1、Ceph是什么?
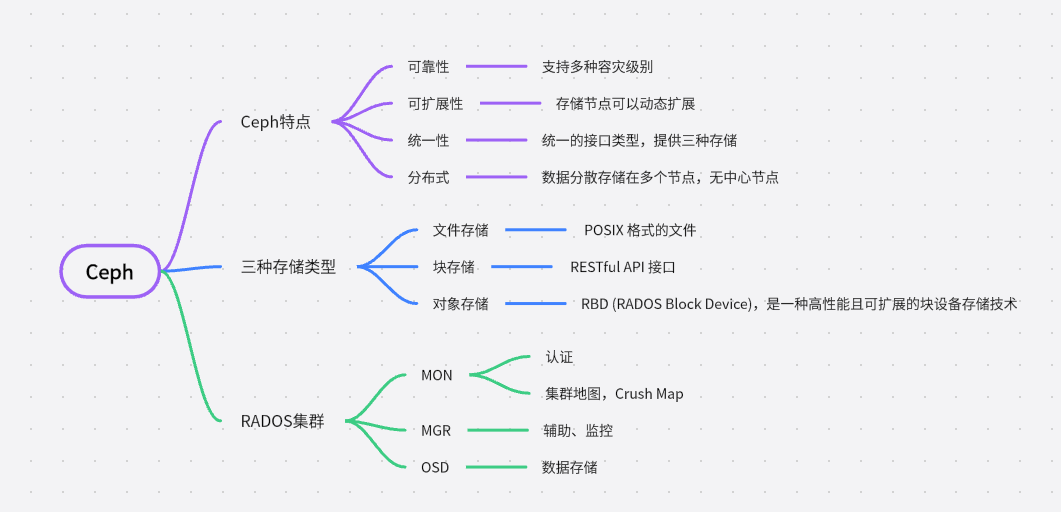
“Ceph is a unified, distributed storage system designed for excellent performance, reliability and scalability.”这句话说出了Ceph的特性,它是可靠的、可扩展的、统一的、分布式的存储系统。Ceph可以同时提供对象存储RADOSGW(Reliable、Autonomic、Distributed、Object Storage Gateway)、块存储RBD(Rados Block Device)、文件系统存储Ceph FS(Ceph Filesystem)3种功能。
-
可靠性,因为它使用数据冗余和容错机制来保护数据的完整性和可靠性。它将数据分散存储在多个存储节点上,通过数据复制和数据恢复技术来避免数据丢失。即使一个存储节点发生故障,数据仍然可以通过其他节点进行访问和恢复。(ceph 是支持多种冗余级别的最小称为盘级别冗余)
-
可扩展性,因为它使用了分布式存储架构。它可以通过增加存储节点,来扩展存储容量和性能。每个节点都可以平行处理和存储数据,因此可以线性地增加整个系统的存储容量和吞吐量。这种可扩展性使得Ceph非常适合处理大规模数据存储和处理需求。
-
统一性:因为它提供了多种存储功能,包括对象存储、块存储和文件系统存储。这些不同类型的存储可以在同一个Ceph集群中同时存在,并且可以根据不同的应用需求进行灵活部署和管理。这种统一性简化了存储架构和管理,并且提供了更好的灵活性和应用兼容性。
-
分布式:因为它将数据分散存储在多个节点上,并且通过网络连接实现节点之间的通信和数据传输。每个节点都可以独立处理和存储数据,没有单点故障,并且可以进行横向扩展。分布式架构提供了高可用性、高性能和灵活性,并且使得Ceph能够适应各种应用场景和规模
2、三种存储类型
-
文件存储: 文件存储是一种以文件为单位进行数据存储的方式。在文件存储中,数据以文件的形式存储在文件系统中,可以通过文件名或路径来进行访问和管理。文件存储适用于存储相对较小的文件,并提供了对文件的完整控制和管理,例如读取、写入、修改和删除文件。常见的文件存储如NFS。其最常见的用途就是可以多用户同时挂载后,同时进行读写操作。
为什么我们需要文件存储,有块存储不就够了吗?
