循环链表的实现
对于数据结构中所有的结构而言,每一次都是用之前初始化(处理一开始的随机值)一下,
用完销毁(不管有没有malloc都能用,用了可以保证没有动态内存泄漏了)一下
而在C++里面,构造函数和析构函数就是解决这个问题的,
它说你不用每一次都做,它直接封装了这个初始化和销毁,它给你写好了,不用你每一次都自己写一遍了
初始化函数——挨个考虑

测试一下

初始化完的循环链表长这样

我们说的是链表的头结点的数据域是不用的
但也有人不想让其浪费了,就一开始让其制成0,plist->data=0;
然后每增加一个数据结点,就让plist->data++;同理删除就- -
以此来存放链表plist的有效数据长度length
后面要是需要求GetLength时,直接返回plist->data就可以了
这里就说明设计和实现是一一对应的
但如果他要这么用,则相应的插入和删除函数都要做出修改

头插函数
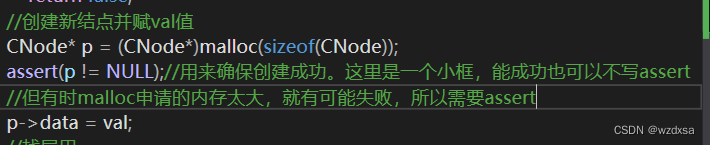
1.malloc申请结点p,val放进去
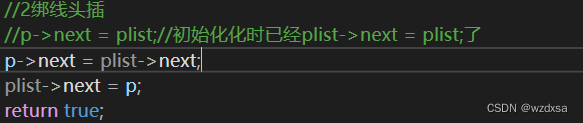
2.绑后面;p->next=plist->next;——>后面就是新申请(右边)的结点的next先按其顺序连线(也就是给p->next赋值),绑即=

3.绑前面plist->next=p;——>左边像后面顺序连接
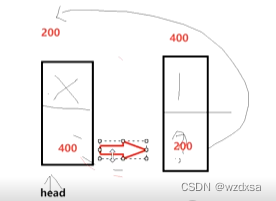

只要用该指针的指向符,则该指针必须要用assert——有->就有assert
p->next=plist只适用于插入第一个数据,
后面的数据再插入时就会出错,例如当第二个有效数据元素进行头插时,先绑后面的,p->next被赋值为plist->next的值,而plist->next就是绑的后面一串数据
如果直接还是让p->next=plist,那就是直接让头插进去的数据元素跟头结点形成总共为2个结点的循环链表,丢掉了后面的一串数据,也就是后面的线没绑起来
然后每次都是让新插入的数据跟头结点形成新的循环链表,前面旧的数据结点就都丢失了
而p->next=plist这句话之所以在只有一个头结点时插入第一个数据结点可以用,是因为此时这个第一个数据结点也就是最后一个数据结点了
而循环链表就是让数据结点的尾巴结点指向头结点plist,所以它p->next=plist只适用于头就是尾,尾就是头的总有效长度为1的头插
所以要用p->next=plist->next,它可以让第一个头插的结点绑向头结点,后面头插的结点绑住后面的元素线

