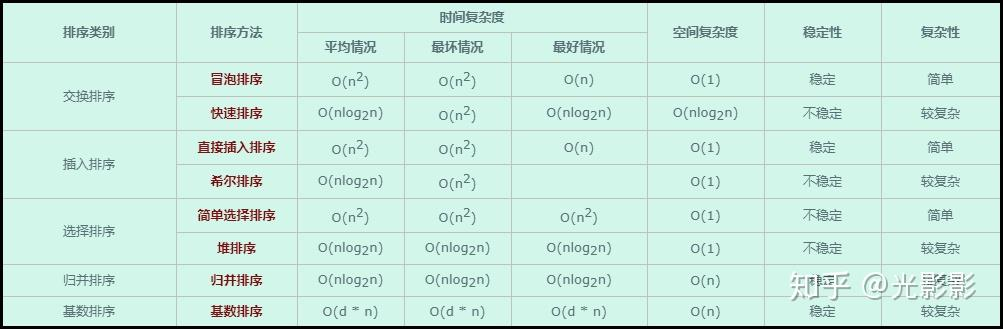
文章目录
- 特征检测的基本概念
- Harris角点检测
- Shi-Tomasi角点检测
- SIFT关键点检测
- SIFT计算描述子
- SURF特征检测
- OBR特征检测
- 暴力特征匹配
- FLANN特征匹配
- 实战flann特征匹配
- 图像查找
- 图像拼接基础知识
- 图像拼接实战
特征点检测与匹配是计算机视觉中非常重要的内容。不是所有图像操作都是对每个像素进行处理,有些只需使用4个顶点即可,如图像的拼接、二维码定位等
特征检测的基本概念







Harris角点检测



详情见官方参考文档

# -*- coding: utf-8 -*-
import cv2
import numpy as np
blockSize = 2
ksize = 3
k = 0.04
img = cv2.imread('./chess.png')
# 灰度化
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Harris角点检测
dst = cv2.cornerHarris(gray, blockSize, ksize, k)
# Harris角点展示
img[dst > 0.01 * dst.max()] = [0, 255, 0]
cv2.imshow('harris', img)
if cv2.waitKey(0) & 0xff == 27:
cv2.destroyAllWindows()

Shi-Tomasi角点检测



距离越大检测到的角数越少,距离越小检测到的角数越多
# -*- coding: utf-8 -*-
import cv2
import numpy as np
# Harris
# blockSize = 2
# ksize = 3
# k = 0.04
# Shi-Tomasi
maxCorners = 1000
ql = 0.01
minDistance = 10
img = cv2.imread('./chess.png')
# 灰度化
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Harris角点检测
# dst = cv2.cornerHarris(gray, blockSize, ksize, k)
# Harris角点展示
# img[dst > 0.01 * dst.max()] = [0, 255, 0]
corners = cv2.goodFeaturesToTrack(gray, maxCorners, ql, minDistance)
corners = np.int0(corners)
for i in corners:
x, y = i.ravel()
cv2.circle(img, (x, y), 3, (0, 255, 0), -1)
cv2.imshow('Tomasi', img)
if cv2.waitKey(0) & 0xff == 27:
cv2.destroyAllWindows()

SIFT关键点检测
详情见官方文档




The distinguishing qualities of an image that make it stand out are referred to as key points in an image. The key points of a particular image let us recognize objects and compare images. Detecting critical spots in a picture may be done using a variety of techniques and algorithms. We utilize the drawKeypoints() method in OpenCV to be able to draw the identified key points on a given picture. The input picture, keypoints, color, and flag are sent to the drawKeypoints() method. key points are the most important aspects of the detection. Even after the image is modified the key points remain the same. As of now, we can only use the SIRF_create() function as the surf function is patented.

