注意
使用的还是源码的案例,添加个人注解。在前面的篇章我们讲解了客户端、服务端rpc构造的基本流程及同步、异步的案例基础之后,再理解此案例就容易了。
想直接看案例实现请看:
server端实现
client端实现
服务端要点概览
controller
server段不用自己new controller,controller在rpc服务接口中被传递过来
停止服务
获取客户端地址
controller->remote_side()
如果client是nginx,remote_side()是nginx的地址。要获取真实client的地址,可以在nginx里设置proxy_header ClientIp $remote_addr;, 在rpc中通过controller->http_request().GetHeader("ClientIp")获得对应的值。
获取服务端地址
controller->local_side()
请求添加附带信息
cntl->response_attachment().append(“bar”);
brpc::ServerOptions配置超时
options.idle_timeout_sec = 100;
设置监听端口
server.Start(FLAGS_port, &options)
SERVER_OWNS_SERVICE参数
Server在析构时会一并删除Service,否则应设为SERVER_DOESNT_OWN_SERVICE。大多数时候我们需要继续使用service,一版设置为SERVER_DOESNT_OWN_SERVICE
停止服务的方法
server.Stop(closewait_ms); // closewait_ms实际无效,出于历史原因未删
server.Join();
Stop()不会阻塞,Join()会。分成两个函数的原因在于当多个Server需要退出时,可以先全部Stop再一起Join,如果一个个Stop/Join,可能得花费Server个数倍的等待时间。
不管closewait_ms是什么值,server在退出时会等待所有正在被处理的请求完成,同时对新请求立刻回复ELOGOFF错误以防止新请求加入。这么做的原因在于只要server退出时仍有处理线程运行,就有访问到已释放内存的风险。如果你的server“退不掉”,很有可能是由于某个检索线程没结束或忘记调用done了。
当client看到ELOGOFF时,会跳过对应的server,并在其他server上重试对应的请求。所以在一般情况下brpc总是“优雅退出”的,重启或上线时几乎不会或只会丢失很少量的流量。
RunUntilAskedToQuit()函数可以在大部分情况下简化server的运转和停止代码。在server.Start后,只需如下代码即会让server运行直到按到Ctrl-C。
// Wait until Ctrl-C is pressed, then Stop() and Join() the server.
server.RunUntilAskedToQuit();
// server已经停止了,这里可以写释放资源的代码。
Join()完成后可以修改其中的Service,并重新Start。
proto定义
syntax="proto2";
package example;
option cc_generic_services = true;
# 请求proto
message EchoRequest {
required string message = 1;
};
# 响应proto
message EchoResponse {
required string message = 1;
};
# rpc服务定义
service EchoService {
rpc Echo(EchoRequest) returns (EchoResponse);
};
server端实现
#include <gflags/gflags.h>
#include <butil/logging.h>
#include <brpc/server.h>
#include "echo.pb.h"
// gflag用法
DEFINE_bool(send_attachment, true, "Carry attachment along with response");
DEFINE_int32(port, 8003, "TCP Port of this server");
DEFINE_int32(idle_timeout_s, -1, "Connection will be closed if there is no "
"read/write operations during the last `idle_timeout_s'");
DEFINE_int32(logoff_ms, 2000, "Maximum duration of server's LOGOFF state "
"(waiting for client to close connection before server stops)");
// Your implementation of example::EchoService
class EchoServiceImpl : public example::EchoService {
public:
EchoServiceImpl() {};
virtual ~EchoServiceImpl() {};
virtual void Echo(google::protobuf::RpcController* cntl_base,
const example::EchoRequest* request,
example::EchoResponse* response,
google::protobuf::Closure* done) {
// This object helps you to call done->Run() in RAII style. If you need
// to process the request asynchronously, pass done_guard.release().
brpc::ClosureGuard done_guard(done);
// server段controller都不需要自己去new,由proto编译生成,只需要将其转换成brpc::Controller即可
brpc::Controller* cntl =
static_cast<brpc::Controller*>(cntl_base);
// The purpose of following logs is to help you to understand
// how clients interact with servers more intuitively. You should
// remove these logs in performance-sensitive servers.
// controller->remote_side()`可获得发送该请求的client地址和端口,类型是butil::EndPoint。如果client是nginx,remote_side()是nginx的地址。要获取真实client的地址,可以在nginx里设置`proxy_header ClientIp $remote_addr;`, 在rpc中通过`controller->http_request().GetHeader("ClientIp")`获得对应的值。
// 如果想获取服务端的地址呢:controller->local_side()获得server端的地址,类型是butil::EndPoint。
LOG(INFO) << "Received request[log_id=" << cntl->log_id()
<< "] from " << cntl->remote_side()
<< ": " << request->message()
<< " (attached=" << cntl->request_attachment() << ")";
// Fill response.
response->set_message(request->message());
// You can compress the response by setting Controller, but be aware
// that compression may be costly, evaluate before turning on.
// cntl->set_response_compress_type(brpc::COMPRESS_TYPE_GZIP);
if (FLAGS_send_attachment) {
// Set attachment which is wired to network directly instead of
// being serialized into protobuf messages.
