目录
一.前言
二.移除链表元素
三.返回链表中间节点
四.链表中倒数第K个节点
五.合并两个有序链表
六.反转链表
七.链表分割
八.链表的回文结构
九.相交链表
十.环形链表
十一.环形链表(二)
六.结语
 一.前言
一.前言
本文主要对平时的链表OJ进行解析,帮助大家更加深入理解关于链表的性质特点。码字不易,希望大家多多支持我呀!(三连+关注,你是我滴神!)
二.移除链表元素
链接:203.移除链表元素

第一种思路:遍历删除
遍历变量cur:用于查找符合val的节点。再添加一个前置变量,用于连接删除过后的节点。
但其实这样子演示还是有弊端存在的~
当开头就出现符合val的节点,那么这两个指针变量又该如何指向呢?
我们可以把前面符合的都先删掉,最后再让head重新指向,另外两个变量也重新指向。
情况分析完毕,现在开始代码部分:
struct ListNode* removeElements(struct ListNode* head, int val) { struct ListNode* pre = NULL, * cur = head; while (cur) { if (cur->val == val)//开始分析情况,如果找到就删除 { //开始删除 if (cur == head)//刚好要头删 { head = cur->next; free(cur); cur = head;//cur需要重新用head赋值,以便遍历 } else//中间部分删除。意味着有pre变量了 { free(cur); pre->next = cur->next; cur = pre->next;//因为free后cur没指向了,需要重新赋值 } } else//找不到就让cur往下走,随便标记pre { pre = cur; cur = cur->next; } } return head; }其实本质就是头删与中间删而已,只不过我们需要为其添加特定条件来应对各种情况~

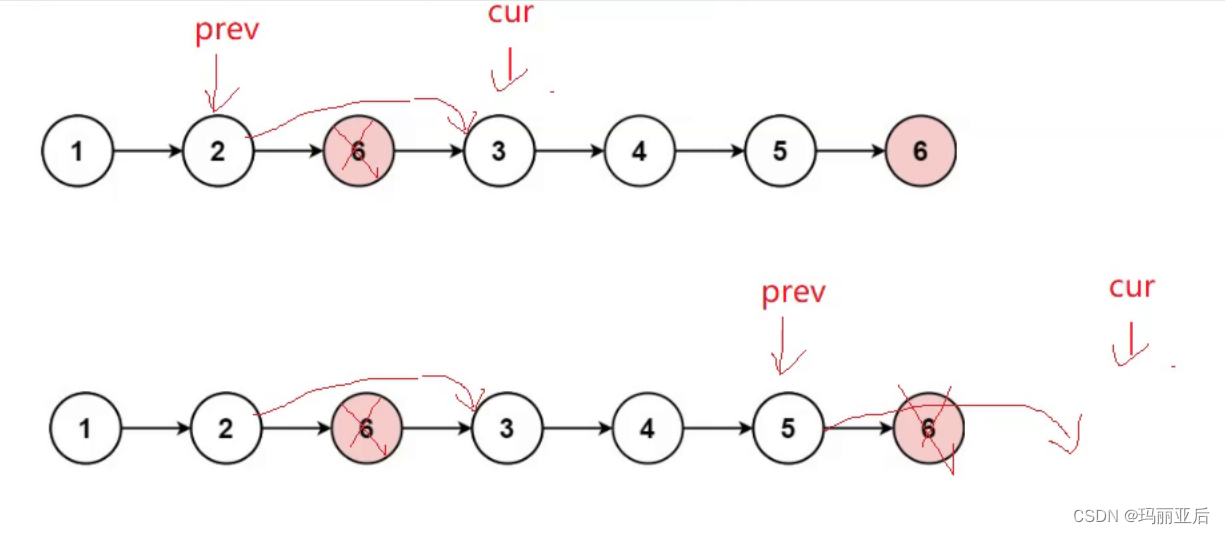
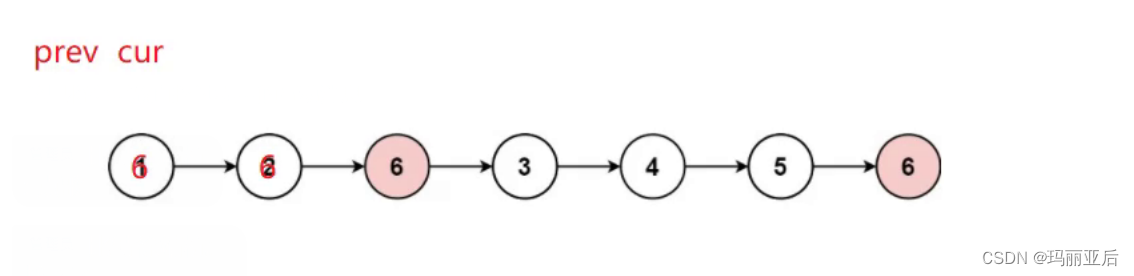

第二种思路:遍历原链表,把不是val的节点尾插到新链表
需要用next变量来保存cur的下一个节点,这样方便cur指向。(当然不用next变量也可以,因为我们并没有改变cur的下一个变量)
在新链表中创造一个节点tail用来尾插。
代码部分:
struct ListNode* removeElements(struct ListNode* head, int val) { struct ListNode* cur = head; struct ListNode* newhead = NULL, * tail = NULL; while (cur) { if (cur->val == val)//当遇到val时,消除再重新指向 { struct ListNode* del = cur; cur = cur->next; free(del); } else//没遇到val时,移动至新链表进行尾插 { //当新链表为空时 if (newhead == NULL) { newhead = tail = cur; } else//当新链表不为空时 { tail->next = cur; tail = tail->next; //tail->next = NULL;//尾插后记得置空//但是注意,不要在这里置空 } cur = cur->next; } } if (tail) { tail->next = NULL; } return newhead; }


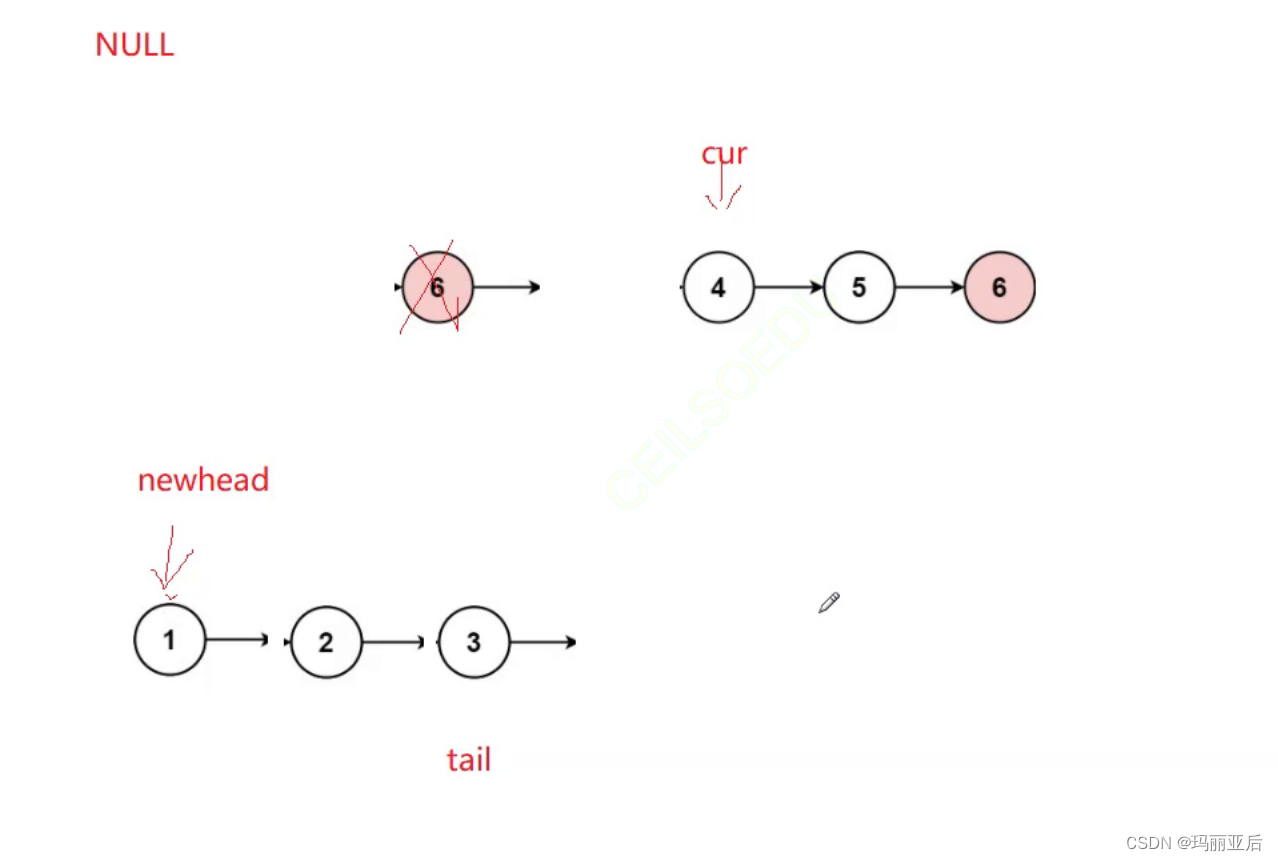
三.返回链表中间节点
链接:876.返回链表中间节点

常规思路:
遍历一遍算出链表长度,再遍历一遍找到中间节点。
第二种思路:快慢指针
一开始两指针起点一致,然后遍历的时候让慢指针(slow)走一步,快指针(fast)走两步。
快指针的速度是慢指针的一倍,那么当快指针指向结尾的时候,慢指针的指向就是中间节点了。
奇数个节点和偶数个节点的情况可能会不一样,所以我们还需要再来分析一遍。
对于奇数个而言是走到尾节点,对于偶数个而言是走向空。
struct ListNode* middleNode(struct ListNode* head) { struct ListNode* fast = head, * slow = head; while (fast && fast->next)//偶数个时fast指向空结束,奇数时fast指向尾节点结束 { slow = slow->next; fast = fast->next->next; } return slow; }