# -*- coding: utf-8 -*-
import cv2
import numpy as np
img = cv2.imread('./chess.png')
# 灰度化
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 创建SIFT对象
sift = cv2.xfeatures2d.SIFT_create()
# 进行检测
kp = sift.detect(gray, None)
# 绘制keypoints
cv2.drawKeypoints(gray, kp, img)
cv2.imshow('img', img)
if cv2.waitKey(0) & 0xff == 27:
cv2.destroyAllWindows()

-
sift = cv2.xfeatures2d.SIFT_create() 实例化
参数说明:sift为实例化的sift函数 -
kp = sift.detect(gray, None) 找出图像中的关键点
参数说明: kp表示生成的关键点,gray表示输入的灰度图, -
ret = cv2.drawKeypoints(gray, kp, img) 在图中画出关键点
参数说明:gray表示输入图片, kp表示关键点,img表示输出的图片 -
kp, dst = sift.compute(kp) 计算关键点对应的sift特征向量
参数说明:kp表示输入的关键点,dst表示输出的sift特征向量,通常是128维的
SIFT计算描述子



# -*- coding: utf-8 -*-
import cv2
import numpy as np
img = cv2.imread('./chess.png')
# 灰度化
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 创建SIFT对象
sift = cv2.xfeatures2d.SIFT_create()
# 进行检测
kp, des = sift.detectAndCompute(gray, None)
print(des)
# 绘制keypoints
cv2.drawKeypoints(gray, kp, img)
cv2.imshow('img', img)
if cv2.waitKey(0) & 0xff == 27:
cv2.destroyAllWindows()


SURF特征检测


# -*- coding: utf-8 -*-
import cv2
import numpy as np
img = cv2.imread('./chess.png')
# 灰度化
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 创建SIFT对象
# sift = cv2.xfeatures2d.SIFT_create()
# 创建SURF对象
surf = cv2.xfeatures2d.SURF.create()
# 进行检测
# kp, des = sift.detectAndCompute(gray, None)
kp, des = surf.detectAndCompute(gray, None)
# print(des[0])
# 绘制keypoints
cv2.drawKeypoints(gray, kp, img)
cv2.imshow('img', img)
if cv2.waitKey(0) & 0xff == 27:
cv2.destroyAllWindows()

好消息,SURF付费了,不是开源的接口了,需要大家自己造轮子,写新的好算法!
OBR特征检测




# -*- coding: utf-8 -*-
import cv2
import numpy as np
img = cv2.imread('./chess.png')
# 灰度化
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 创建SIFT对象
# sift = cv2.xfeatures2d.SIFT_create()
# 创建SURF对象
# surf = cv2.xfeatures2d.SURF.create()
# 创建ORB对象
orb = cv2.ORB_create()
# 进行检测
# kp, des = sift.detectAndCompute(gray, None)
# kp, des = surf.detectAndCompute(gray, None)
kp, des = orb.detectAndCompute(gray, None)
# print(des[0])
# 绘制keypoints
cv2.drawKeypoints(gray, kp, img)
cv2.imshow('img', img)
if cv2.waitKey(0) & 0xff == 27:
cv2.destroyAllWindows()

暴力特征匹配







# -*- coding: utf-8 -*-
import cv2
import numpy as np
# img = cv2.imread('./chess.png')
img1 = cv2.imread('./opencv_search.png')
img2 = cv2.imread('./opencv_orig.png')
# 灰度化
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# create SIFT feature extractor
# 创建SIFT对象
sift = cv2.xfeatures2d.SIFT_create()
# 创建SURF对象
# surf = cv2.xfeatures2d.SURF.create()
# 创建ORB对象
orb = cv2.ORB_create()
# detect features from the image
# 进行检测
# kp, des = sift.detectAndCompute(gray, None)
# kp, des = surf.detectAndCompute(gray, None)
# kp, des = orb.detectAndCompute(gray, None)
# draw the detected key points
kp1, des1 = sift.detectAndCompute(gray1, None)
kp2, des2 = sift.detectAndCompute(gray2, None)
# print(des[0])
# 绘制keypoints
# cv2.drawKeypoints(gray, kp, img)
# 创建匹配器
bf = cv2.BFMatcher(cv2.NORM_L1)
match = bf.match(des1, des2)
img3 = cv2.drawMatches(img1, kp1, img2, kp2, match, None)
cv2.imshow('img', img3)
if cv2.waitKey(0) & 0xff == 27:
cv2.destroyAllWindows()

