Standalone集群搭建与Spark on Yarn配置
1、Standalone
Standalone集群是Spark自带的资源调度框架,支持分布式搭建,这里建议搭建Standalone节点数为3台,1台master节点,2台worker节点,这虚拟机中每台节点的内存至少给2G和2个core,这样才能保证后期Spark基于Standalone的正常运行。搭建Standalone集群的步骤如下:
1)、下载安装包,解压
登录Spark官网下载Spark,官网地址:Spark官网链接

点击“Download”找到“ Spark release archives”找到对应的Spark版本下载。这里选择Spark2.3.1版本下载。
将下载好的Spark安装包上传到Spark Master节点,解压:
![]()
2)、改名
![]()
3)、进入安装包的conf目录下,修改或者复制slaves.template文件,去掉template后缀,在新的slaves文件中添加从节点。保存。
![]()
在slaves中配置worker节点:

4)、复制$SPARK_HOME/conf/spark-env.sh.template 为spark-env.sh,修改spark-env.sh内容:
SPARK_MASTER_HOST:master的ip
SPARK_MASTER_PORT:提交任务的端口,默认是7077
SPARK_WORKER_CORES:每个worker从节点能够支配的core的个数
SPARK_WORKER_MEMORY:每个worker从节点能够支配的内存数
JAVA_HOME:java的home,这里需要jdk8

5)、同步到其他节点上
![]()
![]()
6)、启动集群
进入sbin目录下,执行当前目录下的./start-all.sh
![]()
7)、搭建客户端
将spark安装包原封不动的拷贝到一个新的节点上,然后,在新的节点上提交任务即可。
注意:
- 8080是Spark WEBUI界面的端口,7077是Spark任务提交的端口。
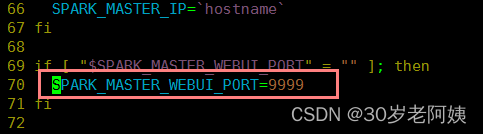
- 修改master的WEBUI端口:
- 修改$SPARK_HOME/conf/spark-env.sh即可【建议使用】:
![]()
- 修改start-master.sh即可。
- 也可以在Master节点上导入临时环境变量,只是作用于之后的程序,重启就无效了。
![]()
删除临时环境变量:
![]()
2、yarn
Spark 也可以基于Yarn进行任务调度,这就是所谓的Spark on Yarn,Spark基于Yarn进行任务调度只需要在Spark客户端做如下配置即可:
![]()
同时这里需要在每台NodeManager节点中将每台NodeManager的虚拟内存关闭,在每台NodeManager节点的$HADOOP_HOME/etc/hadoop/yarn-site.xml中加入如下配置:
<!-- 关闭虚拟内存检查 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>二、Spark Pi任务测试
Spark PI案例:
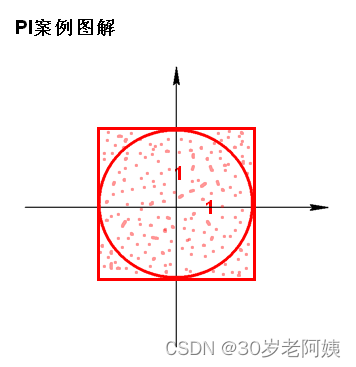
Standalone提交命令:
./spark-submit --master spark://mynode1:7077 --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.3.1.jar 100Spark on YARN提交命令:
./spark-submit --master yarn --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.3.1.jar 100