作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
上篇提到泛型可以看做是对变量类型的抽取,它把原本必须确定的变量类型(比如String/Person)也弄成了变量(E),最终得到代码模板。
但是,敏感的读者马上就会发现这tm是个悖论啊:对象类型不确定,JVM怎么创建对象啊!
要回答这个问题,我们必须了解Java的两个阶段:编译期、运行期。你可以理解为Java代码运行有4个要素:
- 源代码
- 编译器
- 字节码
- 虚拟机
也就是说,Java有两台很重要的机器,编译器和虚拟机。
在代码编写阶段,我们确实引入了泛型对变量类型进行泛化抽取,让类型是不特定的(不特定的即通用的),从而创造了通用的代码模板,比如ArrayList<T>:
public class ArrayList<T> {
private T[] array;
private int size;
public void add(T e) {...}
public void remove(int index) {...}
public T get(int index) {...}
}模板定好后,如果我们希望这个ArrayList只处理String类型,就传入类型参数,把T“赋值为”String,比如ArrayList<String>,此时你可以理解为代码变成了这样:
public class ArrayList<String> {
private String[] array;
private int size;
public void add(String e) {...}
public void remove(int index) {...}
public String get(int index) {...}
}所以add(1)会编译报错。
但事实真的如此吗?
我们必须去了解泛型的底层机制。
泛型擦除与自动类型转换
我们来研究以下代码:
public class GenericDemo {
public static void main(String[] args) {
UserDao userDao = new UserDao();
User user = userDao.get(new User());
List<User> list = userDao.getList(new User());
}
}
class BaseDao<T> {
public T get(T t){
return t;
}
public List<T> getList(T t){
return new ArrayList<>();
}
}
class UserDao extends BaseDao<User> {
}
class User{
}编译得到字节码:
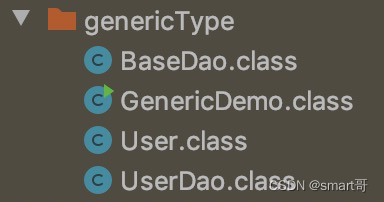
通过反编译工具,反编译字节码得到:
public class GenericDemo {
// 编译器会为我们自动加上无参构造器
public GenericDemo() {}
public static void main(String args[]) {
UserDao userDao = new UserDao();
/**
* 1.原先代码是 User user = userDao.get(new User());
* 编译器加上了(User),做了类型强转
*/
User user = (User)userDao.get(new User());
/**
* 2.List<User>的泛型被擦除了,只剩下List
*/
java.util.List list = userDao.getList(new User());
}
}
class BaseDao {
BaseDao() {}
// 编译器编译后的字节码中,其实是没有泛型的,泛型T底层其实是Object
public Object get(Object t) {
return t;
}
public List getList(Object t) {
return new ArrayList();
}
}
// BaseDao<User>泛型也没了
class UserDao extends BaseDao {
UserDao(){}
}
class User {
User() {}
}反编译后我们很容易发现,其实所谓的泛型T在编译后就会消失,底层其实还是Object。既然泛型底层用Object接收,那么:
- 对于ArrayList<String>,为什么add(Integer i)会编译报错?
- 对于ArrayList<String>,list.get(0)为什么不需要强制转型?
