文章目录
- 一、简介
- 二、单机部署
- 2.1 上传压缩包
- 2.2 解压压缩包
- 2.3 修改配置文件
- (1)配置zookeeper地址
- (2)修改kafka运行日志(数据)存储路径
- 2.4 配置环境变量
- 2.5 启动/关闭
- 2.6 测试
- (1)查看当前服务器中的所有topic
- (2)创建topic等增删改查操作未测试,担心后面升级为集群模式时出问题。
- 三、集群部署
- 3.0 清空log.dirs目录并删除zookeeper的kafka节点
- 3.1 同步到其他机器
- (1)同步Kafka软件
- (2)修改其他机器的broker.id
- (3)配置其他机器的环境变量
- 3.2 启动/停止集群
- 3.3 测试
- (1)查看当前服务器中的所有topic
- (2)创建topic
- (3)删除topic
- (4)发送消息
- (5)消费消息
- (6)查看某个Topic的详情
- (7)修改分区数
- 四、监控(kafka-eagle单机模式)
- 4.0 上传并解压kafka-eagle压缩包
- 4.1 修改Kafka集群配置
- (1)暴露JMX端口
- (2)调大Kafka内存
- (3)分发配置
- 4.2 配置kafka-eagle
- 4.2.1 修改配置文件
- (1)配置zk地址
- (2)Kafka Offset的存储地址
- (3)配置MySQL地址
- (4)其他配置
- 4.2.2 配置环境变量
- 4.3 启动
- 4.3.1 启动Kafka集群
- 4.3.2 启动kafka-eagle
- 4.3.3 关闭kafka-eagle
- 4.4 测试
一、简介
Kafka官网:https://kafka.apache.org/intro
Kafka是Scala开发的,运行依赖JVM,所以安装Kafka前需要先安装JDK。
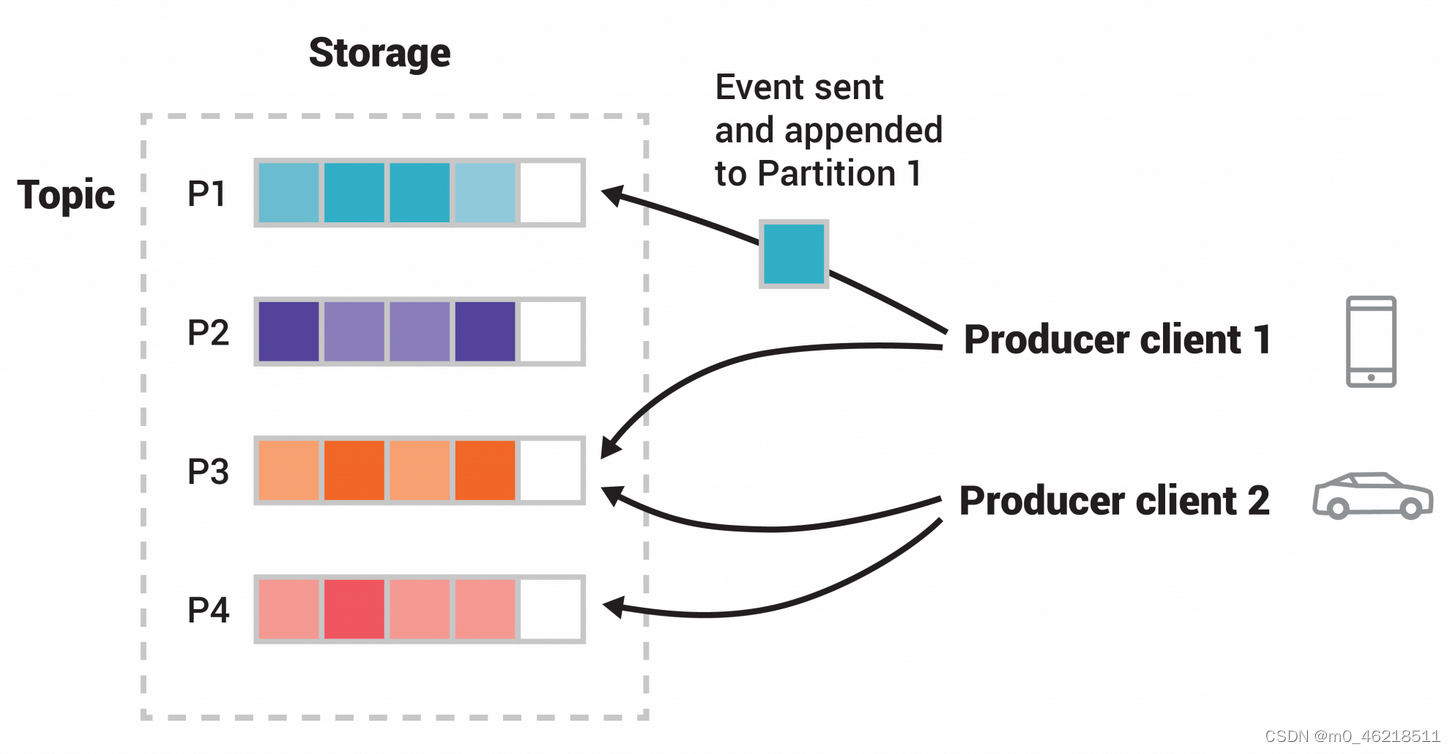
二、单机部署
Kafka集群化部署需要分布式协调服务来帮助Kafka实现高可用,分布式协调服务可以使用通用解决方案Zookeeper或Kafka内部实现的KRaft。ZooKeeper充当的角色是帮助提供公平的选举机制选举leader等作用。本例采用的模式是Kafka with ZooKeeper(参考资料丰富)。
2.1 上传压缩包
2.2 解压压缩包
[hadoop@hadoop102 software]$ tar -zxvf kafka_2.11-2.4.1.tgz -C /opt/module/
2.3 修改配置文件
[hadoop@hadoop102 config]$ vim server.properties
(1)配置zookeeper地址
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
(2)修改kafka运行日志(数据)存储路径
log.dirs=/opt/module/kafka_2.11-2.4.1/datas
2.4 配置环境变量
[hadoop@hadoop102 config]$ sudo vim /etc/profile.d/my_env.sh
新增内容:
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka_2.11-2.4.1
export PATH=$PATH:$KAFKA_HOME/bin
使环境变量生效:
[hadoop@hadoop102 config]$ source /etc/profile
2.5 启动/关闭
[hadoop@hadoop102 config]$ cd /opt/module/kafka_2.11-2.4.1/
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-server-start.sh -daemon config/server.properties
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-server-stop.sh stop
2.6 测试
(1)查看当前服务器中的所有topic
两种查看方式,一种是连kafka查看,一种是连zookeeper看,topic信息存zookeeper上了????
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka --list
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --list
(2)创建topic等增删改查操作未测试,担心后面升级为集群模式时出问题。