// 在brpc中,cntl是Controller对象的缩写,它用于处理RPC请求和生成响应。
//cntl->response_attachment().append("bar");这句话的意思是向Controller对象的response_attachment()方法返回的响应附加信息中添加字符串"bar"。
//在brpc中,每个RPC请求都可以附带一些附加信息,这些信息可以在请求和响应之间传递。
// 通过使用Controller对象的response_attachment()方法,可以在响应中添加自定义的附加信息。
// 在这种情况下,将字符串"bar"添加到响应附加信息中,以便在处理请求时可以访问它。
cntl->response_attachment().append("bar");
}
}
};
int main(int argc, char* argv[]) {
// Parse gflags. We recommend you to use gflags as well.
GFLAGS_NS::ParseCommandLineFlags(&argc, &argv, true);
// Generally you only need one Server.
brpc::Server server;
// Instance of your service.
EchoServiceImpl echo_service_impl;
// Add the service into server. Notice the second parameter, because the
// service is put on stack, we don't want server to delete it, otherwise
// use brpc::SERVER_OWNS_SERVICE.参数为SERVER_OWNS_SERVICE,Server在析构时会一并删除Service,否则应设为SERVER_DOESNT_OWN_SERVICE。大多数时候我们需要继续使用service,一版设置为SERVER_DOESNT_OWN_SERVICE
if (server.AddService(&echo_service_impl,
brpc::SERVER_DOESNT_OWN_SERVICE) != 0) {
LOG(ERROR) << "Fail to add service";
return -1;
}
// Start the server.
brpc::ServerOptions options;
// 配置超时
options.idle_timeout_sec = FLAGS_idle_timeout_s;
// 实际上option的参数很多,像这个例子就可以将自身实现的nsheadservice给配置进去,而不用add_service,关于option的参数,我们会在后续案例中慢慢覆盖全:options.thread_local_data_factory = &local_data_factory;
// options.session_local_data_factory = &local_data_factory;
// options.nshead_service = new Fw2NsheadService(this);
// 一个server只能监听一个端口(不考虑ServerOptions.internal_port),需要监听N个端口就起N个Server。
// 启动时开启`reuse_port`这个flag,就可以多进程共同监听一个端口(底层是SO_REUSEPORT)。
options.idle_timeout_sec = 100;
// 这里仅传如port,ip在brpc中默认是0.0.0.0
if (server.Start(FLAGS_port, &options) != 0) {
LOG(ERROR) << "Fail to start EchoServer";
return -1;
}
// Wait until Ctrl-C is pressed, then Stop() and Join() the server.
server.RunUntilAskedToQuit();
return 0;
}
client端要点说明
channel
与传统socket通信不同,使用channel来与一台或一组服务交互,channel必须初始化才能使用
brpc::ChannelOptions options
channel初始化必须的参数,包含协议类型、超时、重试等
协议类型
options.protocol = FLAGS_protocol;
定义在src/brpc/options.proto中,包含以下类型
enum ProtocolType {
PROTOCOL_UNKNOWN = 0;
PROTOCOL_BAIDU_STD = 1;
PROTOCOL_STREAMING_RPC = 2;
PROTOCOL_HULU_PBRPC = 3;
PROTOCOL_SOFA_PBRPC = 4;
PROTOCOL_RTMP = 5;
PROTOCOL_THRIFT = 6;
PROTOCOL_HTTP = 7;
PROTOCOL_PUBLIC_PBRPC = 8;
PROTOCOL_NOVA_PBRPC = 9;
PROTOCOL_REDIS = 10;
PROTOCOL_NSHEAD_CLIENT = 11; // implemented in baidu-rpc-ub
PROTOCOL_NSHEAD = 12;
PROTOCOL_HADOOP_RPC = 13;
PROTOCOL_HADOOP_SERVER_RPC = 14;
PROTOCOL_MONGO = 15; // server side only
PROTOCOL_UBRPC_COMPACK = 16;
PROTOCOL_DIDX_CLIENT = 17; // Client side only
PROTOCOL_MEMCACHE = 18; // Client side only
PROTOCOL_ITP = 19;
PROTOCOL_NSHEAD_MCPACK = 20;
PROTOCOL_DISP_IDL = 21; // Client side only
PROTOCOL_ERSDA_CLIENT = 22; // Client side only
PROTOCOL_UBRPC_MCPACK2 = 23; // Client side only