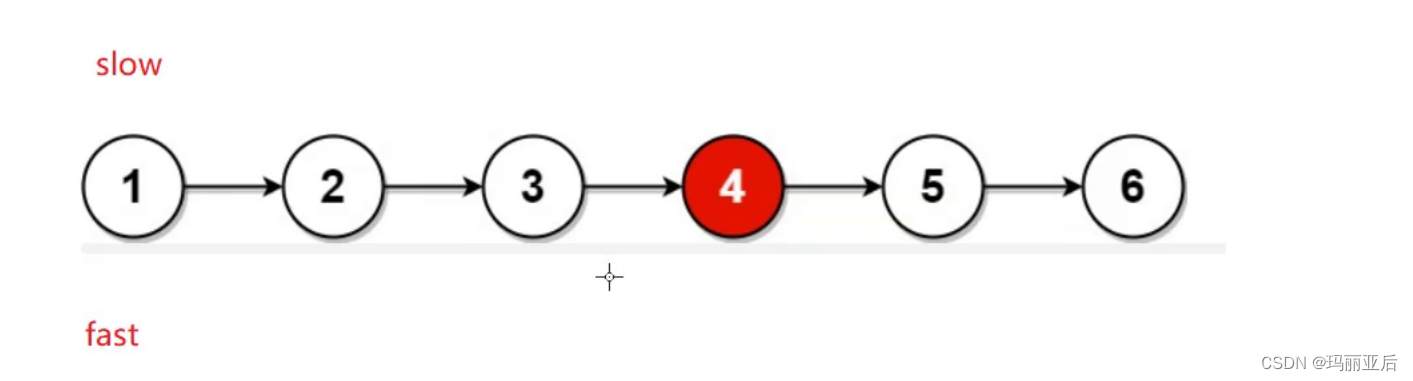

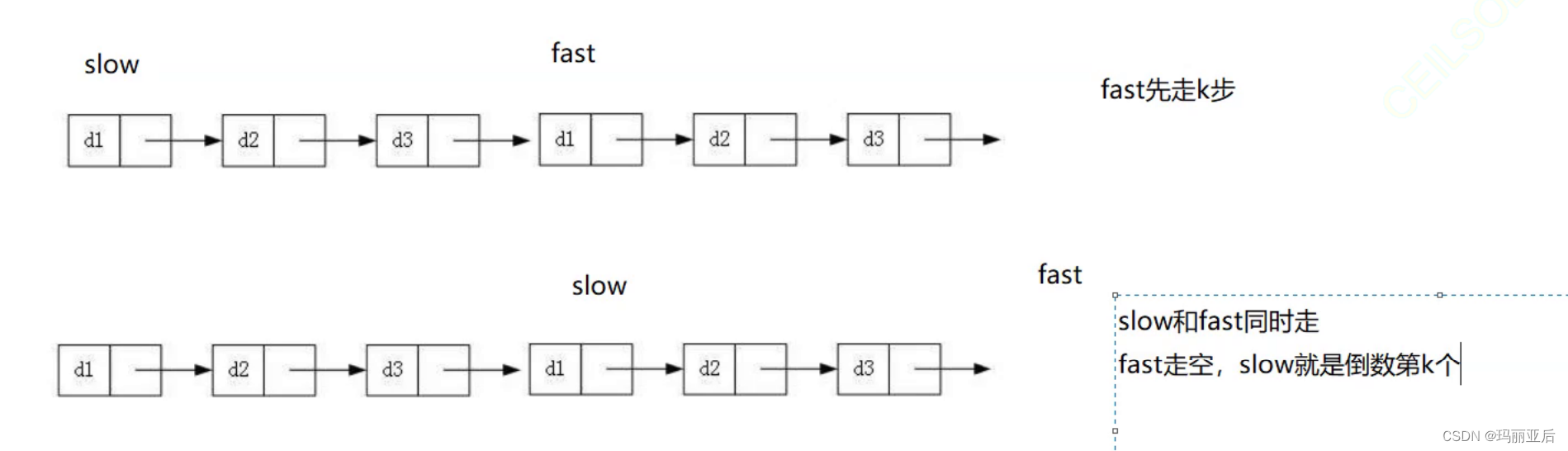
四.链表中倒数第K个节点
链接:链表中倒数第K个节点
这里我们还是可以使用多次遍历的方式来找到目标节点,所以我们额外添加一个条件:只能遍历一遍,那又要怎么做到呢?
还是老规矩,采用快慢指针的方法,只不过步数需要调整。
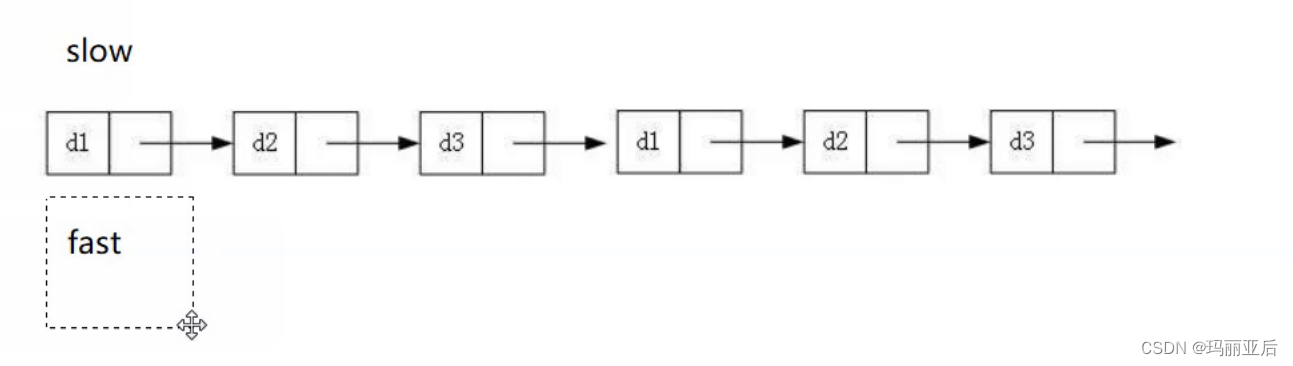
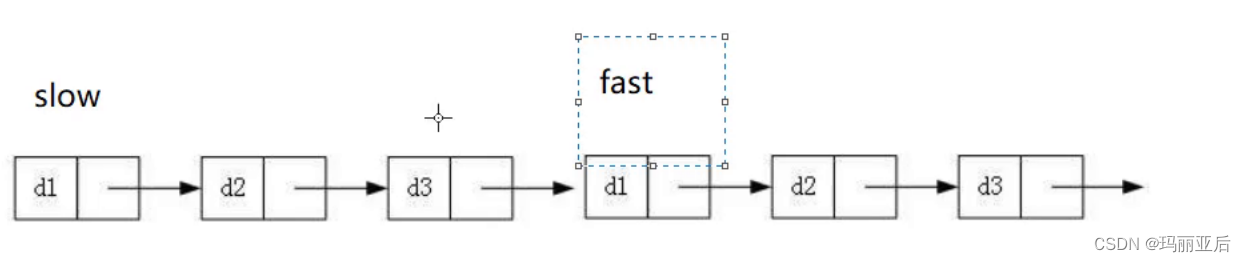
比如我们要找倒数第3个节点,我们先让fast走3步。
然后再让2个节点同时走,走到fast为空时结束。从空开始算起。
还有另外一种方式,就是我们可以先走k-1步。
走到尾节点结束,从尾节点算起。
struct ListNode* FindKthToTail(struct ListNode* head, int k) { struct ListNode* fast = head, * slow = head; while (k--) { //也要考虑例如走倒数第1000个节点这种极端情况,一旦越界立马返回 if (fast==NULL) { return NULL; } else { fast = fast->next; } } while (fast) { fast = fast->next; slow = slow->next; } return slow; }