在回答这个问题之前,让我们先讨论一下数据库。在数据库等系统中,无论是主从还是多主架构,都面临着数据不一致的问题。主从架构下,备库的数据会延迟于主库,而多主从架构下,如果数据是分布式存放的,则请求只能发送到相应的节点,如果是非分布式存放的,则会有多份数据,导致集群的整体利用率不高。
试想一下,如果我们能将数据只存放一份,其在本质上就解决了在不同节点上数据不一致的问题,我们可以采用类似NFS的架构,将一个目录映射到多个数据库节点上,而多个数据库实例实际上请求的都是同一份数据原文件。此时利用的就是文件存储能支持多用户同时挂载和读写。
块存储是否就不支持多用户同时读写了?
块存储也支持多用户同时读写,但是需要通过适当的权限控制和管理来确保数据的一致性和安全性,也就是说需要自行解决数据一致性问题。
-
块存储块存储是一种以块(通常是固定大小的数据块)为单位进行数据存储的方式。在块存储中,数据以块的形式存储在独立的存储设备上,每个块都有唯一的标识符。块存储将数据划分为相对较小且固定大小的块,这些块可以根据需要进行读取、写入和修改。块存储适用于需要随机读写访问的应用,如数据库、虚拟机和操作系统。块存储可以理解为一个磁盘或分区,在linux 系统中此类设备被映射为一个 块类型的文件。如下图中的类型为b(block)
ll /dev/sda
brw-rw---- 1 root disk 8, 0 Nov 13 17:53 /dev/sda而对块设备如果用mkfs.xfs 或 mkfs.ext4 等命令执行文件系统初始化后就是一个文件系统设备。
-
对象存储 对象存储以对象形式存储数据,每个对象都有唯一的标识符。对象通常包含数据本身以及与其相关的元数据。云存储服务如Amazon S3和OpenStack Swift就是典型的对象存储系统。当你上传照片到云相册或者将文件存储到云端时,这些数据都会以对象的形式存储。每个对象都有一个唯一的标识符,比如URL或者API密钥。