// Reserve special protocol for cds-agent, which depends on FIFO right now
PROTOCOL_CDS_AGENT = 24; // Client side only
PROTOCOL_ESP = 25; // Client side only
PROTOCOL_H2 = 26;
}
连接类型
options.connection_type = FLAGS_connection_type;
brpc支持的连接方式
-
短连接:每次RPC前建立连接,结束后关闭连接。由于每次调用得有建立连接的开销,这种方式一般用于偶尔发起的操作,而不是持续发起请求的场景。没有协议默认使用这种连接方式,http/1.0对连接的处理效果类似短链接。
-
连接池:每次RPC前取用空闲连接,结束后归还,一个连接上最多只有一个请求,一个client对一台server可能有多条连接。http/1.1和各类使用nshead的协议都是这个方式。
-
单连接:进程内所有client与一台server最多只有一个连接,一个连接上可能同时有多个请求,回复返回顺序和请求顺序不需要一致,这是baidu_std,hulu_pbrpc,sofa_pbrpc协议的默认选项。
各种连接之间的比较

框架会为协议选择默认的连接方式,用户一般不用修改。若需要,把ChannelOptions.connection_type设为:
(1) CONNECTION_TYPE_SINGLE 或 “single” 为单连接
(2)CONNECTION_TYPE_POOLED 或 “pooled” 为连接池, 单个远端对应的连接池最多能容纳的连接数由-max_connection_pool_size控制。注意,此选项不等价于“最大连接数”。需要连接时只要没有闲置的,就会新建;归还时,若池中已有max_connection_pool_size个连接的话,会直接关闭。max_connection_pool_size的取值要符合并发,否则超出的部分会被频繁建立和关闭,效果类似短连接。若max_connection_pool_size为0,就近似于完全的短连接。

(3)CONNECTION_TYPE_SHORT 或 “short” 为短连接
(4)设置为“”(空字符串)则让框架选择协议对应的默认连接方式。
brpc支持Streaming RPC,这是一种应用层的连接,用于传递流式数据。
关闭连接池中的闲置连接
当连接池中的某个连接在-idle_timeout_second时间内没有读写,则被视作“闲置”,会被自动关闭。默认值为10秒。此功能只对连接池(pooled)有效。打开-log_idle_connection_close在关闭前会打印一条日志。

延迟关闭连接
多个channel可能通过引用计数引用同一个连接,当引用某个连接的最后一个channel析构时,该连接将被关闭。但在一些场景中,channel在使用前才被创建,用完立刻析构,这时其中一些连接就会被无谓地关闭再被打开,效果类似短连接。
一个解决办法是用户把所有或常用的channel缓存下来,这样自然能避免channel频繁产生和析构,但目前brpc没有提供这样一个utility,用户自己(正确)实现有一些工作量。
另一个解决办法是设置全局选项-defer_close_second

设置后引用计数清0时连接并不会立刻被关闭,而是会等待这么多秒再关闭,如果在这段时间内又有channel引用了这个连接,它会恢复正常被使用的状态。不管channel创建析构有多频率,这个选项使得关闭连接的频率有上限。这个选项的副作用是一些fd不会被及时关闭,如果延时被误设为一个大数值,程序占据的fd个数可能会很大。
连接的缓冲区大小
-socket_recv_buffer_size设置所有连接的接收缓冲区大小,默认-1(不修改)
-socket_send_buffer_size设置所有连接的发送缓冲区大小,默认-1(不修改)

设置超时
options.timeout_ms = FLAGS_timeout_ms/milliseconds/;
设置最大重试次数
options.max_retry = FLAGS_max_retry;
发起连接
例:
channel.Init(FLAGS_server.c_str(), FLAGS_load_balancer.c_str(), &options)
连接一台服务器
brpc实现了3种单台服务器连接接口
// options为NULL时取默认值
int Init(EndPoint server_addr_and_port, const ChannelOptions* options);
int Init(const char* server_addr_and_port, const ChannelOptions* options);
int Init(const char* server_addr, int port, const ChannelOptions* options);
这类Init连接的服务器往往有固定的ip地址,不需要命名服务和负载均衡,创建起来相对轻量。但是请勿频繁创建使用域名的Channel。这需要查询dns,可能最多耗时10秒(查询DNS的默认超时)。重用它们。
合法的“server_addr_and_port”:
127.0.0.1:80
www.foo.com:8765
localhost:9000
[::1]:8080 # IPV6
unix:path.sock # Unix domain socket
不合法的"server_addr_and_port":
127.0.0.1:90000 # 端口过大
10.39.2.300:8000 # 非法的ip
连接服务集群
int Init(const char* naming_service_url,
const char* load_balancer_name,
const ChannelOptions* options);
这类Channel需要定期从naming_service_url指定的命名服务中获得服务器列表,并通过load_balancer_name指定的负载均衡算法选择出一台机器发送请求。
你不应该在每次请求前动态地创建此类(连接服务集群的)Channel。因为创建和析构此类Channel牵涉到较多的资源,比如在创建时得访问一次命名服务,否则便不知道有哪些服务器可选。由于Channel可被多个线程共用,一般也没有必要动态创建。
当load_balancer_name为NULL或空时,此Init等同于连接单台server的Init,naming_service_url应该是"ip:port"或"域名:port"。
