
🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
2.数据集介绍
3.技术工具
4.实验过程
4.1导入数据
4.2数据预处理
4.3分词处理
4.4词云可视化
4.5构建语料库
4.6词向量化
4.7构建模型
4.8模型评估
4.9模型测试
5.总结
文末推荐与福利
1.项目背景
随着社交媒体和在线平台的普及,大量用户生成的文本数据不断涌现,其中包含了丰富的情感信息。情感分类是自然语言处理(NLP)领域中的一个重要任务,它旨在自动识别和分析文本中蕴含的情感倾向,如积极、消极或中性等。情感分类在社交媒体舆情分析、产品评论分析、用户反馈分析等领域具有广泛的应用。
然而,由于文本数据的复杂性和多样性,单一的分类器可能无法充分捕捉数据的多样性和复杂性。为了提高情感分类的准确性和稳定性,集成学习成为一种常用的方法。Bagging(Bootstrap Aggregating)是集成学习的一种经典方法,它通过训练多个基分类器并对它们的输出进行组合,从而减少模型的过拟合风险,提高整体性能。
本研究旨在探讨基于Bagging集成学习方法的情感分类预测模型。通过结合多个基分类器的输出,我们可以期望获得更为鲁棒和泛化能力强的情感分类模型,从而更好地适应不同领域和文本类型的情感分析任务。此外,通过采用Bootstrap采样技术,Bagging还能够有效减少过拟合的风险,提高模型的稳定性。
在实验中,我们将选择合适的基分类器,并通过Bagging方法进行组合,比较其性能与单一分类器的差异。通过深入研究基于Bagging的情感分类模型,我们旨在为情感分析领域的研究和应用提供新的思路和方法,从而更好地应对大规模文本数据的情感分类问题。
2.数据集介绍
本数据集来源于Kaggle,原始数据集共有5937条,2个特征变量,一个是评论内容,一个是情绪标签。

3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1导入数据
首先导入常用的一些数据分析的第三方库并加载数据集
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
data=pd.read_csv("Emotion_classify_Data.csv")
data.head()
查看数据大小

4.2数据预处理
首先查看数据集是否存在缺失值和重复值

从结果可以发现,原始数据集中并不存在缺失数据和重复数据。
接着对情绪标签变量进行编码处理
# 使用LabelEncoder编码目标列
from sklearn.preprocessing import LabelEncoder
encoder=LabelEncoder()
data["Emotion"]=encoder.fit_transform(data["Emotion"])
data.head()
类以这种形式编码:-如果Emotion=0表示“愤怒”,如果Emotion=1表示“恐惧”,如果Emotion=2表示“快乐”。
pie_labels=data["Emotion"].value_counts().index
pie_values=data["Emotion"].value_counts().values
plt.pie(pie_values,labels=pie_labels,autopct="%1.1f%%")
plt.show()
可以发现数据是平衡的
4.3分词处理
Punkt句子分词器
Punkt tokenizer通过使用无监督算法为缩写词、搭配和句子开头词构建模型,将文本划分为句子列表。
import nltk
nltk.download("punkt")
加载停用词
nltk.download("stopwords")
from nltk.corpus import stopwords
stopwords.words("english")
词干提取
# 测试词干提取
from nltk.stem.porter import PorterStemmer
stemmer=PorterStemmer()
stemmer.stem("playing") # 测试它是否有效![]()
# 预处理数据的函数
def transformed_text(Comment):
# 将文本转换为小写
Comment = Comment.lower()
# 标记文本
words = nltk.word_tokenize(Comment)
# 初始化Porter Stemmer
stemmer = PorterStemmer()
# 删除英语停词并应用词干提取,同时忽略特殊符号
filtered_words = [stemmer.stem(word) for word in words if word not in stopwords.words('english') and word.isalnum()]
# 将过滤后的单词连接回单个字符串
transformed_text = ' '.join(filtered_words)
return transformed_text
data["final_data"]=data["Comment"].apply(transformed_text)
data.head()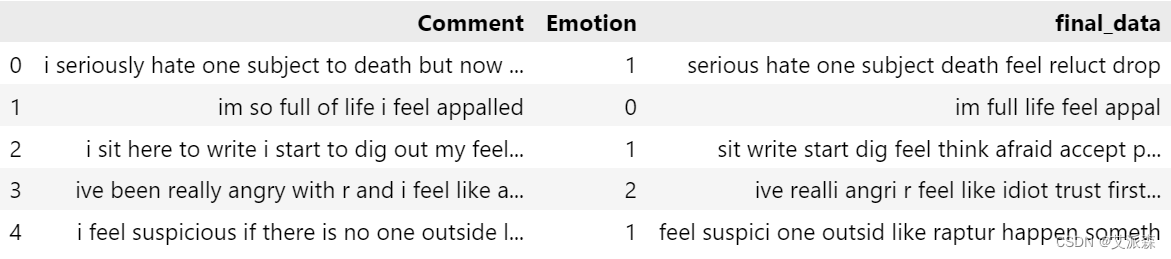
