作者:李钰 - 阿里云资深技术专家、EMR 负责人
EMR 2.0 平台
阿里云正式发布云原生开源大数据平台EMR 2.0已历经一年时间,如今EMR 2.0全新平台在生产上已经全面落地,资源占比超过60%。EMR 2.0平台之所以在生产上这么快落地,源于其体验全面提升,更重要的一点是为客户实现了全面降本增效。
EMR 2.0 平台实现降本增效主要源于四个核心能力
极致弹性
EMR 2.0平台提供极致弹性的能力,主要表现在两个方面。第一是支持抢占式实例,客户可以指定使用抢占式实例的优先级,单节点组最多选择10种不同规格,成本优化策略支持自动选取低价实例规格出价,当抢占式实例不足的时候,会给客户补充按量付费的实例,兼顾成本和业务效果。第二就是极速响应能力,单节点组内和多节点组间均支持并行扩容,支持缩容期间并行扩容,支持突发业务变化;并且在响应能力上也有大幅提升,扩容速度不随着节点的增加而增加,100 节点扩容时间小于2分钟 ,弹性指标检测周期低于30秒,能够更好地响应负载变化;而且单次扩容规模能够达到1000个节点。

智能诊断
EMR 2.0平台具备智能诊断能力,通过EMR Doctor的集群日报和实时检测功能,可以实现避免资源浪费、风险提前预警和实时分析建议的核心效果:通过健康检查服务的集群日报功能查看集群是否存在资源浪费;通过任务评分倒排 Top N,找到资源浪费最多的作业进行优化;通过持续优化,最大化利用资源,避免浪费。

新硬件支持
EMR 2.0平台全面支持倚天 ECS 实例,相较X86实例成本降低20%以上。另外在软件层面、计算引擎层面,针对ARM的指令集也做了一系列优化,性能更高,CPU 占用率更低,在典型TPC-DS大数据 Benchmark 下能够进一步将性能提升1/4,意味着使用EMR2.0新平台加上倚天实例构建大数据集群,可以实现40%成本下降。

资源配比优化
EMR 2.0平台提供资源配比优化能力。虽然大数据负载具备动态性,但是在一定时间内也具备一定的周期性。EMR 2.0平台提供HBO能力,基于历史用量分析用量高峰低谷,推荐更低成本的预付费(包年包月固定资源)和后付费(按量弹性资源)配比。固定和弹性资源用量和账单可视化,历史用量曲线跟踪,更直观地度量资源配比调整前后成本绩效。

基于以上四个方面的优化,使用EMR 2.0平台的客户在生产上确确实实地实现了降本增效。EMR 团队也开始进一步思考以ECS集群方式构建大数据的解决方案是否存在难以解决的问题。
EMR 集群形态难以解决的问题?
有物理机运维经验的同学应该知道,当CPU和内存的使用率都超过70%时,整个集群的负载水位就很高了。所以在生产当中如果资源的综合使用率能够达到70%,就可以认为整个集群的资源使用率是比较高的。如果以70%的资源使用率为标准评判集群的资源是否利用得比较充分,则会观察到一个现象。10%的线上集群资源使用较为充分,有90%的集群资源利用率不到70%。另外观察到超过 3 成集群资源综合使用率不足 50%,而且没有明显的资源峰谷,只是日常综合的使用率。另外考虑到业务负载动态变化,以及集群形态对资源规划者能力要求极高,如果想在资源利用率上更进一步,全面 Serverless 化势在必行。基于以上背景,近一年阿里云EMR团队在Serverless化产品上取得了较大进展。