五.合并两个有序链表
链接:21.合并两个有序链表
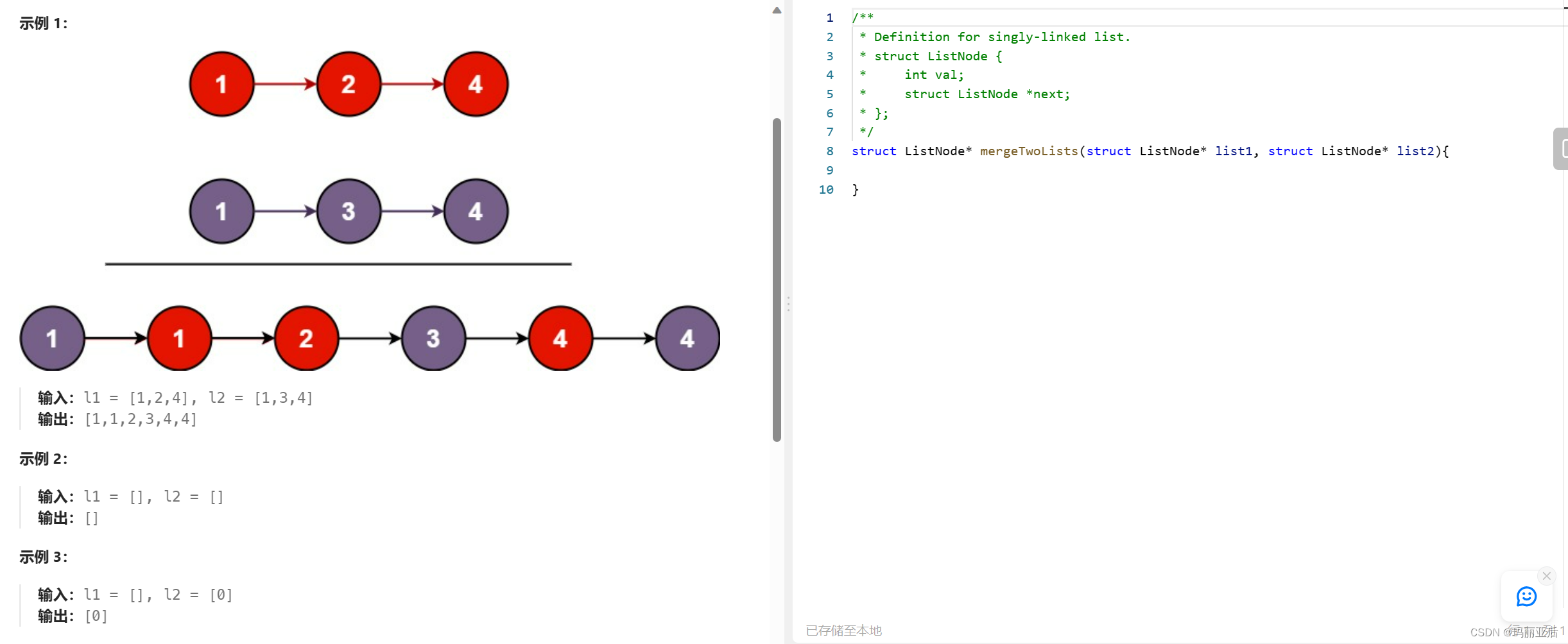
一般思路:构建一个新的链表,然后在两个原链表之间取小的尾插。 (其实这个跟之前的合并数组想法很像)
持续到其中一个链表头节点指向空为止~
代码部分:
struct ListNode { int val; struct ListNode* next; }; struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) { if (list1 == NULL) { return list2; } if (list2 == NULL) { return list1; } struct ListNode* tail = NULL, * head = NULL; while (list1 && list2) { if (list1->val > list2->val) { if (head == NULL)//当新链表为空时 { head = list2; tail = list2; } else//当新链表不为空时 { tail->next = list2; tail = tail->next; } list2 = list2->next; } else { if (head == NULL)//当新链表为空时 { head = list1; tail = list1; } else//当新链表不为空时 { tail->next = list1; tail = tail->next; } list1 = list1->next; } } if (list1) { tail->next = list1; } if (list2) { tail->next = list2; } return head;
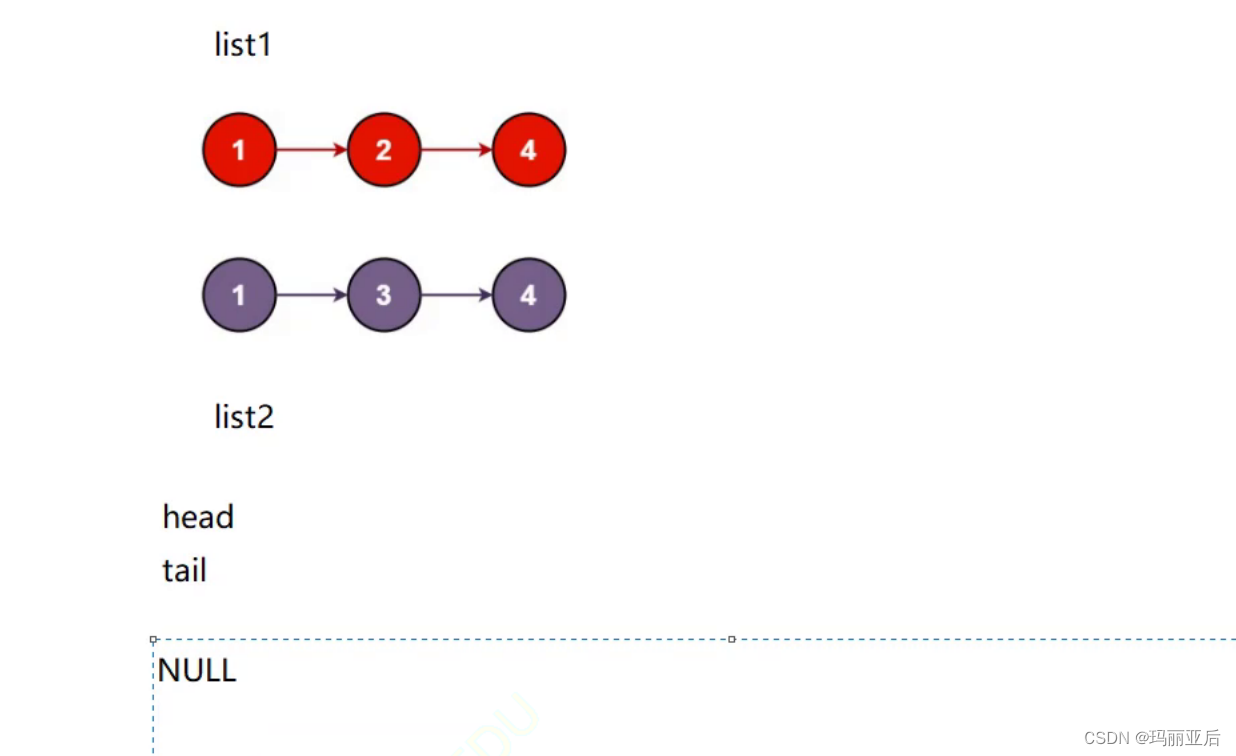
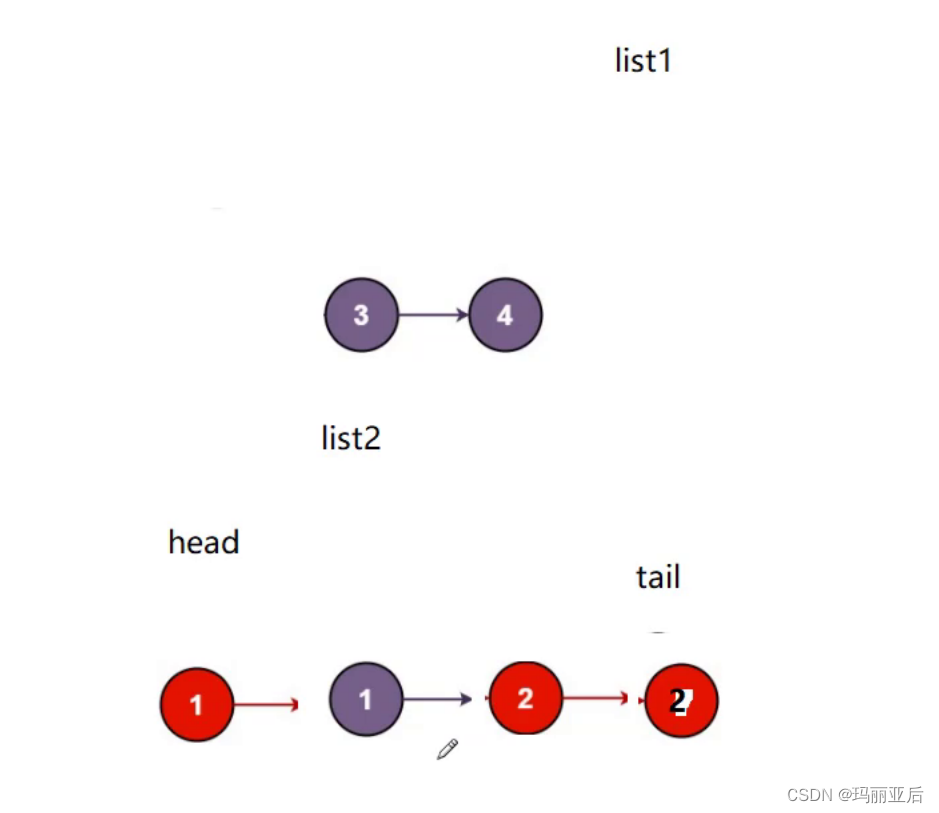
另一种思路:使用带头哨兵位
无带头节点(哨兵位)时还得判断是不是第一次插入,而有了带头节点后就减少了一步判断。
当单链表改成哨兵位时,还可以不用二级指针。
运行代码:
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) { if (list1 == NULL) { return list2; } if (list2 == NULL) { return list1; } struct ListNode* tail = NULL, * head = NULL; tail = head = (struct ListNode*)malloc(sizeof(struct ListNode));//创造哨兵位 while (list1 && list2) { if (list1->val > list2->val) { tail->next = list2; tail = tail->next; list2 = list2->next; } else { tail->next = list1; tail = tail->next; list1 = list1->next; } } if (list1) { tail->next = list1; } if (list2) { tail->next = list2; } //返回的时候删除掉哨兵位 struct ListNode* del = head; head = head->next; free(del); return head; }