4.4词云可视化
愤怒情绪的词云
from wordcloud import WordCloud
wc=WordCloud(width=500,height=500,min_font_size=10,background_color="white")
# 愤怒情绪的词云
anger_wc=wc.generate(data[data["Emotion"]==0]["final_data"].str.cat(sep=" "))
plt.imshow(anger_wc)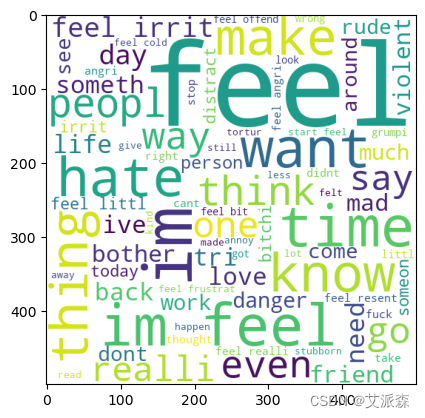
恐惧情绪的词云
# 恐惧情绪的词云
fear_wc=wc.generate(data[data["Emotion"]==1]["final_data"].str.cat(sep=" "))
plt.imshow(fear_wc)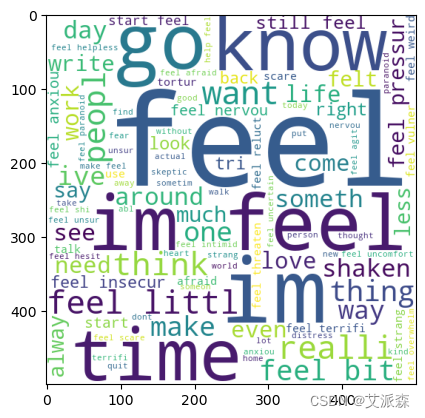
喜悦情绪的词云
# 喜悦情绪的词云
joy_wc=wc.generate(data[data["Emotion"]==2]["final_data"].str.cat(sep=" "))
plt.imshow(joy_wc)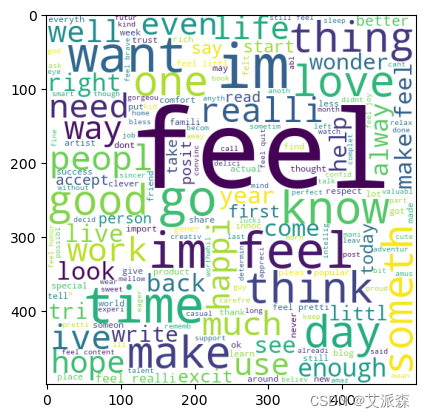
4.5构建语料库
构建愤怒用语的语料库
# 愤怒用语语料库
anger_corpus=[]
for msg in data[data["Emotion"]==0]["final_data"].tolist():
for word in msg.split():
anger_corpus.append(word)
from collections import Counter
pd.DataFrame(Counter(anger_corpus).most_common(50))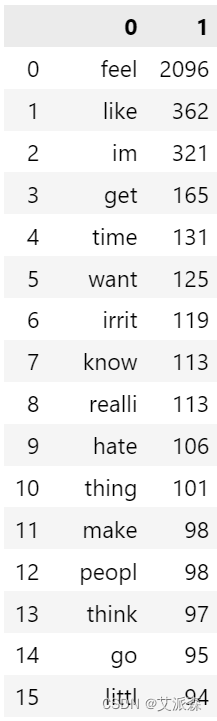
构建恐惧用语的语料库
# 恐惧用语语料库
fear_corpus=[]
for msg in data[data["Emotion"]==1]["final_data"].tolist():
for word in msg.split():
fear_corpus.append(word)
pd.DataFrame(Counter(fear_corpus).most_common(50))
构建喜悦用语的语料库
# 喜悦用语语料库
joy_corpus=[]
for msg in data[data["Emotion"]==2]["final_data"].tolist():
for word in msg.split():
joy_corpus.append(word)
pd.DataFrame(Counter(joy_corpus).most_common(50))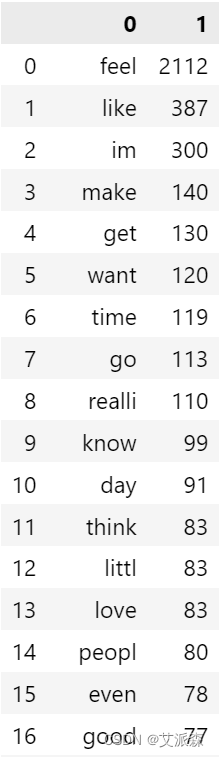
4.6词向量化
from sklearn.feature_extraction.text import CountVectorizer
cvector=CountVectorizer()
x=cvector.fit_transform(data["final_data"]).toarray() # 对数据进行向量化
x
y=data["Emotion"].values
y
4.7构建模型
在构建模型先拆分原始数据集为训练集和测试集
# 分离训练和测试数据
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=3) # 20%的数据将用于测试导入模型的第三方库
# 导入模型
from sklearn.metrics import accuracy_score,precision_score
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.naive_bayes import MultinomialNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier 逻辑回归模型
# Logistic regression逻辑回归模型
log_reg=LogisticRegression()
log_reg.fit(x_train,y_train)
y_log_pred=log_reg.predict(x_test)
yt_log_pred=log_reg.predict(x_train)
log_reg_acc=accuracy_score(y_test,y_log_pred)
log_reg_prec=precision_score(y_test,y_log_pred,average='macro')
tr_log_reg_acc=accuracy_score(y_train,yt_log_pred)
tr_log_reg_prec=precision_score(y_train,yt_log_pred,average='macro')
print("accuracy score on train data is ",tr_log_reg_acc)
