文章目录
1. 导入相关库 2. 加载数据集 3. 整理数据集 4. 图像增广 5. 读取数据 6. 微调预训练模型 7. 定义损失函数和评价损失函数 9. 训练模型
import os
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
- 该数据集是完整数据集的小规模样本
d2l. DATA_HUB[ 'dog_tiny' ] = ( d2l. DATA_URL + 'kaggle_dog_tiny.zip' ,
'0cb91d09b814ecdc07b50f31f8dcad3e81d6a86d' )
demo = True
if demo:
data_dir = d2l. download_extract( 'dog_tiny' )
else :
data_dir = os. path. join( '..' , 'data' , 'dog-breed-identification' )
def reorg_dog_data ( data_dir, valid_ratio) :
labels = d2l. read_csv_labels( os. path. join( data_dir, 'labels.csv' ) )
d2l. reorg_train_valid( data_dir, labels, valid_ratio)
d2l. reorg_test( data_dir)
batch_size = 32 if demo else 128
valid_ratio = 0.1
reorg_dog_data( data_dir, valid_ratio)
transform_train = torchvision. transforms. Compose( [
torchvision. transforms. RandomResizedCrop( 224 , scale= ( 0.08 , 1.0 ) , ratio= ( 3.0 / 4.0 , 4.0 / 3.0 ) ) ,
torchvision. transforms. RandomHorizontalFlip( ) ,
torchvision. transforms. ColorJitter( brightness= 0.4 , contrast= 0.4 , saturation= 0.4 ) ,
torchvision. transforms. ToTensor( ) ,
torchvision. transforms. Normalize(
[ 0.485 , 0.456 , 0.406 ] , [ 0.229 , 0.224 , 0.225 ]
)
] )
transform_test = torchvision. transforms. Compose( [
torchvision. transforms. Resize( 256 ) ,
torchvision. transforms. CenterCrop( 224 ) ,
torchvision. transforms. ToTensor( ) ,
torchvision. transforms. Normalize(
[ 0.485 , 0.456 , 0.406 ] , [ 0.229 , 0.224 , 0.225 ]
)
] )
train_ds, train_valid_ds = [
torchvision. datasets. ImageFolder(
os. path. join( data_dir, 'train_valid_test' , folder) ,
transform= transform_train
) for folder in [ 'train' , 'train_valid' ]
]
valid_ds, test_ds = [
torchvision. datasets. ImageFolder(
os. path. join( data_dir, 'train_valid_test' , folder) ,
transform= transform_test
) for folder in [ 'valid' , 'test' ]
]
train_iter, train_valid_iter = [
torch. utils. data. DataLoader(
dataset, batch_size, shuffle= True , drop_last= True
) for dataset in ( train_ds, train_valid_ds)
]
valid_iter = torch. utils. data. DataLoader(
valid_ds, batch_size, shuffle= False , drop_last= True
)
test_iter = torch. utils. data. DataLoader(
test_ds, batch_size, shuffle= False , drop_last= True
)
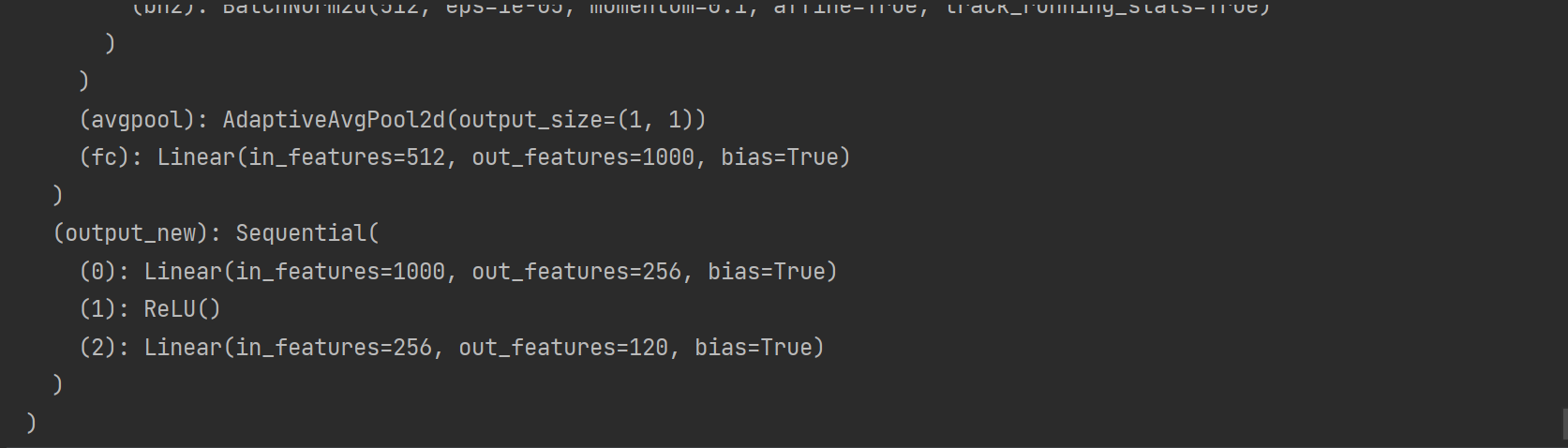
def get_net ( devices) :
finetune_net = nn. Sequential( )
finetune_net. features = torchvision. models. resnet34( weights= torchvision. models. ResNet34_Weights. IMAGENET1K_V1)
finetune_net. output_new = nn. Sequential(
nn. Linear( 1000 , 256 ) ,
nn. ReLU( ) ,
