深度学习过程
data = []
for i,d in enumerate(data):
image,label = d
image,label = image.cuda(),label.cuda()
img = net(image)
optimizer.zero_grad()
#需要将梯度信息清零,因为梯度计算是按照batch分批次计算的,如果这一批batch没清零,会影响下一批batch的梯度计算,这也就是说为什么
#在训练神经网络的时候batch越大越好,但是如果bs越大,则模型的泛化能力越差。
loss = cross entropy(img,label)
#交叉熵损失的计算是将每一个类别的概率值乘以概率值的log值求和,再取负数。
loss.backward()
#梯度回传,计算出梯度
optimizer.step()
#使用优化算法更新参数和偏执
首先需要明确贯穿一点:深度学习最重要的是要求出损失函数的全局最小值(或者最大值),而求极值的过程需要对loss求梯度(求导类似)。
1、问题一:有个问题,二元一次函数求极值,我们直接将导函数令为0,求解极值点即可,为什么求解损失函数时需要梯度下降?
答案是:损失函数一般都是比较复杂的超越方程,不能求出解,只能通过设定初始的值W和B,带入之后并且使用梯度下降算法求得最优解。这个时候学习率就要被引入了,通常学习率是用来限定梯度下降的时候的“步长”。
2、凸函数优化问题,这个问题贯穿了机器学习和深度学习领域,其终极目标就是求出凸函数的极值,值得注意的是一般神经网络的损失函数不是凸函数,这是个非常复杂的函数,具体可以参考这里。
3、损失函数的优化一般采用随机梯度下降法,初始化W和b的值,通过对比计算函数值(这里的函数值还得确认是哪个函数?损失函数还是损失函数的导函数?)进行梯度下降,下降的步长就是所谓的学习率,关于这个问题的解释网上很多。学习率太小,收敛太慢,并且容易陷入局部最优,学习率太大,不宜收敛。这个地方还会涉及到梯度消失和梯度爆炸的问题。
4、梯度消失和梯度爆炸的问题:
1)为什么会产生梯度消失和梯度爆炸?
目前优化神经网络的方法都是基于BP,即根据损失函数计算的误差通过梯度反向传播的方式,指导深度网络权值的更新优化。其中将误差从末层往前传递的过程需要链式求导法则(Chain Rule)的帮助,因此反向传播算法可以说是梯度下降在链式法则中的应用。
而链式法则是一个连乘的形式,所以当层数越深的时候,梯度将以指数形式传播。梯度消失问题和梯度爆炸问题一般随着网络层数的增加会变得越来越明显。在根据损失函数计算的误差通过梯度反向传播的方式对深度网络权值进行更新时,得到的梯度值接近0或特别大,也就是梯度消失或爆炸。梯度消失或梯度爆炸在本质原理上其实是一样的。
【梯度消失】经常出现,产生的原因有:一是在深层网络中,二是采用了不合适的损失函数,比如sigmoid。当梯度消失发生时,接近于输出层的隐藏层由于其梯度相对正常,所以权值更新时也就相对正常,但是当越靠近输入层时,由于梯度消失现象,会导致靠近输入层的隐藏层权值更新缓慢或者更新停滞。这就导致在训练时,只等价于后面几层的浅层网络的学习。
【梯度爆炸】一般出现在深层网络和权值初始化值太大的情况下。在深层神经网络或循环神经网络中,误差的梯度可在更新中累积相乘。如果网络层之间的梯度值大于 1.0,那么重复相乘会导致梯度呈指数级增长,梯度变的非常大,然后导致网络权重的大幅更新,并因此使网络变得不稳定。
梯度爆炸会伴随一些细微的信号,如:①模型不稳定,导致更新过程中的损失出现显著变化;②训练过程中,在极端情况下,权重的值变得非常大,以至于溢出,导致模型损失变成 NaN等等。
参考:梯度消失和梯度爆炸及解决方法 - 知乎 (zhihu.com)
同时为了解决随着网络层数加深带来的网络退化现象,ResNet被提出。
5、ResNet
ResNet的提出大大解决了网络退化的问题,可参考深度学习之3——梯度爆炸与梯度消失 - 知乎 (zhihu.com),深入浅出读懂ResNet原理与实现_残差块公式-CSDN博客


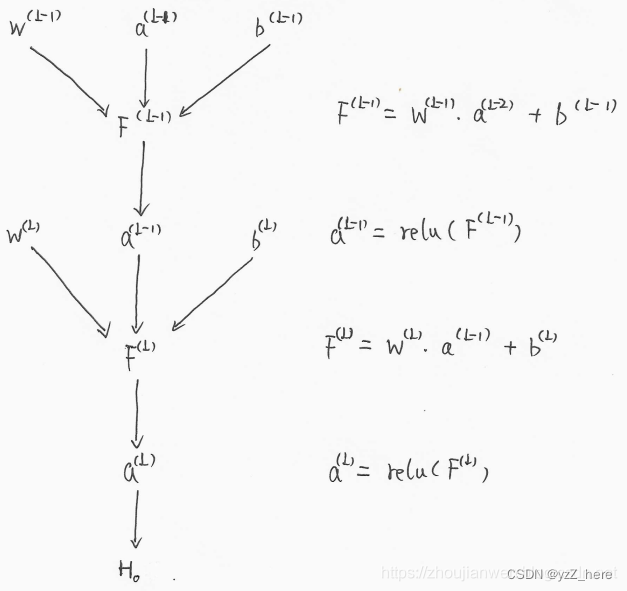
6、交叉熵损失函数 cross entropy
以二分类为例,概念可以自己去看。

为什么交叉熵损失函数中要用log函数,因为所有的神经网络的激活函数输出时概率值,概率都是在0-1之间的,结合log函数的图像可以看出0-1之间都是负值,所有需要负号调节。
7、梯度累积
梯度累积是为了解决显存不够的设备想要大batch size训练的问题。不需要每一个batch训练完之后将梯度清零,可以让梯度进行累积一定次数之后,再将梯度更新,这样子就相当于是积累的4个batch的梯度,相当于一次训练了4个batch。









![[C++] STL_stack queue接口的模拟实现](https://img-blog.csdnimg.cn/ff39f40470e14ddf94928d97c0fef6b8.png)