六.反转链表
链接:206.反转链表

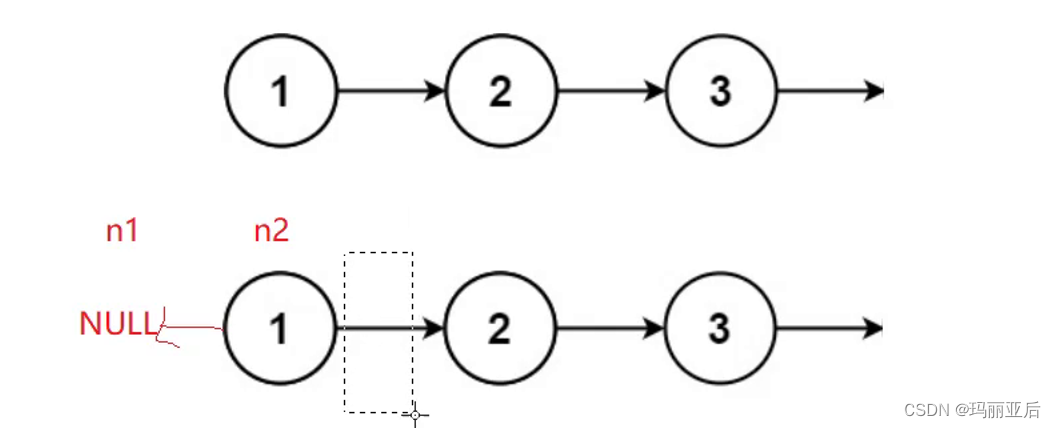
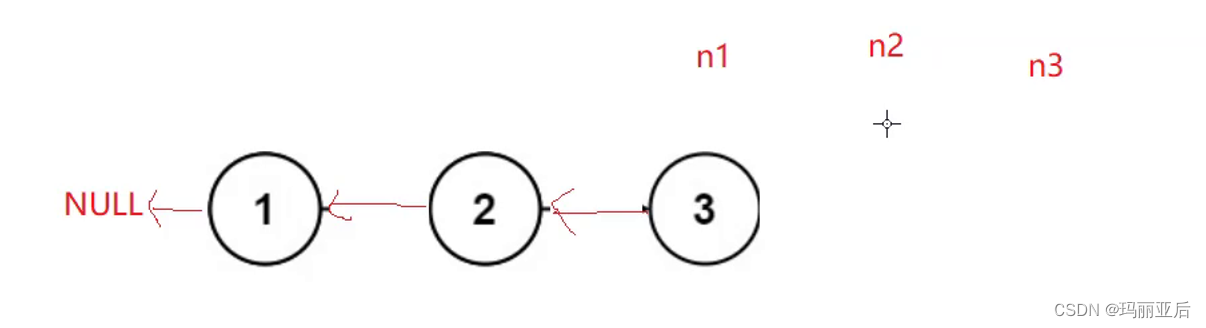
第一种思路:三指针
双指针还不能够实现反转。当n2指向n1时你就找不到下一个了。前两个是反转,后面是为了寻找下一个。
反转结束后再整体往后移动继续反转。
当n2等于空时结束。
但是这样是会有问题的,在我们执行最后一步时,n2已经是执行空了,所以不能让n3执行空的下一位,这样是错误的。
当解决这个问题后还有一个问题,我们没有考虑过链表为空的情况,所以还是跟上面一样的错误。所以很麻烦。

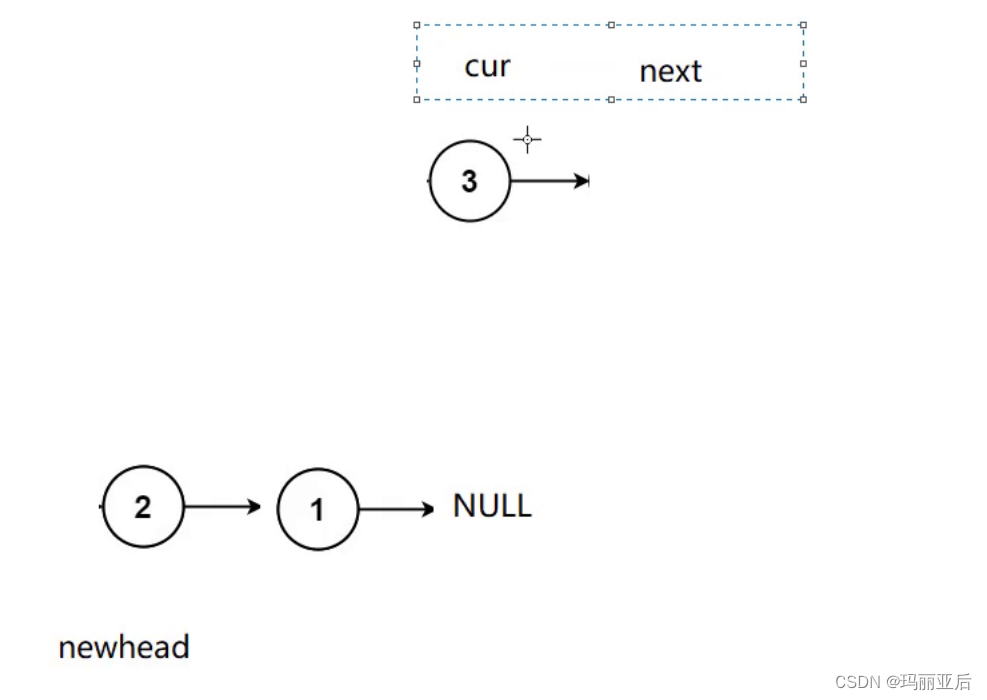
第二种思路:把节点拿下来头插
在第一个节点取下来头插指向newhead后,让newhead指向它,cur继续指向第二节点。
以此类推,直到cur指向空时停止。
运行代码:
struct ListNode* reverseList(struct ListNode* head) { struct ListNode* newnode = NULL; struct ListNode* cur = head; while (cur) { struct ListNode* next = cur->next; //进行头插 cur->next = newnode; newnode = cur; cur = next; } return newnode; }


七.链表分割
链接:CM11.链表分割
本题难点在于不能改变原有顺序(即相对顺序),所以我们开始的思路是再弄两条新链表。
做好尾插后再把两条链表链接起来,最后返回头节点即可。但本题坑点很多,其中不带哨兵位的话会比带哨兵位难很多。
当我们要链接两条链表的时候,要作出很多的判断~
- 当lesstail为空的时候,就不能用链接了,而是直接返回greaterhead.
- 当lesstail不为空时,得确保lesshead是头
- 等等
当我们设置哨兵位的时候,就不用考虑哪个链表是否为空的情况,直接链接即可。
最终指向如上图所示,最后我们只需要消除哨兵位即可。
代码部分:
class Partition { public: ListNode* partition(ListNode* head, int x) { struct ListNode* ghead, * gtail, * lhead, ltail; ghead = gtail = (struct ListNode*)malloc(sizeof(struct ListNode)); lhead = ltail = (struct ListNode*)malloc(sizeof(struct ListNode)); struct ListNode* cur = head; while (cur)//拆分链表 { if (cur->val < x) { ltail->next = cur; ltail = ltail->next; } else { gtail->next = cur; gtail = gtail->next; } cur = cur->next; } //链接新链表 ltail->next = ghead->next; struct ListNode* Head = lhead->next; free(ghead); free(lhead); return Head; } };这样还不够完整,还会出现错误。
最后补充一个小细节,当我们的cur指向5并成功尾插的时候,按理来说5后面应该指向空,因为5后序的数据都不符合第二链表条件,但我们会发现5还会指向1造成了循环。所以我们要及时置空。
完整代码:
class Partition { public: ListNode* partition(ListNode* head, int x) { struct ListNode* ghead, * gtail, * lhead, ltail; ghead = gtail = (struct ListNode*)malloc(sizeof(struct ListNode)); lhead = ltail = (struct ListNode*)malloc(sizeof(struct ListNode)); struct ListNode* cur = head; while (cur)//拆分链表 { if (cur->val < x) { ltail->next = cur; ltail = ltail->next; } else { gtail->next = cur; gtail = gtail->next; } cur = cur->next; } gtail->next = NULL;//及时置空 //链接新链表 ltail->next = ghead->next; struct ListNode* Head = lhead->next; free(ghead); free(lhead); return Head; } };