nn. Linear( 256 , 120 )
)
finetune_net = finetune_net. to( devices[ 0 ] )
for param in finetune_net. features. parameters( ) :
param. requires_grad = False
return finetune_net
get_net( devices= d2l. try_all_gpus( ) )
loss = nn. CrossEntropyLoss( reduction= 'none' )
def evaluate_loss ( data_iter, net, device) :
l_sum, n = 0.0 , 0
for features, labels in data_iter:
features, labels = features. to( device[ 0 ] ) , labels. to( device[ 0 ] )
outputs = net( features)
l = loss( outputs, labels)
l_sum += l. sum ( )
n += labels. numel( )
return ( l_sum / n) . to( 'cpu' )
定义训练函数 def train ( net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period, lr_decay) :
net = nn. DataParallel( net, device_ids= devices) . to( devices[ 0 ] )
trainer = torch. optim. SGD(
( param for param in net. parameters( ) if param. requires_grad) ,
lr= lr, momentum= 0.9 , weight_decay= wd
)
scheduler = torch. optim. lr_scheduler. StepLR( trainer, lr_period, lr_decay)
num_batches, timer = len ( train_iter) , d2l. Timer( )
legend = [ 'train loss' ]
if valid_iter is not None :
legend. append( 'valid loss' )
animator = d2l. Animator( xlabel= 'epoch' , xlim= [ 1 , num_epochs] , legend= legend)
for epoch in range ( num_epochs) :
metric = d2l. Accumulator( 2 )
for i, ( features, labels) in enumerate ( train_iter) :
timer. start( )
features, labels = features. to( devices[ 0 ] ) , labels. to( devices[ 0 ] )
trainer. zero_grad( )
output = net( features)
l = loss( output, labels) . sum ( )
l. backward( )
trainer. step( )
metric. add( l, labels. shape[ 0 ] )
timer. stop( )
if ( i + 1 ) % ( num_batches // 5 ) == 0 or i == num_batches - 1 :
animator. add(
epoch + ( i + 1 ) / num_batches, ( metric[ 0 ] / metric[ 1 ] , None )
)
measures = f'train loss { metric[ 0 ] / metric[ 1 ] : .3f } ' if valid_iter is not None :
valid_loss = evaluate_loss( valid_iter, net, devices)
animator. add( epoch + 1 , ( None , valid_loss. detach( ) . cpu( ) ) )
scheduler. step( )
if valid_iter is not None :
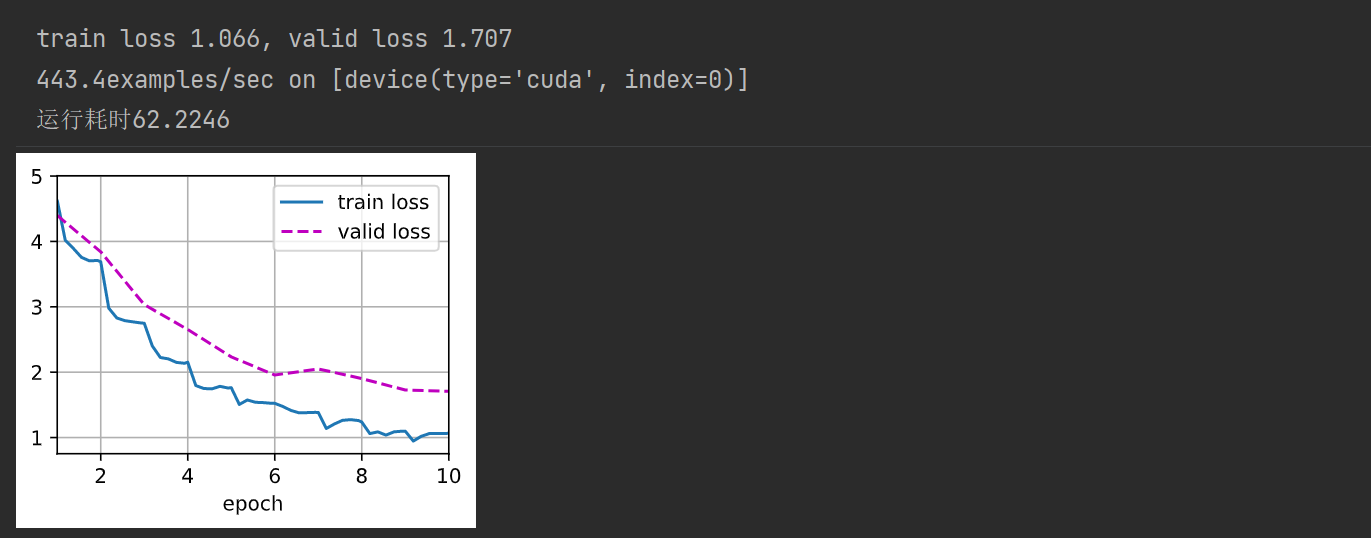
measures += f', valid loss { valid_loss: .3f } ' print ( measures + f'\n { metric[ 1 ] * num_epochs / timer. sum ( ) : .1f } ' f'examples/sec on { str ( devices) } ' )
devices, num_epochs, lr, wd = d2l. try_all_gpus( ) , 10 , 1e-4 , 1e-4
lr_period, lr_decay, net, = 2 , 0.9 , get_net( devices)
import time
start = time. perf_counter( )
train( net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period, lr_decay)
end = time. perf_counter( )
print ( f'运行耗时 { ( end- start) : .4f } ' )