ceph自身是一个对象存储,其能提供对象存储我们能理解,为什么其还能提供块存储和文件存储了?
通用的 RADOS 存储结构和可靠的分布式存储技术。通过统一接口可以更好地处理各种数据类型,以及整合其他存储服务的优势,从而提供块存储和对象存储和文件存储三种存储功能。
3 、 Ceph的逻辑分层
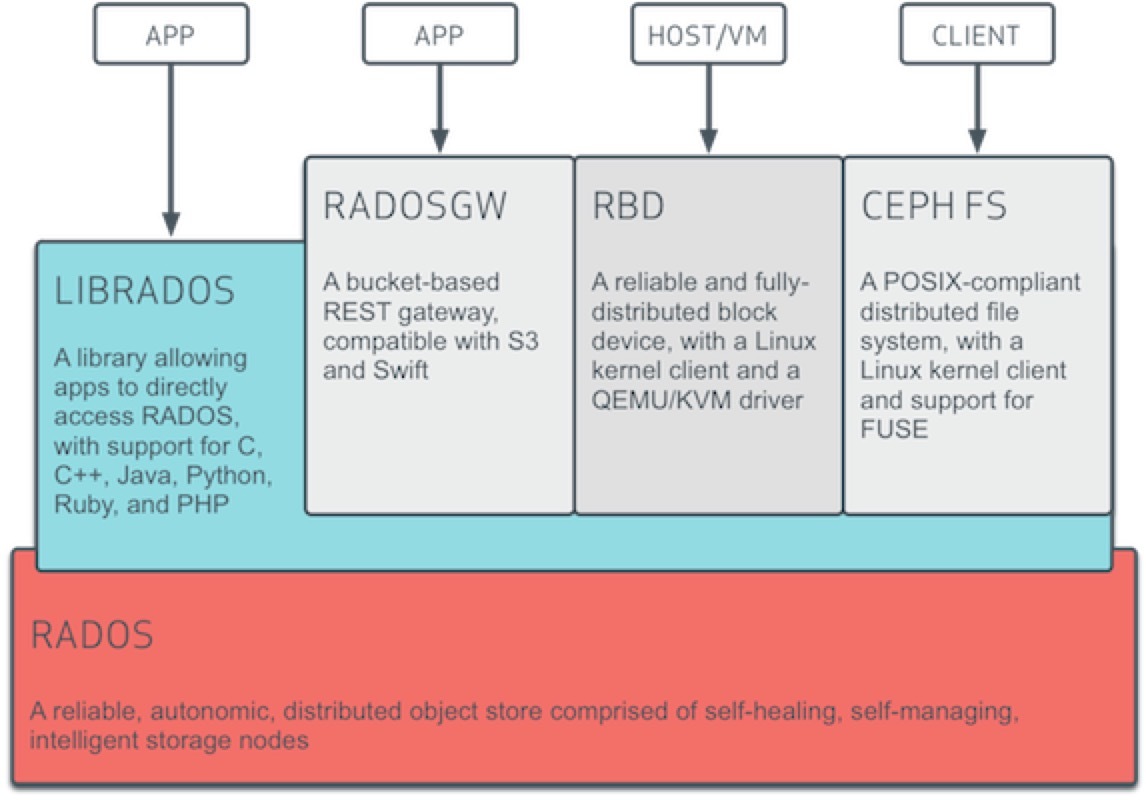
Ceph 官方给的逻辑架构如下图
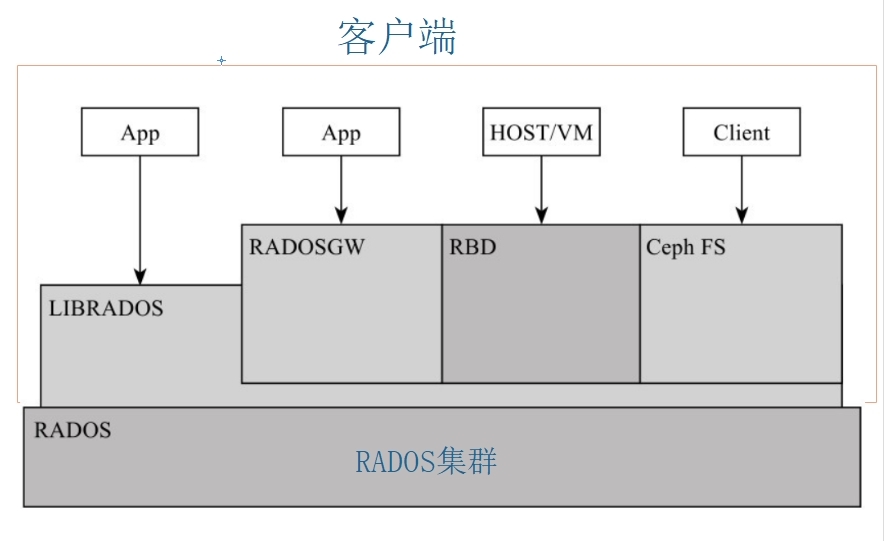
可以总结为两部分,一个集群、一个客户端。 集群就是底层的RADOS集群。客户端就是在RADOS集群之上,利用librados 编程接口的进一步抽象。其本质都是RADOS集群的客户端。
3.1、客户端
如果说RADOS集群是一个具备自我修复等特性,提供了一个可靠、自动、智能的分布式存储,那用户怎么使用他了?因此RADOS提供了供librados库,允许应用程序直接访问,支持C/C++、Java和Python等语言。那是否有一个librados库就可以被用户直接访问到了,理论上只需要调用其库就可以使用DADOS集群。但是又有多少人有能力直接用编程能力去访问RADOS集群了。
因此在librados库基础上做了进一步的封装,针对主流的块存储使用提供了 RBD,针对文件存储使用提供Ceph FS ,基于当前流行的RESTful协议的网关,并且兼容S3和Swift,提供了radosgw 。因为无论是librados、rdb radosgw Ceph fs 都是RADOS的客户端。
3.2 、RADOS集群
一个最小化的RADOS集群只有三个组件 MON 和MGR 和 OSD ,其系统架构如下
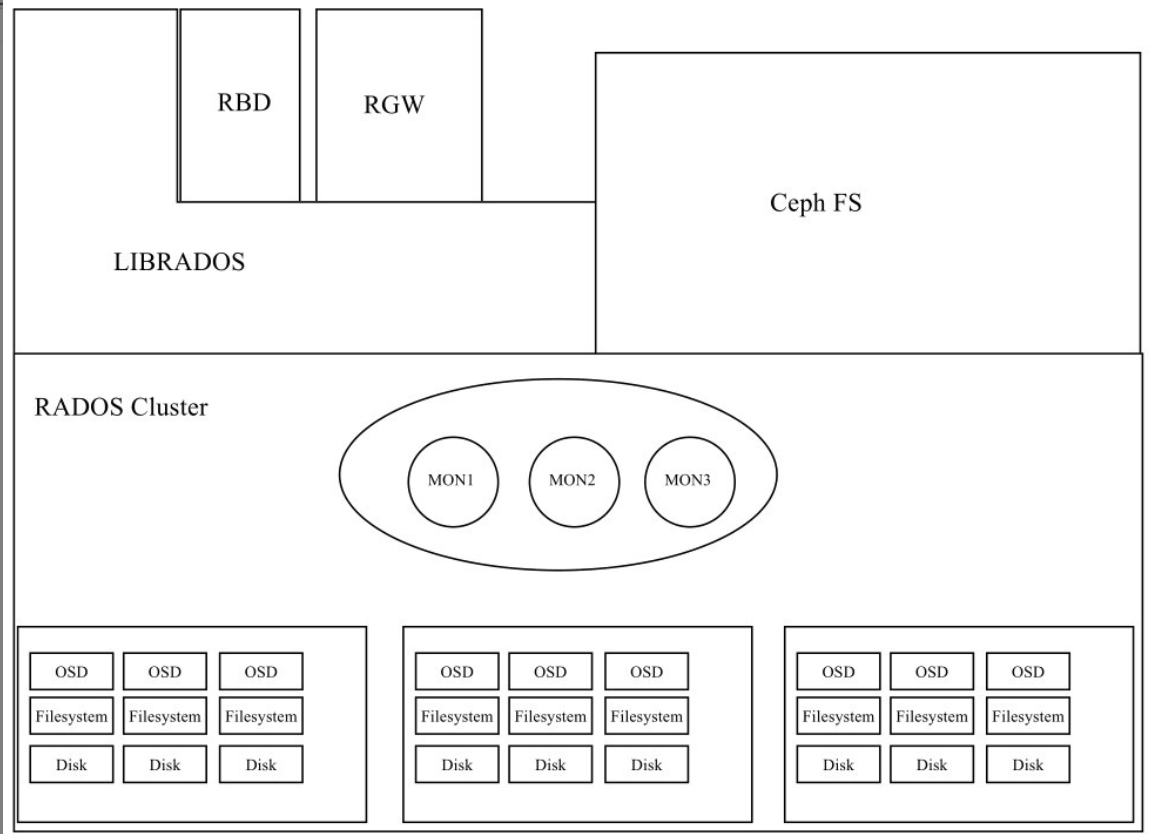
看到这可能有小伙伴会说 不对把,不是应该还有mds吗?先说mds,其主要功能就给文件存储提供元数据索引的,如果我们Ceph集群不需要文件存储,就不需要mds组件了。
3.3 RADOS集群组件