八.链表的回文结构
链接:OR36.链表的回文结构

回文结构也分奇数回文与偶数回文:
想法:找到中间节点,再逆置中间节点后面的节点。最后再来与头节点与指向中间节点的数据一一对比。
我们可以套用前面已经写好的寻找中间节点代码与反转链表来实现找到中间节点与逆置中间节点后面的节点,最后再来处理对比。
逆置完后链表会变成这样,跟前面链表分割一个性质,如果没有刻意去切断链接,那就会藕断丝连。不过这种情况问题不大,应该这两个指针只要任意一个指向空就结束,例如在上图中1与1相等,指向下一位,2与2相等,一个指向3,另一个也指向3还是相等,最后一个指向空结束。
运行代码:
class PalindromeList { public: struct ListNode* middleNode(struct ListNode* head) { struct ListNode* fast = head, * slow = head; while (fast && fast->next)//偶数个时fast指向空结束,奇数时fast指向尾节点结束 { slow = slow->next; fast = fast->next->next; } return slow; } struct ListNode* reverseList(struct ListNode* head) { struct ListNode* newnode = NULL; struct ListNode* cur = head; while (cur) { struct ListNode* next = cur->next; //进行头插 cur->next = newnode; newnode = cur; cur = next; } return newnode; } bool chkPalindrome(ListNode* head) { struct ListNode* mid = middleNode(head); struct ListNode* rmid = reverseList(mid); while (head && rmid)//一方指向空就停止 { if (head->val != rmid->val) { return false; } else { head = head->next; rmid = rmid->next; } } return true; } };


九.相交链表
链接:160.相交链表
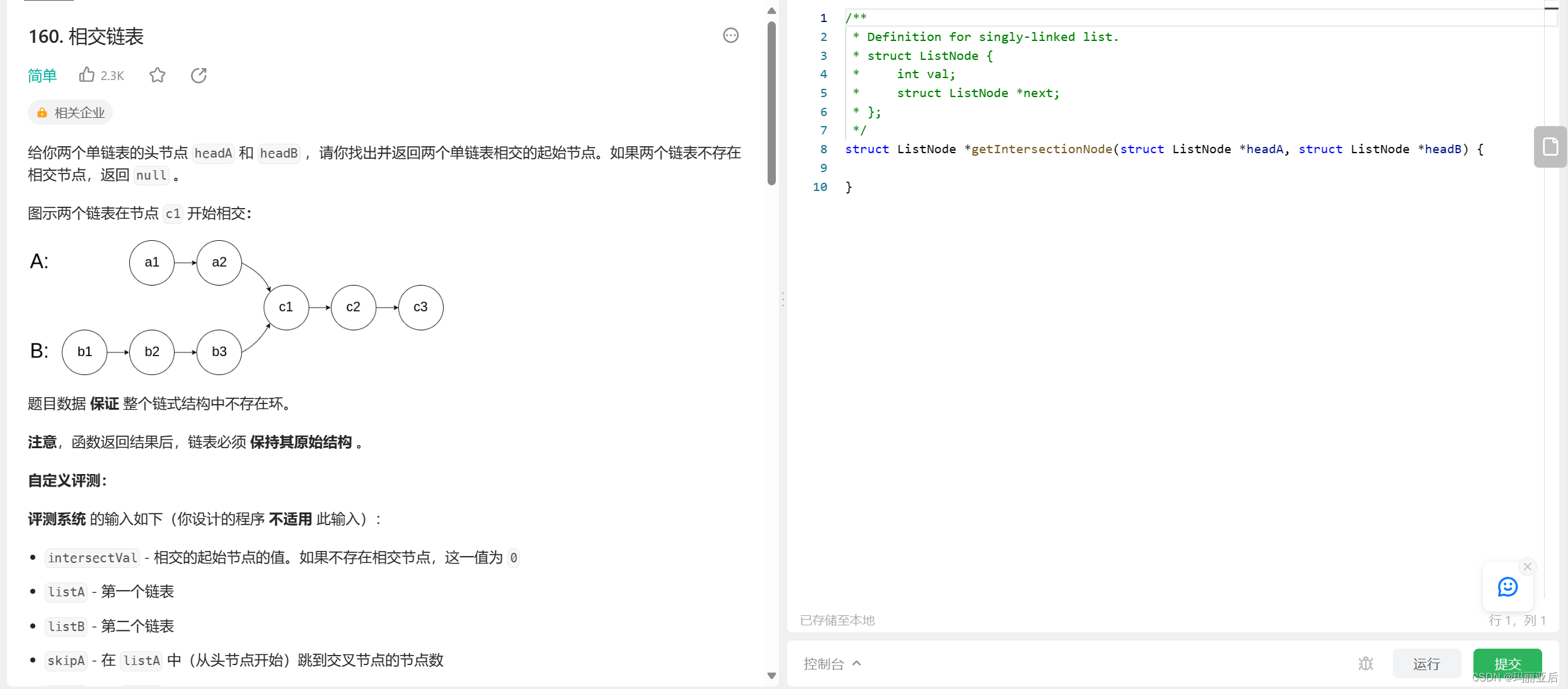
经典误区:
接下来我们应该如何来判断相交呢?——寻找尾节点。记住!比的是地址而不是数值,如果本来就相交,那么一定是共用一个地址的!数值相等的话并不意味着两个节点是同一个地址~
尾节点相等就说明相交。
真正麻烦的是如何找到相交的点~
一种思路是:暴力遍历,依次拿a的节点跟b所有的节点进行地址对比。时间复杂度O(N^2)
优化思路:在寻找交点的时候,想办法让两链表长度一致开始遍历对比。时间复杂度O(N)
运行代码:
struct ListNode* getIntersectionNode(struct ListNode* headA, struct ListNode* headB) { struct ListNode* curA = headA; struct ListNode* curB = headB; //题目说明链表不为空,而且设置为1也没事,反正我们只需要差值 int lenA = 1; int lenB = 1; //寻找尾节点看是否相交 while (curA->next) { lenA++; curA = curA->next; } while (curB->next) { lenB++; curB = curB->next; } if (curA!= curB) { return NULL; } //开始寻找第一个相交点 //先算绝对值 int gap = abs(lenA - lenB); struct ListNode* lonlist = headA;//假设A是长的 struct ListNode* shortlist = headB;//假设B是短的 if (lenA < lenB) { lonlist = headB; shortlist = headA; } //让长的提前走gap步 while (gap--) { lonlist = lonlist->next; } //长度一致时开始一一对比 while (lonlist != shortlist) { lonlist = lonlist->next; shortlist = shortlist->next; } return lonlist; }


十.环形链表
链接:141.环形链表

本题难点在于不清楚哪个节点是环内的,哪个节点是环外的。
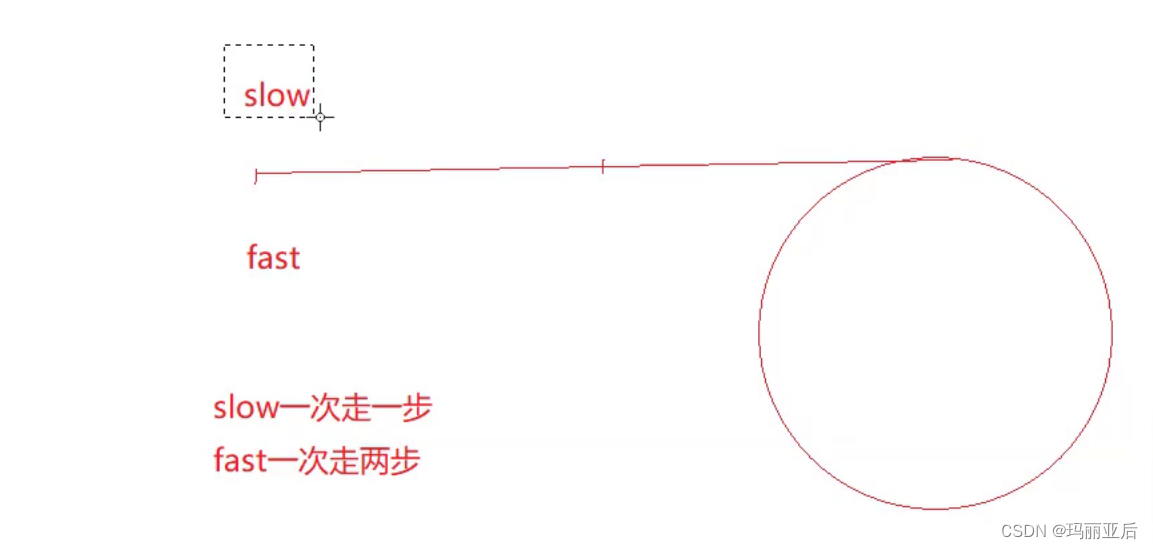
所以我们只能看是否会相遇,如果不是环是不会相遇的,而且fast只会走向尾节点。
运行代码:
bool hasCycle(struct ListNode* head) { struct ListNode* fast = head; struct ListNode* slow = head; //很关键的一步之所以设置两个条件,就是为了预防链表不为环的情况 //当链表奇数个节点时,用fast-next来跳出循环 //当链表偶数个节点时,用fast来跳出循环 while (fast && fast->next) { fast = fast->next->next; slow = slow->next; //如果是带环链表,那么迟早会相遇 if (fast == slow) { return true; } } //如果是不带环链表,那么fast或fast->next会到空节点,所以直接false return false; }