FLANN特征匹配








实战flann特征匹配
参考的官网手册
# -*- coding: utf-8 -*-
import cv2
import numpy as np
# queryImage
img1 = cv2.imread('./opencv_search.png')
# trainImage
img2 = cv2.imread('./opencv_orig.png')
# 灰度化
g1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
g2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# 创建SIFT特征检测器
# Initiate SIFT detector
sift = cv2.xfeatures2d.SIFT_create()
# 计算描述子与特征点
# find the keypoints and descriptors with SIFT
kp1, des1 = sift.detectAndCompute(g1, None)
kp2, des2 = sift.detectAndCompute(g2, None)
# 创建匹配器
# FLANN parameters
index_params = dict(algorithm = 1, trees = 5)
search_params = dict(checks = 50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
# 对描述子进行匹配计算
matchs = flann.knnMatch(des1, des2, k = 2)
good = []
# ratio test as per Lowe's paper
for i, (m, n) in enumerate(matchs):
if m.distance < 0.7 * n.distance:
good.append(m)
ret = cv2.drawMatchesKnn(img1, kp1, img2, kp2, [good], None)
cv2.imshow('res', ret)
if cv2.waitKey(0) & 0xff == 27:
cv2.destroyAllWindows()

图像查找





# -*- coding: utf-8 -*-
import cv2
import numpy as np
img1 = cv2.imread('./opencv_search.png')
img2 = cv2.imread('./opencv_orig.png')
MIN_MATCH_COUNT = 4
# 灰度化
g1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
g2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# 创建SIFT特征检测器
sift = cv2.xfeatures2d.SIFT_create()
# 计算描述子与特征点
kp1, des1 = sift.detectAndCompute(g1, None)
kp2, des2 = sift.detectAndCompute(g2, None)
# 创建匹配器
index_params = dict(algorithm = 1, trees = 5)
search_params = dict(checks = 50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
# 对描述子进行匹配计算
matchs = flann.knnMatch(des1, des2, k = 2)
good = []
for i, (m, n) in enumerate(matchs):
if m.distance < 0.7 * n.distance:
good.append(m)
if len(good) >= MIN_MATCH_COUNT:
src_pts = np.float32([ kp1[m.queryIdx].pt for m in good ]).reshape(-1,1,2)
dst_pts = np.float32([ kp2[m.trainIdx].pt for m in good ]).reshape(-1,1,2)
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0)
h,w = img1.shape[:2]
pts = np.float32([ [0, 0], [0, h-1], [w-1, h-1], [w-1, 0]]).reshape(-1,1,2)
dst = cv2.perspectiveTransform(pts, M)
cv2.polylines(img2, [np.int32(dst)], True, (0, 255, 0))
else:
print('the number of good is less than 4.')
exit()
ret = cv2.drawMatchesKnn(img1, kp1, img2, kp2, [good], None)
cv2.imshow('res', ret)
if cv2.waitKey(0) & 0xff == 27:
cv2.destroyAllWindows()

图像拼接基础知识



(0,0)是第二张图的左上角





图像拼接实战
# -*- coding: utf-8 -*-
import cv2
import numpy as np
#第一步,读取文件,将图片设置成一样大小640x480
#第二步,找特征点,描述子,计算单应性矩阵
#第三步,根据单应性矩阵对图像进行变换,然后平移
#第四步,拼接并输出最终结果
img1 = cv2.imread('map1.png')
img2 = cv2.imread('map2.png')
img1 = cv2.resize(img1, (640, 480))
img2 = cv2.resize(img2, (640, 480))
inputs = np.hstack((img1, img2))
cv2.imshow('input_img', inputs)
if cv2.waitKey(0) & 0xff == 27:
cv2.destroyAllWindows()

