背景
随着openai发布的chatgpt,各界掀起大模型热. 微软、谷歌、百度、阿里等大厂纷纷拥抱人工智能, 表示人工智能将是下一个风口.确实, chatgpt的表现确实出乎大部分的意料之外,网上也不断流传出来,chatgpt未来会替换很多白领.作为一名普通的程序员,觉得非常有必要随波逐流一下,但是最新的openai的模型并不是开源的,说实话,不开源,大部分人在大模型肯定是望而却步,另一方面,大部分模型都是亿级别以上的参数,单单部署方面,硬件要求都已经与大部人无缘了.此时或许有人问,为啥不能直接用openai或者其他大公司的产品,自己还要重复造轮子,主要有2个原因:1是如果只是会用,但是不了解过程,不是程序员的初心,2是很多企业不允许将公司内部资料直接开放给公网平台.但是作为一名屌丝平民,还是感谢IT业的资源共享,找到一些曲线救国的方法.
曲线救国的方法:
如果自己要私有部署一个知识库大模型,至少需要以下的条件.
1、训练好模型,: 虽然openapi没有对最新模型开源, 互联网也有开源一些
https://zhuanlan.zhihu.com/p/618790279
虽然比不上chatgpt3.5或者4,但是自己玩玩也是足够了
2、部署的硬件条件: 如果自己购买,绝对是一笔不小的开支, 还好有其他大公司的慷慨解囊.
https://zhuanlan.zhihu.com/p/651649338