EMR Serverless 化产品

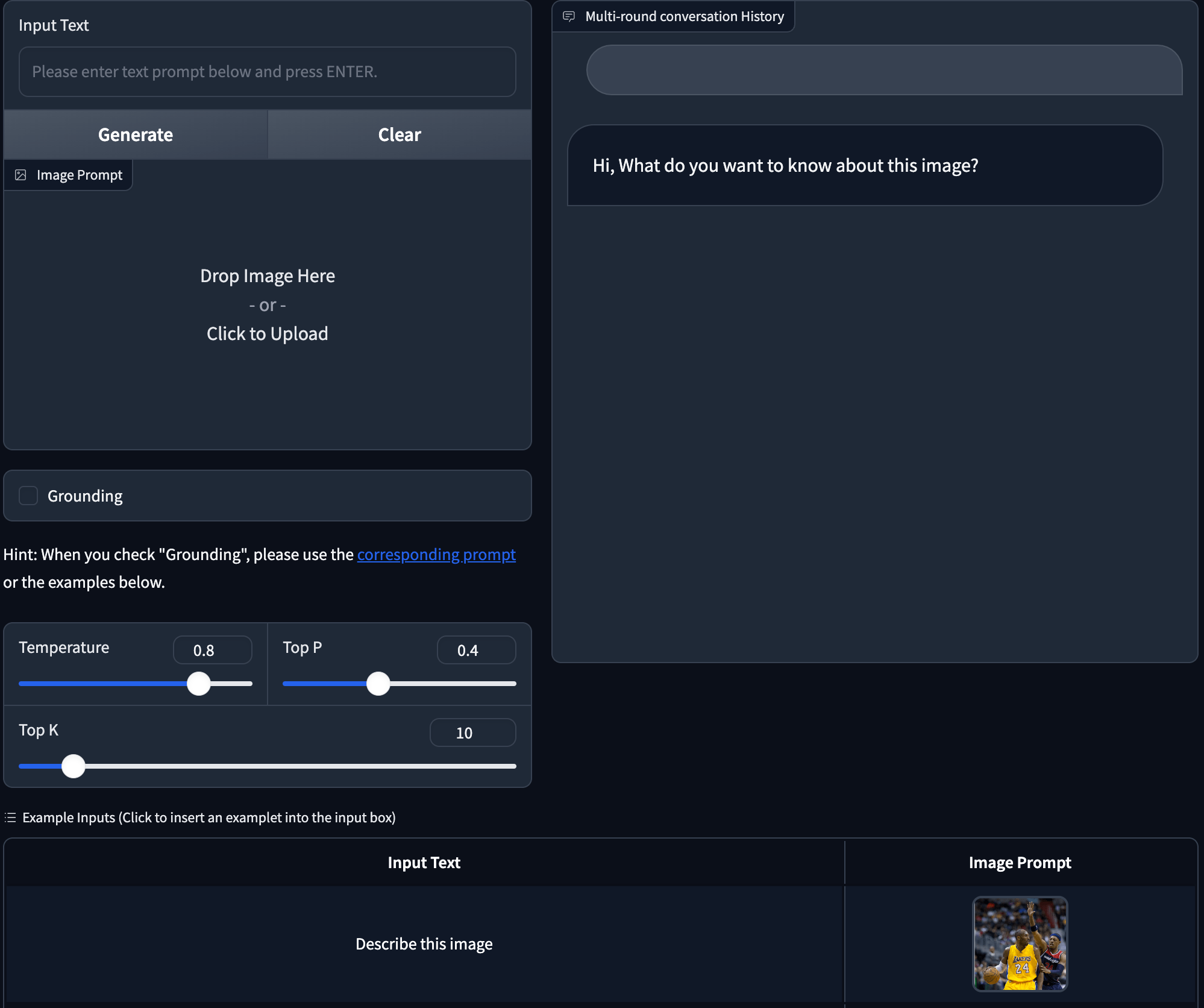
(阿里云EMR数据湖仓架构)
EMR Serverless Notebook
上图是阿里云EMR数据湖仓架构。首先看一下数据开发层,数据开发层分为开发和调度两方面。在数据开发方面EMR推出了Serverless Notebook,是一款即开即用免运维的产品,提供完善的用户权限和企业级的安全能力。用户可以开发SQL、Python等非常通用的Notebook作业。另外EMR Serverless Notebook 几乎全面兼容了HUE的能力,历史存量业务可以无缝迁移,还支持无缝对接各种形态的EMR集群。目前还在测试中,感兴趣的用户可以到EMR官网申请试用。

EMR Serverless Workflow
在数据工作流调度方面,EMR推出了Serverless Workflow。这款产品也是即开即用免运维的全托管产品,完全兼容Apache DolphinScheduler,也提供用户权限和企业级的安全能力。另外还可以随着调度负载的增加和减少提供弹性伸缩的能力,可以无缝对接各种形态的EMR集群,支持包括Spark、Flink在内的各种大数据作业开发,感兴趣的用户可以在EMR工作台直接开通测试。