print("precision score on train data is ",tr_log_reg_prec)
print("accuracy score on test data is ",log_reg_acc)
print("precision score on test data is ",log_reg_prec)
支持向量机模型
# Support vector classifier 支持向量机模型
sv=SVC()
sv.fit(x_train,y_train)
sv_pred=sv.predict(x_test)
svt_pred=sv.predict(x_train)
sv_acc=accuracy_score(y_test,sv_pred)
sv_prec=precision_score(y_test,sv_pred,average='macro')
svt_acc=accuracy_score(y_train,svt_pred)
svt_prec=precision_score(y_train,svt_pred,average='macro')
print("accuracy score on train datais ",svt_acc)
print("precision score on train data is ",svt_prec)
print("accuracy score on test data is ",sv_acc)
print("precision score on test data is ",sv_prec)
决策树模型
# Decision tree Classifier决策树模型
dec_tree=DecisionTreeClassifier()
dec_tree.fit(x_train,y_train)
dec_tree_pred=dec_tree.predict(x_test)
dec_tree_tr_pred=dec_tree.predict(x_train)
dec_tree_acc=accuracy_score(y_test,dec_tree_pred)
dec_tree_prec=precision_score(y_test,dec_tree_pred,average='macro')
dec_tree_tr_acc=accuracy_score(y_train,dec_tree_tr_pred)
dec_tree_tr_prec=precision_score(y_train,dec_tree_tr_pred,average='macro')
print("accuracy score on train data is ",dec_tree_tr_acc)
print("precision score on train data is ",dec_tree_tr_prec)
print("accuracy score on test data is ",dec_tree_acc)
print("precision score on test data is ",dec_tree_prec)
随机森林模型
# Random forest classifier 随机森林模型
rfcl_model=RandomForestClassifier()
rfcl_model.fit(x_train,y_train)
rfcl_pred_model=rfcl_model.predict(x_test)
rfcl_tr_pred_model=rfcl_model.predict(x_train)
rfcl_acc_model=accuracy_score(y_test,rfcl_pred_model)
rfcl_prec_model=precision_score(y_test,rfcl_pred_model,average='macro')
rfcl_tr_acc_model=accuracy_score(y_train,rfcl_tr_pred_model)
rfcl_tr_prec_model=precision_score(y_train,rfcl_tr_pred_model,average='macro')
print("accuracy score on train data is ",rfcl_tr_acc_model)
print("precision score on train data is ",rfcl_tr_prec_model)
print("accuracy score on test data is ",rfcl_acc_model)
print("precision score on test data is ",rfcl_prec_model)
朴素贝叶斯模型
# Naive Bayes classifier 朴素贝叶斯模型
mnb=MultinomialNB()
mnb.fit(x_train,y_train)
mnb_pred=mnb.predict(x_test)
mnb_tr_pred=mnb.predict(x_train)
mnb_acc=accuracy_score(y_test,mnb_pred)
mnb_prec=precision_score(y_test,mnb_pred,average='macro')
mnb_tr_acc=accuracy_score(y_train,mnb_tr_pred)