# -*- coding: utf-8 -*-
import cv2
import numpy as np
#第一步,读取文件,将图片设置成一样大小640x480
#第二步,找特征点,描述子,计算单应性矩阵
#第三步,根据单应性矩阵对图像进行变换,然后平移
#第四步,拼接并输出最终结果
MIN_MATCH_COUNT = 8
def stitch_image(img1, img2, H):
# 1. 获得每张图片的四个角点
# 2. 对图片进行变换(单应性矩阵使图进行旋转,平移)
# 3. 创建一张大图,将两张图拼接到一起
# 4. 将结果输出
#获得原始图的高/宽
h1, w1 = img1.shape[:2]
h2, w2 = img2.shape[:2]
img1_dims = np.float32([[0,0], [0, h1], [w1, h1], [w1, 0]]).reshape(-1, 1, 2)
img2_dims = np.float32([[0,0], [0, h2], [w2, h2], [w2, 0]]).reshape(-1, 1, 2)
img1_transform = cv2.perspectiveTransform(img1_dims, H)
print(img1_dims)
print(img2_dims)
print(img1_transform)
def get_homo(img1, img2):
#1. 创建特征转换对象
#2. 通过特征转换对象获得特征点和描述子
#3. 创建特征匹配器
#4. 进行特征匹配
#5. 过滤特征,找出有效的特征匹配点
# 创建SIFT特征检测器
sift = cv2.xfeatures2d.SIFT_create()
# 计算描述子与特征点
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# 创建特征匹配器
bf = cv2.BFMatcher()
# 对描述子进行匹配计算
matchs = bf.knnMatch(des1, des2, k = 2)
verify_matches = []
for i, (m, n) in enumerate(matchs):
if m.distance < 0.8 * n.distance:
verify_matches.append(m)
if len(verify_matches) > MIN_MATCH_COUNT:
img1_pts = []
img2_pts = []
for m in verify_matches:
img1_pts.append(kp1[m.queryIdx].pt)
img2_pts.append(kp2[m.trainIdx].pt)
#[(x1, y1), (x2, y2), ...]
#[[x1, y1], [x2, y2], ...]
img1_pts = np.float32(img1_pts).reshape(-1, 1, 2)
img2_pts = np.float32(img2_pts).reshape(-1, 1, 2)
# 获取单应性矩阵
H, mask = cv2.findHomography(img1_pts, img2_pts, cv2.RANSAC, 5.0)
return H
else:
print('err: Not enough matches!')
exit()
img1 = cv2.imread('map1.png')
img2 = cv2.imread('map2.png')
img1 = cv2.resize(img1, (640, 480))
img2 = cv2.resize(img2, (640, 480))
inputs = np.hstack((img1, img2))
#获得单应性矩阵
H = get_homo(img1, img2)
#进行图像拼接
result_image = stitch_image(img1, img2, H)
cv2.imshow('input_img', inputs)
if cv2.waitKey(0) & 0xff == 27:
cv2.destroyAllWindows()


# -*- coding: utf-8 -*-
import cv2
import numpy as np
#第一步,读取文件,将图片设置成一样大小640x480
#第二步,找特征点,描述子,计算单应性矩阵
#第三步,根据单应性矩阵对图像进行变换,然后平移
#第四步,拼接并输出最终结果
MIN_MATCH_COUNT = 8
def stitch_image(img1, img2, H):
# 1. 获得每张图片的四个角点
# 2. 对图片进行变换(单应性矩阵使图进行旋转,平移)
# 3. 创建一张大图,将两张图拼接到一起
# 4. 将结果输出
#获得原始图的高/宽
h1, w1 = img1.shape[:2]
h2, w2 = img2.shape[:2]
img1_dims = np.float32([[0,0], [0, h1], [w1, h1], [w1, 0]]).reshape(-1, 1, 2)
img2_dims = np.float32([[0,0], [0, h2], [w2, h2], [w2, 0]]).reshape(-1, 1, 2)
img1_transform = cv2.perspectiveTransform(img1_dims, H)
# print(img1_dims)
# print(img2_dims)
# print(img1_transform)
result_dims = np.concatenate((img2_dims, img1_transform), axis=0)
# print(result_dims)
[x_min, y_min] = np.int32(result_dims.min(axis=0).ravel()-0.5)
[x_max, y_max ] = np.int32(result_dims.max(axis=0).ravel()+0.5)
#平移的距离
transform_dist = [-x_min, -y_min]
result_img = cv2.warpPerspective(img1, H, (x_max-x_min, y_max-y_min))
return result_img
def get_homo(img1, img2):
#1. 创建特征转换对象
#2. 通过特征转换对象获得特征点和描述子
#3. 创建特征匹配器
#4. 进行特征匹配
#5. 过滤特征,找出有效的特征匹配点
# 创建SIFT特征检测器
sift = cv2.xfeatures2d.SIFT_create()
# 计算描述子与特征点
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# 创建特征匹配器
bf = cv2.BFMatcher()
# 对描述子进行匹配计算
matchs = bf.knnMatch(des1, des2, k = 2)
verify_matches = []
for i, (m, n) in enumerate(matchs):
if m.distance < 0.8 * n.distance:
verify_matches.append(m)
if len(verify_matches) > MIN_MATCH_COUNT:
img1_pts = []
img2_pts = []
for m in verify_matches:
img1_pts.append(kp1[m.queryIdx].pt)
img2_pts.append(kp2[m.trainIdx].pt)
#[(x1, y1), (x2, y2), ...]
#[[x1, y1], [x2, y2], ...]
img1_pts = np.float32(img1_pts).reshape(-1, 1, 2)
img2_pts = np.float32(img2_pts).reshape(-1, 1, 2)
# 获取单应性矩阵
H, mask = cv2.findHomography(img1_pts, img2_pts, cv2.RANSAC, 5.0)
return H
else:
print('err: Not enough matches!')
exit()
img1 = cv2.imread('map1.png')
img2 = cv2.imread('map2.png')
img1 = cv2.resize(img1, (640, 480))
img2 = cv2.resize(img2, (640, 480))
inputs = np.hstack((img1, img2))
#获得单应性矩阵
H = get_homo(img1, img2)
#进行图像拼接
result_image = stitch_image(img1, img2, H)
cv2.imshow('input_img', result_image)
if cv2.waitKey(0) & 0xff == 27:
cv2.destroyAllWindows()