实践建议:你可以通过这个Init函数统一Channel的初始化方式。比如你可以把naming_service_url和load_balancer_name放在配置文件中,要连接单台server时把load_balancer_name置空,要连接服务集群时则设置一个有效的算法名称。下面我们先重点介绍下命令服务及负载均衡,再给出一个实践案例。
brpc命名服务及服务配置格式说明
命名服务(NS)把一个名字映射为可修改的机器列表,在client端的位置如下:
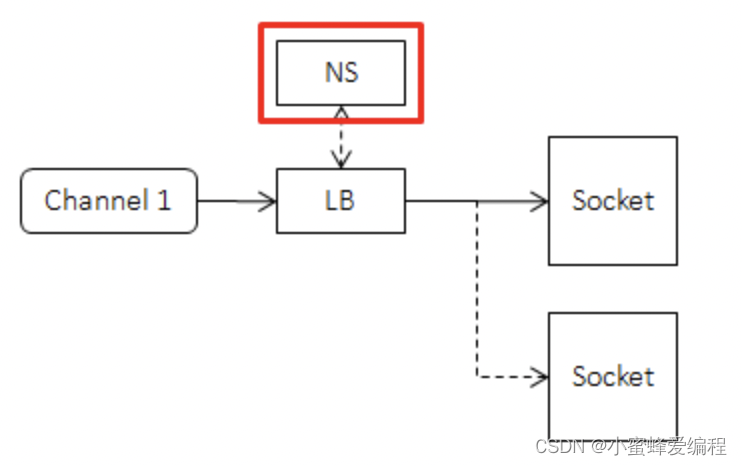
有了命名服务后client记录的是一个名字,而不是每一台下游机器。而当下游机器变化时,就只需要修改命名服务中的列表,而不需要逐台修改每个上游。这个过程也常被称为“解耦上下游”。当然在具体实现上,上游会记录每一台下游机器,并定期向命名服务请求或被推送最新的列表,以避免在RPC请求时才去访问命名服务。使用命名服务一般不会对访问性能造成影响,对命名服务的压力也很小。
naming_service_url的一般形式是"protocol://service_name"
格式一、bns://<bns-name>
BNS是百度内常用的命名服务,比如bns://rdev.matrix.all,其中"bns"是protocol,"rdev.matrix.all"是service-name。相关一个gflag是-ns_access_interval: img
如果BNS中显示不为空,但Channel却说找不到服务器,那么有可能BNS列表中的机器状态位(status)为非0,含义为机器不可用,所以不会被加入到server候选集中.状态位可通过命令行查看:
get_instance_by_service [bns_node_name] -s
格式二、file://<path>
服务器列表放在path所在的文件里,比如"file://conf/machine_list"中的“conf/machine_list”对应一个文件:
- 每行是一台服务器的地址。
- #之后的是注释会被忽略
- 地址后出现的非注释内容被认为是tag,由一个或多个空格与前面的地址分隔,相同的地址+不同的tag被认为是不同的实例。
- 当文件更新时, brpc会重新加载。
# 此行会被忽略
10.24.234.17:8080 tag1 # 这是注释,会被忽略
10.24.234.17:8090 tag2 # 此行和上一行被认为是不同的实例
10.24.234.18:8080
10.24.234.19:8080
优点: 易于修改,方便单测。
缺点: 更新时需要修改每个上游的列表文件,不适合线上部署。
这种方法通常用在测试环境。
格式三、list://<addr1>,…
服务器列表直接跟在list://之后,以逗号分隔,比如"list://db-bce-81-3-186.db01:7000,m1-bce-44-67-72.m1:7000,cp01-rd-cos-006.cp01:7000"中有三个地址。也可以只有一个。
地址后可以声明tag,用一个或多个空格分隔,相同的地址+不同的tag被认为是不同的实例。
优点: 可在命令行中直接配置,方便单测。
缺点: 无法在运行时修改,完全不能用于线上部署。
通常也是在单独测试时,修改conf中服务命为指定list
格式四、http://<url>
连接一个域名下所有的机器, 例如http://www.baidu.com:80 ,注意连接单点的Init(两个参数)虽然也可传入域名,但只会连接域名下的一台机器。
优点: DNS的通用性,公网内网均可使用。
缺点: 受限于DNS的格式限制无法传递复杂的meta数据,也无法实现通知机制。
格式五、https://<url>
和http前缀类似,只是会自动开启SSL。
格式六、consul://<service-name>
通过consul获取服务名称为service-name的服务列表。consul的默认地址是localhost:8500,可通过gflags设置-consul_agent_addr来修改。consul的连接超时时间默认是200ms,可通过-consul_connect_timeout_ms来修改。
默认在consul请求参数中添加stale和passing(仅返回状态为passing的服务列表),可通过gflags中-consul_url_parameter改变consul请求参数。
除了对consul的首次请求,后续对consul的请求都采用long polling的方式,即仅当服务列表更新或请求超时后consul才返回结果,这里超时时间默认为60s,可通过-consul_blocking_query_wait_secs来设置。
若consul返回的服务列表响应格式有错误,或者列表中所有服务都因为地址、端口等关键字段缺失或无法解析而被过滤,consul naming server会拒绝更新服务列表,并在一段时间后(默认500ms,可通过-consul_retry_interval_ms设置)重新访问consul。
如果consul不可访问,服务可自动降级到file naming service获取服务列表。此功能默认关闭,可通过设置-consul_enable_degrade_to_file_naming_service来打开。服务列表文件目录通过-consul _file_naming_service_dir来设置,使用service-name作为文件名。该文件可通过consul-template生成,里面会保存consul不可用之前最新的下游服务节点。当consul恢复时可自动恢复到consul naming service。
格式七、nacos://<service-name>
NacosNamingService使用Open-Api定时从nacos获取服务列表。 NacosNamingService支持简单鉴权。
是一个http uri query,具体参数参见/nacos/v1/ns/instance/list文档。 注意:需要urlencode。
nacos://serviceName=test&groupName=g&namespaceId=n&clusters=c&healthyOnly=true
NacosNamingService拉取列表的时间间隔为/nacos/v1/ns/instance/listapi返回的cacheMillis。 NacosNamingService只支持整形的权重值。
定义自己的命名服务