三、集群部署
从Kafka单机模式升级到Kafka集群模式,一定要先清空log.dirs目录,否则其他机器会启动失败。需要清空zookeeper中kafka信息吗?
3.0 清空log.dirs目录并删除zookeeper的kafka节点
[hadoop@hadoop102 kafka_2.11-2.4.1]$ rm -r datas/
# 启动zookeeper客户端
[zk: localhost:2181(CONNECTED) 5] deleteall /kafka
3.1 同步到其他机器
(1)同步Kafka软件
[hadoop@hadoop102 ~]$ mytools_rsync /opt/module/kafka_2.11-2.4.1/
(2)修改其他机器的broker.id
不同机器的brokerid不能相同
[hadoop@hadoop103 config]$ vim server.properties
# 修改内容:broker.id=1
[hadoop@hadoop104 config]$ vim server.properties
# 修改内容:broker.id=2
(3)配置其他机器的环境变量
[hadoop@hadoop103 config]$ sudo vim /etc/profile.d/my_env.sh
[hadoop@hadoop104 config]$ sudo vim /etc/profile.d/my_env.sh
新增内容:
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka_2.11-2.4.1
export PATH=$PATH:$KAFKA_HOME/bin
使环境变量生效:
[hadoop@hadoop103 config]$ source /etc/profile
[hadoop@hadoop104 config]$ source /etc/profile
3.2 启动/停止集群
# 启动
[hadoop@hadoop102 config]$ cd /opt/module/kafka_2.11-2.4.1/
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-server-start.sh -daemon config/server.properties
[hadoop@hadoop103 config]$ cd /opt/module/kafka_2.11-2.4.1/
[hadoop@hadoop103 kafka_2.11-2.4.1]$ bin/kafka-server-start.sh -daemon config/server.properties
[hadoop@hadoop104 config]$ cd /opt/module/kafka_2.11-2.4.1/
[hadoop@hadoop104 kafka_2.11-2.4.1]$ bin/kafka-server-start.sh -daemon config/server.properties
# 停止
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-server-stop.sh stop
[hadoop@hadoop103 kafka_2.11-2.4.1]$ bin/kafka-server-stop.sh stop
[hadoop@hadoop104 kafka_2.11-2.4.1]$ bin/kafka-server-stop.sh stop
3.3 测试
(1)查看当前服务器中的所有topic
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --list
(2)创建topic
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --replication-factor 2 --partitions 1 --topic first-topic
选项说明:
–topic 定义topic名
–replication-factor 定义副本数
–partitions 定义分区数
(3)删除topic
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --delete --topic first-topic
(4)发送消息
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic first-topic
发送内容:
>hello
>hi~
>are you ok?