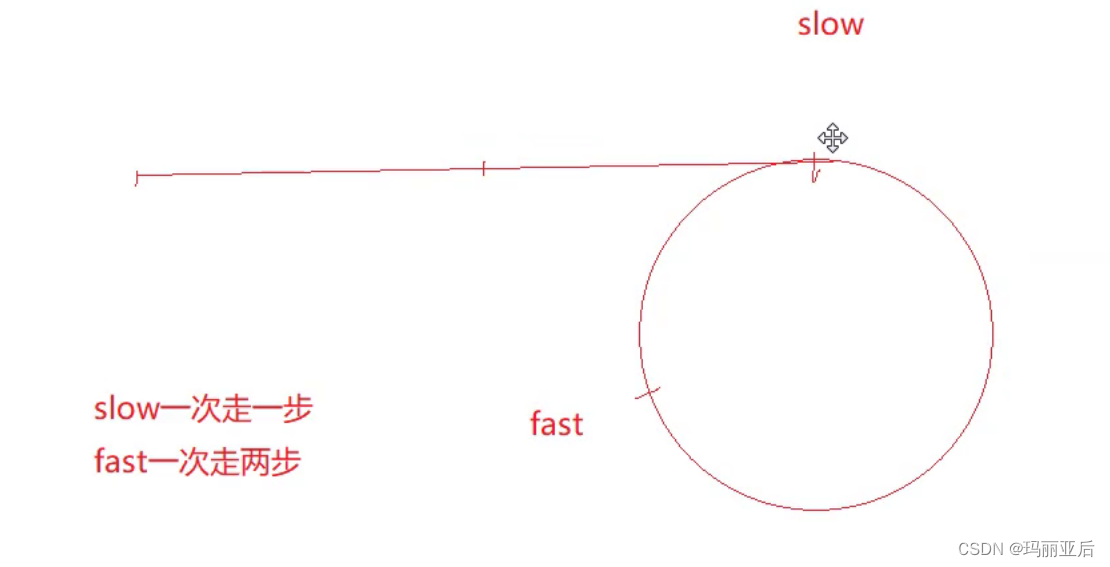

- 思考:
- 如果slow走1步,fast走2步,一定能追上吗?会不会错过了。
- 如果slow走1步,fast走n步(n>=3),一定能追上吗?会不会错过?
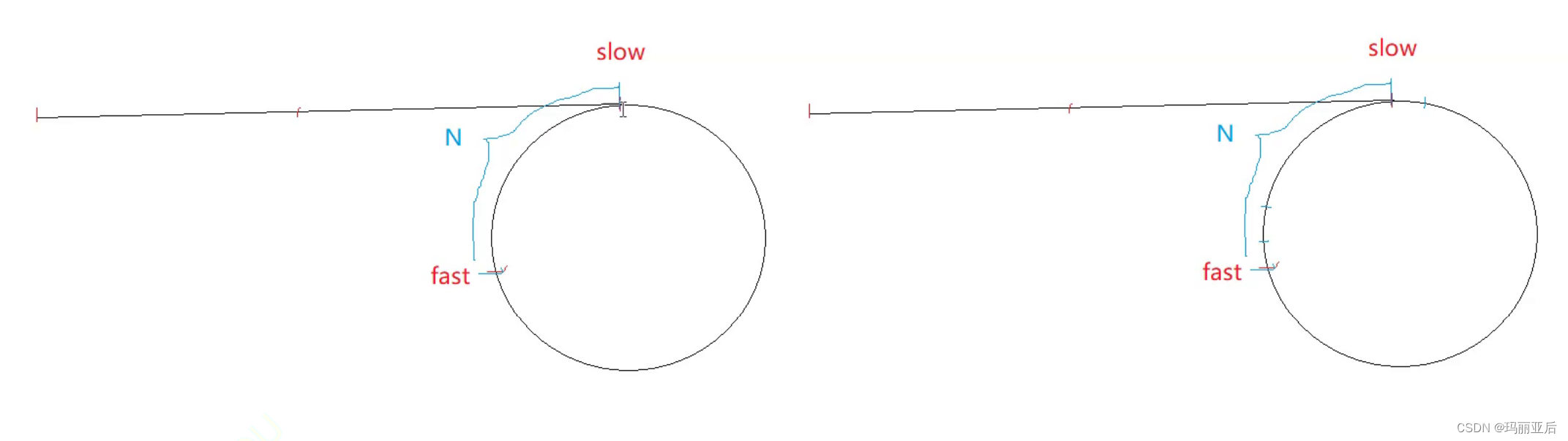


死循环
所以用快慢指针2步走的方法是最稳健的。多于3步的都是要考虑很多情况的。



十一.环形链表(二)
链接:142.环形链表(二)