因为泛型本身是一种编译时的机制,是Java程序员和编译器之间的协议。
ArrayList<T>是已经编写好的代码模板,底层还是Object[]接收元素,但我们可以通过ArrayList<String>的语法形式,告诉编译器:“我希望你把这个ArrayList看做StringArrayList”。
换句话说,编译器会根据我们指定的实际类型参数(ArrayList<String>中的String),自动地在编译器做好语法约束:
- ArrayList<String>的add(E e)只能传String类型
- ArrayList<String>的get(i)返回值一定是String(编译后自动强转,无需我们操心)
基于上面的实验,我们可以得到以下4个结论:
- 泛型是JDK专门为编译器创造的语法糖,只在编译期,由编译器负责解析,虚拟机不知情
- 存入:普通类继承泛型类并给变量类型T赋值后,就能强制让编译器帮忙进行类型校验

- 取出:代码编译时,编译器底层会根据实际类型参数自动进行类型转换,无需程序员在外部手动强转

- 实际上,编译后的Class文件还是JDK1.5以前的样子,虚拟机看到的仍然是Object
举个例子:
- 某小区有两个垃圾桶,原本两个桶无差别的,干湿垃圾可以随便放
- 后来进行垃圾分类了,居委会主任规定:1号桶放干垃圾,2号桶放湿垃圾。但总有人会记错,把湿垃圾放入1号桶,导致垃圾工人收垃圾时被溅了一身
- 后来主任搞了一台湿度检测仪,丢进去之前检测一下垃圾湿度,不符合的就不让放进去
- 本质上1、2号垃圾桶的内部结构没有任何变化,我们只是被湿度检测仪拦截了
垃圾桶本身并没有发生什么改变,只是引入了外部的力量,这个力量能够对一些行为进行约束。换言之,Java在编译期引入了泛型检测机制,对容器的使用进行了强制约束,但容器本身并没有发生实质性的改变。
有兴趣的同学可以在本地执行下面的案例,体会一下如何利用反射绕过编译器对泛型的检查:
public class GenericClassDemo {
public static void main(String[] args) throws Exception {
List<String> list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
// 编译器会阻止
// list.add(333);
// 但泛型约束只存在于编译期,底层仍是Object,所以运行期可以往List存入任何类型的元素
Method addMethod = list.getClass().getDeclaredMethod("add", Object.class);
addMethod.invoke(list, 333);
// 打印输出观察是否成功存入Integer(注意用Object接收)
for (Object obj : list) {
System.out.println(obj);
}
}
}泛型与多态
经过上面的介绍,大家开始慢慢觉得泛型只和编译器有关,但实际上泛型的成功离不开多态。
上一篇我们已经解释了为什么需要代码模板(通用),现在我们来聊聊为什么能实现代码模板。
代码模板的定义是,整个类框架都搭建好了,只是不确定操作什么类型的对象(变量)。但它必须做到:无论你传什么类型,模板都能接收。
泛型固然强悍,既能约束入参,又能对返回值进行自动转换。但大家有没有想过,对于编译器的“智能转换”,其实是需要多态支持的。如果Java本身不支持多态,那么即使语法层面做的再好,无法利用多态接收和强转都是白搭。
所以代码模板的本质就是:用Object接收一切对象,用泛型+编译器限定特定对象,用多态支持类型强转。
大家拷贝下方代码本地运行一下:
/**
* @author mx
* @date 2023-11-21 23:02
*/
public class ObjectArray {
public static void main(String[] args) {