-
mon: Ceph Monitor是负责监视整个群集的运行状况的,这些信息都是由维护集群成员的守护程序来提供的,如各个节点之间的状态、集群配置信息。Ceph monitor map包括OSD Map、PG Map、MDS Map和CRUSH等,这些Map被统称为集群Map。这五张map可以说代表了mon的大部分功能。
-
MGR:Ceph ManagerMGR 承载了许多辅助功能,如监控、报告和资源分配。现在,Ceph Manager Daemon 更多地实现了监视、管理及一些自动化任务,包括维护集群元数据、系统故障检测等。它可以实现跨多个 Ceph 组件的自动容灾和调度,提高整个系统的稳定性和可靠性。
-
OSD: OSD是Ceph的对象存储守护进程。它负责存储数据,处理数据复制、恢复、重新平衡,并通过检查其他守护进程是否有故障来向Ceph Monitor提供一些监控信息。每个存储服务器(存储节点)运行一个或多个OSD守护进程,通常每个磁盘存储设备对应一个OSD守护进程
总结: 一个集群需要被访问,总需是先需要一个认证功能,认证之后将用户的请求调度到后端真正的服务,这个过程就是mon的功能,因为其是分布式的存储,其靠Paxos算法来保证数据一致性。为了集群的稳定,mon维护了集群的map。 mgr则更多是提供监控和辅助功能来减轻mon的负担,osd则是数据真正的存放位置。
在上文中我们说过Ceph集群是无中心节点的分布式存储,那其是怎么做到了?
一切的一切都是靠计算,简单的说就是真正的数据存储在那个osd上,其是靠计算出来,而非查询元数据节点查询出来的。这个计算的过程就是CRUSH算法。关于CRUSH算法我们将在后面章节来讨论,这里我们了解Ceph集群的结构,下一章我们将手动部署一套最小化的Ceph集群来体验下Ceph存储的使用。
文章转载自:ALEX_li88
原文链接:https://www.cnblogs.com/alex0815/p/17850402.html