# -*- coding: utf-8 -*-
import cv2
import numpy as np
#第一步,读取文件,将图片设置成一样大小640x480
#第二步,找特征点,描述子,计算单应性矩阵
#第三步,根据单应性矩阵对图像进行变换,然后平移
#第四步,拼接并输出最终结果
MIN_MATCH_COUNT = 8
def stitch_image(img1, img2, H):
# 1. 获得每张图片的四个角点
# 2. 对图片进行变换(单应性矩阵使图进行旋转,平移)
# 3. 创建一张大图,将两张图拼接到一起
# 4. 将结果输出
#获得原始图的高/宽
h1, w1 = img1.shape[:2]
h2, w2 = img2.shape[:2]
img1_dims = np.float32([[0,0], [0, h1], [w1, h1], [w1, 0]]).reshape(-1, 1, 2)
img2_dims = np.float32([[0,0], [0, h2], [w2, h2], [w2, 0]]).reshape(-1, 1, 2)
img1_transform = cv2.perspectiveTransform(img1_dims, H)
# print(img1_dims)
# print(img2_dims)
# print(img1_transform)
result_dims = np.concatenate((img2_dims, img1_transform), axis=0)
# print(result_dims)
[x_min, y_min] = np.int32(result_dims.min(axis=0).ravel()-0.5)
[x_max, y_max ] = np.int32(result_dims.max(axis=0).ravel()+0.5)
#平移的距离
transform_dist = [-x_min, -y_min]
#[1, 0, dx]
#[0, 1, dy]
#[0, 0, 1 ]
transform_array = np.array([[1, 0, transform_dist[0]],
[0, 1, transform_dist[1]],
[0, 0, 1]])
result_img = cv2.warpPerspective(img1, transform_array.dot(H), (x_max-x_min, y_max-y_min))
return result_img
def get_homo(img1, img2):
#1. 创建特征转换对象
#2. 通过特征转换对象获得特征点和描述子
#3. 创建特征匹配器
#4. 进行特征匹配
#5. 过滤特征,找出有效的特征匹配点
# 创建SIFT特征检测器
sift = cv2.xfeatures2d.SIFT_create()
# 计算描述子与特征点
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# 创建特征匹配器
bf = cv2.BFMatcher()
# 对描述子进行匹配计算
matchs = bf.knnMatch(des1, des2, k = 2)
verify_matches = []
for i, (m, n) in enumerate(matchs):
if m.distance < 0.8 * n.distance:
verify_matches.append(m)
if len(verify_matches) > MIN_MATCH_COUNT:
img1_pts = []
img2_pts = []
for m in verify_matches:
img1_pts.append(kp1[m.queryIdx].pt)
img2_pts.append(kp2[m.trainIdx].pt)
#[(x1, y1), (x2, y2), ...]
#[[x1, y1], [x2, y2], ...]
img1_pts = np.float32(img1_pts).reshape(-1, 1, 2)
img2_pts = np.float32(img2_pts).reshape(-1, 1, 2)
# 获取单应性矩阵
H, mask = cv2.findHomography(img1_pts, img2_pts, cv2.RANSAC, 5.0)
return H
else:
print('err: Not enough matches!')
exit()
img1 = cv2.imread('map1.png')
img2 = cv2.imread('map2.png')
img1 = cv2.resize(img1, (640, 480))
img2 = cv2.resize(img2, (640, 480))
inputs = np.hstack((img1, img2))
#获得单应性矩阵
H = get_homo(img1, img2)
#进行图像拼接
result_image = stitch_image(img1, img2, H)
cv2.imshow('input_img', result_image)
if cv2.waitKey(0) & 0xff == 27:
cv2.destroyAllWindows()