3、基本计算机知识: 确实很扎心, 要完成个人知识库搭建,还是需要基本计算机知识.
小结: 接下来我就结合Langchain-ChatChat和阿里云的PAI—DSW 分享一下自己部署的历程.
实践
1、准备好阿里云的GPU资源(时间有点长)
部分参考基于阿里云免费算力自建LLM(类GPT)大模型文章
不需要参考的部分
选择镜像的时候,不要选择自带的官方镜像,而是要使用https://github.com/chatchat-space/Langchain-Chatchat中推荐的容器镜像,因为这个开源代码对软件(特别是CUDA版本有要求)

docker.m.daocloud.io/nvidia/cuda:12.1.1-cudnn8-runtime-ubuntu22.04 (为了加快拉取外网的镜像)
注意:这个镜像比较大,所以可以在吃饭的中去部署这个环境

注意:不用就停止掉,不然浪费你的资源额度,好像有15天的过期时间,如果15内不启动这个服务器,磁盘会被回收的,数据都没有了,就要重新进行下面安装步骤
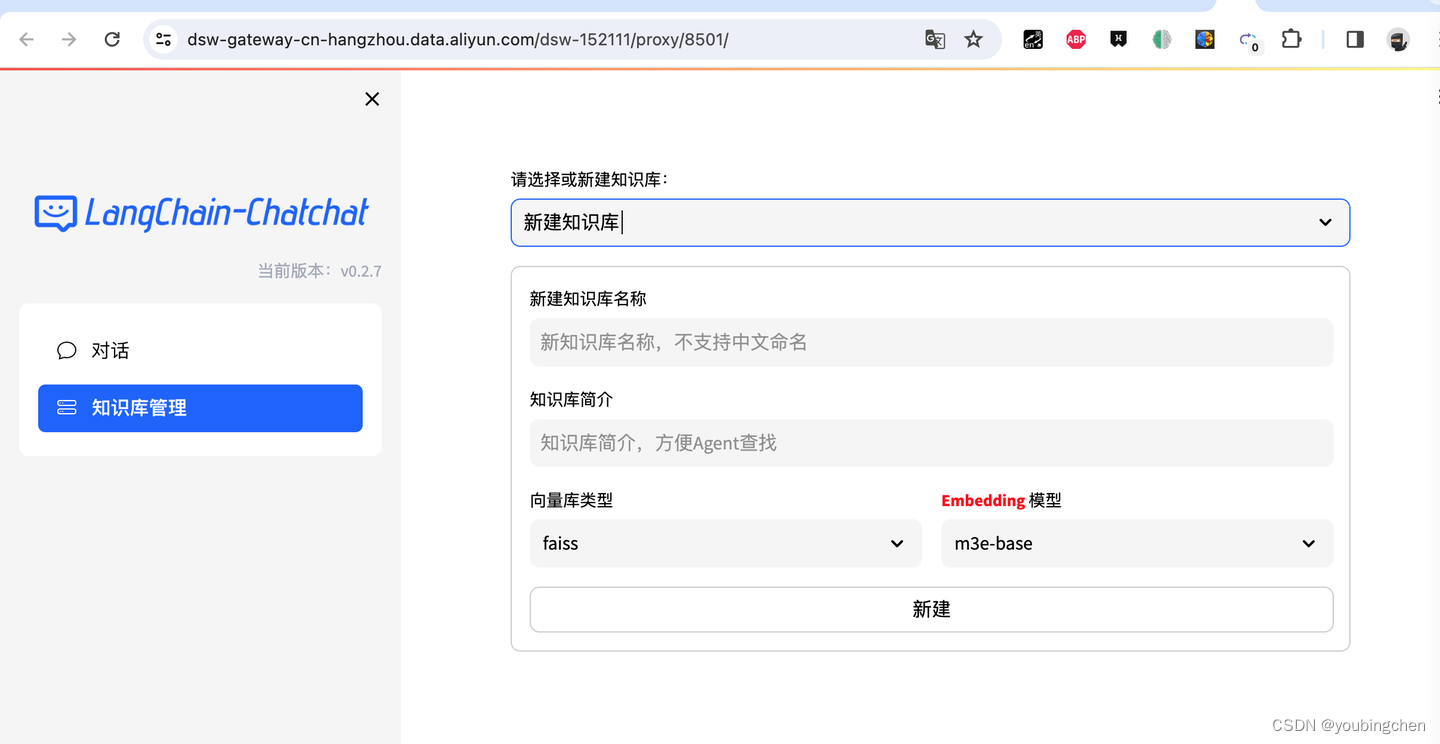
2、安装chat-chat
参考REAME.md
github.com/chatchat-space/Langchain-Chatchat
不能参考部分:
(1)注意: 因为使用nvidai的基础镜像,所以git 、curl环境都没安装,所以可以使用谷歌一下ubuntu安装python3.10 git curl git lfs等工具.
(2)README.md中的第二步模型下载,不用使用huggingface.co(网络不通)
$ git clone https://huggingface.co/THUDM/chatglm2-6b 不要掉
换成:
mkdir THUDM
cd THUDM
git clone https://www.modelscope.cn/ZhipuAI/chatglm2-6b.git
cd …
$ git clone https://huggingface.co/moka-ai/m3e-base 不要掉
换成:
mkdir moka-ai
cd moka-ai
git clone https://www.modelscope.cn/thomas/m3e-base.git
cd …
(3)最好后台启动服务
nohup python3.10 startup.py -a > chat.log 2>&1 &
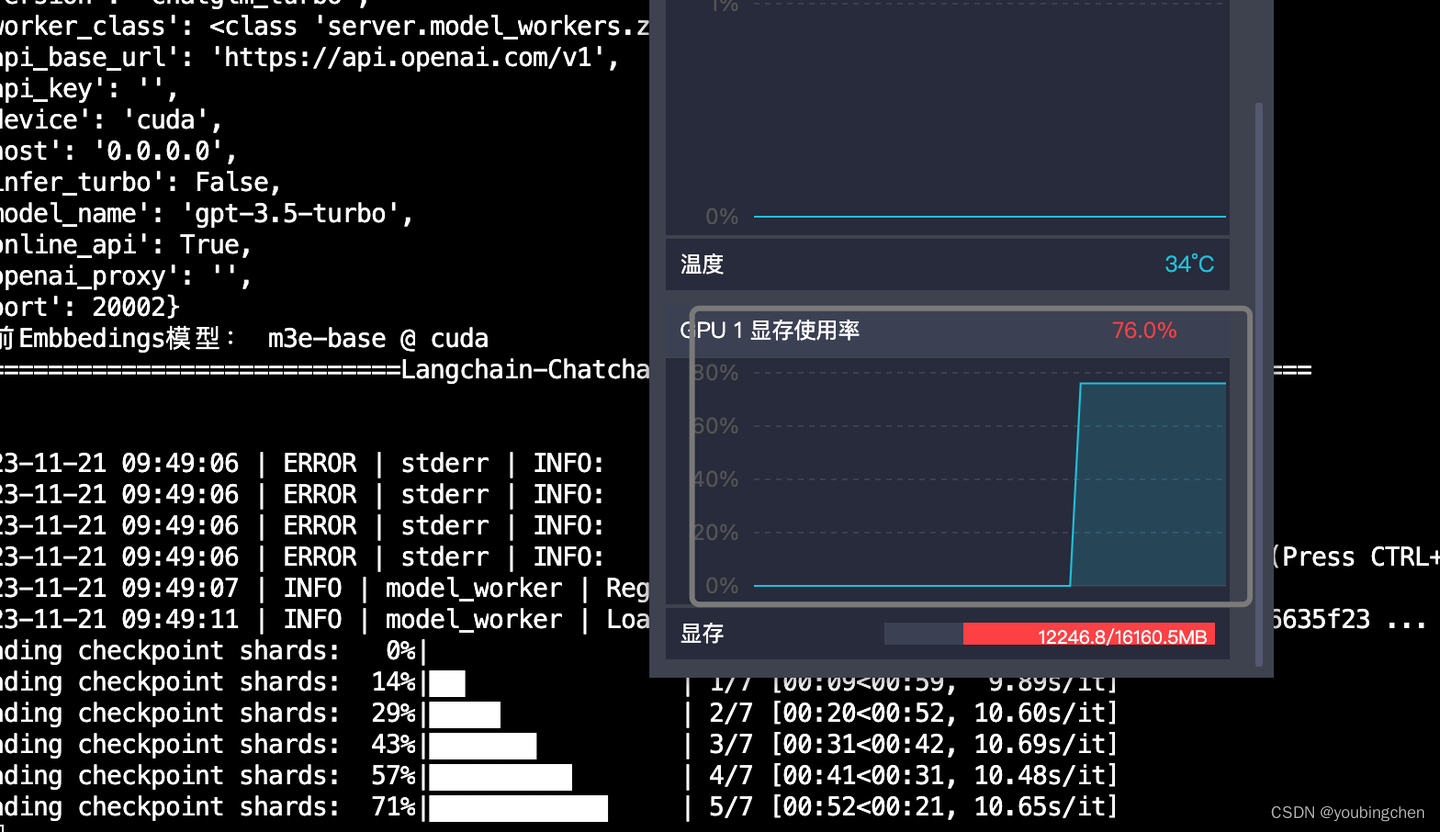
启动完成后, 点击一下chat.log日志中的url:
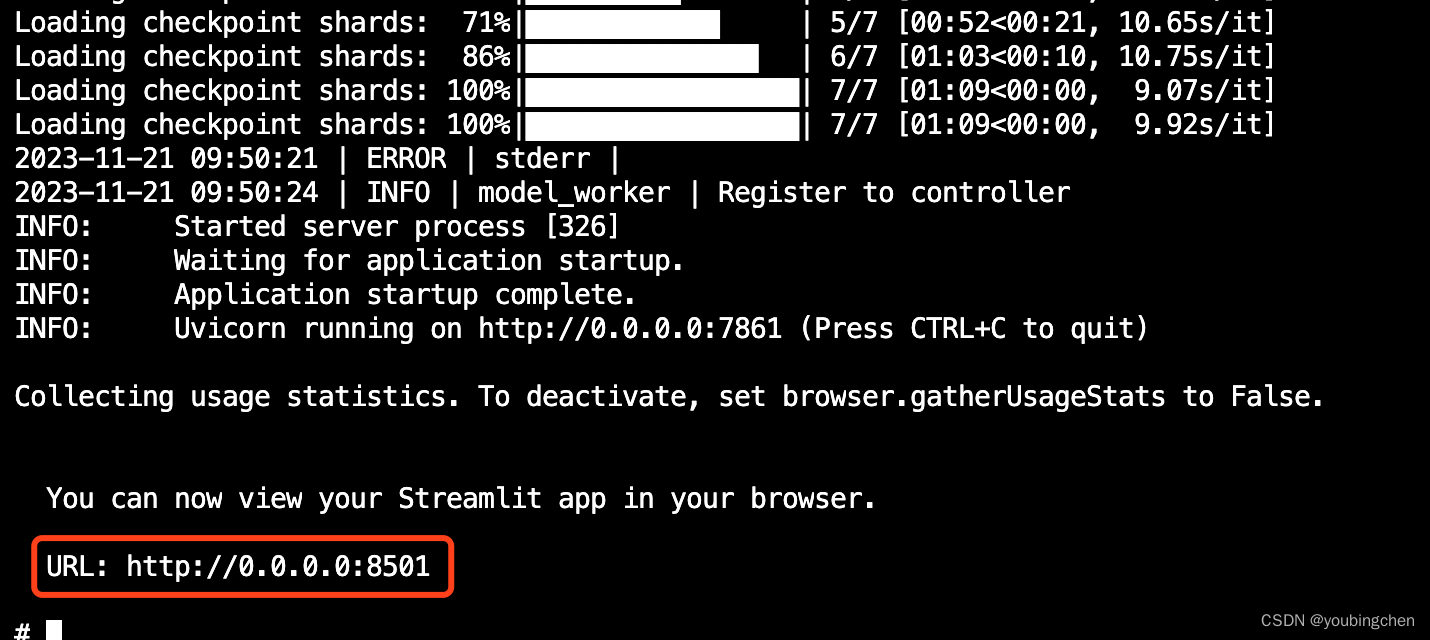
最后可以愉快的玩耍了.