用户可以通过实现brpc::NamingService来对接更多命名服务:
命名服务
在brpc中,NamingService用于获得服务名对应的所有节点。一个直观的做法是定期调用一个函数以获取最新的节点列表。但这会带来一定的延时(定期调用的周期一般在若干秒左右),作为通用接口不太合适。特别当命名服务提供事件通知时(比如zk),这个特性没有被利用。所以我们反转了控制权:不是我们调用用户函数,而是用户在获得列表后调用我们的接口,对应NamingServiceActions。当然我们还是得启动进行这一过程的函数,对应NamingService::RunNamingService。下面以三个实现解释这套方式:
bns:没有事件通知,所以我们只能定期去获得最新列表,默认间隔是5秒。为了简化这类定期获取的逻辑,brpc提供了PeriodicNamingService 供用户继承,用户只需要实现单次如何获取(GetServers)。获取后调用NamingServiceActions::ResetServers告诉框架。框架会对列表去重,和之前的列表比较,通知对列表有兴趣的观察者(NamingServiceWatcher)。这套逻辑会运行在独立的bthread中,即NamingServiceThread。一个NamingServiceThread可能被多个Channel共享,通过intrusive_ptr管理ownership。
file:列表即文件。合理的方式是在文件更新后重新读取。该实现使用FileWatcher关注文件的修改时间,当文件修改后,读取并调用NamingServiceActions::ResetServers告诉框架。
list:列表就在服务名里(逗号分隔)。在读取完一次并调用NamingServiceActions::ResetServers后就退出了,因为列表再不会改变了。
如果用户需要建立这些对象仍然是不够方便的,因为总是需要一些工厂代码根据配置项建立不同的对象,鉴于此,我们把工厂类做进了框架,并且是非常方便的形式:
"protocol://service-name"
e.g.
bns://<node-name> # baidu naming service
file://<file-path> # load addresses from the file
list://addr1,addr2,... # use the addresses separated by comma
http://<url> # Domain Naming Service, aka DNS.
这套方式是可扩展的,实现了新的NamingService后在global.cpp中依葫芦画瓢注册下就行了,如下图所示:

看到这些熟悉的字符串格式,容易联想到ftp:// zk:// galileo://等等都是可以支持的。用户在新建Channel时传入这类NamingService描述,并能把这些描述写在各类配置文件中。
见这里
命名服务中的tag
每个地址可以附带一个tag,在常见的命名服务中,如果地址后有空格,则空格之后的内容均为tag。 相同的地址配合不同的tag被认为是不同的实例,brpc会建立不同的连接。用户可利用这个特性更灵活地控制与单个地址的连接方式。 如果你需要"带权重的轮询",你应当优先考虑使用wrr算法,而不是用tag来模拟。
VIP相关的问题
VIP一般是4层负载均衡器的公网ip,背后有多个RS。当客户端连接至VIP时,VIP会选择一个RS建立连接,当客户端连接断开时,VIP也会断开与对应RS的连接。
如果客户端只与VIP建立一个连接(brpc中的单连接),那么来自这个客户端的所有流量都会落到一台RS上。如果客户端的数量非常多,至少在集群的角度,所有的RS还是会分到足够多的连接,从而基本均衡。但如果客户端的数量不多,或客户端的负载差异很大,那么可能在个别RS上出现热点。另一个问题是当有多个VIP可选时,客户端分给它们的流量与各自后面的RS数量可能不一致。
解决这个问题的一种方法是使用连接池模式(pooled),这样客户端对一个VIP就可能建立多个连接(约为一段时间内的最大并发度),从而让负载落到多个RS上。如果有多个VIP,可以用wrr负载均衡给不同的VIP声明不同的权重从而分到对应比例的流量,或给相同的VIP后加上多个不同的tag而被认为是多个不同的实例。
如果对性能有更高的要求,或要限制大集群中连接的数量,可以使用单连接并给相同的VIP加上不同的tag以建立多个连接。相比连接池一般连接数量更小,系统调用开销更低,但如果tag不够多,仍可能出现RS热点。
命名服务过滤器
当命名服务获得机器列表后,可以自定义一个过滤器进行筛选,最后把结果传递给负载均衡:
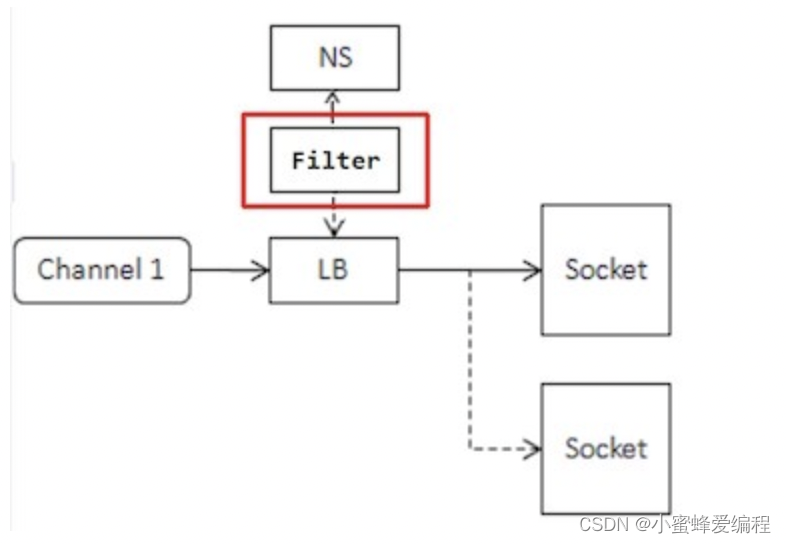
过滤器的接口如下:
// naming_service_filter.h
class NamingServiceFilter {
public:
// Return true to take this `server' as a candidate to issue RPC
// Return false to filter it out
virtual bool Accept(const ServerNode& server) const = 0;
};
// naming_service.h
struct ServerNode {
butil::EndPoint addr;
std::string tag;
};
常见的业务策略如根据server的tag进行过滤。
自定义的过滤器配置在ChannelOptions中,默认为NULL(不过滤)。
class MyNamingServiceFilter : public brpc::NamingServiceFilter {
public:
bool Accept(const brpc::ServerNode& server) const {
return server.tag == "main";
}
};
int main() {
...
MyNamingServiceFilter my_filter;
...
brpc::ChannelOptions options;
options.ns_filter = &my_filter;
...
}
brpc负载均衡
当下游机器超过一台时,我们需要分割流量,此过程一般称为负载均衡,在client端的位置如下图所示:
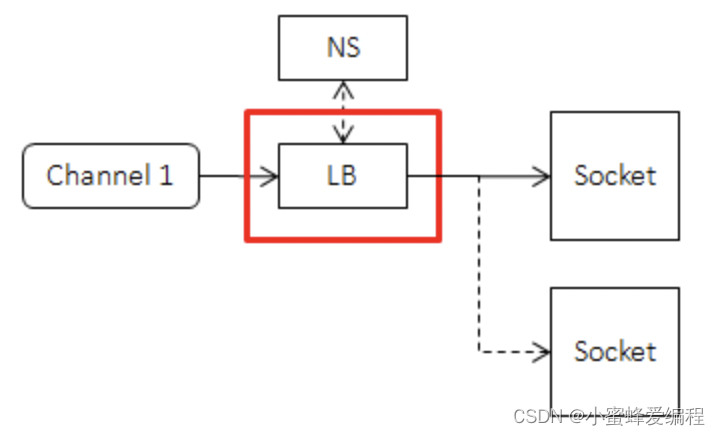