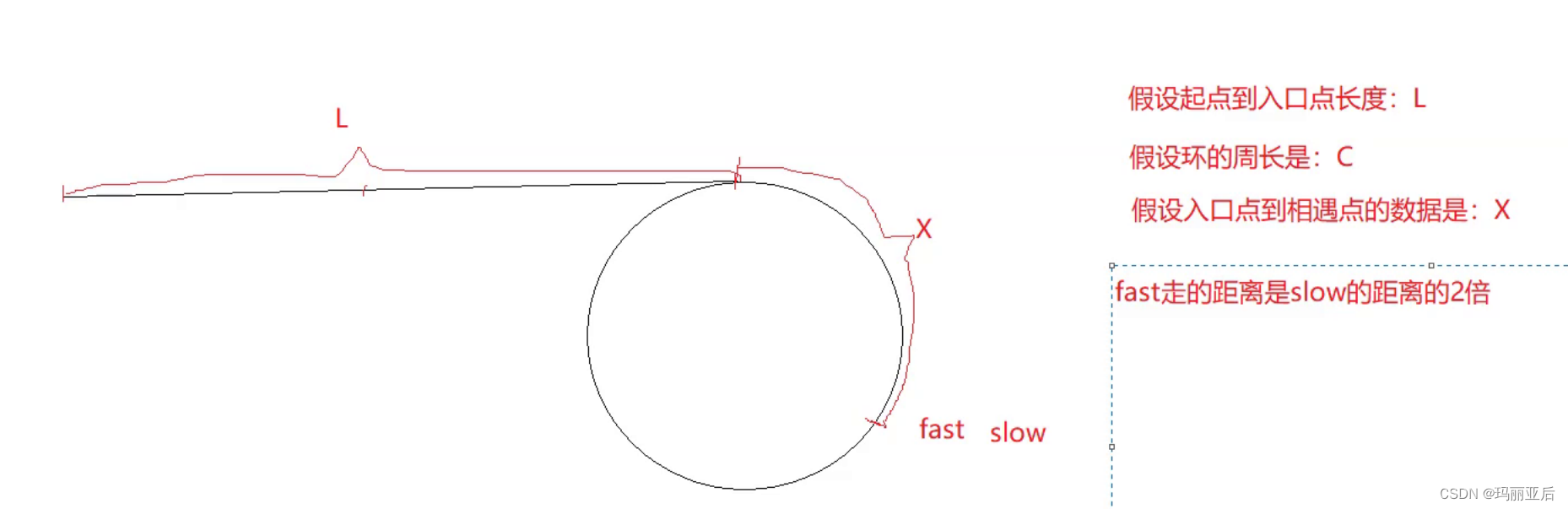
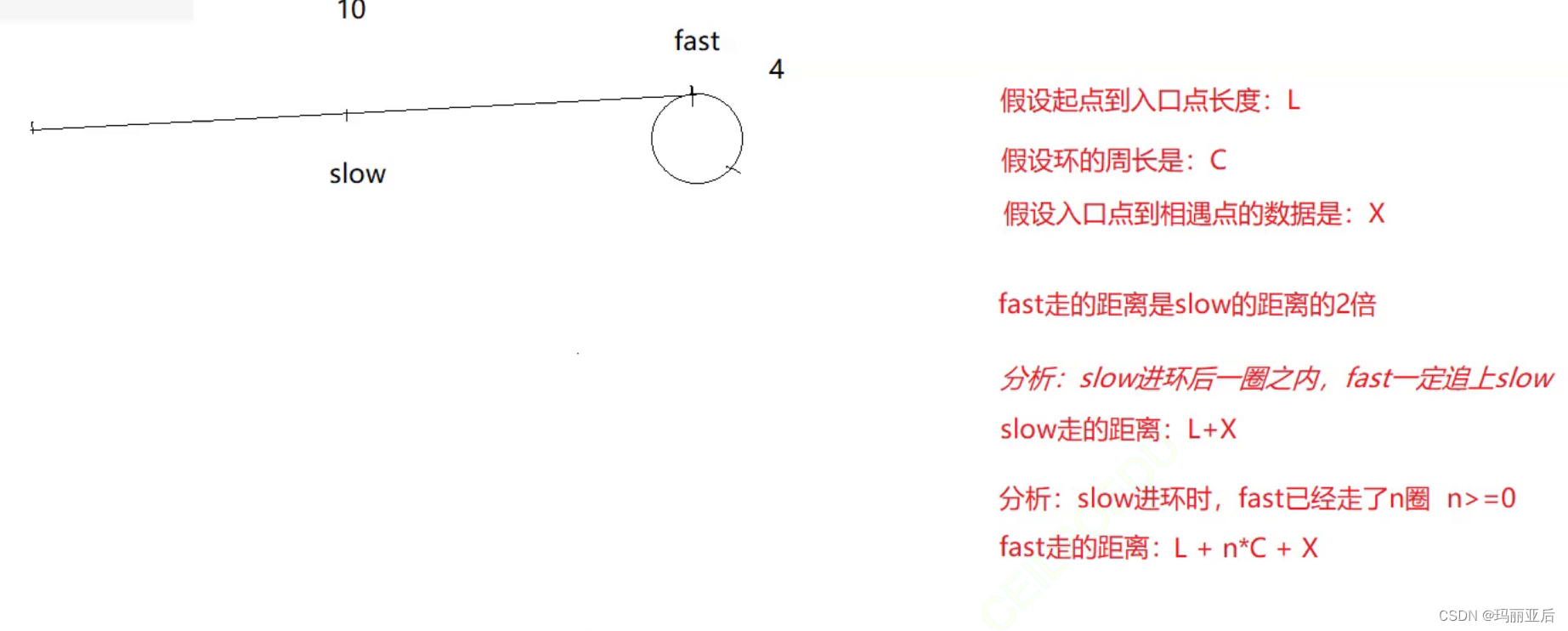
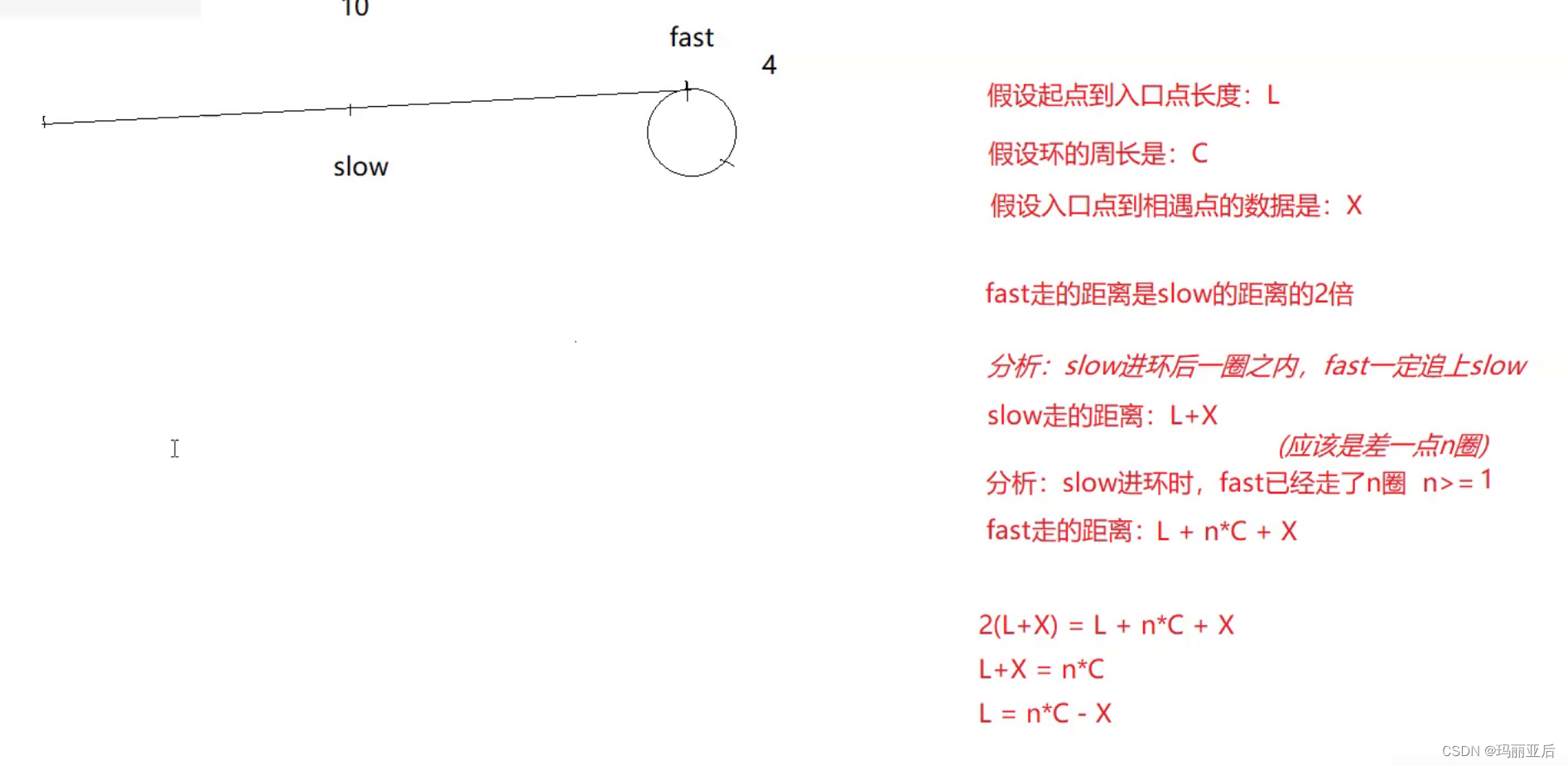
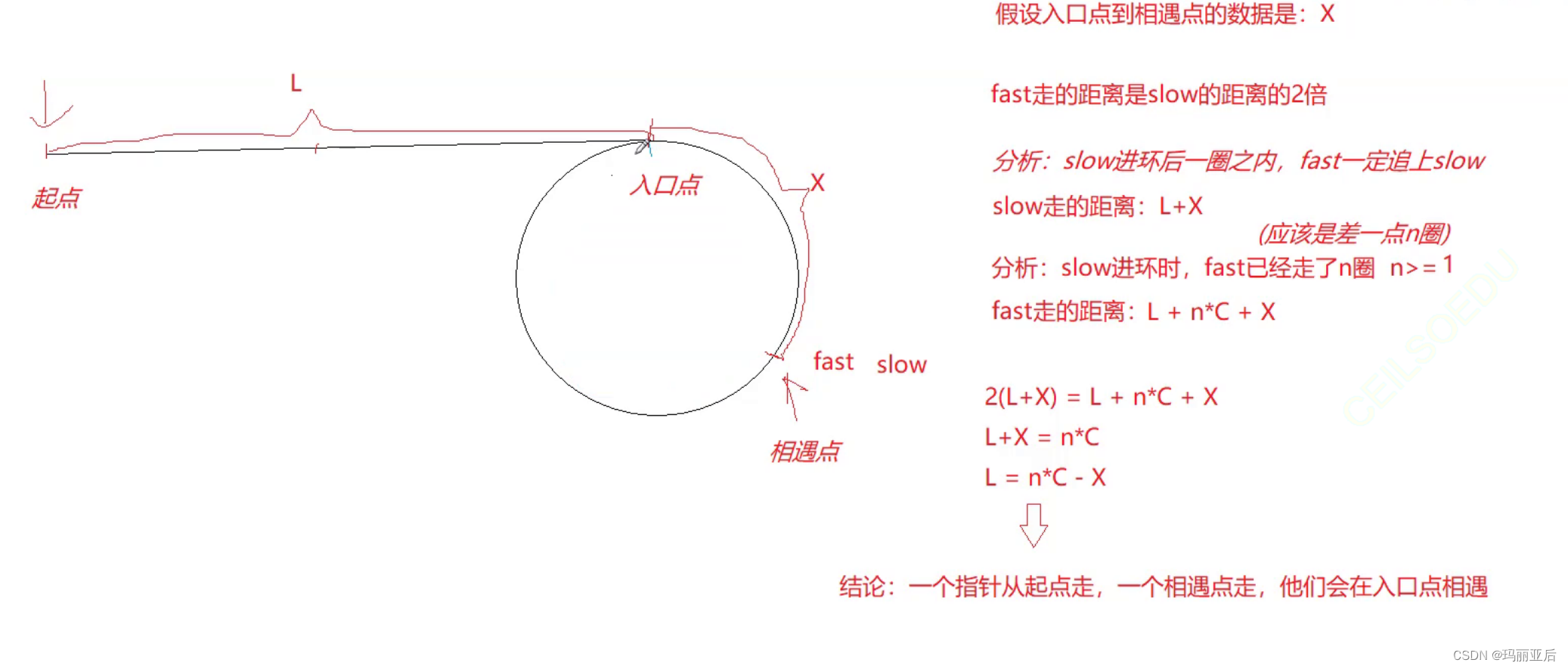
思路一:
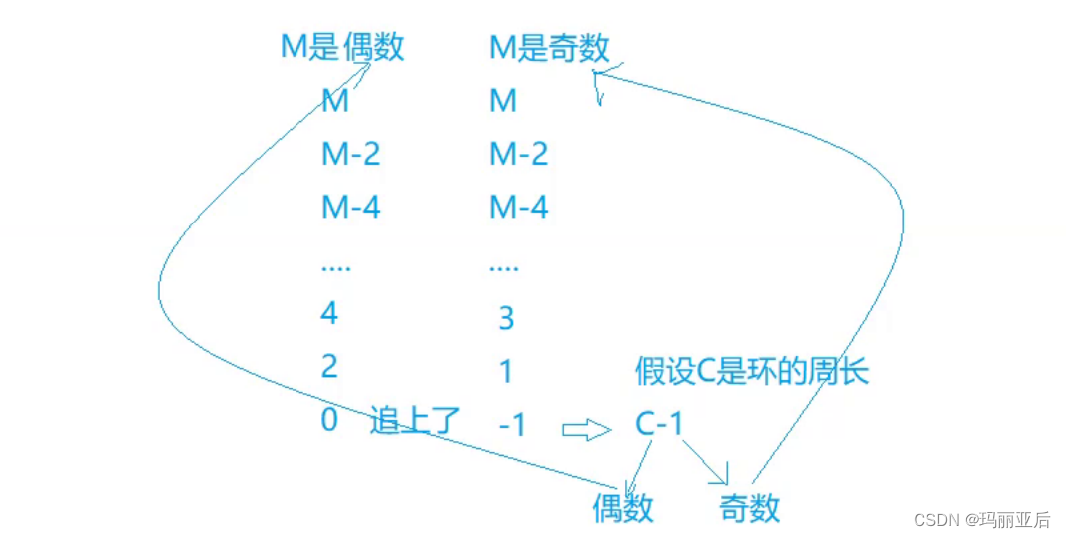
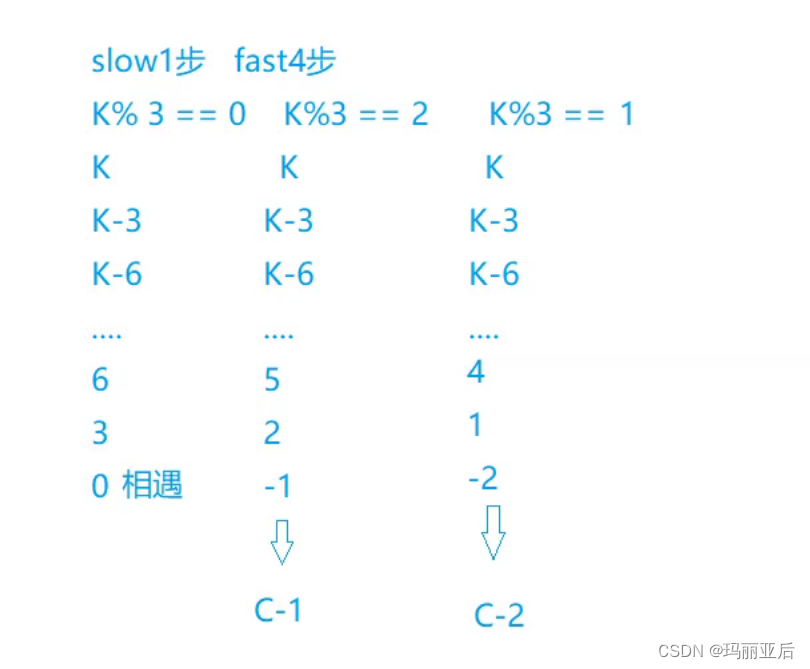
先假设它们在不断地追击
这里我们是否需要判断slow会多走一圈C(圈长)才会和fast相遇呢?——不需要,因为我们在分析走2的时候已经得出结论:它们不会错过。
如果是这样想那结果是经不起推敲的,漏洞百出。
当环很短,L很长的时候,那么L=C-X的公式是不成立的。
我们前面做了这么多的测试就是为了推出这个公式。
struct ListNode* detectCycle(struct ListNode* head) { struct ListNode* slow, * fast; slow = fast = head; while (fast && fast->next) { slow = slow->next; fast = fast->next->next; if (slow == fast) { struct ListNode* meet = slow; while (head != meet) { head = head->next; meet = meet->next; } return meet; } } return NULL; }因为在最后的meet和head相遇的原理就是 L = n*C-x,正是因为我们有这个公式,在后续才可以用whiel循环让head与meet重合找到第一个环入口点。
首先slow与fast相遇时slow从入口点到相遇点已经走过了x的距离,所以从相遇点开始走到入口点就需要C-X的距离,另外还得考虑到无法相遇时要多走的(n-1)C圈,但归根到底,二者相遇的地点一定是入口点,所以我们最后的总结就是让head等于meet即可,因为它们相当于 L(head) = (n*C-x)(meet)