mnb_tr_prec=precision_score(y_train,mnb_tr_pred,average='macro')
print("accuracy score on train data is ",mnb_tr_acc)
print("precision score on train data is ",mnb_tr_prec)
print("accuracy score on test data is ",mnb_acc)
print("precision score on test data is ",mnb_prec)
XGBoost模型
# XGboost classifier XGB模型
xgb=XGBClassifier()
xgb.fit(x_train,y_train)
xgb_pred=xgb.predict(x_test)
xgb_tr_pred=xgb.predict(x_train)
xgb_acc=accuracy_score(y_test,xgb_pred)
xgb_prec=precision_score(y_test,xgb_pred,average='macro')
xgb_tr_acc=accuracy_score(y_train,xgb_tr_pred)
xgb_tr_prec=precision_score(y_train,xgb_tr_pred,average='macro')
print("accuracy score on train data is ",xgb_tr_acc)
print("precision score on train data is ",xgb_tr_prec)
print("accuracy score on test data is ",xgb_acc)
print("precision score on test data is ",xgb_prec)
Adaboost模型
# Adaboost模型
adb=AdaBoostClassifier()
adb.fit(x_train,y_train)
adb_pred=adb.predict(x_test)
adb_tr_pred=adb.predict(x_train)
adb_acc=accuracy_score(y_test,adb_pred)
adb_prec=precision_score(y_test,adb_pred,average='macro')
adb_tr_acc=accuracy_score(y_train,adb_tr_pred)
adb_tr_prec=precision_score(y_train,adb_tr_pred,average='macro')
print("accuracy score on train data is ",adb_tr_acc)
print("precision score on train data is ",adb_tr_prec)
print("accuracy score on test data is ",adb_acc)
print("precision score on test data is ",adb_prec)
GBDT模型
# Gradient Boost 模型
gbc=GradientBoostingClassifier()
gbc.fit(x_train,y_train)
gbc_pred=gbc.predict(x_test)
gbc_tr_pred=gbc.predict(x_train)
gbc_acc=accuracy_score(y_test,gbc_pred)
gbc_prec=precision_score(y_test,gbc_pred,average='macro')
gbc_tr_acc=accuracy_score(y_train,gbc_tr_pred)
gbc_tr_prec=precision_score(y_train,gbc_tr_pred,average='macro')
print("accuracy score on train data is ",gbc_tr_acc)
print("precision score on train data is ",gbc_tr_prec)
print("accuracy score on test data is ",gbc_acc)
print("precision score on test data is ",gbc_prec)
Bagging Classifer模型
# Bagging Classifer模型
bagc=BaggingClassifier()
bagc.fit(x_train,y_train)
bagc_pred=bagc.predict(x_test)
bagc_tr_pred=bagc.predict(x_train)
bagc_acc=accuracy_score(y_test,bagc_pred)
bagc_prec=precision_score(y_test,bagc_pred,average='macro')
bagc_tr_acc=accuracy_score(y_train,bagc_tr_pred)