理想的算法是每个请求都得到及时的处理,且任意机器crash对全局影响较小。但由于client端无法及时获得server端的延迟或拥塞,而且负载均衡算法不能耗费太多的cpu,一般来说用户得根据具体的场景选择合适的算法,目前rpc提供的算法有(通过load_balancer_name指定):
rr(round robin) 轮询
即round robin,总是选择列表中的下一台服务器,结尾的下一台是开头,无需其他设置。比如有3台机器a,b,c,那么brpc会依次向a, b, c, a, b, c, …发送请求。注意这个算法的前提是服务器的配置,网络条件,负载都是类似的。
wrr(weighted round robin) 加权轮询
即weighted round robin, 根据服务器列表配置的权重值来选择服务器。服务器被选到的机会正比于其权重值,并且该算法能保证同一服务器被选到的结果较均衡的散开。
实例的tag需要是表示权值的int32数字,如tag=“50”。
random 随机
随机从列表中选择一台服务器,无需其他设置。和round robin类似,这个算法的前提也是服务器都是类似的。
wr(weighted random)
即weighted random, 根据服务器列表配置的权重值来选择服务器,服务器被选到的机会正比于其权重值。
实例tag的要求同wrr。
la(locality-aware) 低延时优先
locality-aware,优先选择延时低的下游,直到其延时高于其他机器,无需其他设置。实现原理请查看Locality-aware load balancing。
c_murmurhash or c_md5 一致性hash
一致性哈希,与简单hash的不同之处在于增加或删除机器时不会使分桶结果剧烈变化,特别适合cache类服务。redis服务首选
发起RPC前需要设置Controller.set_request_code(),否则RPC会失败。request_code一般是请求中主键部分的32位哈希值,不需要和负载均衡使用的哈希算法一致。比如用c_murmurhash算法也可以用md5计算哈希值。
src/brpc/policy/hasher.h中包含了常用的hash函数。如果用std::string key代表请求的主键,controller.set_request_code(brpc::policy::MurmurHash32(key.data(), key.size()))就正确地设置了request_code。
注意甄别请求中的“主键”部分和“属性”部分,不要为了偷懒或通用,就把请求的所有内容一股脑儿计算出哈希值,属性的变化会使请求的目的地发生剧烈的变化。另外也要注意padding问题,比如struct Foo { int32_t a; int64_t b; }在64位机器上a和b之间有4个字节的空隙,内容未定义,如果像hash(&foo, sizeof(foo))这样计算哈希值,结果就是未定义的,得把内容紧密排列或序列化后再算。
实现原理请查看Consistent Hashing。
其他lb不需要设置Controller.set_request_code(),如果调用了request_code也不会被lb使用,例如:lb=rr调用了Controller.set_request_code(),即使所有RPC的request_code都相同,也依然是rr。
从集群宕机后恢复时的客户端限流原理
集群宕机指的是集群中所有server都处于不可用的状态。由于健康检查机制,当集群恢复正常后,server会间隔性地上线。当某一个server上线后,所有的流量会发送过去,可能导致服务再次过载。若熔断开启,则可能导致其它server上线前该server再次熔断,集群永远无法恢复。作为解决方案,brpc提供了在集群宕机后恢复时的限流机制:当集群中没有可用server时,集群进入恢复状态,假设正好能服务所有请求的server数量为min_working_instances,当前集群可用的server数量为q,则在恢复状态时,client接受请求的概率为q/min_working_instances,否则丢弃;若一段时间hold_seconds内q保持不变,则把流量重新发送全部可用的server上,并离开恢复状态。在恢复阶段时,可以通过判断controller.ErrorCode()是否等于brpc::ERJECT来判断该次请求是否被拒绝,被拒绝的请求不会被框架重试。
此恢复机制要求下游server的能力是类似的,所以目前只针对rr和random有效,开启方式是在load_balancer_name后面加上min_working_instances和hold_seconds参数的值,例如:
channel.Init("http://...", "random:min_working_instances=6 hold_seconds=10", &options);
实际中random:min_working_instances是由集群总数,并发恢复数有关,一般会并发启动30%的实例。
健康检查
连接断开的server会被暂时隔离而不会被负载均衡算法选中,brpc会定期连接被隔离的server,以检查他们是否恢复正常,间隔由参数-health_check_interval控制:

在默认的配置下,一旦server被连接上,它会恢复为可用状态;brpc还提供了应用层健康检查的机制,框架会发送一个HTTP GET请求到该server,请求路径通过-health_check_path设置(默认为空),只有当server返回200时,它才会恢复。在两种健康检查机制下,都可通过-health_check_timeout_ms设置超时(默认500ms)。如果在隔离过程中,server从命名服务中删除了,brpc也会停止连接尝试。
命名服务实践案例:
conf配置(以下写在conf文件中):
[.@VService]
name: my_ser0
tag: lzs1
load_balancer: rr
#service: bns://my-server0-bj-all.person
service: list://127.0.0.1:9002
max_retry: 1
timeout_ms: 100
connect_timeout_ms: 100
backup_request_ms: 25
const comcfg::ConfigUnit& service_conf = rpc_conf["RpcClientConfig"]["VService"][i];
if (service_conf.selfType() != comcfg::CONFIG_ERROR_TYPE) {
