在K8S中,最小运行单位为POD,它是一个逻辑概念,其实是一组共享了某些资源的容器组。POD是能运行多个容器的,Pod 里的所有容器,共享的是同一个 Network Namespace,并且可以声明共享同一个 Volume。在POD中能够hold住网络和存储资源的容器就是,pause容器,它是一个一直循环运行的容器。
首先我们要搞清楚K8S有哪些资源,可以看看下面定义
| 类别 | 名称 |
|---|---|
| 工作负载型 | Pod Replicaset ReplicationController Deployments StatefulSets Daemonset Job CronJob |
| 服务发现及负载均衡 | Service Ingress |
| 配置与存储 | Volume、Persistent Volume、CSl 、 configmap、 secret |
| 集群资源 | Namespace Node Role ClusterRole RoleBinding ClusterRoleBinding |
| 元数据资源 | HPA PodTemplate LimitRang |
用户一般不直接操作POD,而是通过控制器来,在上面的表格中,我主要操作的对象就是Replicaset,Deployments ,DaemonSet,Job,Cronjob,StatefulSet.现在我们分别说说这些控制器的应用场景吧。
Replicaset:代用户创建指定数量的pod副本数量,确保pod副本数量符合预期状态,并且支持滚动式自动扩容和缩容功能。但是现在基本被Deployments 取代了.
Deployment:工作在ReplicaSet之上,用于管理无状态应用,目前来说最好的控制器。支持滚动更新和回滚功能,还提供声明式配置。
DaemonSet:用于确保集群中的每一个节点只运行特定的pod副本,通常用于实现系统级后台任务。比如在Calico中的Agent就是用DaemonSet方式运行。DaemonSet是直接共享宿主机的网络,还有hostAliases,HostNetwork,hostPID,hostname这些资源的
Job:只要完成就立即退出,不需要重启或重建。这个用于一次性运行,比如大数据中的统计执行任务,运行完成了就不用去管了。
Cronjob:周期性任务控制,像Linux中crontab,在某一个时间定时运行程序
StatefulSet:管理有状态应用,比如数据库基本都是有状态应用的,你数据保存在指定的节点,那么下次运行时就必须在这个节点去运行,这样就是有状态的了。
Deployment为Pod和Replica Set(下一代Replication Controller)提供声明式更新,现在我们来创建一个简单的Deployment来运行测试。Deployment.yaml范例文件如下:
apiVersion: apps/v1 #aip版本信息
kind: Deployment #资源类型
metadata: #元数据定义
name: myapp-deploy #资源的名称
namespace: default #资源的命名空间,这里是default
spec: #资源的规格
replicas: 3 #副本数,这里是3个
selector: #标签选择器,这里是去找相应的pod标签
matchLabels: #匹配哪些标签
app: myapp #第一个条件是app=myapp
release: canary #第二个条件是release=canary
template: #pod的模板定义
metadata: #pod的元数据定义
labels: #pod的标签属性
app: myapp #pod的一个标签属性
release: canary #pod的第二个标签属性
spec: #pod的规格定义
containers: #容器定义
- name: myapp #容器的名称
image: ikubernetes/myapp:v2 #容器的镜像
ports: #容器暴露端口
- name: http #端口名称
containerPort: 80 #端口号
在编辑好上面的deployment的yaml文件后,我们来创建它。
kubectl app -f Deployment.yaml

通过kubectl get deploy,kubectl get pods --show-labels 我们可以查看到已经创建了三个副本的myapp-deploy的deployment资源。我们通过上图中的get pods可以获得三个副本的IP地址,由于pod是开放了容器的80端口。我们直接访问可以获得相关内容。
curl 10.42.1.8