接下来看一下计算层,我们通常将大数据的计算分为三类,批处理、流处理和Olap交互式分析。流处理主流产品是Flink,阿里云对应推出了实时计算Flink版产品。EMR则在批处理和Olap两个方向分别推出了对应的产品。
EMR Serverless Spark
- 一站式数据开发平台
EMR Serverless Spark 提供了一站式数据开发平台,在这个一站式数据开发平台上面,用户可以便捷地开发SQL作业,也可以很方便地进行试运行和调试,调试完成后支持一键上线及发布,同时还提供内置工作流编排能力,用户可以基于已经开发好的SQL作业来编排工作流,并且在工作流上做定时调度,当工作流编排调度好了之后还提供工作流和任务两个维度且比较完善的监控和运维能力。用户可以在工作流维度上看到工作流每次运行的状态,例如运行到哪个节点失败,点击失败的节点可以看到失败的原因。此外还支持智能诊断,比如Spark作业有数据倾斜或者某个并发数据GC的问题,智能诊断能力可以帮助用户更快地解决问题。

- 企业级 Native 引擎
除了一站式数据开发平台,EMR Serverless Spark 在内核上也做了优化。首先是企业级Native引擎优化,基于Native算子及SIMDJson优化的向量化执行引擎;支持高性能列式的Shuffle,可以将Shuffle的数据量最多减少40%;面向不同指令集做的指令集粒度优化,包括zstd等比较先进的压缩、解压缩算法的优化;最后还提供原生的C++接口来对接湖格式、OSS—HDFS存储,从而提供端到端完整的高性能。下图左侧是EMR Native Engine 和 Apache Spark3.3在TPC-DS 10TB这个benchmark上的对比,可以看到企业级Native引擎可以达到开源引擎3倍以上的性能。

- 企业级 RSS 支持
EMR Serverless Spark 提供企业级 RSS 支持。众所周知,批处理云原生和Serverless化需要将本地的状态和存储依赖去掉,就要把ESS转换成使用Remote shuffle service。EMR Serverless Spark 提供的企业级 RSS 支持是基于Apache Celeborn 的,也是阿里云EMR团队捐赠给 Apache 孵化器的一款 RSS 软件,目前在整个生态上面有非常多国内外公司在使用,包括国外的 Linkedin、Shopee,国内的网易、哔哩哔哩。EMR Serverless Spark 在完全兼容Celeborn的基础上,还提供了企业级多租户能力,支持企业级的安全隔离。另外依托于阿里内部的生产实践,在大规模、高性能和全面功能性上都做了完整的提升。下图左侧就是Remote Shulffe Service相比于ESS的性能对比情况,可以看到有非常明显的提升。

- 按量付费&极致弹性
此外,EMR Serverless Spark 支持按量付费和极致弹性。全新的按量计费方式,打破了传统的按规格计费方式,根据计算资源和存储空间的实际使用量计费,计算资源以CU为单位,1个CU性能等于 1 Core CPU 4 GB Mem。在同样规则的情况下,Serverless 可以更好地响应负载变化,成本节省高达50%!

EMR Serverlesss StarRocks
EMR Serverlesss StarRocks 已经正式商业化,除了有一站式应用的开发平台之外,还能够全面覆盖数据湖分析的各种场景,另外还具备企业级内核能力和云原生能力。

- 企业级 StarRoks Manager 管控
EMR Serverless StarRocks 提供企业级 StarRocks manager 管控,不仅支持实例级别管理和监控,还可以做一站式SQL开发查询,支持慢 SQL Profile 查询分析,另外还提供智能诊断分析能力,帮助用户更方便地使用 StarRocks。

- 企业级数据湖分析场景支持
EMR Serverless StarRocks 在数据湖分析场景的支持也非常完善。一方面支持数据湖查询加速,另一方面在传统数仓分层ETL的场景下,作为ADS层的Olap引擎,同时也支持DWD和DWS层的查询加速。EMR Serverless StarRocks 在企业级数据湖分析场景做到按需秒级弹性,0负载0成本,提供全面的负载分析和诊断分析;通过内核优化实现了相比于开源Trino3—5倍的提升,支持 Trino 兼容以及一键迁移,另外在 Benchmark测试下性能显著优于开源的ClickHouse和Apache Doris;另外在查询加速方面,针对缓存管理也做了增强,企业级外表物化视图,可有效实现湖仓分层,企业级缓存管理模块,支持配置热表,热分区等淘汰策略,可根据业务场景平衡性能与成本。