// objects其实就是对应ArrayList内部的Object[]
Object[] objects = new Object[4];
// 引入泛型后的两个作用:
// 1.入参约束:如果是ArrayList,那么入参约束会在一开始就确定,而下面的objects就惨多了,Integer/String都可以随意出入
objects[0] = 1;
objects[1] = 2;
objects[2] = "3";
objects[3] = "4";
// 2.自动类型转换:如果是ArrayList,由于入参已经被约束,那么返回值类型也随之确定,编译器会帮我们自动转换,无需显式地手动强转
Integer zero = (Integer) objects[0];
Integer one = (Integer) objects[1];
String two = (String) objects[2];
String three = (String) objects[3];
System.out.println(zero + " " + one + " " + two + " " + three);
}
}上面的代码是对泛型底层运作的模拟。
当泛型完成了“编译时检查”和“编译时自动类型转换”的作用后,底层还是要多态来支持。
你可以理解为泛型有以下作用:
抽取代码模板:代码复用并且可以通过指定类型参数与编译器达成约定
类型校验:编译时阻止不匹配元素进入Object[]
类型强转:根据泛型自动强转(多态,向下转型)
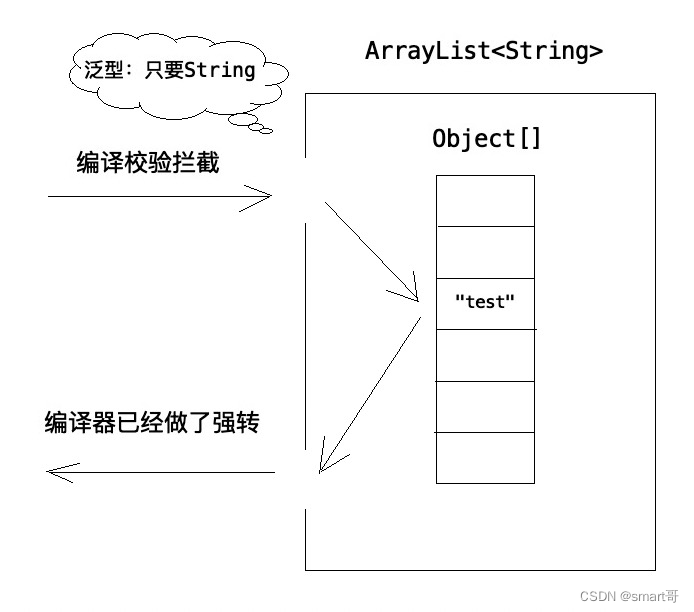
但实际运行时,Object[]接收特定类型的元素,体现了多态,取出Object[]元素并强转,也体现了多态。
在编程界有一句话:如果一段代码注定要报错,那么应该尽量提前到编译期,而且编译器自动转型比手动转型安全得多。
所以,泛型只是程序员和编译器的约定,程序员告诉编译器,我假定这个List只能存String,你帮我盯着点。对于存入的方法,如果不小心放错类型,就编译报错提醒我。对于取出的方法,编译时你根据我给的实际类型参数自动帮我类型转换吧~
泛型:一切其实都是确定的
对于初学者来说,他们惧怕泛型是因为泛型给人一种不确定的感觉。我们一起再来看看文章开头的问题:

其实,就我目前为止学习Java的感受来说,除了多态,似乎没有什么是不确定的。
泛型真的把对象类型弄成了变量吗
并没有,通过反编译大家也看到了,其实根本没有所谓的泛型类型T,底层还是Object,所以当我们new一个ArrayList时,JVM根本不会傻傻等着T被确定。T作为参数类型,只作用于编译阶段,用来限制存入和强转取出,JVM是感知不到的,它不关心这个对象将来是ArrayList<Integer>还是ArrayList<String>,仍然还是按JDK1.4以前的做法,底层准备好Object[],以便利用多态特性接收任意类型的对象。
更何况JVM实际new对象是在运行期,编译期的小把戏和它有什么关系?
所以对于泛型类本身来说,它的类型是确定的,就是Object或Object[]数组。
对象类型不确定导致JVM无法创建对象?
如果你指的是泛型类内部的对象类型,上面已经解释了,它的类型是确定的,就是Object或Object[]数组。
如果你指的是存入的元素类型,这个就更荒谬了:
List<User> list = new ArrayList<>();
list.add(new User());
我就是踏踏实实new了一个User对象,怎么会是不确定的呢?
所以泛型有什么是不确定的吗?没有。
实在要说的话,泛型的不确定性在于程序员要求编译器检查的类型是不确定的:
- ArrayList<Integer>:嘿,编译器,帮我把元素限制为Integer类型
- ArrayList<String>:嘿,编译器,帮我把元素限制为String类型
- ...