Deployment资源对象是可以进行回滚的,它有一个属性revisionHistoryLimit,是一个可选配置项,用来指定可以保留的旧的ReplicaSet数量,默认保存记录10个。该理想值取决于心Deployment的频率和稳定性。如果该值没有设置的话,默认所有旧的Replicaset或会被保留,将资源存储在etcd中,是用kubectl get rs查看输出。每个Deployment的该配置都保存在ReplicaSet中,然而,一旦删除的旧的RepelicaSet,Deployment就无法再回退到那个revison了。
如果将该值设置为0,所有具有0个replica的ReplicaSet都会被删除。在这种情况下,新的Deployment rollout无法撤销,因为revision history都被清理掉了。可以通过descirbe详细看看deployment当前的配置,我们可以看到当前的更新策略是StrategyType:RollingUpdate是滚动更新策略,它还有一个策略是Recreate: 重建式更新,就是删一个建一个。类似于ReplicaSet的更新方式,即首先删除现有的Pod对象,然后由控制器基于新模板重新创建新版本资源对象。
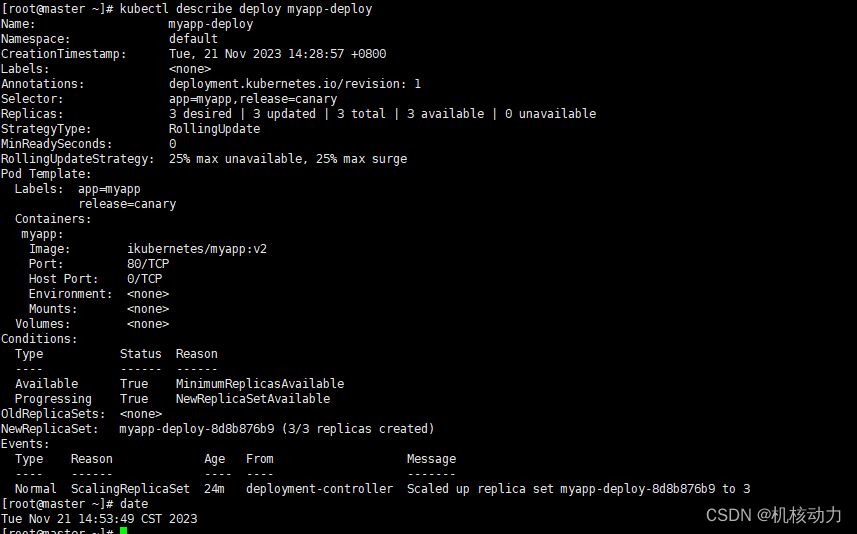
现在我们通过修改Deployment.yaml文件来进行版本升级。升级的版本配置如下,我们把镜像版本改成v1然后升级deployment.
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: myapp
release: canary
template:
metadata:
labels:
app: myapp
release: canary
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
ports:
- name: http
containerPort: 80
下面可以看到整个deployment升级过程,是停止一台,升级一台的这种循环。
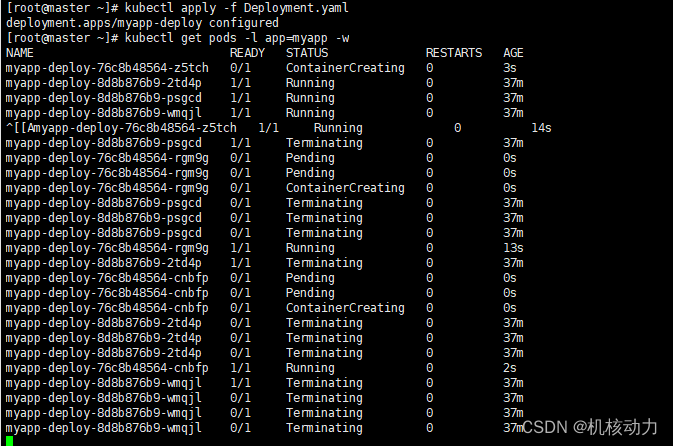

以下可以看到原的rs作为备份,而现在是启动新的rs

通过kubectl rollout history deployment myapp-deployment 查看有多少个历史版本

现在我们可以回滚回原来的版本,也就是V2的版本,用如下命令
kubectl rollout undo deployment myapp-deploy


当然也可以通过如下指令,回到指定的版本,比如:
#回滚到第一个版本
kubectl rollout undo deployment myapp-deploy --to-revision=1
当然也可以通过命令的方式升级pod镜像,
kubectl set image deployment/myapp-deploy myapp=ikubernetes/myapp:v2
使用以下命令扩容 Deployment
kubectl scale deployment myapp-deploy --replicas 5
#通过打补丁的方式进行扩容:
kubectl patch deployment myapp-deploy -p '{"spec":{"replicas":5}}'
通过打补丁的方式进行修改更新策略
kubectl patch deployment myapp-deploy -p '{"spec":{"strategy":{"rollingupdate":{"maxsurge":1,"maxUnavailable":0}}}}'
金丝雀发布也就是灰度更新。
#设置maxSurge:1,maxUnavailable=0
kubectl set image deployment myapp-deploy myapp=ikubernetes/myapp:v3 && kubectl rollout pause deployment myapp-deploy
#观察更新状态
kubectl rollout status deployments myapp-deploy
#如果更新的节点没问题,然后resume继续剩下的更新
kubectl rollout resume deployment myapp-deploy
#查看最后的更新情况
kubectl get pods -l app=myapp -w