std::string name = service_conf["name"].to_cstr();
std::string service = service_conf["service"].to_cstr();
std::string load_balancer = service_conf["load_balancer"].to_cstr();
options.connect_timeout_ms = service_conf["connect_timeout_ms"].to_int32();
options.timeout_ms = service_conf["timeout_ms"].to_int32();
options.backup_request_ms = service_conf["backup_request_ms"].to_int32();
options.max_retry = service_conf["max_retry"].to_int32();
if (_my_client->push_channel(name, service, load_balancer, options) != 0) {
CFATAL_LOG("Fail to add rpc re_v : %d", i);
return RET_ERROR;
}
发起访问
一般来说,我们不直接调用Channel.CallMethod,而是通过protobuf生成的桩XXX_Stub,过程更像是“调用函数”。stub内没什么成员变量,建议在栈上创建和使用,而不必new,当然你也可以把stub存下来复用。Channel::CallMethod和stub访问都是线程安全的,可以被所有线程同时访问。比如:
XXX_Stub stub(&channel);
stub.some_method(controller, request, response, done);
甚至
XXX_Stub(&channel).some_method(controller, request, response, done);
一个例外是http/h2 client。访问http服务和protobuf没什么关系,直接调用CallMethod即可,除了Controller和done均为NULL
访问的方式有同步、异步、半同步几种,我们有篇文章专门讲过,这里就不赘述。
下面的案例我们使用的是NewCallBack创建回调入口、response/controller等对象,发起访问后,xxx_stub就结束了,server端的处理是在回调函数中处理的
我们再来回顾下异步访问的知识:
异步访问
指的是:给CallMethod传递一个额外的回调对象done,CallMethod在发出request后就结束了,而不是在RPC结束后。当server端返回response或发生错误(包括超时)时,done->Run()会被调用。对RPC的后续处理应该写在done->Run()里,而不是CallMethod后。
由于CallMethod结束不意味着RPC结束,response/controller仍可能被框架及done->Run()使用,它们一般得创建在堆上,并在done->Run()中删除。如果提前删除了它们,那当done->Run()被调用时,将访问到无效内存。
你可以独立地创建这些对象,并使用NewCallback生成done,也可以把Response和Controller作为done的成员变量,一起new出来,一般使用前一种方法。
发起异步请求后Request可以立刻析构。(SelectiveChannel是个例外,SelectiveChannel情况下必须在请求处理完成后再释放request对象)
发起异步请求后Channel可以立刻析构。
注意:这是说Request/Channel的析构可以立刻发生在CallMethod之后,并不是说析构可以和CallMethod同时发生,删除正被另一个线程使用的Channel是未定义行为(很可能crash)。
企业日志实践:brpc log_id
cntl->set_log_id(log_id ++);
通过set_log_id()可设置64位整型log_id。这个id会和请求一起被送到服务器端,一般会被打在日志里,从而把一次检索经过的所有服务串联起来。字符串格式的需要转化为64位整形才能设入log_id。在实际工作中,我们常通过log_id将上下游服务的请求串联起来,从而方便问题的定位排查。后续我们也会专门讲述企业日志实战。
client端实现
#include <gflags/gflags.h>
#include <butil/logging.h>
#include <butil/time.h>
#include <brpc/channel.h>
#include "echo.pb.h"
DEFINE_bool(send_attachment, true, "Carry attachment along with requests");
DEFINE_string(protocol, "baidu_std", "Protocol type. Defined in src/brpc/options.proto");
DEFINE_string(connection_type, "", "Connection type. Available values: single, pooled, short");
DEFINE_string(server, "0.0.0.0:8003", "IP Address of server");
DEFINE_string(load_balancer, "", "The algorithm for load balancing");
DEFINE_int32(timeout_ms, 100, "RPC timeout in milliseconds");
DEFINE_int32(max_retry, 3, "Max retries(not including the first RPC)");
void HandleEchoResponse(
brpc::Controller* cntl,
example::EchoResponse* response) {
// std::unique_ptr makes sure cntl/response will be deleted before returning.
std::unique_ptr<brpc::Controller> cntl_guard(cntl);