- 企业级物化视图ELT场景支持
EMR Serverless StarRocks 提供企业级物化视图ELT场景支持。当数据量没有那么大的时候,可以用 StarRocks 处理所有 Pipeline,极大地加速整个业务流程。EMR Serverless StarRocks 通过大量算子 Spill 特性优化,提供企业级 MPP ETL 模式,确保了高稳定性,同时利用 VVP CTAS / CDAS 能力打造了全链路实时数仓;完善的 Data Sink Connector,支持多种湖格式,基于 DataLake 的 ELT 全链路,一站式读写和加工湖数据;此外,后续还会推出视图血缘功能,提供企业级物化视图血缘关系,可以更方便地构建实时数仓,还可以基于历史信息优化,推荐更完善、性能更好、更稳定的物化视图,帮助用户在ELT场景下更好地支撑业务。

- 存算分离&极致弹性
除了能够全面地支撑数据湖分析场景之外,EMR Serverless StarRocks 还支持企业级的存算分离和极致弹性能力。在存算分离架构下,基于底层的OSS数据湖存储在极大地降低存储成本的同时,还能够保证很高的数据可靠性;另外多 Data WareHouse 场景可以基于同一份物理数据创建两个 Virtual Data Warehouse,一个用于扫表,一个用于高维查询,两个Warehouse 有各自的缓存策略,对于业务隔离和SLA保障有非常好的提升;另外在性能上,依托于EMR Serverless StarRocks 企业级缓存能力,在缓存打开的时候性能和存算一体基本持平,当缓存不命中的情况下,查询性能也较为可控。

数据湖管理 DLF 重磅升级
- 统一元数据管理
首先在元数据管理方面,DLF 有2.5倍性能提升,单表支持500万分区;推出了全面兼容HMS功能,也就是Hive MetaStore的能力。
- 统一权限管理
中心化权限管理方面,全面兼容 Ranger 鉴权,全面支持访问审计,还支持对接 LDAP;全场景权限检查方面,支持 Hive/Spark 表鉴权, 支持文件目录鉴权,另外还可以对接 EMR 全系列产品组件。
- 统一数据治理
在数据治理方面也做了很多工作。在生命周期管理方面,支持全面分析访问日志、访问时间,智能识别数据冷热,允许指定规则,智能执行冷热分层和归档,较好地节约成本;湖表格式加速方面也全面支持湖表格式加速,全面覆盖 Paimon、Delta、Hudi、 Iceberg 等常用湖格式。
- 在线平滑迁移
DLF 支持HMS 迁移、支持 HDFS、S3 迁移 、支持双跑校验比对;支持 HDFS 透明协议代理。实现在线平滑迁移,不影响在线应用,无需修改业务,在数据迁移过程中和迁移之后可以做双跑数据对比校验,没有数据损害。

数据湖存储 OSS-HDFS 全面升级
数据湖存储 OSS-HDFS 也做了全面升级,目前在线上已经有超过1000个客户,服务存储量超过100PB。
- 大幅提升性能
元数据访问性能提升了2倍以上,对于某些特定的操作,性能提升能够达到10倍。IO 访问支持智能预读,请求数减少 20%+,支持高效并发,CPU 使用降低 30%+。
- 多举措降低成本
全面支持 OSS 归档能力,新增支持冷归档和深冷归档,支持归档直读,无须回转;对于分层存储和归档数据也有完善管理,支持无限制目录级/分区级归档,支持目录 Access Time,高效识别数据冷热。
- 全方位数据保护
对 Kerberos 认证、Ranger鉴权、审计日志、数据清单功能进行全面安全支持,另外还提供目录保护的能力,支持指定目录保护,避免误删,对于回收站的清理策略也支持更细粒度的管理。
- 全面开源生态兼容
全面兼容HDFS,兼容 HDFS 接口、支持 HDFS 二进制协议兼容、支持 HDFS 命令;另外还支持 fsimage 导出 。

最后,阿里云 EMR 团队也在规划全托管数据湖缓存加速,预计明年4月份会和大家见面,欢迎关注。