bagc_tr_prec=precision_score(y_train,bagc_tr_pred,average='macro')
print("accuracy score on train data is ",bagc_tr_acc)
print("precision score on train data is ",bagc_tr_prec)
print("accuracy score on test data is ",bagc_acc)
print("precision score on test data is ",bagc_prec)
KNN模型
# KNN classifier模型
knn=KNeighborsClassifier(n_neighbors=5)
knn.fit(x_train,y_train)
knn_pred=knn.predict(x_test)
knn_tr_pred=knn.predict(x_train)
knn_acc=accuracy_score(y_test,knn_pred)
knn_prec=precision_score(y_test,knn_pred,average='macro')
knn_tr_acc=accuracy_score(y_train,knn_tr_pred)
knn_tr_prec=precision_score(y_train,knn_tr_pred,average='macro')
print("accuracy score on train data is ",knn_tr_acc)
print("precision score on train data is ",knn_tr_prec)
print("accuracy score on test data is ",knn_acc)
print("precision score on test data is ",knn_prec)
4.8模型评估
前面我们使用了10个机器学习中的分类模型进行了拟合,现在综合评估各模型的指标情况,选择最佳模型
# 显示各模型性能指标
pd.DataFrame({"model_name":["logistic_regression","support_vector_classifier","decision_tree","random_forest","multinomial_NB","xgboost","adaboost","gradientboost","bagging","knn"],
"train_precision_score":[tr_log_reg_prec,svt_prec,dec_tree_tr_prec,rfcl_tr_prec_model,mnb_tr_prec,xgb_tr_prec,adb_tr_prec,gbc_tr_prec,bagc_tr_prec,knn_tr_prec],
"test_precision_score":[log_reg_prec,sv_prec,dec_tree_prec,rfcl_prec_model,mnb_prec,xgb_prec,adb_prec,gbc_prec,bagc_prec,knn_prec],
"train_accuracy_score":[tr_log_reg_acc,svt_acc,dec_tree_tr_acc,rfcl_tr_acc_model,mnb_tr_acc,xgb_tr_acc,adb_tr_acc,gbc_tr_acc,bagc_tr_acc,knn_tr_acc],
"test_accuracy_score":[log_reg_acc,sv_acc,dec_tree_acc,rfcl_acc_model,mnb_acc,xgb_acc,adb_acc,gbc_acc,bagc_acc,knn_acc]
})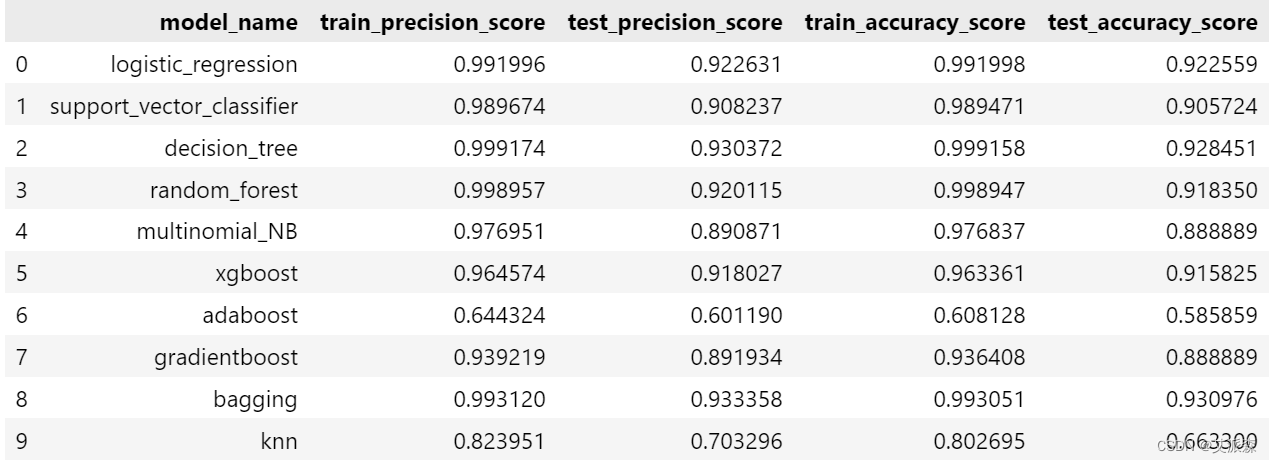
可以发现,决策树模型表现良好,但它可能导致数据过拟合,我们可以考虑Bagging和随机森林分类器,因为它们给出了最好的结果,精度和准确性得分很好地平衡。
4.9模型测试
使用Bagging模型进行测试新数据
# 测试新数据
user_text = "i hope that the next quote will be able to let my special someone knows what im feeling insecure about and understand that no matter how much i trust"
# 转换给定的文本
transformed_user_data = transformed_text(user_text)
# 向量化转换后的文本
text_vectorized = cvector.transform([transformed_user_data]).toarray()
# 使用模型进行预测
prediction = bagc.predict(text_vectorized)
# 打印预测结果
if prediction==0:
print("emotion is anger")
elif prediction==1:
print("emotion is fear")
else:
print("emotion is joy")
可以发现模型分类正确!