std::unique_ptr<example::EchoResponse> response_guard(response);
if (cntl->Failed()) {
LOG(WARNING) << "Fail to send EchoRequest, " << cntl->ErrorText();
return;
}
LOG(INFO) << "Received response from " << cntl->remote_side()
<< ": " << response->message() << " (attached="
<< cntl->response_attachment() << ")"
<< " latency=" << cntl->latency_us() << "us";
}
int main(int argc, char* argv[]) {
// Parse gflags. We recommend you to use gflags as well.
GFLAGS_NS::ParseCommandLineFlags(&argc, &argv, true);
// A Channel represents a communication line to a Server. Notice that
// Channel is thread-safe and can be shared by all threads in your program.
// 定义channel,一个channel负责与一个服务交互(单台或集群)
brpc::Channel channel;
// Initialize the channel, NULL means using default options.Channel必须在Init之后才能使用
// Channel不会修改options,Init结束后不会再访问options。所以options一般就像上面代码中那样放栈上。Channel.options()可以获得channel在使用的所有选项。
brpc::ChannelOptions options;
options.protocol = FLAGS_protocol;
options.connection_type = FLAGS_connection_type;
options.timeout_ms = FLAGS_timeout_ms/*milliseconds*/;
options.max_retry = FLAGS_max_retry;
if (channel.Init(FLAGS_server.c_str(), FLAGS_load_balancer.c_str(), &options) != 0) {
LOG(ERROR) << "Fail to initialize channel";
return -1;
}
// Normally, you should not call a Channel directly, but instead construct
// a stub Service wrapping it. stub can be shared by all threads as well.
example::EchoService_Stub stub(&channel);
// Send a request and wait for the response every 1 second.
int log_id = 0;
while (!brpc::IsAskedToQuit()) {
// Since we are sending asynchronous RPC (`done' is not NULL),
// these objects MUST remain valid until `done' is called.
// As a result, we allocate these objects on heap
example::EchoResponse* response = new example::EchoResponse();
brpc::Controller* cntl = new brpc::Controller();
// Notice that you don't have to new request, which can be modified
// or destroyed just after stub.Echo is called.
example::EchoRequest request;
request.set_message("hello world");
cntl->set_log_id(log_id ++); // set by user
if (FLAGS_send_attachment) {
// Set attachment which is wired to network directly instead of
// being serialized into protobuf messages.
cntl->request_attachment().append("foo");
}
// We use protobuf utility `NewCallback' to create a closure object
// that will call our callback `HandleEchoResponse'. This closure
// will automatically delete itself after being called once
// 异步访问关键
google::protobuf::Closure* done = brpc::NewCallback(
&HandleEchoResponse, cntl, response);
stub.Echo(cntl, &request, response, done);
// This is an asynchronous RPC, so we can only fetch the result
// inside the callback
sleep(1);
}
LOG(INFO) << "EchoClient is going to quit";
return 0;
}
结语
这是我们brpc的第一个案例,我们力求能将更多的细节讲述出来,当然很多还是得力于官方资料的完整,我们附加了一些企业应用案例,但还是有很多东西没讲到,像熔断、重试、超时策略等。我们计划在后续的写作中逐步完善。