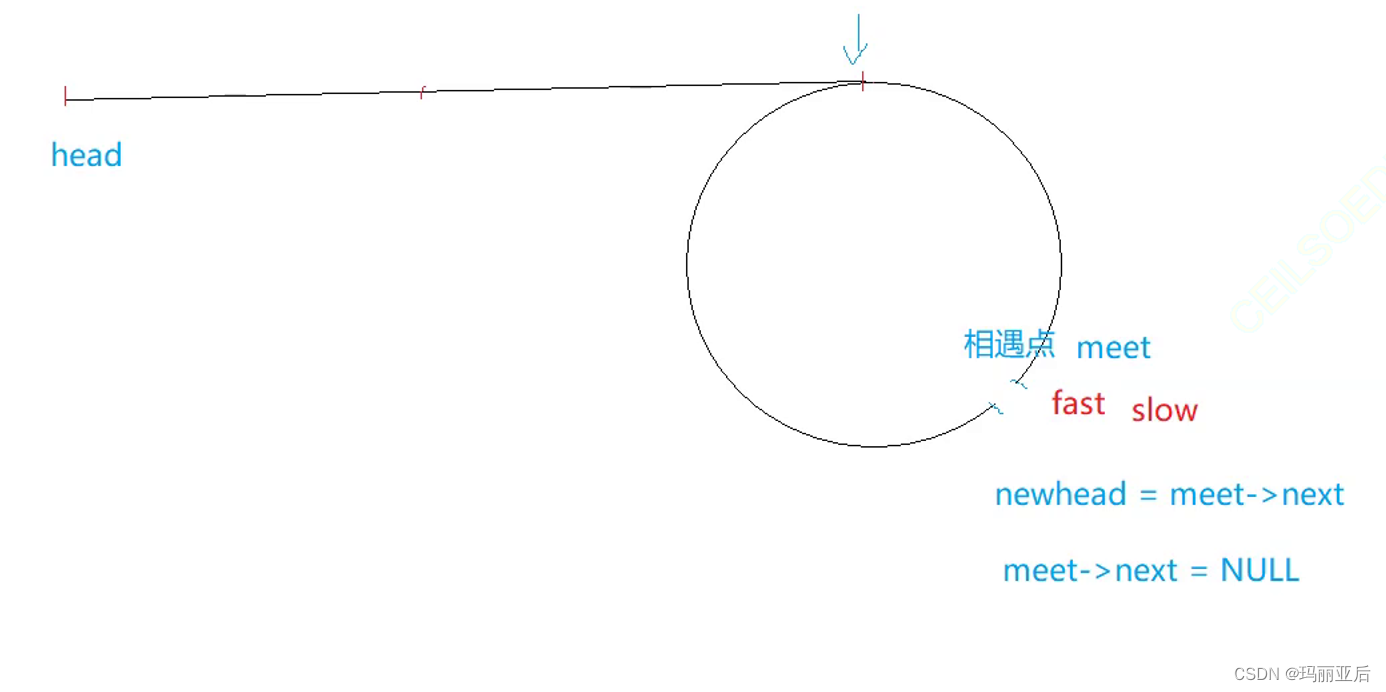
方法二:
把当前meet结点搞成尾,让newnode新结点变成头。
复制相交链表接口
一个从newnode开始走,一个从head开始走,找交点。
因为通过条件slow==fast可以得出只有环才可以相遇,那么接下来只需要找相交结点即可.
那我们又为什么要进行断尾呢?因为套用相交链表的前提是要用到尾部结点的,如果不主动断尾,就会陷入死循环。
struct ListNode* detectCycle(struct ListNode* head) { struct ListNode* slow, * fast; slow = fast = head; while (fast && fast->next) { slow = slow->next; fast = fast->next->next; if (slow == fast) { struct ListNode* meet = slow; struct ListNode* newnode = meet->next; meet->next = NULL; return getIntersectionNode(newnode, head); } } return NULL; }
 六.结语
六.结语
如果大家能够把这些经典的链表OJ题融会贯通,那你接下来关于链表的题型大部分都会迎刃而解的啦~最后感谢大家的观看,友友们能够学习到新的知识是额滴荣幸,期待我们下次相见~


![web:[GXYCTF2019]禁止套娃](https://img-blog.csdnimg.cn/02609482c9274d219e1fd798943d3dff.png)


![②【Hash】Redis常用数据类型:Hash [使用手册]](https://img-blog.csdnimg.cn/20a7f1b58dfb4660b75d7f021c157d57.png#pic_center)

![[Docker]七.配置 Docker 网络](https://img-blog.csdnimg.cn/0d6d61034d204cf09e0eaff795e5fcaa.png)