可以发现其跟单链表里面的头插是一样的
这里先绑后面的,后面是空就绑空,是数据1的结点就绑1结点

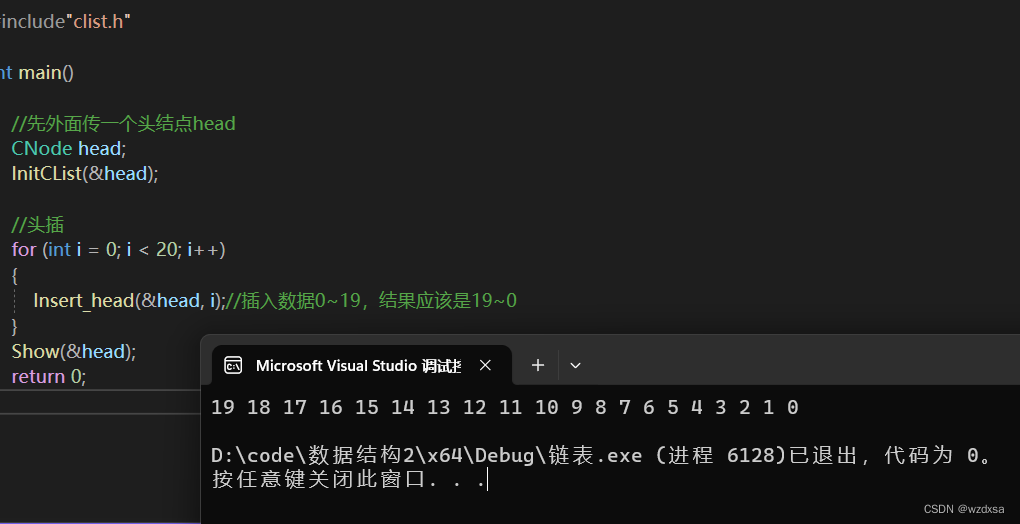
现在来测试一下
先写一下输出函数

它跟单链表唯一不同的地方就是循环退出条件为p!=plist;在单链表里面所有数据结点走完一遍p就到NULL了;而在循环链表里面数据结点遍历完一遍又从尾巴返回头结点plist了,这里plist相当于原来的NULL的位置
如果这里继续写p!=NULL的话,就相当于进入无限死循环的打印了,循环链表里面的next没有NULL,所以循环链表里面不能写NULL,只要写NULL就是错误
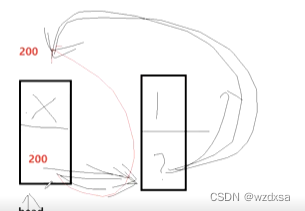
尾插函数(考试重点)

由上图知,尾插中找尾巴的遍历p要初始化成plist,对应的终止条件为p->next!=plist


绑后面也可以这样写,因为q->next==plist(循环链表里面)

除了遍历终止条件不是空,其他跟单链表也是一样的
所以循环链表就是将单链表里面空的地方换成plist,没空不管,有空就换

测试

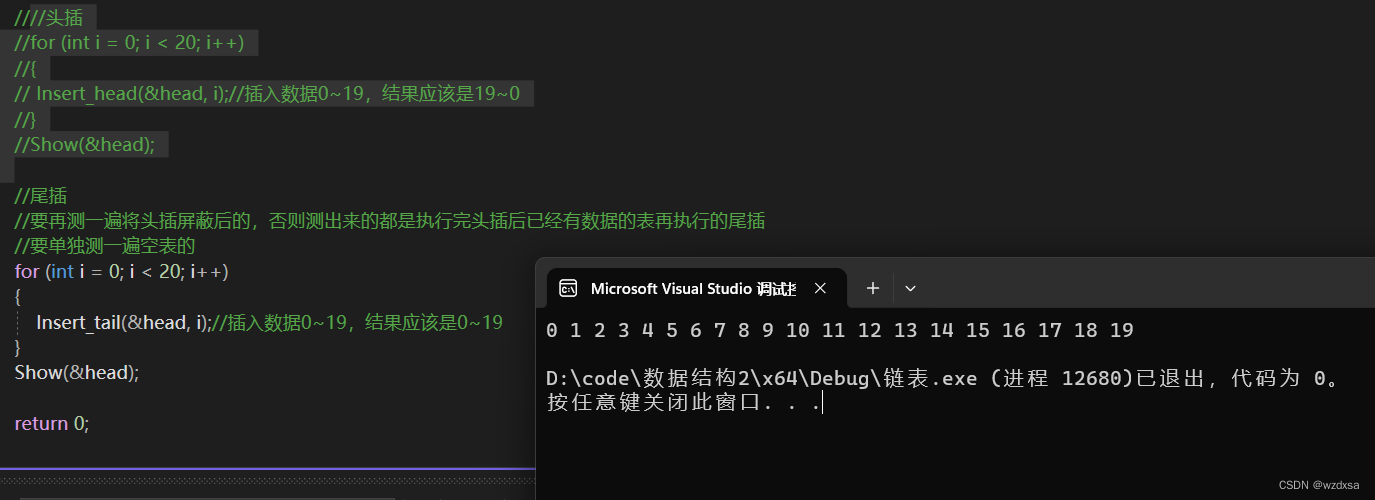
上面可以看到,头插是逆序,尾插是正序


![2023年中国羽绒制品需求现状、市场规模及细分产品规模分析[图]](https://img-blog.csdnimg.cn/img_convert/2c5266ceeb3caa72909d677679b46acd.png)