(5)消费消息
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first-topic
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic first-topic
消费者组内的消费者数和topic的分区数的关系?
(6)查看某个Topic的详情
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic first-topic
(7)修改分区数
[hadoop@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --alter --topic first-topic --partitions 3
四、监控(kafka-eagle单机模式)
用于监控Kafka的消息堆积、消息延迟等情况。
注意:需要提前准备好MySQL环境,kafka-eagle会将监控数据保存到MySQL中。
4.0 上传并解压kafka-eagle压缩包
注意:压缩包里面还有一个压缩包,需要解压两次
[hadoop@hadoop102 software]$ cd /opt/software/
[hadoop@hadoop102 software]$ tar -zxvf kafka-eagle-bin-1.4.8.tar.gz
[hadoop@hadoop102 software]$ cd kafka-eagle-bin-1.4.8/
[hadoop@hadoop102 kafka-eagle-bin-1.4.8]$ tar -zxvf kafka-eagle-web-1.4.8-bin.tar.gz -C /opt/module/
4.1 修改Kafka集群配置
先关闭Kafka集群
[hadoop@hadoop102 bin]$ vim kafka-server-start.sh
(1)暴露JMX端口
JMX(Java Management Extensions)是一个为应用程序植入管理功能的框架。JMX是一套标准的代理和服务,实际上,用户能够在任何Java应用程序中使用这些代理和服务实现管理。用人话说,就是对外暴露更多数据,方便某些监控之类的插件来使用
(2)调大Kafka内存
默认初始化内存、运行内存为1G,使用kafka-eagle监控,1G内存不够用。需要增加到2G。
修改内容:
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
#export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="9999"
fi
(3)分发配置
[hadoop@hadoop102 bin]$ mytools_rsync kafka-server-start.sh
4.2 配置kafka-eagle
4.2.1 修改配置文件
[hadoop@hadoop102 ~]$ cd /opt/module/kafka-eagle-web-1.4.8/conf/
[hadoop@hadoop102 conf]$ vim system-config.properties
(1)配置zk地址
为什么要配置zk的地址,因为Kafka的配置信息存储在了zk中。
修改内容:
kafka.eagle.zk.cluster.alias=cluster1
cluster1.zk.list=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
(2)Kafka Offset的存储地址
kafka-eagle需要监控Kafka的offset,所以需要知道Kafka的offset存储在了哪里,存储位置是在Kafka集群中配置的,Kafka默认将offset存储在了kafka的topic中。
修改内容:
cluster1.kafka.eagle.offset.storage=kafka
(3)配置MySQL地址
修改内容:
kafka.eagle.driver=com.mysql.jdbc.Driver
kafka.eagle.url=jdbc:mysql://mall:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
kafka.eagle.username=root
kafka.eagle.password=123456
(4)其他配置
# 是否启动监控图表
kafka.eagle.metrics.charts=true
4.2.2 配置环境变量
[hadoop@hadoop102 conf]$ sudo vim /etc/profile.d/my_env.sh
新增内容:
# kafkaEagle
export KE_HOME=/opt/module/kafka-eagle-web-1.4.8
export PATH=$PATH:$KE_HOME/bin
使环境变量生效:
[hadoop@hadoop102 conf]$ source /etc/profile
4.3 启动
4.3.1 启动Kafka集群
见本文3.2内容
4.3.2 启动kafka-eagle
启动前先放开MySQL所在机器的3306端口号,因为kafka-eagle启动后会进行初始化操作,包括在MySQL中创建ke数据库等。如果不放开初始化数据库会失败!
注意:阿里云安全组内网之间也需要放开对应端口号才能通信。能互相ping同ip,为什么不能连通端口???
[hadoop@hadoop102 conf]$ cd /opt/module/kafka-eagle-web-1.4.8/bin
# 给启动文件执行权限
[hadoop@hadoop102 bin]$ chmod 777 ke.sh
[hadoop@hadoop102 bin]$ cd /opt/module/kafka-eagle-web-1.4.8/
[hadoop@hadoop102 kafka-eagle-web-1.4.8]$ bin/ke.sh start
4.3.3 关闭kafka-eagle
[hadoop@hadoop102 kafka-eagle-web-1.4.8]$ bin/ke.sh stop
4.4 测试
安全组放开8048端口
访问:http://hadoop102:8048/ke
Account:admin
Password:123456






![数据结构~~~~ [队列] ~~~~](https://img-blog.csdnimg.cn/a9158d3f7445411abcba2cf40d796e38.png)