_avg_income+edu_1+edu_2+edu_3+edu_4'
model = ols(formula=formula, data=data) # 建立模型
model = model.fit() # 训练
summary = model.summary()
print('summary=', '\n', summary)
参考文献
https://home.ustc.edu.cn/~wdyknight/notes/reg_chap3.pdf