大家可以暂时把Java的运行环境理解为一颗双层巧克力球,第一层是编译器,第二层是JVM,泛型可以暂时简单理解为一种约束性过滤,但JVM本身在JDK1.5前后是没有太大区别。
泛型是对变量类型的抽取,从而让变量类型变成一种参数(type parameter),最终得到通用的代码模板,但这种所谓的类型不确定,只是为了方便套用各种对象类型进行语法校验,都是编译期的。
而编译期的不确定并不影响运行期对象的创建,因为容器的对象类型始终是Object,元素的类型是用户自己指定的,比如new User(),也是确定的。
一点补充
晚上和一位知友讨论为什么泛型不支持基本类型,我觉得角度挺好的,特别在这里补充。老实说,我一开始也没考虑过这个问题,因为太习惯泛型只能用于引用类型了。
后来我自己查了Oracle官方文档,官方解释了为什么要用泛型,但没解释为什么不支持基本类型:

Why Use Generics?
JDK1.0开始就有基本数据类型和引用类型,直到JDK1.5才引入泛型。而引用类型存在多态,基本数据类型没有多态,因为多态是面向对象的特征。
多态极大地扩展了Java的可玩性,但也有一些弊端。还是以ArrayList为例:

ArrayList是JDK1.2出来的,那会儿还没有泛型,而ArrayList想什么都能存,于是内部用的是Object[]。一个Object[]存了具体类型的元素,本身就构成多态,那么取出时就会面临类型强转的问题(不转就用不了实际类型的很多方法)。
存进去时Object obj = new User(),取出来没记住,转成(Cat)obj了,就强转异常了,于是JDK1.5引入了泛型,在编译期进行约束并帮我们自动强转。
可以说,本身泛型的引入就是为了解决引用类型强转易出错的问题,也就自然不会去考虑基本类型。
当然,网上也有这样解释的,说JDK1.5不仅引入泛型,还同时发布自动拆装箱特性,所以int完全可以用Integer代替,也就无需支持int。
大家猜猜Integer、Long这些包装类啥时候出来的?是不是和我一样以为是JDK1.5出来的?
也就是说,其实即使本身JDK1.5没有引入自动拆装箱,用Integer这些包装类也能勉强糊弄事,手动把基本类型包装后丢进去就好了。
但是大家有没有想过,JDK1.5发布泛型的同时为什么还发布了自动拆装箱特性?虽然真实原因已经无法考究,但我猜测自动拆装箱引入的目的有两个:
- 简化代码
- 从某种意义上让泛型支持基本类型
Java泛型是依赖 编译器+泛型擦除 实现的,它底层还是用Object去接收各类数据。即使编译器在语法上让ArrayList<int>过去了,泛型擦除后int可就要被Object接收了。
所以问题就变成了,Java能不能做到
Object obj = 666;
很显然,不能。 引入了自动拆装箱后还真能!

所以JDK1.5以后,只要你敢把基本类型数据赋值给引用类型,JDK就毫不留情地帮你转成包装类,到头来还是引用类型。
从这个层面来讲,JDK1.5以后基本类型也“变成了”引用类型(基本运算除外),泛型写成ArrayList<int>还是ArrayList<Integer>已经没有什么差别,甚至从语义上来讲ArrayList<Integer>似乎比ArrayList<int>更自洽,坚持了“泛型是对引用类型变量的抽取”这一信条。
我个人观点是,Java已经尽自己最大的努力让泛型支持基本类型了。只不过它不是从语法上支持,而是从功能上支持。拒绝ArrayList<int>保证语义自洽的同时,通过list.add(1)配合自动拆装箱新特性,从功能上实现对基本类型的支持 。
但归根结底,Java泛型之所以无法支持基本类型,还是因为存在泛型擦除,底层仍是Object,而基本类型无法直接赋值给Object类型,导致JDK只能用自动拆装箱特性来弥补,而自动拆装箱会带来性能损耗。
只能说JDK也是不得已而为之吧。
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
进群,大家一起学习,一起进步,一起对抗互联网寒冬