5.总结
本实验旨在通过对英文文本中的愤怒、恐惧和喜悦等情感进行分类,利用10个常用的机器学习分类模型进行实验比较,最终选择Bagging模型进行拟合。实验结果显示,在测试集上,该Bagging模型取得了显著的准确率,达到了93%。
首先,通过对数据进行仔细的预处理和清洗,以及有效的特征提取,我们确保了输入模型的文本数据质量。选择10个常用的分类模型,包括决策树、支持向量机、逻辑回归等,为实验提供了广泛的比较基准,有助于找到最适合任务的模型。
然后,通过在这些模型中进行比较,我们发现Bagging模型在多方面指标上表现最为理想,具有较好的性能和稳定性。Bagging的优势在于能够通过组合多个基分类器的输出,降低过拟合的风险,并提高整体性能。最终的93%的准确率反映了该Bagging模型在情感分类任务中的出色表现。这意味着模型对于英文文本中的情感极性有着较强的识别和泛化能力。
综合来看,本实验通过充分比较不同分类模型,选择了Bagging模型作为最终的情感分类器,为处理英文情感文本提供了一个有效的解决方案。未来的研究可以进一步深入探讨模型的可解释性、对不平衡数据的适应性等方面,以进一步提升情感分类任务的性能。
文末推荐与福利
《AI智能化办公》与《巧用ChatGPT高效搞定Excel数据分析》二选一免费包邮送出3本!


内容简介:
《AI智能化办公》:
本书以人工智能领域最新翘楚“ChatGPT”为例,全面系统地讲解了ChatGPT的相关操作与热门领域的实战应用。
全书共10章,第1章介绍了ChatGPT是什么;第2章介绍了ChatGPT的注册与登录;第3章介绍了ChatGPT的基本操作与提问技巧;第4章介绍了用ChatGPT生成文章;第5章介绍了用ChatGPT生成图片;第6章介绍了用ChatGPT生成视频;第7章介绍了用ChatGPT编写程序;第8章介绍了ChatGPT的办公应用;第9章介绍了ChatGPT的设计应用;第10章介绍了ChatGPT的更多场景应用。
本书面向没有计算机专业背景又希望迅速上手ChatGPT操作应用的用户,也适合有一定的人工智能知识基础且希望快速掌握ChatGPT落地实操应用的读者学习。本书内容系统,案例丰富,浅显易懂,既适合ChatGPT入门的读者学习,也适合作为广大中职、高职、本科院校等相关专业的教材参考用书。
购买链接:
当当链接:http://product.dangdang.com/29646620.html
京东链接:https://item.jd.com/14256742.html
《巧用ChatGPT高效搞定Excel数据分析》:
本书以Excel 2021办公软件为操作平台,创新地借助当下最热门的AI工具——ChatGPT,来学习Excel数据处理与数据分析的相关方法、技巧及实战应用,同时也向读者分享在ChatGPT的帮助下进行数据分析的思路和经验。
全书共10章,分别介绍了在ChatGPT的帮助下,使用Excel在数据分析中的应用、建立数据库、数据清洗与加工、计算数据、简单分析数据、图表分析、数据透视表分析、数据工具分析、数据结果展示,最后通过行业案例,将之前学习的数据分析知识融会贯通,应用于实际工作中,帮助读者迅速掌握多项数据分析的实战技能。
本书内容循序渐进,章节内容安排合理,案例丰富翔实,适合零基础想快速掌握数据分析技能的读者学习,可以作为期望提高数据分析操作技能水平、积累和丰富实操经验的商务人员的案头参考书,也可以作为各大、中专职业院校,以及计算机培训班的相关专业的教学参考用书。
购买链接:
京东购买链接:https://item.jd.com/14256748.html
当当网购买链接:http://product.dangdang.com/29646616.html
- 抽奖方式:评论区随机抽取3位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2023-11-24 20:00:00
名单公布时间:2023-11-24 21:00:00
免费资料获取,更多粉丝福利,关注下方公众号获取





![web:[GXYCTF2019]禁止套娃](https://img-blog.csdnimg.cn/02609482c9274d219e1fd798943d3dff.png)


![②【Hash】Redis常用数据类型:Hash [使用手册]](https://img-blog.csdnimg.cn/20a7f1b58dfb4660b75d7f021c157d57.png#pic_center)

![[Docker]七.配置 Docker 网络](https://img-blog.csdnimg.cn/0d6d61034d204cf09e0eaff795e5fcaa.png)