# -*- coding: utf-8 -*-
import cv2
import numpy as np
#第一步,读取文件,将图片设置成一样大小640x480
#第二步,找特征点,描述子,计算单应性矩阵
#第三步,根据单应性矩阵对图像进行变换,然后平移
#第四步,拼接并输出最终结果
MIN_MATCH_COUNT = 8
def stitch_image(img1, img2, H):
# 1. 获得每张图片的四个角点
# 2. 对图片进行变换(单应性矩阵使图进行旋转,平移)
# 3. 创建一张大图,将两张图拼接到一起
# 4. 将结果输出
#获得原始图的高/宽
h1, w1 = img1.shape[:2]
h2, w2 = img2.shape[:2]
img1_dims = np.float32([[0,0], [0, h1], [w1, h1], [w1, 0]]).reshape(-1, 1, 2)
img2_dims = np.float32([[0,0], [0, h2], [w2, h2], [w2, 0]]).reshape(-1, 1, 2)
img1_transform = cv2.perspectiveTransform(img1_dims, H)
# print(img1_dims)
# print(img2_dims)
# print(img1_transform)
result_dims = np.concatenate((img2_dims, img1_transform), axis=0)
# print(result_dims)
[x_min, y_min] = np.int32(result_dims.min(axis=0).ravel()-0.5)
[x_max, y_max ] = np.int32(result_dims.max(axis=0).ravel()+0.5)
#平移的距离
transform_dist = [-x_min, -y_min]
# 齐次坐标
#[1, 0, dx]
#[0, 1, dy]
#[0, 0, 1 ]
transform_array = np.array([[1, 0, transform_dist[0]],
[0, 1, transform_dist[1]],
[0, 0, 1]])
result_img = cv2.warpPerspective(img1, transform_array.dot(H), (x_max-x_min, y_max-y_min))
result_img[transform_dist[1]:transform_dist[1]+h2,
transform_dist[0]:transform_dist[0]+w2] = img2
return result_img
def get_homo(img1, img2):
#1. 创建特征转换对象
#2. 通过特征转换对象获得特征点和描述子
#3. 创建特征匹配器
#4. 进行特征匹配
#5. 过滤特征,找出有效的特征匹配点
# 创建SIFT特征检测器
sift = cv2.xfeatures2d.SIFT_create()
# 计算描述子与特征点
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# 创建特征匹配器
bf = cv2.BFMatcher()
# 对描述子进行匹配计算
matchs = bf.knnMatch(des1, des2, k = 2)
verify_matches = []
for i, (m, n) in enumerate(matchs):
if m.distance < 0.8 * n.distance:
verify_matches.append(m)
if len(verify_matches) > MIN_MATCH_COUNT:
img1_pts = []
img2_pts = []
for m in verify_matches:
img1_pts.append(kp1[m.queryIdx].pt)
img2_pts.append(kp2[m.trainIdx].pt)
#[(x1, y1), (x2, y2), ...]
#[[x1, y1], [x2, y2], ...]
img1_pts = np.float32(img1_pts).reshape(-1, 1, 2)
img2_pts = np.float32(img2_pts).reshape(-1, 1, 2)
# 获取单应性矩阵
H, mask = cv2.findHomography(img1_pts, img2_pts, cv2.RANSAC, 5.0)
return H
else:
print('err: Not enough matches!')
exit()
img1 = cv2.imread('map1.png')
img2 = cv2.imread('map2.png')
img1 = cv2.resize(img1, (640, 480))
img2 = cv2.resize(img2, (640, 480))
inputs = np.hstack((img1, img2))
#获得单应性矩阵
H = get_homo(img1, img2)
#进行图像拼接
result_image = stitch_image(img1, img2, H)
cv2.imshow('input_img', result_image)
if cv2.waitKey(0) & 0xff == 27:
cv2.destroyAllWindows()

之后我会持续更新,如果喜欢我的文章,请记得一键三连哦,点赞关注收藏,你的每一个赞每一份关注每一次收藏都将是我前进路上的无限动力 !!!↖(▔▽▔)↗感谢支持!






![【Sorted Set】Redis常用数据类型: ZSet [使用手册]](https://img-blog.csdnimg.cn/20a7f1b58dfb4660b75d7f021c157d57.png#pic_center)